基于自训练卷积神经网络的遥感场景图像异常探测方法
2024-01-29张方泽龚循强周秀芳刘卓涛
张方泽,龚循强,周秀芳,刘卓涛
1. 宁波市阿拉图数字科技有限公司,宁波 315042;
2. 东华理工大学 测绘与空间信息工程学院,南昌 330013;
3. 东华理工大学 自然资源部环鄱阳湖区域矿山环境监测与治理重点实验室,南昌 330013;
4. 东华理工大学 江西生态文明建设制度研究中心,南昌 330013
1 引 言
场景分类作为一项重要的遥感图像解译技术,可自动提取并识别遥感场景中丰富的语义信息,已经成为遥感图像信息提取的重要手段之一,在自然资源调查、城市规划、土地利用等领域得到了广泛的应用(Ma 等,2022;龚健雅和钟燕飞,2016)。面对海量遥感数据中的大量无标签场景图像,如何赋予其准确的标签已成为研究热点。目前对无标签的遥感场景图像进行标注通常采用监督分类、非监督分类和半监督分类方法(贾霄等,2021;吴列等,2022)。然而,无论采用何种方法对无标签的遥感场景图像进行分类,其赋予的标签均可能存在与实际类别不匹配的异常情况,这种分类后含有异常标签的数据称为伪标签数据(龚循强等,2020;杨雨龙等,2021)。使用含有异常标签的遥感场景图像进行科学研究和实际应用,将会对结果造成较大的影响,因此,对遥感场景图像中的异常标签进行探测极为重要。
在图像分类和异常探测领域,相关学者进行了大量的研究。史旭东和熊伟丽(2020)为了处理工业数据中的无标签数据,提出了一种基于改进自训练算法的高斯过程回归软测量建模方法。Gu 等(2022)引入了一种新的交叉检查策略,使其在自训练过程中交换伪标签信息,能够最大限度地提高伪标签的准确率。张晓男等(2018)提出了一种集成多个模型的遥感场景分类算法,通过构建反向传播网络实现了场景图像的复杂度度量,并对多个卷积神经网络(convolutional neural network,CNN)进行训练,从而提高分类准确率和预测速度。Baloch(2020)针对小型网络提出了一个五层的CNN 模型,其参数远少于其他常用的网络,但分类的准确性仍能与常用的网络接近。Shi 等(2021)提出了一种基于多尺度CNN 的遥感图像融合算法,通过CNN对多光谱图像的每个波段进行多尺度图像分析,以提取多光谱图像中不同波段的典型特征。此外,张能欢和王永滨(2020)为了解决 ResNet-18 和ResNet-50 网络固定感受野的不足,引入自适应感受野的方法,同时加入注意力机制来进一步提高场景图像识别的精度。
CNN 因具有较好的识别能力在遥感场景图像中被广泛采用,但该优势是建立在大量标注的训练样本之上,而数据标注需要耗费大量的人力、物力和财力(陈学业等,2022)。目前,遥感场景的样本标注主要由人工通过自身经验进行判读,由于遥感场景的复杂性,遥感场景数据集常常存在类别标注不合理、场景中存在其他类别的地物等标签异常情况,从而影响CNN 模型的训练效果。探测遥感场景数据集中存在的上述标签异常情况有助于提高模型的分类精度。自训练算法经常被运用在半监督学习中,其通过迭代运算将获得的结果加入训练集中以增强网络模型的性能,可以较好地解决CNN在训练时样本不足的问题(赵婵娟等,2019)。因此,本文提出一种基于自训练CNN 的遥感场景图像异常探测方法,通过少量真实标签训练CNN 中常用的GoogLeNet、ResNet 和DenseNet 模型,并结合自训练算法对遥感场景图像中标签和实际类别不匹配的异常图像进行探测,将探测结果为正类和异类的标签分别加入真实标签与伪标签进行下一轮探测,直到各项指标变化稳定后结束探测,以实现在少量训练样本下的高精度遥感场景图像异常探测。
2 研究方法
本文提出的自训练CNN 方法是在CNN 的基础上结合自训练算法构建的,因此,在介绍自训练CNN 方法之前,有必要对常用的三种CNN 进行介绍。
2.1 卷积神经网络
CNN 是一种前馈神经网络,其中包含卷积运算且具有一定的深度结构,本文将基于GoogLeNet、ResNet、DenseNet 这三种CNN 网络进行实验验证。其中,GoogLeNet 网络结构中包含3 个卷积层(conv)、5 个池化层(pool)、2 个批规范化层(batch normal,BN)、9 个Inception 模块和1 个全连接层(FC),最后通过softmax 函数进行类别输出(Jamali等,2021)。具体结构如图1 所示。本文主要对数据集中含有的异常标签进行探测,因此,在softmax 之后增加一个判断结构,将输入的标签与网络输出的标签进行匹配,若匹配结果一致,认为该图像的标签是正确的;否则认为该图像的标签是异常标签。
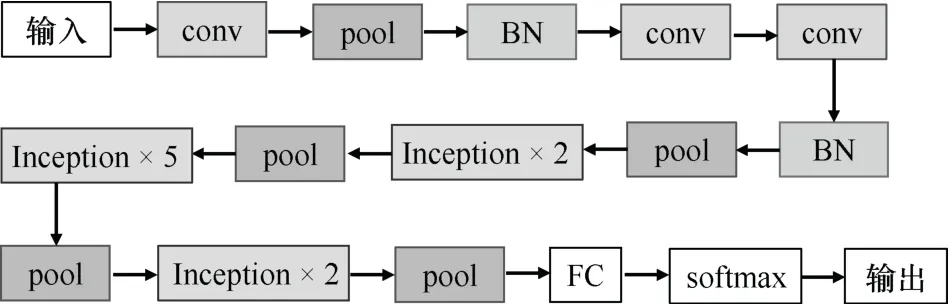
图1 GoogLeNet 结构Fig.1 GoogLeNet structure diagram
ResNet 网络结构采用ResNet-50,其中,包含了1 个卷积层、2 个池化层、16 个残差卷积层(Residual block)和1 个全连接层。残差块一共分为四部分,每部分的数量分别为3、4、6 和3(Balnarsaiah等,2021;龚国栋等,2022)。具体ResNet网络结构如图2 所示。同样,在softmax 函数之后增加一个判断结构,将预先输入的标签与网络输出的标签进行匹配,判断测试图像的标签是否准确。

图2 ResNet 结构Fig.2 ResNet structure diagram
DenseNet 网络结构采用DenseNet-121,其中包含了1 个卷积层、2 个池化层、4 个稠密连接模块(Dense block)、3 个传输层(Transition Layer)和1个全连接层。4 个稠密连接模块中含有的卷积层个数分别为6、12、24、16(Tao 等,2018;林超,2022)。具体DenseNet 网络结构如图3 所示。与GoogLeNet 和ReseNet 相同,在输出模块中增加判断结构用以测试图像的标签是否准确。
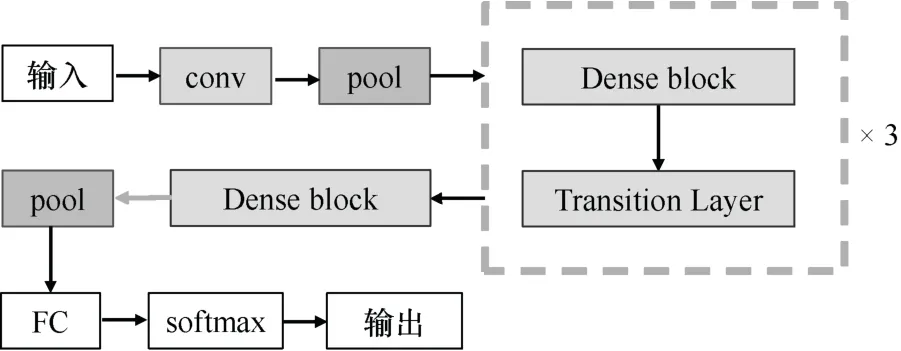
图3 DenseNet 结构Fig.3 DenseNet structure diagram
2.2 自训练CNN 方法
随着现代科学技术的飞速发展,如今快速高效地获取大量数据已成为可能,但获得的大多数是无标签数据,而获取有标签数据的成本依然较高。如果只使用少量的有标签数据进行学习与使用,那么不仅会限制分类器的泛化能力,还会因忽略大量无标签数据中的有用信息而造成资源的浪费(Ge 等,2021;吕佳和李婷婷,2021)。自训练算法不需要大量的标签数据作为先验知识,只需要少量的标签数据进行迭代运算就可不断地扩充训练数据,因此在半监督学习中被广泛采用(程康明和熊伟丽,2020;Li 等,2021;Pedronette 和Latecki,2021)。
在遥感场景图像中,每张图像都具有一定的复杂性,其亮度值为0~255。如果只是简单地将图像转化为数值进行异常探测,那么将无法获得准确的探测结果。CNN 通过训练可以有效地识别出每个场景类别对应的特征,因此,在图像分类、目标识别、迁移学习中被广泛采用。虽然CNN 能够较好地识别不同类别的复杂图像,但其性能会受到初始训练样本数量的影响,当初始训练样本较少时,其识别性能会大大降低,而自训练算法可以通过迭代运算不断地扩充训练集,以解决CNN 在训练样本不足时性能较低的问题。为了探测出遥感场景图像中标签和实际类别不匹配的情况,本文充分利用自训练算法和CNN 的优势,提出自训练CNN 方法。
自训练CNN 方法通过少量真实标签对CNN 进行初始训练,然后对含异常标签的伪标签数据集进行异常探测,将探测结果为正类的标签加入真实标签中,探测结果为异类的数据仍保留在伪标签中进行下一轮探测;重复运算直至各项指标稳定后输出异常探测的结果。具体的步骤如下:
(1)提取少量准确标签数据作为真实标签,并将剩余的数据作为伪标签数据;
(2)将真实标签数据作为训练集训练三种CNN模型,即GoogLeNet、ResNet 和DenseNet,利用训练结果对伪标签数据进行异常探测;
(3)对探测结果进行精度评定,根据各项评价指标确定是否结束迭代,如果是则输出结果,否则进行步骤(4);
(4)将探测结果为正类的数据加入真实标签中,探测结果为异类的数据作为伪标签,重复步骤(2)、(3),具体计算流程如图4 所示。
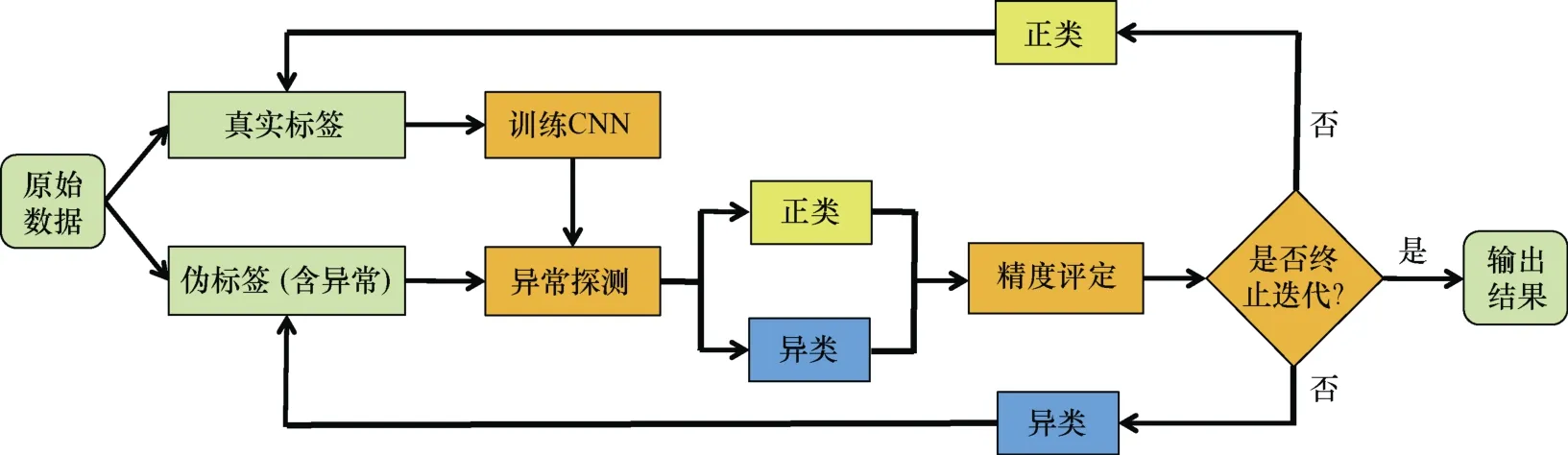
图4 自训练CNN 技术流程Fig.4 Flowchart of self-training CNN
3 实验设计
3.1 实验数据集和图像预处理
本文采用SIRI-WHU 数据集、RSSCN7 数据集。SIRI-WHU 数据集由武汉大学在2016 年发布,数据资源来自Google Earth,其中包含12 个场景类别,分别是农田、商业区、港口、裸地、工业区、草地、立交桥、公园、池塘、住宅区、河流和湖泊。每类均有200 张图像,大小为200 像素×200 像素,空间分辨率为2 m(Zhao 等,2016;龚希等,2021)。每个场景图像示例如图5 所示。
RSSCN7 数据集,2015 年由武汉大学发布,其采集于不同的季节和天气环境下,保证了同一类别图像的丰富性(Zou 等,2015)。该数据集一共包含7 个场景类别,分别是草地、农田、工业区、河湖、森林、住宅区和停车场,其中,每个类别包含400张图像,大小为400 像素×400 像素,场景图像示例如图6 所示。
对含有异常标签的遥感场景图像数据进行异常探测时,本方法需要通过先验知识获取一定数量的正常标签作为初始训练样本,再不断进行迭代运算以加强网络模型的性能,从而提高对异常标签的探测能力。综合考虑运算效率和人工成本,本文选取10%的准确标签作为真实标签,再对剩余90%图像的标签进行修改,使得每类图像含有占比为5%~30%的异常标签作为伪标签并保持总数不变。每类场景含不同异常比例的标签数量如表1 所示,通过10%的真实标签及自训练CNN 对伪标签进行探测。本文采用的数据集在读取之后还需要进行图像预处理,对其依次进行图像裁剪并缩放至224 像素×224 像素、图像翻转、张量转换和图像归一化处理。

表1 每类场景含不同异常比例的标签数量表Tab.1 Number of labels with different abnormal proportions in each type of scene
3.2 实验参数及环境
通过前期的测试,本文实验参数中的epoch 为200,由于CNN 训练时在前期可设置较大学习率以加快收敛速度,后期设置较小学习率使得损失函数收敛在最优值附近,即loss 稳定时其值尽可能的小,因此,学习率分为两部分:在第1~100 的epoch 中学习率设置为0.01;第101~200 的epoch 中学习率设置为0.001。批次大小设置为32,损失函数选取交叉熵误差,优化方法为随机梯度下降(stochastic gradient descent,SGD)法,动量设置为0.9。
实验环境采用Windows 10 操作系统,处理器为八核十六线程的Inte(lR) Core(TM) i7-11700K 3.6 GHz,内存为16GB(8GB×2)3200 MHz 的双通道内存条,显卡为华硕NVIDIA GeForce RTX 3060 12 GB,CUDA 为11.0,深度学习框架为Pytorch,编程语言为Python 3.6。
3.3 评价指标
对遥感场景图像异常探测效果采用四个评价指标,分别是准确率、精确率、召回率和F1 分数。准确率是探测正确的占所有探测的比例,即把正类探测为正类与异类探测为异类的和除以总类数。精确率是探测结果中实际为正类的占探测为正类的比例。召回率是探测为正类的占实际全部正类的比例。精确率和召回率是相互矛盾的,因此,可以同时考虑精确率和召回率,选择它们之间的一个平衡点,即F1 分数。准确率(A)、精确率(P)、召回率(R)和F1 分数(F1)的计算如下:
式中,TP、FN、FP 和TN 分别为正类探测为正类、正类探测为异类、异类探测为正类和异类探测为异类的数量。
4 实验结果与分析
探测次数和异常占比直接影响异常探测的效果,因此,有必要分别讨论探测次数和异常占比对异常探测结果的影响。
4.1 探测次数对结果的影响
探测次数的选择关乎异常探测的效果,前期由于初始真实标签仅占数据集的10%,探测效果通常不够理想,而随着迭代次数的增加,网络性能的不断增强,探测效果越来越好,但所需要的时间也在不断增加,因此,有必要选择一个合适的节点结束循环。三种自训练CNN 在含不同异常标签比例的两种数据集探测中变化规律基本保持一致,因此,选取异常标签占15%的结果进行展示,所得结果如图7 所示。
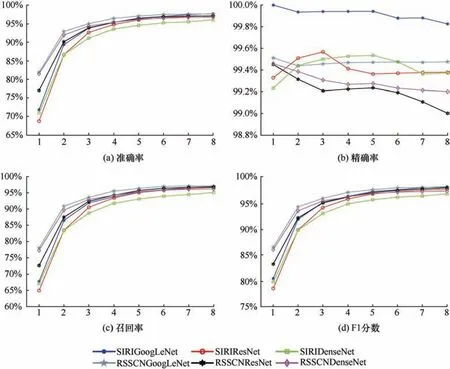
图7 自训练CNN 在不同探测次数中的结果Fig.7 Results of self-training CNN in different detection times
由图7 可以看出,初次探测时的准确率、召回率和F1 分数都较低,分别为69.9%~81.0%、64.9%~78.0%、77.7%~87.1%。随着探测次数的增加,三项指标均在不断提高,当探测次数为6 次时,各项指标已经趋于稳定,且均能够达到94.0%以上。三种自训练 CNN 的精确率在初次探测时均在99.0%以上,其中,自训练GoogLeNet 的精确率更是达到了100%,证明加入真实标签的正类图像中几乎不含错误标签,但是随着探测次数的增加精确率会在99.0%~100%波动。这是因为在探测时可能会有少数含异常标签的图像被当作正类图像加入到真实标签中,导致精确率不断下降。综合考虑准确率、精确率、召回率和F1 分数四项评价指标可以看出,当探测次数为6 时已经趋于稳定。因此,后续异常探测实验的探测次数均为6 次,即将第6次的异常探测结果作为最终结果。
4.2 异常占比对结果的影响
三种自训练CNN 在不同异常标签占比时的准确率、精确率、召回率和F1 分数,如图8 所示。在含有5%~30%的6 种异常标签占比的SIRI-WHU数据集中,自训练GoogLeNet 的准确率分别为96.944%、96.944%、96.435%、96.111%、96.435%和95.509%,均在95.5%以上。在含有5%~30%的6种异常标签占比的RSSCN7 数据集中,自训练GoogLeNet 的准确率分别为96.865、96.429%、96.984%、95.714%、96.151%、96.270%,均在95.7%以上,通过比较可以发现两种数据集的异常探测准确率较为接近。自训练ResNet 在6 种异常标签占比的SIRI-WHU 数据集、RSSCN7 数据集中准确率分别为95.370%、95.046%、95.926%、95.833%、96.157%、94.861%和95.595%、95.794%、96.270%、95.238%、95.437%、95.476%;其中,SIRI-WHU数据集在异常占比为25%时准确率最高、占比为30%时最低,RSSCN7 数据集在异常占比为15%时准确率最高、占比为20%时最低。自训练DenseNet在6 种异常标签占比的SIRI-WHU 数据集、RSSCN7数据集中准确率分别为 95.046%、95.648%、94.444%、95.741%、95.185%、95.278%和95.952%、95.952%、95.794%、95.952%、95.595%、95.278%。通过以上数据可以看出,自训练GoogLeNet 的准确率在不同异常标签占比时均高于另外两种自训练CNN;在SIRI-WHU 数据集中自训练GoogLeNet的准确率随异常标签占比的增加呈降低的趋势,而在RSSCN 数据集中自训练GoogLeNet 的准确率随异常标签占比的增加上下波动,整体相对稳定。精确率是探测为正类的结果中实际为正类的比例,在实际探测过程中,由于网络性能的限制,每次探测时都会有少量的异常标签被错误地判断为正类加入到真实标签中,因此,自训练CNN 的精确率在第一次能够取得较高的结果,随着探测次数的增加,其结果也在逐渐降低。原因是当数据集中异常标签占比越高,异常标签被错误判断的情况就越多,其值就相对较低。
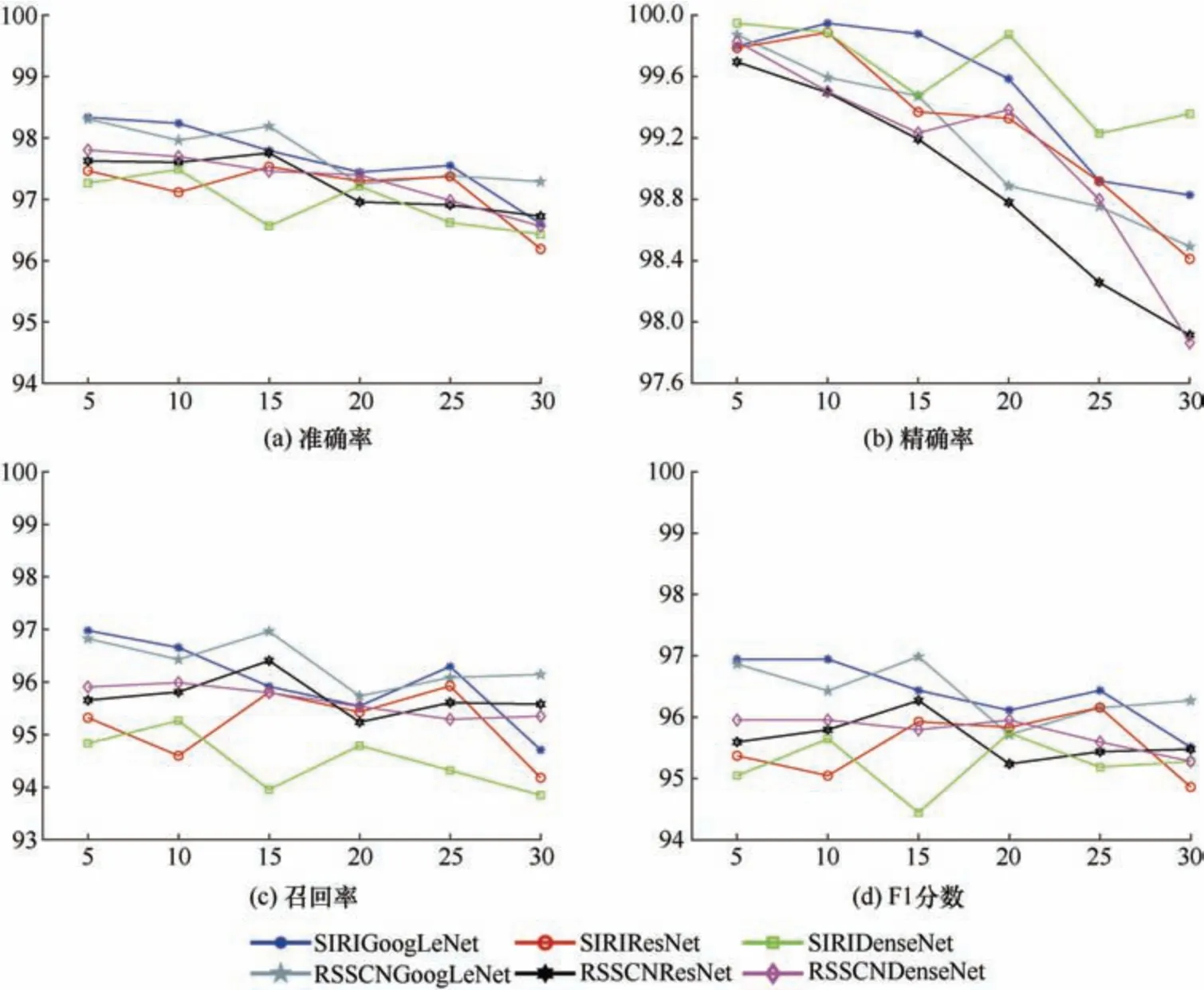
图8 自训练CNN 在不同异常占比中的结果(%)Fig. 8 Results of self-training CNN in different anomaly proportions (%)
三种自训练CNN 在不同异常标签占比时的召回率变化趋势和准确率相似,其中,自训练GoogLeNet 的结果最好。自训练GoogLeNet 在不同异常标签占比的SIRI-WHU 数据集、RSSCN7 数据集中F1 分数分别为98.335%、98.239%、97.794%、97.444%、97.551%、96.603%和98.310%、97.962%、98.191%、97.248%、97.385%、97.289%,其中,含5%异常占比的F1 分数均达到最高。自训练ResNet异常探测的F1 分数结果相对于准确率同样有所提升,整体上升呈现先快后慢的趋势,其值分别为97.467%、97.116%、97.531%、97.297%、97.373%、96.192%和97.625%、97.603%、97.755%、96.958%、96.908%、96.724%,其中,含15%异常占比的F1分数均达到最高。自训练DenseNet 在6 种异常标签占比的F1 分数分别为97.266%、97.488%、96.564%、97.215%、96.621%、96.430%和97.803%、97.696%、97.459%、97.396%、96.981%、96.562%;在SIRI-WHU 数据集中含10%异常占比的F1 分数最高,含30%异常占比的F1 分数最低;在RSSCN7数据集中含5%异常占比的F1 分数最高,含30%异常占比的 F1 分数最低。综上所述,自训练GoogLeNet 的整体效果要优于其他两种方法。
5 结 论
为了有效地对遥感场景图像中标签与实际类别不匹配的异常图像进行探测,本文提出一种基于自训练CNN 的遥感场景图像异常探测方法。采用SIRI-WHU 和RSSCN7 遥感场景数据集,首先,选取准确的10%标签样本作为真实标签,从而为CNN提供初始模型;其次,使用自训练算法增强网络性能,不断地对含有不同异常标签占比的遥感场景数据集进行异常探测;再次,将探测为正类的加入真实标签中,探测为异类的返回至伪标签中;最后,通过不断运算,直至各项指标稳定后,将剩下的伪标签数认定为异常图像。结果表明,三种自训练CNN 在含有不同异常标签的SIRI-WHU 数据集、RSSCN7 数据集中,各项指标均能够取得较好的效果。即使仅选取10%的初始训练样本,含有高达30%的异常标签这一苛刻条件下,其准确率、召回率和F1 分数均依然在93.8%以上,精确率能够保持到97.8%以上。在不同自训练CNN 的异常探测中,自训练GoogLeNet 的总体表现最好,优于自训练ResNet 和自训练DenseNet。
