混合目标与搜索区域令牌的视觉目标跟踪
2024-02-20薛万利张智彬裴生雷张开华陈胜勇
薛万利 张智彬 裴生雷 张开华 陈胜勇
1 (天津理工大学计算机科学与工程学院 天津 300384)
2 (青海民族大学物理与电子信息工程学院 西宁 810007)
3 (南京信息工程大学计算机学院 南京 130012)
(xuewanli@email.tjut.edu.cn)
视觉目标跟踪是计算机视觉的重要研究方向[1].其研究任务是在视频序列首帧中给定任意目标,并在后续视频序列中持续预测目标位置. 目标跟踪被广泛应用于无人驾驶、智能视频监控、人机交互等领域[2]. 如何设计简单、高效的通用视觉目标跟踪方法是一个亟需解决的难题. 尤其在真实复杂场景中,目标表观受光照影响、尺寸变化、严重遮挡等挑战,会产生持续的剧烈变化,从而影响跟踪结果.
近些年,基于卷积神经网络(convolutional neural network, CNN)的目标跟踪获得广泛关注. 然而受限于感受野规模,CNN 更多用于处理目标在时间域或空间域的局部特征,未能有效捕获目标特征之间的长期依赖关系[3]. 当前基于CNN 的主流跟踪框架主要包括:基于孪生网络(siamese network)[4-7]的目标跟踪和基于在线学习判别式模型[8-10]的目标跟踪. 这些方法在获取图像局部特征时表现优异,但在复杂场景中,如目标被频繁遮挡或出现剧烈形变时,则不能很好地建模特征的全局上下文关系.
此外,基于Transformer 的跟踪方案通过引入全局自注意力(self-attention)机制获取特征间长期依赖关系[11-13]. 在此类方案中,多数跟踪方法采用CNN 作为主干网络对图像进行特征提取,随后利用Transformer 设计编码器和解码器. 文献[14−15]专注简化跟踪步骤,将Transformer 作为特征提取器并直接输出预测位置. 然而,此类跟踪方案中起核心作用的自注意力机制,由于其计算复杂度为,使得其随图像大小增加导致计算量陡增,并直接影响目标跟踪效率.
为了降低计算量,一些研究采用视觉多层感知器(multi-layer perceptron,MLP)来构建主干网络[16-17].这些研究使用MLP 层代替Transformer 中的自注意力层,并在时域进行令牌(token)间信息交互,所谓令牌即目标和搜索区域对应的样本被切分成若干个不重叠的图像块. 令牌间的信息交互进一步简化时域信息的融合操作. MLP 的引入降低了计算复杂度,但是在训练和测试中随着令牌数量增加,会显著加大MLP 计算量,同样会影响目标跟踪效率.
受全局滤波网络设计启发[3],本文提出利用快速傅里叶变换(fast Fourier transform, FFT)对令牌进行高效融合,以降低视觉MLP 模型在令牌数量增加时产生的计算开销. 首先,利用FFT 将令牌时域特征转变为频域特征. 随后,在频域空间中捕获目标当前信息及其历史信息与搜索区域信息间的长程依赖关系.最后,利用快速傅里叶逆变换(inverse FFT, IFFT)将频域特征转换回时域特征. 上述FFT,IFFT 运算步骤使得所提跟踪方法,能够以较低的对数复杂度在频域空间快速学习目标在时空维度上的交互关系. 此外,为了更好地自适应目标在跟踪过程中的表观变化,提出一种基于质量评估的目标模板记忆存储机制. 该机制根据当前跟踪状态动态更新记忆存储器中稳定的历史目标信息,用于学习适应目标变化的外观模型,有助于在搜索区域内准确匹配目标.
本文的主要贡献有3 点:
1) 提出一种快速获取令牌间长程依赖关系的跟踪算法. 特征提取与融合以端到端的形式进行学习,同时在频域空间以更小的计算复杂度建模目标令牌与搜索区域令牌间的交互关系.
2) 提出一种基于质量评估的目标模板记忆存储机制,动态自适应地捕捉目标在视频序列中的稳定变化过程,提供高质量的长期历史目标信息.
3) 所提跟踪方法在3 个公共跟踪数据集LaSOT[18],OTB100[19],UAV123[20]上获得优秀评价.
1 相关工作
1.1 基于CNN 的目标跟踪
目标跟踪框架通常可以被划分为3 部分:1)提取图像特征的主干网络;2)目标与搜索区域特征融合模块;3)生成预测位置模块. 多数跟踪方法[5-9]将CNN 作为主干网络. 其中,基于孪生网络的跟踪框架以端到端方式进行训练.SiamFC[7]采用全卷积孪生网络提取目标特征,跟踪过程中不进行目标模板更新.DSiam[21]基于孪生网络以正则化线性回归模型动态更新目标模板.SiamRPN[6]利用孪生网络提取目标与搜索区域特征,同时结合目标检测研究中的区域推荐网络对目标位置进行精准定位.SiamRPN++[5]在训练过程中辅以位置均衡策略缓解CNN 在训练过程中存在的位置偏见问题. 此外,一些基于在线学习的判别式目标跟踪模型也取得优异性能.DiMP[8]采用端到端网络模型离线学习目标与背景间的差异,同时在线更新目标模板.PrDiMP[9]基于DiMP[8]将概率回归用于端到端训练,在测试阶段对搜索区域生成关于目标状态的条件概率密度来捕获目标. 基于CNN的目标跟踪在训练时容易造成归纳偏置.
1.2 基于Transformer 的目标跟踪
当前Transformer 网络被广泛用于各项视觉任务中,如目标分类及检测[22-24]. Transformer 中的自注意力机制将每个输入元素与其他元素进行相关性计算.在视觉跟踪研究中,TrDiMP[13]使用Transformer 增强目标上下文信息,在编码器中通过自注意力机制增强目标模板特征,利用解码器融合上下文模板进行目标定位. TransT[12]提出一种基于多头注意力机制的特征融合网络,融合后特征分别输入目标分类器及边界回归器. Stark[11]则利用ResNet[25]作为主干网络提取目标特征,以Transformer 编码器和解码器进行端到端训练. SwinTrack[14]借鉴Swin Transformer[22],采用完全基于注意力机制的Transformer 进行特征提取及融合. ToMP[26]同样是一种完全基于Transformer 的跟踪算法,使用一个并行的2 阶段跟踪器来回归目标边界. Mixformer[15]提出一种同时混合注意力模块用于特征提取及融合. 基于Transformer 的目标跟踪方法虽然取得出色性能,但是随着搜索区域增大,其计算复杂度也将呈2 次方增加,从而影响目标跟踪效率.
1.3 基于MLP 的混合令牌相关工作
MLP-mixer[16]采用MLP 代替Transformer 中的自注意力机制进行令牌混合.ResMLP[17]基于MLP-mixer,利用仿射变换代替归一化进行加速处理.gMLP[27]使用空间门控单元在空间维度上给令牌重新加权. 上述MLP 混合令牌的研究同样存在计算量增加问题,即随着输入令牌数量增多其时间复杂度会以2 次方增加,并且MLP 通常存在固定空间权重很难扩展到高分辨率图像的情形.
2 方法介绍
图1 展示了基于FFT 的目标与搜索区域间令牌高效混合的目标跟踪框架,该框架为端到端方式. 首先,初始目标模板大小设置为Ht×Wt×3,记忆存储器中存储的历史目标模板的帧数设置为T,搜索目标区域的大小为Hs×Ws×3. 之后,将记忆存储器内所有目标样本和搜索区域对应图像样本,切分成不重叠的、规格为τ×τ×3的图像块,这些图像块称为令牌. 将这些令牌拼接起来,组成1 维令牌序列. 该序列包含目标信息与搜索区域信息. 下面分2 步进行模型的离线训练.
1) 针对预测目标框分支进行训练. 为了高效学习目标与搜索区域令牌间的长程依赖关系,采用3阶段网络设计进行令牌间混合. 在阶段1 中,使用线性嵌入层将原始令牌投影为维度为C的令牌特征,再将这些令牌特征输入至线性嵌入层和包含2 个FFT的令牌混合网络层. 在阶段2 中,为了扩大模型的感受野,通过线性合并层来减少令牌数量,并将其输出特征维度设置为 2C,这一过程由线性合并层和3 个FFT 的令牌混合网络层组成. 在阶段3 中,继续进行线性合并,同时经过6 个FFT 令牌混合网络层,此时输出的特征维度设置为 4C. 将在频域空间中获得的融合令牌信息进行IFFT 运算,将频域特征重新转换为时域特征,并输入由3 个Conv-BN-ReLU 网络组成的预测头网络估计目标位置.
2) 对跟踪质量评估分支进行离线训练,受Stark[11]启发,跟踪质量评估分支由一个3 层MLP 网络组成,用于评价当前跟踪质量,以决定是否将当前跟踪结果更新到记忆存储器中.
下面将详细介绍基于FFT 的令牌混合网络和基于跟踪质量评估的目标模板动态记忆存储机制.
2.1 基于FFT 的令牌混合网络
如图1 所示,提出的基于FFT 令牌混合网络层将特征提取与融合进行集成. 具体地,先利用图像分块操作将原始的2 维目标模板和搜索区域样本转化为N个不重叠的τ×τ×3大小的令牌. 经过裁剪等预处理后,得到一组特征矩阵P=(p0,p1,…,pN−1),pi∈R3τ2,i∈[0,N−1]. 之后,将P输入至FFT 令牌混合网络,在频域空间快速获得目标特征的多尺度交互及搜索区域与目标之间的有效交互. 其中,FFT 令牌融合网络层的结构如图2 所示,对于第i个令牌先将其映射成C维向量:

Fig. 2 Structure diagram of FFT tokens fusion network图2 FFT 令牌融合网络结构图
其中ω0∈R3τ2×C为每个令牌首层可学习权重,b0为首层权重位移参数向量,N为输入令牌个数.
FFT 令牌融合网络层的输入特征为X=(x0,x1,…,xN−1)∈RC×N,其中C为输出通道数. 然后采用式(2)将输入的时域特征转换为频域特征X′:
其中,FFT 函数为F(·)用于获得输入特征的频域表达,W为输入图像的宽,H为输入图像的高.
FFT 令牌混合网络层利用可学习的滤波器K∈CH×W×N学习X′的频域特征X′′:
其中 ⊙为K中每一个元素与X′对应位置元素间相乘[3].
最后,根据式(4)将频域特征X′′转换为时域特征X∗,并更新令牌进入下一层特征融合模块.
其中F−1(·)为IFFT,用于将频域特征转化为时域特征.
参照Stark[11],本文采用一个3 层Conv-BN-ReLU预测头网络来估计目标位置. 具体地,估计过程被建模为预测边界框的左上角和右下角坐标的概率值图,并回归概率值图分布获得预测目标的最终坐标. 不同于Stark 的预测头网络高度依赖编码器和解码器,本文所提预测头网络由3 个简单的全卷积网络组成.离线训练预测头位置分支的损失Lloc由L1损失和Lgiou损失组成,具体定义为:
其中 α为L1损失的权重系数,设置α=5; β为Lgiou的权重系数,设置β=2 .Bi为第i帧搜索区域的真实标签,Bpred为预测头网络输入预测的目标位置.
2.2 基于跟踪质量评估的目标模板记忆存储机制
为了提升跟踪速度的同时规避跟踪过程中引入的累计误差,多数跟踪算法仅采用第1 帧目标模板进行匹配. 然而在跟踪过程中目标表观通常会出现剧烈变化,此时固定目标模板的跟踪方法容易产生漂移. 部分算法采用跟踪响应图的统计特性来预测当前跟踪质量,如使用峰旁比[28]、平均峰值相关能量[29]等. 然而基于上述统计数值判断跟踪质量的做法在经历长期不稳定的跟踪后,容易导致不准确的评分结果.
如果跟踪算法可以及时预先获取当前跟踪质量,并将高质量跟踪结果放入记忆存储器中,则能够有效捕获目标在时序上的稳定表观信息变化,为目标与搜索区域的令牌混合提供有效依据.
因此,在预测头网络中添加了一个用于预测当前跟踪质量的分支. 该分支的输入为令牌融合网络层最终输出的令牌时域特征,输出为2 个经过softmax 函数处理过后的数值Si0与Si1. 其中Si0代表第i帧输出的预测目标位置不是目标,Si1表示当前预测结果是目标.当Si1>Si0时,表示当前跟踪质量良好,可以将当前跟踪结果更新到记忆存储器中,此时设置ϵi=1;当Si1≤Si0时,表示当前跟踪质量较弱,不适宜将跟踪结果更新至记忆存储器,同时设置ϵi=0 .ϵi表示预测当前跟踪质量评估结果. 离线训练跟踪质量评价分支使用二值交叉熵损失评估,具体定义为:
其中li为第i帧样本真实的标签,当li=1时表示当前搜索区域包含真实目标,当li=0时表示当前搜索区域不包含搜索目标.
记忆存储器M定义为长度T的队列,更新间隔设为TINR. 对应的更新策略如算法1 所示,当第i帧的质量评估为跟踪状态良好时,即ϵi=1且符合提取间隔,则将当前跟踪结果加入记忆存储队列M. 若记忆存储队列M的长度超过T,则选择删除M队列中首个元素M0. 当跟踪失败或者跟踪质量较低时,所提基于跟踪质量评估的目标记忆存储机制,能够有效缓解目标模板产生误差带来的消极影响.
该机制的可视化展示如图3 所示. 第1 帧给定初始目标,并将其存入记忆存储器中. 记忆存储器的长度T设置为5,根据跟踪质量评价结果,动态地将可靠的目标模板存入M中. 第200 帧时,目标被完全遮挡,此时质量评估较差,不进行更新存储操作. 至此,M中的目标模板分别来自第90 帧、第100 帧、第110 帧、第120 帧、第130 帧的跟踪结果. 在第260 帧时目标重新出现,此时质量评估良好,所以当前M存储的目标模板调整为第120 帧、第130 帧、第240帧、第250 帧、第260 帧的跟踪结果.
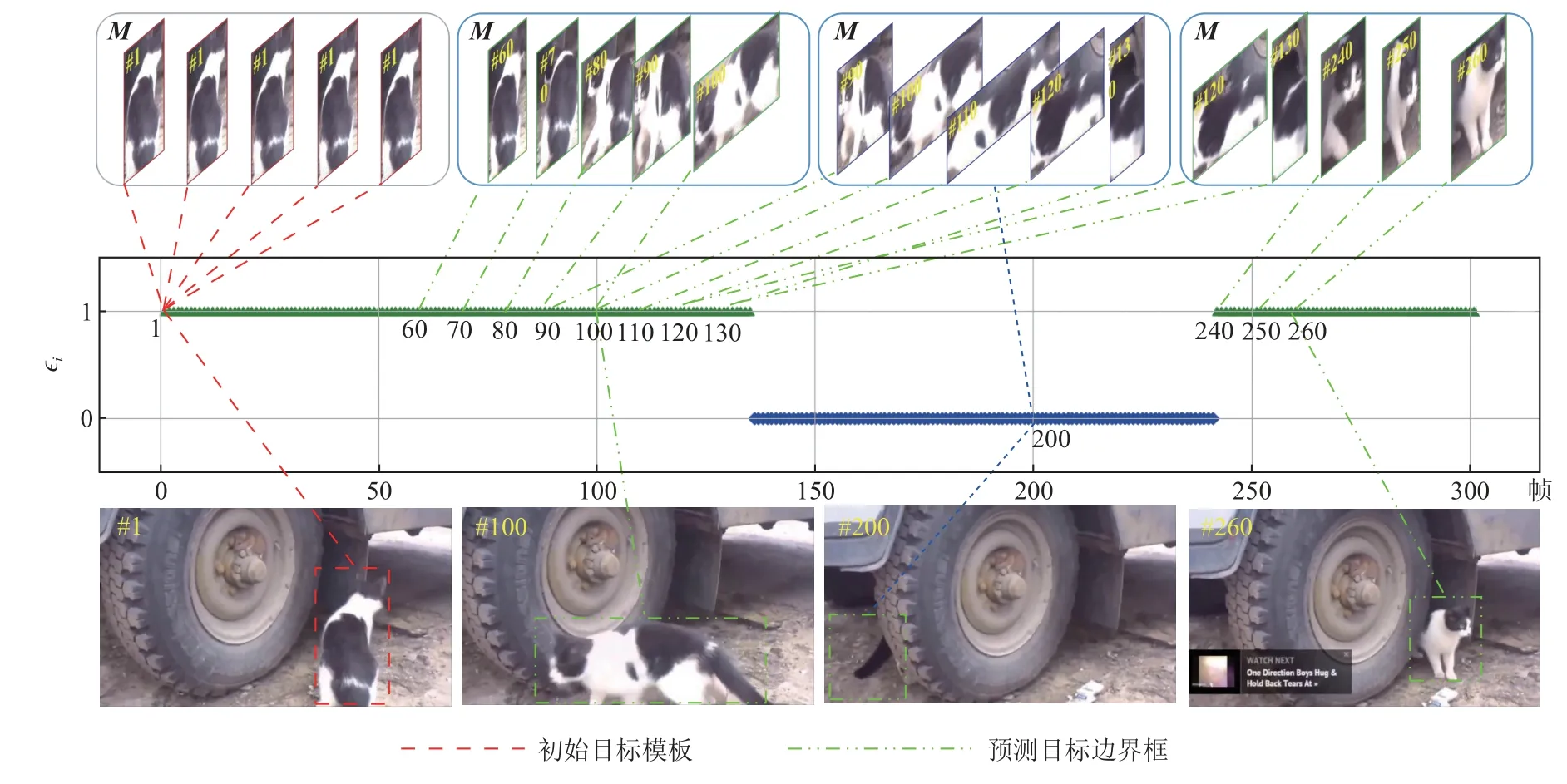
Fig. 3 Visualization of template memory storage algorithm based on quality assessment图3 基于质量评估的模板记忆存储算法的可视化
算法1.基于跟踪质量评估的目标模板记忆存储.

3 实验结果分析
3.1 模型训练设置
目标模板大小为Ht×Wt×3,搜索区域的大小为Hs×Ws×3. 设置Ht,Wt两者值均为128;Hs,Ws两者值均为384.记忆存储器长度T=5. 记忆器更新模板的间隔TINR=10. 图像分块操作中块大小τ=4. 训练数据集为LaSOT[18],GOT-10k[30],TrackingNet[31].
考虑到定位和分类的联合学习可能导致2 个任务存在次优解[11]. 因此,借鉴Stark[11]和Mixformer[15]的训练方式,分2 步训练特征融合模型. 首先,进行300 批次的预测目标位置分支训练,采用Adam[32]损失优化器将学习率设置为1E−4;其次,进行100 批次的预测当前跟踪质量的分支训练,学习率设置为1E−5. 软件环境为Ubuntu20.04,Python3.6,Torch1.10.3,Cuda11.3.硬件环境为NVIDIA RTX3090 24 GB.
3.2 定量分析
在LaSOT[18],OTB100[19],UAV123[20]数据集上验证本文方法的有效性. 评价指标为成功率(success ratio)和精度图(precision plot),其中成功率使用成功率曲线下面积(area under curve, AUC)作为排序依据.
LaSOT[18]数据集包含1 400 个视频序列,共计70类目标. 其中1 120 个视频用于训练,280 个视频用于测试. 视频序列平均长度2 400 帧. 数据集包含视野外等14 种挑战.图4 显示本文算法与TrDiMP[13],TransT[12],Alpha-Refine[33],SiamR-CNN[34],PrDiMP[9],DiMP[8],SiamGAT[35],SiamBAN[36]8 种优秀算法比较结果. 结果表明本文算法在成功率和精度图中均处于领先水平. 精度图方面比TransT 高3.3%,成功率比Alpha-Refine 高0.8%.图5 展示本文算法与5 种先进算法在不同挑战下的实验结果,可以看出本文算法在多数挑战中均表现优异.

Fig. 4 Comparison of success ratio and precision plot in our algorithm and other state-of-the-art algorithms on LaSOT dataset图4 本文算法与其他最先进算法在LaSOT 数据集上的成功率指标与精度图比较
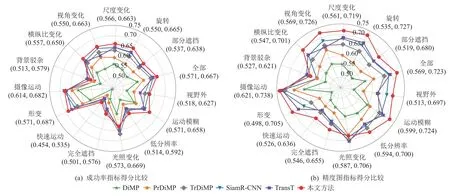
Fig. 5 Score comparison of the indictors in success ratio and precision plot for different challenges on LaSOT dataset图5 LaSOT 数据集上不同挑战的成功率指标和精度图指标得分比较
OTB100[19]数据集包含100 个视频序列,涉及快速运动等11 种挑战.图6 展示本文算法与TransT[12],SiamRPN++[5],SiamBAN[36],PrDiMP[9],DiMP[8],ECO[37],MDNet[38],ATOM[10]的比较结果. 本文方法取得最高的成功率值和精度图值,分别比SiamRPN++ 提升0.2%和0.5%.

Fig. 6 Comparison of the success ratio and precision plot in our algorithm and other state-of-the-art algorithms on OTB100 dataset图6 本文算法与其他最先进算法在OTB100 数据集上的成功率与精度图比较
UAV123[20]数据集由123 个无人机低空拍摄的视频序列构成. 小目标和频繁遮挡是该数据集的独特挑战. 表1 显示本文算法与TrDiMP[13],TransT[12],SiamR-CNN[34],SiamGAT[35],SiamBAN[36],PrDiMP[9],DiMP[8],SiamRPN++[5]的比较结果. 本文算法在成功率和精度图评价指标上均排名第一.
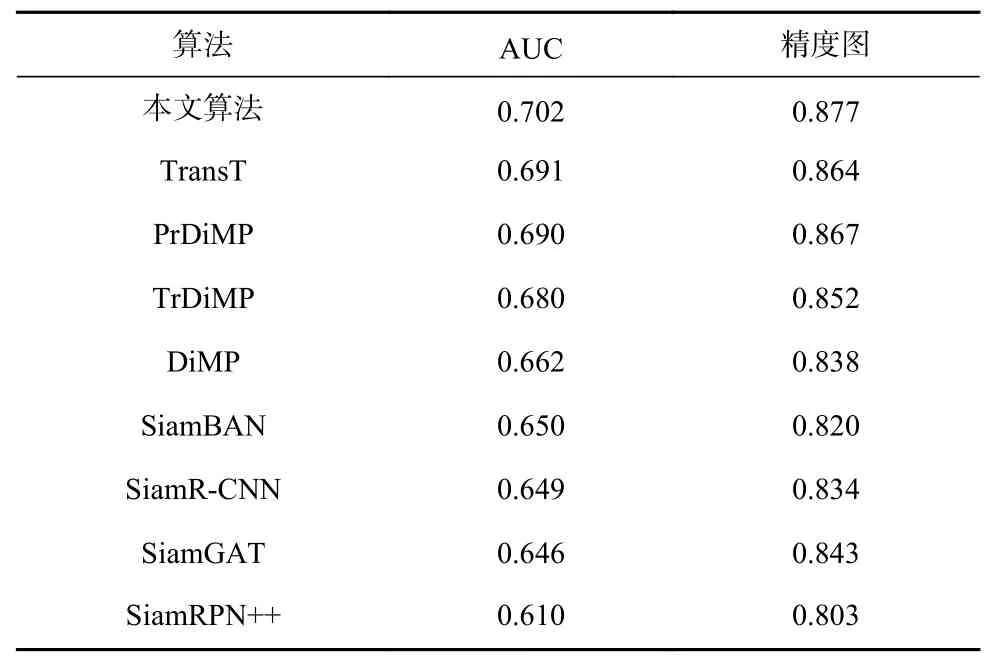
Table 1 Comparison of Our Algorithm and Other State-ofthe-art Algorithms on UAV123 Dataset表1 本文算法与其他先进算法在UAV123 数据集上的比较
3.3 定性分析
本节用可视化展示本文算法与6 种优秀算法在旋转、快速移动、尺寸变换及遮挡等挑战下的表现.
图7 展示LaSOT[18]数据集中bird-17 视频序列的跟踪结果. 该视频序列具备快速移动、视野外等挑战. 目标在148~156 帧快速向左移动至视野外,导致Alpha-Refine[33]和TrDiMP[13]发生跟踪漂移. 在第184帧中目标再次回归视野内,只有本文算法可以准确跟踪目标. 由于目标同时发生快速移动、运动模糊、旋转等挑战,其他算法均跟踪失败. 而本文算法拥有记忆存储器中的稳定目标模板,可以增强跟踪器对目标表观的自适应能力,并且在搜索目标时可快速计算目标模板和搜索区域之间的匹配关系,因此可以高效、稳健地跟踪目标.
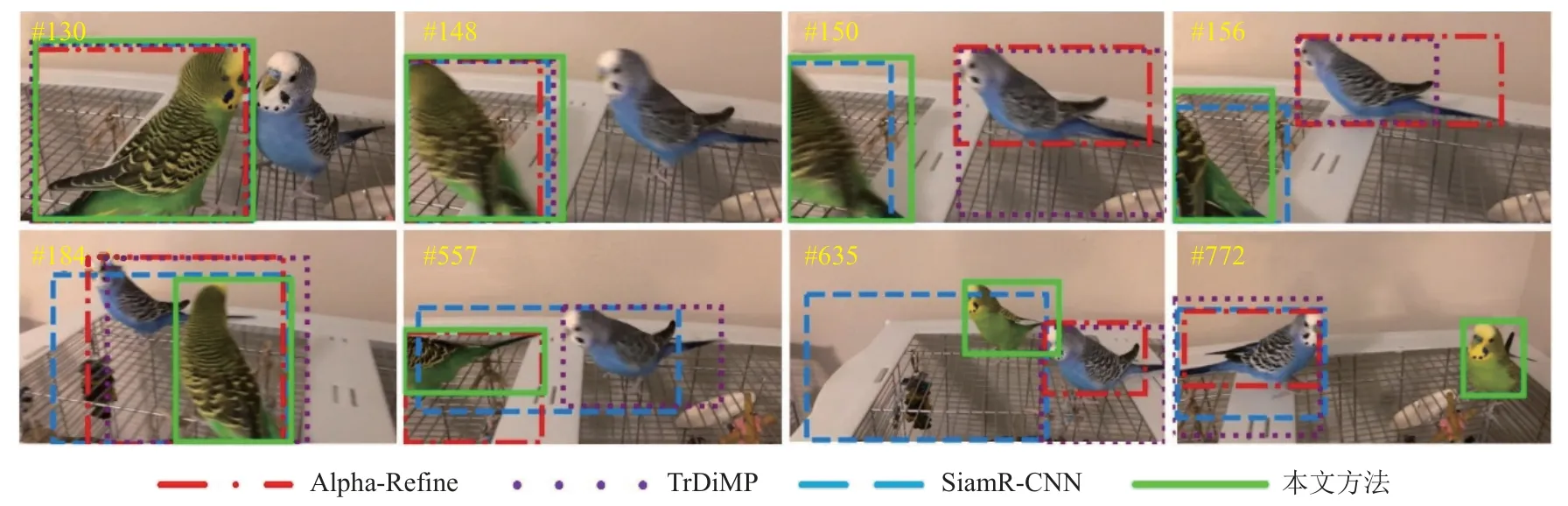
Fig. 7 Tracking results of bird-17 video sequence in LaSOT dataset图7 LaSOT 数据集中bird-17 视频序列中的跟踪结果
图8 展示LaSOT[18]数据集中bicycle-18 视频序列的跟踪结果. 在此视频中目标受遮挡、旋转等挑战影响. 第344~400 帧目标被岩石遮挡,导致TransT[12]和SiamGAT[35]丢失目标. 第437~517 帧目标发生剧烈旋转,SiamGAT,TransT,PrDiMP[9]均无法快速应对剧烈旋转引起的外观突变而发生漂移. 本文算法则依托令牌混合方案快速对目标与搜索区域特征进行交互,有效地获取更加稳健的时空特征,最终成功跟踪目标.

Fig. 8 Tracking results of bicycle-18 video sequence in LaSOT dataset图8 LaSOT 数据集中bicycle-18 视频序列中的跟踪结果
3.4 消融实验
本节验证本文算法中基于FFT 的令牌混合网络和基于跟踪质量评估的目标模板动态记忆存储机制的有效性. 表2 展示不同变体在LaSOT[18]测试集上的成功率和精度图得分.

Table 2 Results of the Ablation Experiments of Our Proposed algorithm on LaSOT Dataset表2 在LaSOT 数据集上本文算法的消融实验结果
首先,探讨基于FFT 的令牌混合网络的有效性.表2 中变体1 采用基于CNN 融合目标与搜索区域令牌的方法,并且仅利用第1 帧初始目标区域作为目标模板. 变体2 采用FFT 融合方法,同样仅采用第1帧初始目标区域作为目标模板进行匹配. 结果显示,基于FFT 的融合方法比基于CNN 的融合方法的成功率和精度图分别高1.3%和2.5%. 基于传统CNN 的融合方式在训练时只能学习特征间的局部依赖关系,无法获取全局长程依赖,且利用CNN 训练模型存在较大的归纳偏置. 为了更加充分融合目标与搜索区域间的信息同时建立两者间的长程依赖关系,本文提出利用FFT 进行令牌间的高效融合. 可以观察到在平均跟踪速度上变体2 比变体1 提升近1 倍,结果证实基于FFT 令牌混合网络的有效性.
其次,变体3 在变体2 的基础上增加了基于质量评估的目标模板动态记忆存储机制,用于获得更新稳定的目标模板信息,从而自适应目标表观变化. 由于记忆存储机制增加了目标模板数量,所以对平均跟踪速度上有一定影响. 变体3 在测试时的平均跟踪速度比变体2 降低了7 fps,但变体3 在成功率和精度图上,分别比变体2 高出0.6% 和1.4%. 结果显示基于跟踪质量评估的目标模板动态记忆存储机制有效.
此外,为了进一步验证本文方法具备高效的特征提取与融合能力. 在LaSOT 数据集上将本文方法与基于1 阶段训练的Mixformer[15]和基于2 阶段训练的TrDiMP[13]进行对比,结果如表3 所示. 与采用2 阶段训练的TrDiMP[13]相比,本文方法的成功率和精度图分别提升2.7%和5.7%,同时平均跟踪速度比TrDiMP[13]快8 fps.与基于1 阶段训练的Mixformer[15]相比,虽然成功率和精度图降低2.5%和2.4%,但是推理速度比Mixformer[15]高9 fps.实验结果表明本文方法在准确率和推理速度间的平衡能力更好,同时34 fps 的平均跟踪速度达到跟踪实时性[11]要求(>30 fps).

Table 3 Comparative Experimental Results of Reasoning Speed on LaSOT Dataset表3 LaSOT 数据集上推理速度的对比实验结果
4 总 结
本文提出了一种端到端的基于傅里叶变换的高效混合目标与搜索区域令牌的视觉目标跟踪方法.该方法将特征提取与融合相结合,利用傅里叶变换将令牌的时域特征转换为频域特征,以便快速学习搜索区域与目标模板之间的长程依赖关系. 为了捕获目标在时序上的外观变化,提出了一种基于跟踪质量评估的目标模板动态记忆存储机制,确保更新目标外观模板的合理性. 广泛的实验结果验证了所提方法的有效性.
作者贡献声明:薛万利提出论文整体思路并负责撰写与修改论文;张智彬负责算法设计与实验并撰写论文;裴生雷负责算法设计及论文审核;张开华负责论文修改;陈胜勇参与了论文思路的讨论及审核.
