基于知识结构的自适应测试模型及其应用
2024-01-25许晴媛
郑 琼,许晴媛
(1.闽南师范大学a.教育与心理学院;b.计算机学院,福建漳州 363000)
0 引言
目前,对课业的评估大多采用所有学习者考同一张试卷的传统方式.学习者获得的评估结果仅是分数或排名,对获得自身当前的知识状态及缺失的知识点显得无能为力,仅有少数学习者有机会获得有经验的教师人工诊断每道错题背后缺失的知识点.若利用计算机模拟这个过程,可让所有学习者随时随地获得这方面的帮助,有利于教育资源公平化,也能减轻教师负担.要实现不仅能给出测试的分数、还能给出学习者当前的知识状态及缺失的知识点的计算机自适应测试(Computer adaptive testing,CAT),需要引入新的理论做基础.而知识空间理论(Knowledge Space Theory,简称“KST”)[1]在评估学习者知识结构和能力水平方面极具优势.本文以知识空间理论为基础,建立基于知识结构的自适应测试模型.KST是由美国数学心理学家Falmagne 和比利时数学心理学家Doignon 于1985 年提出的用数学的方法对学习者进行知识评价和指导学习的一种数学心理模型.国外已有大量对知识空间理论的研究,并成功将其理论应用于自适应教学系统和测评系统[1-4].
近年来,国外的KST 研究持续有新成果涌现,如:Pasquale 等[5]将GaLo 模型扩展到技能不独立的情况,并通过一个良级的能力空间来描述技能之间的依赖关系;Heller 等[6]阐述了唯一技能评估的充要条件;Anselmi 等[7]在文中提出了技能评估测试开发的新方法——引入基于能力的测试开发.
国内学者对知识空间理论也开展了一些研究,如:周弦[8]基于传统的知识空间理论,提出了从知识状态边界角度研究自适应测试的选题方法;孙波等[9]将KST 延伸至技能层面,得到了扩展KST 并采用二分法的选题策略;刘艳花等[10]把知识状态边界推广到扩展知识空间理论;周银凤等[11]运用形式概念分析的方法寻找学习路径并进行技能评估;其勒格尔[12]利用KST 的学习诊断模型在“大学计算机基础”课程中进行实践研究;杨桃丽等[13-16]对技能背景下的知识空间理论做许多研究.
从国内外文献研究来看,知识空间理论的研究经过30 多年的发展已趋于成熟,利用知识空间理论实现自适应测试是一种很好的方式,但在应用上还有很多值得探讨的方面.首先,现有研究在测试实施前,大多采用先从问题出发建立知识结构再测试的方式.这样做的弊端是随着试题数量的增加,试题间关系确定难度大.从学科的角度看,特定学科的试题数量往往繁多,甚至海量.且先由问题建立知识结构,当问题改变时,初始步骤就要重建,这将带来麻烦.其次,现有研究在测试过程中,通常采用二分法选题的选题策略,该方法偏程序化,不能真正根据测试对象的特征实现个性化.再次,选题方式会影响测试效率.根据受测者当前的知识状态的选题方法,能符合受测者的特征出题,真正实现个性化.
为了解决以上问题,本文利用知识空间理论,提出了一种基于知识结构的自适应测试模型,设计了该模型的详细实施步骤.在测试中,选题策略采取了在知识基中找边界的方法,提升了选题效率.依据该模型,以“数据库原理与应用”课程中的“SQL 单表查询”内容为对象,编写了自适应测试程序,用程序模拟实现了受测者对该领域知识的个性化诊断,并给出其知识结构和能力水平.
1 预备知识
1.1 知识空间理论
知识空间理论的核心概念包括:问题域、知识状态、知识结构、知识空间和问题之间的推测关系.
问题域是指由一系列问题组成的一个非空有限集Q.
定义1[3]若K是由非空问题域Q的子集构成的集族,且K至少包含∅和Q,则称(Q,K)为知识结构.若K满足并封闭,即对任意Ki,Kj∈K,有Ki⋃Kj∈K,则称(Q,K)为知识空间.K中的元素被称为知识状态.
知识状态是在非空问题域Q={q1,q2,q3,…,qn}中,受测者在理想状态下所能正确解决的问题的集合,用K表示,其中K⊆Q.理想状态是指受测者在没有受到外界压力或情绪干扰的情况下,没有粗心导致的错误和侥幸猜对的情况.
在问题域Q明确的情况下,可直接用K表示知识结构.受测者的知识状态为空集∅,表示其对所测问题域的知识一无所知.受测者的知识状态为全集Q,表示其已全部掌握所测问题域的知识.
定义2[3](Q,K)是一个知识结构,≾是定义在Q上的关系:r≾q⇔Kr⊇Kq,其中r,q∈Q,Kr,Kq⊆K分别表示包含问题r和q的知识状态的集合.当满足r≾q时,称r是q的前提,对应的关系“ ≾”称为推测关系或前提关系.
不与推测关系相冲突的问题集合构成了K的成员.r≾q在语义上可以理解为:解决r是解决q的前提;或者说受测者可以正确回答q,那么就能正确回答r.
定义3[8]设问题域Q是非空有限问题集,K是问题域Q上的知识空间.对任意知识状态K∈K,知识状态K的邻居记作N(K),且N(K)={K′∣K′ ∈K,d(K,K′)≤1};知识状态K与K′之间的距离记作d(K,K′),且d(K,K′)=∣K△K′∣=∣(KK′) ⋃(K′K)∣;知识状态K的边界记作F(K),且F(K)
定义4[2]设F是问题域Q的非空子集族,q∈⋃F,F中包含q的极小集合称为元素q的一个原子(atom),知识基B就是Q中所有问题的原子构成的集族.
例1 设有一知识结构(Q,K),K={∅,{a},{a,b},{b,c},{a,b,c}}中,知识状态{b,c} 是元素b的一个原子,同时也是元素c的一个原子;元素b有两个原子:{a,b} 和{b,c} ;元素a只有一个原子{a} .
一个知识状态可以是几个问题的原子,一个问题也可以有多个原子.这些原子不能由其它知识状态通过并操作来构成,且有限的知识结构中每个问题至少有一个原子.
文献[17]介绍了知识空间中关于基的基本理论和方法.有限的知识空间必有一个基,且知识空间可由基唯一确定.由文献[8]我们有如下定理.
定理1知识空间(Q,K)中,F(K)为知识状态K在知识基B中的边界,则有:
(1) 对任意问题q∉K,如果q∈F(K),当且仅当存在包含q的元素Bq∈B,Bq{q} ⊆K;
(2) 对任意问题q∈K,如果q∈F(K),当且仅当存在不包含q的元素
例2 设有一知识空间(Q,K),Q={a,b,c},K={∅,{a},{c},{b,c},{a,c},{a,b,c}},知识状态K={a,c} .
由定义4,易求得其知识基B={{a},{c},{b,c}},B中的元素分别为问题a,c,b的原子.由定理1,解得知识状态K在知识基B中的边界为:F(K)={a,b,c}.
1.2 基于技能的知识空间理论
基于技能的知识空间理论是知识空间理论引入了技能的扩展[12],原理论中的内容依然有效.基于技能的知识空间理论中有技能域、技能状态、技能结构、技能空间和技能之间的推测关系等概念,这些概念与原理论类似,主要概念描述如下.
定义5[3]若T是由非空技能集S的子集构成的集族,且T至少包含∅和S,则称(S,T)为技能结构;S称为技能结构的域(domain),简称为技能域,T中的元素称为技能状态;若T满足并封闭,则称(S,T)为技能空间.
定义6[3](S,T)是一个技能结构,≾是定义在S上的关系:s≾t⇔Ts⊇Tt,其中s,t∈S,Ts,Tt⊆T分别表示包含问题s,t的技能状态的集合.当满足s≾t时,称s是t的前提,对应的关系“ ≾”称为推测关系或前提关系;T的成员是不与推测关系相冲突的技能集合.
知识结构(Q,K)和技能结构(S,T)之间通过技能函数和问题函数相互联系.对于给定的知识结构与技能结构,以下定义描述了二者之间的联系.
定义7[9]技能函数γ:Q→22S,γ(q) 表示解决问题q所需的极小技能集合的集族,γ(q) 中的元素也称为极小技能状态.
若|γ(q)|=1,表示解决问题q的方法只有一种;若|γ(q)|>1,则表示解决问题q的方法有多种.在建立了技能函数γ的基础上,再定义技能状态函数η.
定义8[9]技能状态函数η:Q→2T,η(q) 表示解决问题q可能的技能状态集合.
由定义7 和定义8 可知,在给定的技能结构(S,T)中,任意问题q,且| |γ(q)=1 时,η(q) 中所有元素的交集即是γ(q) .
定义9[9]问题函数δ:2S→2Q,并且要求满足:δ(∅)=∅,δ(S)=Q.δ(t)表示技能集合t能解决问题的集合.
例3 设有一技能结 构(S,T),S={u,v,w},T={∅,{u},{v},{u,v},{u,w},{u,v,w}},问题域Q={1,2,3}技能函数γ(q)的取值分别为γ(1)={{u}},γ(2)={{v}},γ(3)={{u,w}}.
根据定义8,可求得对应的技能状态函数值分别为
根据定义8,可以求得问题函数:
进而得到知识结构K={∅,{1},{2},{1,2},{1,3},{1,2,3}},从而实现了技能结构与知识结构的联系.
下面阐述基于知识结构的自适应测试模型,并以教育技术学专业课程“数据库原理与应用”中的“SQL 单表查询”内容为实验对象,应用该模型进行自适应测试.
2 基于知识结构的自适应测试模型
基于知识结构的自适应测试模型是对于某个具体的知识领域,利用知识空间理论,建立知识结构并进行自适应测试,并把整个测试过程划分成不同的步骤.基于知识结构的自适应测试模型包括四个步骤.
2.1 建立技能结构
本文统一把知识点当作技能.对于特定学科领域,虽然题目众多,但知识点的数量较固定且有限,故选择从技能开始建立技能结构.学科专家根据测试目标确定技能结构的域,并根据经验确定技能间的推测关系,由推测关系,建立技能结构(S,T).
2.2 构建知识结构
学科专家根据技能结构的域S,选择问题构成知识空间的问题域Q;根据经验和定义7,建立技能函数γ:Q→22S;根据定义8,计算得出技能状态函数的值η:Q→2T;再根据定义9,求得问题函数δ:2S→2Q;进而构建用于测试的知识结构(Q,K).
下面给出构建知识结构的算法.
算法1 构建知识结构.
输入:问题域Q,各问题和其前提问题的键值对preKps.
输出: 知识结构KStruct.
步骤1: 计算所有可能的知识状态AllStateSet.
步骤2:构建知识结构.
(1)KStruct=set()
(2)for KState in AllStateSet:
如果KState 中任意问题如果存在前提问题,且其前提问题都在KState 中,则将该问题加入到KStruct 中;
如果KState 中有问题不存在前提,则将该问题加入到KStruct 中.
步骤3:输出KStruct.
2.3 实施基于知识结构的自适应测试
建立技能结构和知识结构后就可以进行测试.测试的重点是选题策略,即每次选出哪个问题进行测试.根据受测者当前已掌握知识状态出题能真正实现个性化.更优的选题策略能兼顾个性化又能尽快的诊断出结果,从而提升测试效率.常用的选题算法是二分法,如文献[9],该方法偏程序化,不能真正实现个性化.另一种方法是在知识状态的边界中选出下一测试问题,如文献[10],通过计算各当前知识状态的邻居(距离≤1),从而得到该知识状态K的边界F(K),进而按照规则在F(K)中选择下一个要进行测试的问题.此法较二分法更能实现“个性化”,但随着问题数量增多,知识状态的数量将会成指数增长,此法需要不断的计算当前知识状态的邻居和边界,将消耗大量的时间和内存,势必会影响选题效率.而在一个知识空间中,知识基的数量远小于所有知识状态的数量.故本文引入知识基的概念,采用在知识基的边界进行选题的策略来解决这个问题,以实现更高效的个性化测试.
在测试中,判断受测者是否掌握了某个问题q或极小知识状态B,B∈B,约定以下规则:
(Ⅰ)掌握了q,则一定掌握了q的至少一个极小知识状态B;
(Ⅱ)掌握了某个极小知识状态B,则一定掌握了B中所有的问题;
(Ⅲ)没有掌握q,则没有掌握q所有的极小知识状态,反之亦然.
当受测者正确回答某一问题r时,应用规则(Ⅰ)确定其掌握了r的极小知识状态K′(如果r有多个极小知识状态,则随机选择一个),反复应用规则(Ⅰ)、(Ⅱ)可以确定受测者掌握了属于K′的问题和包含于K′的极小知识状态K″,并令该受测者已掌握问题的集合为当前知识状态K,进而根据定理1,计算K的边界F(K),并从F(K)中选取还未掌握的问题出题.
如果受测者错误回答某一问题r时,应用规则(Ⅲ)确定其没有掌握r所有的极小知识状态,则保持其当前知识状态K不变,并继续从F(K)中选取还未掌握的问题出题.
测试结束条件:边界F(K)中无题可选或F(K)为空.受测者的最终知识状态为K,计算最终知识状态K与Q之间的距离d(K,Q)可以确定受测者的能力水平,并转换为技能状态.
下面给出基于知识结构的自适应测试中,采用在知识基的边界进行选题的策略,由受测者某一时刻知识状态,得到最终知识状态的测试算法.
算法2 基于知识基边界选题策略的测试算法.
输入: 受测者在某时刻的知识状态temp_KState.
输出: 测受测者最终掌握的知识状态.
步骤1: 约定几个变量.
令Q为问题域,Bk为知识基,KState 为受测者的知识状态,YcT 为已出题的集合.
步骤2: 定义函数FK(tempKState),其功能是在知识基中求知识状态的边界.
步骤3: 在知识基的边界中选题.
(1)border=FK(temp_KState)#border 为知识状态在知识基中的边界.
(2)choicedTp=list(border-temp_KState)#choicedTp 为可选问题.
(3)while choicedTp:
步骤4: 当无题可选或边界为空时,return KState.
2.4 输出测试结果
通过技能函数,把受测者的最终知识状态转化为对应的技能状态,计算其与技能域S 的差可得到受测者缺失的技能.自此,基于知识结构的自适应测试已完成,实现了对测试对象能力的评估.
上述基于知识结构的自适应测试模型可用图1 描述.如图1 所示,左图是测试的主要步骤,右图是选题过程的主要流程.

图1 基于知识结构的自适应测试模型
3 基于知识结构的自适应测试模型应用
通过“数据库原理与应用”课程的学习中可知,建立数据库的目的是存储数据、查询和处理分析数据.数据库查询是数据库的核心操作.在学习过程中,获取学习者对查询操作的掌握情况,可帮助学习者及时查漏补缺,有利于个性化学习.下面以“SQL 单表查询”内容为例,阐述基于知识结构的自适应测试模型进行测试的具体实施过程.
3.1 建立技能结构(S1,T1)
由学科专家确定“SQL 单表查询”内容的知识点,则技能结构的域S1={a,b,c,d,e}中各技能编码及描述如下:a为select 语句的一般格式,b为查询表中的若干列,c为查询表中的若干元组,d为对查询结果进行排序,e为对查询结果进行分组.
学科专家根据经验,定义技能域S1={a,b,c,d,e}中各技能之间如下语义:
(1)若受测者掌握了技能b,那么必掌握了其前提技能a;
(2)若受测者掌握了技能c,那么必掌握了其前提技能a;
(3)若受测者掌握了技能d,那么至少掌握了其前提b,c中的一个;
(4)若受测者掌握了技能e,那么必掌握了其前提技能b.
根据以上语义,由定义6 易得技能域S1={a,b,c,d,e}中各技能的推测关系为:a≾b,a≾c,b⋁c≾d,b≾e.如图2 所示.

图2 技能域S1={a,b,c,d,e}中各技能推测关系
根据定义6,符合以上推测关系的技能状态有12 种,它们构成了技能结构T1={∅,{a},{a,b},{a,c},{a,b,c},{a,b,d},{a,b,e},{a,c,d},{a,b,c,d},{a,b,c,e},{a,b,d,e},{a,b,c,d,e}}.自此,建立了技能结构(S1,T1),其哈斯图如图3所示.由定义5可知,T1在并上封闭,故(S1,T1)是一个技能空间.

图3 技能结构(S1,T1)哈斯图
3.2 构建知识结构(Q1,K1)
下面在“SQL 单表查询”内容建立技能结构(S1,T1)基础上构建其对应的知识结构(Q1,K1),具体步骤如下:
第1步 由学科专家根据技能结构(S1,T1),从教材《数据库系统原理教程(第2 版)》[18]中选出基于“学生-课程”数据库的查询题目,构成一个关于“SQL 单表查询”的问题域Q1={q1,q2,q3,q4,q5},如表1 所示.开放性的问题可一定程度上避免侥幸猜对的情况.

表1 “SQL 单表查询”的问题域Q1
学科专家根据经验,给出问题域Q1中各问题之间存在的如下语义:
(1) 若受测者能解决问题q2,那么一定能解决问题q1;
(2) 若受测者能解决问题q3,那么一定能解决问题q1;
(3) 若受测者能解决问题q4,那么至少能解决问题q2,q3中的一个;
(4) 若受测者能解决问题q5,那么一定能解决问题q2.
根据以上语义,由定义2 易得问题域Q1={q1,q2,q3,q4,q5}中各问题的推测关系为:q1≾q2,q1≾q3,q2⋁q3≾q4,q2≾q5..如图4 所示.
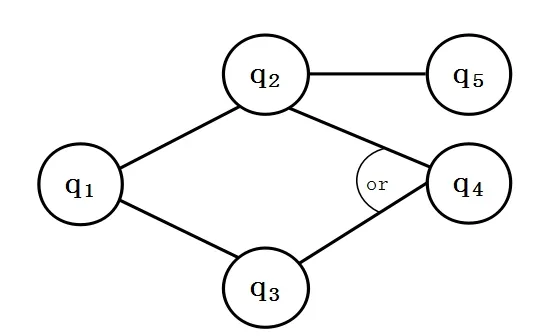
图4 问题域Q1 上的推测关系≾
第2步 由定义7,学科专家依据经验,对“SQL 单表查询”内容,给出技能函数γ1:Q1→22S1,取值如下:
根据定义8,在技能函数的基础上,计算技能状态函数η1:Q1→2T1的值.由T1={∅,{a},{a,b},{a,c},{a,b,c},{a,b,d},{a,b,e},{a,c,d},{a,b,c,d},{a,b,c,e},{a,b,d,e},{a,b,c,d,e}},可以求得对应的技能状态函数η1值为:
这里需要检查技能状态函数η1是否是单射.如果不是单射,即存在不同问题有相同的技能状态函数值,则根据需要保留其中一个问题,从而保证每一个问题都是可辨识的,满足|Q1|≤|T1-{∅}|.因η1(q1),η1(q2),η1(q3),η1(q4),η1(q5)的值都不同,即问题域Q1中所有的问题是可辨识的.
第3步 由定义9,求解问题函数δ1:2S1→2Q1.我们仅须考虑有意义的元素,即缩小定义域为T1,因此问题函数δ1:T1→2Q1,T1⊆2S1.对技能结构T1中的每一个技能状态都进行计算,结果如下:
根据以上计算得出所有问题函数的值,就是知识结构K1的值.故有
由以上方法构建的知识状态与技能状态是一一对应的.自此,建立了测试用的知识结构(Q1,K1),其哈斯图如图5 所示.由定义1 可知,K1在并上封闭,故(Q1,K1)是一个基于能力的知识空间.

图5 知识结构(Q1,K1)的哈斯图
3.3 实施“SQL 单表查询”内容的自适应测试
由定义4,易得“SQL 单表查询”内容对应的知识空间K1的知识基B1={q1},{q1,q2},{q1,q3},{q1,q2,q4},{q1,q3,q4},{q1,q2,q5},即B1中各元素分别是问题q1,q2,q3,q4,q5(q4有2 个原子:{q1,q2,q4},{q1,q3,q4})的极小知识状态.
“SQL 单表查询”基于知识结构的自适应测试过程阐述如下:
(1) 假定受测者初始知识状态K=∅,初始边界为∅.
(2) 随机选择问题域Q1中的一个问题作为初始测试问题.
若受测者对初始问题回答错误,则选择该问题的前提问题再测试.如果一直回答错误,直到空集,表示受测者对这个领域的知识一无所知.如果回答正确,按照下述方法继续测试.
假定初始测试问题是q2,且受测者回答正确,根据基于知识结构的自适应测试规则(Ⅰ)可知其掌握了问题q2的极小知识状态{q1,q2},分别根据规则(Ⅱ)、(Ⅰ)可知受测者掌握了问题q2,q1以及{q1},此时受测者的知识状态K1为已掌握问题的集合,即K1={q1,q2}.
(3) 由定理1,解得知识状态K1={q1,q2}在知识基B1中的边界为F(K1)={q2,q3,q4,q5}.因为q2已经在其当前知识状态K1中,故从边界中任选其它问题q3,q4,q5.不妨选择q3,若受测者回答正确,根据规则(Ⅰ)可知其掌握了问题q3的极小知识状态{q1,q3},根据规则(Ⅱ)可知其掌握了问题q1,q3,故受测者的知识状态被更新为K2={q1,q2,q3}.
(4) 由定理1,解得知识状态K2={q1,q2,q3}在知识基B1中的边界为.由于q2q3已经在受测者的知识状态中,不必重复测试,故在q4,q5中随机选择q5,假定受测者回答正确,根据规则(Ⅰ)可知其掌握了问题q5的极小知识状态{q1,q2,q5},根据规则(Ⅱ)可知其掌握了题目q1,q2,q5,受测者此刻的知识状态被更新为K3={q1,q2,q3,q5}.
(5) 由定理1,解得知识状态K3={q1,q2,q3,q5}在知识基B1中的边界为由于q3已测试过,不必重复测试,故择问题q4,假定受测者回答错误,根据规则(Ⅲ)可知,受测者对于问题q4的两个极小知识状态({q1,q2,q4},{q1,q3,q4})均没有掌握,受测者此刻的知识状态保持不变,即K4=K3.继续从F(K3)中选取没有被掌握的问题出题,而F(K3)中已无题可选,故测试结束.该受测者最终知识状态为K4={q1,q2,q3,q5}.
测试过程如图6 所示,图中描述了由初始试题q2沿箭头方向依次出题q3,q5,q4的全过程,圆角矩形框内为题目qi对应的极小知识状态;Ki为受测者在某一时刻的知识状态;“q2+”表示受测者正确回答问题q2;“q4-”表示受测者错误回答问题q4.
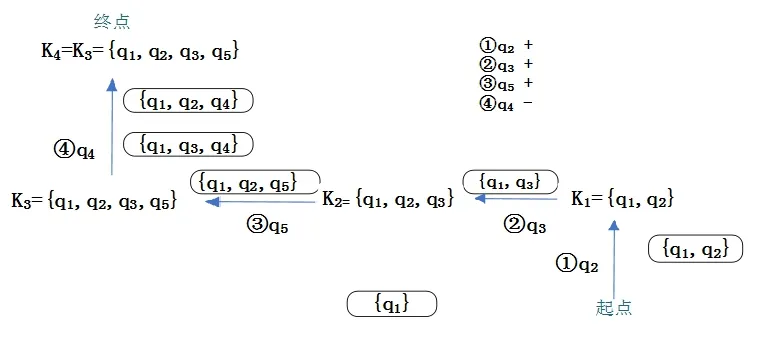
图6 基于知识结构的自适应测试过程
3.4 输出测试结果
通过技能函数γ1,把受测者最终的知识状态K4={q1,q2,q3,q5}转化为对应的技能状态{a,b,c,e},于是,得到该受测者未掌握的技能是{d} .至此,该受测者本次就“SQL 单表查询”内容基于知识结构的自适应测试已经完成,并得到了受测者知识结构和能力水平.
4 实验模拟
下面依据基于知识结构的自适应测试模型,使用Python 编程语言,在算法1、算法2 的基础上编写程序.该程序主要功能是实现对“SQL 单表查询”的自适应测试,受测者通过与程序交互,完成测试,实现对受测者能力水平的快速测试.运行环境为:Intel(R)Core(TM)i7-5500UCPU@2.40GHz 处理器,8GB 内存,64 位Windows7操作系统,Anaconda3,Python3.8.
下面给出两次模拟实验演示的具体测试情况.
模拟实验1 是运行自适应测试程序并模拟受测者作答的一次测试过程,其具体过程如下:
首先,系统随机出题q3,根据程序提示,模拟受测者输入的正确答案“select sname,sage from student where sage<20”,程序立即给出作答正确反馈,并计算出当前知识状态为{q1,q3},边界为{q2,q3,q4},可选问题为{q2,q4}.继续出题q4,模拟输入错误答案“>”,程序批改并保持知识状态不变.继续出题q2,模拟输入正确答案“select sno,sname from student”,程序给出作答正确反馈且更新当前知识状态为{q1,q2,q3},边界为{q2,q3,q4,q5},因q2,q3已掌握,q4已测试过,不必重新测试,故可选问题为{q5}.继续出题q5,模拟输入错误答案“<”,程序给出作答错误反馈,并保持知识状态不变.此时,已无题可选,故测试结束.
最后,给出本次测试结果:受测者最终的知识状态为{q1,q2,q3},已掌握技能为{a,b,c},缺失技能为{d,e}.模拟实验1 的自适应测试过程如图7 所示.


图7 基于知识结构的自适应测试过程实验模拟1
模拟实验2 是运行自适应测试程序并模拟受测者作答的再一次的测试过程,如图8 所示.程序运行后,进入测试环节,依次出题q5,q4,q3,分别模拟受测者给予正确、错误、正确的回答,程序依次根据作答情况给出反馈,并迅速得出本次测试结果:测试者最终知识状态为{q1,q2,q3,q5},已掌握技能为{a,b,c,e},缺失技能为{d}.本次模拟测试结束.
以上两次模拟实验验证了运用本文所提出的基于知识结构的自适应测试模型就“SQL 单表查询”内容对受测者进行诊断,其可行性、选题算法的有效性和测试的个性化.因此,该模型能够实现对受测者进行个性化能力诊断.
综上所述,基于知识结构的自适应测试采用在知识基的边界中选题的方式,缩小了搜索范围.随机选择初始问题,增强了可操作性,之后每一次选题都取决于受测者当前的知识状态,且不同测试者其测试过程所需回答问题及其数量因人因时而异.从而实现了真正意义上的个性化测试.
5 总结与展望
本文主要探讨了一种基于知识结构的自适应测试模型,并把该模型应用在“SQL 单表查询”内容,用程序模拟实现了受测者对这部分学习内容的个性化诊断,并给出其知识结构和能力水平.在已有方法的基础上,本文主要进行了两个方面的改进:提出从技能而不是从问题入手的顺序更符合教学规律也便于实现,易于扩展;采用知识基的边界选题节省了大量计算邻居的开销,能更好地实现快速个性化诊断.除了测试功能,未来可以扩展到个性化学习资源推送和生成可视化学习分析报告等方面.问题域Q 的各成员可以扩展到一类问题,每一类由多个问题组成.每次抽取某一类中的一题组成问题域.这样可以达到不同的受测者使用不同问题,或者同一测试者多次测试而问题不同.
