基于视觉注意力的图文跨模态情感分析
2024-02-22王法玉郝攀征
王法玉,郝攀征
(天津理工大学 智能计算及软件新技术天津市重点实验室,天津 300384)
0 引 言
传统的情感分析只关注文本内容和学习不同结构的表示,例如单词、短语、句子和文档。然而近年来,用户生成内容的组成更加复杂和多样化,纯文本描述逐渐被图像和文本的混合表示所替代[1]。同时许多电子商务或者在线购物网站允许用户发布图片作为评论的一部分。而大多数情况下,图像不单独作为情感特征描述情感,视觉图像往往包含与评论中的文本信息高度相关的补充信息。同时,评论中附加的图片可以反映该评论的主题。
根据上述情况,我们使用视觉注意力来提高评论情感分析的准确率,利用多个图像作为查询,来定位和衡量评论文本中单词的重要性。如图1所示,它是Yelp网站上旧金山地区的一家餐厅的评论,包含两张图片和几个描述食物的句子,根据视觉注意力机制,我们对评论文本中的“cheese pizza”和“pesto linguine”赋予更高的权重,从而提高情感分析的性能。

图1 Yelp网站餐厅评论
然而,有些评论中视觉注意力无法完全覆盖文本内容,如图2所示,图片的内容包含一些食物,同时会对评论文本中前5个方框里面的内容赋予更高的权重,但是在最后一个方框里面的内容在说服务的问题,这个内容并没有在图片中表现出来。

图2 评论图像无法完全覆盖文本
本文基于上述问题,提出了一种在线评论情感分析的方法,我们的贡献主要如下:
(1)本文提出一种基于视觉注意力的跨模态情感分析模型(BERT-VistaNet),它可以处理评论中的图像和文本从而得到情感分类,用BERT模型提取评论文档的文本信息,弥补VistaNet模型中图像无法完全覆盖文本的问题。
(2)我们对Yelp餐厅评论的公开数据集进行实验,并将我们的模型和各个基线模型进行比较。实验结果表明,我们的方法可以提高情感分析的准确性。
1 相关工作
1.1 图文单模态情感分析
随着深度神经网络的发展,基于深度学习的算法如长短期记忆(LSTM)、双向长短期记忆(BiLSTM)、门控循环单元(GRU)、双向门控循环单元(BiGRU)、卷积神经网络(CNN)[2]、胶囊网络[3]和基于Transformer结构的模型(BERT)[4]被广泛应用于文本的情感分析。由于注意力机制的提出,使得可以更好减少图像中的噪声,图像的情感分析也受到了更多的关注,Li等[5]提出一种注意力机制模型,它应用VGG-19模型和显着图来表示图像中的视觉注意力。He等[6]提出一种多注意力金字塔模型用于视觉情感分析,它是从全局图像不同尺度的多个局部区域中提取局部视觉特征,然后植入自注意力机制来挖掘局部视觉特征之间的关联,从而得到情感表示。
1.2 图文跨模态情感分析
相较于前文的单模态情感分析,跨模态情感分析目前仍处于起步阶段。以往的研究主要使用传统的基于特征的分类方法来实现情感分类,例如Dai等[7]从形容词-名词对的联合分布中生成情感词袋,并引入一组情感部分特征来整合多个统计流形上的视觉和文本描述符。现在多使用的是基于深度学习的跨模态情感分析,Chen等[8]利用CNN提取图像和文本的特征,并将它们拼接在一起组成一个图像文本的联合表示进行进一步的训练。Xu等[9]提出了一种用于多模态情感分析多深度语义网络,并利用图像特征多LSTM模型结合注意力机制提取关键词。Truong等[10]提出了一种视觉注意力的多模态情感分类模型(VistaNet),它将视觉内容作为注意力与文本内容进行对齐,使用注意力来指出文本中重要的信息。
以往的跨模态情感分析大都是将图片的特征和文本的特征进行融合,然而视觉特征的稀疏性会降低文本特征对最终情感结果的作用。本文在VistaNet的基础上提出了一种跨模态情感分析模型(BERT-VistaNet),本模型采用视觉信息作为注意力来突出图像情感的关键信息,加入BERT模型对文档中的文本信息进行特征提取,保证文档中的文本信息不会因为视觉信息的稀疏性而减弱,同时对视觉信息无法覆盖到的文本信息进行补充。
2 BERT-VistaNet跨模态情感分析模型
给定一个文档集合C, 对于其中的每一个文档c(c∈C) 都包含两个部分:文本部分和视觉部分。文本部分是由L个句子组成的序列,每个句子有t个单词,其中每个单词记为wi(i∈[1,T])。 视觉部分为M张图片组成的集合,其中每张图片记为aj(j∈[1,M])。
为了能有效获取视觉-文本的情感表征和两种模态之间的交互信息,本文采用基于视觉注意力的方法构建跨模态情感分析模型,提出的BERT-VistaNet模型的架构如图3所示。首先是采用VistaNet模型提取基于视觉注意力的文档特征,然后采用BERT模型提取基于文本的文档特征,将这两个特征融合作为最终的文档情感表征,最后输入情感分类层得到情感标签。
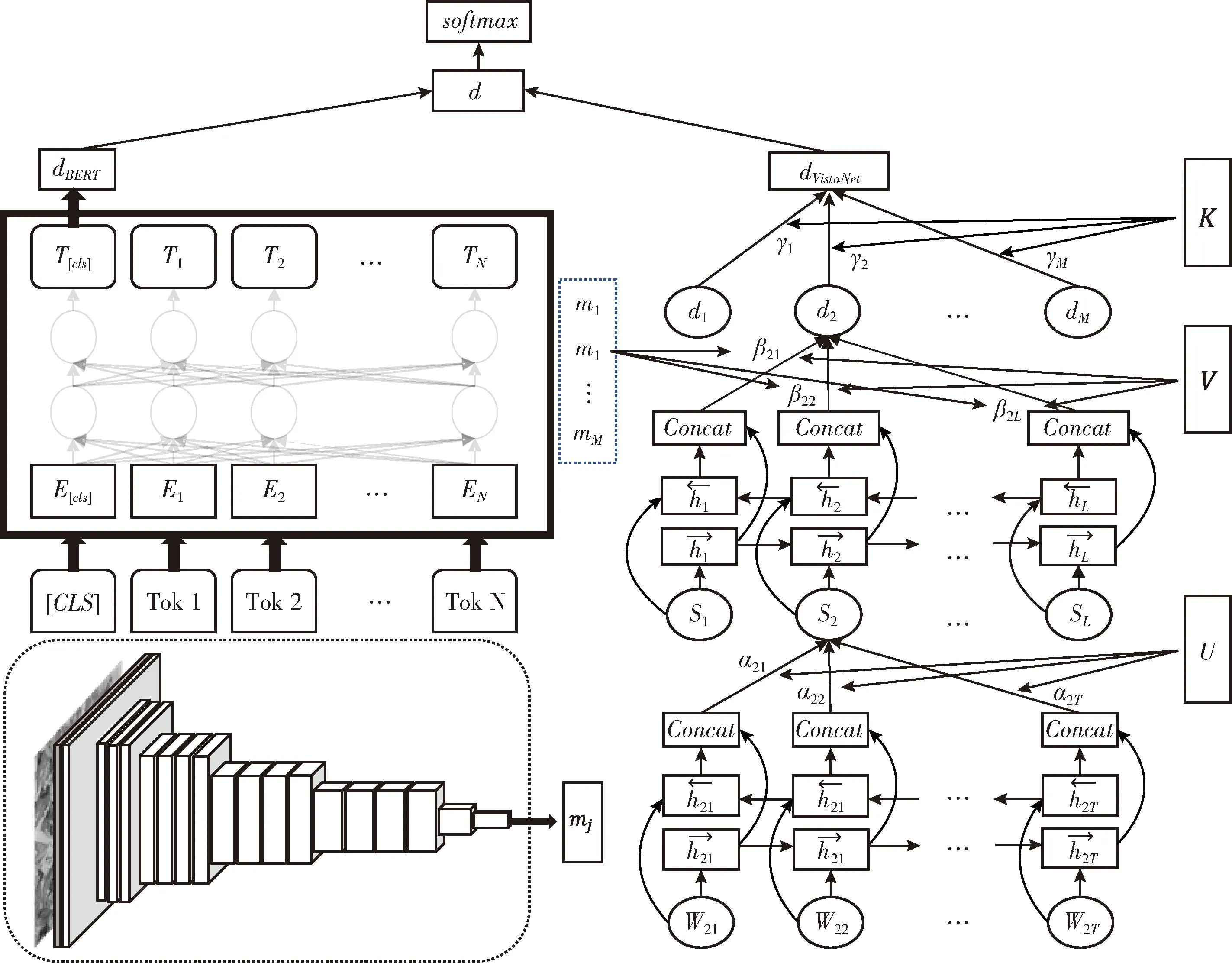
图3 BERT-VistaNet模型
2.1 基于视觉注意力的文档特征
在图3中,右侧部分是提取基于视觉注意力的文档特征,这部分由最底层的单词编码层、中间层的句子编码层和最上层的文档情感层组成。单词编码层使用双向GRU单元,将单词转换为句子形式的表示;句子编码层使用视觉注意力机制,将句子形式表示转换为文档形式表示;文档情感层使用soft attention加权求和得到最终的基于视觉注意力的文档表示。
2.1.1 单词编码层
该层是将单词表示转化为句子表示,对每个评论文档中的句子Si进行嵌入,由每个单词的词向量w和它们的嵌入矩阵得到它们的嵌入表示
xit=Wewit
(1)
其中,wit代表文档中的单词,We是由预训练的嵌入(glove.6B.200d.txt)初始化的嵌入矩阵,xit表示单词的嵌入表示。
在双向RNN中,每个时间步的输出同时由当前步的之前和之后的输出确定,它可以考虑到整个句子的信息。为了对整个词嵌入的序列进行编码,使用带有GRU单元的双向RNN来获得结合上下文的词向量编码
(2)
(3)
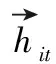
句子中单词的权重都是不同的,不同的单词和权重对于情感分析的重要程度是不同的,所以得到hit之后,使用软注意力机制为每个单词对于句子语义的贡献进行加权得到的句子表示Si
uit=UTtanh(Wwhit+bw)
(4)
(5)
Si=∑tαithit
(6)
其中,uit是贡献分数,表示每个单词wit的相对重要程度。Ww表示词嵌入xit的向量编码hit所对应的权重矩阵,UT表示上下文矩阵,由训练中初始化得到。αit为注意力权重,句子表示Si由当前句子中的单词表示hit和它们的注意力权重αit加权求和得到。
2.1.2 句子编码层
该层是将句子表示转化为基于特定图像的文档级别的表示,首先再次使用单层双向RNN处理单词编码层得到的句子表示Si, 得到包含了上下文信息的句子文档级表示hi
hi=Bi-RNN(Si)
(7)
对文档中的图像进行编码,VGG模型在图像相关任务上表现优异,使用预训练的VGG16模型得到每张图片aj的表示mj, 将VGG16模型的FC7层的输出作为图像的表示
mj=VGG16(aj)
(8)
因为经过VGG16得到的图片表示mj和包含上下文信息的句子文档级表示hi的维度不同,我们需要经过非线性激活函数tanh,将mj和hi投影到同一个注意力空间中,得到图像投影pj和句子投影qi
pj=tanh(Wpmj+bp)
(9)
qi=tanh(Wqhi+bq)
(10)
为了学习句子基于特定图像的注意力值vji, 我们采用元素乘法和元素求和的方式,让pj和qi进行交互,再通过加权求和,将句子表示聚合为基于特定图像的文档表示
vji=VT(pj⊙qi+qi)
(11)
(12)
dj=∑iβjihi
(13)
其中,⊙表示Hadamard product(两个向量pj和qi之间的元素乘积),它可以保证在计算注意力权重βji时,softmax函数不会清除视觉部分的信息,而元素的加法则是为了降低视觉部分的稀疏性对文本部分效果的影响。βji表示注意力权重,通过注意力权重使用加权平均得到基于特定图像的文档表示dj。
2.1.3 文档编码层
一个文档中有M张图片,对于每一张图片mj都会产生一个基于特定图像的文档表示dj, 我们将这些表示聚合形成最终的文档表示,但是不同图片对于文本的重要性不同,因此我们需要学习重要性权重γ
kj=KTtanh(Wddj+bd)
(14)
(15)
dVistaNet=∑jγjdj
(16)
其中,kj表示每个图片的相对重要性,KT表示权重矩阵。γj表示注意力权重,dVistaNet表示最终的基于视觉注意力的文档表示。
2.2 基于文本信息的文档特征
为了解决VistaNet模型图片无法完全覆盖文本的问题,在图3中,左侧部分是使用预训练的BERT模型提取评论文档中文本的全局特征。BERT模型的具体结构如图4所示,它的语义提取层是以Transformer编码器为基本单元的多层双向解码器,输出隐含层是文档文本的数学表达式,其中隐藏层的任何隐含单元都包含了经过Transformer编码器中的注意力机制后的文档文本中的所有情感信息。
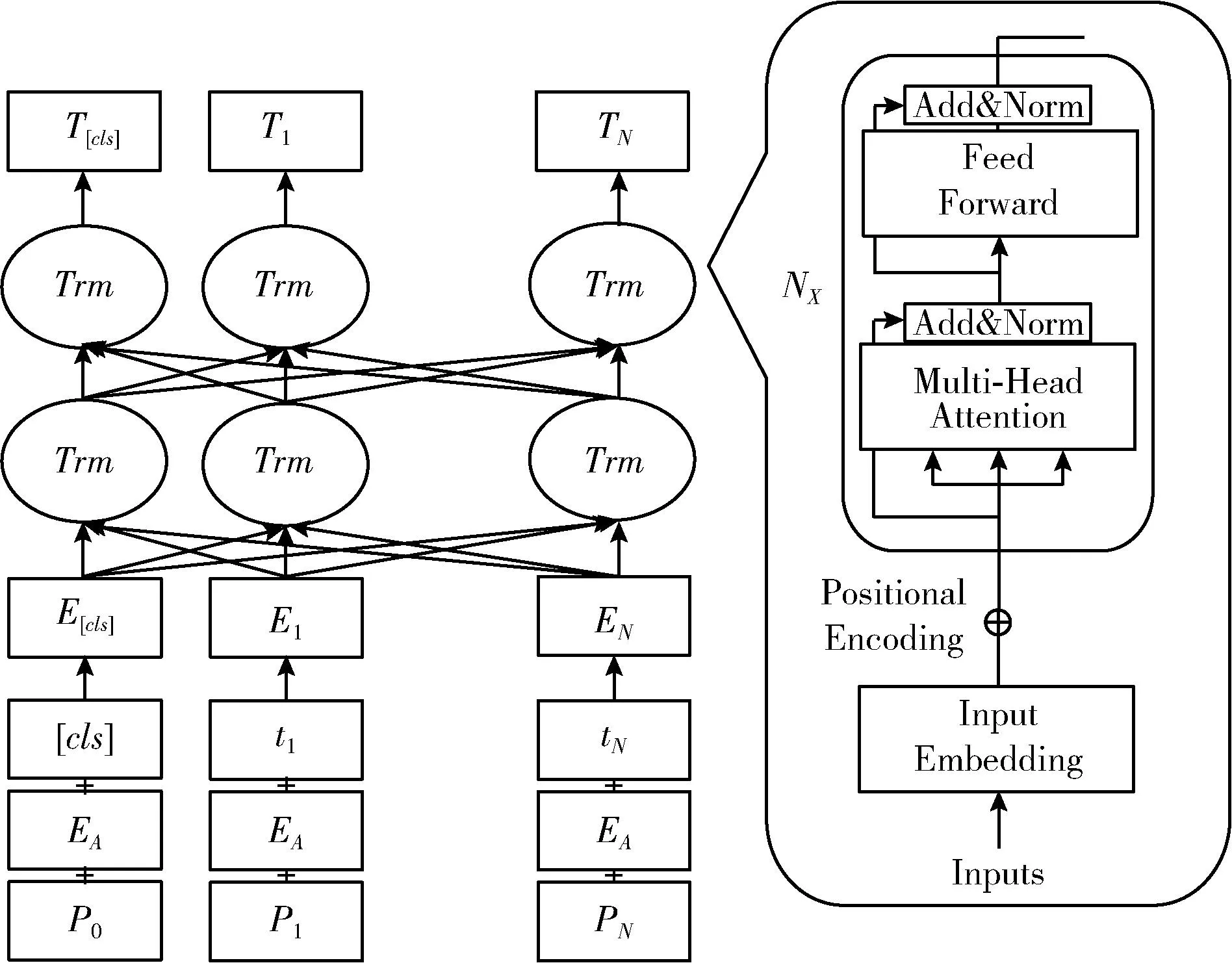
图4 BERT模型结构
BERT模型的输入是由词向量t、 句子编码E和位置编码P,3个向量拼接而成的向量矩阵E={e1,…en}。 其中词向量是预训练模型提供的词表初始化的单词编码;句子编码是区分输入的是一个句子还是两个句子,如果输入只有一个句子,那么它的句子编码就都全是0;位置编码是记录词在评论文本中的位置,通过式(17)和式(18)得到位置编码
(17)
(18)
其中,pos表示单词在句子中的位置,2i和2i+1表示词向量的偶数和奇数维度,d表示词向量的维度,同时它也是输出向量P的维度。
自注意力机制保证了评论文本中的每个词向量都包含了该文档中所有词向量的信息,计算公式如式(19)所示
(19)
其中,Q、K、V为3个向量矩阵,Q表示序列中一个单词的向量表示、K表示序列中所有单词的向量表示、V表示Value值。将注意力机制转为标准正态分布,softmax(*)是归一化,它使得评论文本中每个单词和其它的单词的注意力权重相加。多头自注意力层就是将Q、K、V先经过参数矩阵进行映射,再做自注意力机制,最后将结果拼接起来一起送到全连接层。
层标准差用来对selfAttention输出的单词表示进行标准化处理,方便后续ReLU激活函数进行非线性处理,同时层标准差通过归一化神经网络中的隐藏层能加速模型对标准正态分布的训练,从而加速模型收敛,如式(20)所示。残差连接利用了残差网络的特性,当层数加深时仍然能够很好训练,解决了梯度消失和网络退化的问题,如式(21)所示
(20)
X=Xembedding+Attention(Q,K,V)
(21)
在多头注意力机制的内部,主要是在运行矩阵乘法,也就是进行的都是线性变换,然而线性变换的学习能力不如非线性变换,因此需要加入前馈神经网络,通过激活函数的方式,来加强表达能力。前馈神经网络由ReLU激活函数激活,输出评论文档中的文本经过输入编码层和注意力机制处理后的隐藏序列
Xhidden=ReLU(Linear(Linear(X)))
(22)
前馈神经网络的输出会再次经过层标准化和残差连接,进而输入到下一个编码器中,第一个编码器的输入是词编码矩阵,之后每一步的输出都是下一步的输入,直到最后一个输出的就是编码器编码后的矩阵。我们使用最后一层的第一个[CLS]标签的输出作为该句话的特征表示,也是我们使用BERT模型提取到的基于文本信息的文档特征dBERT。
2.3 语义连接和情感分析
如图3所示,最上方语义连接的主要作用就是将VistaNet模型提取到的基于视觉注意力的文档特征和BERT模型提取到的基于文本的文档特征连接起来,构建评论文档的整体情感表征
d=Dense(dVistaNet,dBERT)
(23)
情感分类主要任务是构建情感分类器,获取评论文档的情感表征d相对于情感标签的得分向量,并输出最终的情感标签。使用softmax函数在语义连接层作出相应的输出,从而对评论文档进行情感分类
y=softmax(Wcd+bc)
(24)
其中,Wc为权重,bc为偏置,y是实际输出的情感分类概率分布。使用交叉熵损失函数来衡量情感标签的真实概率分布和预测分布之间的误差
(25)
其中,y=[y0,…,y4] 是一个概率分布,每个元素yi是样本属于第i类的概率;k=[k0,…,k4] 表示样本实际的标签值。
3 实 验
3.1 数据集
我们使用的是Yelp提供的餐厅评论公开数据集,该数据集包含了波士顿、洛杉矶、芝加哥、纽约和旧金山5个城市的业务。每个评论由一个文本段落和多个图像组成,数据集已经被划分为训练集、验证集和测试集,它们的比例为80%、5%、15%。目标标签是每个评论文档的评分(从1到5),其中1、2是消极评价,3是中性评价,4、5是积极评价。数据集的详细信息见表1。
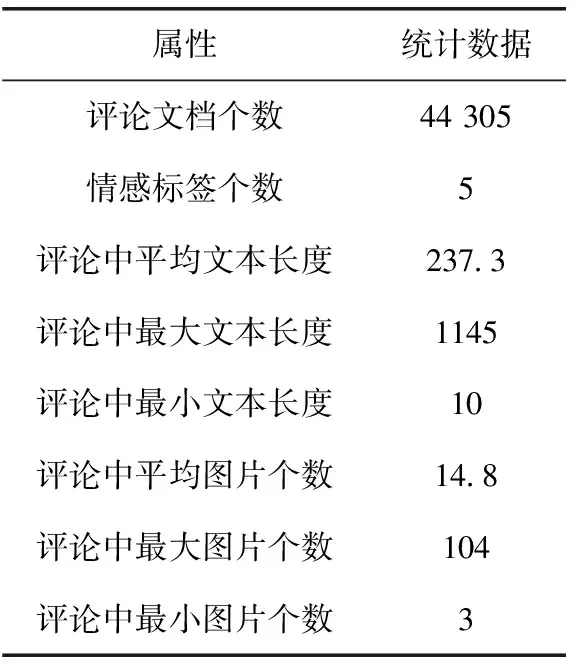
表1 Yelp数据集的统计信息
3.2 模型训练
本实验使用开源框架Tensorflow来构建整个模型,VistaNet模型使用预训练GloVe词表[11](glove.6B.200d.txt)进行词嵌入,将每个词编码为200维的向量,GRU单元的隐藏层维度为50,每个图片表示为4096维向量,它是VGG16模型的最后一个全连接层(FC7)的输出。BERT模型使用google提供的预训练模型[12](base-uncased)进行初始化,将每句话的第一个[CLS]标签的输出作为该句话的特征表示,根据Yelp数据集的统计信息,设定每个评论中的最大单词数为256,对于超过的部分进行截断。在训练中,设置batchsize为32,迭代次数为20次,采用ReLU激活函数,优化器选用RMSprop,设定初始学习率为0.001。
3.3 对比模型
将我们的模型和以下几个模型进行比较,它们大部分是同时使用文本特征和视觉特征进行情感分类。
(1)TFN-VGG:TFN[13]是基于张量外积的多模态融合方法。将文本特征和视觉特征使用张量外积进行融合。因为每个评论都有多张图片,而池化层起到聚合图像信息的作用,TFN-mVGG和TFN-aVGG分别对应TFN模型的最大池化和平均池化。
(2)BiGRU-VGG:BiGRU[14]是由两个GRU组成的序列处理模型,使用双向门控单元捕获前向依赖和后向依赖。BiGRU-VGG是将BiGRU提取到的文本特征和VGG提取的视觉特征拼接融合得到最终的文档情感特征。BiGRU-mVGG和BiGRU-aVGG分别对应最大池化和平均池化。
(3)HAN-VGG:HAN[15]使用层次的注意力网络获取文档的表示,第一层是单词级的注意力机制,根据不同单词的贡献,产生句子级别的表示,第二层是根据句子的贡献,产生文档级别的表示。基于HAN-ATT的文本特征和基于VGG的图像特征拼接为文档情感特征。同样根据池化层的不同产生两个对比模型:HAN-mVGG和HAN-aVGG。
(4)FastText:它是Word2Vec衍生所得,可以高效学习单词表示以及句子分类问题。用它得到文档中文本的表示,进而和BERT模型进行比较。
(5)LSTM:它是一种加入了门控单元的特殊RNN,可以比常规RNN更准确地学习序列数据。将LSTM得到的文档文本分类结果和BERT得到的进行比较。
(6)BERT:它是由多个Transformer的Encoder部分叠加而成,利用自注意力机制让序列中的每一个Embedding都可以相互注意,采纳权重。有效解决句子长期依赖问题,显著提升了理解不同任务中无标记文本的能力。
(7)VistaNet:该模型利用视觉信息作为注意力将图像和文本的信息进行融合,可以有效分析评论文档的情感极性。
3.4 实验结果与分析
表2展示了7个对比模型和我们的模型在Yelp数据集上的准确率,其中平均值表示数据集不按照城市划分,模型效果的提升是以TFN-aVGG模型为基线得到。
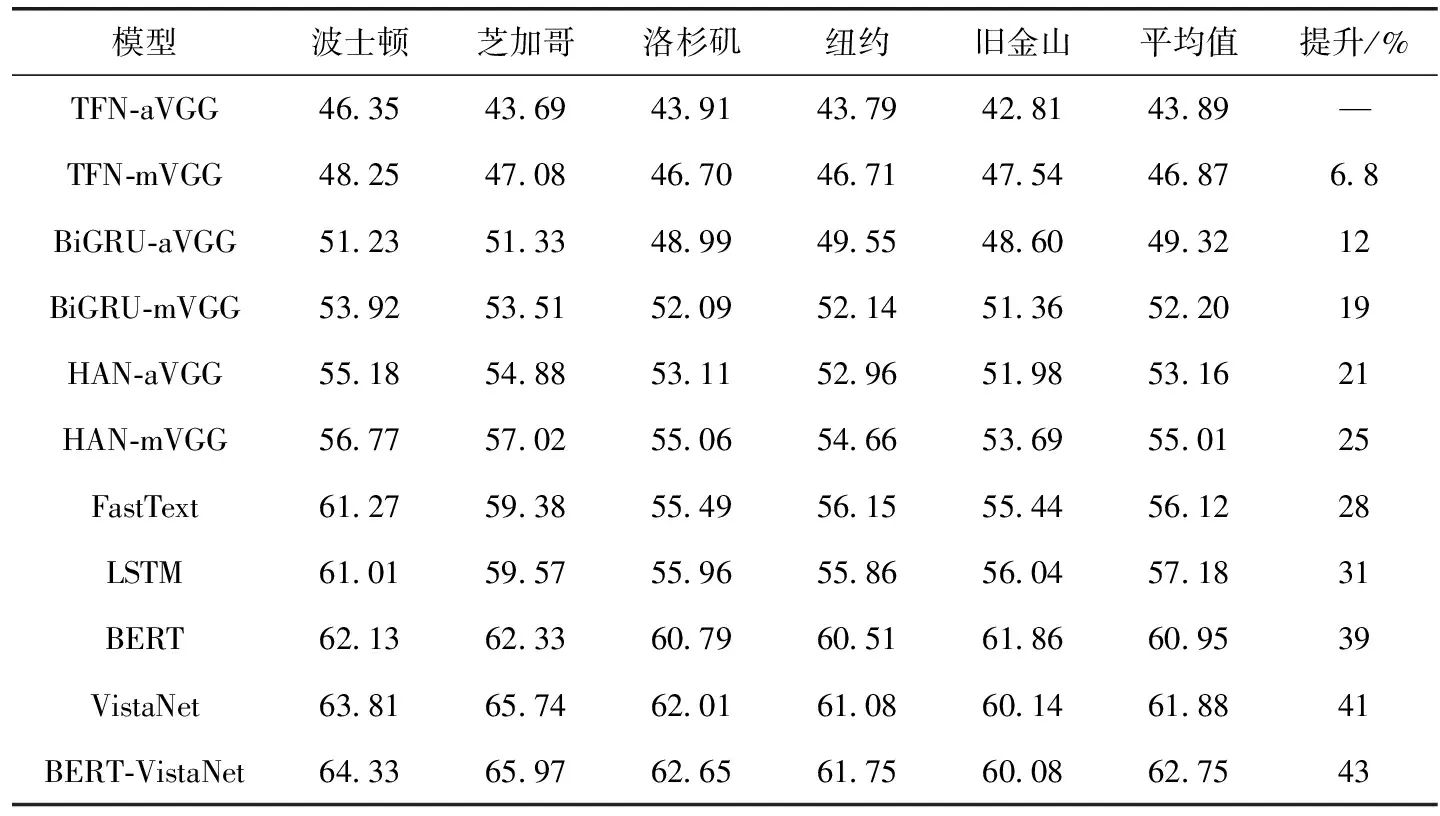
表2 情感分析的准确性比较
我们使用两个模型FastText和LSTM与BERT模型比较,最终选用BERT模型来获取基于文本的文档表示。我们的模型BERT-VistaNet相比于基线模型TFN-aVGG提升了43%,相比于VistaNet模型提高了1.4%。使用视觉注意力的VistaNet模型相比于没有使用视觉注意力的模型TFN、BiGRU、HAN效果有明显提升,说明图像中的一些信息可以为评论的整体情感起到帮助作用。BERT-VistaNet模型的效果相较于VistaNet模型有所提升,说明图像中的信息无法完全覆盖评论中的文本信息,基于文本的文档特征对视觉信息中缺少的情感信息进行了有效的补充。
为了进一步评估所提出的模型,分析我们模型的结构,总结出可以影响情感分析的几种结构因素:层次结构、自注意力机制、视觉注意力机制、视觉注意力特征和文本特征的拼接。我们对BERT-VistaNet模型进行消融实验,分析每一个组件对模型的贡献。
如表3所示,我们在Bi-GRU的基础上增加组件进行实验,首先加入了层次结构,模型的准确率在Bi-GRU的基础上提升了4.8%,然后在层次结构的基础上又加入了注意力机制,模型又提升了1.4%。VistaNet模型在此基础上加入了视觉注意力,平均准确率也相应提升到61.88%,最后将BERT提取的文档特征与VistaNet提取到的基于视觉注意力的文档特征结合得到我们的模型BERT-VistaNet,模型的效果也得到了提升,准确率达到了62.75%。这样的结果表明模型中各个组件都起到了积极作用,有助于评论的情感分析。
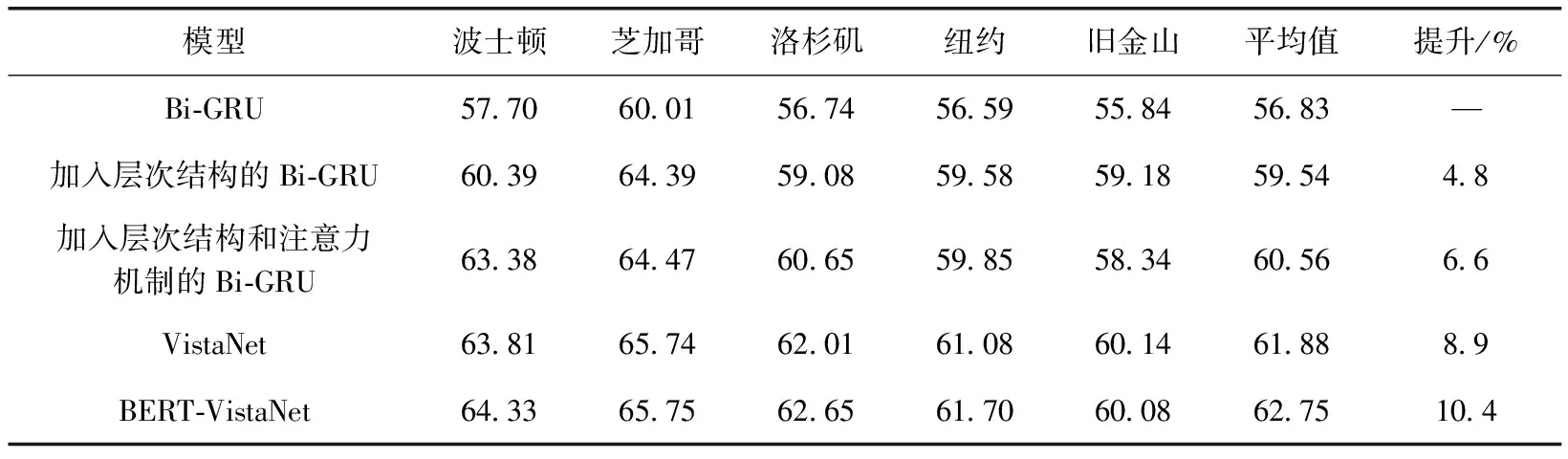
表3 消融分析
4 结束语
本文对图文情感分类的相关工作进行了研究,针对于评论中图像的视觉注意力无法完全覆盖文本的问题,在Yelp网站公开的餐厅评论数据集上,提出使用BERT提取文档的文本特征,并将提取到的特征和基于视觉注意力的特征融合在一起,形成新的文档情感特征,从而提高图像和文本跨模态情感分类的性能。我们对美国5个城市的Yelp网站上在线评论进行了实验,结果表明我们的模型的准确率高于其它10个基线模型,从而验证了模型的有效性。
情感分类是一个极有意义的研究方向,本文所提出的模型只是关注于图像和文本的情感分析,跨模态的融合不应只局限于此,我们后续将研究更多的模态,包括音频、视频等。希望可以找到更有效的特征提取和特征融合的方法,为情感分类提供更有效的信息。
