基于嗅觉受体激活关系模拟的气味感知预测*
2024-02-24左敏胡静珺颜文婧王瑞东张青川范大维
左敏, 胡静珺, 颜文婧, 王瑞东, 张青川, 范大维
1.北京工商大学农产品质量安全追溯技术及应用国家工程研究中心,北京 100048
2.北京市房山区教师进修学校,北京 102401
人类生理嗅觉系统十分复杂,气味分子和嗅觉受体(ORs, olfactory receptors)在气味感知表现中起着关键性作用。气味分子与嗅觉受体结合并激活嗅觉受体,将气味信号传递给大脑(Li et al.,2018),最终,人类对气味信号的感知被转化为相应的描述性词语(Lapid et al.,2011; Debnath et al.,2020;Francia et al.,2021)。受文化、语言和经验的影响,对于同一个气味分子人们可能会使用不同的感知词进行描述(Majid et al., 2018)。因此,对气味分子的气味感知进行预测是一项极具挑战性的任务。为解决这个问题,近年来智能信息研究领域尝试使用机器学习(ML, machine learning)方法构建气味感知预测模型(Keller et al., 2017),并获得了较好的效果。
目前大多数的气味感知预测模型都是从分子结构出发预测气味感知,该方式强烈依赖于分子表征(Pattanaik et al.,2020)。通常采用的方法是利用计算机表示方法对分子特征进行描述,进而构建机器学习模型。Shang et al.(2017)基于气味分子参数(MPs, molecular parameters),采用支持向量机(SⅤM, support vector machine)对1 026 个分子的10 种气味感知实现了正确率为97.08%的预测。Li et al.(2018)同样基于MPs,并采用随机森林算法(RF, random forest)对DREAM(dialogue on reverse engineering assessment and methods)数据集进行气味感知回归预测,气味强度预测的皮尔逊相关性指标达到了近似0.6。Kasyap et al.(2022)采用图神经网络(GNNs, graph neural networks)提取分子结构特征并在DREAM 数据集上进行气味感知多分类预测,模型的AUC指标为0.89。
然而,从生理学机制上看,仅仅考虑分子物化特性无法对气味感知的形成进行解释,相似的分子结构可能产生不同的感知,而不同的分子结构也可能会产生相同的感知。研究者已经对人类嗅觉生理学机制进行揭秘,发现激活的嗅觉受体是气味感知产生的关键(Buck,2008)。目前只有少数研究基于气味分子-嗅觉受体激活关系进行气味感知预测。Kowalewski et al.(2020)发现,在气味感知预测任务上,结合嗅觉受体激活特征对气味分子进行感知预测更具优势,可取得更好的效果。
本研究首先创新性地构建了嗅觉受体蛋白质关系网络,通过引入人类嗅觉受体蛋白之间的复杂关系来学习气味分子和嗅觉受体之间的复杂非线性高维关系。其次,采用图卷积网络,在分子拓扑结构和蛋白质网络结构上提取气味分子和嗅觉受体蛋白质关系网络上的关键特征,在大规模气味感知数据集DREAM 上实现对气味感知的精准预测。最后,基于预测的嗅觉受体激活信息,并结合模型正确决策的解释性分析,对气味分子-嗅觉受体活动-气味感知之间的模式进行分析,为人类嗅觉研究提供新的视角。
1 研究方法
1.1 研究框架
本研究首先基于人类嗅觉受体蛋白质关系网络构建嗅觉受体激活预测模型,通过图卷积方法分别提取气味分子和嗅觉受体蛋白的特征。其次,基于嗅觉受体激活预测模型的模拟结果,融合分子摩根指纹,基于DREAM 数据集实现对气味感知的回归预测。
工作流程如图1所示。
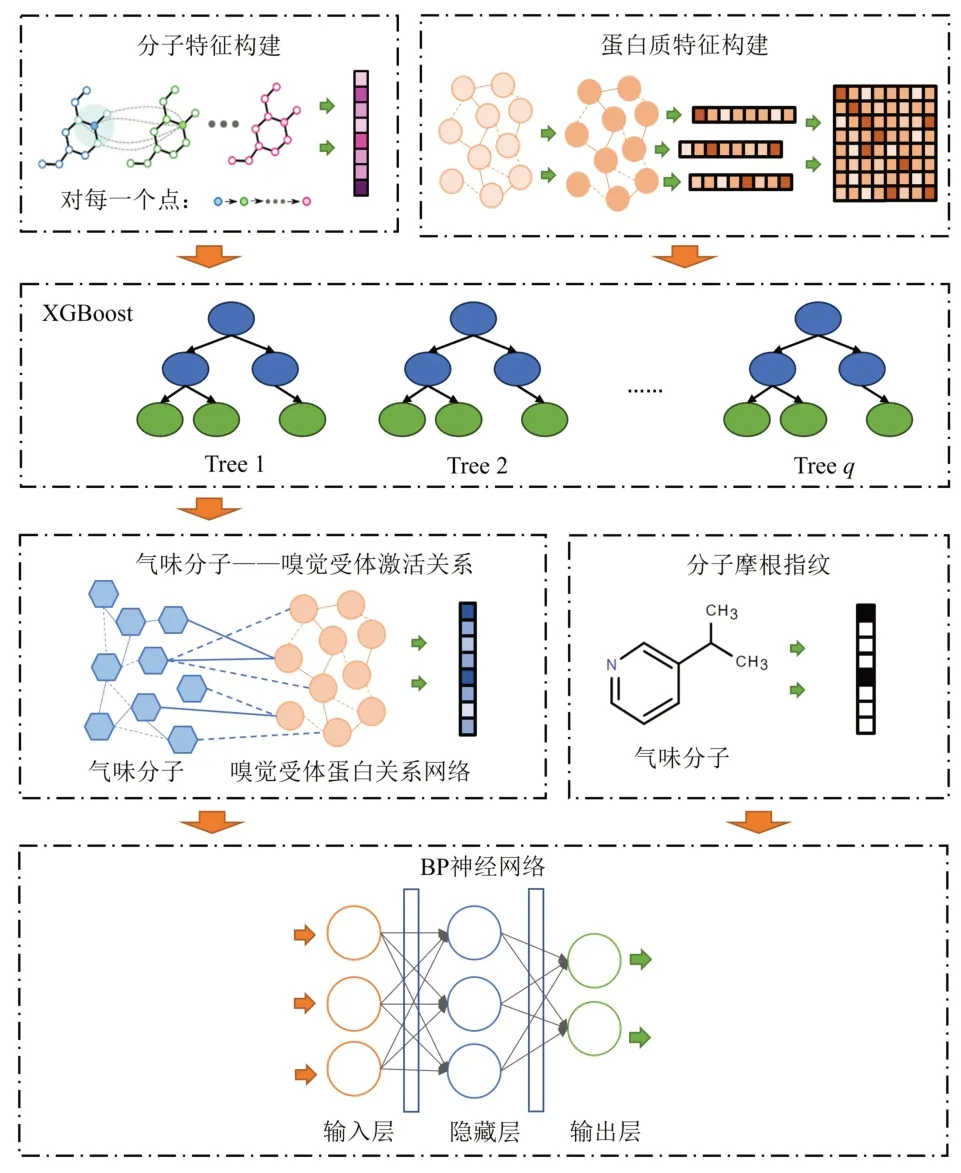
图1 气味感知预测工作流程图Fig.1 Olfactory perception prediction workflow diagram
1.2 蛋白质特征构建
1.2.1 嗅觉受体蛋白质关系网络构建本研究收集了43 个经过生物实验验证的确定可以被特定配体激活的人类嗅觉受体(Ⅴassar et al.,1993; Mata‐razzo et al.,2005; Jacquier et al.,2006; Neuhaus et al.,2006; Braun et al.,2007; Fujita et al.,2007;Keller et al.,2007; Menashe et al.,2007; Schmiede‐berg et al.,2007; Cook et al.,2009; Saito et al.,2009; Jaeger et al.,2013; Topin et al.,2014; Shirasu et al.,2014),采用One-Hot编码表示嗅觉受体蛋白氨基酸序列。嗅觉受体蛋白质三级结构信息有两个不同的来源。经过实验验证的结构来自于Uniport 蛋白质数据库,未知的嗅觉受体蛋白质三级结构则采用AlphaFold 蛋白质3D 结构预测模型进行预测。
嗅觉受体蛋白质关系网络以嗅觉受体蛋白质作为节点,其氨基酸序列作为节点特征,嗅觉受体蛋白质三级结构的相似关系作为边。根据已获得的嗅觉受体蛋白质三级结构,本研究采用TMscore (template modeling score)方法计算蛋白质之间的相似度。TM-score 是一种用于评估蛋白质结构拓扑相似性的指标,通过比较两个蛋白质全局结构的相似性来评估它们的匹配程度,其取值范围介于0 到1 之间。TM-score 低于0.17 被认为对应于随机选择的不相关蛋白质(Zhang et al.,2004),而大于0.5 则表示具有相似的折叠状态(Xu et al.,2010)。 TM-score的计算公式为
其中Ltarget是目标蛋白质的氨基酸序列长度,Lcommom是在模板结构和目标结构中均存在的残基数量,dt是模板和目标结构中第t对残基之间的距离,d0(Ltarget)是用来归一化距离的距离尺度。获得嗅觉受体蛋白质三级结构相似度后,可以构建嗅觉受体蛋白质关系网络。
1.2.2 蛋白质图卷积特征图卷积(graph convo‐lution)是一种适用于处理具有节点间关联关系的图数据的卷积操作方法。在本研究中,嗅觉受体蛋白质关系网络表示为Gp=(Vp,Ep),其中节点集合Vp表示嗅觉受体蛋白氨基酸序列集合,边集合Ep表示嗅觉受体蛋白质三级结构之间的相似度集合。每个节点的特征向量定义为vp,vp∈Vp,边的特征向量定义为ep,ep∈Ep。
嗅觉受体蛋白质关系网络是通过对嗅觉受体蛋白氨基酸序列和嗅觉受体蛋白质三级结构相似度进行编码得到的。嗅觉受体蛋白氨基酸序列被编码为一个具有20 种氨基酸和331 个序列位置的特征向量,其维度为[20,331],嗅觉受体蛋白质三级结构间相似度被编码为一个维度为1 的特征向量。
蛋白质图卷积特征的构建方法如下:
1.3 分子特征构建
1.3.1 分子摩根指纹在本研究中,任意分子图表示为Gm=(Vm,Em),其中节点集合Vm表示原子集合,边集合Em表示化学键集合。每个原子的特征向量定义为vm,vm∈Vm,化学键的特征向量定义为em,em∈Em。
摩根指纹(Morgan fingerprints)方法是一种用于描述分子结构的化学指纹方法。它基于分子的拓扑结构,对于节点v通过递归遍历分子的邻居节点u∈Rv,Rv是与节点v相连的节点集合,并将邻居节点的特征向量进行累积求和。然后,将累积特征向量Fu与连接边的信息Gu,v进行异或操作,并通过哈希函数进行映射,最终得到摩根指纹。摩根指纹计算公式
1.3.2 分子图卷积指纹分子图卷积指纹基于分子拓扑结构进行分子特征提取,分子和化学键的特征基于原子符号、相邻原子、相邻氢原子、隐含价、芳香性以及化学键类型等进行编码。具体如表1所示。

表1 分子特征向量构成Table 1 Molecular feature vector composition
对分子图进行图卷积操作
1.4 预测模型
1.4.1 SⅤM支持向量机(SⅤM, support vector machine)是一种常用的监督学习算法,其基本原理是寻找一个最优的超平面,将样本空间分成两个不同类别,并最大化样本与超平面之间的间隔。对每一个样本数据,SⅤM决策函数
其中x是输入样本特征向量,WSVM是决策函数的权重矩阵,bSVM是偏置项,sign是符号函数。
1.4.2 ELM极限学习机(ELM, extreme learning machine)通过随机初始化输入层和输出层之间的权重,然后利用解析解的方式直接计算隐藏层的权重。这使得ELM 能够快速地训练神经网络,并在很短的时间内生成准确的预测结果。对每一个样本数据,ELM决策函数
其中x是输入样本特征向量,HELM(x)是基于输入特征计算得到的隐藏层输出矩阵,WELM是输出层到隐藏层的权重矩阵,bELM是偏置项。
1.4.3 XGBoostXGBoost 是一种基于梯度提升树的集成学习算法。它通过迭代训练多个弱分类器(通常是决策树),并将它们组合成一个强大的模型。对全部N个样本数据,XGBoost的目标函数
其中LossXGB(yn,)是第n个样本的损失函数,yn是样本n的标签,是样本n的预测值,Ω(Φ)表示模型中的每个子模型的正则化项,Q是决策树的个数,γ是正则化系数。
1.4.4 BP 神经网络BP(back propagation)人工神经网络模型基于反向传播算法,通过不断调整网络中连接权重和偏置,使网络能够学习输入与输出之间的高维非线性映射关系。
BP神经网络的标准前向传播公式为
其中P表示训练样本的个数。
1.5 SⅤD-PCA
基于奇异值分解(SⅤD, singular value decom‐position)的主成分分析(PCA, principal component analysis)是一种常用的降维技术。SⅤD-PCA 的优点是可以处理高维数据,并且对异常值具有较好的鲁棒性。
给定一个数据矩阵XSP,首先对XSP进行标准化处理获得矩阵,使得每个特征均值为0,方差为1。然后,对标准化后的数据矩阵进行SⅤD分解
其中C和O是由SⅤD计算得到的矩阵,S是由SⅤD得到的正交矩阵。
PCA 的结果是通过选择奇异值及其对应的左奇异向量来进行降维。主成分矩阵可以通过以下公式计算得到
其中Z是降维后的数据矩阵。
2 实验过程
2.1 实验数据集
2.1.1 数据库1:气味分子-嗅觉受体激活关系数据库本文基于现有发表文献建立气味分子-嗅觉受体激活关系数据库,所有数据都来自于截至在2023 年7 月之前Web of Science 数据库中收录的文献。数据库共收集了43 个人类嗅觉受体,以及它们对选定的170个化合物的254条激活关系和61条非激活关系数据。
2.1.2 数据库2:气味分子-气味感知关系数据库DREAM 数据集使用包括强度、愉悦度和熟悉度在内的23 个感知定义气味感知。数据集包括49 名健康参与者(没有专业气味感知训练)对476种气味分子产生的21 种气味感知数据,评分范围为0~100。本研究选用标记为“高浓度”的数据共405 条。
2.2 嗅觉受体激活预测模型训练
嗅觉受体激活预测XGBoost 模型参数设置如表2所示。

表2 XGBoost模型参数调节范围1)Table 2 Parameter adjustment range of XGBoost model
模型评价指标选取准确率(accuracy)、F1-score、受试者工作特征(ROC, receiver operating character‐istic curve)的曲线下面积(AUC, area under the curve)。
2.3 气味感知预测模型训练
气味感知预测模型训练采用5折交叉验证,即将数据划分为大致相等的5个子数据集,依次采用不同数据集作为训练集和测试集。取5次训练平均精度的平均值即得到模型精度,这样得到的模型精度更具有泛化性。
气味感知预测BP模型参数设置如表3所示。

表3 BP模型参数调节范围1)Table 3 Parameter adjustment range of BP model
模型评价指标选取R2-score、皮尔逊相关性、均方根误差(RMSE, root mean square erro)。
3 实验结果与分析
3.1 嗅觉受体蛋白质关系网络
本研究使用嗅觉受体蛋白质关系网络中100%的相似度、前70%的相似度、前50%相似度网络关系,获取相关网络性质指标,并使用基于模块度的社区发现算法分析网络的模块性(Blondel et al.,2008)。分析如表4所示。本研究基于相似度排名前50%的数据绘制出嗅觉受体蛋白质关系网络图(图2)。使用相似度排名前50%的网络呈现出明显的3个子模块,且不存在孤立节点。属于同一模块的嗅觉受体具有相似的蛋白质结构,比如,图2中嗅觉受体OR2J3 与OR2J2 同属于一个社区模块,同时,研究也证实它们是人类嗅觉受体中最为相似的嗅觉受体对之一(Crasto et al.,2002)。

表4 嗅觉受体蛋白质关系网络概览Table 4 Network overview of olfactory receptor protein relationship

图2 嗅觉受体蛋白质关系网络(前50%)Fig.2 Olfactory receptor protein relationship network (Top 50%)
3.2 基于不同特征提取方式的嗅觉受体激活预测结果比较
分子的表征方式在化学领域中尚未形成统一的标准,不同的表征方法各具优势和局限性。本文对气味分子和嗅觉受体蛋白分别采用了两种不同的特征提取方法,并进行对比实验。结果如表5所示。结果表明,当分别使用图卷积进行分子特征和嗅觉受体蛋白氨基酸序列特征提取时,采用XGBoost 算法实现了最佳的嗅觉受体激活预测效果,准确率为77%,F1-score 为0.78,AUC 值为0.77。4 种特征提取方式AUC 比较结果如图3所示。

表5 不同分子特征提取方式组合在数据库1上的准确率、 F1-score和AUCTable 5 Accuracy, F1-score, and AUC of different feature extraction methods for database 1

图3 不同特征提取方式组合的ROC曲线及AUC值Fig.3 ROC curves and AUC values of different feature extraction methods
3.3 基于不同分类器的嗅觉受体激活预测模型比较
基于图卷积特征提取,本文采用XGBoost、SⅤM 以及ELM 3 种机器学习方法进行嗅觉受体激活预测,并进行对比实验,结果如表6所示。实验结果表明,XGBoost 算法在气味分子-嗅觉受体激活关系数据库上表现结果最优,准确率为77%,F1-score 为0.78,AUC 为0.77。3 种分类器的嗅觉受体激活预测模型AUC比较结果如图4所示。

表6 不同分类器的嗅觉受体激活预测模型在数据库1的准确率、F1-score和AUCTable 6 Accuracy, F1-score and AUC of olfactory receptor activation prediction models for different classifiers on database 1

图4 不同分类器的嗅觉受体激活预测模型的ROC曲线和AUC值Fig.4 ROC curves and AUC values of olfactory receptor activation prediction models for different classifiers
3.4 气味感知预测结果比较
本研究在嗅觉受体激活预测模型的基础上,对DREAM 数据集中的化合物与43 个嗅觉受体的激活关系进行预测,将获得的新气味分子-嗅觉受体激活关系作为分子特征应用于气味感知预测模型。在数据集和回归预测模型相同的情况下,引入气味分子-嗅觉受体激活关系进行气味感知预测结果明显优于仅基于分子结构进行气味感知预测。实验结果说明在进行气味感知预测时,考虑嗅觉受体的活动情况是必要的。实验结果如表7所示。
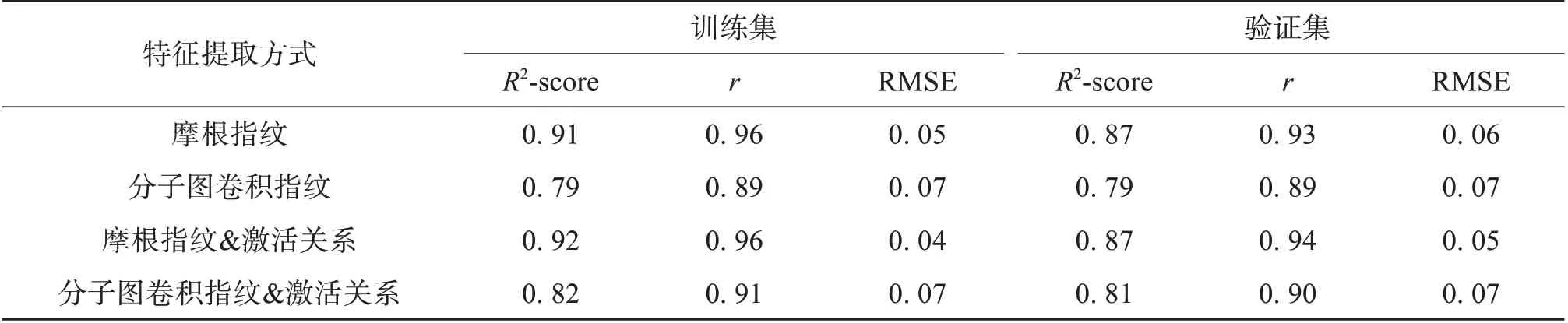
表7 不同特征提取方式在DREAM数据集上的R2-score、 r和RMSETable 7 R2-score, r and RMSE on the DREAM dataset with different feature extraction methods
在3.3 节中,对于嗅觉受体激活预测任务,图卷积特征提取方法明显优于摩根指纹特征提取。然而,在本节的气味感知预测任务中,摩根指纹方法表现更优。这是由于图卷积方法和摩根指纹方法对分子特征表达方式不同造成的。图卷积方法基于图结构进行特征提取,考虑了原子之间的连接关系,在捕捉分子的全局信息上具有优势。而摩根指纹根据分子的物理化学性质进行有效编码,更擅长总结分子的理化特征(Cereto-Massagué et al.,2015; Duvenaud et al.,2015; Kipf et al.,2016)。
3.5 气味分子-嗅觉受体激活-气味感知模式
本研究通过嗅觉受体蛋白质关系网络,整合了DREAM 数据集和气味分子-嗅觉受体激活关系信息。采用基于奇异值分解的主成分分析方法对嗅觉受体在特定气味感知中的贡献进行分析。嗅觉受体对21 种气味感知的贡献度归一化后的结果如图5所示。大部分嗅觉受体会对特定气味感知产生较高的贡献度(Audouze et al.,2014)。
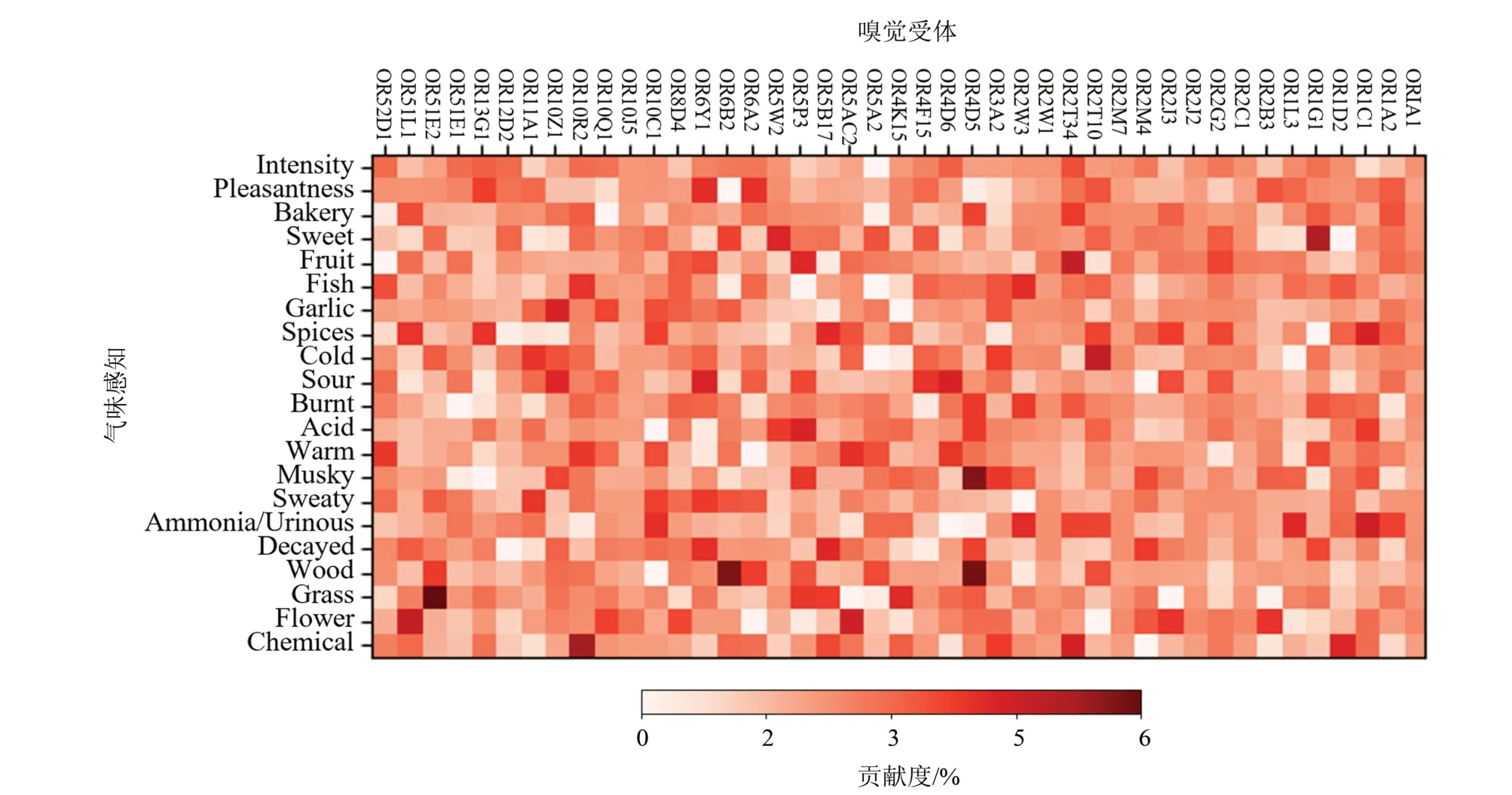
图5 嗅觉受体对气味感知贡献度Fig.5 Olfactory receptor contribution to olfactory perception
此外,本研究采用密度聚类算法(Campello et al.,2020),对来自DREAM 数据集的405 个气味分子的43 个嗅觉受体激活特征进行聚类,将分子分为4个类别,并绘制了气味分子-嗅觉受体激活-气味感知模式图。如图6所示,产生激活关系少于20条的嗅觉受体并没有被绘制,DREAM 数据集中气味感知评分低于5 分的气味感知描述词没有被绘制。

图6 气味分子-嗅觉受体激活-气味感知模式Fig.6 Odor molecule-olfactory receptor activation-olfactory pattern
研究结果表明,经由气味分子-嗅觉受体激活关系对分子进行分类在气味感知上出现了明显的模式上的不同。例如,“腐烂(decayed)”只与第1类分子激活的3个嗅觉受体相连;“花(flower)”只与第4类分子激活的4个嗅觉受体相连等,本研究部分结果与已得到的生物实验结果验证一致(Chaput et al.,2012; El Mountassir et al.,2016; Keller et al.,2016)。本研究同时尝试了使用SMⅠLES分子表达式和摩根指纹对分子进行聚类,所获得的结果难以提取出明显的气味分子-嗅觉受体激活-气味感知模式。
4 结 语
本研究旨在提出一种基于数据驱动方法的气味感知预测和分析的新解决方案。首先,构建了嗅觉受体蛋白质关系网络,采用图卷积方法以获得更全面有效的嗅觉受体蛋白特征。在嗅觉受体激活关系数据的基础上,构建了嗅觉受体激活预测模型。其次,面向DREAM 数据集并引入其嗅觉受体激活数据,以提供必要的生理信息补充,实现对气味分子感知的精准预测。最后,对模型形成的正确决策机制进行解释分析,并总结了气味分子-嗅觉受体激活-气味感知模式。研究结果表明,综合考虑气味分子特征和气味分子-嗅觉受体激活关系构建预测模型,能够获得更好的预测结果,并获得对人类气味感知模式的有效总结。
尽管研究结果仍需要进一步验证,但本研究为进一步探索和理解气味感知机制提供了有价值的参考和启示。未来的工作将面向更多的气味感知数据集进一步优化模型,基于数据驱动技术进一步学习气味分子与嗅觉受体激活的对接模型,为气味感知的预测提供更多有用的信息,进一步推进人类嗅觉机理研究。
