渐进式逐层密集连接网络图像超分辨率重建
2024-02-22韩小伟


摘要:针对现有基于深度神经网络的图像超分辨率重建,存在未完全考虑层次特征信息的提取和利用问题,本文提出了一种渐进式逐层密集连接网络。通过设计一种逐层密集连接特征融合块,以挖掘和利用图像中不同层次的特征信息,并且利用一种渐进式特征融合机制,在全局层次上融合从逐层密集连接特征融合块中提取到的特征信息,促进图像纹理细节的重建。实验结果表明,所提方法与其他方法相比,在客观评价指标与主观视觉效果上有着更加显著的表现。
关键词:超分辨率;卷积神经网络;层次特征;逐层密集连接;渐进式特征融合
引言
单幅图像超分辨率重建(SISR)是一种图像增强技术,致力于从低分辨率图像(LR)重建出对应的高分辨率图像(HR),该技术已被广泛应用于医学成像[1]、安全监控[2]、遥感图像[3]等领域。随着深度神经网络(DCNN)的显著发展,越来越多开创性的超分辨网络被提出,并取得了卓越的成就,深度神经网络的发展主导了当前学者们对SISR的研究。
早期构建超分辨网络模型的工作主要集中构建简单模型以实现优越的性能。Dong等人[4]首次將卷积神经网络(CNN)引入SISR任务中,称为超分辨卷积神经网络(SRCNN),是一种端到端的三层CNN方案。Shi等人[5]又提出了ESPCN,其在网络末端包含一个亚像素卷积层,可以处理不同放大因子的图像超分辨率重建问题,具有较快的处理速度。虽然简单的线性模型参数量很小,但是面对纹理特征丰富的图像时,难以满足性能要求。为解决这些问题,学者们提出了许多深度更深、连接方式更加复杂的超分辨率重建模型。Simonyan等人[6]在VDSR方法中,通过拓展网络深度来提高SR性能,从3个卷积层增加到20个卷积层,此外,该网络还引入全局残差学习来提升收敛速度。Lim等人[7]堆叠出一个更深更广的残差网络称为EDSR,虽然不断增加网络深度可以提取更加丰富的局部特征,但无法有效整合这些局部特征。为了使网络能够更好地学习和保留图像的细节特征,Kim等人[8]提出在CNN模型中使用多个递归层来获得SR图像,这被称为深度递归卷积网络(DRCN)。Tong等人[9]通过SRDenseNet引入了密集块,不再线性堆叠卷积层来获取更优秀的性能,而是允许同一个密集块内的任意两个卷积层直接进行连接,有助于增强特征信息的传递和共享。
尽管上述模型在图像重建性能方面表现出色,但这些模型未充分考虑不同层次特征信息的提取及整合问题,使得模型重建性能不足。为此,本文提出了一种渐进式逐层密集连接网络,该网络充分利用分层特征信息,提高特征表达能力,增强网络的重建性能。
1. 渐进式逐层密集连接网络
1.1 网络框架概述
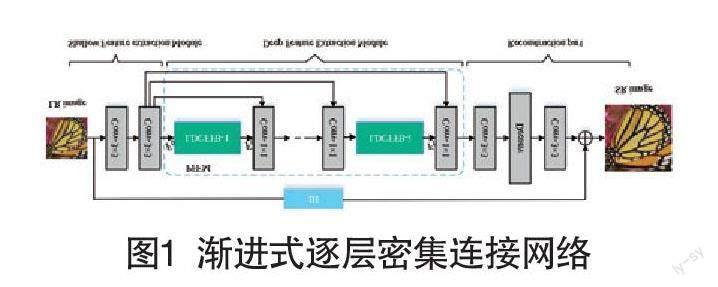
本文所提网络模型框架如图1所示。渐进式逐层密集连接网络主要包括三部分,分别为浅层特征提取模块、深层特征提取模块、重建模块。在模型中,浅层特征提取部分负责捕捉图像的初始特征,而深层特征提取部分进一步挖掘图像的高频特征。最后,重建模块将这两个阶段网络提取到的特征用于构建最终的超分辨图像。
1.2 渐进式逐层密集连接结构
在提取图像的浅层特征时,本文提出的网络采用了直接输入小尺寸低分辨率图像的策略。使用两个3×3的卷积层作为浅层特征提取模块,经过卷积操作后,浅层特征被传输到深层特征模块。则
(1)
式中,F0代表从低分辨率图像中提取到的浅层特征;HSF(.)表示浅层特征提取模块;LLR表示输入的低分辨率图像;C3×3(.)表示3×3卷积运算。
在渐进式逐层密集连接网络(progressive layer-by-layer dense connection network, PLDCN)中,深层特征提取模块主要由多个相同结构的逐层密集连接特征融合块(layer-by-layer dense connection feature fusion blocks,LDCFFB)通过渐进式特征融合机制(progressive feature fusion mechanism,PFFM)连接而成,具体来说,使用1×1卷积层逐步融合不同层次的特征信息,如图1虚线框所示。渐进式特征融合机制能够以全局方式利用不同层次的特征,从而更有效地捕捉和表达图像的边缘、纹理信息。
LDCFFB为网络的核心模块,主要包括逐层密集连接特征提取单元和特征融合单元。逐层密集连接特征提取单元结构如图2所示,这个单元由三个并行分支组成,每个分支采用相同的结构,包括三个3×3卷积层、两个1×1卷积层以及两个级联算子。这三个分支通过纵向交错连接将各个分支的路径相互连接,将前一行提取的特征作为下一行各个分支的输入,实现了特征的分层传递。特征融合单元将三个不同分支处理后的特征信息级连在一起,然后利用局部残差学习的方法将模块的输入和输出相互连接,从而促使单个模块内部的信息传递和优化。
在逐层密集连接特征提取单元提取到不同层次的特征后,通过特征融合单元来充分融合这些特征。利用残差连接获得最终的输出特征Fi为
(2)
如图1所示,重建模块包含了两个3×3普通卷积层和一个反卷积层,使用残差模块连接双三次插值后的图像并与卷积输出的结果进行叠加,获得最终的重建图像。最后一个普通卷积层则用于恢复通道数,生成RGB三通道图像。最终生成的高分辨率图像FSR为
(3)
式中,Frec为重建模块;HBI为双三次插值后的图像。
损失函数衡量了生成图像和目标高分辨率图像之间的差异,目的是使生成图像尽可能接近真实高分辨率图像。L1损失函数对误差的绝对值进行惩罚,在一定程度上能够更好地保留图像的细节和纹理,产生更接近真实感觉的高分辨率生成图像。因此所提方法使用L1损失函数,其定义如下:
(4)
式中,N为网络训练图像数量;IPLDCN为模型重建后的图像;IHR为原始真实图像。
2. 实验与分析
2.1 实验细节设置
實验系统为ubuntu20.04服务器,GPU为NVIDIA corporation GP102,使用PyCharm编译平台,利用Python语言、Pytorch框架实现了模型的构建。实验采用高质量的2K图像数据集DIV2K进行训练,该数据集有800张训练图像。在训练阶段使用水平、垂直、翻转和旋转90°等数据增强技术,随机裁剪48×48的LR小图像作为网络模型的输入,以拓展数据集的多样性和数量。在评估性能时采用了五个基准数据集,包括Set5,Set14,BSD100,Urban100和Manga109。在训练过程中设置以下参数,网络采用Adam优化器,初始学习率设置为0.0002,每经过200个epoch学习率降低一半,训练批次的大小设置为16。为了客观评价所提方法的性能,采用了图像处理领域公认具有权威性的指标:峰值信噪比(PSNR)和结构相似性(SSIM)。
2.2 实验结果对比
将本文提出的方法与经典的方法在五种基准数据集上进行定量对比,经典方法包括SRCNN、FSRCNN、VDSR、LapSRN[10]、IDN[11]、MSRN[12]。表1至表3展示了放大因子分别为×2、×3、×4时,不同方法在五种基准数据集中的PSNR和SSIM值。从表1至表3可以看出,所提算法与一些经典的算法相比,在不同放大因子上均有着良好的性能,在大多数情况下,PSNR和SSIM都明显优于其他方法。放大因子×4时,所提方法与MSRN相比,在Set5、Urban100和Manga109数据集上分别增加了0.28dB、0.29dB、0.57dB。综上,本文提出的模型相比其他方法展现出更加优秀的重建性能,尤其在放大因子较大的情况下,性能更加突出。
为了进一步证明所提方法的优越性,本文展示了图像的视觉效果对比图,如图3所示。在“86000”图像中,本文提出的方法重建出的图像线条更加清晰,而其他方法重建出的图像存在模糊和线条变形问题。以上视觉效果对比证明了提出的PLDCN模型在细节恢复和图像保真方面的表现非常优异。
结语
针对部分网络提取特征不充分、无法充分利用分层特征等问题,本文提出了一种渐进式逐层密集连接网络图像超分辨重建方法。逐层密集连接递归块为主要模块,采用对角交错连接的方式,实现特征的级联传递,引入残差连接将浅层特征与深层特征通过跨层连接的方式进行整合,既减少了浅层特征信息向更深层次传播过程中的丢失,又充分利用了各中间层次的特征。渐进式特征融合机制为主干连接方式,益于捕捉高频特征信息,为高分辨率图像的重建提供丰富的特征信息。在五种基准数据集中的实验结果证明,本文提出的网络模型与其他先进的网络模型相比具有一定的优势,并且在主观视觉效果对比上,所提方法重建后的图像更加清晰,保真度更高。
参考文献:
[1]胡芬,林洋,侯梦迪,等.基于深度学习的细胞骨架图像超分辨重建[J].光学学报,2020,40(24):54-61.
[2]Zou W W W,Yuen P C.Very low resolution face recognition problem[J].IEEE transactions on image processing:a publication of the IEEE Signal Processing Society,2011,21(1):327-340.
[3]黄硕,胡勇,顾明剑,等.基于深度学习的红外遥感目标超分辨率检测算法[J].激光与光电子学进展,2021,58(16):288-296.
[4]Dong C,Loy C C,He K,et al.Learning a deep convolutional network for image super-resolution[C]//Computer Vision-ECCV 2014:13th European Conference,Zurich,Switzerland,September 6-12,2014,Proceedings,Part IV 13.Springer International Publishing,2014:184-199.
[5]Shi W,Caballero J,Huszár F,et al.Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network[C]//Proceedings of the IEEE conference on computer vision and pattern recognition.2016:1874-1883.
[6]Simonyan K,Zisserman A.Very deep convolutional networks for large-scale image recognition[J].arXiv preprint arXiv:2014(1):1409.1556.
[7]Lim B,Son S,Kim H,et al.Enhanced deep residual networks for single image super-resolution[C]//Proceedings of the IEEE conference on computer vision and pattern recognition workshops.2017:136-144.
[8]Kim J,Lee J K,Lee K M.Deeply-recursive convolutional network for image super-resolution[C]//Proceedings of the IEEE conference on computer vision and pattern recognition.2016:1637-1645.
[9]Tong T,Li G,Liu X,et al.Image super-resolution using dense skip connections[C]//Proceedings of the IEEE international conference on computer vision.2017:4799-4807.
[10]Lai W S,Huang J B,Ahuja N,et al.Deep laplacian pyramid networks for fast and accurate super-resolution[C]//Proceedings of the IEEE conference on computer vision and pattern recognition.2017:624-632.
[11]Hui Z,Wang X,Gao X.Fast and accurate single image super-resolution via information distillation network[C]//Proceedings of the IEEE conference on computer vision and pattern recognition.2018:723-731.
[12]Li J,Fang F,Mei K,et al.Multi-scale residual network for image super-resolution[C]//Proceedings of the European conference on computer vision(ECCV).2018:517-532.
作者簡介:韩小伟,硕士研究生,研究方向:图像超分辨。
