基于对抗训练的事件要素识别方法
2024-02-22沈文龙张顺香马文祥
廖 涛,沈文龙,张顺香,马文祥
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
0 引 言
事件抽取是信息抽取的一个重要子任务,事件要素识别的效果对自然语言处理领域的下游任务有着重大的意义。根据ACE(automatic content extraction)评测会议的定义,事件抽取是由事件检测和事件要素抽取两大任务组成的。其中,事件检测包括事件触发词识别和事件类型分类,事件要素抽取包括事件要素识别和事件要素角色分类。事件触发词通常表示为事件发生的词,事件要素指的是包含在事件句中的时间、地点、对象等需要被识别的要素。例如,给定一个事件句S1:
S1 8日凌晨,合宁高速公路上一辆货车与一辆大客车相撞。
事件检测任务首先会识别出“相撞”为事件的触发词,并将其分类为“交通事故”事件。事件要素抽取任务需要识别出时间为“8日凌晨”,地点为“合宁高速公路”,对象为“货车”和“大客车”。本文的研究内容为事件要素识别任务。
为了丰富文本的向量表示,本文使用组合神经网络Bert-BiGRU-CRF作为基础模型。考虑到字符级别的信息不能够完整表示事件要素,将词信息与字信息进行融合,丰富向量表示。为了提升模型的鲁棒性,将对抗训练引入模型中提升模型的效果。在CEC语料库中的实验结果表明,该方法能有效提高事件要素识别的效果。
1 相关工作
传统的事件要素识别方法有基于模式匹配和机器学习的方法,早期采用模式匹配的方法,该方法依赖于特征工程和领域专家知识,将待抽取的事件和已知的模式通过模式匹配算法进行匹配,通常在某一特定的领域表现较好,但可移植性较差。基于机器学习方法开始将事件要素识别任务转化为分类问题,注重于分类器的构建和特征的选择,代表性的模型有隐马尔可夫模型、支持向量机模型和条件随机场模型等。近年来,深度神经网络模型发展迅速,事件要素识别的工作利用神经网络也大放异彩。
Nguyen等[1]提出一种基于句法依存树图的卷积神经网络模型,和一种新的基于实体提及的池化方法,实验结果优于当时的主流模型。Wang等[2]针对现有的方法没有关注事件要素角色之间的概念相关性,提出了一种分层模块化的时间要素抽取模型,最终在ACE2005数据集上取得了59.3%的F1值。沈兰奔等[3]提出一种结合注意力机制和双向长短期记忆网络的模型,将中文事件检测任务转化为序列标注任务,解决了中文事件检测的特定问题。Du等[4]提出了一种具有全局文档记忆的模型框架,将之前抽取的事件作为额外的上下文来帮助模型学习事件间的依赖性,实验验证了该方法有助于事件要素的识别与分类。蔺志等[5]提出一种基于半监督的方法,通过领域词典匹配进行标注,在公共数据集上的实验结果取得了较为理想的效果。Kan等[6]提出一种基于多层扩张门控卷积神经网络的事件抽取模型,并将增强的全局信息和字特征进行融合,在ACE2005数据集上的实验验证了该方法的有效性。Shen等[7]提出一种基于CNN-BiGRU的联合抽取模型,通过CNN和BiGRU网络同时学习局部和全局信息的特征表示,使用注意力机制去融合两种特征,在MLEE数据集上的实验表明了该模型可以很好地同时处理触发词和事件要素的抽取。陈敏等[8]运用机器阅读理解的框架来完成事件论元的抽取,通过回答关于事件论元的问题来抽取论元,利用了论元角色类别的先验信息,在ACE2005数据集上的实验验证了该模型的有效性。此外,还有其它的学者[9-13]也将神经网络模型用于事件抽取任务。
对抗训练最早应用于计算机视觉领域,指在训练样本中添加细微的扰动因子,导致最后模型产生错误的分类。通过这种训练可以让模型适应这种改变,提高模型的鲁棒性。Miyato等[14]在文本分类领域提出了对抗训练的方法,在递归神经网络的词嵌入中添加扰动,验证了对抗训练在文本的任务中也能具有不错的表现。黄培馨等[15]提出一种融合对抗训练的端到端知识三元组抽取模型,提高了模型的鲁棒性和抽取效果。
2 基于对抗训练的事件要素识别模型
基于对抗训练的事件要素识别模型分为4层,如图1所示。第一层为嵌入层,采用Bert预训练语言模型将文本编码为字向量,并与含有边界信息的分词向量融合作为融合向量;第二层为对抗训练层,在融合向量中添加扰动因子得到对抗样本;第三层为编码层,通过BiGRU网络获得文本的上下文语义特征;第四层为CRF层,通过CRF层从训练数据中学习到约束规则,保证预测标签的合理性,来完成事件要素识别任务。

图1 模型框架
2.1 嵌入层
本文使用Bert-Base-Chinese预训练语言模型来获得输入文本的向量表示。该模型包含了12层Transformer,每层Transformer含有12 个多头自注意力和768个隐层单元。输入句子通过Bert模型进行编码后,可以得到包含丰富语义信息的特征向量。给定一个句子S={W1,W2,…,Wi,…,Wn}, 其中Wi表示给定句子的第i个字,在句子的开头添加[CLS]符号表示一个句子的开头,[SEP]分句符号用于断开输入文本的两个句子。
经过预训练语言模型Bert-Base-Chinese处理后得到的字向量为St={t1,t2,…,ti,…,tn}, 其中ti是由3部分相加得到的,分别为Token Embedding、Position Embedding和Segment Embedding。Token Embedding表示输入文本本身的向量;Position Embedding表示输入文本的位置信息的向量;Segment Embedding表示区分输入文本相邻句子的向量。其中,Token Embedding层是将输入的文本每个词转化为固定维度的向量,在本文中,表示为768维的向量。Segment Embedding层通过两种不同的向量表示来区分两个句子,将0赋值给前一个句子中的各个token,把1赋值给第二个句子中的每个token。相同的token在不同的位置具有不一样的语义信息,Position Embedding层通过构建一个表来区分不同位置的token,给模型传递token的输入顺序信息。
Bert 模型包含两个预训练任务,分别为掩盖语言模型MLM(masked language model)和下一句预测NSP(next sentence prediction)。
(1)为了获得具有双向特征的向量,采用掩盖语言模型进行预训练,使用[MASK]标记去随机代替语料15%的Token,训练模型去预测被掩盖掉的Token。
(2)为了让模型具备理解两个句子之间的潜在关系,采用了下一句预测的预训练方法。对于语料库中的任何两个句子S1和S2,句子S2有50%的概率是句子S1的下一句。通过将两个任务进行联合训练,能够得到丰富语义信息的向量表示。
中文在书写上的表达不同于英文,没有天然的分隔符,因此很难捕捉到词语的边界信息,这给中文事件要素识别任务增加了一定的难度。本文采用基于Python的jieba分词方法对输入文本进行处理,设经过Bert模型编码得到的某个字向量为ti, 包含该字的分词编码为特征向量Ci, 接着将字向量与特征向量融合得到富含更丰富语义信息的融合向量Ri。 融合向量Ri的表示如式(1)所示
Ri=ti⊕Ci
(1)
其中,ti表示该字向量;Ci表示分词特征向量;⊕表示向量拼接。最后将融合向量送入模型中继续训练。
2.2 对抗训练层
本文使用对抗训练作为一种正则化的方式,通过向原始数据中添加微小的扰动来提高模型的泛化能力。输入文本在经过嵌入层编码为字向量后,向其添加扰动因子radv来获得对抗样本,生成的对抗样本可以让模型有概率产生错误的判断,以此来训练模型的对抗防御能力。
在自然语言处理领域通常有两种添加扰动的方式,分别为离散扰动和连续扰动。离散扰动指的是在输入文本中直接进行微小的修改;连续扰动指的是在输入文本生成的字向量中添加扰动。添加的扰动需具备以下两个特征:一是添加的扰动必须是微小的;二是添加的扰动是要有意义的,即能够让模型产生错误的输出。离散扰动由于是在文本中进行修改,对抗样本与原始样本的差异能够直接被找到,而连续扰动同时具备上述两个特征。因此本文使用的是连续扰动。
设字词融合后的向量表示为R={r1,r2,…,rn}, 扰动因子radv的计算公式由式(2)所示
(2)
其中,ε表示超参数的小有界范围,g表示损失函数关于Ri的偏导。g的计算公式由式(3)所示
(3)
其中,L为损失函数。Y表示标签信息,θ表示模型参数。得到的对抗样本Radv如式(4)所示
Radv=R+radv
(4)
将融合向量与对抗样本一起送入编码层进行下一步训练。
2.3 编码层
本文使用BiGRU神经网络来学习文本的上下文语义信息。LSTM和GRU都是RNN的变种模型,解决了RNN模型中长距离梯度爆炸的问题。GRU是LSTM的改进模型,相比较LSTM而言,GRU拥有更简单的结构和更少的参数。GRU的结构中只引入两个门控单元来控制信息的更新,分别为更新门和重置门,其中,更新门是由LSTM模型中的遗忘门和输出门合并而来的。更新门负责控制对前一时刻信息的筛选与接收的信息,更新门的值越大说明前一时刻的信息被接收的越多;重置门负责控制是否遗忘前一时刻的信息,重置门的值越小说明遗忘的越多。GRU的单元结构如图2所示。

图2 GRU单元结构
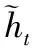
zt=σ(Wzxt+Uzht-1+bz)
(5)
rt=σ(Wrxt+Urht-1+br)
(6)
(7)
(8)
其中,σ表示sigmoid 激活函数;tanh表示Tanh激活函数;⊙表示Hadamard乘积。
单向的GRU网络只能捕捉从前向传递来的信息,而没有考虑下文信息的重要性,因此使用双向的门控循环神经单元网络。将字词融合后的向量和对抗样本输入到BiGRU网络中,并将前向信息和后向信息融合得到具有上下文语义信息表示的向量。BiGRU的模型结构如图3所示。

图3 BiGRU模型结构
2.4 CRF层
BiGRU 网络层为每个标签输出一个预测分数值,挑选分值最高的作为该标签的预测分类,但可能会出现标签序列不合理的情况。在本文中,在BiGRU网络的后面接一个CRF层,可以为最后的预测标签添加约束条件来保证结果是合理的,得到最优的标签序列。
条件随机场是在一组给定的输入序列X的前提下,得到标签序列Y的条件概率分布模型。将 BiGRU层输出的标签概率作为发射分数,和转移分数一起计算最终得分。计算公式如式(9)~式(10)所示
(9)
(10)
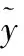
3 实验设计与结果分析
3.1 数据集
CEC语料库是由上海大学(语义智能实验室)所构建。以XML语言作为标注格式,包含了Event(事件)、Denoter(标志词)、Time(时间)、Location(地点)、Participant(参与者)和Object(对象)这6个数据标记,5类(地震、火灾、交通事故、恐怖袭击和食物中毒)突发事件的新闻报道合计332篇。CEC语料库虽然在规模上较小,但对事件和事件要素的标注却最为全面。
3.2 实验参数
本文实验环境是在Windows 10操作系统上完成的,模型利用深度学习PyTorch框架进行训练,编程语言选择的是Python 3.7版本,GPU为NVIDIA GeForce RTX 3060,内存为16 GB。实验参数的设置见表1。

表1 实验参数
3.3 评价指标
本文采用准确率P(Precision)、召回率R(Recall)和F1值来评价事件要素抽取的效果,计算公式如式(11)~式(13)所示
(11)
(12)
(13)
其中,TP表示被正确抽取的论元数量;FP表示被错误抽取的论元数量;FN表示未被抽取的正确的论元数量。
3.4 实验结果及分析
为了验证本文提出的模型的有效性,进行了两组实验,分别为消融实验和对比实验。消融实验以本文模型为基础模型,通过移除某些组块之后该模型的性能,来验证该组块对整个模型的作用。对比实验通过和当前的主流神经网络模型进行比较,验证模型的有效性。实验结果分别见表2和表3。
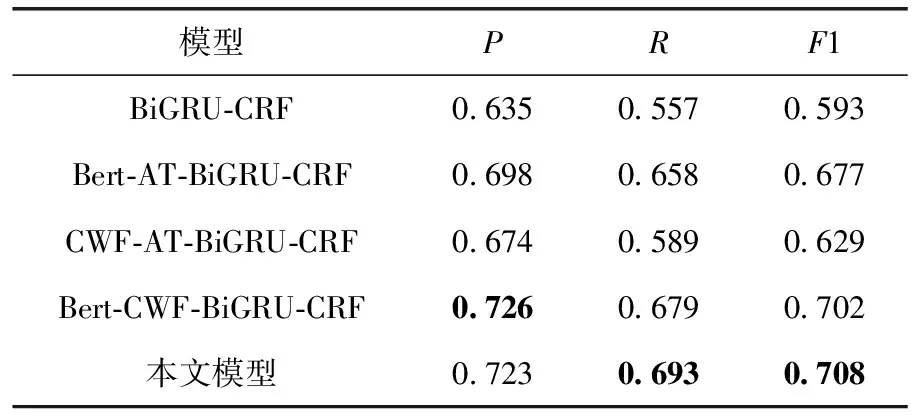
表2 消融实验结果

表3 对比实验结果
表2表示消融实验的结果。通过结果的对比,当模型仅使用BiGRU和CRF之后,模型的整体性能大幅下降。在本文模型的基础上移除字词融合模块,实验结果的准确率、召回率和F1值分别下降了2.5%、3.5%和3.1%,说明融合词信息后,可以丰富向量的语义表示,对要素识别的效果有帮助。Bert预训练语言模型具有强大的表征学习能力和上下文理解能力,当不使用Bert时,相比较本文模型,准确率、召回率和F1值分别下降了4.9%、10.4%和7.9%,说明了Bert模型的双向编码能力有助于提高事件要素识别的结果。当本文的模型移除对抗训练模块后,准确率上升了0.3%,召回率和F1值分别下降1.4%和0.6%。对抗训练在事件要素识别任务中作为一种正则化的模块,可以提高模型的泛化能力。总体来看,Bert模块对本文模型效果的提升最大,字词融合和对抗训练模块在一定程度上都有利于提高事件要素识别的效果。
表3表示对比实验的结果。相比较DMCNN模型,本文的模型提高了12.8%的准确率,8.0%的召回率和10.4%的F1值,在DMCNN模型中,输入层将词嵌入、位置嵌入和事件类型嵌入拼接作为词级别的特征,而本文使用了预训练语言模型Bert去丰富字词的向量表示。本文的模型相比于JRNN模型提高了8.0%的准确率、9.6%的召回率和8.9%的F1值,用BiGRU网络代替双向循环神经网络,解决了长距离信息遗忘的问题。相对于JMEE[16]模型,本文用双向门控循环单元网络代替双向长短期记忆网络,计算变得更加简洁,在嵌入层融合了字向量的信息,丰富向量的表示,分别提高了4.5%的准确率、4.7%的召回率和4.6%的F1值。
4 结束语
针对当前中文事件要素识别任务中未充分考虑词边界信息的问题,本文提出一种融合词级别信息的对抗训练事件要素识别模型。通过Bert-Base-Chinese预训练语言模型获得字符向量,利用jieba分词工具将原始文本进行切分得到词级别的信息,和字符向量进行融合得到特征向量,对特征向量进行对抗训练生成对抗样本,和特征向量一同送入BiGRU网络学习文本的上下文语义信息,最后用CRF进行解码。在CEC语料库上的实验结果表明,本文提出的字词融合和对抗训练模块对识别结果有效,使模型的准确率、召回率和F1值都有了不同程度的提高。
