基于密集连接和多尺度池化的X射线焊缝缺陷分割方法
2024-01-31张勇王鹏吕志刚邸若海李晓艳李亮亮
张勇, 王鹏, 吕志刚,, 邸若海, 李晓艳, 李亮亮
(1.西安工业大学 电子信息工程学院, 陕西 西安 710021;2.西安工业大学 发展规划处, 陕西 西安 710021;3.西安工业大学 机电工程学院, 陕西 西安 710021)
1 引言
随着我国石油天然气行业的高速发展,输送油气管道的焊接质量问题[1]显得尤为重要。X射线成像[2]成为工业界焊缝缺陷检测[3]一个重要的研究手段。该方法利用X射线对焊缝管道进行照射,进而获取焊缝内部的形态图像[4]。对焊缝缺陷检测和评估质量的传统方式是通过工程师经验来评测,此方式存在检测人员评判标准不一、费时费力、检测误差大等问题。
为了提高焊缝底片评测[5]的精度和效率,许多科研工作者试图提取缺陷区域[6]。文献[7]提出了一种利用拉普拉斯算子[8],根据缺陷的纹理特征来分割缺陷边缘,最后分类图像的特征信息的方法。Zhang[9]等人利用大律法(OSTU)结合部分不均匀像素分割焊缝,并通过串行区域分割方法识别缺陷。用图像处理的方法进行缺陷检测,噪声大且鲁棒性差。在传统机器学习算法中,高炜欣[10]等人研究焊缝缺陷,提出利用像素点个数的密度近似相等,采用聚类分析[11]的算法进行缺陷分割。Jiang[12]等人提出用主成分分析法[13]提取缺陷信息的特征,再采用支持向量机[14]对该特征进行缺陷分类。传统机器学习的方法在缺陷分割中的灵活性与精确性表现欠佳。
近年来,深度学习中的卷积神经网络在图像分割[15]任务中取得了很好的效果。人工智能也应用于越来越多的行业。在工业质检行业,人工智能和语义分割相结合有着广泛应用[16]。文献[17]提出全卷积神经网络(Fully Convolutional Networks,FCN),先输入图像,然后对最后一层特征图利用反卷积的方式进行加权,最后恢复到原尺寸大小,得到图像像素,保留原始信息,最后逐像素分类。该方法得到的结果在细节上不够敏感且特征表达不够准确。U-net[18](Unity Networking)属于FCN的变体,网络结构成U型对称,采用Encoder-Decoder[19]的设计思想实现特征融合,相比FCN有优势,但其在训练不同大小数据集时,模型结构不灵活。Schlemper[20]等人提出A-Unet(Attention Gated Networks)分割模型,即分割模型融入了注意力机制。该模型可以在相关任务中重点关注、捕捉感兴趣的区域而抑制无用特征,但存在边界分割不清晰等问题。Huang[21]等人提出了全尺度连接的Unet+++网络,该网络可以在一定程度上提高小缺陷分割精度,但无法保证边界缺陷的分割精度和数据不平衡导致的分割困难等问题,单一的密集连接[22],易造成过拟合现象。Qin[23]等人提出U2net网络用于图像分割,采用RSU(ReSidual U-blocks)的池化操作,在提升模型架构的基础上,不增加计算模型的复杂度。Chen[24]等人提出了DeepLabv3+分割算法解决下采样造成分辨率减小,导致分割精度降低的问题。上述方法在分割任务中均有应用价值,但在分割过程中,模型对于细节特征提取能力较弱且产生了大量冗余信息,导致在X射线缺陷数据集上表现不佳。
针对上述X射线焊缝缺陷分割的不足之处,本文提出了一种在上下采样间加入编解码信息提取模块DP_Block的U形网络Dilated_Pooling_Unet(DP_Unet),同时融入GAM(Global Attention Mechanism)注意力模块[25],最后提出了一种混合损失函数Dice_BCE,提升了网络对于焊缝缺陷的分割精确度。
2 Unet模型
Unet起初是一个应用于医学二维图像分割的卷积神经网络。作为最经典的语义分割模型之一,它的优势在于利用Encoder-Decoder的U形网络结构,Unet结构如图1所示,左侧由4个部分组成,每个部分中有两个卷积层,每部分之后会有一个激活函数和一个池化层操作。图像的起始分辨率为572²,每个模块的分辨率如图1标识。相应解码器也包含了4个部分,分辨率随着上采样操作而升高,从而得到最终图像。图1中灰色箭头表示跳跃连接,目的是连接上采样的输出结果和下采样中子模块有着相同大小的输出结果,作为该子模块的下一个模块的输入。
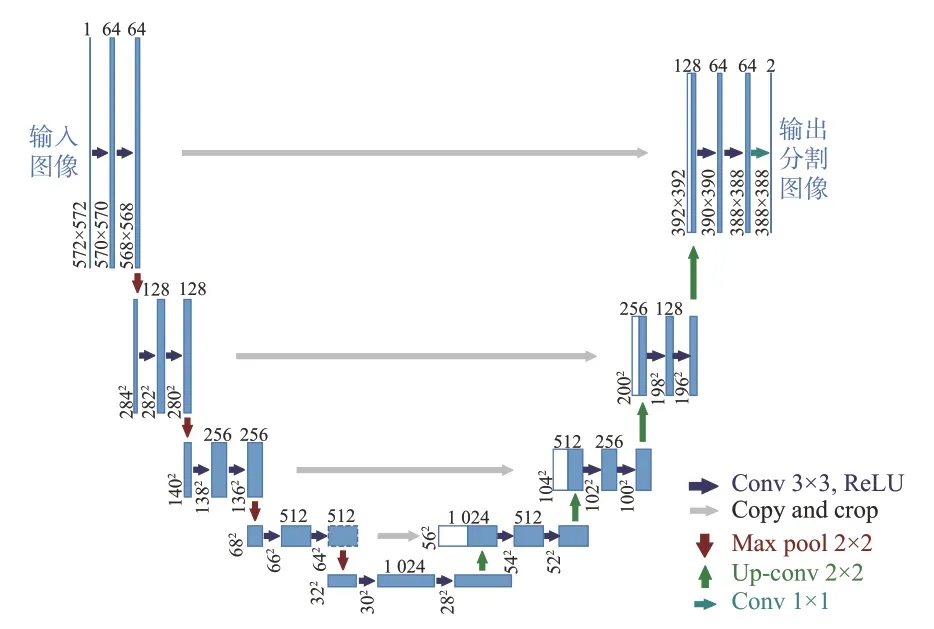
图1 Unet结构图Fig.1 Unet structure diagram
3 本文方法
Unet的缺点在于编码器部分的语义信息既可以通过跳跃连接也可以通过上下采样传递给解码端,从而产生冗余的信息。传递方式不一样,也会存在信息融合的不确定性,导致缺陷边界分割模糊,小缺陷分割精度低。另外,在下采样时随着分辨率升高而生成的浅层特征信息,其缺陷边缘有着不够充分的特征表现,且通过跳跃连接将编码端结果传至解码端时容易导致信息不完整,缺陷分割精度低。
针对上述Unet网络存在的问题。改进后的Dilated_Pooling_Unet(DP_Unet)网络模型如图2所示,本文有以下优化:(1)提出一个介于上下采样间的编解码语义信息提取模块DP_block,它由密集空洞卷积和多尺度池化层组成。通过增强焊缝缺陷信息及最大限度对缺陷进行特征提取来保留图片原始信息和提升焊缝缺陷分割效果。(2)将GAM注意力机制引入下采样中重点关注缺陷信息部分,改善缺陷分割模型效果差的问题。(3)提出一种混合损失函数Dice_BCE,具体为二元交叉熵(Binary Cross Entropy,BCE)和Dice函数采用不同比重相结合的混合损失,提升焊缝缺陷边界分割精确度和模型的泛化性。
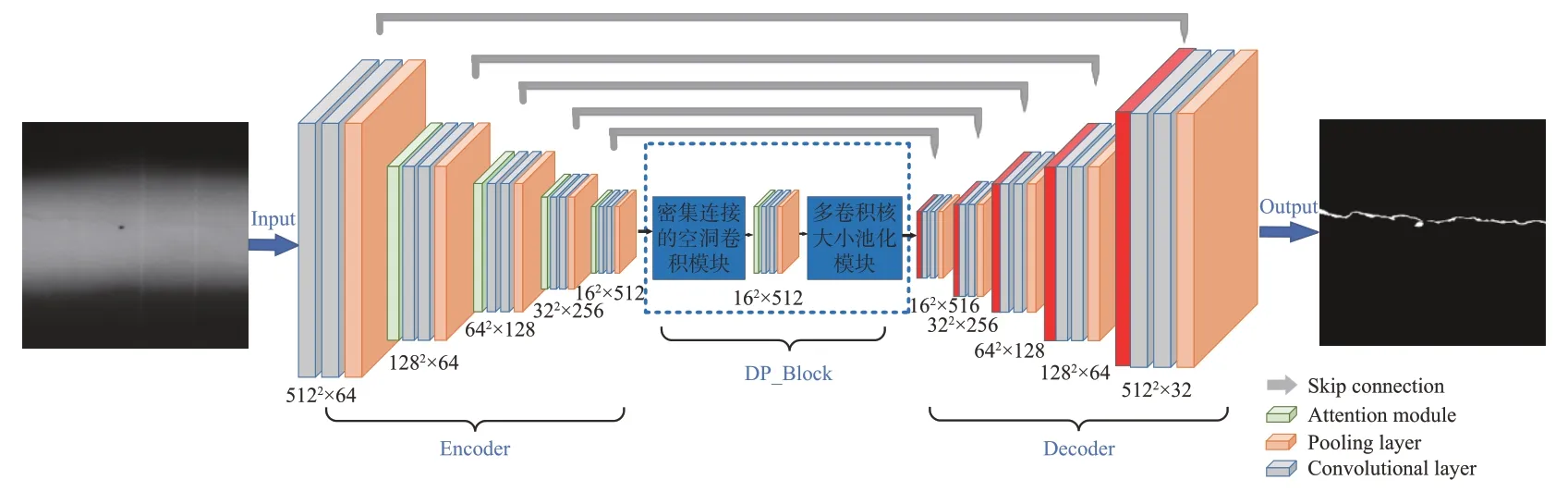
图2 DP_Unet模型图Fig.2 DP_Unet model diagram
3.1 DP_block
由于X射线底片焊缝上的缺陷具有丰富的语义信息及形状大小的不同,在缺陷分割任务中,浅层神经网络难以得到充足的特征信息。本文沿用Encoder-Decoder架构,提出在上下采样间加入编解码信息提取模块DP_block,旨在减少连续池化和卷积导致的信息损失,增强编码器下采样后X射线底片焊缝缺陷的语义信息及最大限度地对缺陷进行特征提取来保留图像原始信息,以便更好地服务于上采样过程,达到提升底片焊缝缺陷分割效果。它由基于密集连接的空洞卷积模块和基于空间金字塔的多卷积核大小池化模块组成。空洞(扩张)卷积网络[26]的提出是为了有效计算小波变换,后来用于解决图像语义分割的问题,空洞卷积引入”Dilated rate”参数,定义了卷积核各点之间的间隔数量,如图3所示,分别是该参数rate为1的标准卷积、rate为4和rate为6的空洞卷积。
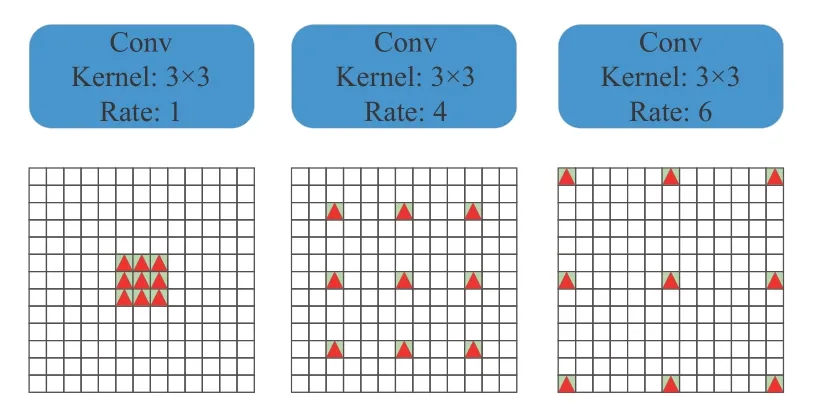
图3 感受野示意图Fig.3 Flowchart of height measurement
3.1.1密集连接的空洞卷积模块
深度学习中有Inception和Resnet两个经典架构。Inception系列结构使用了不同的卷积核大小来扩大感受野,Resnet则采用快捷机制避免梯度消失,使卷积神经网络层数突破上千。二者结合后,继承了两种优点,至此深度神经网络达到了新的高度。受上述机制和空洞卷积的启发,提出基于密集连接的空洞卷积模块,发挥提取高级语义特征的作用。如图4所示,密集连接的空洞卷积模块有4个分支,rate值随着卷积数量的增加而增加到1、4和6,每个支路的感受野大小分别是3、9、11和23。分别加入一个1×1卷积在并联支路中来线性激活。最后,如同resnet快捷机制,将原始特征与其他特征相融合。大目标的抽象特征往往被大感受野的卷积核所提取,而小感受野更适合于小缺陷。通过组合不同大小的rate值,该模块能够提取不同大小对象的特征。

图4 密集连接的空洞卷积模块Fig.4 Dense connected atrous convolution module
3.1.2基于空间金字塔的多卷积核大小池化模块
能够使用编解码器中有效语义信息的多少往往取决于感受野的大小,一般只使用3×3这种单个池化核进行池化操作。本文提出了基于空间金字塔的多卷积核大小池化模块。图5所示共4个不同大小的感受野池化模块,分别对应了4级输出,分别含有不同池化大小的特征图像。每池化一次,相应地用一个1×1卷积来减少计算成本和维数,将特征图像的权重维数减少为原始特征图像维数的1/K,K值为原始特征图像的通道数。然后网络通过上采样方式将低维特征图恢复至高维原始图像大小,最后将该特征图与上采样后的特征图连接。

图5 多卷积核大小池化模块Fig.5 Multi convolution kernel pooling module
3.2 GAM注意力模块
Unet模型通过下采样和跳跃连接来提取和传递有效特征信息,这种途径会导致传递冗余信息和传递过程中信息的不完整性和不确定性。针对上述两种方式融合,各维度特征进行简单拼接,从而无法获取丰富的特征信息,尤其对于焊缝缺陷这种具有小目标特征提取是不利的。因此,在编码器结构中加入一种全局注意力(Global Attention Mechanism,GAM)模块以提高上下文的联系能力。如图6所示,GAM注意力模块是一种序贯模式的通道-空间注意力机制,对CBAM(Convolutional Block Attention Module)[27]注意力机制进行重新设计,通过减少信息损失并放大全局交互表示来提高深度神经网络的性能。其中的通道(Channel)注意力模块在3个维度上使用三维阵列的方式来保存信息。然后,在跨维度模式下,利用一个多层感知机放大了通道和空间的依赖性;利用两个卷积层在空间(Spatial)注意力模块中融合空间层的信息,便于更好地关注空间信息。
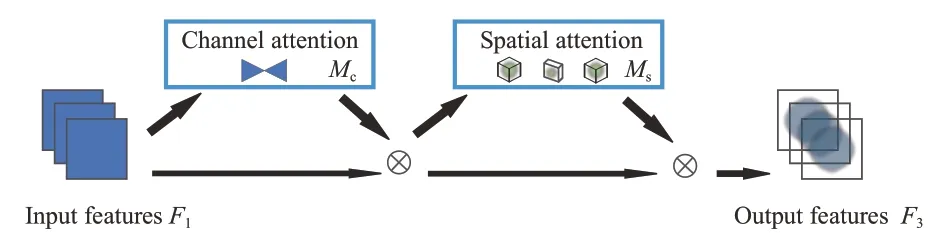
图6 GAM注意力机制Fig.6 Overview of GAM
如图6所示,给定输入特征映射F1∈RC×H×W,中间状态F2和输出F3定义如式(1)和式(2)所示:
其中:Mc是通道图,Ms为空间图,⊗是乘法操作数。GAM模块能够有效地学习通道和空间的特征信息,更加关注感兴趣的区域,在焊缝缺陷分割上具有良好效果。
3.3 损失函数
通常利用Dice损失函数来解决目标和背景部分的不平衡分割问题,Dice系数用来评估正类和负类的相似程度。
Dice_loss损失函数[28]如式(3)所示:
对于语义分割任务而言,其中的|X|和|Y|分别表示分割当中的真值图(Ground_truth)的值和预测图(Predict_mask)的值。通常用Dice损失函数描述分割结果和真值的相似度。随着模型的训练,往往将结果Dice系数最大化,目的是为了尽可能地提高分割结果与分割真值的相似程度。但是,当缺陷过小时,结果容易导致Dice损失函数值发生剧烈震荡,从而影响整个训练过程。二元交叉熵(Binary Cross Entropy,BCE)函数更着重于其中每个像素单元的预估概率,其值是目标和背景区域中所有像素的交叉熵,如式(4)所示:
如果缺陷区域较小,交叉熵损失值的变化随着模型预测结果的变化影响较小,可解决Dice损失函数的弊端带来的问题。本文考虑数据与模型的契合性,并结合两种不同损失函数的特点,提出一种Dice_BCE混合损失函数,如式(5)所示:Loss=β· BCE_loss+(1-β)· Dice_loss , (5)式中,权重影响因子β用于改变两个损失函数的比重,在0~1内取值。最后,训练过程中为了提升模型的泛化性,加入dropout层,目的是加快模型收敛、避免模型过拟合。
4 实验与分析
4.1 实验数据集
本文采用GDX-ray公共数据集的焊缝缺陷数据集。将数据集图片经过裁剪、滑窗的方式,共得到4 674张底片图像。每张图片分辨率大小为512×512,标签分为缺陷与非缺陷,像素大小分别用255和0表示。训练集和测试集随机划分,前者占80%,后者占20%。训练图片含3 748张,测试图片包括926张。
4.2 实验环境与参数设置
本文实验所用的训练平台是32G内存的Windows10操作系统,处理器为AMD Ryzen 5600X,GPU是显存为8G的RTX3070。采用Pytorch 1.11.0框架,环境为CUDA11.3,torchversion版本为0.12.0,python版本采用3.8。
4.3 评价指标
本文采用4种常见的评价指标来定量评价所提模型分割性能,分别是Dice系数值、体积叠加误差率(VOE)、相对体积的差(RVD)、两样本之间的最大对称距离(MSSD)。
Dice系数常应用于图像分割模型评价,它用于计算分割结果X和标签Y两个样本的相似度或重叠度,如式(6)所示:
其中,Dice的取值范围在[0,1]。
VOE是体积重叠误差,其值越小,代表分割性能越好,如式(7)所示:
RVD用于计算两个样本的相对体积差,如式(8)所示:
MSSD代表结果与真值的最大对称表面距离:
其中:T()是表面像素值,S(q,T())表示像素到表面像素的距离。以mm为单位。
4.4 实验结果与分析
4.4.1 损失函数对分割精度的影响
本文对所提混合损失函数的影响因子β进行分析,用来测试损失函数对分割精度的影响,如图7所示,实验结果为随着β选取不同值,Y轴产生不同的Dice结果,介于82.9%~87.3%。当β值为0时,Y轴显示的Dice值为82.9%。Y轴结果随着X轴影响因子的增加而逐渐增高,表明混合损失函数可以提高模型分割效果,Dice系数值在影响因子选为0.7时结果为87.3%,为最高值。综上,本文将β选为0.7进行本文实验。权重β为0.7时,网络模型训练过程中训练集上的Loss值随训练次数的迭代降到较低值,并且保持整体稳定下降趋势。训练次数为20 000次时,损失值降至相对较少的值;训练次数为40 000次时,损失值趋于稳定;最终,损失值降至约0.002,整体得到一个较好的训练效果。
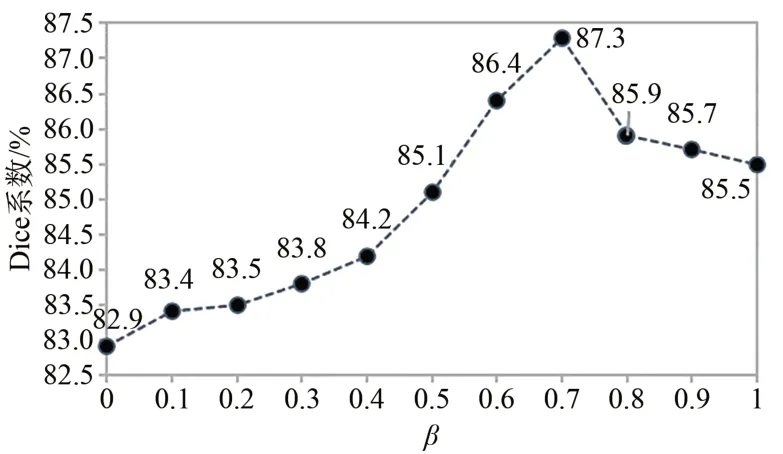
图7 Dice系数随β变化趋势图Fig.7 Trend of Dice coefficient with weighting factor β
4.4.2 注意力机制对分割精度的影响
通过在编码器路径中添加GAM注意力模块,本文以是否添加注意力模块、添加CBAM注意力模块和添加GAM注意力模块做对比实验,图8展示了注意力模块提高模型分割精度的效果。如果模型中加入CBAM注意力机制,仅相比于没有添加注意力模块提升了0.5%;但添加GAM注意力模块后,提升至93.45%,分割精度提高了1.05%。
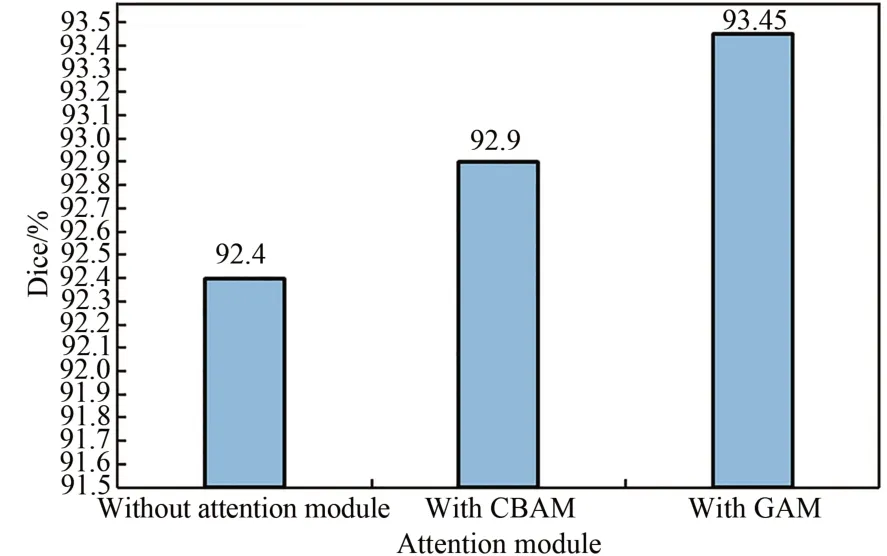
图8 添加和未添加注意力模块的分割结果Fig.8 Segmentation results before and after adding attention module
4.4.3 消融实验
DP_Unet模型将密集连接的空洞卷积模块和多卷积核池化模块组成的DP_block加入到上下采样间,并在下采样添加GAM注意力机制。表1体现了添加的各个模块对模型分割效果的影响。本文做了多个消融实验,以Unet算法为基线的算法进行底片缺陷分割的Dice系数值仅有87.24%,而采用“Unet+密集连接空洞卷积”的Dice值达到90.55%,“Unet+多卷积核池化”的Dice结果为90.88%,“Unet+DP_block”模型可以提升至92.33%。同时VOE值、RVD值和MSSD值均有不同程度的减小。这说明DP_Unet模型中新增模块均能提高模型分割性能,分割精度也有不同程度的提升。另外,与其他组合模型比较,DP_Unet模型通过加入密集连接空洞卷积模块与多卷积核池化模块组成的DP_Block和注意力模块获得了最高的Dice系数值和最低的VOE、RVD和MSSD等评价指标。
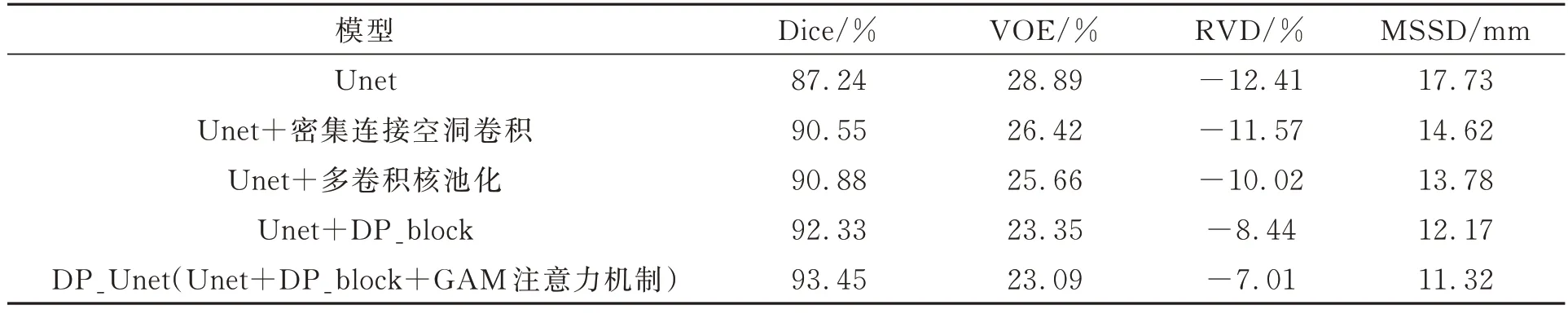
表1 加入不同模块的消融实验结果Tab.1 Ablation experiment results of adding different module ablation
4.4.4 实验结果比较
图9为测试集部分X射线底片缺陷分割的可视化结果。从图中可看出,Unet、U2net、Linknet、DeepLabv3+和TransUnet模型基本均可分割出底片缺陷区域,但对于边界模糊和小缺陷,存在分割不全、过分割和漏分割现象。

图9 不同算法实验结果Fig.9 Experimental results of different methods
可以看到,红色框部分可以显著突出本文算法分割更精细的地方,分割效果更为直观。DP_Unet通过解决缺陷特征提取时难以最大限度保留图像原始信息问题和有效弥补缺陷信息损失问题,且可以精确分割边缘目标,实验结果好于其他模型。表2是采用不同算法在公开数据集GDX-ray上的实验结果。分别采用4个不同的评价指标对实验结果进行定量分析。本文方法的Dice系数结果相比U2net提高了7.34%、相比Unet提高了6.21%、相比Linknet提高了2.88%,相比DeepLabv3+提高了1.79%,相比TransUnet提高了1.38%,但是DeepLabv3+的MSSD值得到了最小值11.07,比本文方法略低0.25 mm。实验结果表明,提出的编解码语义信息提取模块、GAM注意力机制和混合损失函数,可以有效提升X射线底片缺陷分割的精度。
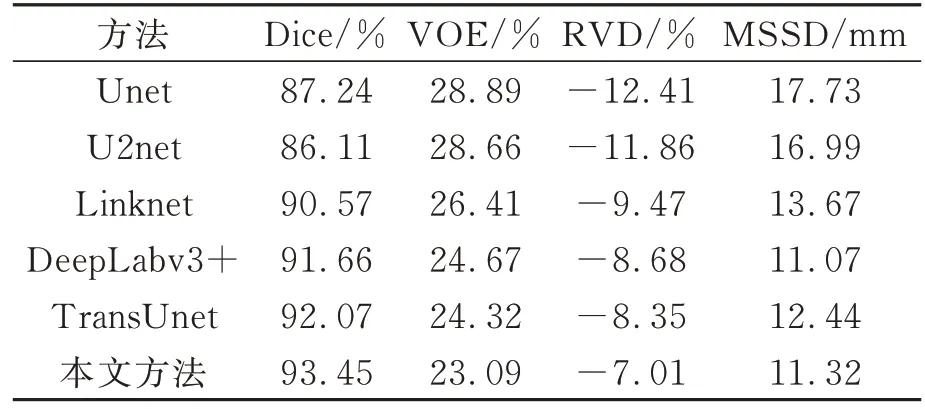
表2 不同方法的缺陷分割性能定量比较Tab.2 Quantitative results of different defect segmentation methods
4.4.5 实测数据分割结果
本文对陕西西宇无损检测公司提供的30张缺陷样片图像进行测试,以进一步验证所提算法的普适性。图10所示为部分底片缺陷图像的可视化结果,第一行为原始图像,第二行为分割真值,第三行为本文方法的分割结果。可以看出,本文所提方法可有效分割气孔、夹渣和裂纹等缺陷,且与真值结果相近。

图10 本文方法在无损检测公司提供的数据集上的分割结果Fig.10 Segmentation results of this method on the dataset provided by a non-destructive testing company
采用上述评价指标对缺陷样片30张测试图像进行定量分析。得到的Dice、VOE、RVD、MSSD 4个评价指标如表3所示,分别为90.36%、23.97%、-9.06%和12.87 mm,表明无论在公共数据集还是实测数据集都有较为理想的分割效果,均可实现底片焊缝缺陷的高精度分割,体现了模型的强鲁棒性。

表3 本文方法在无损检测公司提供数据集上的定量分析Tab.3 Quantitative analysis of this method on data sets provided by non-destructive testing companies
5 结论
针对底片焊缝缺陷分割精度低、边界分割模糊等问题,本文构建了一种改进的DP_Unet的X射线底片焊缝缺陷分割方法:(1)提出了编解码信息提取模块DP_block,最大程度解决特征提取过程中信息损失、分割精度低的问题;(2)在编码器结构中,加入GAM注意力机制,可增强高级语义表征能力,以更好地捕捉缺陷,抑制无用的信息;(3)采用BCE函数与Dice系数搭建混合损失函数Dice_BCE,不但可以通过Dice系数解决类的不平衡分割问题,还可通过交叉熵在回传类别时稳定梯度使模型加快收敛。在公开数据集GDX-ray上的实验结果表明,所提出的DP_Unet能够提升缺陷区域的边缘特征,使分割精度有所提高,Dice值达到93.45%,与基线算法相比均有大幅提高,具有更优的模型性能,对工业无损检测领域有着重要的应用意义。
