基于双螺旋结构的声卡同步输入输出
2024-02-22陆成刚王斌龙皋月
陆成刚, 王斌, 龙皋月
(1.浙江工业大学 理学院, 浙江 杭州 310023;2.浙江华数广电网络股份有限公司,浙江 杭州 310017)
0 引 言
声卡是计算机处理多媒体声音功能的重要部件,甚至被用于工控系统的数据采集[1],除了集成在主板的声卡外,还有一些场合是使用PCI插槽形式的独立声卡。一般情况下,声卡的录音和播放是独立、互不相关的,除了在本地场合使用声卡作为演讲的扩音设施,或者作为远程通信的语音终端之外,很少需要考虑录音和播放之间的严格同步。事实上这涉及到声学回声消除的问题[2]1,与使用麦克风阵列进行声源定位的波束形成、有源主动降噪技术等问题类似[3],它们都需要考虑多路信号的数据同步。
由于声卡晶振的老化[4]和操作系统软件的调度抖动[5]等因素,如果不去专门针对性地加强设计,那么录音、播放即便在同等调度优先级下,它们的调用频率的一致性都是有欠缺的。在使用计算机声卡进行远程语音通信时,通常需要集成声学回声消除模块,而声学回声消除模块的有效性需要声卡输入输出较好的同步性支持。历史上,这个问题解决得较好的是Global IP sound公司,但该技术的同步的实现细节一直没有使用专利或论文披露,后来该公司被谷歌收购,就是现今谷歌WebRTC技术的由来[2]2。
本文从声卡录音播放的编程模式着手,分析了常用的教科书式的录音、播放调度模式的频率失衡,然后从回调递归的对称交叉,进行逻辑链变向,设计了一种结构类似于基因双螺旋的录音播放调度模式[6],起到了对系统抖动一定程度的缓冲中和,达到了提升录音播放频率平衡的目的。
1 声卡调度原理
计算机系统一般使用DMA直接内存访问机制进行声卡读写,声卡在DMA控制器下直接与DMA读写交互,免于频繁地受到CPU干预,提高了CPU/操作系统的调度效率。操作系统与DMA控制器协作,以内核缓存对DMA进行读写交换,这样将声卡数据交换出/入内核缓存,然后操作系统以内核缓存数据交换出/入应用缓存,而应用缓存是声卡应用程序直接读写的。和DSP等嵌入式系统的音频应用接口比较,计算机声卡读写具有一定的延时(应用缓存块数至少要大于等于3),除此之外,由于DMA机制使得声卡外设独立工作,极大降低了声卡应用程序的CPU占用率。图1为基于DMA的声卡读写机制的数据交换示意图。
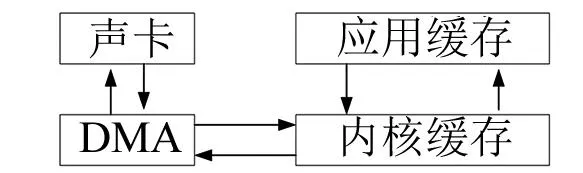
图1 声卡读写的数据交换示意
无论读写,在应用程序开始时设定音频规格参数、应用缓存分配,然后将所有缓存块填入声卡,之后利用声卡读写的回调函数,从最旧的缓存开始循环地更新缓存。由于回调函数不能驻留太久,一般如果在数据读写前后进行预处理或后处理(回声消除是读声卡后的数据处理,而调音等滤波是数据写到声卡前的处理),那么应该启动子线程来执行预/后处理及缓存读写更新。其中读写回调函数可以根据返回的结束消息而中断读写更新,可结束缓存读写的循环过程。图2给出了这一读写缓存更新的循环示意。

图2 读写回调循环示意
如图2所示,读写一旦一次性将多块缓存填入后进入“读写回调<—>读写缓存更新”的循环,这个回调函数是间接性的递归调用,即回调函数不会调用其本身,但它调用的读写更新函数又会调用该回调函数,因此可以称之为回调递归模式。
假设音频规格参数的帧率设置固定(即每个缓存块设置成相同的块长),无论读写,在“读写回调<—>读写缓存更新”的循环中都表现出操作系统的抖动性,即块更新的时间间隔不是完美的块长时间,而是在块时长上下随机浮动。例如设置帧时长100 ms,设计一个录音程序,在酷睿i7/win11系统录得19帧序列的帧时长分布如图3所示。
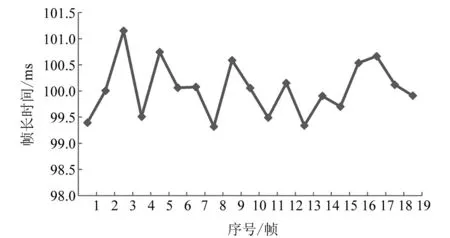
图3 帧序列帧时长抖动
又例如,设计一个录音、播放程序,运行多次持续时长不一的测试,记录得到每次测试的录音、播放的各自的总帧数以及平均帧时长,其中音频帧长规格定为20 ms, 如表1所示。由于录音播放是各自抢占性地调用的,尽管系统的调度优先等级是相同的,但由于资源博弈是动态的平衡,因此每次测试录得的效果均有随机的波动。总体来说,录音、播放的频次存在着一点失衡。帧差数越高显示录音、播放间的失衡越大。
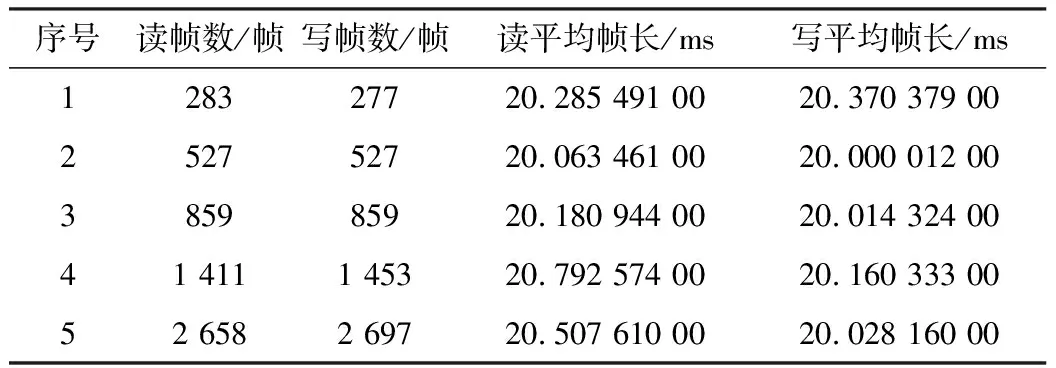
表1 录音、播放频率失衡性
2 双螺旋结构的录音放音调度
在录音放音的调度循环中,对于读或写而言,回调函数环节及缓存更新环节皆存在着不同的抖动,由于读写双方在同等优先级下系统调度保持动态的平衡,因此失衡就体现在读写各自过程不同环节误差的积累上。在录音播放程序中,可以采用各自的回调函数调用对方的缓存更新,又保持对录音、放音流程的驱动,那么不失为一种缓冲、中和抖动效应的方法,如图4所示。
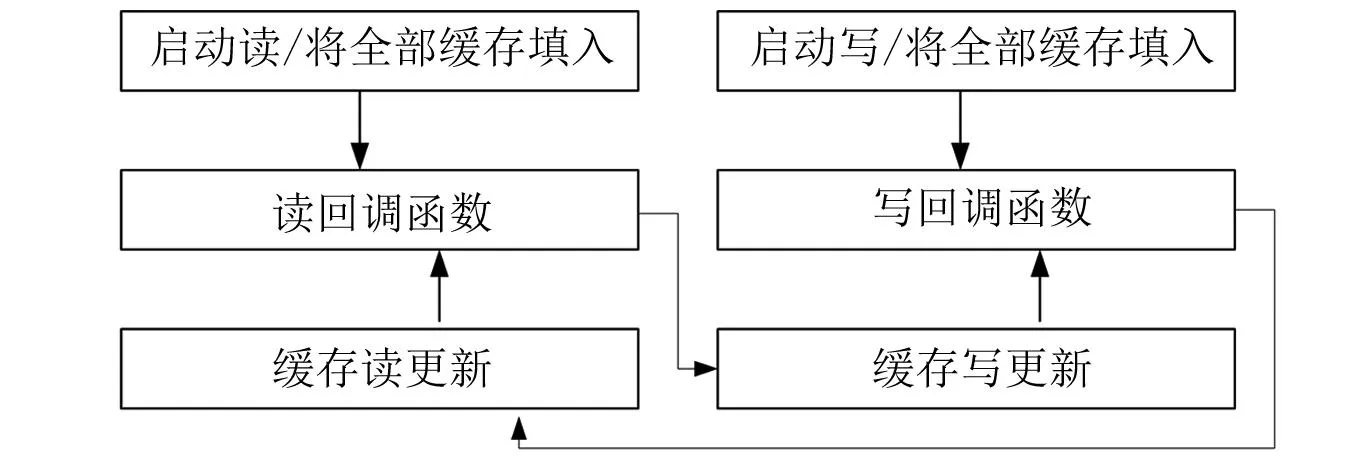
图4 录音放音回调调用对方的缓存更新
图4体现了回调递归的对称交叉、逻辑链变向,特别从录音、播放两个时间点开始的调用逻辑链展示了录音播放交织在一起进行演变:
→加入录音缓存→录音回调→向声卡写入缓存→播放回调→
→向声卡写入缓存→播放回调→加入录音缓存→录音回调→
如果把ATGC四种碱基对和上述流程环节对应,那么上述两条时间线演变的逻辑链恰似基因双螺旋结构,如图5所示。

图5 录音播放的双螺旋调度与基因双螺旋结构的对照
3 传统录音播放调度与双螺旋结构调度的测试对比
在酷睿i7/win11系统采集传统模式和双螺旋模式的6次测试结果如表2所示。
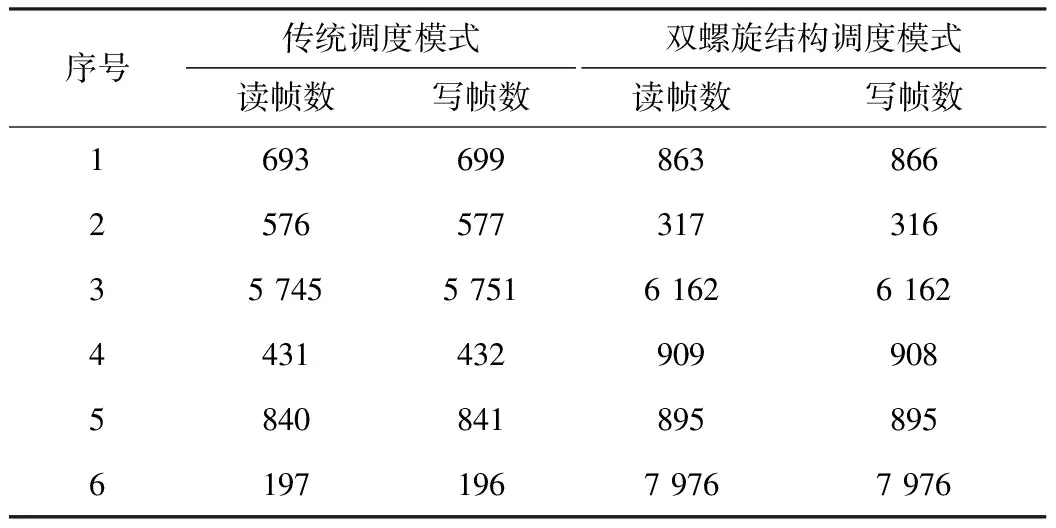
表2 帧数对比 单位:帧
关于总帧差数,传统模式总计16帧,双螺旋模式只有5帧,前者较后者高2倍。但由于这12次测试程序运行时长各不相同,因此把各自的总帧差除以各自总帧数得到相对帧差率,传统模式为0.000 94,而双螺旋模式为0.000 19,可见传统模式比双螺旋模式高了4倍。总帧差数、相对帧差率越高,显示录音播放之间的失衡越严重,从表2看出双螺旋模式具有同步性提升的作用。
从另一个侧面分析,传统模式对抖动中和的能力较弱,那么反映在帧时长分布的方差比双螺旋模式要剧烈些。仍以20 ms帧长规格为例,对传统/双螺旋模式各采集5次测试得到帧长分布的根方差见表3。

表3 传统/双螺旋模式的帧长根方差 单位:ms
从表3可以看到,传统模式和双螺旋模式各有一类调度是极稳定的(如表3在传统模式中写调度的帧数平均根差2.349,双螺旋模式的读调度帧数平均根差0.644),然后另外一类再和对应的那类保持动态平衡,例如传统模式是读对写保持动态平衡,读侧的帧数平均根差9.426,双螺旋模式是写对读保持动态平衡,写侧的帧数平均根差3.681。这种情况不固定,应仅仅是试验录得的情形。但总体而言,两种模式下,双螺旋模式的极稳定类(读调度)对比传统模式的极稳定类(写调度)要更优、更稳定,而双螺旋的写调度相对于传统模式的读调度也更优、更稳定。且考虑两种模式的综合平均根方差,即传统模式取读写两侧的根差平均为5.888,双螺旋模式读写两侧根差平均为2.163,传统模式比双螺旋模式高出一倍多,即传统模式的帧间隔变化更为剧烈,即保持动态平衡的程度也更剧烈,说明同步性也更逊色。
4 结束语
针对传统录音、播放调度的同步性存在可优化性,采用双螺旋结构的新型设计加以改进,经过实测,基于输入输出帧差、相对帧差以及帧时长分布的根方差定量地证明了双螺旋结构较传统模式“成数倍”提升了同步性。
