卷积神经网络在航测图像自动识别中的应用探讨
2024-01-29孙健飞王占岗陶恩海
孙健飞,王占岗,陶恩海
(1.江苏省地质矿产局第六地质大队,江苏 连云港 222023;2.灌云县城乡规划服务中心,江苏 连云港 222200;3.江苏兼金信息产业有限公司,江苏 连云港 222300)
0 引 言
近年来,无人机航测因其使用灵活方便、成本低、设备展开及数据获取速度快等优势,广泛应用于国土资源勘探、智慧工地、林业调查、应急救援等各领域。 外业量测中,轻量化无人机能根据需求快速获取多角度的航测影像。在内页处理中许多影像处理软件应运而生。目前配套的内业处理软件,如大疆智图、PIX4D、SMART3D等,这些软件的处理能力日益丰富,使数字正射影像图和三维模型的生产愈发简便化。但在矢量化地形图的生产上,现有软件在自动识别技术方面还存在缺陷,如R2V软件,对原有单色地形图图纸的扫描件支持较好,而对于数字正射影像图的采集成图难以实现。识别过程中极易受到航测影像采集的视角、姿态、光照、遮挡等条件差异和场景的多样性导致目标发生形变[1]。另外,海量数据带来的处理效率问题,给航测影像的目标分类和识别带来巨大挑战[2-4]。
针对上述问题,本文分析近年来计算机图像识别方面的人工智能模型,结合航空影像固有特性,通过研究识别后与已有绘图软件交互。通过一组基于经典卷积神经网络的航测影像自动识别实验对其实用性进行探讨。
1 卷积神经网络学习框架
传统的目标检测和识别方法采用基于滑动窗口的特征提取框架:区域选择-特征提取(SIFT,HOG)-模型建立(分类器/回归器)。当前研究主要集中于基于人工特征的构造和分类算法上,存在严重依赖人工经验,模型鲁棒性差,泛化能力弱等缺点。并不适用于背景复杂、分辨率高的无人机航拍图像。
与传统方法相比,深度学习的方法采用端到端的解决思路,类似于人的视觉系统,从原始信号摄入开始(瞳孔摄入像素),首先进行初步处理(大脑皮层某些细胞发现物体的边缘、颜色),再进行抽象(大脑判定眼前的物体的形状是圆形的),然后进一步抽象(大脑进一步判定该物体是只气球),最后在大脑中构建出一幅视觉图像[5]。卷积网络受视觉神经机制的启发,为识别二维形状专门设计了一个多层感知器,对平移、比例缩放、倾斜或者其他形式的变形具有高度不变性。
卷积神经网络基本结构可以分为输入层、卷积层、全连接层和输出层4个部分,图1为牛津大学的视觉几何组(Visual Geometry Group)和Google DeepMind公司的研究员一起研发的用于图像识别的经典卷积神经网络模型VGG-NET。
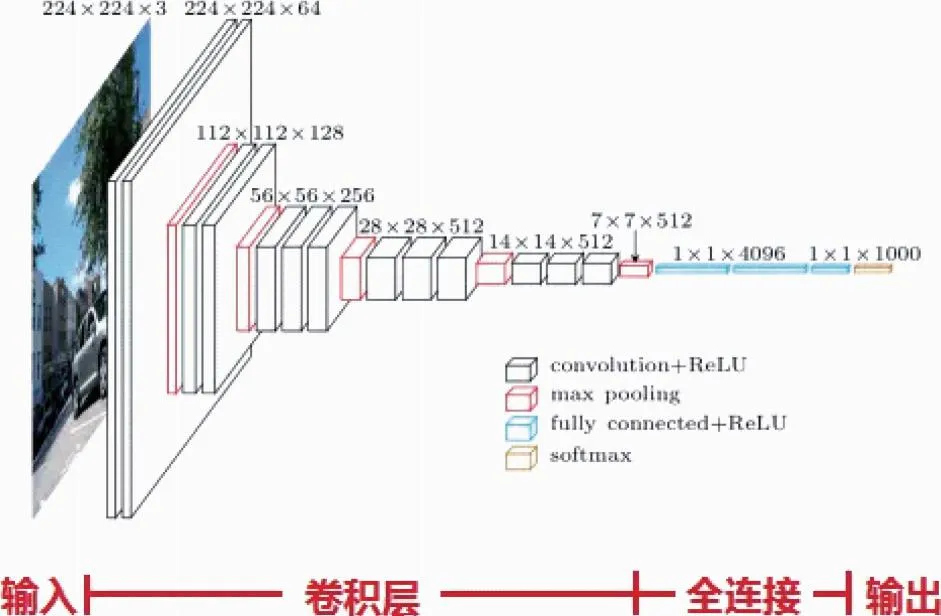
图1 VGG-NET结构图
由图1可知,卷积神经网络借鉴生物神经网络,采用了非全连接和权值共享的多层网络结构。卷积神经网络因其局部权值共享的特殊结构在图像处理方面相比于彼此连接网络有着显著优势。其特征检测层对训练数据进行隐式学习,避免了显式的特征抽取,并且由于同一特征映射面上的神经元权值相同,大大降低了网络的复杂性。在处理时可以采用并行计算技术,对于多维输入向量的图像,可直接输入网络这一特点避免了特征提取和分类过程中数据重建的复杂度。
2012年,Hinton用CNN结合GPU并行处理技术用于Imagenet Challenge数据库中,使分类错误率从26.2%下降到16%,取得了当年最好的分类结果。2014年3月,Facebook用400万张人脸图片训练了一个9层的卷积神经网络,在著名的公共测试数据集LFW(Labeled Face in the Wild)上达到了97.25%的识别正确率,基本接近人眼的辨识水平。
随后,香港中文大学基于Fisher Discriminant Analysis的算法将人脸识别的正确率提高到98.52%,超过了人类水平(97.53%)[5-10]。
2 模型设计与实验分析
2.1 实验环境
本文使用Python和Tensorflow的开发环境并结合航测采集软件探讨航测影像自动采集的可行性。实验环境如表1所示。

表1 实验环境
2.2 数据集
(1)从历史航拍的原始图库中,挑选包含“厂房”“道路”“民房”3种需要标注的物体的图片,通过Photoshop人工截取相关物体的小图,分类保存在CF(厂房)、DL(道路)和MF(民房)3个文件夹中,每种标签的样本制作100个。厂房的原始样本如图2所示。

图2 原始样本
(2)利用OpenCV对每个样本分别进行水平翻转(镜像)、垂直翻转(倒影)、旋转变换,将每个类别的样本数量扩展到400个,并将所有样本图片缩放到同一大小(图3)。

图3 缩放后图片样本
(3)每个标签的样本图片随机取320张,制作用于训练的Tfrecord训练集,剩下的80张图片制作测试集。运行结果如图4所示。

图4 运行结果截图
2.3 模型设计
(1)航测采集软件及接口
在1∶2000比例尺地形图采集中,使用PIX4D软件生成点云并分类、抽稀后处理为高程点,在地物采集方面比较困难。DOM加载进CASS软件的采集方式较为直观,上手最容易。CASS作为Auto CAD二次开发的软件,支持命令栏输入的方式绘制地形图,以命令栏为接口,可方便的实现Python软件的输入。
在CASS通过命令导入的方式实现后,逐步探讨三维模型采集软件EPS中自动采集的可行性。
(2)搭建CNN神经网络
经对比LeNet5、AlexNet、GoogleNet、ResNet等常用卷积神经网络模型,最终选择采用VGG16模型(图5)。
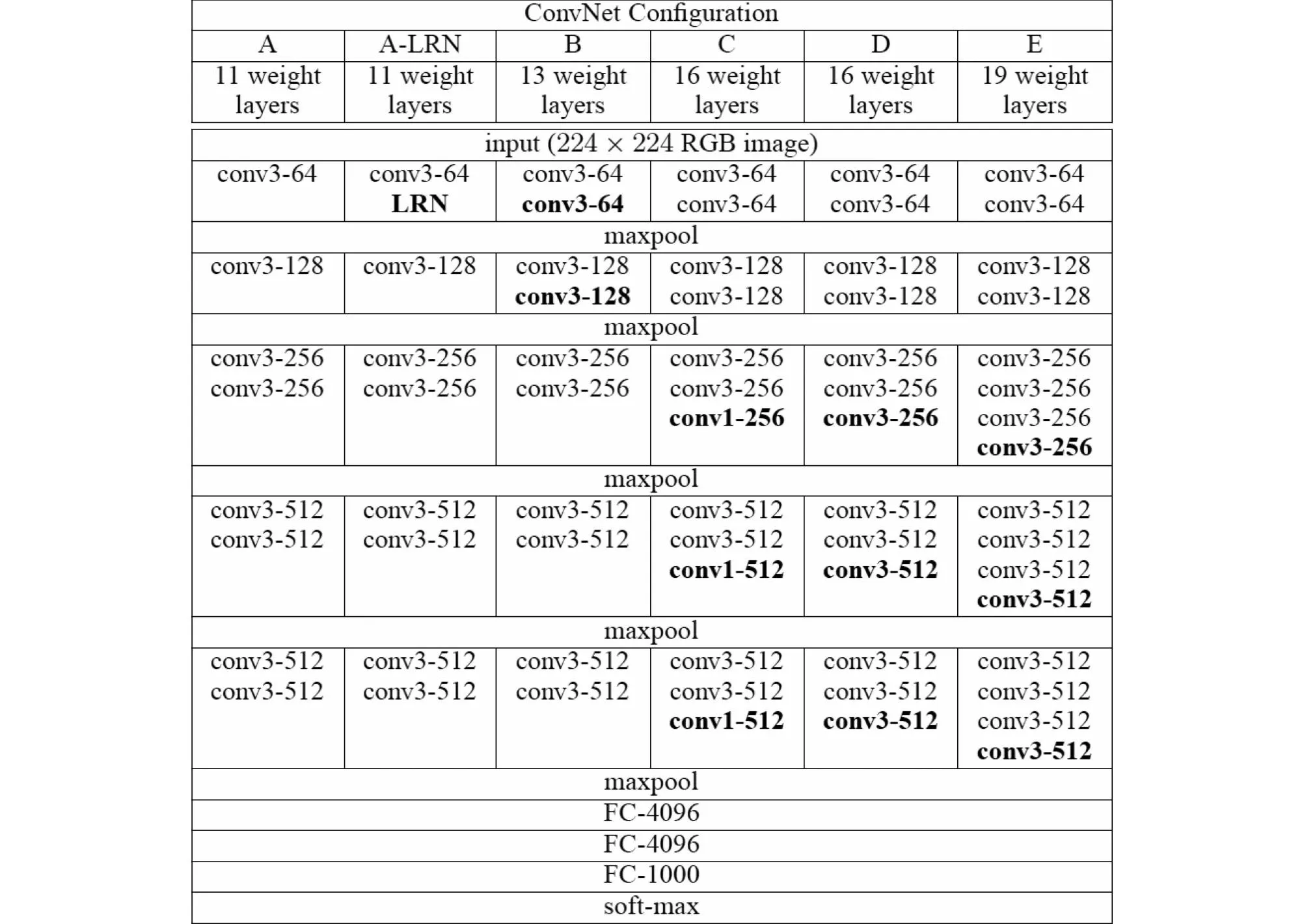
图5 VGG-NET模型分类图(D即为VGG16)
(3)初始化变量,然后执行模型的训练和测试,并保存训练好的模型(图6-图8)。

图6 训练和测试截图

图7 保存训练模型

图8 模型训练验证对比
3 实验结果与分析
载入待处理的航拍图片,通过过滤器和训练的模型识别图片中目标物体,得到包含物体的矩形框的4个点坐标(图9)。

图9 确定处理范围
利用坐标截取图片,通过OpenCV的边缘检测获取边缘线,得到目标物体的顶点坐标;对于细部生成的边长短于30 cm的,去除多余边(图10)。

图10 识别边缘效果
读取jgw文件中的原始坐标和精度,结合矩形框坐标和物体顶点坐标,计算出目标物体的实际坐标值,保存到结果文件中。
将结果文件导入CAD,经验证对厂房的识别率达到97%,因为目标区域正处于大规模基建阶段,道路和路灯的完成度低,识别准确率较低。由于影像分辨率差异较大,存在边缘提取坐标与实测坐标存在误差的情况,后续改进时外业航测精度需提高。
4 结 语
本文探讨了利用经典卷积神经网络提取航测图像中感兴趣目标的可行性。结果表明,VGG16模型非常适合处理能够有效提升高分辨率和复杂背景的航拍图像的识别准确率,但在较小目标如路灯等目标的识别准确率较低,本文后续考虑从以下几个方面改进:① 对输入图像进行精细的预处理(如滤波、白化等);② 原数据集进行数据增强,并进行更多次的迭代;③ 构建具有双重损失函数的糅合模型。
