一种基于规则解析的地理信息元数据批量采集方法
2024-01-29范登科张恒韩祖杰全玉山宋永军杨斌张利明
范登科 ,张恒 , ,韩祖杰 ,全玉山,宋永军,杨斌,张利明
1. 中国铁路设计集团有限公司,天津 300308;
2. 城市轨道交通数字化建设与测评技术国家工程研究中心,天津 300308;
3. 西南交通大学地球科学与环境工程学院,成都 610031;
4. 甘肃天陇铁路有限公司,兰州 730046
1 引 言
元数据是关于数据的数据(薛娇等,2020;Sawadogo 和Darmont,2021)。在地理信息数据分析、处理、交换和服务发布过程中,元数据提供了统一的数据描述规则和方法,以便各方在信息理解和数据解译上达成一致(Lassoued 等,2007;Sheoran和Parmar,2020;刘纪平等,2022)。我国于2005年发布《地理信息 元数据》(GB/T 19710—2005)标准,定义了元数据的组成单元、特征和数据字典,有效规范了元数据的内容和形式,并在《基础地理信息数字成果元数据》(GB/T 39608—2020)中提出了基于XML 语言的元数据规则实现方式。为了实现地理信息元数据的结构化存储和标准化应用,全国地理信息标准化技术委员会发布了国家标准化指导性技术文件《地理信息 元数据 XML 模式实现》(GB/Z 24357—2009),明确了基于XML语言编制元数据规则,用以描述元数据数据字典的全部组成单元及其彼此间的关系(张涛等,2007;李爽,2017;Lacayo 等,2021)。由于地理信息数据具有时空海量、多源异构等特点(徐冠华和黄写勤,2022),导致元数据内容多样、规则关系复杂。常规手工对文件编辑处理的方式导致元数据的生产、管理和交互等工作效率低下、内容繁杂,致使元数据技术的推广应用受到限制(张敏等,2019;周成虎等,2020;李新等,2021)。如何对复杂规则关系进行解析,批量自动地采集标准化的元数据,是对海量时空大数据达成一致理解的重要前提。
现有元数据采集方法主要包括三类。一是基于数据库的采集。根据数据字典设计好数据库表结构,通过表之间的关系反映元数据实体和元数据元素间的逻辑关系,采集时将元数据实体的实例存储为数据库表中的一行记录(罗英伟等,2005;宋鸿运,2017;Parmar 和Sheoran,2021)。这种方法将元数据的各种关系隐含在数据库表关系中无法显式表达,一旦进行信息交换或迁移,还需要执行繁琐的数据库查询和修改操作,以保证元数据与所描述数据统一一致。二是将XML 规则文件描述的数据字典转为RDF、DTD 或其他建模语言描述(程志华,2018;孙立健等,2018;王晓迪等,2023)。该方法不仅使元数据的批量采集能力和交互编辑能力受限于特定建模语言或软件,还增加了转换过程中数据字典信息错漏的风险。三是采用文本描述语言,如XML、TXT、Json等固定的语法和结构,直接写入信息批量生产实例文件(Hu 等,2022;郑聪和张衍伟,2019;任赳龙等,2019)。这种方法仅能处理通用、固定的元数据内容,由于缺少规则约束,难以保证元数据信息的完整性,以及与数据字典描述的一致性;同时由于需要在软件研发阶段固化元数据结构和内容,可扩展性和灵活性较低。此外,现有软件如国家基础地理信息中心的MetaGear、商业软件ArcGIS 仅支持对基础地理信息元数据的编辑,缺乏对行业特定扩展元数据的采集能力,极大限制了元数据在各专业领域的应用(Cartledge,2018;Brodeur 等,2019;Closa 等,2019)。
为解决元数据采集自动化程度和效率低、行业应用受限等问题,本文提出一种基于规则解析的地理信息元数据批量快速采集方法,以实现规则约束下的元数据标准化采集,提高元数据的采集效率及产品的可靠性,满足行业扩展应用的需求。首先,通过定义元数据的数据类型,将元数据规则文件中的各类组成单元解析为相对应数据类型的对象;其次,采用属性描述组成单元间的关系,重建数据字典结构;最后,建立交互视图以实现元数据实例的批量表达和编辑。
2 研究方法
图1 展示了基于规则解析的地理信息元数据批量快速采集方法的总体技术框架,主要包括元数据数据类型定义和规则解析、元数据数据字典的结构重建,以及元数据信息交互视图构建三个步骤。
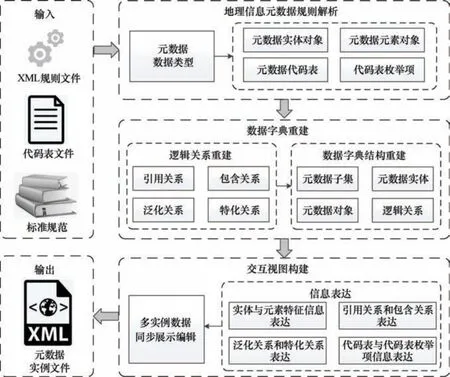
图1 本研究总体技术框架Fig.1 Overall technical framework
2.1 建立描述架构
2.1.1 元数据组成单元类型定义
遵照国家标准的规定,采用计算机语言分别定义元数据实体类、元素类、代码表类和代码表枚举项类。其中,实体类和元素类中各项属性的数据类型与元数据特征之间的对应关系,如表1 所示。将元数据代码表和代码表枚举项的“名称(中文)”“名称(英文)”“域代码”和“说明”四个特征的数据类型全部定义为字符串型。

表1 各组成单元特征与数据类型定义间的对应关系Tab.1 Correspondence between the constituent units characteristics and the data type
2.1.2 元数据组成单元间关系描述
元数据各要素之间具有四类逻辑关系,分别是包含关系、引用关系、泛化关系和特化关系。作为元数据元素的一类特殊值类型,代码表与其枚举项同样构成包含关系。通过在相应要素类中新增属性定义实现上述关系描述,各属性的数据类型与所描述逻辑关系的对应情况,如表2 所示。

表2 四类逻辑关系与属性的数据类型间的对照Tab.2 Comparison between the four types of logical relationships and the data types of attributes
2.2 XML 规则文件解析方法
一组地理信息元数据规则文件记录了以XML语言实现的数据字典描述(蔡鲁湘,2005)。遵照国家标准化技术性指导文件的规定,元数据各要素及其实例均采用了特定的XML 语法、Tag 标记和组织形式进行定义。本研究通过解析这些固定的格式、标记和组织形式,将元数据的数据字典信息从XML 规则文件传递到上述所建立的描述架构中,图2 描述了XML 规则文件解析的具体方法。
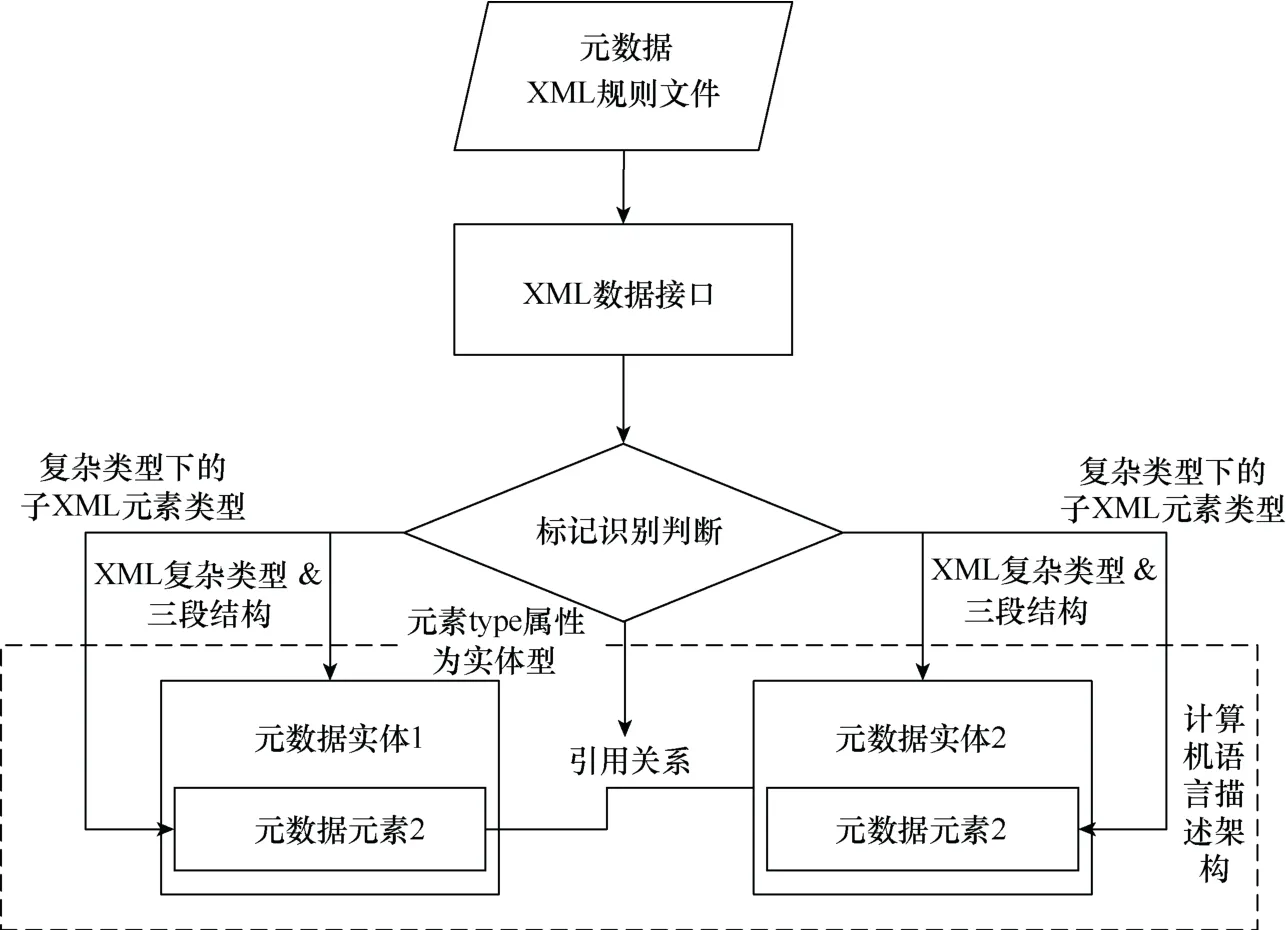
图2 解析XML 规则文件内数据字典信息到所建立的描述架构的方法Fig.2 A method of parsing metadata data dictionary in XML schema files into the description framework proposed
以元数据实体CRCI_Contact 为例,图3 展示了将其XML 规则内容解析为实体类对象和元素类对象的过程,其中将上述所建描述结构中定义的实体类命名为MetadataEntity,元素类命名为MetadataElement,解析所得实体对象为O,其包含的各元素对象为ei,各项元数据特征值解析为对象的属性值。

图3 从规则文件中解析元数据实体对象和元素对象的过程示意Fig.3 Schematic of the process of parsing metadata entity objects and element objects from the schema files
元数据的数据字典定义了一整套从根实体MD_Metadata 出发的、自上而下的“子集—实体—元素”三级组织架构。通过包含关系、引用关系、泛化关系、特化关系四种逻辑关系,元数据各要素有序组织在一起,在数据结构上表现为树结构,如图4 所示。树结构中的节点为元数据实体O 或元素e,节点间的连接线代表其逻辑关系,分别是实体与元素的包含关系,元素与实体的引用关系,实体与子实体的特化或泛化关系。在规则解析过程中,随着各要素对象的实例化,对象间的各类逻辑关系解析为对象的属性值。至此,借助计算机语言,元数据数据字典的全部信息被完整地描述出来。

图4 元数据数据字典的树结构示意Fig.4 Tree structure of the metadata dictionary
2.3 构建交互视图
2.3.1 元数据特征表达
采用统一的树列表结构视图表达由上述解析得到的元数据数据字典。如图5 所示,该视图中的一行表示一个节点,反映了一个元数据元素对象的信息。元数据的三个特征——“名称/角色(中文)”“数据类型”和“可选性”的实例信息,分别通过视图的第一列数据、第二列数据和节点图标表达。其中,“名称/角色(中文)”和“数据类型”特征直接表达为属性值,“可选性”特征则通过节点图标样式差异化表达元素是可选的还是必选的。
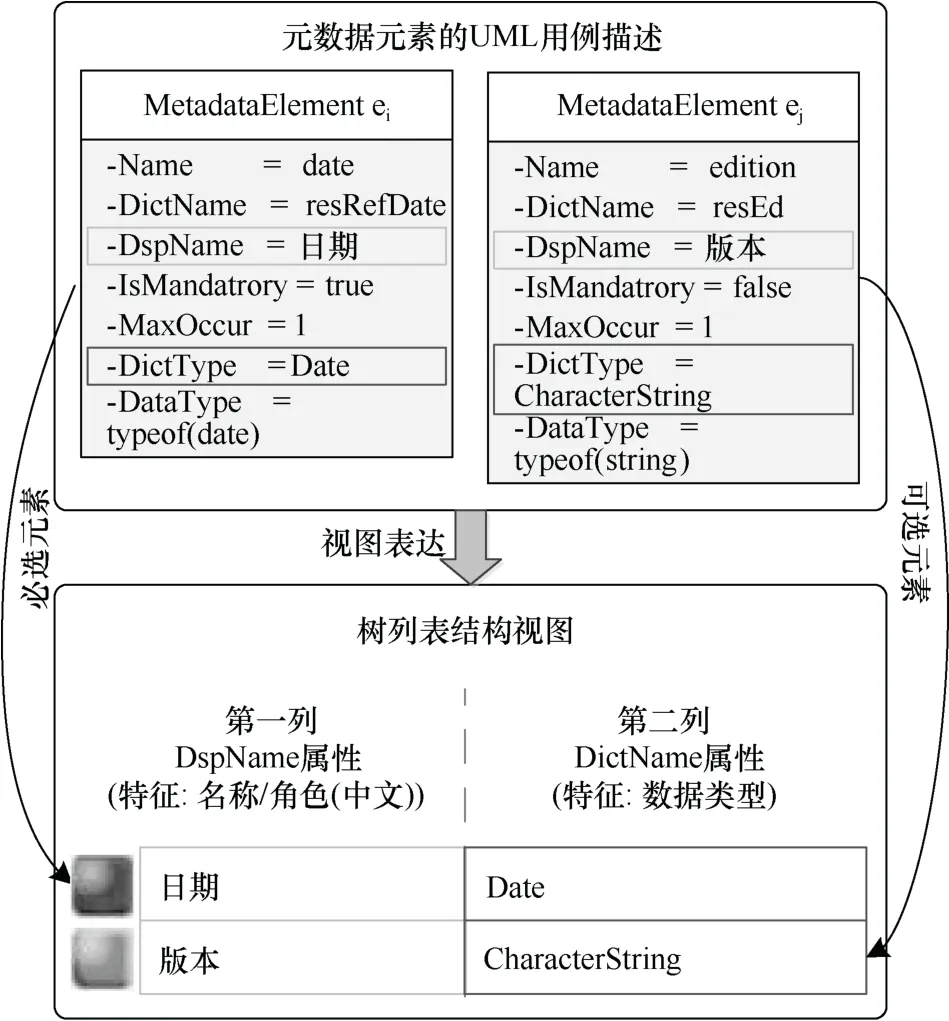
图5 元数据特征表达视图的构建过程示意Fig.5 Construction process of metadata feature representation view
2.3.2 引用关系与包含关系的表达
当元数据元素与实体之间构成引用关系时,该元素值的数据类型为实体型。在交互视图中,引用关系通过节点的第一列数据——元素的“名称/角色(中文)”特征与第二列数据——元素的“数据类型”特征二者间的对应关系表达。元数据实体与其所含元素之间的包含关系则通过树结构中节点及其子节点间的包含关系表达。以引用 CRMD_Keywords 实体的元素及该实体所包含的元素为例,引用关系和包含关系在视图中表达方式,如图6所示。
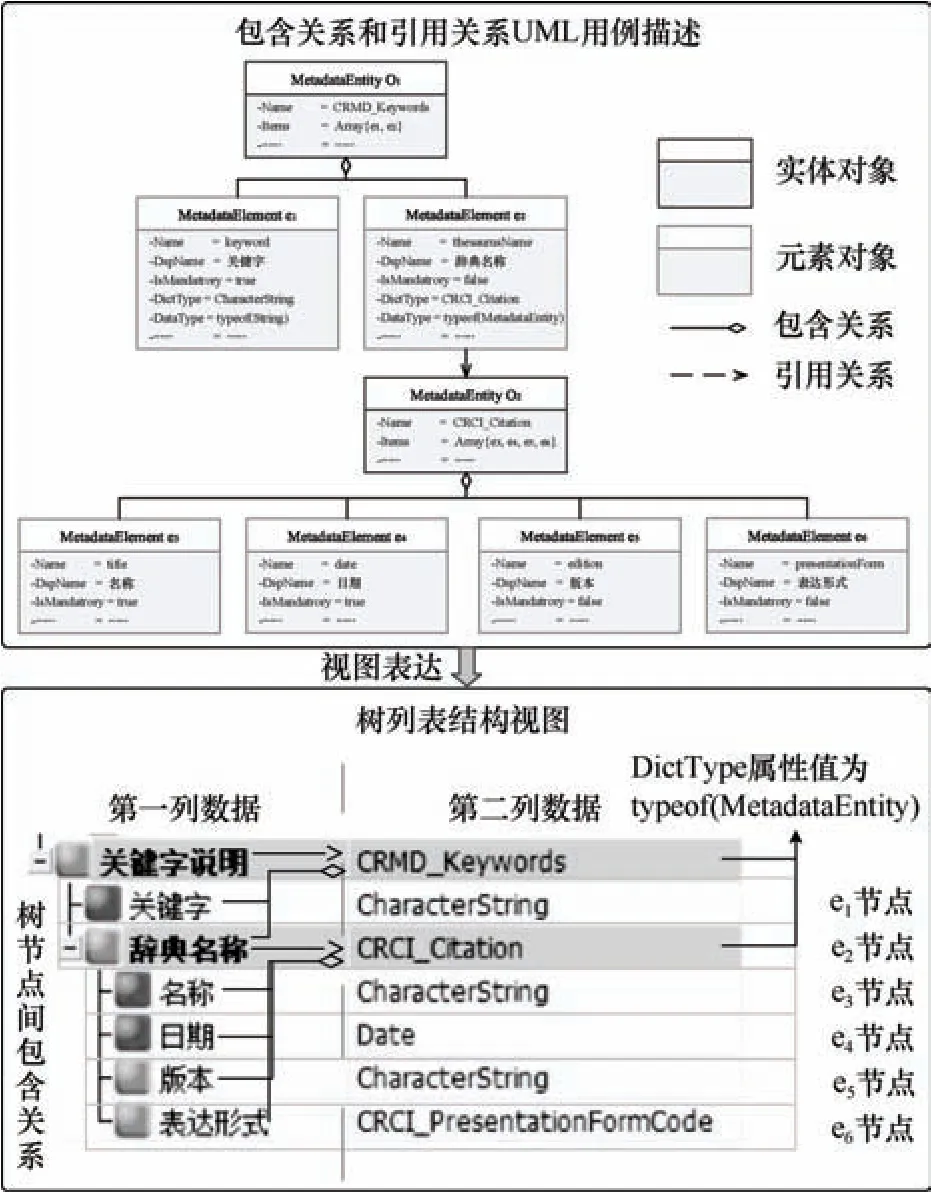
图6 交互视图中以树列表结构表达引用关系和包含关系Fig.6 Tree list structure of the reference relationship and the containment relationship in the interactive view
2.3.3 泛化关系与特化关系的表达
与计算机语言描述的类型派生类似,元数据实体之间具有泛化或特化关系。以空间表示(CRMD_SpatialRepresentation)实体为例,由其特化出格网空间表示(CRMD_GridSpatialRepresentation)、矢量空间表示(CRMD_VectorSpatialRepresentation)和模型空间表示(CRMD_ModelSpatialRepresentation)三个实体;其中,格网空间表示又特化出地理校正(CRMD_Georectified)实体。在交互视图中,以上述特化关系创建树列表子视图,如图7 所示,并通过上述构建的树结构中第二列数据——元素的“数据类型”特征与主视图关联。当选中子视图中某实体类型时,其包含的元素作为子节点添加到主视图中,从而实现元数据实体的多态化表达。
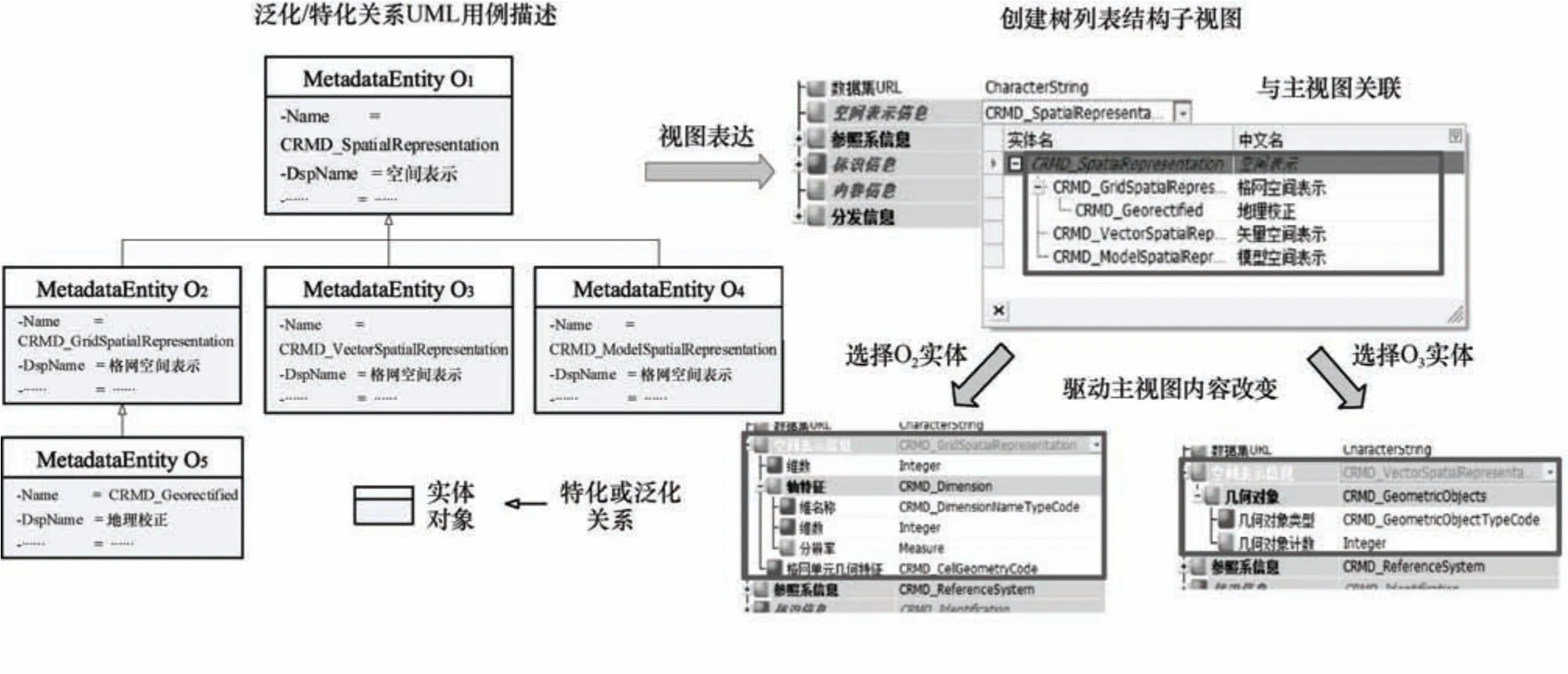
图7 特化关系或泛化关系的子视图表达、与主视图关联及多态化Fig.7 Subview representation of generalization or specialization, association with main view, and polymorphism
2.3.4 批量同步采编及空间信息驱动
如图7 所示树列表主视图中,除前两列表达元数据的两个特征外,其他列用于展示元数据的实例值。一个元数据实例文件的内容由主视图中的一列数据表达。图8 示意了不同元数据应用类型、不同空间数据类型的元数据实例文件内容在主视图中同步展示的效果。由于相同项目数据的元数据在一些元素(如创建日期、制作单位、说明等)上取值相同,可以对视图展示的所有或部分元数据按行(元素)统一赋值,从而实现元数据的批量同步采编。
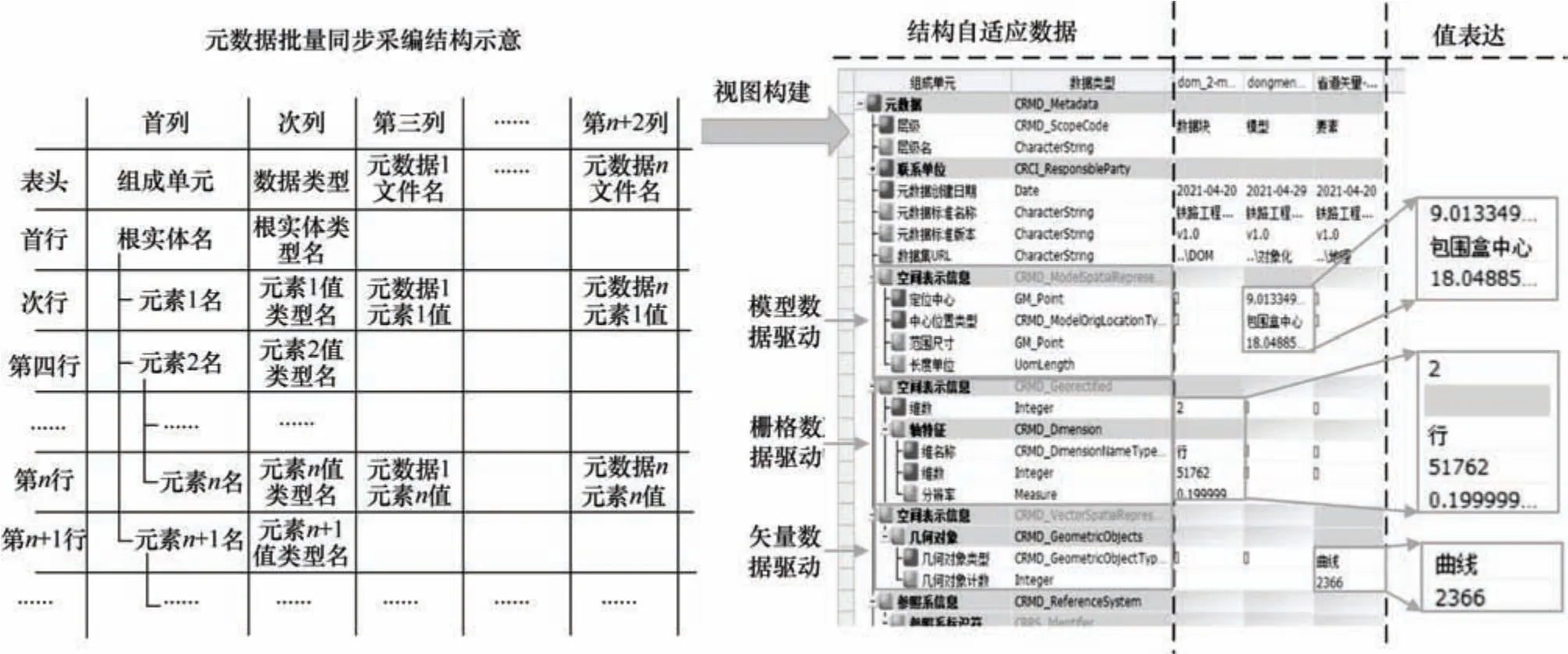
图8 元数据批量同步采编及空间信息驱动下的元素多实例化Fig.8 Metadata batch synchronous collection and element multi-instantiation driven by spatial information
借助空间数据接口,能够自动采集与空间信息相关的元数据实例信息。由于作为这些信息载体的元数据实体(如空间表示信息、内容信息)具有与上述相同的多态性。对不同数据类型的地理信息数据批量同步采编时,相同元素在空间信息的驱动下表达为不同数据类型(实体类型)的实例。
3 生产实践应用及对比分析
本方法适用于基于XML 规则实现的、遵照国家标准GB/T 19710 及GB/Z 24357 扩展规定编制的各型元数据的采集。基于本方法,地理信息数据生产人员在昌景黄高速铁路、京雄城际铁路等工程的信息化项目中开展了元数据采集实践应用,采集目标为铁路建设周边地理要素矢量、数字正射影像图(digital orthophoto map,DOM)和数字高程模型(digital elevation model,DEM)影像、工程要素模型、施工图设计参数表格等地理信息数据,目标数据量总计约45 GB,采集所得元数据实例文件数为382 个。元数据采集效率和质量得到提升,进一步规范了地理信息数据管理,缩短了数据服务发布周期。本文实验包括以下三个步骤。
(1)元数据数据类型定义和规则解析。首先,根据地理信息元数据的XML 模式实现规则,采用计算机语言定义元数据各类组成单元对象的数据类型;其次,从元数据XML 规则文件和代码表文件中,提取其中记录的元数据实体、元素和代码表及代码表枚举项实例信息,解析为数据类型的对象。
(2)元数据数据字典的结构重建。扩展定义步骤(1)元数据的数据类型中实体类和要素类的属性,以描述元数据数据字典中记录的包含关系、引用关系、泛化关系和特化关系。通过上述四类关系将步骤(1)解析获得的实体对象和元素对象关联组织在一起,形成数据字典的数据结构。
(3)元数据信息交互视图构建。采用树列表结构,创建视图表达步骤(2)解析形成的数据结构,包括元数据实体和元数据元素的部分特征信息,以及彼此间的四类关系,形成按照视图结构表达的、统一的、多态可控的组织形式。采用列表结构,创建子视图表达步骤(1)解析得到的各代码表及所含代码表枚举项的全部特征信息。最终关联上述视图和子视图,通过所描述地理信息数据的类型驱动生成采集视图,将在组织关系上相关的元数据实例同步显示到树列表结构视图的不同列中,以统一赋值、自动提取空间信息等方式实现元数据批量快速采集。
3.1 与MetaGear 采集方式的对比
MetaGear 是国家基础地理信息中心研发的一款地理信息元数据采集软件,能够个性化地采集生产不同区域的XML 元数据,但与本方法相比,其不足之处在于一次仅能采集一个元数据实例,且需要在采集前指定地理信息数据所对应的数据类型模板,在整个采集过程中元数据数据字典结构固定,不具有灵活可变的特性。本方法解决了MetaGear 无法一次采集多个元数据实例的问题,支持多种数据类型的元数据实例同时展示,并在采集过程中可以灵活调整元数据数据字典组织内容和结构,可以有效应对当前如FileGDB、KMZ 等混合数据类型的地理信息数据的采集。
3.2 与传统元数据采编方式的效率对比
采用本方法与文本直接编辑方法的元数据采集进行效率对比实验,两种采集过程的采集人员、采集环境和采集目标数据均保持一致,并分别从新建实例数据和修改实例数据两方面作比较。新建实例数据的实验过程是,根据需求新建并采集20 个不同地理信息数据类型的元数据文件,其中包含具有代表性的矢量数据文件7 个、栅格数据文件7 个、模型数据文件6 个,且同类文件中空间信息各不相同,分别记录无地理信息数据类型先验知识和有地理信息数据类型先验知识两种情况下两种方法的处理时间;修改实例数据的实验过程是,根据需求修改20 个既有不同地理信息数据类型的元数据文件,不同类型文件数量及信息差异性与前者保持一致,分别记录无增删元数据元素和有增删元数据元素情况下两种方法的处理时间;最终四种情况等权计算平均水平。两种方法在多环境下元数据处理时间的统计结果,如表3 所示。

表3 两种元数据处理方法效率对比Tab.3 Efficiency comparison of two metadata processing methods min
由表3 可知,本方法在各种情况下均优于文本直接编辑方法。由于后者在处理过程中不仅需要编辑大量的XML 节点,而且还需要充分考虑元数据数据字典层次关系的正确描述,对数据处理人员熟悉地理信息元数据XML 模式的程度有很高要求。在有先验知识的新建实例数据和有增删元素的修改实例数据情况下,本方法能显著提升处理效率,平均时间节约达60.5%。
4 结 论
本文提出的基于规则解析的地理信息元数据批量快速采集方法解决了现有方法中存在的处理效率低、信息不完整、交互能力弱、灵活性差等问题。基于地理信息元数据XML 规则解析的数据字典重构和元数据信息交互视图的构建是本方法实现的技术基础。在规则解析与数据字典重构方面,本方法采用计算机语言描述了由XML 模式定义的地理信息元数据实体、元素、代码表及代码表枚举项的各类特征和逻辑关系,重新建立了元数据数据字典的多层级、多态化数据结构。在元数据信息交互视图构建方面,方法借助树列表视图多维信息表达的优势,直观、完整地反映元数据数据字典的全部内容,动态、灵活地表现其多层级和多态化数据结构,为批量快速采集地理信息元数据实例提供了高效的、可扩展的方法。未来工作将关注于与元数据规则相匹配的数据库表的自动创建和修改,以及元数据实例自动入库管理方法研究上,进一步提升元数据管理的统一性和规范性。
