面向小样本抽取式问答的多标签语义校准方法
2024-02-18陈艳平邹安琪秦永彬黄瑞章
刘 青,陈艳平,邹安琪,秦永彬,黄瑞章
1.贵州大学公共大数据国家重点实验室,贵州 贵阳 550025
2.贵州大学文本计算与认知智能教育部工程研究中心,贵州 贵阳 550025
基于跨度的小样本抽取式问答(extractive question answering,EQA)任务是机器阅读理解(machine reading comprehension,MRC)领域中最具挑战性的任务之一。与常规的抽取式问答任务相同,其模型能够理解给定的上下文,因此可以利用包含答案的上下文生成针对特定问题的答案[1]。小样本抽取式问答广泛应用于智能客服、自然语言理解和知识图谱等人工智能领域。
目前,常规抽取式问答的标准方法是通过微调预训练语言模型来预测答案跨度[2],其中,常用的预训练语言模型包括BERT[3]、SpanBERT[4]以及RoBERTa[5]等。该方法在多个问答基准数据集上表现出色,但其需要对大量带标注的问答实例进行微调。在实际应用场景中,训练高质量的标注数据不仅是耗时费力,而且成本很高,因此在实际场景中获得的带有标注信息的训练实例是非常有限的,在训练样本很少的情况下模型性能会受到严重限制。以基准数据集SQuAD[6]为例,当训练集包含10 万个问答实例时,预训练语言模型Roberta-base[5]和SpanBERT-base[4]分别实现90.3 和92.0 的F1 得分。但当只有16 个训练实例可用时[7],预训练语言模型Roberta-base 和SpanBERT-base 的F1 得分将下跌至7.7 和18.2。
为了使EQA 任务适用于更加现实和实用的场景,文献[7] 在现有的基准数据集中进行采样,构建并发布了不同尺寸的小样本训练集,形成了小样本EQA 任务场景下训练实例使用的统一标准。同时该文献还提出了适用于小样本场景的基线模型Splinter,该模型作为一个预训练语言模型,主要通过引入特殊字符[QUESTION] 来重构输入,并利用该特殊字符学习实例中不同的循环跨度,以此模拟问题回答。在此基础上,模型进一步使用问题感知跨度选择(question-aware span selection,QASS)层来感知答案范围,最终通过该特殊字符[QUESTION] 返回预测的答案跨度。该模型虽然能有效缩小EQA 任务与预训练语言模型任务间的差距,提升模型在小样本EQA 任务中的性能,但这种方法仍然存在着以下不足:首先,模型只利用循环跨度训练该特殊标签,会导致该标签的语义信息缺乏全局语义;其次,模型使用不同循环跨度训练相同标签,会导致该标签在答案跨度预测时语义存在偏差。为了解决上述问题,本文利用不同层级的语义来获取答案,同时提出了一个多标签语义校准方法,该方法有效提升了模型对文本的理解,进一步提高了模型的准确性。
本文利用头标签[CLS] 与Splinter 模型特有的[QUESTION] 标签构成了多标签,引入双门控机制实现了多标签语义之间的交互。首先,针对头标签的隐藏层进行线性变换,利用语义融合门选择性地保留全局语义信息,以解决[QUESTION] 标签缺乏全局语义信息的问题;其次,利用语义筛选门,在引入全局语义信息的基础上保留或舍弃信息以控制信息的流动,调整了答案预测标签[QUESTION] 的语义信息,解决了标签语义在预测答案跨度时的语义偏差问题。最后,在输出阶段,通过引入KL(Kullback-Leibler)散度[8]来优化损失计算,平衡了信息数据中误分类和正确分类的情况,校准了模型对答案范围的感知,提高了模型预测的准确性。本文在抽取式问答的8 个小样本数据集上进行了共56 组实验,相较于基线模型Splinter和SpanBERT,本文方法的F1 值普遍得到提高。此外,为验证双门控机制的校准能力,本文对各门控单元进行了研究分析。
本文的主要贡献有以下3 点:1)用原有输入构建多标签的语义融合方法实现了多标签与语义的交互。2)通过语义融合门和语义筛选门的组合使用,实现了多标签间信息流的控制,有效弥补了基线模型Splinter 的不足,校准了模型对答案范围的感知,提高了模型预测的准确性。3)在8 个小样本EQA 数据集上进行了56 组实验,相较于基线模型,本文模型拥有更好的性能,证明了所提方法的有效性。
1 相关工作
EQA 任务是自然语言处理领域中一个常见任务,其形式是根据给定问题在上下文中获取能回答该问题的答案片段。该任务目前被广泛应用于各种不同的场景,例如问答系统、信息检索等。本节将概述与EQA 相关的数据集,并简要介绍针对小样本EQA 任务的相关研究工作。
1.1 抽取式问答数据集
抽取式问答数据集是指适配抽取式问答任务的数据集统称。此类数据集的数据来源广、涉及领域多,在数据的结构上拥有以下共性:每个数据集都至少包含上下文、问题以及从上下文中获取的答案片段。近年来出现了许多大规模的抽取式问答数据集,极大地促进了EQA任务的发展。其中,斯坦福大学于2016 年发布了SQuAD 数据集[6],包含536 篇维基百科文章,涵盖超过10 万个抽取式问答对。该数据集推广了从给定文本中选择连续跨度作为答案的评估格式,目前已被多个领域的数据集采用。例如,文献[9] 提出的NewsQA 数据集,该数据集包含1.1 万篇以上的新闻文章和12 万个以上的问答对,属于新闻专业领域的数据集;文献[10] 提出的ScienceQA 数据集涉及了视觉背景信息和文本背景信息,属于科学问答领域;MLQA 数据集[11]和TyDi QA 数据集[12]专门用于评估模型跨语言问答的性能。文献[13] 通过WikiReading 数据集[14]构建了Slot-Filling 标注数据,引入了无答案问题作为负样本。此外,斯坦福大学在2018 年发布了SQuAD2.0[15],在原有数据集的基础上进一步加入了“无法回答”的问题,该数据集所涉及的文章达到13 万篇,问答对数量高达15 万。另外还有需要根据给定信息细节进行回答的DROP 数据集[16]和涉及广泛知识领域的Quoref[17]数据集等。以上EQA 数据集均采用了相同的评估格式。
本文所述的8 个小样本数据集的原始数据集已被MRQA2019[18]采集,并经过规范化处理形成统一的输入格式。MRQA2019 同样遵循以上评估格式,关注的问题类型为单跨度问题。为了更好地进行对比试验,本文使用的小样本数据集是从MRQA2019 中抽样来的,且抽样结果与基线模型保持一致。
1.2 抽取式问答模型
在抽取式问答任务中,基于大规模数据集的抽取式问答任务已引起相关学者的广泛研究。早期的模型利用注意力机制捕获上下文与问题之间交互的语义信息,例如文献[19] 提出的门控自匹配网络模型以及文献[20] 提出的指针网络模型。近几年,预训练语言模型诸如GPT[21]、BERT[3]、RoBERTa[5]和SpanBERT[4]等强大的建模能力使得基于预训练-微调的语言模型在抽取式问答任务上拥有了极高的性能。
然而,在小样本的情况下,采用这种标准的微调方式可能会导致过拟合,这使得相关学者对使用大规模数据集来训练模型的实用性产生了疑虑。于是,需要进一步研究针对小样本数据集的相关模型。文献[22] 提出的LinkBERT 模型在传统的预训练语言模型基础上,利用文档链接作为预训练信息,融入更多的知识以提高模型的理解能力。文献[23] 利用生成式神经网络的特点,形成简单易用的框架以支持小样本抽取式问答任务。文献[24] 提出了基于知识增强的对比提示模型,利用外部知识库来提高模型对小样本数据的适应性,并在任务的不同阶段引入了提示和对比学习等方法,进一步提高了模型对正确答案跨度的识别能力。文献[7]提出了Splinter 模型,在利用重复跨度训练特殊字符[QUESTION] 的基础上,通过QASS 层感知答案范围,最终通过该特殊字符预测答案跨度的开始位置和结束位置。
上述的小样本模型在构造数据集时,其采样和评估方式均存在标准不统一的情况,为更好地进行对比实验,本文所采用的小样本数据集和评估方法与小样本基线模型Splinter 的保持一致。
2 模型
本文提出的多标签语义融合校准模型的整体架构如图1 所示。下文将详细描述模型的输入以及多标签的构造,并介绍如何利用双门控机制控制信息的流动实现多标签语义的最终校准。

图1 模型结构Figure 1 Model architecture
2.1 多标签构造
本文使用小样本EQA 任务中的基准模型Splinter 作为编码器来获取不同标签的上下文嵌入。Splinter 模型是一种基于Transformer 架构的抽取式问答模型,和其他预训练语言模型一样,只有一个统一的输入。在Splinter 模型中,语义信息的交互和建模通过Transformer 模型[25]的自注意机制实现,这种机制能够自动地对输入进行加权和选择,从而更好地捕捉上下文语义信息。本文省略预训练语言模型完整的公式陈述,只描述Splinter 模型涉及的高级架构。
在预训练语言模型Splinter 中,给定一个输入序列IInput={a1,···,al},其中l表示最大序列长度。嵌入层由词嵌入、位置嵌入和标记类型嵌入组成,Splinter 通过嵌入层和连续堆叠L层的transformer 将输入转换为上下文表示,以捕捉输入文本中的语义信息和关系,公式为HL∈Rl×h,其中h表示隐藏层维度。在预训练语言模型Splinter 中,输入IInput由问题(Q)、文段(C)以及特殊的字符([CLS]、[SEP] 和[QUESTION])串联而成。
上述操作在遍历Splinter 模型之后可以得到两个“表示”。一是包含全局语义信息的[CLS] 语义表示,记为HC∈Rh。另一个是用于预测跨度开始位置S和结束位置E的[QUESTION] 语义表示,记为HQ∈Rh。
预训练语言模型的全局语义信息是由头标签[CLS] 所承载的,因此本文使用头标签的语义信息为模型预测引入全局语义,在模型图的输入中将头标签[CLS] 用绿色标记加以突出。
另外,[QUESTION] 标签的语义信息通过预训练语言模型Splinter 训练而来,Splinter 可使用[QUESTION] 标签替换循环跨度,即对文本中重复出现的跨度进行替换。例如,图1 中上下文片段部分表明了[QUESTION] 标签的训练信息来源。为便于理解,本文对不同循环跨度使用不同颜色进行标记,同时将循环跨度和其对应的[QUESTION] 标签标记为相同颜色。在模型输入部分,使用橙色对[QUESTION] 标签进行标记。
综上所述,本文在不引入额外的标签语义信息的情况下,使用原始输入中头标签[CLS]和预训练语言模型Splinter 特有的标签[QUESTION] 构成了本文的多标签。
2.2 多标签语义融合
受文献[26] 的启发,本文构造双门控机制进行多标签的语义融合。模型通过双门控机制来控制全局语义信息HC的引入量和标签语义信息HQ的保留量,并生成表示HN,用于预测答案跨度。
首先,通过语义融合门实现了HC和HQ的交互。根据交互结果确定全局语义信息HC的具体引入量为
其次,通过语义筛选门确定HQ表示的语义信息的保留量,公式为
式中:W2、b2为可训练参数;p2是用于计算标签语义信息保留量的权重值。
最后,表示HN经过QASS 层输出最终的预测答案。具体来说,在QASS 层中,通过计算HN与每个字符表示的内积,输出整个序列的概率分布情况,进而获取预测答案跨度的开始位置S和结束位置E。QASS 层的作用与标准预测方法[3]相同,但由于预训练语言模型Splinter 是通过[QUESTION] 标签动态计算答案开始和结束边界的,标准方法在该模型中并不适用,为了与Splinter 模型协同使用,需要用QASS 层替换标准方法。本文使用预训练语言模型Splinter 获取编码输入,因此在进行答案预测时,同样使用QASS 层获取答案边界。
在小样本EQA 任务中,训练实例最小取至16 例。当训练实例过少时,神经网络会过度记忆数据中的噪声和细节,导致模型出现过拟合的情况。为此,本文在损失计算时引入KL 散度优化损失计算,形式化结果为
式中:sg,eg分别为正确答案跨度的开始位置和结束位置;q为标签[QUESTION];lossKL表示计算的KL 散度损失。
3 实验
3.1 数据集
在小样本EQA 任务中,由于训练实例较少,对数据集使用不同的采样方法会显著影响模型的性能评估。为确保实验的有效性,本文使用了基线模型Splinter 采样的小样本数据集进行实验。该小样本数据集利用MRQA2019 统一了输入格式,其中涉及了MRQA2019 中Split I的6 个大型问答数据集即SQuAD[6]、NewsQA[9]、TriviaQA[27]、SearchQA[28]、HotpotQA[29]和Natural Questions[30](NQ),以及Split II 中两个领域专家注释的数据集BioASQ[31]和TextbookQA[10]。
分别对Split I 中6 个大型数据集的训练集进行随机采样,产生6 种小样本训练集。在每种小样本训练集中,根据采样数量的不同构建出不同尺寸的训练集,训练集的大小在对数尺度上变化,且训练实例尺寸范围为16~1 024。为减少方差,对每个尺寸的训练集均使用5 个随机种子并采样5 组,取5 组平均性能作为最终性能结果。同时,由于MRQA 2019 的Split I不包含测试集,因此使用官方开发集作为测试集进行评估。
对于Split II 所选取的两个数据集,MRQA2019 中只公开了开发集,所以本文使用的训练集与测试集均来源于开发集。使用其中400 个实例作为测试集进行评估,并在余下实例中,采用与Split I 中同样的方法构建不同尺寸训练集。
3.2 实验参数
本文使用Adam 优化器进行模型训练,并对小样本学习过程中的偏差进行实时校正。在训练过程中,使用了2.4 M 个训练步骤。每个批次包含256 个序列,每个序列长度为512。使用Warmup 的方式对学习速率进行预热,这能使学习速率在其达到最大值之后线性衰减。在所有层中dropout rate 取0.1。当数据集的尺寸为1 024 或更小时,将模型训练10 个epoch 或200个最小步长(使用训练性能较好的模型进行评估)。设置训练批次大小为12,评估批次大小为16。使用最大学习率为3×10-5。设置训练实例的尺寸为16、32、64、128、256、512、1 024。模型使用指标F1[32]进行评估,具体超参数设置如表1 所示。
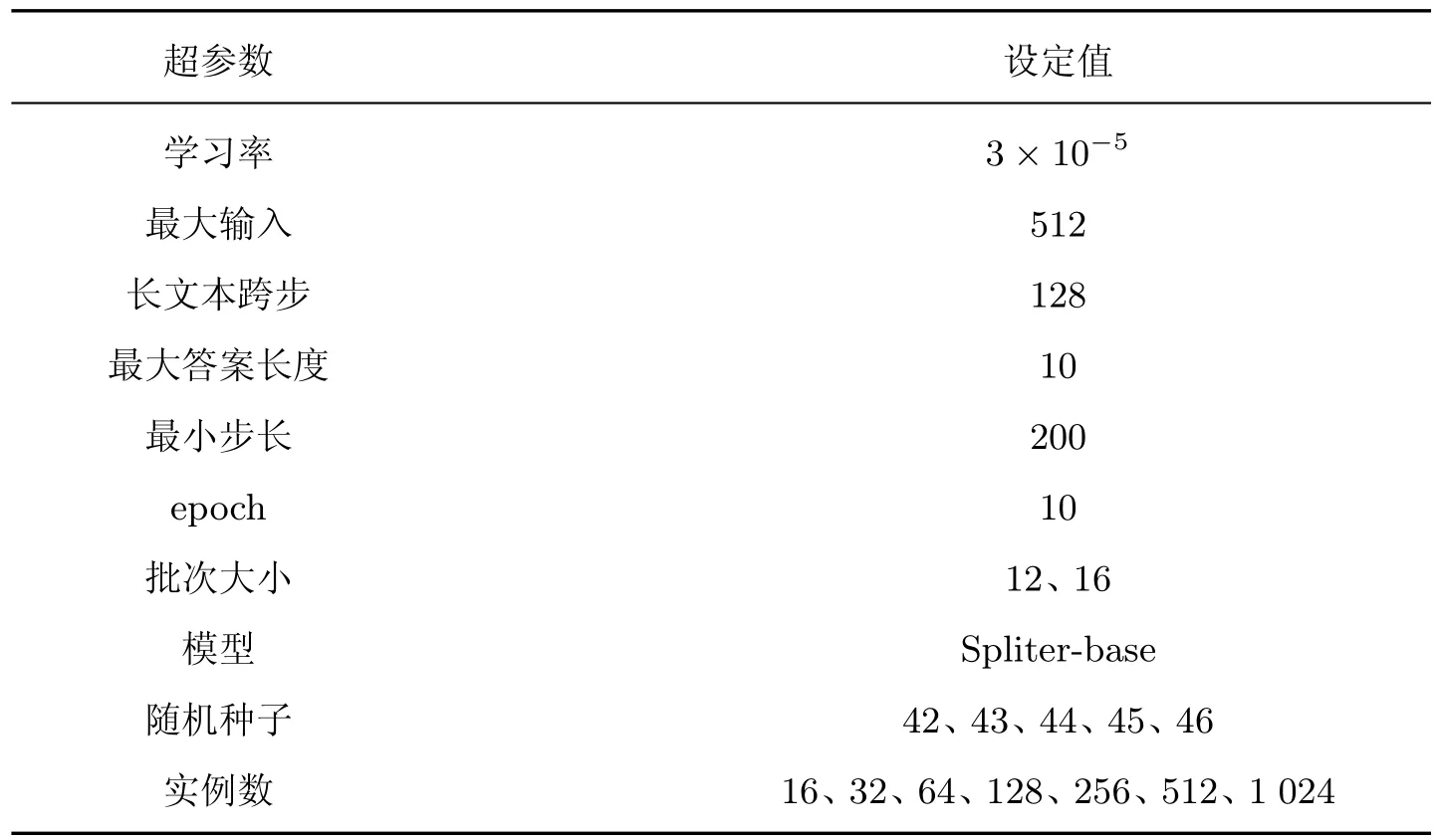
表1 超参数设置Table 1 Hyperparameter setting
3.3 实验结果
本文针对小样本EQA 进行了多个实验,表2 展示了在8 个数据集中使用16、32、64、128、256、512、1 024 个训练实例时,本文模型与基线模型Splinter 和预训练语言模型SpanBERT 的实验对比结果。

表2 实验结果Table 2 Experimental results
从单个实验结果来看:在TriviaQA 数据集中,当训练实例尺寸为16 时,本文方法的F1值达到了26.6,比Splinter 高7.7%,比SpanBERT 高13.8%;当训练实例尺寸为64 时,比Splinter 高9.2%,比SpanBERT 高21.9%。从总体实验结果来看:本文方法在56 组实验中的平均性能比Splinter 模型高1.9%,比SpanBERT 模型高17.3%。
实验表明,当目标任务是小样本EQA 时,无论训练实例的尺寸是16 还是1 024,相较于基线模型Splinter 和SpanBERT,本文提出的多标签语义校准方法都具有更好的性能。
从观察数据集TriviaQA 和数据集SearchQA 的实验结果可以发现,随着使用的训练实例尺寸增加,本文模型与基线模型Splinter 的预测准确率都在提高,同时两个模型的性能逐渐趋于接近,如图2 所示。

图2 TriviaQA 和SearchQA 实验结果实例Figure 2 Examples of TriviaQA and SearchQA experimental results
本文推测造成上述结果的原因是,当有足够多的可用训练实例时,模型利用训练实例就可以得到很好的学习效果。本文将通过消融实验,进一步验证本文模型的有效性。同时,本文模型在个别训练实例中存在实验结果略低于基线模型Splinter 的情况,如在TextbookQA 数据集中,训练实例的尺寸为64 时,本文模型性能略低于Splinter 模型。对此本文在下一节将做进一步分析。
3.3.1 实验数据分析
分析发现,本文模型在样本更小的情况下引入全局语义信息的效果更为明显。然而,在不同数据集或者同一数据集不同尺寸的训练实例中仍然存在一些差异。这些差异主要来源两方面:
1)数据集差异 本文涉及的8 个数据集在文章来源、提问风格和文章与问题的连接关系3 个方面存在较大差异。不同数据集的文章来源不同,涉及的知识领域也存在差异。如BIOASQ 数据集涉及生物和医学领域的知识,NewsQA 数据集来源为新闻信息等。在提问风格上,不同数据集的问题侧重点也不同,如TriviaQA 数据集的问题更集中于评估推理方面。各数据集的问题获取方式也不同,如HotpotQA 数据集的提问内容由众包工作者提供,Natural Questions 数据集的问题则由Google 搜索引擎中的真实问题汇总而来。在文章与问题的连接关系方面,部分数据集的问题根据文章内容设计而来,而部分数据集的问题是独立提出的,如SearchQA。另外,对于本文中所使用的8 个数据集,虽然数据集通过MRQA2019统一了输入格式,但是这些数据集的原始构造是为了测试模型的不同能力和特点而设计的。例如,TextbookQA 数据集涉及文本、图表和推理的复杂解析,涉及的知识领域也比较广泛。这种设计可能会导致问题答案与文章的关联性存在差异,特别是在EQA 任务中。
表3 具体展示了这些数据集在文章来源、提问风格、文章与问题的连接关系等方面存在的差异,其中问题独立性表示问题是否是根据文章内容设计的,如果是,标记为“是”,否则标记为“否”。

表3 数据集差异Table 3 Dataset difference
2)数据采样差异 本文的数据集通过随机采样而来,在评估时使用5 组的平均得分作为最终得分。然而,在问答任务中,不同的提问内容占比不同,使用“What”针对“是什么”的提问频次远高于使用“Who”针对“是谁”的提问频次。单纯使用随机抽样的方式可能会导致抽取的训练实例相似度过高,从而造成小样本数据集不平衡,进一步使得实验结果存在差异。
综合56 组实验结果和数据分析来看,尽管在某些数据集上本文所提出的方法的性能会随着训练实例数量的增加而突然下降,出现低于基线模型的情况,但总体而言,本文方法仍然能够成功地引入全局语义信息,在小样本EQA 任务中获得了有效的性能提升。值得注意的是,该效果在数据样本较少时表现得更为显著。
3.4 消融实验
为了进一步评估双门控机制在多标签语义融合中的贡献,本文进行了消融实验,通过减少和增加门控数量来探究其影响。具体实验包括:
1)在NewsQA 数据集中,选取7 组不同尺寸的训练实例,进行单门控与双门控的纵向对比实验;
2)在8 个数据集中,分别选取了尺寸为32 的训练实例和尺寸为512 的训练实例,进行单门控与双门控的横向对比实验;
3)在HotpotQA 数据集中,选取7 组不同尺寸的训练实例,进行双门控与三门控的对比实验。
表4 展示了在数据集NewsQA 中7 组不同尺寸的训练实例下,仅使用单门控机制与本文双门控机制的纵向对比实验结果。表5 展示了在8 个数据集中且尺寸为32 的训练实例和尺寸为512 的训练实例下,仅使用单门控机制与本文双门控机制的横向对比实验结果。
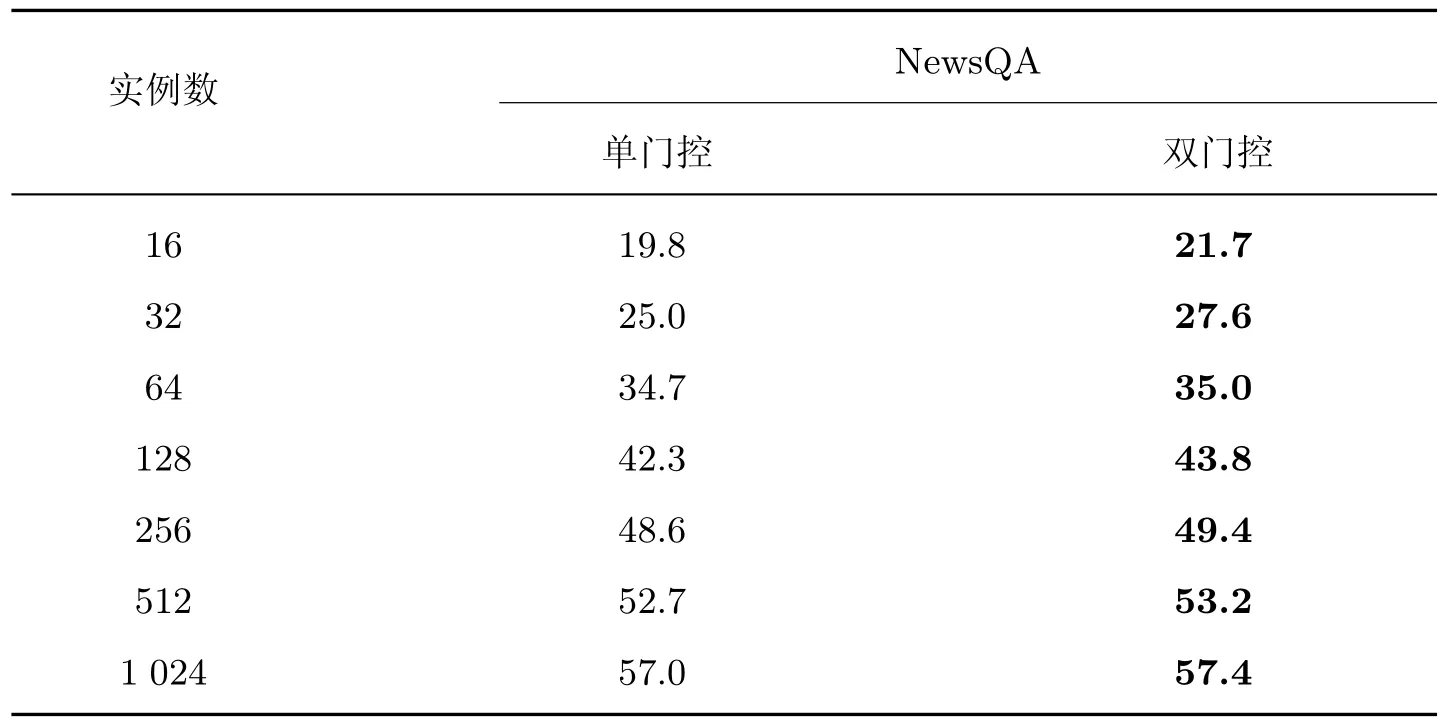
表4 单门控和双门控纵向对比实验Table 4 Longitudinal comparison test of single and double gate control

表5 单门控和双门控纵向对比实验Table 5 Single and double gate lateral comparison test
本文在设置单门控机制时,仅使用单一门控对[QUESTION] 标签的语义信息进行筛选。通过以上实验可以发现,相较于单门控机制,无论是针对同一数据集的不同训练尺寸还是针对相同训练尺寸的不同数据集,双门控机制都拥有更显著的性能。
表6 展示了在数据集HotpotQA 中使用7 组不同尺寸训练示例下,三门控机制与本文双门控机制的纵向对比实验结果。在单双门控的两组对比实验中可以看出:双门控机制能更显著地提升模型性能。基于此,本文进一步构造三门控机制以验证增加门控数量能否继续提升模型性能。三门控机制是在双门控机制的基础上建立的,它进一步对舍弃的[QUESTION] 语义部分构建门控,进行二次过滤。从对比实验结果可以看出:门控的数量与模型性能不呈现正相关,双门控机制在提升模型性能方面优于三门控机制。
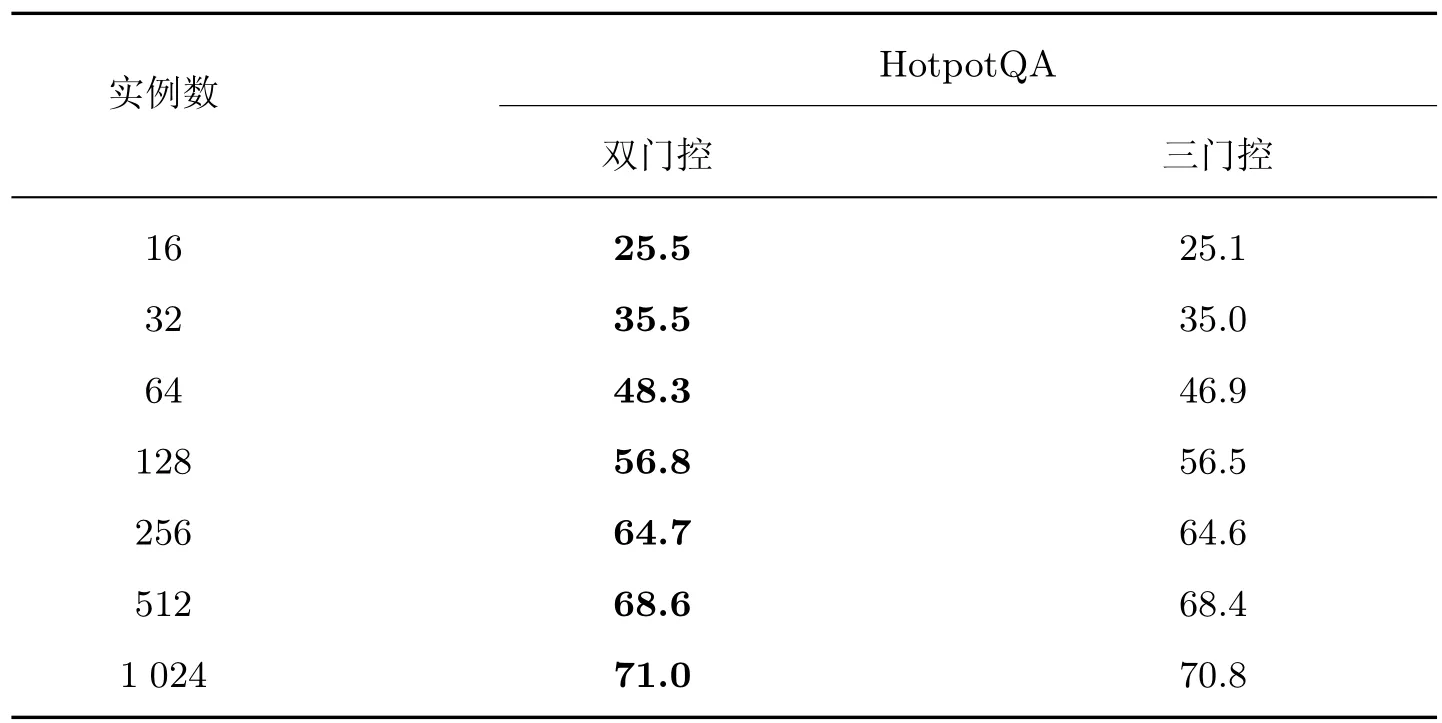
表6 双门控和三门控纵向对比实验Table 6 Comparison test of double and triple gate control
综上所述,相较于单门控机制和三门控机制,模型使用双门控机制能够最有效地实现标签间的语义融合,更显著地提升模型性能。
4 结语
本文旨在通过基于门控机制的多标签语义校准方法,利用全局语义信息解决小样本EQA任务中基线模型的语义校准问题。该方法使用特殊标签[QUESTION] 与头标签[CLS] 构成多标签,并构建双门控机制实现多标签间的语义融合。通过这种方式,本文提出的方法能够有效保留[QUESTION] 标签中的语义信息,并引入更多的全局语义信息。在模型预测时,通过引入的全局语义信息可以提升模型对上下文的敏感度,使模型更准确地进行答案预测。本文通过在56 组小样本EQA 数据集上进行实验,证明了该方法的有效性。实验结果表明,本文方法在预测准确性方面表现出色。这意味着本文模型能够更好地适应和处理小样本EQA 任务,提高了问题回答的准确性。这对于提高语言输出的质量和降低误解的概率都具有重要意义。
然而,在引入全局语义信息的过程中,仅通过构建多标签语义融合的方式可能存在局限。因此,未来的工作将尝试双仿射与现有任务的结合,通过获取并筛选[QUESTION] 标签与句中每一个字的语义交互信息,进一步在训练数据极其有限的情况下为模型预测引入更多的语义信息,提高模型在小样本EQA 任务中的预测能力。
