基于残差网络和注意力机制的恩施玉露茶品级分类
2024-02-21毛腾跃欧阳德维
毛腾跃,欧阳德维
(1.中南民族大学 计算机科学学院,湖北 武汉 430074;2.湖北省制造企业智能管理工程技术研究中心,湖北 武汉 430074)
恩施玉露是湖北省著名的茶叶品牌,深得人们的喜欢,且不同品质的茶叶价格也有极大的不同[1]。目前,对于茶叶品质高低的判别,国家制定了《GB/T 23776-2018 茶叶感官审评方法》,主要是对茶叶的外形、汤色、香气、味道等方面进行判定。根据审评标准,茶叶的外形特征是分级检测的重要参考方向之一。茶叶的外形评定包含了茶叶的条索、色泽、净度以及嫩度等方面的评定,其中嫩度是从白毫多少来鉴别,条索的好坏主要从茶叶的松紧、整碎、曲直来判断,色泽主要从茶叶的颜色和光泽上来判断,净度则主要观察茶叶中是否混有茶梗等杂物。现阶段对于茶叶品质评审方法主要有感官评审、成分检测和新兴技术[2-3]。而对于购买茶叶时的品级判断,个人感官判断是最为普遍的感官检测方法,但是这种方式主观性较强,对人们评茶经验要求高。因此基于新兴技术提出一种准确、快速、低成本的恩施玉露茶品级分类方法很重要。
随着计算机视觉技术的发展,对物体分类研究也取得了一定的进步[4-7]。传统机器学习需要手动地提取特征,并利用这些特征信息来进行图片分类。目前,国内外利用计算机视觉结合传统机器学习对茶叶的分类研究较多,也取得了较好的效果。成都大学周敬结合计算机视觉技术提出了一种结合茶叶颜色、形状以及杂质的相关特征提取算法,运用K均值聚类算法,准确率达到92.5%[8]。余洪建立了基于PCA-GA-BP神经网络和PCA-PSO-LSSVM支持向量机的计算机视觉茶叶品质分级模型,对碧螺春和婺源绿茶品质进行分类准确率分别达到92%和91.5%[9]。刘鹏采用中值滤波和拉普拉斯算子对茶叶图像进行预处理,提取茶叶的颜色特征和纹理特征,使用监督正交局部保持投影(SOLPP)的降维方法,用不同神经网络作为分类模型,准确率达到93.75%[10]。
目前利用卷积神经网络对茶叶品级进行分类的研究应用较少,但已在农业领域中有了较多应用。例如张怡提出基于ResNet卷积神经网络的绿茶种类识别模型,通过结合ResNet-18结构与SGD优化算法,建立了一个新的模型,能对复杂背景下的茶叶图片进行分类,准确率达到90.99%[11]。韩旭,赵春江提出了一种基于注意力机制及多尺度特征融合的分类方法,在DenseNet的基础上引入了注意力机制及多尺度特征融合结构,选择性的强调信息特征并对特征进行精准定位,对番茄叶片缺素的平均识别准确率可达95.92%[12]。陈思伟和戴丹在ResNet152V2的基础上引入迁移学习和注意力机制,将对核桃果仁等级分类的准确率提升了2.04%[13]。
以上研究表明,目前关于成品茶叶的分类研究较多且分类效果较好,但大多数都是采用的传统机器学习的算法进行分类,分类速度较慢,并不是十分适用于恩施玉露品级评定场景。本文通过对主流的图像分类模型ResNet进行分析研究,首先在残差模块里面添加注意力模块,让图像的特征表达更鲜明[14-16],然后在最后两个残差模块里面引入深度可分离卷积代替常规卷积,降低模型的参数量,防止网络过拟合。通过引入注意力机制与深度可分离卷积相结合的方式,设计出一个适用于恩施玉露茶品级分类的网络模型,避免消费者在选购恩施玉露时对品质分级存疑的问题。
一、ResNet与CBAM
1.ResNet
深度残差网络是目前应用在图像分类领域中最为主流的一种CNN网络模型。CNN网络中,更深层次的网络模型具有更高的特征提取能力,而网络层次过深则会带来梯度爆炸和梯度消散问题。ResNet通过在网络结构中加入残差模块,让网络学习恒等映射,一定程度上抑制了这些退化问题,它使得网络模型不仅具备了较深的网络层数,也让其有了更高的精确度[17-18]。如表1所示,ResNet网络有ResNet18、ResNet34、ResNet50、ResNet101、ResNet152多种不同的层数。ResNet18是ResNet系列网络中层数最少的网络,它相比于其他网络不仅模型较小、对于单张图片的识别较快,而且准确率也有一定保证。故选择ResNet18作为基础的网络模型。
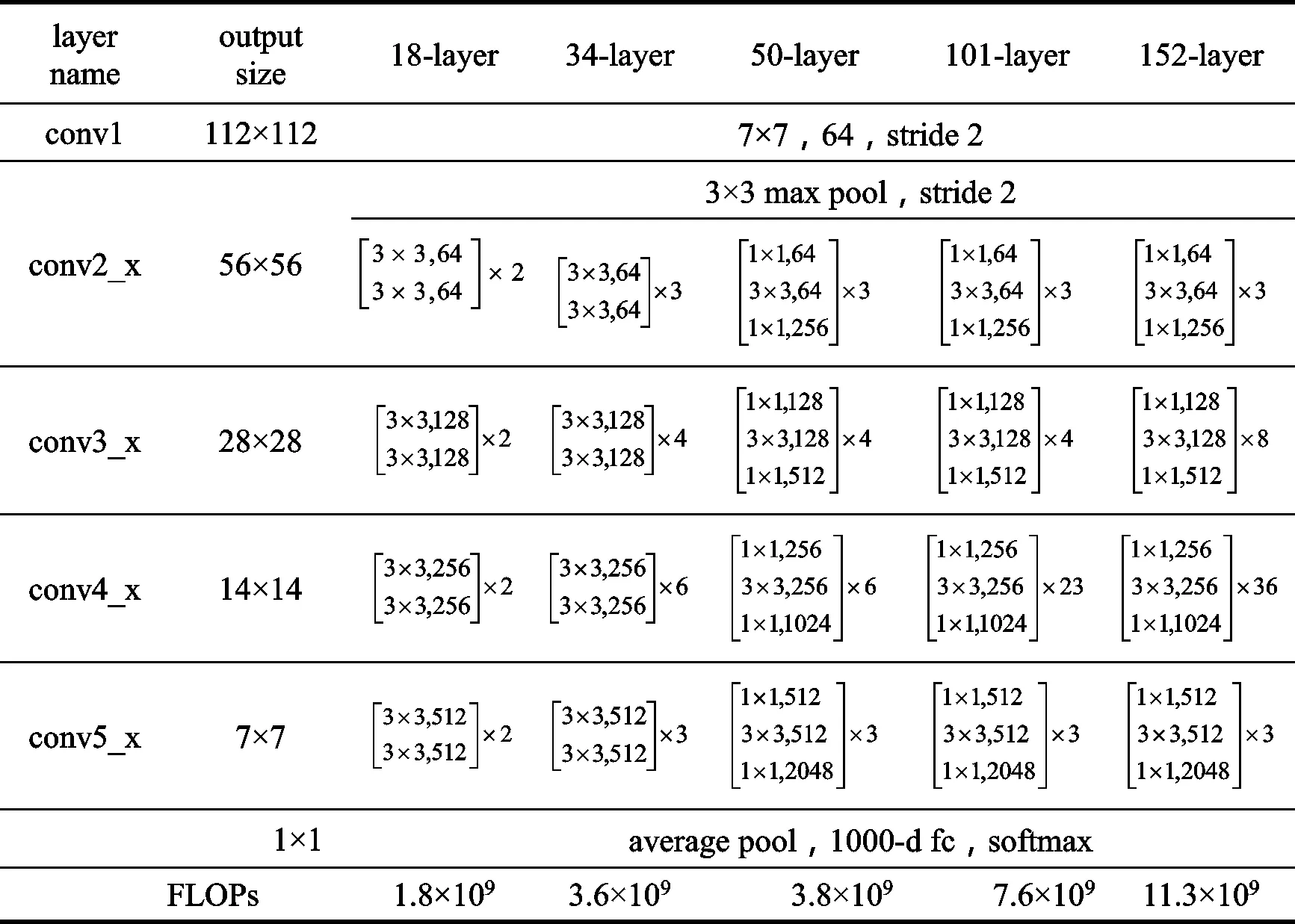
表1 ResNet结构
2.CBAM
注意机制是人们在机器学习里面嵌入的一种特殊结构,能自适应的学习和计算出输入数据对输出数据影响的权重大小。CBAM体积较小,相比于其他注意力机制模块节省了参数量和计算资源,而且能够很方便的插入到各式各样的网络中去[19]。CBAM结构如图1所示。CBAM由通道注意力和空间注意力并行组成,通道注意力模块主要关注输入特征中有意义的特征信息, 让网络先在通道的维度上自适应学习出特征在通道上的权重系数M,将通道权重系数乘以输入特征,就可得到加权后的新特征。空间注意力模块关注的是目标的位置信息,让网络在空间的维度上自适应的学习出特征在空间上的权重系数K,将经过通道注意力加权后的特征乘以空间权重系数,即可得到最终输出特征。
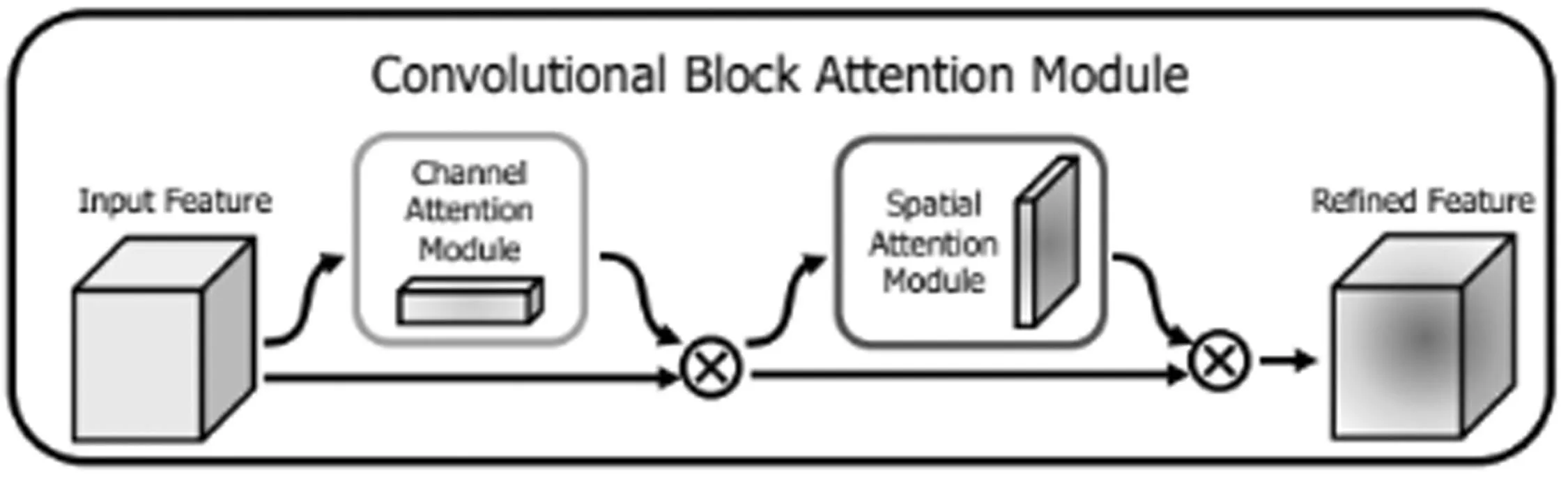
图1 CBAM注意力机制模块
3.深度可分离卷积
深度可分离卷积常用于一些轻量级的网络模型中,如MobileNet和Xception结构,它能够有效减少网络模型的大小,防止网络过拟合,加快网络模型的处理速度[20-21]。如图2所示,深度可分离卷积由深
度卷积和逐点卷积构成,相比于普通卷积,深度可分离卷积能够有效减少模型参数量,降低运算成本。如图a所示深度卷积采用与输入特征图通道数相同的卷积核数量,且卷积核的通道数为1,这样可以对输入特征图的每个通道做单独的卷积运算,分割输入特征图在不同通道间的联系。如图b所示,逐点卷积采用大小为11的卷积核,能将新生成的特征矩阵做一个深度方向的加权操作,这样生成的特征图大小,与经过常规卷积后的特征图大小相一致 。
二、改进的ResNet18网络
1.增加注意力机制
自然拍摄的恩施玉露茶图片往往会带有无关背景,且背景信息复杂多变,这给图片在ResNet18网络中进行分类时带来了困难。在ResNet18网络中,图像经过第一层卷积层进行特征提取后,就会进入残差结构,残差结构使得较低维的特征也能在较高维度得以使用,减少了图像在传播过程的特征损失。 因此本文结合注意力机制的特点,在ResNet18的残差模块中加入CBAM注意力模块,这种方式可以在一定程度上抑制较低维度的无关背景特征,增强低维度里面的相关茶叶特征,也能让茶叶信息特征可以通过残差结构传递到更高维度,让其得以重复利用。通过这种在残差网络中添加CBAM注意力机制的方式,能够加强ResNet18网络在各种各样的复杂背景中获取更多的茶叶信息的能力,让其忽视与之无关的背景信息,提高模型的分类的准确率。CBAM的计算公式为:
F'=Mc(F)*F
(1)
F"=Ms(F')*F'
(2)
其中F代表输入特征图,F'代表经过通道优化后的特征图,F"代表经过通道和空间优化后的特征图,Mc表示通道注意力模块一维卷积,Ms表示空间注意力模块二维卷积,*表示逐个像素相乘。
改进后的残差网络结构如图3所示,将CBAM模块添加残差模块的尾端。通过前面的卷积操作能提取到更多的信息特征,将提取到的特征图放入CBAM中,让网络自适应的获取和恩施玉露茶相关的通道信息和空间信息。将输出的加权特征信息矩阵与输入特征信息矩阵相加以此来降低卷积过程中损失的相关特征信息,最后再将相加的特征图经过一次Relu非线性激活后得到最终输出结果。基于通道和空间注意力机制的残差模块中的计算公式为:
XL+1=f(XL+H(F(XL,WL),ML))
(3)
其中XL+1和XL分别代表着第L个残差单元的输出与输入,F是残差函数,表示学习到的残差,f是Relu激活函数,W代表了残差模块里面的卷积操作,H为CBAM注意力函数,M代表CBAM模块里面的卷积与池化操作。
2.深度可分离卷积替换常规卷积
在网络模型的标准卷积层中,数量较多的单一卷积核能提取到更复杂的信息特性,但也意味着更多的参数量。通过使用深度卷积和逐点卷积组合的方式来代替标准卷积已经在不少网络模型中得到了应用,深度可分离卷积在牺牲极小准确率的基础上,能极大程度降低模型的参数量和计算量,这为网络模型应用到移动端提供了可靠依据。因此我们可以将残差模块中的第二层标准卷积替换为深度可分离卷积,这样不仅能保证第一层标准卷积能提取到更多的原始特征信息,而且还可以极大程度的降低残差模块的参数量。引入深度可分离卷积后的残差结构如图4所示。其中常规卷积与深度可分离卷积的参数量计算公式分别为公式4和公式5:
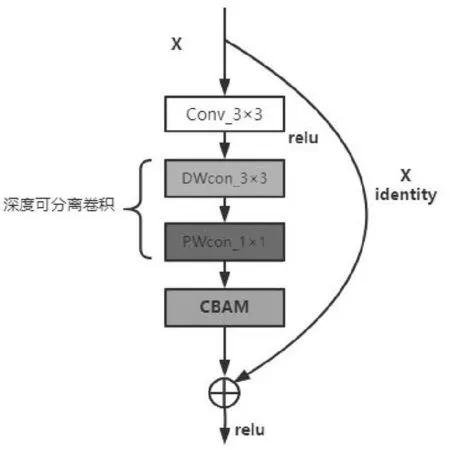
图4 基于深度可分离卷积和CBAM注意力机制的残差模块
params1=C0×(Kw×Kh×Ci)
(4)
params2=(Kw×Kh×1)×Ci+(1×1×Ci)×C0
(5)
在卷积层的参数计算量公式中,其中C0表示输出通道数,Ci表示输入通道数,Kw表示卷积核的宽,Kh表示卷积核高。
从公式5中可以发现,深度可分离卷积的参数量仅为标准卷积的参数量的1/C0+1/Kw×1/Kh,参数量做到了极大的减少。在ResNet18网络中,每个残差模块中的卷积核大小都相同,卷积核宽Kw和卷积核高均为3,所以逐点卷积的参数量均为标准卷积的1/9。但输出通道数C0会随着成残差模块所在的位置而成倍增加, 从第一个残差模块到最后一个残差模块,经过标准卷积所输出的通道数分别为64、128、256、512,使用深度卷积替换标准卷积,能将参数量分别降至为原始的1/64、1/128、1/256、1/512。从中可以发现,替换较高维度残差模块中的标准卷积层,所减少的参数量也就越多,模型大小也就减少的越明显。但替换标准卷积数量过多也会造成训练参数减少,带来精度损失的问题。在前面两个残差结构中,由公式4可知,因为输出通道数Ci和输出通道数C0较少,故残差模块所占内存也较小,使用深度可分离卷积替换,会造成低维特性信息的损失,且内存减少不显著。 替换最后两个残差模块中的标准卷积,这种方式既能保留低维的特征信息,也能减少高维空间中多余的训练参数,避免模型过拟合,且最后两个残差模块内存较大,内存大小减少显著。
三、实验
1.实验总体流程
本实验总共分为四个步骤,整体实验流程如图5所示。第一步先对数据集进行格式化处理,再在原始数据集的基础上进行图像裁剪、翻转以及加入不同噪声的方式对数据集进行扩充,提高数据的泛化性,避免数据集太少而带来的过拟合问题。第二步先对数据集进行预处理,将其缩放成224×224格式,然后选用不同网络模型进行消融实验,选取模型准确率以及模型大小最为合适的网络作为基础网络模型,经实验结果得出ResNet18为最优模型。第三步为提高模型准确率,分别在网络中引入不同的注意力模块进行消融实验,判断哪种注意力模块能对网络产生较好的影响。最后为方便将模型应用到移动端,也为避免模型训练参数过多而带来的过拟合问题,采用深度可分离卷积对模型进行轻量化处理。为验证添加位置的合理性,分别在网络中的不同位置添加深度可分离卷积进行消融实验,实验得出替换最后两个残差模块中的传统卷积效果最佳。

图5 实验整体流程图
2.数据集
本研究中,实验采用自建数据集训练与预测,茶叶由来自于湖北省恩施市鹤峰县上的茶厂所提供,且茶叶经过专业评鉴师评鉴且标注过,茶叶分为四类不同的品质,共有12 421张。如图6所示,其中特级品质茶叶图片共3 236张、高级品质茶叶图片共3 150张,中等品质茶叶图片共3 283张、低等品质茶叶2 752共张。对所收集的图片数据进行随机裁剪,随件翻转以及添加高斯噪声和椒盐噪声4种图像增广操作后,如图7所示,共得到张58 395茶叶图片。对增广后的图片按照8∶2比例将数据集分为训练集与验证集。

图6 恩施玉露茶样本

图7 图像增广操作
3.实验环境与模型训练
本实验基于windows平台通过python语言实现,操作系统选择的是windows11,硬件配置中CPU为12th Generation Intel®CoreTMi5-12400F@4.4GHz,显卡为NVIDIA GeForce RTX 3060,学习框架选用pytroch。
模型训练时,选取47 806张图片作为训练集,11 634张图片作为测试集,对模型输入的图片大小设置为224×224,批处理的图片数量设置为32,损失函数选择的是交叉熵损失函数,优化器为Adam优化器,学习率的初始值设置为0.000 1。
在模型训练过程中,loss可以用来衡量模型的预测值与真实值的不一致的程度,loss越小,模型的鲁棒性就越好。在模型训练过程中,损失函数曲线如图8所示,从图中可以观察到,在前10个epoch时,loss下降的比较快,在训练了30个epoch后,loss下降比较慢,训练了40个epoch时,loss已经趋于平稳,模型已经到达收敛。
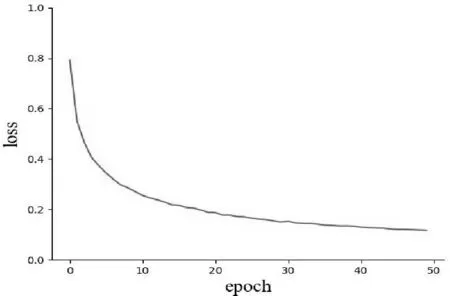
图8 损失函数曲线
4.评价指标
本研究通过准确率、模型大小这两个方面的均衡性来衡量模型的性能。准确率是图片分类中最常用的度量单位,用于评价模型分类效果的好坏。考虑到未来在移动端使用,模型大小也是一个重要的评价指标,模型越小识别图片的速度也就越快。因此需要在保证模型准确率的情况下,减小模型的内存占用空间。准确率计算公式为:
(6)
其中TP表示将正样本成功预测为正;TN表示将负样本成功预测为负;N表示预测样本总数。
5.试验分析
(1)不同分类模型的分类性能对比
为了验证选取分类模型的合理性,故设计了消融实验。通过对比VGG16、GoogleNet、ResNet18、ResNet34、ResNet50、ResNet101这些主流的分类网络模型对恩施玉露茶的分类准确率、模型内存占用空间这两方面进行评估。从图9中可以看出,在epoch次数相同的情况下,在准确率方面, ResNet系列网络都对恩施玉露茶有较好的分类效果。在模型内存占用空间方面,从表2中可以看出,ResNet18和GoogLeNet在分类网络中所占内存最少。而其他ResNet网络模型随着网络层数的增加,对图片的分类准确率几乎保持不变,且都占用了较大的内存,并不能很好地满足在移动端使用的场景,因此在确保准确率的情况下最后选择ResNet18作为基础的分类模型,ResNet18的内存大小仅为42.72MB,为VGG16大小的8.34%,RestNet50的47.46%,ResNet101的26.25%。其中ResNet18分类结果的混淆矩阵如图10所示。
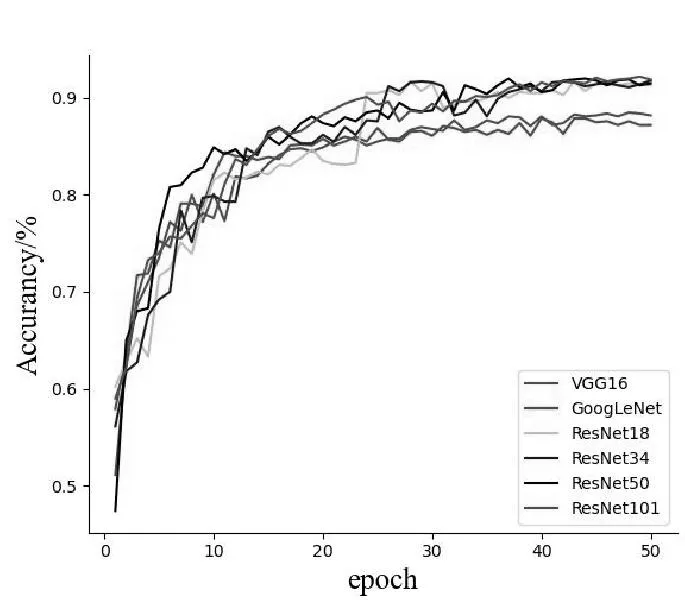
图9 不同网络模型分类结果
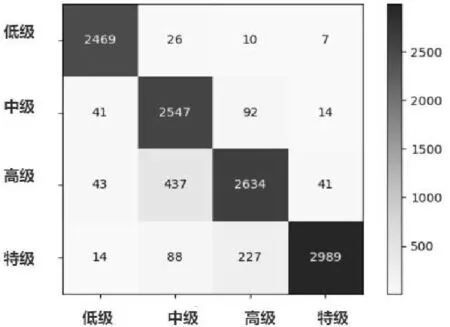
图10 ResNet18分类结果混淆矩阵
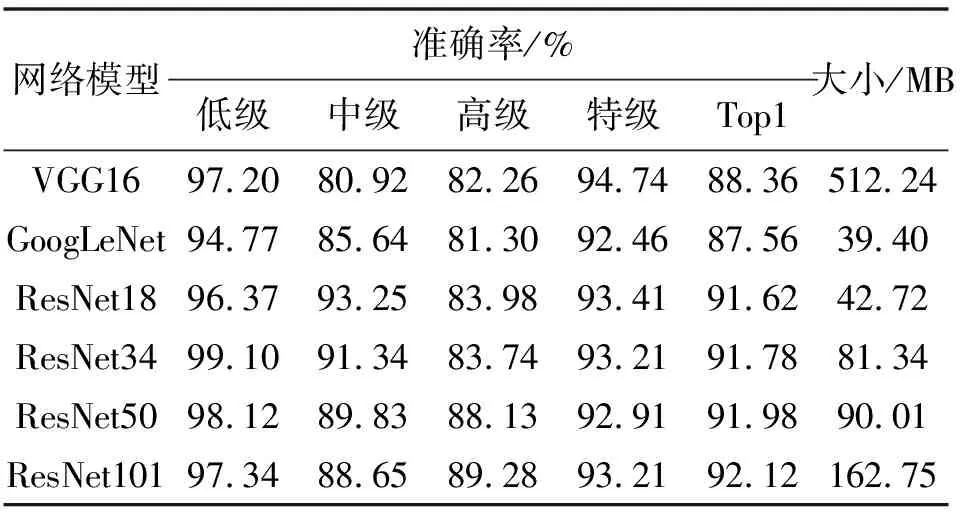
表2 不同网络模型的识别效率和大小
(2)不同注意力方法对比
为了验证选取的注意力机制的合理性,分别选用了4种注意力机制来进行消融实验,将不同注意力模块分别加在残差模块的后面,通过增强和抑制部分特征信息,让其侧重关注于提取后的相关茶叶信息。其中实验Ⅰ添加的是SE注意力机制模块,让网络模型在通道上投入更多的注意力,实验Ⅱ添加的是CA注意力机制模块,CA模块通过将位置信息嵌入到通道注意力里面,加强了网络模型在通道上提取关键特征信息的能力,实验Ⅲ添加的是CBAM注意力机制模块,通过让网络先后通过通道和空间注意力模块,让网络在空间和通道这两个维度对投入更多的注意力以进行特征自适应优化,实验Ⅳ添加的是SimAM注意力机制模块,通过从当前的神经元中推断出空间维度和通道维度,然后以反向优化神经元的方式来优化网络。通过表3可知,不同的注意力模块对ResNe18网络有着不同的影响,其中ResNet18+SE提升了1.18%,ResNet18+CA提升了0.35%,ResNet18+CBAM提升了3.90%,而ResNet18+SimAM却下降了0.21%。
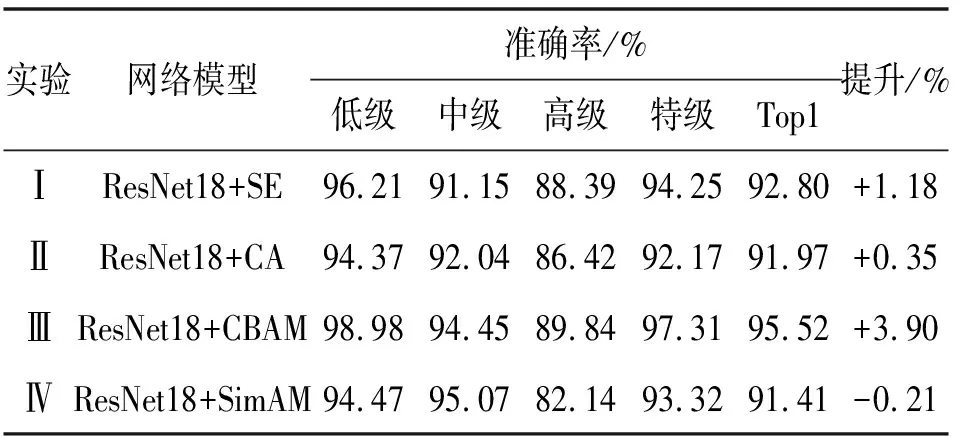
表3 不同注意力的准确率和提升大小
这表明CBAM模块对ResNet18网络有较好的优化性,CBAM对要关注的茶叶信息会分配较高的权重,对一些无关的背景信息则分配较低的权重,从而让网络模型能够将注意力集中在需要重点关注的茶叶信息区域,从而提升了分类的准确率。其中ResNet18+CBAM的分类结果混淆矩阵如图11所示。

图11 ResNet18+CBAM分类结果混淆矩阵
(3)深度可分离卷积添加位置对比
对于残差网络随着网络层数的加深,网络能提取到更多的特征信息,但也需要更多的参数,这容易导致过拟合问题。通过使用深度可分离卷积替换标准卷积,可以有效降低模型参数,防止模型过拟合。但使用深度可分离卷积替换标准卷积过多,也会降低模型提取信息特征的能力,导致模型准确率下降。为验证添加深度可分离卷积位置的合理性,分别替换不同位置残差结构中的标准卷积来进行消融实验,其中实验Ⅰ为替换最后一个残差结构中的标准卷积,实验Ⅱ为替换最后两个残差结构中的标准卷积,实验Ⅲ为替换最后3个残差结构中的标准卷积,实验Ⅳ为全部替换残差结构中的标准卷积。从表4的实验结果中可以发现,替换越高维度的标准卷积,减少的模型参数效果也就越明显,替换过多也会造成模型精度损失过大。实验Ⅰ中替换第四层残差结构中的标准卷积,准确率虽然降低不多,但模型仍有过拟合问题。实验Ⅳ中替换所有残差结构中的标准卷积,尽管模型大小显著降低,但准确率却损失过多。实验Ⅲ通过替换后面两个残差结构的标准卷积,让网络在较低维度提取到更多的信息特征,也降低了网络的过拟合,这种方式不仅减小了模型的大小,且准确率仍得到了保留。故最终选择实验2中的网络模型ResNet18+CBAM_DW作为最终的网络模型。

表4 深度可分离卷积不同添加位置的准确率和模型大小
四、结论
本文以四种不同等级的恩施玉露茶图片作为实验样本,对其进行图像裁剪、图像翻转、添加噪声等图像增强操作来实现数据集扩充。在ResNet18的基础上,提出了一种基于空间和通道注意力机制结合深度可分离卷积的茶叶分类网络,并对不同的分类方法、不同的注意力机制以及嵌入不同位置深度可分离卷积的有效性进行了验证。首先通过实验对比出不同分类网络对恩施玉露茶的分类效率,得出Resnet18不仅在内存方面占用较小仅为42.72MB,且分类准确率也较高,达91.62%。通过在ResNet18的残差模块里面加入空间和通道注意力机制让网络能够自适应的关注茶叶的有效特征信息,提高模型准确率。为避免模型的过拟合,减少模型参数,在最后两个残差模块里面引入深度可分离卷积,降低模型内存大小。实验结果表明,本文选用的方法能有效提高ResNet18网络对于恩施玉露茶的品质分类性能,最高准确率可以达到95.48%,能有效解决现实生活中消费者对于复杂背景下的恩施玉露茶品质分级的存疑的问题。
