改进的YoloV3轻量化多目标检测算法
2024-02-22苏擎凯何睿清曹雪虹
苏擎凯,童 莹,何睿清,曹雪虹,
(1.南京邮电大学 通信与信息工程学院,江苏 南京 210003;2.南京工程学院 信息与通信工程学院,江苏 南京 211167)
0 引 言
目标检测的任务是找出图像中所有感兴趣的目标,确定它们的类别和位置[1]。如今目标检测的应用已经遍及生活的各个方面,往往需要将目标检测网络部署在各种边缘端、移动端上,而由于边缘设备、移动设备的硬件限制要求目标检测网络在降低参数量的前提下尽可能达到实时、准确的目标检测效果,因此高精度轻量化目标检测网络研究具有重要的现实意义。经典的目标检测网络分为双阶段检测算法和单阶段检测算法。单阶段检测算法有更快的检测速度。最具代表性的是SSD(single shot multibox detector)[2]与Yolo(you only look once)系列网络。Redmon提出的YoloV1[3]、YoloV2[4]与YoloV3[5],以及Bochkovskiy等提出的YoloV4网络,逐渐提高了检测精度,但也使得网络结构更加复杂,推理速度下降,这并不利于目标检测网络在移动设备上的运行。因此轻量化神经网络越来越为人们所重视,MobileNet[6-8]系列,MnasNet[9]以及ShuffleNet系列[11,12]等相继被提出,这些网络降低了参数量,同时也降低了检测精度。
针对以上问题,本文设计实现了一种轻量化多目标检测网络MSPF-YoloV3,此网络采用MobileNetV2作为YoloV3的特征提取网络;在特征提取网络的瓶颈结构(Bottleneck)中,利用低内存占用、低分组数的通道混洗(Shuffle)结构增加通道间信息交流,提高检测精度;采用SPP模块融合多尺度的感受野;改进特征融合网络,将浅层特征与深层特征融合,增加对不同大小目标[13-16]的检测精度。
1 网络结构
1.1 网络结构总体设计
本文设计实现的网络MSPF-YoloV3如图1所示。原YoloV3网络的参数量主要来自于特征提取网络DarkNet53,因此本文将其替换为更加轻量化的MobileNetV2网络,并且对其中的Bottleneck进行改进,在Bottleneck的输入与输出的位置分别加入分组数为2的通道混洗操作,增加通道之间的信息交流(如图1中Bottleneck)。在特征提取网络的输出之后增加SPP模块,将不同大小的特征图进行拼接,将多重大小感受野进行融合(如图1中SPP)。最后改进特征融合网络PANet,引出浅层特征与深层特征的上采样结果融合(如图1中Feature Fusion)。此网络名字中M代表MobileNetV2,S代表通道混洗Shuffle操作,P代表SPP模块,F代表特征融合,YoloV3表示使用YoloV3的基础网络结构。

图1 MSPF-YoloV3网络结构总览
1.2 特征提取网络
DarkNet53是YoloV3的特征提取网络[5],作为原Yolov3的主干网络,网络结构见表1。
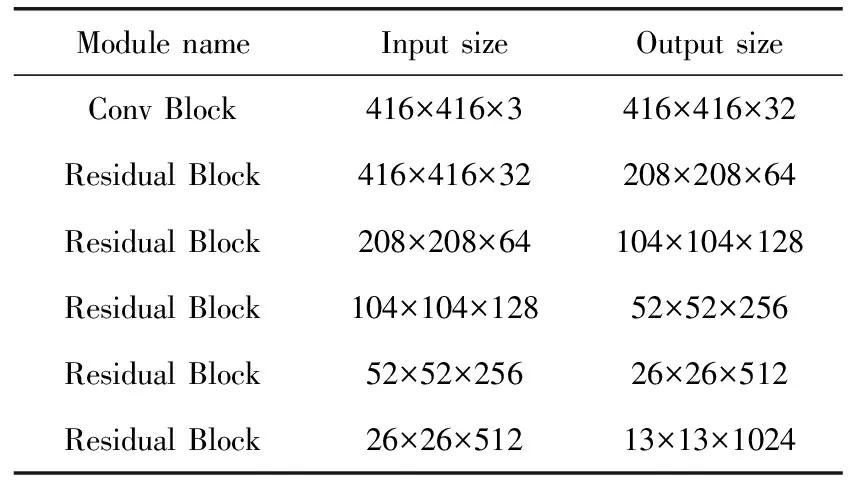
表1 DarkNet53结构
本文采用MobileNetV2网络代替DarkNet53作为YoloV3的特征提取网络。网络结构见表2。
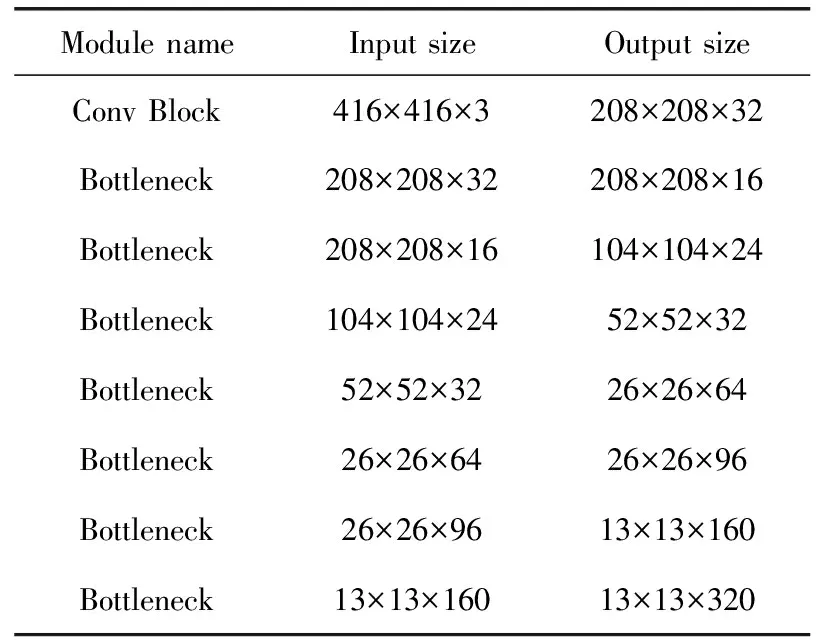
表2 MobileNetV2网络结构
MobileNetV2网络提出了一种新的逆残差模块[7]Bott-leneck,使得残差模块中的特征传递可以在高维度进行,残差模块之间的特征传递在低维度上进行,有效提高了特征提取效果,且使用了深度可分离卷积,大大减少了参数量。其内部结构变化如图2所示。
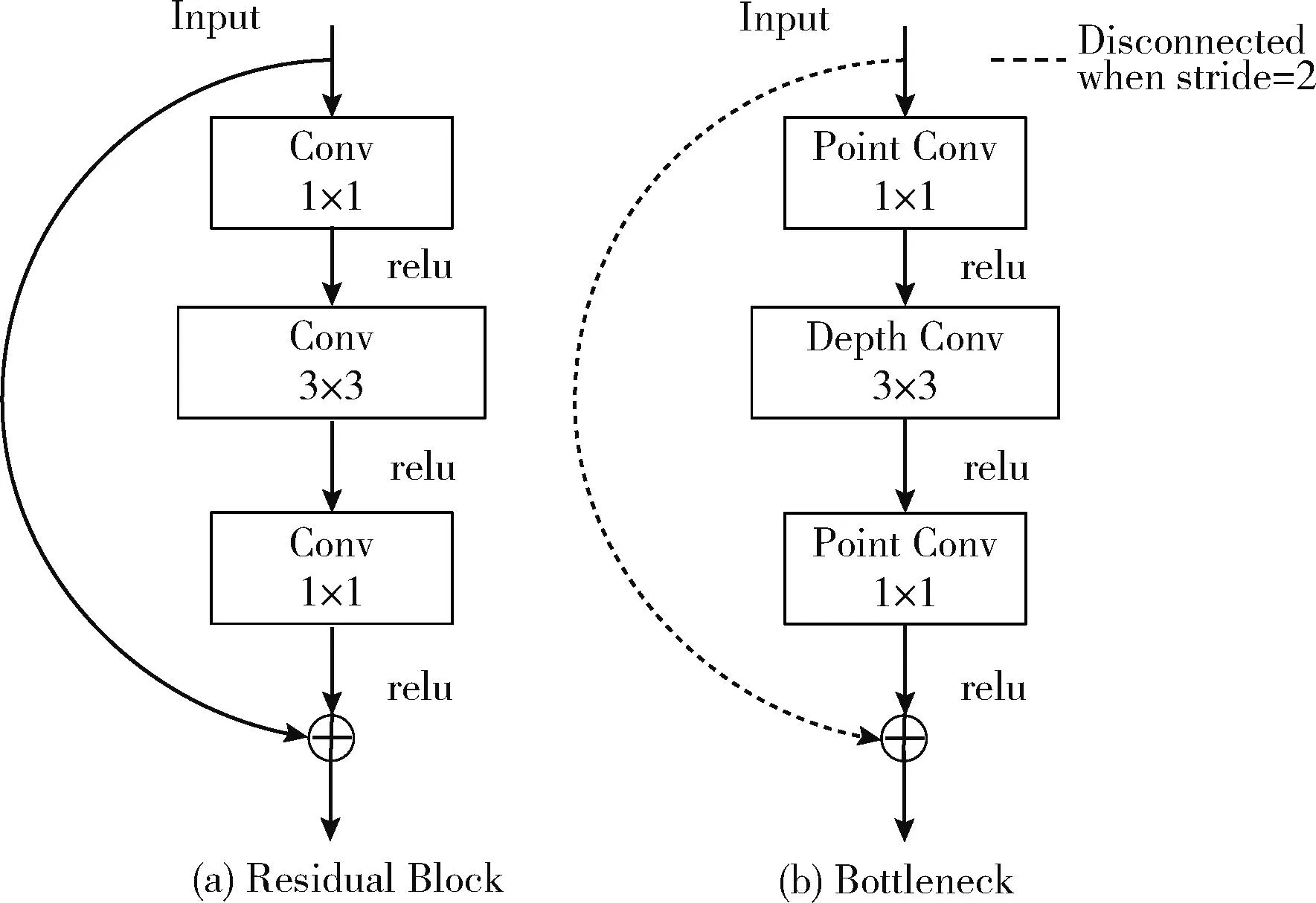
图2 残差结构对比
Bottleneck只有在步长为1时才使用残差连接,在步长为2时不使用[7]。该结构中首先通过一个1×1卷积块将输入升维,然后通过深度可分离卷积代替一般的卷积块,实现对图像的卷积和降维,同时将输出的激活函数relu改为Linear线性连接。深度可分离卷积将普通卷积分解成深度卷积与点卷积。k为卷积核大小,C1为输入通道数,C2为输出通道数,普通卷积参数量Pc如式(1)所示
Pc=k×k×C1×C2
(1)
深度可分离卷积参数量Pdc如式(2)所示
Pdc=k×k×C1+1×1×C1×C2=
C1×(k×k+C2)
(2)
深度可分离卷积与普通卷积的参数量比值Pdc/c如式(3)所示
(3)
一般卷积核大小选择3×3,因此深度可分离卷积的参数量约为普通卷积的1/8到1/9。同样的,本文将网络的所有普通卷积都替换成深度可分离卷积,既达到了与原来相同的效果,又减少了大量的参数,以此作为基础网络M-YoloV3。
1.3 通道混洗
2018年,ShuffleNetV1提出了一种分组卷积和通道混洗的方法[11],分组卷积是将输入通道分若干组,不同组的通道与不同的卷积核进行卷积,最后将结果拼接在一起,这种卷积方式会导致不同组的通道之间没有任何的信息交流,而通道混洗的操作会按照既定规则将各个分组中的通道打乱,重新排列,使得不同分组之间的信息相互融合,克服了组卷积的缺点。经过ShuffleNetV1网络的实验,发现分组数g越大,网络的识别效果越好[11],但是ShuffleNetV2提出分组数g越大,占用的内存越大[12],这对于在移动设备上运行神经网络是一个劣势。
本文使用的特征提取网络中的深度可分离卷积可以看作是组卷积的一个特殊情况,即分组数g与输入通道相同,因此也具有通道间信息交流少的特点。本文设计用两次分组数g为2的通道混洗操作来代替一次分组数g为4的通道混洗操作增加不同组通道之间的信息交流,既满足分组数越大效果越好的结论,也符合减少分组数以减少内存占用的原则。
通道混洗的具体做法是先将输入通道分组叠加为矩阵,之后将这个矩阵转置并逐行读入,便得到了输出通道。遵循这种方法,本文证明两次g=2的通道混洗结果与一次g=4的通道混洗结果一致,而且此操作不会增加模型的参数量。推算过程如图3、图4所示。

图3 一次g=4的通道混洗
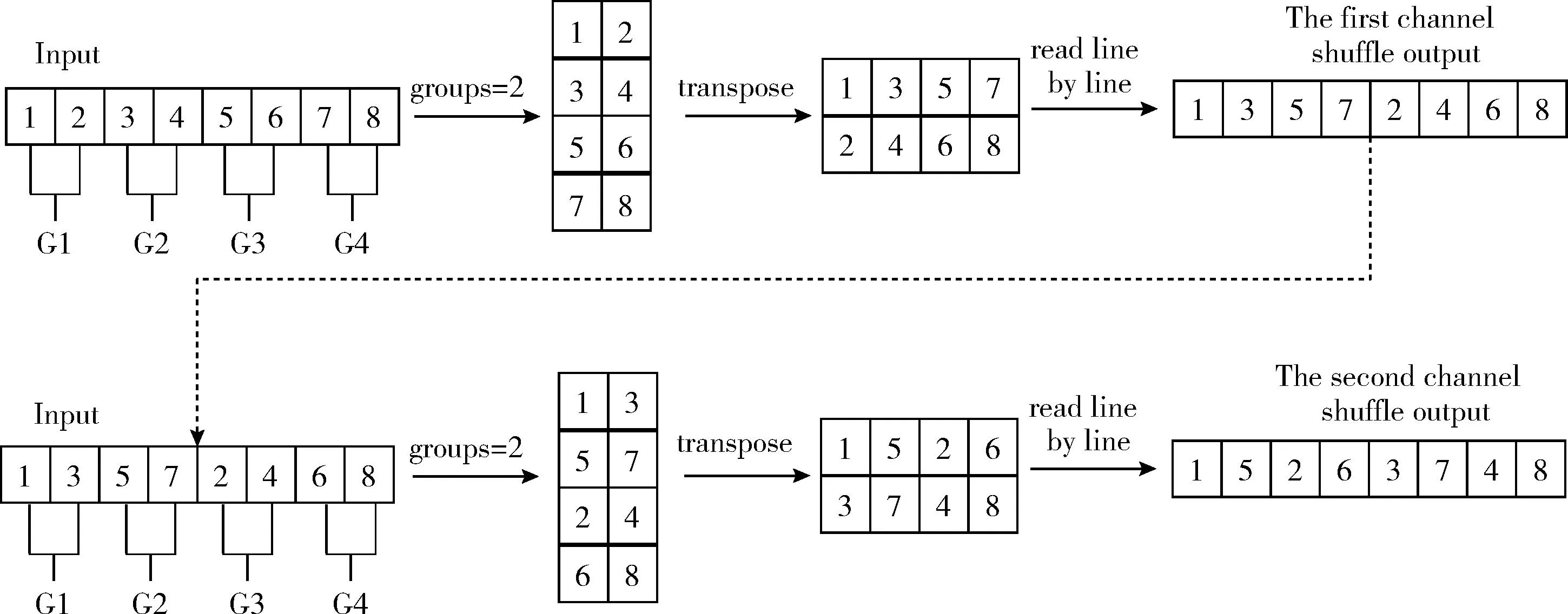
图4 两次g=2的通道混洗
因此本文在原Shuffling Module(如图5(a)所示)基础上进行改进,在输入与输出的位置分别加入g=2的通道混洗操作作为本文改进的Bottleneck,如图5(b)所示。在图中位置加入通道混洗,可以在两个Bottleneck之间形成等价于g=4的通道混洗操作,既节约了内存,又尽可能利用高分组数增加了通道之间的信息交流,提高目标检测精度。本文将使用这种Bottleneck的网络称为MS-YoloV3。

图5 原Shuffle Module与加入通道混洗的Bottleneck对比
1.4 SPP模块
SPP模块的功能是将输入特征图并行经过不同大小的池化层,再将各支路的结果拼接在一起,结构如图6所示。
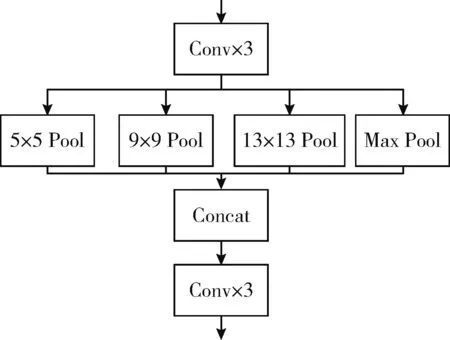
图6 SPP模块结构
SPP模块借鉴了空间金字塔的思想[16-18],实现了局部特征和全局特征融合,丰富了特征图的表达能力,有利于待检测图像中目标大小差异较大的情况,提高对不同大小目标的检测精度。
因此本文将SPP模块直接连接在特征提取网络的输出之后,可以将不同尺寸的特征融合,提高感受野大小,对于YoloV3这种多目标检测网络非常有利,本文将这种网络结构称为MSP-YoloV3。
1.5 特征融合
经过上述的理论分析,MSP-YoloV3网络结构设计如图1(不包括图中特征融合部分)所示。将M-YoloV3网络与MSP-YoloV3网络在PASCAL VOC数据集上进行训练,分别向两个网络分别输入一张相同的图片,两种网络推理得到结果如图7中的前两张结果所示。

图7 各网络推理结果
对比两种网络推理结果,发现MSP-YoloV3网络比M-YoloV3网络多检测到了最左边的汽车,且绝大多数的检测置信度大于基础网络的检测置信度,但是对于远处的尺寸较小的行人却没有标示出检测框,分析原因:
(1)M-YoloV3网络对左侧的车可能已经检测到了,但由于置信度较低(低于设置的阈值0.5),导致结果中没有标示出检测框。而网络的对人检测的精确度比对汽车的精确度高,对远处的人的置信度达到了0.5,因此标示出了检测框。
(2)对比两张推理结果中的各个检测框,可以看到MSP-YoloV3网络每一个目标的置信度都是大于M-YoloV3网络的,因为加入通道混洗操作之后通道间的信息交流增加,提高了精确度,但是对于远处的行人这种尺寸较小的目标检测精度却降低了,因为在特征提取网络中的各个Bottleneck都加入了通道混洗操作,导致浅层的特征图中所包含的目标信息过早被打乱,使得小尺寸目标的检测更加困难。
在特征提取网络中,浅层的特征图感受野小,特征语义信息比较少[19-21],但是目标位置准确,比较适合检测小尺寸目标;而深层的特征图感受野大,包含更多的特征语义信息,也包含了更多的背景噪音,对小尺寸目标的检测不利。因此本文将经过更少量特征提取网络的浅层特征图引出,并与深层特征图在PANet中进行融合,利用浅层特征的位置信息,指导深层特征对小尺寸目标进行更加准确的检测。网络结构设计如图1所示,增加图1中的特征融合部分,得到本文完整的网络MSPF-YoloV3。推理图片结果图7中的第三张结果图所示。MSPF-YoloV3推理结果证明将浅层特征与深层特征进行融合,增加了对小尺寸目标的识别精度,效果较为显著。
2 实验结果与分析
2.1 实验环境
本文的实验平台为Ubuntu16.04,装有两块NVIDIAGTX 1080Ti显卡,评价指标采用mAP,即各类别AP的平均值。数据集采用PASCAL VOC07+12数据集与COCO2014数据集,COCO2014数据集使用与PASCAL VOC07+12数据集中相同的20个类的图片。初始学习率设置为0.001,随训练epoch动态减少,训练epoch为500,loss稳定后保存结果。
2.2 实验结果
本文在PASCAL VOC07+12数据集上训练测得YoloV3原网络、M-YoloV3网络,MP-YoloV3网络,MSP-YoloV3网络以及MSPF-YoloV3的mAP与FPS(Frames Per Second)见表3。

表3 PASCAL VOC07+12数据集上的性能对比
在COCO2014数据集上测得的mAP与FPS,结果见表4。

表4 COCO2014数据集上的性能对比
从表3和表4中的结果可以看出,以MobileNetV2代替DarkNet53作为特征提取网络,参数量的降低导致了一定检测精度损失,而加入SPP模块、修改Bottleneck以及改进特征融合网络都使检测精度得到了显著提升。这些改进使得网络在推理时的FPS在两个数据集上分别达到了44.21 FPS与43.78 FPS。验证了本文网络改进在不同数据集上的鲁棒性。
本文提出的各种改进措施均不会增加大量的参数量,在深度可分离卷积的作用下网络权重大小降低了约198 MB。适合在存储空间有限的移动设备上运行,各网络的权重文件大小见表5。
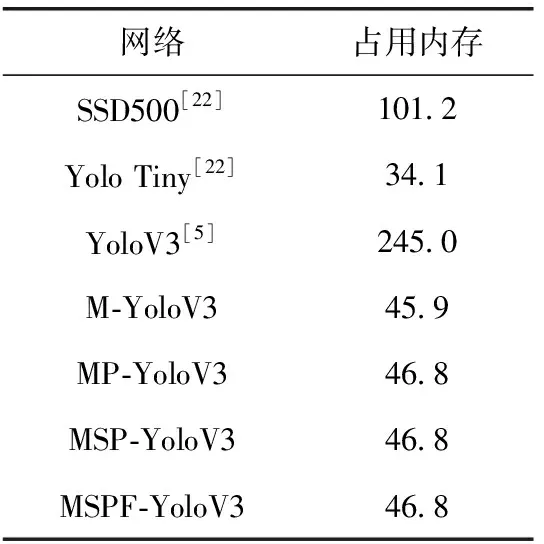
表5 不同网络模型权重文件大小/MB
MSPF-YoloV3网络在PASCAL VOC07+12数据集20个分类(a)~(t)的准确率如图8所示,COCO2014数据集中20个分类的准确率如图9所示。图中纵坐标表示识别率Precision,范围是0~1,横坐标表示得分阈值Score-Threhold,范围是0~1,本文取Score-Threhold=0.5时的Precision作为最终结果,每张子图的右下角标注了数据的类别(class)和识别精确度(precision)。
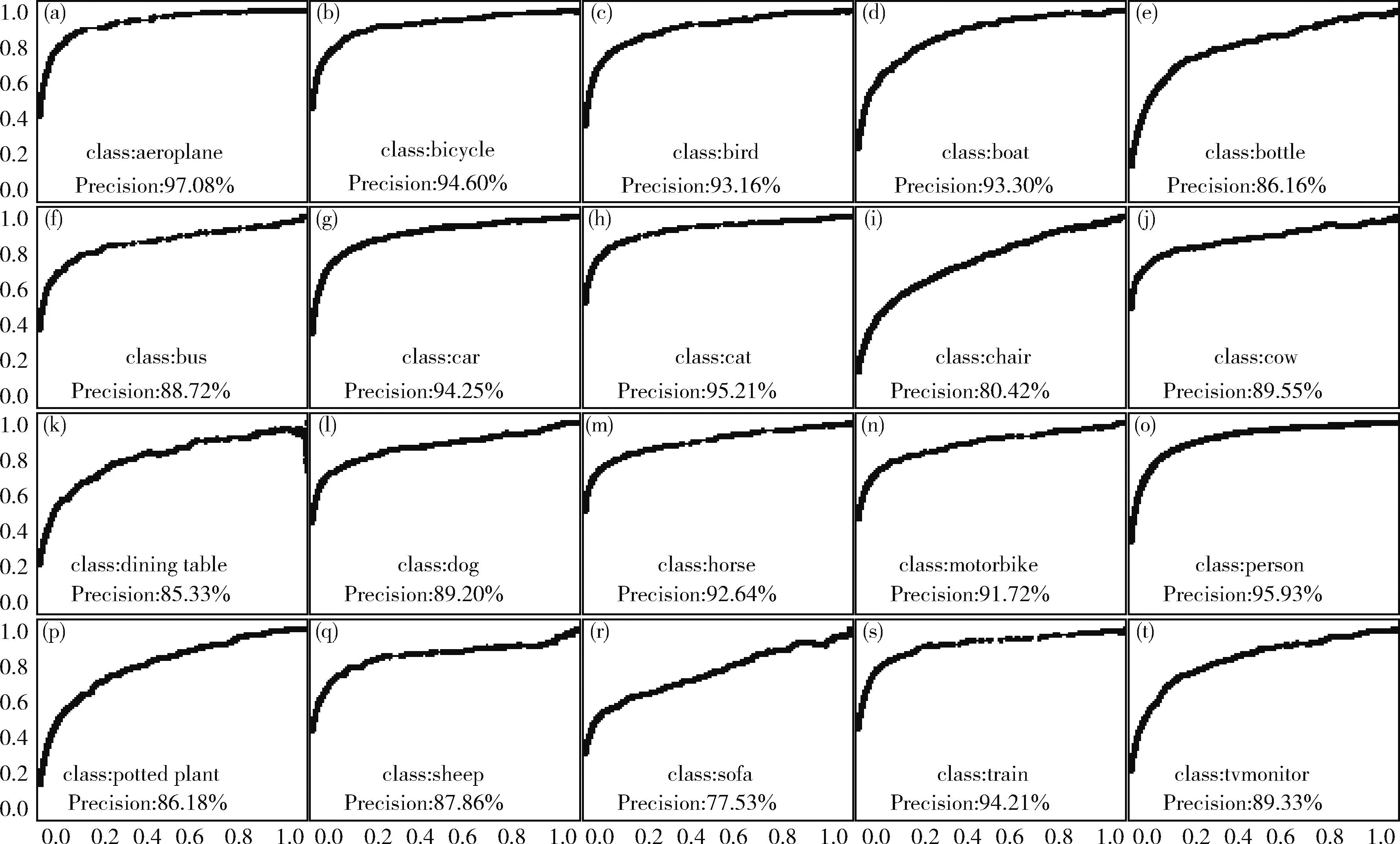
图8 20个类别的准确率(PASCAL VOC07+12)

图9 20个类别的准确率(COCO2014)
其次本文为了验证加入分组数为2的通道混洗之后可以达到与分组为4的效果且会占用较少的内存,测量了不同通道数时通道混洗操作的占用内存,结果见表6。
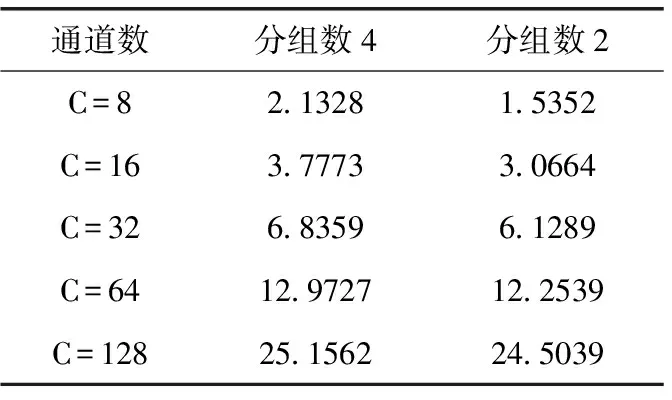
表6 不同通道数情况下占用的内存/MiB
表中分组数g=4列表示一次g=4的通道混洗操作,分组数g=2列表示两次g=2的通道混洗操作,所测数据表明在每一种通道数的情况下,将分组数g=4的通道混洗操作替换为两次g=2的通道混洗操作,使得内存占用平均下降了14%。
最后,本文向各种网络送入与图7不同的图片,这些图片拥有不同大小、不同类别的目标。各种网络的推理结果如图10所示。

图10 3种网络的推理结果
从图10检测结果中可以看出,M-YoloV3网络可以检测出来的目标较少且大多置信度不高,而加入了通道混洗操作的MSP-YoloV3网络可以检测到更多的目标,但却存在着一些识别错误或者没有检测到小尺寸目标的情况,比如(a)列第二行的图片中的左下角目标框,将motorbike标注为了bicycle,(b)列第二行的图片中将右侧汽车标注为了bus,而第三行改进了特征融合网络的MSPF-YoloV3,对不同大小,不同类别的目标检测置信度都有所提升,验证了模型推理效果的有效性与普适性。
3 结束语
本文通过采用MobileNetV2作为YoloV3网络的特征提取网络,将网络中的所有普通卷积替换为深度可分离卷积,并且在特征提取网络的Bottleneck结构中设计实现了一种低分组数、低内存占用的通道混洗结构,参数量更少,保证了网络的检测精度,最后改进PANet将位置信息更为准确的浅层特征作为“指导”与深层特征融合弥补小目标检测的劣势,得到MSPF-YoloV3网络。通过消融实验方法验证了每一步网络结构修改的有效性,通过在不同的数据集以及不同的推理图片上的实验结果验证了MSPF-YoloV3网络的鲁棒性与普适性。
本文设计实现的MSPF-YoloV3网络相比于YoloV3网络权重大小降低了约80%,mAP提升了约16%,且这种通道混洗结构设计的思路可以灵活运用增加通道间信息交流,为解决移动设备上运行目标检测网络提供了一种思路。
