融合GhostNet 的YOLOv5 垃圾分类方法*
2024-02-17胡军国
李 耀,胡军国,乐 杨
(浙江农林大学 数学与计算机科学学院,浙江 杭州 311300)
0 引言
近年来,随着我国城市人口的增加,城市生活垃圾总量增长迅速。据相关统计,我国城市生活垃圾清运量已经从2004 年的15 509 万吨增长为2021 年的24 869 万吨。自党的十八大以来,党中央高度重视生态文明建设,垃圾处理问题已经成为城市生活中必须解决的问题,在城市社区生活中,居民垃圾分类的意识较弱,且较多依赖于传统人工分拣,传统人工分拣存在耗时长、效率低、工作环境差及精准度较低等问题。若有效地利用计算机视觉技术对垃圾进行目标检测,通过对垃圾目标的快速定位和精确分类,将极大地减少人力资源的消耗,有效地提高垃圾分类效率,为后续的垃圾回收工作提供支持,进一步改善城市人居环境。
计算机视觉技术常用的目标检测方法有3 种,分别是Blob 分析法(Blob Analysis)[1]、模板匹配法、深度学习法。Blob 分析是对图像的连通区域进行检测,从而识别目标。模板匹配法是通过研究某一特定对象物的图案位于图像的什么地方,进而识别对象物体。深度学习法首先提取出大量圈中对象的候选框,然后通过神经网络将正确的候选框进行输出。Blob 分析法和模板匹配法属于人工设计其特征表示,迁移性差,精度低。深度学习法则是通过算法提取合适的目标特征表示,相比人工特征设计更高效,且能适用于更多场景。
目标检测是计算机视觉领域的主要研究方向之一,在人脸识别、智慧交通、自动驾驶等领域广泛使用,具有十分重要的研究意义。目前目标检测领域的深度学习方法主要分为双阶段(tow-stage)算法和单阶段(onestage)算法两类。双阶段算法通过算法生成候选框,再使用卷积神经网络对进行目标分类和定位,代表算法有Faster R-CNN[2]、R-FCN[3]、Fast R-CNN[4]。单阶段算法通过滑窗的方式直接产生候选框,再进行分类与回归识别目标,代表算法有YOLO[5−7]系列、SSD[8]系列。由于两者的策略不同,导致前者在准确率和定位精度上占优,后者在检测速度上占优。
随着计算机视觉技术的成熟,许多学者针对垃圾目标检测问题提出了深度学习解决方案。如:康庄等[9]提出基于Inception V3 特征提取网络的垃圾分类算法,对自制数据集中两大类垃圾的识别率达到99.86%;王莉等[10]提出基于YOLOv5s 网络的垃圾分类算法,对具体的12 种垃圾,精度达到95.34%,而计算性能要求较高,网络体积较大;陈志超等[11]提出基于MobileNet V2 的垃圾图像分类算法,通过嵌入通道注意力算法,在自制数据集中14 类具体垃圾的精度为94.6%。上述方法中数据集分类无法完全满足实际生活中垃圾分类场景的需求,且网络体积较大,不适合移动端服务部署。
本文基于4 类城市垃圾分类检测任务,提出一种融合GhostNet 网络和改进版通道注意力的垃圾分类算法,使用轻量化卷积Ghost Module 降低特征模型体积和计算量,并保证模型精度,融合注意力机制加强特征图的整体通道特征,得到识别精度高、推理速度快的轻量化模型。
1 理论基础
1.1 YOLOv5 网络结构
YOLOv5 识别精度高、推理速度快,同时YOLOv5 模型包含多尺度的检测头能检测图像中不同大小的目标,能通过参数控制网络深度和宽度能自由选择参数大小合适的模型。通过比较不同模型的精度、体积和推理速度,本文选择YOLOv5s 作为基线模型。
YOLOv5s 网络结构可分为输入端、主干网络、颈部网络和检测头。输入端负责图像处理方法和自适应锚框计算,有效地提升了数据多样性;主干网络包含特征提取模块CBS、跨阶段局部网络(Cross Stage Partial Network,CSPNet)[12]架构模块C3 和金字塔池化模块(Spatial Pyramid Pooling-Fast,SPPF);颈部网络采用路径聚合网络(Path Aggregation,PANet)[13]结构,充分融合了不同层的特征;Head 部分主要用于检测目标。
1.2 GhostNet 原理
GhostNet[14]是一种使用少量的参数生成特征的网络,其基本单元Ghost Module 分2 步生成特征图,先使用少量卷积核进行传统卷积生成通道较少的特征图;再对第一步操作获得特征图进行逐层卷积获得更多的特征,最后进行特征连接获得完整的特征信息,Ghost Module 模块原理如图1 所示。

图1 Ghost Module 模块原理
Ghost Module 具体计算过程为:
第一步为普通卷积,式(1)中,X为输入的特征图,Y′为输出的原始特征图,f′为使用的卷积核;第二步操作是对第一步输出的原始特征图进行线性运算,式(2)中,yi'为Y′中的第i个特征图,Φi,j为第j个线性映射,yi,j是由第i个原始特征图生成的第j个幻影特征图(ghost)。最后将第一步生成的特征图与第二步操作生成的特征图进行concat的操作,得到完整的特征图。与传统卷积相比,Ghost Module 不改变输出特征图大小,缩减了参数量和计算时间,实现模型轻量化[15]。
2 Ghost-YOLOv5 网络模型设计
本文的模型设计以设计小体积、高精度垃圾分类模型为目标,以YOLOv5s 网络为主干,融合高效通道注意力模块、融合GhostBottleneck 的CSP 模块和Ghost 卷积模块形成新的特征提取网络。具体网络结构如图2 所示,其中GhostC3 模块代表融合GhostBottleneck 的CBS模块,GhostConv 模块是融合Ghost 卷积的特征提取模块,改进后网络结构如图2 所示。

图2 Ghost-YOLOv5 网络结构图
2.1 融合GhostNet 的主干网络
YOLOv5 的主干网络是借鉴了CSPNet 的架构。CSPNet 通过将梯度的变化集成到特征图中,解决了梯度信息重复的问题。YOLOv5 中基础的CSP 模块为C3模块。C3 模块是3 个标准卷积层和多个残差模块Bottleneck 组成,C3 模块结构如图3 所示。

图3 C3 模块结构图
为了使用最少的计算量和参数达到最佳的性能,本文参考华为提出的轻量级网络GhostNet。GhostNet 中的残差元GhostBottleneck 分为两种结构,如图4 所示。步长为1 时,直接进行两个Ghost 卷积操作;步长为2 时,使用步长为2的DW卷积[16]连接2个Ghost Module,GhostBottleneck 结构如图4所示。

图4 GhostBottleneck 的结构图
本文使用GhostNet 中的残差模块ChostBottleneck 替换C3 模块中的标准残差模块,形成新的CSP 单元GhostC3 模块。GhostC3 模块计算简易、体积小、计算量小,能有效降低网络体积和计算速度。GhostC3 模块结构如图5 所示。
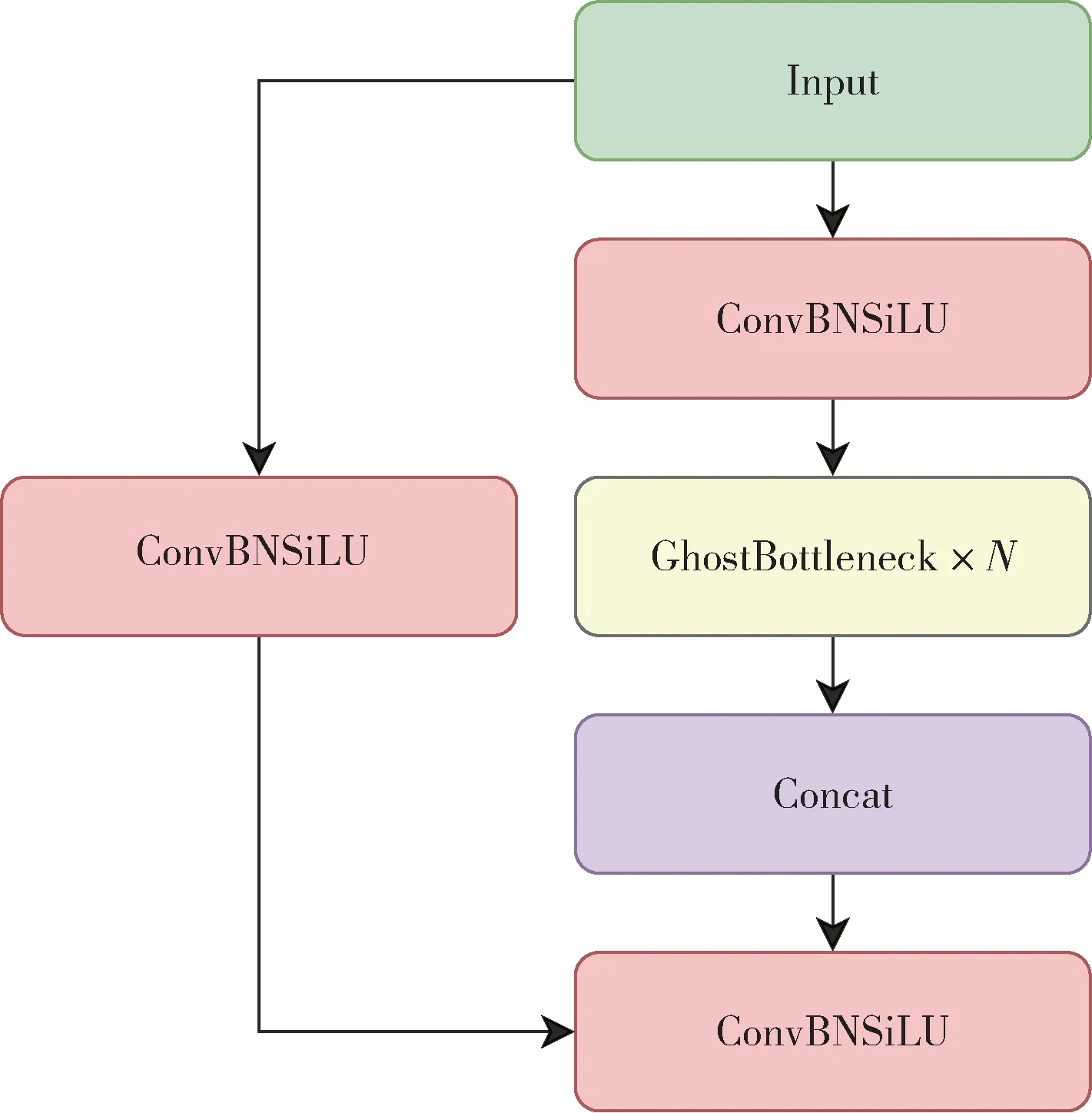
图5 GhostC3 模块结构图
YOLOv5 主干网络中另一个基础模块是卷积模块CBS,CBS 模块由二维卷积层、正则化层和激活函数层组成。本文结合CBS 模块和Ghost Module 的设计原理,提出GhostConv 模块。使用GhostConv 模块后网络体积进一步降低,CBS 模块和GhostConv 模块如图6所示。

图6 CBS 和GhostConv 结构图
2.2 加权边界框融合
YOLOv5 在预测阶段产生了多个预测框,为了确定目标的位置,需要对预测框进行筛选。YOLOv5 采用非极大值抑制(Non-Maximum Suppression,NMS)[17]筛选预测框,NMS 判断预测框之间的交并比(Intersection Over Union,IoU)[18]是否高于阈值,并舍弃其中IoU 低于阈值的框。因此会导致有用的目标信息丢失,造成误检或漏检。本文提出采用加权边界框融合(Weighted Boxes Fusion,WBF)[19]方法,WBF示意图如图7所示。其中(x1,y1)和(x2,y2)分别代表预测框左上角和右下角的坐标,c表示预测框的置信度得分,下标i表示第i个预测框的相关数据。
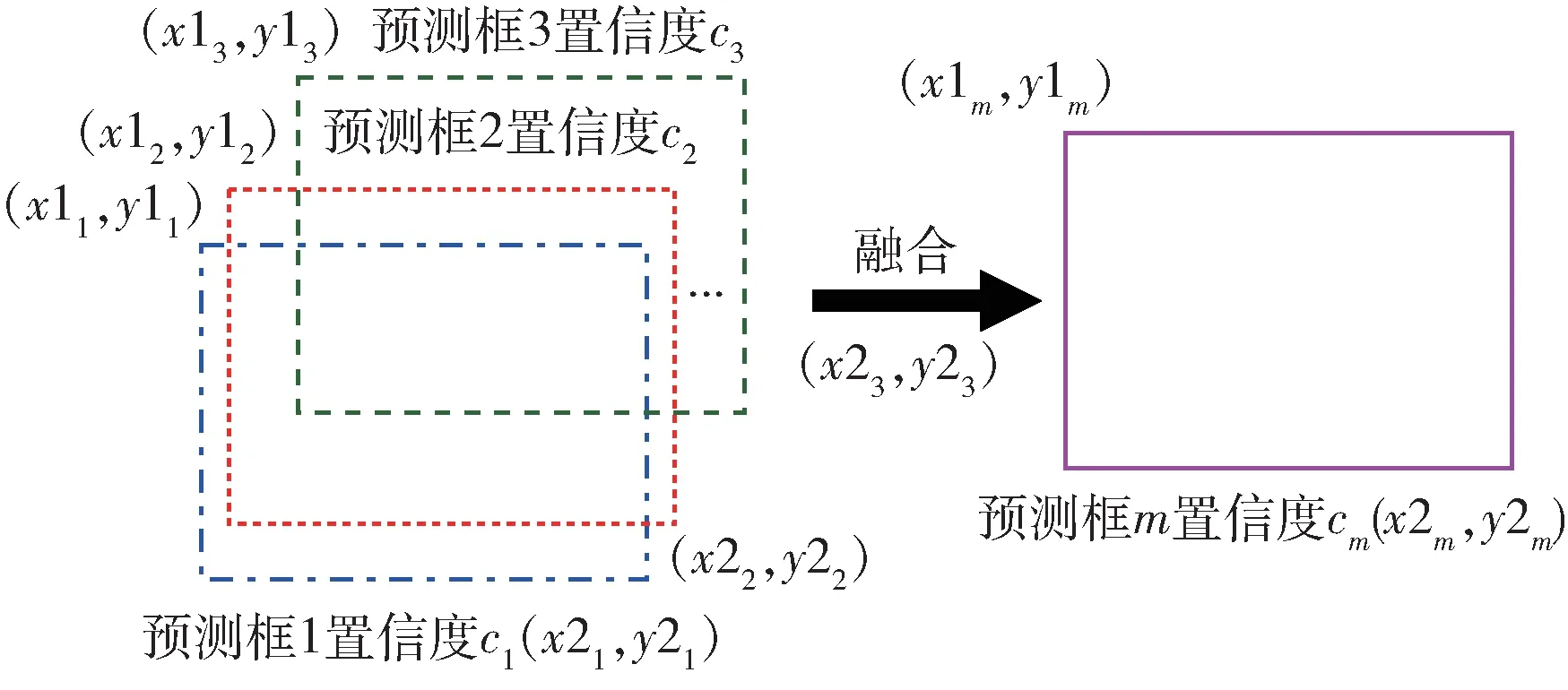
图7 WBF 示意图
WBF 通过置信度信息和每个预测框的位置信息生成最后的融合预测框,根据置信度分数赋予每个预测框权重,融合了每个预测框在检测框生成中的作用。WBF 算法在计算过程中将检测预测框与融合框的IoU 是否大于阈值,若符合要求,则按式(3)更新融合框。
其中,n表示符合条件的预测框数量。
图8 为垃圾目标的预测结果示意图,相较NMS 方法,WBF 在定位精度上有明显提升。

图8 垃圾目标预测示意图
2.3 ECA 模块
压缩激励网络(Squeeze-and-Excitation Networks,SENet)[20]将信息通道注意力引入卷积块,提升模型对通道特征的敏感性。改进通道注意力(Efficient Channel Attention,ECA)[21]在SE 注意力基础上进行了改进,ECA 提出了用一维卷积实现了局部跨通道交互,可以在保持性能的同时显著降低模型的复杂性。
ECA 模块的具体做法是使用全局平均池化(Global Average Pooling,GAP)对特征图进行空间特征压缩,得到1×1×C的通道注意力特征图,再对压缩后的特征图进行快速一维卷积,最后将通道注意力和原始特征图进行逐通道相乘并输出,ECA 模块结构如图9 所示。

图9 ECA 模块示意图
在进行快速一维卷积时,ECA 模块使用了动态的卷积核,来解决不同输入特征图,提取不同范围特征的问题。ECA 使用了自适应的方法确定卷积核大小K,卷积核自适应函数如式(4)所示,C表示通道数,odd 表示K只取最接近的奇数,γ和b用于改变通道数C和卷积核大小之间的比例,本文中γ和b分别取2 和1。
3 实验部署与结果分析
3.1 实验平台和训练参数
本文实验平台基于PyTorch1.7.0 深度学习框架和CUDA 11.0.3 网络加速库,开发语言为Python3.7.0,使用Windows 10操作系统,GPU 为 NVIDIA GeForce RTX2070 super。实验训练超参数设置如表1 所示,实验过程中使用余弦退火(Cosine Annealing)[22]优化算法控制学习率动态变化。

表1 训练参数设置
3.2 实验数据集
实验使用数据集为自制垃圾数据集,该数据集包含4 大类图片可回收垃圾(recyclable waste)、有害垃圾(hazardous waste)、厨余垃圾(kitchen waste)和其他垃圾(other waste)共2 748 张,通过网络收集了2 300 张。另外通过手机拍摄生活垃圾照片作为数据集的补充,图片均完成标注。图10 为数据集中的部分样本。

图10 部分训练数据集图像
3.3 评价指标
本文选用精确率P(Precision)、召回率R(Recall)、平均精度均值(mean Average Precision,mAP)和F1 分数作为模型精度衡量指标。四者依赖于混淆矩阵(Confusion Matrix)的计算。混淆矩阵如表2 所示。

表2 混淆矩阵
精确率计算公式如式(5)所示,召回率的计算公式如式(6)所示。
由于P值与R值是矛盾的,一者上升则另一者下降,因此本文采用F1 值综合评价模型的优劣,计算方法如式(7)所示。
mAP 指标表示多个类别的平均精度的均值,即所有AP 的平均值,AP 指单个垃圾类别的平均精度,计算方式见式(8)、式(9)。
3.4 不同注意力机制分析
为了证明改进算法的注意力机制有效性,在控制其他条件相同的情况下,仅对注意力机制类型进行修改,实验结果如表3 所示。由表3 可知,ECA 注意力的mAP提高了3.9%,表明其特征信息的获取能力更好。
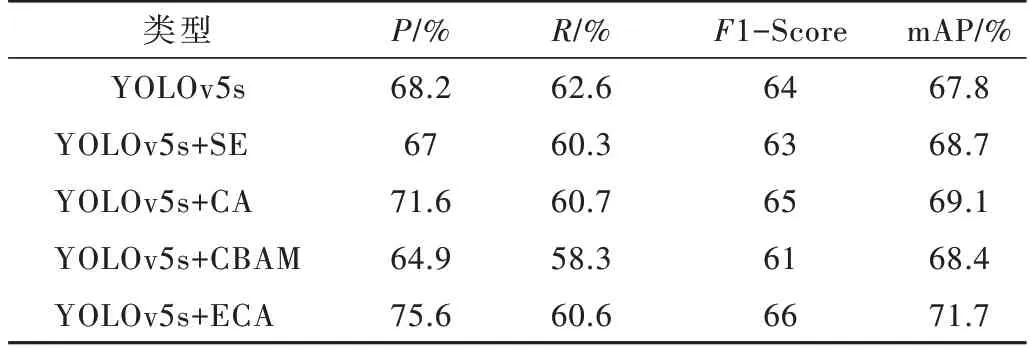
表3 不同注意力机制对比
3.5 消融实验
为了更好地分析各个模块对模型的影响,本小节进行消融实验。消融实验以YOLOv5s 作为消融实验的基准,将本文提出的各个改进模块依次融合到YOLOv5s中,并保持每组实验的实验环境和模型超参数相同,在自制数据集上进行训练,在相同的测试集进行性能测试,比较添加不同改进模块对模型性能的影响。实验结果如表4 所示。
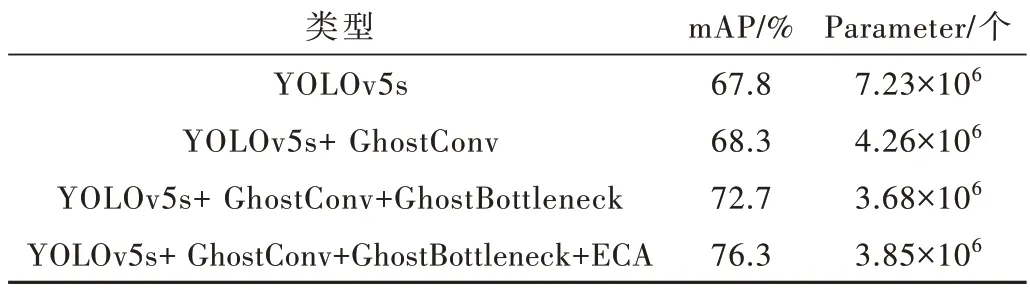
表4 消融实验结果
从实验结果可知,融合GhostConv 和GhostBottleneck 能在保证精度的同时参数量减少了46.7%。在加入ECA 模块后参数量仅增加4%,模型精度提升了3.6%。由此可知,本文所进行的模块改进实现了精度提升和模型轻量化。
3.6 对比实验
为了证明本文提出的轻量级目标检测算法的有效,本节设计了对比实验。对比算法的对象有YOLOv4、YOLOv5s、ShuffleNet V2[23]和GhostNet,参与对比的网络模型输入大小均为640 px×640 px。将本文提出的Ghost-YOLOv5 与其他目标检测模型分别在本文数据集上进行训练,然后比较它们在验证集上的检测性能,实验结果如表5 所示。其中Ghost-YOLOv5 网络参数数量约为3.85×106,mAP 值为76.3%,识别平均用时为11.23 ms,模型精度较高、参数量少,具有较好的实时能力。

表5 不同模型对比实验
4 结论
本文对YOLOv5s 网络进行了改进,使用Chost-Bottleneck 替换了C3 模块中的标准残差模块,并采用线性变化的卷积模块代替了传统卷积模块,保证网络精度的同时实现了网络的轻量化;在主干网络引入注意力机制ECA,使用低消耗的局部跨信道交互策略加强了特征图的整体通道特征,使模型更加关注感兴趣的位置,提升了模型精度;在预测阶段使用加权边界框融合算法,有效解决了漏检和预测结果偏移的问题。改进前后模型的对比实验表明,在相同测试集下mAP 由67.8% 提升至76.3%,推理速度达到11.23 ms,模型参数量显著降低。本文提出的算法速度快、精度高、体积小,适用于移动端设备的部署,满足快速识别的需求。
本文研究算法主要解决了低复杂度、少目标图像的分类识别问题,在后续工作中将着重提高模型在多目标、多类别和目标遮挡的复杂场景下的识别精度,拓宽模型应用场景。
