针对短时交通流预测的ISSA-SVR模型
2024-02-22叶得学韩如冰颜鲁合
叶得学,韩如冰,颜鲁合
(1.兰州工商学院 信息工程学院,甘肃 兰州 730101;2.甘肃中医药大学 经贸与管理学院,甘肃 兰州 730101)
0 引 言
目前,短时交通流预测方法有两种:统计分析法和数据驱动智能预测方法。前者如时序模型、多元线性回归和滤波模型[1-4],这类方法计算量较小,但短时交通流具有非线性复杂多变非平衡特性,所以预测准确率一般较低,无法满足目前复杂环境的预测需求。数据驱动智能预测方法主要结合历史数据和学习模型对交通流进行预测。模型以数据驱动,预测精度更高。如:黄艳国等[5]设计改进花授粉算法与BP神经网络的短时交通流预测模型,通过优化初始权重和阈值,构建交通流预测模型。邹宗民等[6]提出结合PSO-SVM的高速路短时交通流预测算法,但PSO有易获局部最优的不足。何祖杰等[7]提出通过改进灰狼算法优化SVM关键参数,并构建短期交通流预测模型。胡松等[8]先利用天牛须搜索和自适应权重对鲸鱼算法优化,再结合最小二乘SVM构建短时交通流预测模型。徐钦帅等[9]利用引力搜索算法对最小二乘SVM参数寻优,构建交通流预测模型。Ren等[10]设计基于深度学习模型的交通流预测算法。
短时交通流无法采集大量样本,具有明显小样本特征。SVR模型具有泛化能力强、训练效率高的特点,尤其适用于小样本环境中的预测问题,因而在网络舆情预测[11]、电力负载预测[12]、风速预测[13]等领域得到了广泛应用。SVR的预测精度主要由两个关键参数:惩罚因子c和核函数参数g决定。而针对SVR关键参数的优化思路有3种:尝试法、网格搜索法和启发式方法。其中,前两种方法适用性有限,计算代价过高。而启发式方法借助智能优化算法的启发式搜索机制,大大提高了搜索效率,降低了寻优代价。如前所述,灰狼算法、粒子群算法、天牛须算法、鲸鱼算法等都已应用于预测模型关键参数寻优,但算法综合搜索性能还有待提升。麻雀搜索算法SSA[14]是近年来出来的一种新型智能算法,无论寻优精度还是收敛速度都体现出一定优势,但在求解复杂问题上还是有收敛慢、易获局部最优的不足。为此,本文将设计混合多策略改进麻雀搜索算法HMSSSA,再利用HMSSSA寻找SVR的最优惩罚因子c和核函数参数g取值对,并构建短时交通流预测模型。
1 混合多策略改进麻雀搜索算法HMSSSA
麻雀搜索算法SSA中的种群由发现者、追随者和警戒者3种角色组成,都代表问题的候选解,但更新机制各异。发现者为种群提供捕食方向和区域,最接近食物源,追随者则紧跟发现者。发现者搜索能力强、捕食快,追随者向发现者学习提升能力。发现者、追随者通常各占种群的10%~20%,且可以进行角色互换,但比例不变。警戒者负责监视捕食区域,若发现危险时,会及时向其它个体发出警报,以便种群作出反捕食行为。3种角色会不断更新自身位置,以求不断逼近食物源完成捕食。
SSA算法由于具有更好的搜索性能已被应用在物联网频谱分配[15]、学习模型优化[16]、图像分割[17]、WSN节点定位[18]等领域。但标准SSA存在目标解搜索精度低、收敛慢和容易得到局部最优的缺陷,为此:毛清华等[19,20]分别设计了反向学习、正余弦优化和莱维飞行改进麻雀搜索算法加快算法收敛速度,高晨峰等[21]设计黄金正弦自适应麻雀搜索算法提高搜索精度,付华等[22]利用精英混沌反向学习对麻雀搜索算法进行改进,李爱莲等[23]融合正余弦和cauchy变异策略改进SSA。以上研究都一定程度改善了SSA算法的性能,但依然没有根本解决好算法全局搜索与局部开发均衡、避开局部最优、拓展搜索空间改进搜索精度等问题。本文将混合多种策略对SSA算法进行全面改进,实现综合性能的有效提升。
1.1 基于反向学习和中心游移的种群初始化
SSA算法的初始种群是随机生成的,这也是群体智能优化算法生成初始种群的常规方法,为的是确保个体分布的随机性。但这种方法生成的初始个体往往质量较差,容易导致个体聚集、个体差异性低和空间覆盖不够,进而降低算法的寻优速度。研究表明,反向学习策略可以提高初始生成个体的质量,该方法通过计算个体的反向点并结合贪婪选择策略提升初始种群的质量,并已成功应用在多种算法中。问题在于:反向学习策略在较小空间内的搜索效果要明显优于较大空间的搜索问题。为了得到更高质量的初始种群,同时又保留部分初始种群的随机分布特征,本文将结合反向学习和中心游移机制实现种群初始化,通过中心游移方式对反向学习后的个体位置进行随机偏移,以此分隔寻优空间,实现个体的多点同步搜索,提高种群多样性。
令个体xi,j(t) 为迭代t时个体i的j维位置,随机生成方式为
xi,j(t)=lbj+rand×(ubj-lbj)
(1)
则其反向解的对应位置为
xi,j′(t)=ubj+lbj-xi,j(t)
(2)
式中:[lbj,ubj] 为个体在j维空间上的搜索范围,rand为[0,1]间随机量,xi,j(t)、xi,j′(t) 则分别表示个体原位置和反向解位置。生成反向解后,再根据中心游移策略对原始解和反向解进行中心游移以保留随机性,具体公式为
xi,j″(t)=xi,j(t)+γ×xi,j′(t)
(3)
式中:xi,j″(t) 为个体中心游移解,γ为游移因子,控制个体游移步长。
种群初始化过程如下:根据式(1)随机生成个体的初始位置,并根据式(2)计算其反向解,再根据式(3)对生成的反向解进行中心游移,并择优保留在种群中。图1是种群随机初始化、反向学习初始化和中心游移初始化3种方法得到的二维空间内的种群分布图,种群规模为30,个体搜索区域限定为[0,1],游移因子γ设置为0.618。可见,随机初始化仍有很多覆盖盲区,种群分布多样性和遍历性不如后两种初始化方向。构建反向解后,个体质量有所改善,但个体间距相比中心游移生成的初始种群仍较大,这样向最优解方向偏移时会需要更多的迭代时间,寻优效率有所下降。
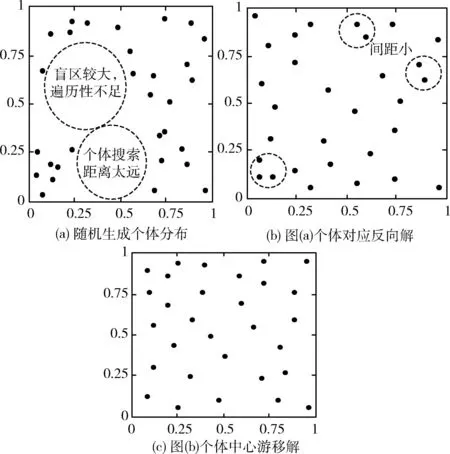
图1 不同策略下的种群个体分布
1.2 基于分段惯性权重和蝴蝶算法的发现者更新机制
SSA算法的发现者位置更新方式为
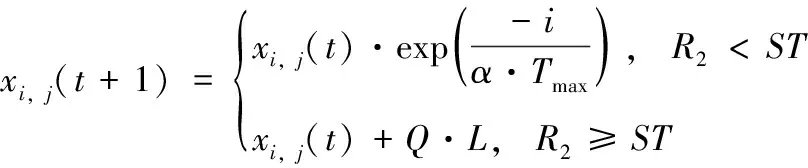
(4)
式中:xi,j(t)、xi,j(t+1) 分别为个体i在j维的原位置和更新位置,j=1,2,…,d,t为当前迭代次数,Tmax为最大迭代次数,α∈(0,1) 为随机量,R2、ST分别为预警值和安全值,且R2∈[0,1],ST∈[0.5,1],Q为服从正态分布的随机量,L为1×d的矩阵,元素均为1。
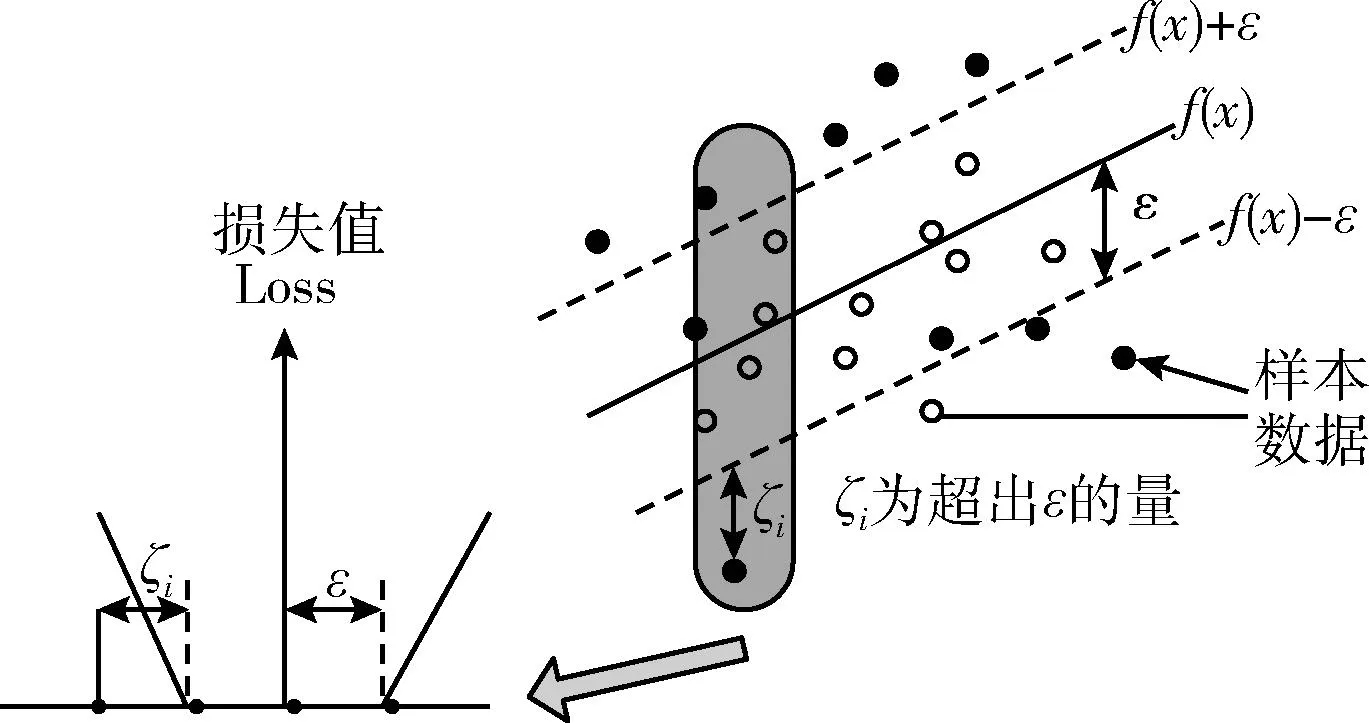
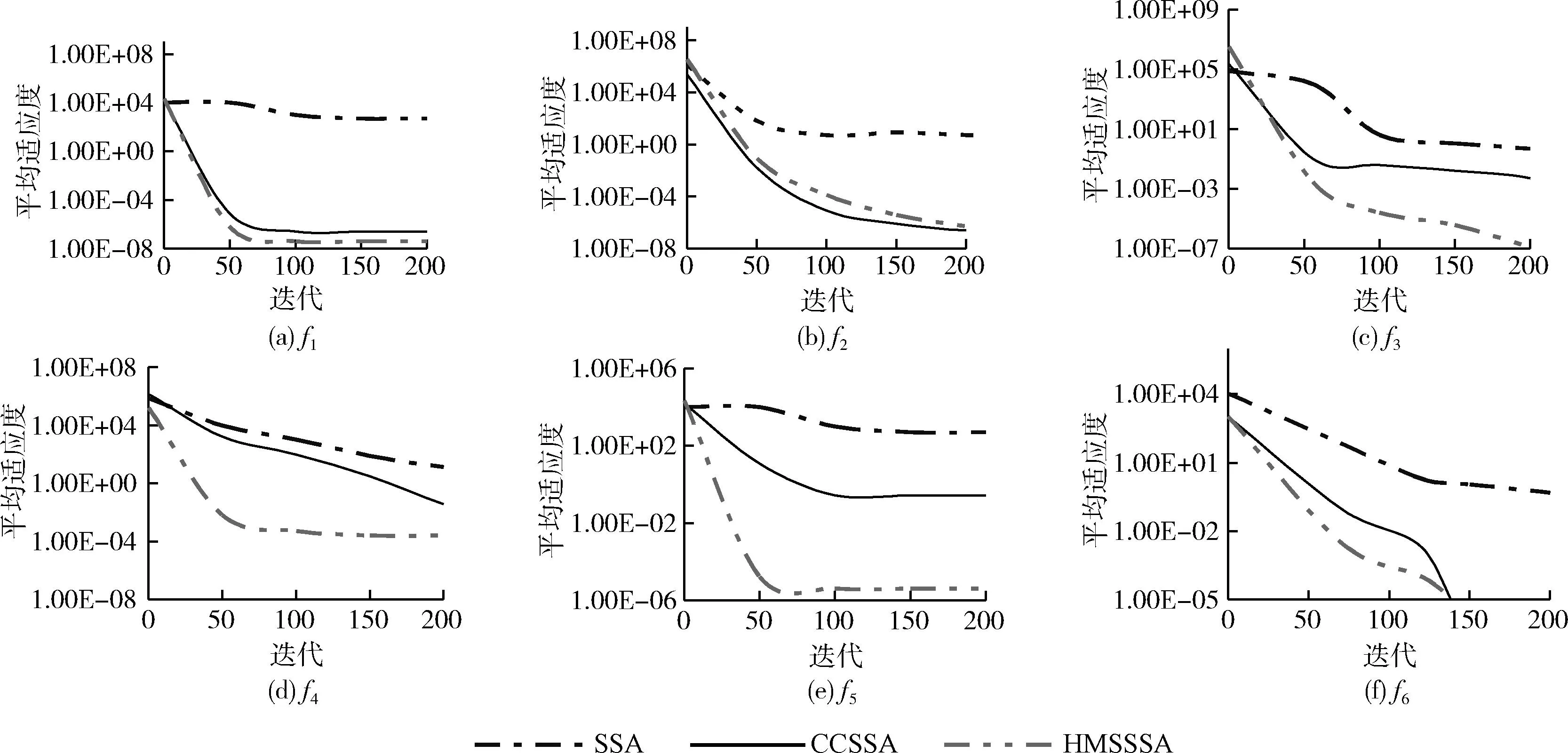
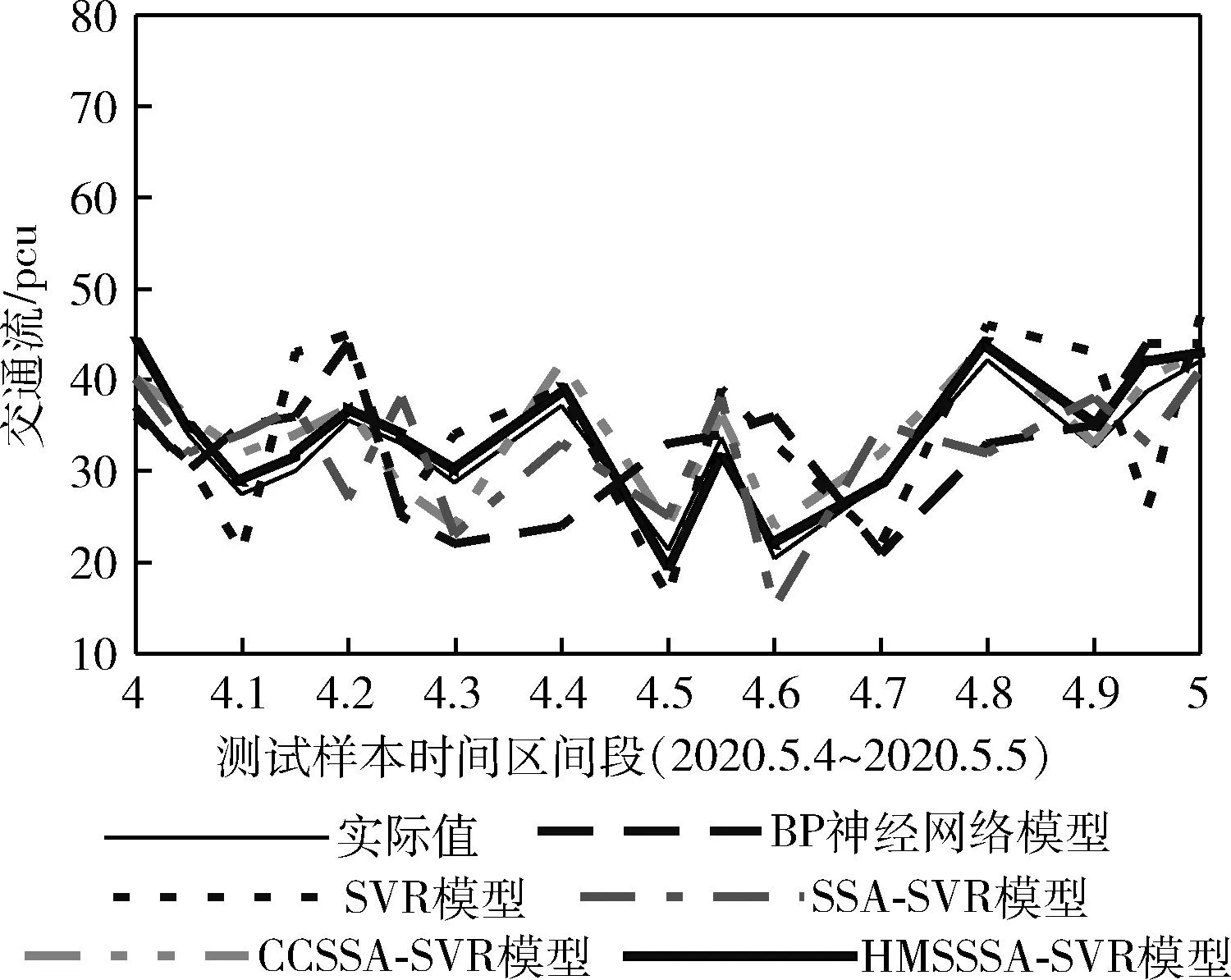
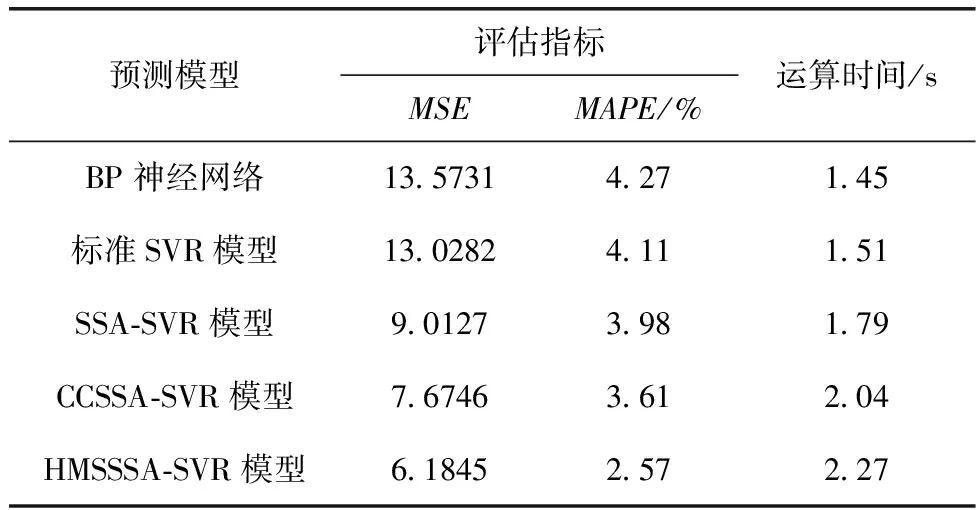
由SSA的发现者位置更新方式可知,若R2≥ST,发现者将以正态分布进行随机移动;若R2 蝴蝶优化算法BOA[24]是受蝴蝶的觅食、求偶行为启发而来的新型群智能算法。蝴蝶在飞行觅食过程中会产生一种香味,不同个体拥有不同的香味浓度。通过空气的扩散作用,其它个体可以感知到这种香味。蝴蝶的搜索轨迹主要取决于感知到的香味浓度。当感知到香味浓度最优的蝴蝶时,蝴蝶将进行全局搜索,朝着最优解的方向移动。当蝴蝶未感知到任何其它蝴蝶的香味时,个体将进行局部开发,以随机游走的方式作随机移动。蝴蝶的位置更新方式为 xi,j(t+1)= (5) 式中:xbest,j为全局最优解在j维度上的位置,fi为蝴蝶i的香味浓度,r1、r2∈[0,1], 表示随机量,xrand1、xrand2为选取的两个随机个体,P为搜索方式的切换概率,P∈[0,1]。 结合BOA算法的全局搜索方式,发现者位置更新改进为 xi,j(t+1)= (6) 根据式(6)可知,发现者进行位置更新时增强了与最优解之间的信息交互,能够更好地受最优解的引导,解决了原始方式中信息交互不足的问题。同时,蝴蝶优化算法的全局搜索方式能够拓展发现者的搜索区域,提高种群分布的多样性。 此外,对于SSA,搜索前半段,发现者应尽可能维持搜索的广泛性,保持更强的全局搜索能力。因此,此时的个体应以更稳定且较大的权重值维持全局寻优。而搜索后半段,应该加快算法收敛,个体应具有更强的局部开发能力,以求在有限范围内作精细开采。因此,此时的个体应以稳定且较小的权重值确保深度挖掘。基于此考虑,改进算法在式(6)的基础上引入分段权重思维对发现者位置更新,结合对数和指数非线性自适应方式调节惯性权重值。具体地,在迭代前半段,算法结合对数函数和指数函数设计权重因子w1(t) 为 w1(t)=e(t/Tmax)-10+lnt+logat (7) 式中:常量a=1/2。 在迭代后半段,以指数函数设计权重因子w2(t) 为 (8) 结合分段权重,HMSSSA的发现者位置更新方式为 xi,j(t+1)= (9) 由分段惯性权重定义可得,搜索前半段,w1(t)∈(0,1), 搜索后半段,w2(t)∈[-1,1)。 图2是800次迭代过程中发现者在不同更新策略下的分布情况,可见,利用BOA算法的全局搜索方式可以明显提升发现者的多样性。在相同的迭代次数下,原始发现者更新方式仍有小半区域未覆盖。而改进后的发现者位置更新方式在迭代前期并不会导致维度的快速减小,无论是正向或是反向变化的可能性都可所提同,这样也提高了发现者的全局搜索能力。 图2 原始发现者和更新后的发现者 SSA算法的追随者通过监视最优发现者调整自身位置,其位置更新方式为 xi,j(t+1)= (10) 由SSA算法追随者位置更新方式可知,追随者受全局最优解牵引并以一定概率向其靠近。该方式能以精英个体为导向加速算法收敛,但容易带来种群多样性缺失,陷入局部最优。为了确保追随者向发现者有效靠近,保证全局收敛同时,改进算法将以一定概率实现个体变异。 柯西分布是一种常规连续分布,其密度函数为 (11) 柯西分布为表示为C(α,β)。 若α=1,β=0,则可得标准柯西分布密度函数为 (12) 柯西分布比较高斯分布,两翼更加扁平,在原点附近拥有较低极值,且向两翼的递减速率要慢于高斯分布。因此,从概率上看,柯西分布具有更广泛的分布,实现更强烈的个体变异。利用柯西变异生成的子代个体距离父代更远,更易于跳离局部极值。基于这种结论的考虑,HMSSSA引入柯西变异对引导追随者位置更新的最优解位置进行变异,利用柯西算子的调节功能,使算法跳离局部最优。具体公式为 xnew=xbest+cauchy(0,1)·xbest (13) 式中:cauchy(0,1) 为服从柯西分布的柯西算子。 改进算法还需维持一定全局渐近和快速收敛状态,即维持向当前最优解逼近的状态,此时可以不进行个体变异,而维持原来的追随者位置更新方式。故针对最优解的变异将以一种自适应概率进行,将变异概率定义为 (14) SSA算法的警戒者位置更新方式为 (15) 式中:xbest,j(t) 为全局最优位置,β为步长因子,为正态分布随机量,K为随机量,K∈[-1,1],fi为个体i的适应度,fg、fworst分别为当前全局最优适应度和最差适应度,ξ为极小常量。若fi>fg,表明麻雀处于边界,未受到警戒保护;若fi=fg,表明处于中间位置的麻雀已意识到危险,需相互靠拢。xbest,j(t) 为种群的中心位置。 根据式(15)可知,参数β、K决定警戒者移动步长,控制全局搜索和局部开采进度。但SSA算法中两个因子都是正态分布随机值,无法满足个体对空间搜索的灵活要求。因此,为了提高算法的搜索效率,HMSSSA针对两个参数依迭代次数进行自适应更新,具体为 (16) (17) 式中:βmax、βmin、Kmax、Kmin分别为步长因子的最大值和最小值。其中,因子β(t) 以指数函数形式更新,K(t) 以正切函数形式更新,使个体的移动步长能在迭代前期较快递增,扩大搜索范围,充分全局搜索;而在迭代后期放缓增速,集中于局部开发,加快算法收敛。 当个体位置越界时,SSA的处理方式是利用搜索边界替代越界位置,该方式虽然比较简单,在小规模种群中比较有效。但是,对于大规模种群,会降低个体间的差异性,降低算法的寻优效率。为此,本文将根据边界邻域的思想对越界个体进行修正,将越界个体修正至邻域内的随机点位置,以此维持多样性。若xi,j(t) 为发生越界的位置,即存在xi,j(t)>ubj或xi,j(t) (18) 式中:U(a,b) 表示在区间(a,b)服从均匀分布的随机值。 HMSSSA算法流程如图3所示。 图3 HMSSSA算法 步骤1 初始化HMSSSA的相关参数,包括:种群规模N、搜索空间维度d、最大迭代次数Tmax、发现者数量、追随者数量、警戒者数量、游移因子γ、警戒值R2、步长因子β和K的最值βmax、βmin、Kmax、Kmin; 步骤2 根据式(2)、式(3)的反向学习和中心游移策略生成初始麻雀种群; 步骤3 计算种群适应度,确定种群最优解Xbest和最差解Xworst; 步骤4 按比例选择发现者:根据式(7)、式(8)计算分段权重,再根据式(9)更新发现者麻雀的位置; 步骤5 按比例选择追随者:根据柯西变异式(13)按变异概率式(14)对个体进行变异,再根据式(10)更新追随者麻雀的位置; 步骤6 按比例选择警戒者:根据式(16)、式(17)更新步长因子β和K,再根据式(15)更新警戒者麻雀的位置; 步骤7 根据式(18)对个体位置进行越界处理; 步骤8 判断算法的迭代次数是否达到最大,若没有,返回步骤3执行;否则,输出当前种群中的全局最优个体;算法运行终止。 SVR的目标是寻找一个最优超平面,使所有样本点与最优超平面间的偏差和达到最小。令样本数据集为 {(xi,yi),i=1,2,…,n},xi为模型的输入,yi为模型的输出,xi、yi∈Rn。 以非线性映射Ψ(x) 将样本数据投射至高维线性空间,即:f(x)=wΨ(x)+b, 其中,f(x) 为回归函数的预测值,w、b为目标参数。 为了均衡SVR的预测精度和预测效率,需要利用偏差容忍度ε使SVR具备一定容错能力,如图4所示。为了求解目标参数w、b,将问题转换为最优化问题求解 (19) 图4 SVR原理 (20) 式中:c为惩罚因子,且c>0,Lε[f(xi)-yi] 为算法的损失函数。c作为关键参数,可以通过调整对边界外数据误差的惩罚程度控制预测模型的精度。 引入拉格朗日函数得到对偶模型求解,可得最终模型解为 (21) 以SVR模型进行短时交通流预测,其关键参数,即惩罚因子c和核函数参数g直接决定了预测结果。其中,惩罚因子c决定了支持向量回归超平台与支持向量间的距离,即c越小,模型训练误差容忍越小,但会增加模型过拟合与泛化能力降低的风险,反之亦然;核函数参数g实现低维数据至高维映射,g越小,映射维度降低,但模型训练误差加大,且会增加数据欠拟合。标准SVR的两个关键参数若以经验取值肯定无法确定最佳的训练模型,通过HMSSSA针对连续优化问题的寻优能力在训练集中搜索性能最优的参数组合(c,g),并实现针对短时交通流预测的HMSSSA-SVR模型。 HMSSSA-SVR的目标是对短时交通流进行预测,主要在小样本量前提下利用HMSSSA优化支持向量回归模型,构建交通流预测模型。算法主要实施步骤如下: 步骤1 样本采集。由于是针对短时交通流预测,样本采集频率不能太高,设置为10 min,并将数据以标准车当量数pcu表示; 步骤2 原始样本数据预处理。包括异常值识别、样本缺失填充,利用小波阈值降噪法处理异常数据,缺失样本则以前后窗口大小为4的均值方式填充,最后利用标准化函数对数据进行归一化处理; 步骤3 将原始样本数据划分为训练集和测试集,分别用于HMSSSA-SVR的训练与测试; 步骤4 对HMSSSA的参数进行初始化,包括种群规模、最大迭代次数;并确定SVR网络结构及关键参数搜索范围; 步骤5 确定拟优化参数惩罚因子c和核函数参数g,根据拟优参数对种群个体编码,并根据反向学习和中心游移策略进行种群初始化; 步骤6 确定评估麻雀个体的适应度函数,以均方误差函数作为适应度函数; 步骤7 计算种群个体适应度,确定当前的最优解和最差解; 步骤8 根据图3所示HMSSSA算法对SVR的优化参数进行迭代寻优,若未到达最大迭代次数,则转入步骤7执行;否则,进入下一步骤; 步骤9 得到最优参数组合,作为初始值代入SVR,进行模型训练,检查预测误差是否符合精度要求;若符合,则输出短时交通流预测结果。 图5是HMSSSA-SVR预测短时交通流的执行流程。 图5 HMSSSA-SVR模型预测短时交通流执行流程 实验分两部分进行:第一部分引入6个基准函数对HMSSSA算法的寻优性能进行验证;第二部分引入特定交通流数据集对HMSSSA-SVR模型的预测性能进行验证。算法参数中,种群规模N=30,最大迭代次数Tmax=200,游移因子γ=0.618,步长因子β和K的最值βmax=0.9,βmin=0.1,Kmax=0.8,Kmin=0.1。引进如表1所示的6个基准函数进行算法的寻优测试。 表1 测试函数 基准函数表达式如下所示。其中,f1(x)~f4(x) 为单峰值函数,f5(x)~f6(x) 为多峰值函数,前者利于测试算法的搜索精度和全局搜索能力,因为众多局部极值点,后者可以测试高维空间内算法的全局搜索能力以及跳离局部极值点的能力。 (1)Sphere函数 (2)Schwefel2.22函数 (3)Schwefel1.2函数 (4)Schwefel2.21函数 f4(x)=maxi{|xi|,1≤xi≤d} (5)Griewank函数 (6)Rastigin函数 交通流预测实验的样本选取美国加州PeMS系统采集的交通流数据集。该系统通过部署于各交通要道路口的大量传感器收集车辆交通流,是目前应用在交通流预测领域最广泛的数据集之一。选择2020年5月1日~2020年5月5日间所采集的某一主干道路口共5天的车流量数据作为实验样本,样本采集时间间隔为10 min,采集样本总量为1440个。图6是测试所用样本数据,图中将采集数据根据城市道路工程设计规范中的pcu,即标准车当量数进行表示,采样频率为10 min。将前4天采集的样本作为模型训练集,第5天的样本作为模型的测试集,则训练集包含1152个样本,测试集包含288个样本。对原始交通流数据集进行小波降噪过程中,小波函数采用db3,设置分解层数为1,并利用ddencmp和wdencmp工具实际原始交通流数据降噪处理。 图6 所选5天交通流样本数据 为了加快预测模型的收敛速度和消除量纲影响,对小波降噪后的样本数据进行标准化处理,使数据归一化至区间[0,1]之间,所采用的标准化函数(采用Matlab平台提供的mapminmax函数)形式为 (22) 其中,x为样本处理后的标准数值,x为原始样本数值,xmax、xmin为原始样本值的最大值和最小值。待预测模型完成预测后还需要对预测结果进行反归一化处理。 引入标准SSA算法和混沌反向学习改进SSA算法CCSSA[22]进行对比分析,两种对比算法的种群规模和迭代次数选取与前文实验配置一致,每个基准函数在实验中独立测试20次,为了测试算法的稳定性和准确性,选择函数的均值结果,最优值和标准差两个统计量进行综合评价。表2在低维度20和高维度50下测试3种算法的寻优结果。可以看出,HMSSSA能够在多数基准函数中求解到最优解,说明该算法在标准SSA算法的基础上是可以提高搜索精度的,且在单峰函数和多峰函数上具有很好的稳定性。从目标函数的标准差来看,HMSSSA算法在多数标准测试函数中也得到了更好的表现,说明算法中所采用的反向学习和中心游移机制、分段惯性权重和蝴蝶优化算法、柯西变异及自适应警戒者更新对改进SSA的寻优能力是有效可行的。同样作为针对SSA的改进算法,CCSSA算法的全面性能方面不如HMSSSA,而SSA还是容易得到局部最优解。图7是维度20时基准函数的收敛曲线。可见,HMSSSA算法收敛时的搜索精度要高于对比算法,并且算法能够更快的搜索到离最优解更近的候选解,进一步说明改进策略能够更好地指导个体的寻优方向,在拓展广阔的搜索空间和避免局部最优的同时,能够均衡全局搜索和局部开发间的关系,提升寻优收敛速度。 表2 测试结果 图7 收敛曲线 以均方误差MSE和平均绝对百分比误差MAPE评估算法预测短时交通流的误差情况。两个指标的定义如下 (23) (24) 其中,n为预测总时长,yi、y′i分别为短时交通流实际值和预测值。两个指标值均是取值越小,模型预测误差越小,预测精度越高。对比模型方面,引入标准SVR模型进行横向对比,引入BP神经网络作纵向对比,再引入标准SSA算法优化SVR的SSA-SVR及混沌反向学习改进SSA算法优化SVR的CCSSA-SVR[22]进行智能算法优化性能方面的对比。 图8是5种模型在测试样本上的预测结果及实际交通流。可以看出,未经优化调参的BP神经网络和SVR在整个一天的短时交通流预测上与实际交通流误差还是比较大,个别时段可以接近实际值,但难以实现全时段短时交通流预测,模型稳定性有待提升。3种优化调参模型则能够较好预测短时交通流的变化趋势。从数据值的拟合程度看,HMSSSA-SVR与实际值具有更高的拟合度,再进一步结合表1的定量指标分析模型的预测性能。 图8 预测结果 表3是5种模型预测值与实际值间的均方误差和平均绝对百分比误差表现。MSE方面,两个标准模型均方误差均大于10%,经群体智能优化算法对学习模型优化后,预测模型的均方误差均降低至10%以内,表明对关键参数寻优很有必要。但优化效果不一,HMSSSA-SVR相比SSA-SVR和CCSSA-SVR在均方误差上分别又降低了45.72%和24.09%,HMSSSA算法的综合改进更加有效。MAPE趋势与MSE一致,说明HMSSSA-SVR相比对比模型能更好地实现精确短时交通流预测。此外,表3最后一列还给出各模型的运算时间,可以看出,本文的HMSSSA-SVR模型的运算时间略高于4种对比模型。标准BP神经网络和标准SVR模型均没有进行超参寻优,其运行效率要高于超参调估后的预测模型。经过SSA算法、CCSSA算法和HMSSSA算法优化SVR模型,需要通过若干次迭代搜索SVR的最优参数,再构建最优预测模型,所以一定程度上增加模型的运算时间。但相比于大幅度预测误差,所提高的运算时间也是可以接受的。 表3 预测模型误差表现 为观察5种预测模型在测试数据集上预测的误差离散分布情况,将所统计的两个评估指标MSE和MAPE绘制为箱形图进行结果的对比。图9可见,HMSSSA-SVR模型在MSE和MAPE指标上的中位数、四分位以及上界值方面均低于对比的4种模型,其预测误差的分布更为集中,表明该预测模型在数据集上预测性能更加稳定。 图9 指标的箱形图对比 图10展示了5种预测模型求解适应度的收敛曲线,模型一共迭代200次。由于适应度函数为均方误差函数,所取值越小,预测误差也越小。适应度不变说明模型已经收敛。结合曲线趋势看,BP神经网络最快收敛,但由于得到的是局部最优解,适应度较差,预测误差较大。SVR模型的预测误差弱小于BP神经网络,适应度值更小。3种智能算法应用于调参后的SVR模型明显可以降低预测误差,得到更低的适应度值,但收敛速度不一样。SSA-SVR模型在运行100左右迭代时收敛,晚于CCSSA-SVR模型和HMSSSA-SVR模型的81次迭代。从预测误差和预测精度上看,本文的HMSSSA-SVR模型无疑是最佳的,验证混合多策略改进策略极大地提升了对SVR关键参数取值的寻优,使预测模型达到最佳的预测性能,并最终收敛于最优适应度处。另外,HMSSSA-SVR模型能够更快的降低预测误差,提升预测精度还在于算法提供了更有效的局部极值跳离机制,使得预测模型在预测短时交通流领域具有更好的适用性。 图10 模型收敛性能 为提高短时交通流的预测精度,提出基于改进麻雀搜索算法优化支持向量回归的短时交通流预测模型。先结合反向学习和中心游移、分段惯性权重和蝴蝶优化算法、柯西变异及自适应警戒者更新对SSA的种群初始化多样性、全局搜索和寻优能力、收敛速度及寻优精度进行改进,然后利用混合多策略改进麻雀搜索算法优化支持向量回归的超参,构建短时交通流预测模型。结果表明,改进方法泛化能力更好,预测误差更低,能够对短时交通流实现精确预测。

1.3 基于柯西变异的追随者位置更新

1.4 基于自适应的警戒者位置更新

1.5 越界处理机制
1.6 HMSSSA算法设计

2 HMSSSA-SVR模型设计
2.1 支持向量回归算法SVR
2.2 HMSSSA-SVR预测短时交通流

3 实验分析
3.1 实验环境说明


3.2 基准函数寻优结果分析

3.3 交通流预测结果分析


4 结束语
