MOOCDR-VSI:一种融合视频字幕信息的MOOC 资源动态推荐模型
2024-02-20吴水秀罗贤增钟茂生吴如萍
吴水秀 罗贤增 钟茂生,2 吴如萍 罗 玮
1 (江西师范大学计算机信息工程学院 南昌 330022)
2 (江西师范大学江西教育数字化转型研究中心 南昌 330022)
(wushuixiu@jxnu.edu.cn)
中国的教育已步入新时代,为了更好地落实科教兴国、人才强国战略,国家对教育现代化[1]和信息化[2]均提出了新要求、新使命. 同时,普通民众对知识更新的需求不断增高,以固定时间、确定地点进行的线下课堂教学活动,已经难以满足知识日益更新、终生学习的新形势和新需求. 在知识快速更新的新形势和终身自主学习的新需求推动下,各种大规模开放式在线课程(massive open online courses,MOOC)学习平台如雨后春笋般地发展起来,如edX、Coursera、MIT Open Courseware、Stanford Online、ITS、腾讯课堂、百度传课、智学网和淘宝教育等. 在线学习(elearning)、开放学习(open-learning)为实现“人人皆学、处处能学、时时可学”和“终身学习”,为教育优质均衡发展和实现教育公平提供了技术上的保证;对于构建学习型社会,促进人的素质的全面提高,也具有重要的意义.
MOOC 平台汇聚了海量的优质教学资源,这些种类繁多、琳琅满目的资源为广大学习者实现自主学习的同时,也造成了“信息过载”和“信息迷航”等问题. 一项对在线学习用户的研究表明,以不适当的课程视频向用户提供学习内容会降低他们的参与度[3].随着个性化学习需求的不断增加,基于学习者的知识偏好和学习需求向用户推荐符合他们的兴趣和认知水平的教学资源变得越来越重要.
推荐技术旨在解决“信息过载”问题,使用户从浩如烟海的信息中快速定位到自己感兴趣的内容,已经广泛应用于许多领域,如产品推荐、新闻推荐、亚马逊图书推荐和Netflix 电影推荐[4-5]. 受这些领域成功案例的启发,有研究者将推荐技术引入MOOC推荐中,用以解决学习资源与学习者兴趣和需求不匹配等问题,并取得一定进展. 然而,目前的推荐方法在建模学习者学习偏好和预测学习者需求时仍然存在3 点不足:
1) 无法深度挖掘课程内容的隐含信息. MOOC大多以视频为载体向学习者传递知识,而视频包含了丰富的信息,如语音、字幕等,通过挖掘课程视频信息能够进一步过滤与学习者需求不符的课程资源.例如,有的教师讲授数据结构课程时采用C 语言,而有的教师可能采用C++或者Java 语言,这些潜在信息对于精确表示课程特征、提高推荐质量具有辅助意义.
2) 容易形成“蚕茧效应”. 推荐的课程若不能在学习者兴趣的基础上适度延伸、拓展,就不可避免地产生“蚕茧效应”,造成学习者视野日益狭窄、丧失学习兴致,而要打破这种“蚕房”的桎梏,就要求模型能够挖掘课程内容的个性和共性特征,增加推荐的多样性. 例如,学习者在学习“操作系统”课程的“哲学家进餐问题”时,模型能够给出“信号量机制”“银行家算法”等相关的延伸知识的推荐.
3) 难以捕获学习者动态变化的学习需求和兴趣. 随着学习者对知识的不断内化和迁移,其需求和兴趣可能会随之变化,如何动态追踪学习者不断变化的学习需求和兴趣也是亟待解决的关键问题.
针对这3 点不足,本文提出了一种融合视频字幕信息的MOOC 资源动态推荐模型(MOOC resource dynamic recommendation model fusing video subtitle information, MOOCDR-VSI). 视频的字幕文本是向学习者传递信息的重要载体,通过提取字幕的语义特征能够从自然语言处理的角度理解视频内容,进而深度挖掘课程内容的隐含信息. MOOCDR-VSI 的思想类似于观看外文电影时,双语字幕能够帮助观看者理解视频内容. 另一方面,通过引入课程内容的语义关联挖掘视频内容的个性和共性特征,增加推荐的多样性,能够适度地扩充学习者的视野和兴趣.MOOCDR-VSI 首先探索学习者的学习记录和相应的课程内容,学习记录中的观看完成率是刻画学习者对当前学习内容是否感兴趣的重要特征. 对于课程内容,MOOCDR-VSI 首先采用BERT(bidirectional encoder representations from transformers)[6]编码器和多头注意力机制获取每个视频字幕的语义信息和挖掘视频内容的个性特征. 然后,MOOCDR-VSI 采用一种基于LSTM(long short-term memory)[7]的网络结构动态建模学习者的兴趣状态. 接着通过引入注意力机制关注不同课程的共性特征. 最后,结合学习者当前的兴趣状态和课程内容的特征生成推荐列表. 总的来说,本文的主要贡献包括4 个方面:
1) 通过BERT 编码器获取MOOC 视频字幕的文本表示,并采用多头注意力从不同的语义空间捕获局部特征间的依赖关系,深度挖掘了课程内容之间的个性信息和共性信息;
2) 通过外部矩阵建模了不同MOOC 与各个知识点的关联性,学习者每一次完成MOOC 学习后,采用一种基于LSTM 的网络架构更新学习者对每一个知识的偏好状态,从而动态获取学习者的知识偏好状态;
3) 引入注意力机制捕获MOOC 视频之间的相关性,结合学习者当前的知识偏好状态推荐出TopN个学习者可能感兴趣的MOOC 视频;
4) 构建了融合字幕信息的MOOC 推荐模型MOOCDR-VSI,在真实学习场景下收集的MOOCCube 数据集上的实验验证了该模型的有效性.
1 相关工作
传统的课程推荐算法包括协同过滤推荐算法[8-10]、基于内容的推荐算法[11]和混合的推荐算法[12-14]. 其中,协同过滤推荐算法主要依赖用户对课程的反馈(包括评价、打分),而较少地考虑用户和课程的内容信息,当用户对课程的交互信息较少时,容易产生冷启动问题. 有研究者通过引入学习行为[15]、社交网络[16]、用户属性[17]和上下文[18]等辅助信息减少用户对课程交互信息的依赖,缓解了由交互数据稀疏带来的冷启动问题. 基于内容的推荐算法主要依赖挖掘课程之间的相似度,为用户推荐与过去学习相似的课程,但项目的内容信息往往同时包含结构数据和非结构数据,因此这种算法高度依赖特征工程. 为了满足个性化学习的需求,混合推荐算法成为解决复杂场景的主流算法,如Chen 等人[19]提出了一种基于内容的协同过滤方法来获得与内容相关的课程集,然后根据学习者学习序列,使用顺序模式挖掘算法,对课程集进行筛选.Li 等人[20]通过融合用户兴趣模型和教学资源模型构建了个性化网络教学资源系统,改进的混合推荐算法在个性化课程推荐系统中具有更好的性能,但这些方法大都将用户偏好视为静止状态,即无法动态监控用户每一次交互后的兴趣变化,因此依然存在一定局限性.
近年来,深度学习因其具有强大的特征提取能力受到研究者们的关注,受其在语音分析[21]和文本处理[22]等领域成功的启发,有研究者将深度学习引入课程推荐系统.Zhao 等人[23]提出了一种全路径学习的推荐模型,该模型首先对学习者集合进行聚类,接着训练LSTM 来预测学习者的学习路径和学习成绩,最后根据学习路径预测的结果推荐个性化学习的完整路径. Li 等人[24]提出了一种基于互信息的特征选择(mutual information feature selection,MIFs)模型和学习者学习资源二部图关联模型,利用深度神经网络挖掘学习者的个性化偏好基础,进而为学习者推荐资源.Fan 等人[25]通过构建了一个多注意力(学习记录注意力、课程描述注意力等)网络模型探索多个非结构化信息,为分析学生的学习行为和进行个性化的MOOC 推荐提供了一种可解释的策略.Wang等人[26]提出了一种基于图神经网络的TopN个性化课程推荐方法,并探索了2 种不同的聚合函数来处理学习者的序列邻居. 在考虑课程内容的工作中,Xu等人[27]提出一个融入课程名称、课程评价等信息的多模态课程特征提取的推荐框架. 考虑到课程推荐存在丰富的实体关系,Gong 等人[28]通过构建异构信息网络(heterogeneous information network,HIN)[29]捕获多种实体,如课程、视频、教师之间的关系并将其纳入学习过程. 这些方法相较传统的协同过滤方法能够获得较好的推荐效果,但由于其无法深入挖掘课程内容的隐含信息,可能导致推荐的结果存在“蚕茧效应”,即无法在学习者兴趣的基础上进行扩展及延伸式的推荐. 另一方面,这些方法大多将学习者兴趣和需求视为静止状态,不符合学习者的兴趣随学习时间变化的过程,因此,这些方法依然存在一定的局限性.
2 问题描述与研究思路
2.1 问题描述
课程视频推荐可以形式化为一个有监督的序列预测问题,假设在一个学习系统中存在一个学习者S和一组课程视频E,学习者S1的学习序列表示为其中元组表示该学生在时刻t的学习交互,titlet和captiont分别表示学习者时刻t学习的MOOC视频的标题和字幕文本,和分别表示观看视频的开始时间和结束时间,dt表示该课程视频时长. 通过预设的模型捕捉每个时刻学习者的学习兴趣和需求,并预测该学习者在时刻t+1 可能感兴趣的N个MOOC 视频.
2.2 研究思路
针对传统MOOC 推荐模型存在的无法深入挖掘课程视频内容信息、推荐结果扩展性较差以及无法捕捉学习者动态变化的学习兴趣和需求等问题,本文按照以下研究思路进行学习者兴趣动态建模和MOOC 推荐:
首先,本文将BERT 作为视频标题和字幕文本的编码器,考虑到BERT 模型采用双向的Transformer结构[30],因此它能够较好地捕获前后文的语义信息.接着采用多头注意力机制从不同语义空间捕获局部特征间的依赖关系,进一步挖掘课程视频的个性特征和共性特征,以此获得较好的扩展性推荐结果. 对于建模学习者的学习兴趣变化过程,本文采用LSTM获取每一时刻学习者的知识偏好状态,由于课程视频的完成率能够从侧面反映学习者对当前视频感兴趣的程度,因此学习者每一时刻的知识偏好状态由当前视频的知识点和完成率共同决定. 同时,课程的知识点并不孤立而是彼此关联,因此在这个过程中引入了课程视频知识点的关联性以刻画学习者完成当前视频学习后对潜在知识点偏好的影响. 最后通过注意力机制获取已学习MOOC 和未学习MOOC间的关联,并结合当前时刻学习者的知识偏好状态召回TopN个学习者可能感兴趣的MOOC 视频.
3 MOOCDR-VSI 模型
本节给出了MOOCDR-VSI 的总体框架和各个模块的实现过程,包括MOOC 的文本(标题文本、字幕文本)特征提取、学习者知识偏好动态建模、MOOC推荐等模块以及模型的训练方法.
3.1 模型总体框架
本文提出的MOOCDR-VSI 架构如图1 所示,主要分为3 个模块:MOOC 文本特征提取、学习者知识偏好动态建模、MOOC 推荐.
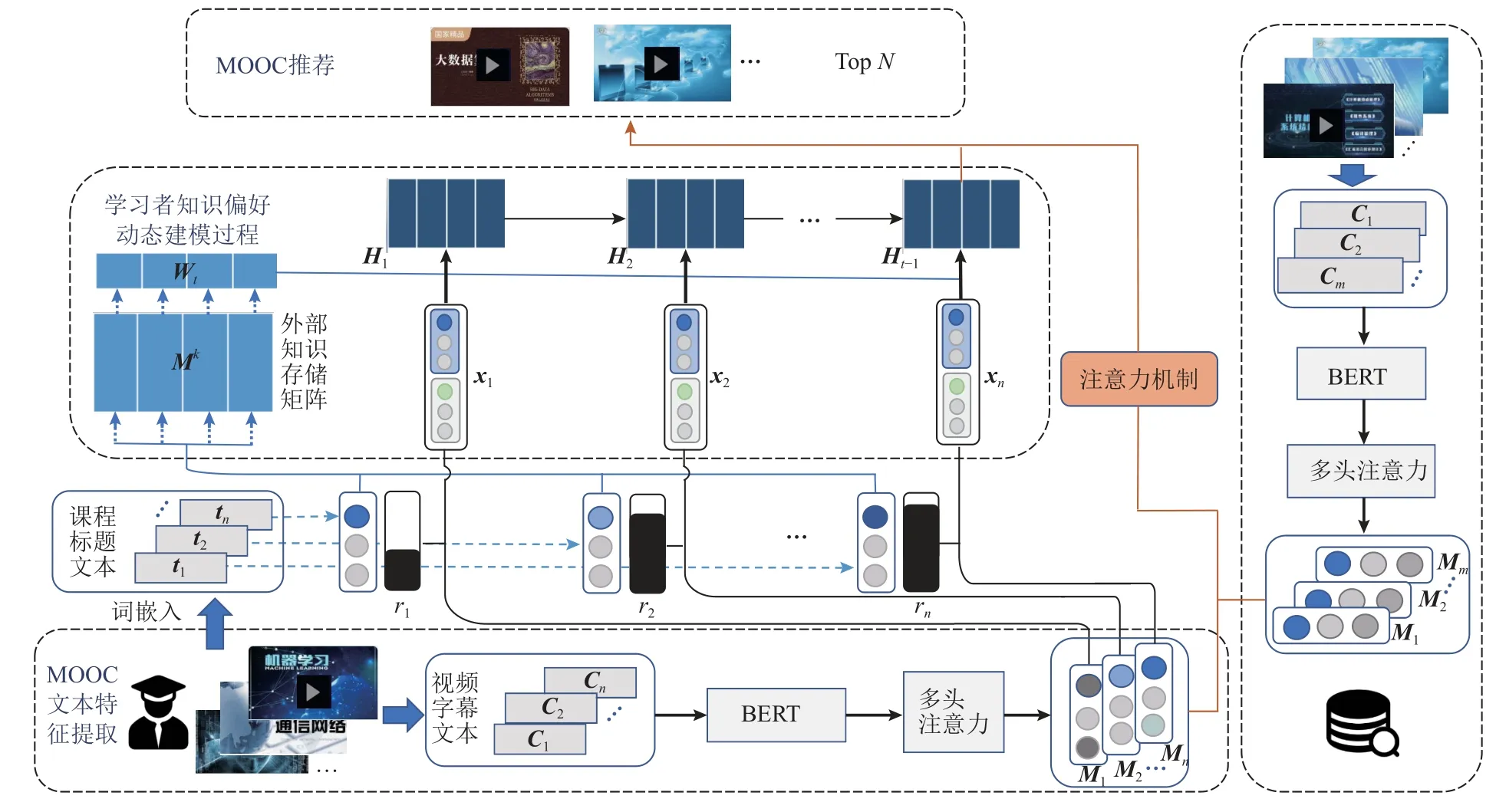
Fig. 1 MOOCDR-VSI framework图1 MOOCDR-VSI 框架
1) MOOC 文本特征提取. MOOC 包含了标题和视频字幕等文本信息,并通过BERT 编码器获得其字符级的文本嵌入表示,接着采用多头注意力机制从不同语义空间捕获局部特征间的依赖关系,并输出最终文本特征的嵌入表示.
2) 学习者知识偏好动态建模. 该模块将学习者学习序列的每个交互信息作为输入,包含经特征提取后得到的MOOC 字幕文本的嵌入表示和当前MOOC 的完成率,MOOC 标题信息经特征提取后与外部知识存储矩阵计算当前MOOC 知识点与其他MOOC 知识点的关联性,接着通过LSTM 输出每次学习交互后学习者的知识偏好状态.
3) MOOC 推荐. 该模块将结合当前时刻学习者的知识偏好状态以及经注意力机制提取的MOOC 视频之间的相关性,从未学习的MOOC 资源中召回N个MOOC 视频.
3.2 MOOC 文本特征提取
MOOC 中含有大量文本信息,包括标题、字幕等,通过这些信息能从文本的角度来理解视频的内容.本文首先将BERT 作为编码器,获取MOOC 的标题和字幕文本的词向量. 与传统的Word2vec[31]词向量表示方法不同,BERT 采用的双向Transformer 结构包含位置编码,因此能够考虑上下文语义信息. 给定MOOC 标题文本title= {x1,x2,…,xn}和字幕文本caption= {y1,y2,…,ym},通过BERT 预训练模型得到标题矩阵Ot和字幕文本矩阵Oc表示:
其中Ot∈,Oc∈,n,m分别为MOOC 标题和字幕文本的长度,Ti,Cj分别表示MOOC 标题和字幕文本的第i和j个词的向量表示,为向量维度大小d=768. 接着使用Oc在不同语义空间的文本信息:
其中headi为第i个头的自注意力,,,为第i头自注意力的权重矩阵,接着将所有自注意力矩阵拼接在一起,最后乘以一个权重矩阵W0得到多头注意力M.
3.3 学习者知识偏好动态建模
学习者知识偏好动态模块的目标是通过建模学习者的学习序列,进而追踪学习者知识偏好状态随着学习过程的动态变化. 这个过程考虑了3 个方面的输入对学习者知识偏好的影响:1)当前MOOC 标题的语义信息Ot;2)当前MOOC 视频字幕经多头注意力捕获的语义信息M;3)当前MOOC 学习的完成率.
通常MOOC 标题包含了当前学习内容的知识点信息,为了量化完成当前MOOC 后对不同知识点的影响,在建模过程引入了外部存储矩阵Mk,首先将当前MOOC 标题语义信息Ot和知识空间矩阵Mk的每一列相乘得到权重wt:
表示当前MOOC 视频与知识空间所有知识点的相关度,Mk存储的是MOOC 标题语义的嵌入表示. 接着,为了量化不同MOOC 视频的完成率对学习者知识偏好的影响,采用了一种合并的方式将完成率与当前MOOC 视频字幕文本语义的向量聚合. 具体而言,首先将学习者对当前MOOC 视频的观看完成率ri扩展为与字幕语义向量相同维度的全“ri”的向量,然后与Mi拼接得到维度为2d的向量xi:
接着,当前时刻学习者的知识偏好状态可以表示为
其中为学习者对知识空间中第j个知识的偏好状态,其含义为学习者完成当前MOOC 后对不同知识点的偏好影响由当前MOOC 与其他知识点的关联度决定,并将关联度映射到知识偏好状态矩阵Hi的第j列. 接着,在时刻t,模型采用LSTM 对学习者的每一个知识点的学习偏好进行更新,即具体计算过程为:
其中Zx∗,Zh∗,b∗是网络参数,为学习者在时刻t对第i个知识点的偏好状态. LSTM 是循环神经网络的一种变体,对于处理长序列依赖问题有出色的性能,与RNN 不同,LSTM 设置了输入门、遗忘门、输出门来控制单元状态在每一个时刻的更新.
3.4 MOOC 推荐
MOOC 推荐过程是从m个未学习的MOOC 视频中召回n个当前学习者可能感兴趣的MOOC 视频,该过程采用注意力机制的方法计算学习者未学习的MOOC 视频与过去学习的MOOC 视频的相似度,并根据学习者当前知识偏好状态Ht召回n个MOOC 视频. 具体而言,学习者未学习的MOOC 与过去学习的MOOC 的相似度由它们之间的语义余弦相似度刻画:
βij为MOOC 视频字幕语义Mi与Mj的相似度,接着,结合学习者当前的知识偏好状态Ht计算第i个MOOC 视频被召回的概率:
其中yt+1为预测信息的表征,W1,W2,b1,b2为模型参数,pt+1表示第i个MOOC 视频被召回的概率,pt+1值越大,代表学习者对其感兴趣的程度越大,最后通过 取pt+1前n个最大值作为推荐结果.
3.5 目标函数
模型的目标函数是基于学生MOOC 学习序列的负对数似然函数:
4 实验与结果
本节介绍了实验所采用的数据集、对比模型以及评价模型性能的指标. 然后给出了实验结果以及对实验结果的分析,包括模型损失下降过程和不同注意力头数对模型性能的影响分析. 最后,给出了追踪学习者知识偏好状态的变化过程和MOOC 视频关联性的可视化分析.
4.1 数据集、对比模型和评估方法
本文实验选用的数据集MOOCCube[32]为中国最大的 MOOC 平台之一的学堂在线收集的在线学习数据集,该数据集包含了199 199 名学习者在706 门真实在线课程的选课和视频观看记录,这些课程涉及38 181个教学视频和114 563 个知识概念.
为了验证MOOCDR-VSI 模型的有效性,本文选取了9 个典型的基准方法的对比实验结果.
1) MLP[33]. 该方法利用多层感知器来学习用户-项目交互的协同过滤方法.
2) FISM[9]. 该方法基于内容的方法来生成TopN推荐,该方法将项目相似度矩阵学习作为2 个低维潜在因子矩阵的乘积,缓解了模型的性能由于数据稀疏的增加而减低的问题.
3) NAIS[34]. 该方法基于内容协同过滤的神经注意项目相似性模型,通过注意力网络区分用户交互记录中哪些历史项目对预测更重要.
4) NARM[35]. 该方法基于一种具有编解码结构的神经注意推荐机,通过在RNN 中加入注意机制来捕获当前会话中用户的连续行为和主要目的.
5) metapath2vec[36]. 该方法是一种异构网络中元路径引导的随机行走策略,能够捕获不同类型节点和关系的结构和语义关联.
6) ACKRec[28]. 该方法是一种基于图神经网络的注意卷积网络知识推荐器,通过构建一个异构信息网络,以捕获不同类型实体之间的有效语义关系,并将其纳入表示学习过程.
7) HRL[13]. 该方法是一种基于分层强化学习的课程推荐方法,其在NAIS 模型的基础上改进以去除噪声数据.
8) 文献[25]方法. 该方法是一种基于多级注意力的方法,通过学习记录注意、单词级注意、句子级注意等探索了多个非结构化信息.
9) DARL[37]. 该方法是一种基于动态注意和分层强化学习的课程推荐方法,在每次学习交互记录中自适应更新课程的注意力权重.
参照大部分MOOC 推荐模型的研究工作,本文实验采用命中率(hit radio,HR)和归一化折损累计增益(normalize discount cumulative gain,NDCG)作为评估指标.HR是评价召回准确率的指标,用于衡量成功推荐给学习者的项目数所占的百分比,计算公式为:
其中GT表示所有学习者测试集长度之和,Hitsu@K表示测试集中第u个学习者的推荐列表中的项目数.NDCG是衡量精确度的指标,其值越大,表示推荐准确的结果排名越靠前,计算公式为:
其中为排名在第i位的推荐结果与第u个用户的匹配度,如果命中测试集中的课程则=1,否则=0,IDCGu@K为DCGu@K的理想值,即可能取得的 最大值.
4.2 实验结果与分析
本文实验模型参数为:MOOC 视频标题文本字符长度title_length=10,该长度为标题预处理后文本的最大长度,BERT 隐藏单元数hidden_num=768(即词向量维度大小),BERT 处理每个MOOC 字幕文本长度text_length=510,多头注意力机制的头数num_head=8,batch_size=128,learningrate=0.001,dropoutratio=0.2.实验将数据集80% 的数据划分为训练集与验证集,20%的数据划分为测试集. 图2 展示了MOOCDRVSI 方法的损失曲线. 由图2 可知,MOOCDR-VSI 经过46 轮的迭代后基本达到收敛,RMSE(root mean square error)稳定在0.89 附近.

Fig. 2 Loss curve of MOOCDR-VSI图2 MOOCDR-VSI 的损失曲线
实验结果如表1 所示,MOOCDR-VSI 在HR@5,HR@10,NDCG@5,NDCG@10,NDCG@20 指标上取得了最佳的性能,比目前最优方法分别提高了2.35%,2.79%,0.69%,2.2%,3.32%,实验结果证明了MOOCDRVSI 的有效性.图3 展示了HR@K和NDCG@K随着迭代次数的变化,第47 次左右迭代后趋于稳定,达到了最优效果.
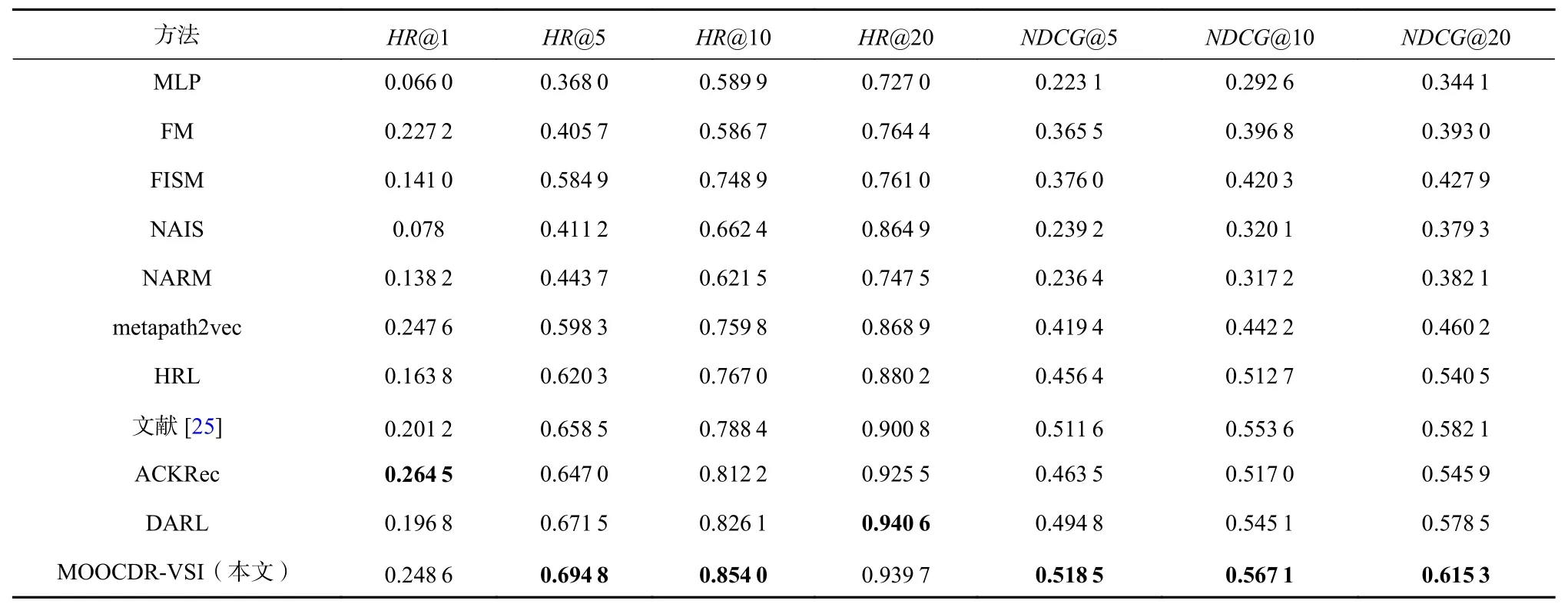
Table 1 Experimental Results and Performance Comparison表1 实验结果与性能对比
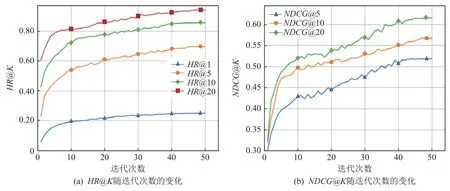
Fig. 3 HR@K and NDCG@K curves vary with the number of epoches图3 HR@K 和NDCG@K 随迭代次数的变化曲线
本文采用了多头注意力从不同语义空间的文本信息提取特征,为了研究不同的注意力头数num_head对模型性能的影响,实验分别取num_head= 1, 2, 4, 8,12 进行实验,不同头数的注意力对模型的影响如图4 所示. 图4 中,当num_head= 8 时,模型获得最佳效果,当num_head= 1 时,此时的多头注意机制为自注意机制,随着注意力头数的增加,MOOCDR-VSI 性能取得一定提升,这验证了多头注意力机制能够捕捉多方面的信息,深度挖掘MOOC 视频的个性信息.但当继续增加多头注意力的头数时,导致了MOOCDR-VSI 性能不升反降,这是由于过多的注意力头数可能会引入噪声信息从而误导模型,使得模型性能下降.
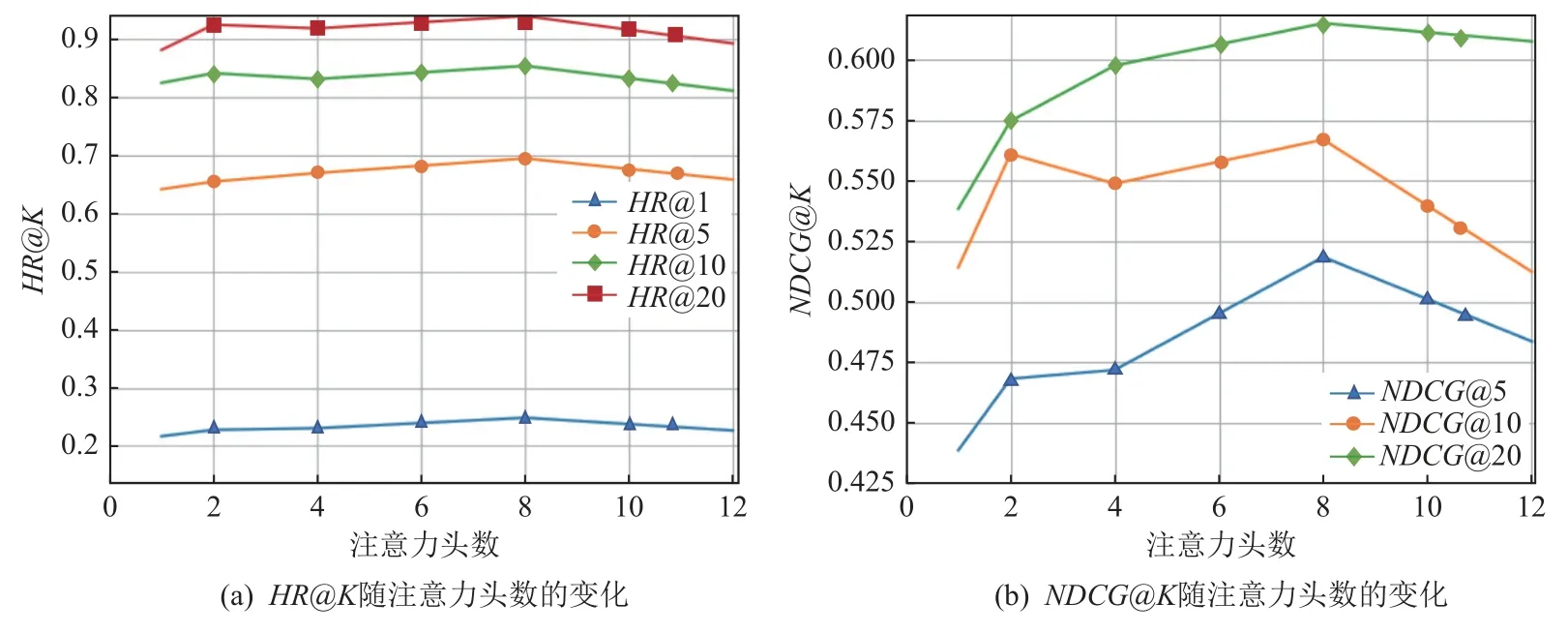
Fig. 4 Effect of different attention heads on MOOCDR-VSI performance图4 不同注意力头数对MOOCDR-VSI 性能影响
另外,MOOCDR-VSI 模型能够动态跟踪学习者随学习不断变化的知识偏好和需求,为了证明模型追踪学生知识偏好状态的合理性和可解释性,我们对同一个学习者在6 个知识点的偏好状态进行可视化追踪,如图5 所示,其中深颜色表示对应知识点有较高的偏好状态. 可以看出,该学习者在完成第5 次学习后,可能对“K_含水层_地质学”和“K_孔隙比_地质学”有较高的兴趣;当完成第15 次学习后,该次学习内容可能与“K_透水性_地质学”和“K_孔隙比_地质学”等知识点具有较高的关联性,因此捕捉到学习者可能有学习相应知识点的倾向,通过不断追踪学习者变化的学习偏好和需求能够使模型更加精准地推荐相关MOOC 资源,并且使得模型能够提供学习者知识偏好层面的解释.

Fig. 5 Visualization of learners’ knowledge preference state changing with learning图5 学习者随着学习变化的知识偏好状态可视化
除此之外,MOOCDR-VSI 具有较好的扩展学习者兴趣的能力,图6 展示了基于学习者的学习记录的MOOC 视频推荐结果,纵轴为一名学习者已学习过的MOOC 视频,横轴为向该学习者推荐的Top 10的MOOC 视频. 从学习者的历史学习记录来看,该学习者可能对“化学”“基因”等学习内容感兴趣,在推荐结果中给出了“编码”“继承”等非“化学”学科的相关延伸知识,能够在一定程度上缓解“蚕茧效应”造成的学习者视野日益狭隘等问题,体现了推荐结果的拓展性和多样性. 另外,模型通过计算MOOC 字幕文本之间的特征相似性而获得MOOC 内容语义层面的相关性,这种关联性可作为向学习者推荐MOOC 的依赖信息. 图6 中格子颜色越深表示课程之间的相关性越高,如“K_氨基酸_化学”与“K_核酸_化学”可能在内容上有较高的相关性,这种相关性可能体现在涉及的知识点或有语义层面的共性特征,这些自动学习到的结果可以作为教育领域的数据补充.
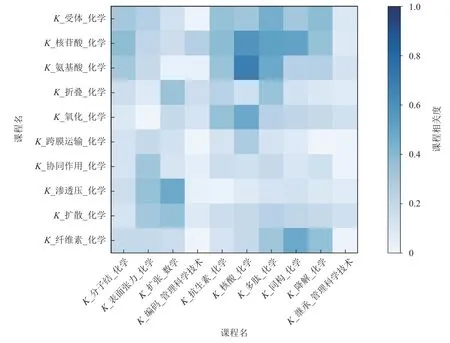
Fig. 6 MOOC video recommendation results and their correlation analysis图6 MOOC 视频推荐结果及其相关性分析
5 结束语
本文提出了一种融合字幕信息的MOOC 推荐模型对学习者的知识偏好状态进行动态追踪,进而为学习者推荐其可能感兴趣的MOOC 视频资源. 首先通过BERT 编码器获得MOOC 视频的文本语义信息的表征;接着采用多头注意力机制提取到局部语义特征的关联性;其次采用基于LSTM 的网络架构捕获学习者随着学习不断变化的知识偏好状态;然后通过挖掘MOOC 视频之间的字幕文本语义关联性获得MOOC 之间的相关性;最后结合当前学习者的知识偏好状态召回TopN个学习者可能感兴趣的MOOC 视频. 这种通过深入挖掘MOOC 视频内容的方法能够获得词语级粒度的MOOC 个性信息和共性信息,从而获得更加精准的推荐结果. 除此之外,通过追踪学习者知识偏好状态的变化过程和挖掘MOOC 之间的关联性能够使模型提供知识层面的解释性.
后续工作我们将构建的知识图谱引入多种实体之间,如学生与课程、课程与教师、课程与知识点等的关系作为MOOC 推荐约束的方法. 实体之间并不是相互独立而是彼此关联,例如,不同的教师授课具有不同的风格,不同的学习者对不同教师的授课风格具有不同的偏好,因此不同实体之间具有一定的依赖关系,将知识图谱等辅助信息引入推荐模型获得不同实体之间的内在关联,可以作为MOOC 推荐任务的约束条件.
作者贡献声明:吴水秀负责模型的搭建与算法的设计;罗贤增和钟茂生负责模型实现与论文的撰写;吴如萍和罗玮负责实验的可行性分析.
