基于深度学习模型识别风电场避让物的方法研究
2024-02-10雷鸣
雷 鸣
(1. 中国电建集团西北勘测设计研究院有限公司,西安 710065;2. 中铁第一勘察设计院集团有限公司,西安 710065)
0 引言
2020 年9 月,中国明确提出了2030 年碳达峰与2060 年碳中和的目标[1]。根据云南省绿色能源行业协会发布的统计数据,截至2022 年9 月底,中国风电新增装机容量为1924 万kW,其中,西北、华北和东北地区(下文简称为“三北”地区)的风电新增装机容量占比约为74.3%。“三北”地区的风电场以风电基地项目居多,而目前新建风电场不仅需要避让生态保护红线、永久基本农田、自然保护区、风景名胜区等国家限建区域,以及需要考虑风电场内风电机组之间的尾流影响,还需要重点关注周边已建风电场对新建风电场的尾流影响。工程中针对尾流影响的计算,通常采用当地遥感影像对周边已建风电场的风电机组机位进行人工标记,然后将标记后的风电机组机位与拟建风电场的风电机组机位共同建模,进行尾流计算。但该方法的工作效率低,过失误差较大。
根据国家发展和改革委员会能源研究所的统计,截至2021 年年底,中国现有在役风电机组超过14 万台,其中,0.85~1.5 MW 的风电机组超过5万台。据其测算,在2021—2030 年期间,中国风电机组累计改造退役容量将超过6000 万kW。由此可见,未来需要进行技改的老旧风电场规模十分可观。
早期建设的风电场大部分位于平原地区,需要进行技改的老旧风电场通常已运营多年,且其周边也已建有大量风电场。老旧风电场在进行技改时需要对风电机组机位进行重新布置,除考虑要利用既有集电线路、既有道路等已建设施之外,其他风电场对本风电场的尾流影响也不可忽视。但由于老旧风电场附近环境复杂、已建风电机组数量多,采用人工标记已建风电机组机位的方式容易出现缺漏。
针对新建风电场和老旧风电场技改中风电机组机位的布置,本文提出一种基于深度学习模型识别风电场避让物的方法,利用深度学习模型对遥感影像中已建风电场风电机组和民房等敏感因素进行识别标记,采用OpenWind 软件对这些敏感因素进行避让,并快速进行风电机组布置。
1 风电机组机位选址
风电机组机位的布置需要考虑以下几点:
1)需要考虑该位置的风能资源禀赋性。测风塔实测数据只能代表该位置的风能条件,需要利用Meteodyn WT、WindSim、OpenWind、WAsP等风电场风资源仿真软件对场区内各位置的风能资源进行推算。
2)风电机组机位选择时需要避开国家公园、森林公园、压覆矿区域、自然保护区、永久基本农田、生态保护红线、饮用水源保护区、风景名胜区等限制建设区域。
3)合适的避让距离。由于风轮转动时将产生噪声,风电机组布置时应保证与附近民房相隔一定的距离,使风电机组运行时的噪音经过距离衰减后符合GB 3096—2008《声环境质量标准》的要求,但各省市针对避让距离的要求并不统一,大多数在300~500 m 之间。
4)无论是中国早年开发的风电场,还是目前新建的风电基地项目,大多数都建于平原地区;同时,这些风电场周边也已建有其他风电场。因此需要考虑周边风电场对本项目的尾流影响。
目前,获取周边风电场的风电机组机位点坐标的方法有以下4 种:
1)实地走访。通过现场踏勘的方式,利用实时动态(RTK)载波相位差分技术测量仪等工具逐个采集周边风电场的风电机组机位点坐标。该方法的优点是获取的机位点坐标准确、精度高;但缺点是耗时、耗力,并且容易产生遗漏。
2)资料收集。向当地政府或周边风电场业主收集各场区内的风电机组机位点坐标。该方法的优点是获得的机位点坐标准确,不易遗漏;但缺点是由于沟通对象较多,协调工作量大,配合困难,工作进度不可控。
3)利用遥感影像人工识别。工程师采用当地遥感影像对周边已建的风电机组和民房进行逐个标记。该方法的优点是工作进度可控,协调工作量小,易于实施;但缺点是所获得的数据质量完全取决于工程师的细心程度,容易造成风电机组机位统计的缺漏,过失误差较大。
4)基于深度学习模型识别风电场避让物。为降低过失误差,提高遥感影像的识别效率及精度,本文提出基于深度学习模型识别风电场避让物的新方法,利用训练后的深度学习模型对遥感影像中的风电机组和民房进行识别标记,并绘制场区民房分布图及风电机组机位分布图,获取风电机组机位点坐标。该方法利用计算机分析并标记避让物可有效消除过失误差,同时借助计算机运算可极大提高识别风电场避让物的工作效率和结果精度。同时,工程师可利用识别结果与遥感影像进行快速比对,判断模型质量并对结果进行校核。
2 深度学习模型
深度学习模型是基于人工神经网络算法衍生出的一种模型,该模型通过建设多层运算层次结构[2],利用给定的输入层和输出层,通过网络的学习和调整参数权重,建立起输入层和输出层的函数关系,并逐步修正其误差[3]。深度学习模型可以根据不同的数据集进行自我调整,以适应不同的应用场景。
该模型旨在建立输入层与输出层的函数关系。通过训练样本对模型进行学习与修正,然后利用修正后的模型对遥感影像进行避让物识别与标记。首先利用模型中的卷积神经网络(CNN)算法提取遥感影像中的信息;然后逐层建立神经元,在神经元网络中,除顶层外其他所有层的权重均设置为双向,正向传播时的权重用于“认知”,反向传播时的权重用于“生成”;最后采用CNN算法进行“正向传播-反向传播”循环迭代,调整除顶层外其他所有层的权重,使输入层和输出层的结果达成一致。
深度学习模型的工作流程图如图1 所示。
3 基于深度学习模型识别风电场避让物方法的具体措施
3.1 避让物识别
本文提出的基于深度学习模型识别风电场避让物的方法中,避让物识别的具体步骤包括训练区避让物标记、训练区避让物特征值导出、模型训练、避让物提取 。
1)训练区避让物标记。截取遥感影像中的部分区域作为模型的训练区域,利用特征提取骨干网络(convolution network)得到训练区域的特征图。在训练区域内对风电机组、民房等需要避让的物体进行人工标记。
2)训练区避让物特征值导出。在对应的坐标系内,通过指定的切片尺寸对所有标记出的避让物进行切片并提取其特征。
3)模型训练。将样本数据输入至模型,利用Mask R-CNN 算法使输入层与输出层的结果达到一致。Mask R-CNN 算法采用ResNet 残差网络算法完成多层预测与赋权重,可使预测结果的准确度不随卷积层层数的增加而下降[4]。模型采用双线性差值(RPN)算法,对训练区域生成的特征图的规律生成一系列的锚框,并判断锚框中是否存在待识别物体。通过深度学习模型不断的“正向传播-反向传播”循环迭代,调整模型中除顶层外其他所有层的权重,使对锚框中避让物的识别更加准确[5]。
4)避让物提取。导入需要标记避让物的遥感影像,然后利用训练后的深度学习模型对遥感影像中的避让物进行自动识别、标记、导出。
3.2 遥感影像区域的风能资源评估
将处理后的实测地形图,当地的欧空局全球陆地覆盖数据(ESA)、美国国家土地覆盖数据库(NLCD)等粗糙度图谱,以及测风塔测风数据作为输入文件,导入由法国美迪公司开发的Meteodyn WT 或挪威WindSim 公司开发的WindSim 等流体力学计算(CFD)软件中,通过求解Navier-Stokes方程,仿真遥感影像区域的风流运动,求得该区域风能资源分布图谱。
3.3 风电机组机位布置
OpenWind 软件可利用地理信息和风能资源模型对风电机组机位进行自动寻优排布[6]。
1)在OpenWind 软件中导入由深度学习模型提取的周边风电场中已建风电机组的机位点坐标,用于测算风电场之间的尾流影响。
2)输入由深度学习模型绘制的场区民房分布图及当地的限制建设区域分布图。风电机组布置时还需要再考虑与周边民房之间的距离,避让距离为300~500 m。
3)在OpenWind 软件中导入前面得到的遥感影像区域风能资源分布图谱,利用该软件的自动寻优功能,对风电机组机位进行寻优排布。
4 案例分析
以宁夏回族自治区某风电场为例,采用本文提出的基于深度学习模型识别风电场避让物的方法进行老旧风电场技改的风电机组机位选址分析。该风电场于2007 年3 月投产,属于平原风电场,共安装了66 台由金风科技股份有限公司生产的750 kW 风电机组,总装机容量为49.5 MW。该风电场场址范围内设立了1 座测风塔,编号为0001#。
该风电场属于宁夏回族自治区最早开发建设的风电场之一,项目所在区域的风能资源已被充分开发利用,其周边建有多个风电场。该风电场已运行16 年,根据国家能源局2023 年发布的《风电场改造升级和退役管理办法》,该风电场具备改造升级条件,计划对其风电机组机位进行重新规划布置。
该风电场内测风塔的基本信息如表1 所示,其地理位置示意图如图2 所示。

表1 测风塔的基本信息Table 1 Basic information of anemometer tower
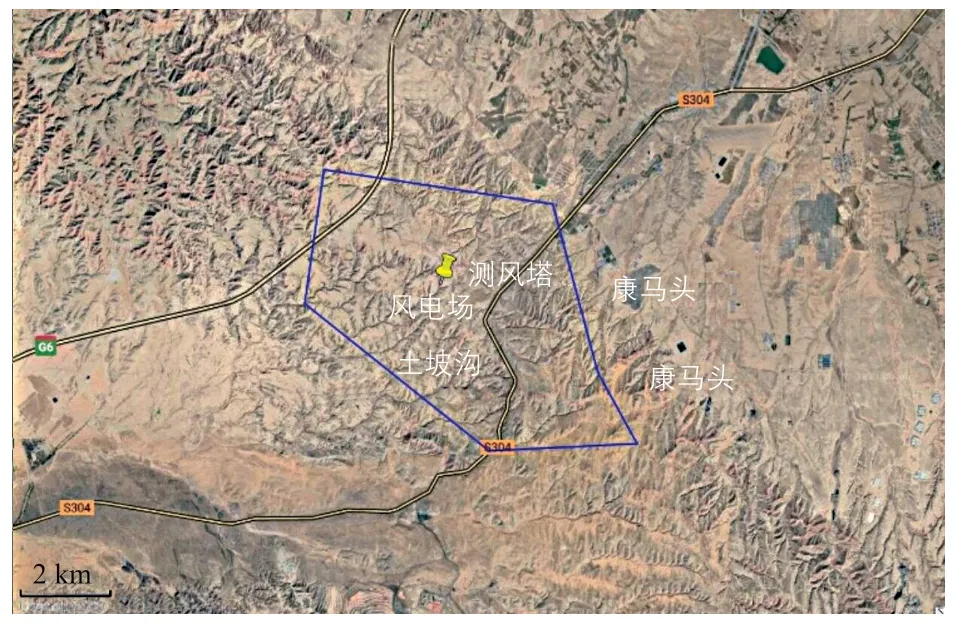
图2 测风塔的地理位置示意图Fig. 2 Geographical location diagram of anemometer tower
测风塔有效数据的完整率大于90%;再加上该风电场的地形为平坦地形,测风塔所在位置的海拔高度与场区平均海拔高度接近,因此该测风塔处的风能资源数据具有较好的代表性。该测风塔115 m 高度处:代表年平均风速为5.82 m/s,平均风功率密度为180 W/m2;风向主要集中在正南,占全部风向分布的24.68%;风能也主要集中在正南,占全部风能分布的28.35%;平均空气密度为1.032 kg/m3;综合切变指数为0.109;15 m/s 风速段的湍流强度为0.116。该风电场场区的风能资源分布图如图3 所示。
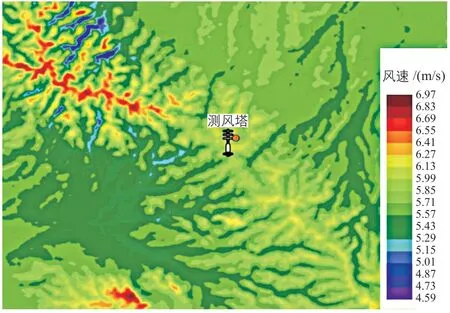
图3 该风电场场区的风能资源分布图Fig. 3 Wind energy resource distribution map in the wind farm area
根据项目区域特点,本次深度学习模型“前后循环迭代次数”设置为“20 回”,“验证百分比”设为“10%”,“切片尺寸”设置为“1000 pix”,“步幅”设置为“256 pix”,“旋转角度”设置为“0”。
通过深度学习模型识别出遥感影像区域内已建风电机组共有436 台,其中包括该项目的66 台原有风电机组。为了展示识别标记的效果,局部遥感影像区域内已建风电机组的分布图如图4 所示。图中:红框内容为识别的红色标记的放大图。
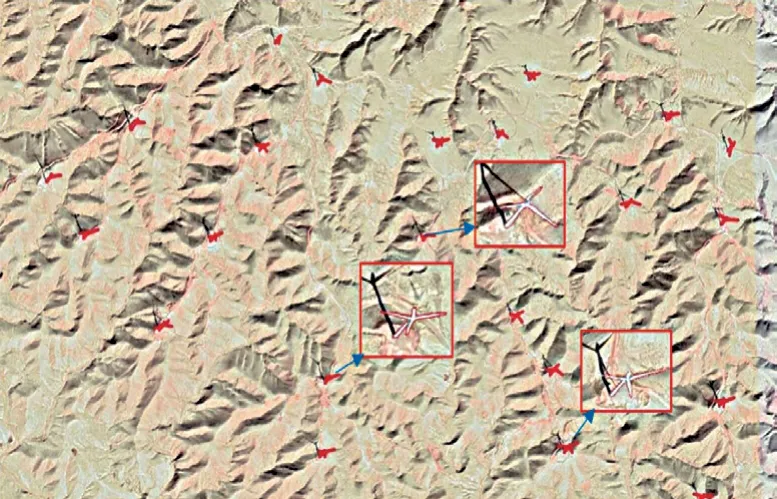
图4 局部遥感影像区域内已建风电机组分布图Fig. 4 Distribution map of existing wind turbines in the local remote sensing image area
利用OpenWind 软件进行风电机组寻优排布后,该风电场改造为采用10 台5 MW 风电机组,改造后风电场的年上网电量预计为13246 万kWh,年等效满负荷小时数预计为2676 h。改造方案的推荐风电机组机位点与周围已建风电机组机位点的相对位置如图5 所示。图中:蓝色点为推荐风电机组机位点;红色点为周围已建风电机组机位点。

图5 改造方案的推荐风电机组机位点与周围已建风电机组机位点的相对位置图Fig. 5 Relative position map of recommended wind turbine location points for renovation plan and surrounding existing wind turbine location points
5 结论
本文提出一种基于深度学习模型识别风电场避让物的方法,利用深度学习模型对遥感影像中的已建风电场风电机组和民房等敏感因素进行识别标记,采用OpenWind 软件对这些敏感因素进行避让,并实现风电机组快速布置,得出以下结论:
1)利用深度学习模型绘制场区民房分布图及风电机组机位分布图,获取风电机组机位点坐标,结果准确、不易产生遗漏、能够有效消除过失误差。同时,工程师可利用该民房分布图和机位分布图与遥感影像进行快速比对,判断模型质量并对模型生成的成果进行校核。
2)深度学习模型可以根据不同的数据集进行自我调整,从而适应不同的应用场景,因此可以利用深度学习模型对民房、厂房、牛棚、110/220kV 铁塔、沟渠、河道、道路、光伏电站等风电场避让物进行标记。
3)利用深度学习模型进行避让物标记的方法大幅降低了人工标记避让物时的工作量,有效减少了大量的繁杂、低效、高重复性的工作,提高了工作效率。
需要说明的是,深度学习模型是通过对比训练区域特征图与标记处的特征值,不断修正模型中除顶层外其他所有层的权重,从而提高识别精度的方法。因此,在训练区避让物标记这一步骤中,人工标记避让物时不能漏标避让物,否则会引入极大的误差,从而严重降低训练模型的精度。
本方法对遥感影像的分辨率和计算机配置的要求较高。随着遥感影像分辨率的增加,深度学习模型的识别精度会显著提高。深度学习模型擅长图像处理、文本分析领域,通常来讲,使用图形处理器(GPU)训练模型的效率更高。
