匿名化的动态优化与系统建构
2024-01-25闫怡萱王梓嫣李文健
■ 文/闫怡萱 王梓嫣 李文健
随着互联网、大数据的快速发展以及数据共享范围的逐步扩大,数据的自动收集和发布越来越方便。然而,任何事物的出现都具有两面性,在数据发布过程中隐私泄露问题也日益突出,而匿名化技术可以有效解决链接攻击所带来的隐私泄露问题,成为扼制信息泄露的一大关键手段。
匿名化的法律法规
数据、隐私等个人信息需要保护已成为世界之共识,美国、欧盟、新加坡等国家和地区均发布了匿名化相关的法律法规(见表1)。目前,我国的匿名化概念是指,通过对个人信息的技术处理,使得个人信息主体无法被识别或者关联,且处理后的信息不能被复原的过程。其关键点在于,数据一旦经过了匿名化处理,就不再属于个人信息。这就使得匿名化反而成为逃脱隐私信息保护责任的捷径,因为数据只要经过极其简单的匿名化处理,就不再属于个人信息,也就免除了技术处理人员对处理后信息的保护义务。这样的逻辑无疑赋予了匿名化斩断个人信息与信息主体一切关联的效果,片面强调匿名化的效果而忽略数据流转、处理的动态过程。
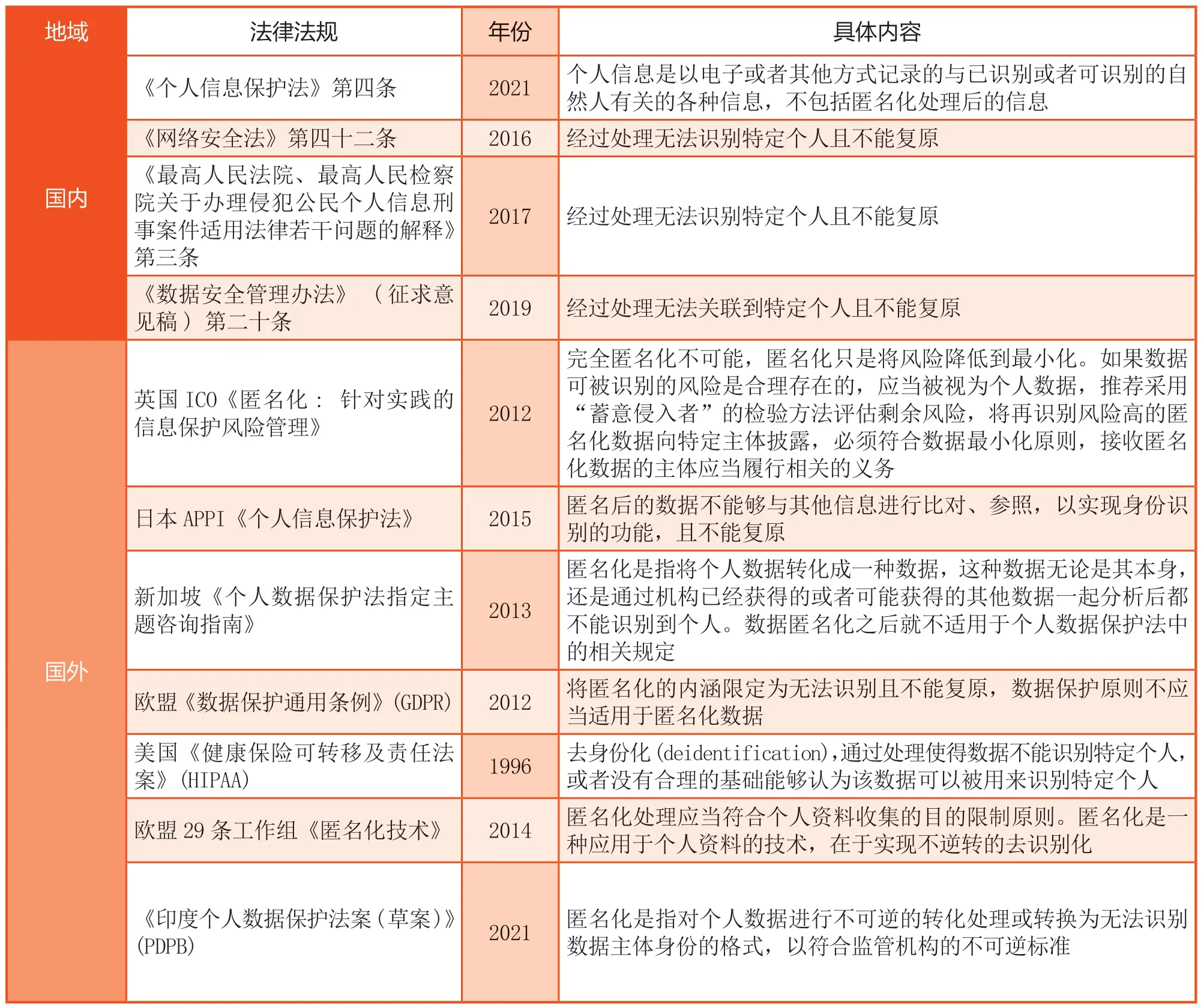
表1 匿名化相关的法律法规
然而,假如采取了较为严格的匿名化认定模式,那么匿名化又成为伪命题,因为只要有足够的外部信息,经过匿名化的数据都可以被重新识别还原,这就使得真正的匿名化需要抹杀掉原始数据全部的后续利用价值。
动态化的匿名化及场景理论
●动态化的匿名化
由上文可知,匿名化操作的技术有效性和数据实用性的矛盾成为难以平衡的价值选择。英国南安普敦实大学法学院信息技术法和数据治理教授索菲·斯塔尔- 鲍迪伦(Sophie Stalla-Bourdillon)和法学研究员艾利森·奈特(Alison Knight)等曾提出,应当将匿名化视为一个持续不断的动态过程。笔者认为,匿名化如果可以随着数据的使用和流转而不断进行下去,将有利于实现对数据的监管。
动态的匿名化是指在信息处理的各个过程以及先后多次的匿名化过程中进行匿名操作和监管的匿名化方式,有别于传统的“操作即完成”的静态匿名。在动态匿名化的实现中,不可或缺的一项就是引用场景化。对于不同的场景,法律所保护的个人信息敏感点并非是完全相同的,即使相同的数据在不同的使用场景下也需要采用不同的匿名化处理,在场景的转换中进行相应的操作从而实现实时更新的匿名化。
●场景化的引入
场景化并非是在互联网的信息保护领域最先出现的。场景在一开始仅为影视传媒中的概念,经过学者在更多维度的使用,场景理论的适用范围从现实场景延伸到了互联网场景中。场景理论看似与匿名化没有直接关联,个性化信息的匿名似乎是不具有公共性的。然而,在个人信息的背后隐含着共同的匿名需求和共性的匿名操作。此外,相同的匿名化操作会因为场景的变换而导致信息的匿名有效性发生变化。
新西兰康奈尔理工学院信息科学教授海伦·尼森鲍姆(Helen Nissenbaum)在应对匿名化的动态性问题时提出了场景完整性理论。此概念通过社科类型的定义应对技术领域的难题,以此为隐私确定界限。该理论强调个人信息的隐私性指的并非信息的不可泄露,而是信息的合理使用和传递,因为只有信息不断传递才能完成社会关系的建立,这是对个人隐私的合理期待。此理论中,信息拥有者、信息关联主体、信息传输者、信息接收者以及信息的种类构成了信息流动的五要素,任何一个要素都决定了信息流动的性质。
匿名化的场景实现
●风险评估体系的引入
匿名处理为适应多种场景实现动态化会面临不同场景标准不同的问题,这就需要引入针对各个场景的风险评估体系。不过,国内目前并未确立完备的评估规范,仅停留在行业内的经验交流阶段,属于法律法规的空白地段。匿名化的安全性和后续数据实用性上的平衡难以精确把控,信息使用场景多样化、不同场景的敏感程度不同,是规范难以确立的两大关键因素。
匿名化的风险评估体系需要结合的是场景下的信息隐私性程度,需要着重考量以下内容。一是信息接收者可利用的技术和工具水平。随着人工智能技术的发展,信息重识别不再成为专业技术人员的“专利”,因此在技术手段逐渐公开化、大众化的进程中,获取可操作的重识别方式的成本大大降低。无论是客观方面还是主观方面,这一条件都会影响信息接收者的重识别的意愿。二是其他外部信息的可获取程度,这一点决定了去匿名化的可能性大小。三是信息使用者的使用目的与申请信息时的目的是否匹配,如果发现信息使用者在使用过程中违背了申请接收信息时的目的,可以认定其为违法行为。
●风险评估体系的构建
匿名化处理者需要在处理时进行一定的风险预测,目前看来有较为严格的“所有合理可能性”标准,还有“蓄意入侵者检验”标准,以及“专家判别”标准,我们需要做的不是将三者简单相加,对匿名化进行一层一层的过滤,而是将三者融合为一体,各司其职,充分发挥其可用性的同时避免程序冗杂。
第一步,针对信息处理者而言,仅需要对相应的风险进行可能的、合理的排除。虽然“所有合理可能”看似过于严格,不适于应用在动态化监管之中,但这不意味着此项标准应被完全摒弃,而是应当要求信息处理者按照合理的程度进行自查,在数据中不得在一般认知和法律框架下出现缺漏,其流程包括对特定标识符的删除或替换、对可能再识别的人群的甄别、对再识别动机的分析以及考虑所有合理可能手段。
第二步,进行蓄意入侵检验,通过实践操作模拟入侵状况。只需在信息现有处理者完成自查之后提交给监督机构,相关技术人员确定相应场景下的再识别风险,综合运用网络上任何可以合法获得的信息进行再识别测试,以确保蓄意入侵检验可以排除绝大多数的再识别情形。在完成这一步后,数据即可准许流通,但并不意味着信息处理者的法律责任终结。
第三步,进行专家判别。在第二步完成后,安排专家以最前沿的匿名化认知以及前瞻性的视角定期对数据进行抽检,开展隐私风险评估,明确当前及可预见未来的威胁,并及时对数据匿名策略做出调整。
风险评估体系的法律责任
在引入风险评估体系之后,相应的法律责任划分也应当进一步明确。对信息接收者而言,需要严格遵守信息流通合同中的内容。另外,信息接收者需要在信息流通中首先进行申请,明确信息使用的用途和范畴,并且在接收数据后严格按照此范围进行,否则应当承担违约责任、行政责任甚至刑事责任。双方不得在合同中约定排除最基本、最低限度的防范重识别的义务。同时,也应当在合同中对数据的后续使用做出安排,或者在项目完成时对数据进行返还销毁,或者进行下一步流转。在信息再次传递时,应当同样按照匿名化标准进行,并及时告知上游信息传递者,以便对信息实现监管,多层的信息流转采用间接监管而非垂直监管的模式。
引入动态化的匿名化,使匿名化不再于一次操作后戛然而止,而是随着数据的使用和流转不断更新,这有利于对全流程的信息保护。法律责任的空缺区域需要弥补,从而形成较为严密的法律责任分配体系。为了实现匿名化的动态化,可引入场景化,充分保证数据的有效性并更具针对性,形成基于场景的数据流转闭环。为了更好地实现场景化,应引入风险评估体系。
匿名化的初衷是降低隐私泄露风险,匿名化的动态化将极大地改善匿名化对隐私保护的效用,为数据主体提供强有力的隐私保障,从而增强民众对大数据的信任,促进大数据领域的健康发展。
