基于深度聚类的通信辐射源个体识别方法
2024-02-23郭京京齐子森
贾 鑫, 蒋 磊, 郭京京, 齐子森
(1.空军工程大学信息与导航学院,西安,710077;2.93184部队, 北京,100076)
随着人工智能技术广泛应用于军事领域,新科技将推动战争形态向智能化演变,同时带来更大机遇和挑战[1]。通信辐射源个体识别是情报侦察和电子支援的前提,是跟踪目标辐射源位置和获取敌方通信网络的基础。电磁频谱作为连接陆、海、空、天、网等作战空间的纽带,随着战场通信设备的种类和数量日益增多,空间电磁环境复杂度进一步提升,通信辐射源个体识别难度不断加大,目前已成为信号处理领域的研究热点之一。
辐射源个体识别(specific emitter identification, SEI)技术也被称为射频指纹识别技术(Radio Frequency Fingerprinting, RFF),是一种通过测量射频信号的外部特征并提取发射器特定信息识别发射源的技术[2]。该技术不依赖信号传输内容,通过直接提取发射设备硬件的细微特征进行识别,提取的细微特征即为射频指纹[3]。射频指纹来源于硬件设备制造时的偏差,无法避免和伪造,具有通用性、稳定性、唯一性、可测量性和独立性[4]。SEI的核心在于射频指纹信息的提取和分类。一般情况下可分为2类:①基于人工的辐射源个体识别方法;②基于深度神经网络的辐射源个体识别方法[5]。基于人工的辐射源个体识别方法又可分为基于瞬态特征的识别方法[6-8]和基于稳态特征的识别方法[9-11]。基于瞬态特征的识别方法,通过提取设备状态切换过程中的瞬态特征进行个体识别。此类方法中提取的瞬态特征与设备指纹特征直接相关,但其持续时间短,难以获得,并且对设备的精密度以及采集条件要求较高,因此并未被广泛应用。基于稳态特征的识别方法利用设备功率稳定期间采集的稳态特征进行个体识别。相较于瞬态特征,该特征更易提取,但计算分析复杂度较高。基于人工的辐射源个体识别方法原理清晰、特征明确、鲁棒性强,但随着物联网技术的快速发展,设备类型和数量急剧增加,导致上述方法出现复杂度较高、泛化性较差、识别率较低等问题,已逐渐难以满足大规模数据和高实时性的要求[12]。部分学者提出了基于无监督的通信辐射源个体识别方法以解决上述问题。李昕等[13-14]提出了基于密度峰值算法进行通信辐射源个体识别,在信噪比为20 dB时,识别准确率为64%以上,随后其利用核密度估计及热扩散方程改进算法,在信噪比为20 dB时,识别准确率为68%以上。
基于深度学习的通信辐射源个体识别技术按照数据预处理方法可分为3类:第1类是数据降维处理的方法;第2类是数据转为图像处理的方法;第3类是I/Q信号直接处理的方法。第1类方法是对原始数据特征提取后进行降维处理,再对降维后的数据进行分类识别。Ding等[15]利用CNN对降维后的矩形积分双谱进行个体识别,较好地实现了对多个通用软件无线电外围设备的识别。第2类方法是将数据转换成图像,再利用CNN网络进行识别。Peng等[16]通过差分星座轨迹图来提取ZigBee设备的射频指纹特征,并利用K均值聚类的方法完成分类识别,实验对54个ZigBee设备在信噪比为30 dB和15 dB的情况下,识别准确率分别达到99.1 %和93.8 %。第3类方法是直接对I/Q数据进行特征提取及分类识别。Liu等[17]利用深度双向长短期记忆网络和一维残差卷积网络的组合,对基带I/Q信号进行特征提取,实现了较低计算量下的个体识别。以上3类方法被学者们大量研究,其中第1类方法数据量较低,但从高维到低维特征转换中难以避免特征损失。第2类方法更吻合深度神经网络的特征提取要求,效率更高、鲁棒性更强,但转换为图像过程中存在部分特征丢失。第3类方法无需进行数据预处理,在保证特征信息完整的前提下可充分发挥深度神经网络的特征提取能力,因此被视为基于深度学习的通信辐射源个体识别方法的发展趋势。
上述基于深度学习的通信辐射源个体识别方法均在有监督条件下进行,其前提条件是需要大量有标签数据,但在非合作通信场景下,获取未知目标的先验信息极为困难,无法制作足够的有标签数据样本,导致基于有监督的深度学习方法性能恶化,无法满足此场景下的个体识别需求,因此广大学者开始研究基于无监督深度学习的通信辐射源个体识别方法。深度聚类方法作为无监督深度学习方法的主流之一,被广泛应用于计算机视觉,音频,图形,文本等诸多领域,并取得巨大成功[18-20]。
深度聚类算法通过将深度神经网络与浅层聚类分析有效融合,实现了在潜在特征空间中进行聚类分析,使数据特征区别度扩大,更好地进行聚类分析。深度聚类算法通常分为分步深度聚类算法和联合深度聚类算法2类。第1类是先利用深度学习模型进行特征降维,然后再进行聚类分析。Tschannen等[21]通过训练的深度自编码器来学习表征特征,并将这些特征作为K-means方法的输入来完成聚类。Huang等[22]学习关联矩阵和实例表示,然后通过对关联矩阵的谱聚类来完成深度聚类,并取得较好效果。第2类则是在模型的训练过程中,特征表示和聚类标签同时学习优化。张旭[23]提出联合深度图聚类与目标检测的SLAM算法,在保证实时性的前提下,提高了SLAM系统的定位精度。邢若苇[24]利用实例-簇级别对比聚类算法,在实力级别和簇级别均融合类别信息,并同时进行特征学习和簇分配,并取得较好聚类效果。由于分步深度聚类方法中特征提取和聚类是独立进行的,因此特征提取和聚类分析融合度可能较低,导致聚类效果不理想;联合深度聚类方法同步进行特征提取和聚类分析,可以有效避免所提特征与聚类网络融合度低的问题。
1 基于深度聚类的个体识别算法
联合深度聚类模型中最典型的为采用自编码器结构的模型,其通过使输出逼近输入,实现对输入数据的深层特征学习,因其简单有效,而被广泛应用于联合深度聚类方法[25]。1986年,Rumelhart等[26]最先提出了采用编码器结构的联合深度聚类模型的相关概念。由于其本身优异的特征学习能力,在近年来成为深度聚类领域中广泛使用的网络结构。2016年,Xie等[27]对已有方法进行改进,提出了深度嵌入式聚类(deep embedded clustering,DEC),通过自训练目标分布迭代优化来同时优化表征特征和聚类分配的整体框架,来提升效果。本文在DEC的基础上,提出了基于深度聚类的通信辐射源个体识别算法。
1.1 算法模型
本文基于联合深度聚类方法,设计了针对通信辐射源个体识别的算法,设计流程如图1所示。数据预处理是通过对原始复值I/Q数据进行切分,得到2路实值I/Q数据之后,进行数据切割和加噪处理,并根据实际需求划分训练集和测试集,完成网络训练数据集的生成。表征学习中采用了自编码器结构,利用变分自编码器的编码器和解码器完成信号样本的特征压缩与样本重构,通过最小化重构信号样本与初始信号样本的均方误差实现网络的优化更新,完成对信号样本的深层特征提取。分类识别中采用了划分聚类算法中的K-means聚类算法,其思想是计算样本与聚类中心的欧氏距离划分各样本所属的聚类簇[28],通过最小化样本和所属聚类簇中心的距离实现样本分类。
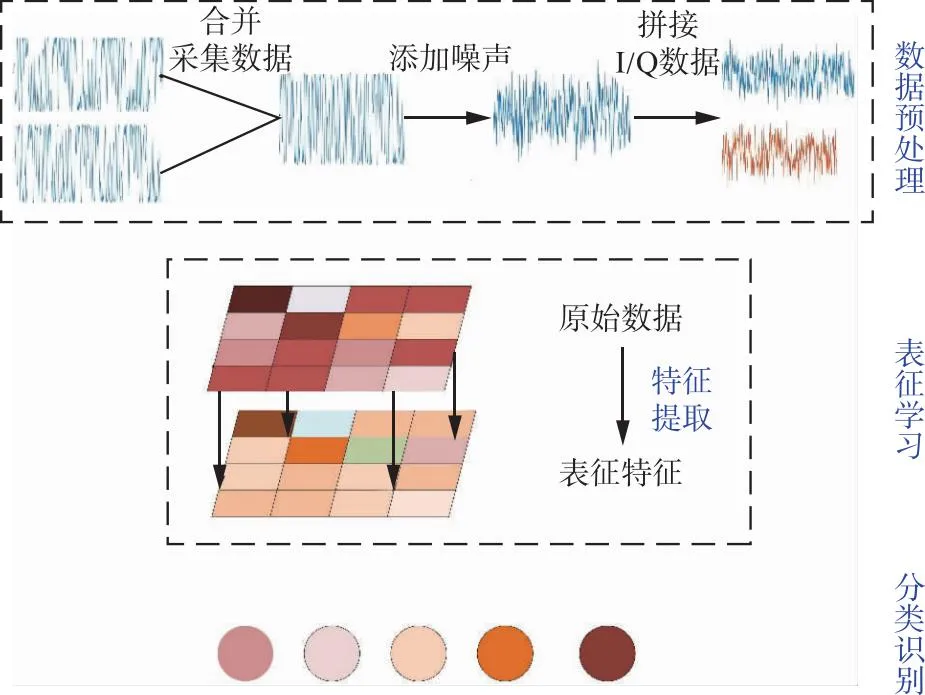
图1 基于深度聚类的通信辐射源个体识别流程
1.2 网络结构设计
基于深度聚类的通信辐射源个体识别模型网络结构如图2所示。

图2 基于深度聚类的通信辐射源个体识别网络
本文算法为实现对通信辐射源个体的精准分类识别,同时匹配I/Q数据的输入,将整体网络设计为表征学习和聚类过程。采用了自编码器结构,包含编码器与解码器。编码器由输入层、3层卷积层、1层全连接层构成,主要完成原始I/Q数据到低维特征的提取过程。解码器由3层反卷积层和输出层构成,主要完成由低维特征重构原始数据的过程。输入层将数据处理模块I/Q数据样本进行维度变换,由m×n维转换成m×2×n×1维。考虑到样本维度大小,通过二维卷积conv2D,以same模式对m×2×n×1维样本进行卷积操作,即对每个样本的边缘进行补零,确保卷积得到的样本尺寸保持一致。卷积核尺寸为(1,8),特征通道数分别为32、64、128个,分别提取得到m×32,m×64,m×128维特征,之后采用Relu函数进行激活。该函数是具有分段线性的线性整流单元(deep sparse rectifier neural networks),可以促进梯度的反向传播,降低反向函数的运算量,其部分激活特性相当于对网络施加了稀疏正则化,对网络的鲁棒性和泛化能力有一定的提升。解码器采用3层反卷积层来重构原始I/Q数据,并通过反向传播算法,最小化重构I/Q数据与原始I/Q数据差异,促进网络学习到通信辐射源网络个体特征。3层反卷积层的网络参数与卷积层的参数对称布置。聚类过程中为了简化网络结构与降低运算复杂度,采用了K-means算法进行聚类分析。首先随机选择要分成簇的个数k,并随机选择k个数据点作为初始质心,随后计算每个数据点与质心之间的距离并进行簇分配,更新质心位置,不断进行迭代,直到最后质心稳定后停止迭代。
1.3 网络优化更新
1.3.1 损失函数
本文深度聚类网络的损失函数为联合损失函数,由重建损失函数和聚类损失函数共同构建。重建损失是自编码器原始数据和解码器重构出的数据之间的均方误差,表达式为:
式中:n为样本数量;xi为原始数据样本;gθ(·)为解码器函数;fφ(·)为编码器函数。通过最小化重建损失Lrec使提取到的特征尽可能接近原始数据特征[29]。
聚类损失采用KL散度,KL散度可度量2个分布之间的差异指标,从而最大化真实分布X与拟合分布Y之间的差异,其表达式为:
(2)
式中:yij为提取特征得到的点Si与聚类中心Ui的相似程度,可用t分布进行度量,其具体表达式为:
(3)
式中:α为t分布的自由度。
真实分布X的表达式为:
(4)
1.3.2 评估指标
为了更好地调试和优化网络结构性能,对网络进行具体性能分析,本文采用了3类评估指标对深度聚类网络的性能进行评价,包含识别准确率(accuracy)、标准互信息指数(normalized mutual information,NMI)和调整兰德指数(adjusted Rand index,ARI)。ACC表示正确分配的结果数量样本占该样本总量的百分比,其计算式为:
(5)
式中:n为样本总数;li为真实簇标签;ci为算法输出的预测簇标签;m(ci) 为映射函数表示真实标签与预测标签之间一一映射,一般使用匈牙利算法进行实现。
标准互信息指数(NMI)是利用2个数据分布的信息熵来衡量其接近程度,其计算式为:
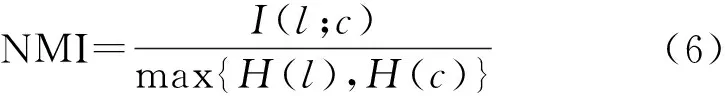
式中:I(l;c) 为真实标签与预测标签之间的互信息程度;H(l)为真实标签的熵值;H(c) 为预测标签的熵值。
ARI表示真实类别与聚类划分类别的重叠程度,其计算式为:
以上3类评估指标值域是0到1,指标越高,意味着划分越准,聚类效果越好。
2 实验与结果分析
2.1 实验平台和数据预处理
本实验基于Python下的Tensorflow、Pytorch深度学习框架完成,所使用的硬件平台为Intel(R) Core(TM) i7-10875H CPU,GPU为NVDIA GeForce RTX 3090。
采用的数据集为5种ZigBee设备的实采信号[16],5种设备的样本来自于各自对应的5段原始信号(9个帧段)。将每种设备采集到的复值数据进行切分得到I路和Q路实值数据,并按列拼接后进行加噪处理,得到2×M维数据,再进行样本切片后得到1 441个2×256维的I/Q数据样本。将这些I/Q数据样本进行混合,生成实验数据集。利用生成数据集中信噪比为20 dB的数据,进行网络预训练,将训练好的网络参数保存,并进行实验。
图3为深度聚类网络损失函数曲线图,从图中可以看到,随着训练轮次增加,网络损失逐渐降低并趋于稳定,说明深度聚类网络在训练过程中收敛较好。
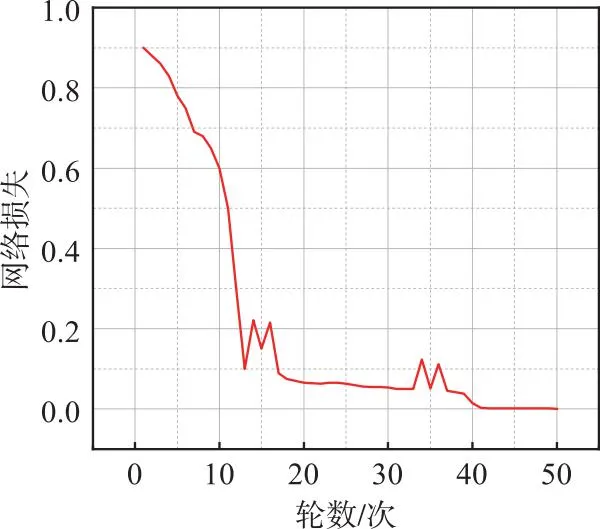
图3 网络损失函数曲线图
2.2 不同样本长度下识别效果验证
图4为不同样本长度下的识别性能曲线图。图4(a)为不同信噪比条件下,样本长度分别为64、128、256时,5个通信辐射源个体的平均识别准确率,从图中可以看出,样本长度为256的识别准确率最高,在信噪比为15 dB时,3种样本长度的识别准确率均接近一致,达到了100%。图4(b)为不同信噪比条件下,3种样本长度下2类评估指标的变化,从图中可知,样本长度为256的2类评估指标最高,3种样本长度下的评估指标随信噪比的升高逐渐增大。
图5为10 dB信噪比下的3种样本长度分类效果图,通过对比图5(a)~图5(c),可以看出,10 dB信噪比下,长度为256的分类识别效果最好。

(a)识别准确率
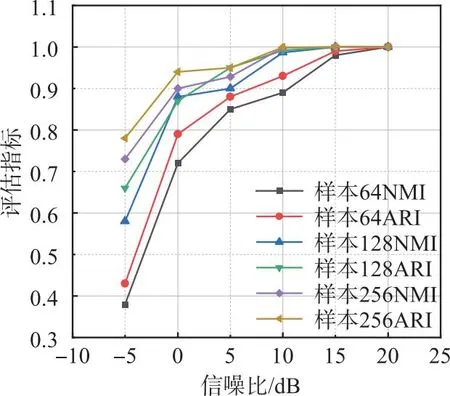
(b)评估指标
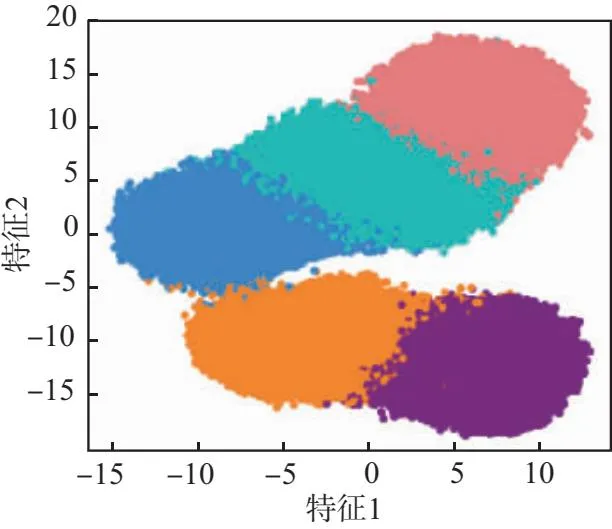
(a)样本长度为64
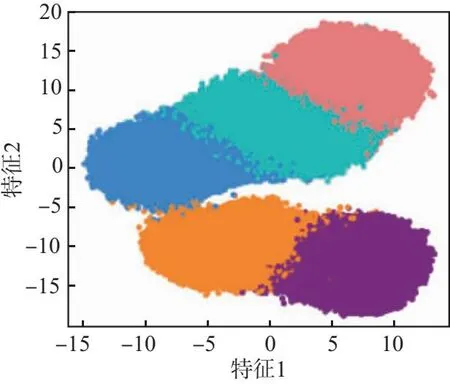
(b)样本长度为128

(c)样本长度为256
通过以上实验可知:相同信噪比条件下,样本长度较长的通信辐射源个体识别效果较好;随着信噪比升高,不同样本长度的识别效果逐渐变好,并趋于100%。
2.3 不同信噪比下识别效果验证
图6为0~15 dB信噪比下的分类混淆矩阵,由图可得:随着信噪比的提高,5类个体的识别准确率均有所提高;在0 dB下,平均识别准确率达到了85%以上,说明了在较低信噪比下,个体识别准确率仍可以保持较高;在15 dB下,5类个体的识别准确率趋于稳定并达到100%。
图7为不同信噪比下5类个体的识别性能图,由图7(a)可知,随着信噪比的提升,5类个体的识别准确率均有所提高,在0 dB以上时,通信辐射源个体的识别准确率均在85%以上,证明本文方法对5类个体均有效;由图7(b)可得,3类评估指标随着信噪比的提升逐渐升高,在10 dB时趋于1,证明了本文方法的有效性。
图8为0~20 dB下样本长度为128的信噪比分类效果图。通过对比各个子图结果可知,样本长度为128时,随着信噪比的升高,5个通信辐射源个体识别效果逐渐变好,信噪比越高,5个通信辐射源个体的类间距越大,分类效果越好,直观地证明了本文方法可以较好地完成通信辐射源个体的识别。
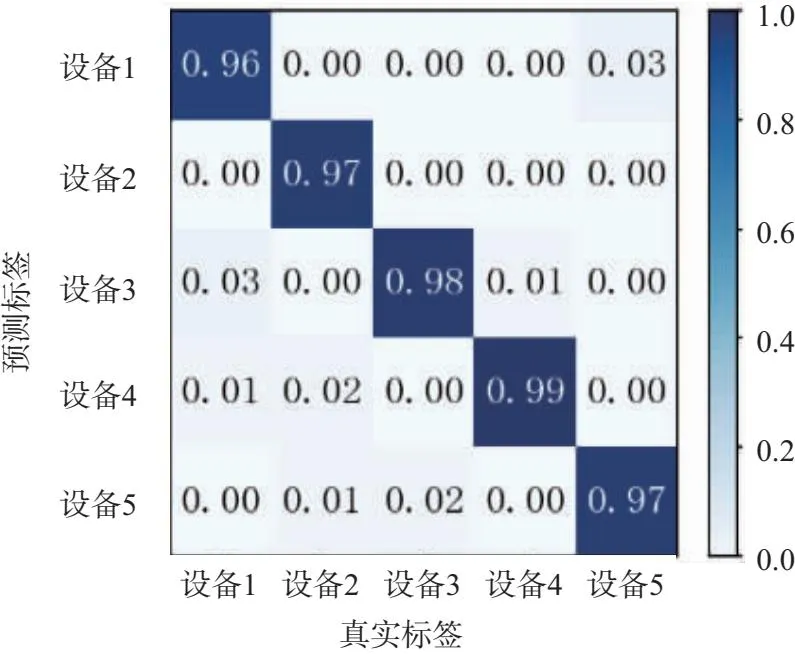
(a)混淆矩阵(SNR=0 dB)
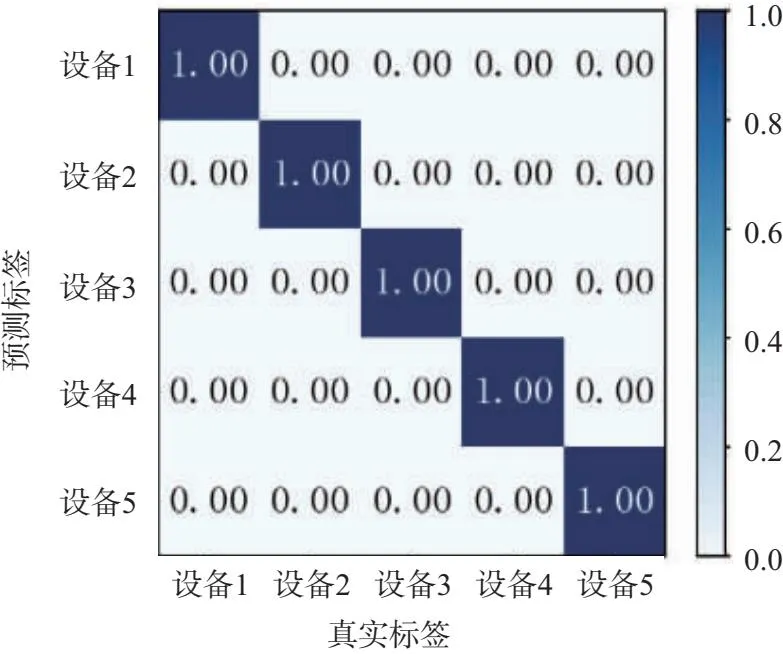
(b)混淆矩阵(SNR=5 dB)
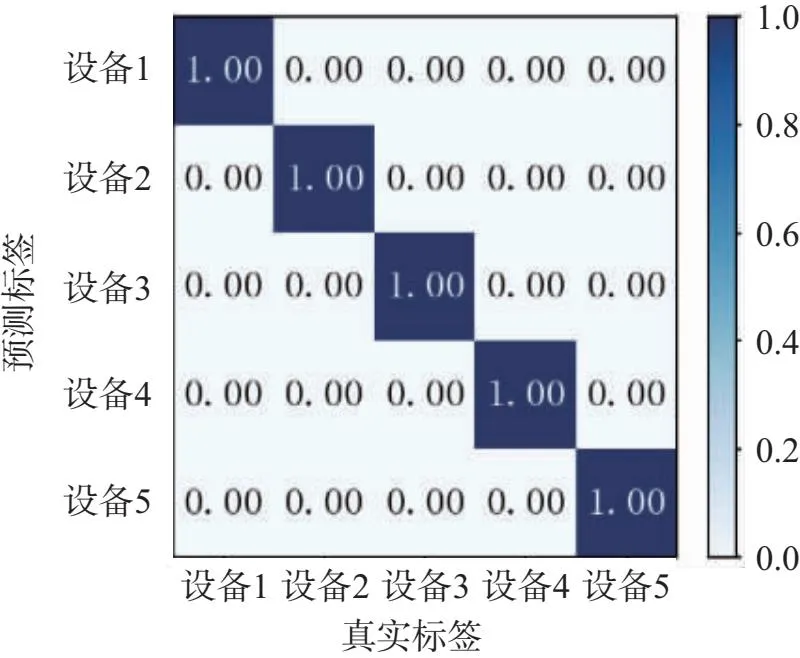
(c)混淆矩阵(SNR=10 dB)

(d)混淆矩阵(SNR=15 dB)
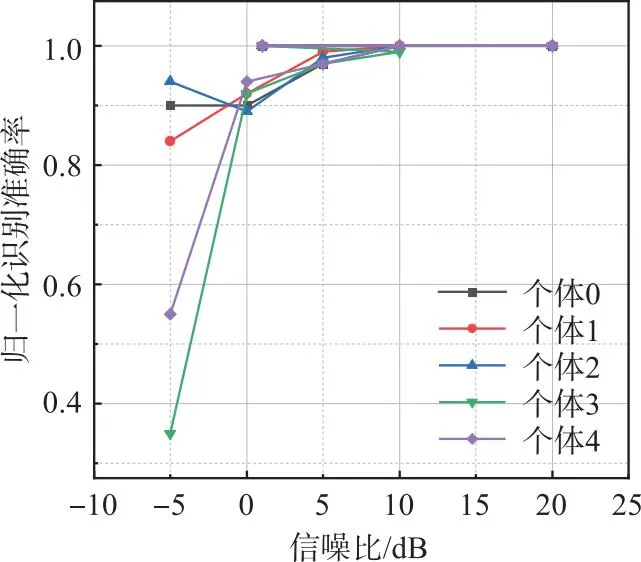
(a)识别准确率
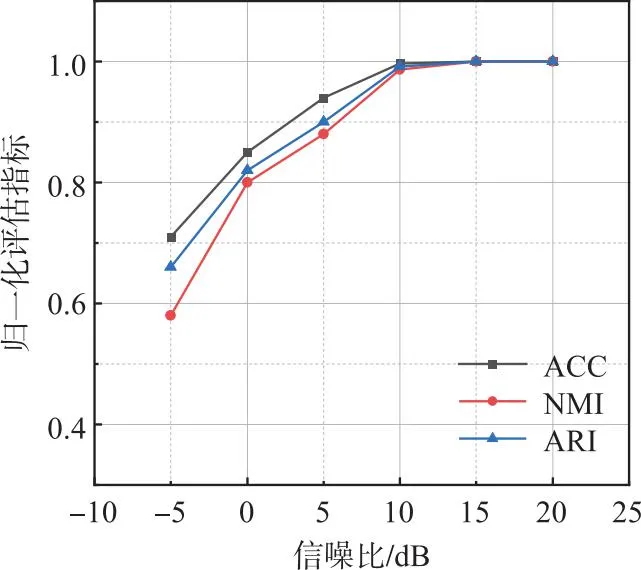
(b)评估指标


(a)-5 dB (b)0 dB


(c)5 dB (d)10 dB

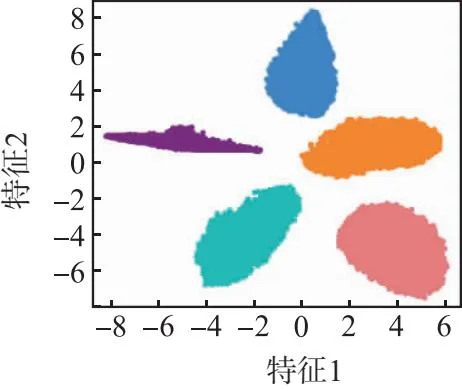
(e)15 dB(f)20 dB
2.4 与其他算法性能对比
将本文算法与典型的无监督算法进行对比实验。实验设置:5种ZigBee设备的实采信号,添加高斯白噪声得到-5~20 dB信噪比的信号,将不同信噪比下的信号数据切分为长度为128的样本,并随机抽取其中的4 000个样本组成实验数据集。
图9为本文算法与4种无监督算法的性能对比。其中,基于密度峰值聚类(density peaks clustering,DPC)算法是基于传统深度聚类方法[13],K-means++[30]、Dbscan[31]是典型的无监督机器学习方法,infoGan方法是在Dbscan上加入先验特征的深度学习算法[32]。从图9可以看出,本文所设计的算法在不同信噪比条件下较其他4种方法拥有更好的识别准确率,因此本文所用的基于深度聚类的方法较传统聚类方法和经典无监督机器学习方法的识别率有所提高,进一步证明了本文设计的基于深度聚类的通信辐射源个体识别方法的有效性和可靠性。

图9 算法性能对比
3 结语
本文针对非合作通信条件下缺乏足够有标签样本的通信辐射源个体识别的问题,提出了基于深度聚类网络的通信辐射源个体识别方法,通过自编码器的特征提取与数据重构能力,增强了对原始I/Q数据的指纹特征提取性能,并用联合优化的方式实现特征提取与聚类分析的更新优化,实现了无监督条件下的通信辐射源个体分类,仿真结果表明文中方法在信噪比0 dB以上时可以达到85%以上的识别准确率,证明了本文方法的有效性和稳定性。
