机器学习指导相和硬度可控的AlCoCrCuFeNi 系高熵合金设计
2024-01-25李亚豪叶益聪赵凤媛朱利安白书欣
李亚豪,叶益聪,赵凤媛,唐 宇,朱利安,白书欣
(国防科技大学 空天科学学院 材料科学与工程系,长沙 410073)
钢铁、铝合金及镁合金等传统合金是以单一元素为主要元素,掺杂少量其他元素来改善材料性能,因此合金的性能常常受限于其主元的性质。Yeh 等[1]和Cantor 等[2]提出的高熵合金(high entropy alloy,HEA)打破了传统合金的设计理念,它是一种无主元或多主元合金,每种组成元素都是合金的主元,这使得高熵合金的原子分布混乱无序,而恰恰是这种高混乱度产生了意想不到的稳定性,使得高熵合金更倾向于形成固溶体结构。通过对高熵合金组成主元的自由设计,有望解决传统结构材料低温和高应变速率下韧脆转变、强度塑性矛盾等问题[3-5],拥有广泛的应用潜力[6-7]。例如,Li 等[3]设计的相变增塑的双相Fe50Mn30Co10Cr10高熵合金,相比同等晶粒尺寸的CrMnFeCoNi 合金,塑性提高超过20%的同时强度增加近30%。
高熵合金多种主元的复杂性造成其潜在成分空间过于庞大以及合金相结构与性能的影响因素众多等问题,若采用传统的材料研究方法,合金设计过程将十分困难,研发及性能优化周期也比较长。研究人员曾试图从以往的数据中总结高熵合金相形成的规律[8-12],例如Zhang 等[8]通过计算Ω参数来分辨高熵合金是否形成固溶体结构。然而受限于可视化分析和高熵合金样本的数据量,在对合金的参数进行结构判据的归纳总结过程中,仅支持2 个至多3 个参数同时分析,难以充分考虑高熵合金相结构影响因素,使得经验参数的判据只能局限于小体系中。随着数据挖掘技术和人工智能的高速发展,以机器学习方法为代表的数据驱动材料科学能够有效联合经验、理论、实验和计算机模拟方面的优势,更准确地探究高熵合金成分-结构-性能间的关系与规律[13-14]。近年来,使用机器学习手段辅助高熵合金设计的报道逐渐增多[15-20],通过这种数据驱动的方法,能够极大减少新型合金设计的时间和成本。目前机器学习模型已经在高熵合金各种性质的预测上有所研究,例如,Yan 等[16]通过训练好的梯度提升(gradient boosting,GB)模型,预测并验证了10 种新型固溶体结构的难熔高熵合金。Sun 等[18]利用XGBoost 模型实现了对TiZrNbTa 合金硬度的精准预测,经过实验验证,其预测值的准确率高达97.8%。Liu 等[19]在利用机器学习方法研究γ′相增强的Co 基高温合金的工作中,将合金的γ,γ′相分类模型和γ′相固溶度的回归模型同时用于成分空间的高通量筛选,取得了较好的结果。
AlCoCrCuFeNi 系高熵合金具备良好的软磁性能[21]、力学性能[22]、耐磨性[23]等特点。冯力等[23]将AlCoCrCuFeNi0.5 合金作为耐磨涂层用于45#钢表面。自该体系高熵合金提出以来已被众多学者研究报道,特别是关于其相组织和硬度的研究,至今已积累了大量相关的材料数据,为数据驱动的研究提供了有利条件。目前已有一些建立机器学习模型辅助AlCoCrCuFeNi 合金体系研究的相关报道,例如Huang 等[24]基于神经网络算法构建了AlCoCrCuFeNi合金的相分类模型,对于该体系合金固溶体和金属间化合物的分类准确率高达94.3%。然而,仅做了模型计算工作,并未进行实际的实验验证,无法证明其模型的实际泛化能力。Wen 等[20]以AlCoCrCuFeNi 合金的成分作为输入,硬度作为输出,通过支持向量机模型设计了硬度高达880HV 的新型合金。本工作采用机器学习的方法,以AlCoCrCuFeNi 高熵合金为切入点,通过同时建立高熵合金的相预测模型和硬度预测模型,以期使用相对传统实验方法更低的设计成本和时间,在高熵合金设计空间中快速筛选出相种类和硬度皆符合预期的新合金,并通过实验检验模型结果,开展合金设计的新模式。
1 实验材料与方法
1.1 机器学习方法
建立机器学习模型的过程,本质上是利用特定的机器学习算法,根据所给的数据集计算特定的参数组合,学习数据集中隐含的知识,得到与数据拟合程度较高且具有一定泛化能力的预测模型。
1.1.1 数据集的建立
多年的高熵合金研究积累了大量的数据,关于高熵合金的相结构和硬度预测模型,也有很多相关的文献报道。本工作借鉴了Senkov 等[25-27]、Machaka[28]、Wen 等[20]和Qiao 等[29]的工作。其中Machaka[28]使用1460 个高熵合金相数据来训练模型,并对高熵合金面心立方(face centered cubic, FCC)相、体心立方(body centered cubic, BCC)相和FCC+BCC 双相的三分类进行了较为准确的预测,然而该数据集中涉及到制备方法和热处理工艺等影响因素,使得合金成分上存在较多重复。由于工艺因素影响复杂,且验证过程较难控制,本工作将不考虑这些因素造成的影响,仅选择报道最多的电弧熔炼法制备的铸态合金数据,最终得到一个包含323 条数据的高熵合金相结构数据集。硬度数据集则沿用Wen 等[20]所用的一个包含155 条Al-CoCrCuFeNi 系高熵合金硬度的数据集。此外,注意到Senkov 等[27]的报道中含有18 个额外的AlCoCr-CuFeNi 系高熵合金硬度数据。本工作将两个硬度数据合并,样本增加至173 个。至此,构建了一个较大的高熵合金相结构数据集和一个较小的硬度数据集,两个数据集中的样本成分覆盖了大部分现有的AlCoCr-CuFeNi 系高熵合金成分。
值得一提的是,前人的工作中在建立相预测模型时使用了很多经验参数,而较少使用成分作为特征,而建立硬度预测模型时常使用成分作为特征,较少增添经验参数。为了探究AlCoCrCuFeNi 系高熵合金的相结构和硬度模型,选用由合金成分及元素物理性质计算得到的价电子浓度(valence electron concentration, VEC)[9]、电负性差Δχ[11]、原子尺寸差δ[8]、平均熔点Tm、混合焓ΔHmix[8]、混合熵ΔSmix[8]和Ω[12]等7 种经验参数。原因是:(1)这些经验参数都曾经被用来研究过对高熵合金相形成的影响,并取得了一定的研究成果,说明这些参数是对合金设计有一定影响作用以及指导意义的;(2)这些参数的计算较为方便,所涉及到的元素物理基本性质都较易获取,其中元素的价电子数、Pauling 电负性和原子尺寸的数据来源于文献[30],元素之间的ΔHmix数据来源于文献[31]。
1.1.2 机器学习算法
虽然一般的机器学习算法都能解决分类和回归任务,但是由于其原理不同,在问题解决的方式上会有所偏好,因此使用合适的机器学习算法来拟合数据集,能够得出最优的效果。因此,机器学习模型的选择尤为重要,这需要了解每种模型的特点。其中表1中所示的支持向量机(support vector machine,SVM)、随机森林(random forest,RF)和人工神经网络(artificial neural net,ANN)三种经典算法分别代表着经典二分类算法、树集成算法和黑箱模型算法,本工作选择这三种算法分别训练并对比高熵合金的相预测模型和硬度预测模型。

表1 机器学习算法及描述Table 1 Machine learning algorithms and characteristics
分类和回归是两种不同的任务,使用的评价标准也不同。对于相分类模型的训练,选择准确率作为评价标准,对于回归模型的训练,选择可决系数R2和均方根误差(root mean square error,RMSE)作为评价标准。此外,为了提高模型的泛化能力,避免过拟合,采用5 折交叉验证(5-fold cross validation,5-CV)求取平均准确率的方法获得模型最适合的超参数。
1.2 高熵合金设计路线
图1 为机器学习指导高熵合金设计的路线图,模型部分即是高熵合金相预测模型和硬度预测模型的建立过程。完成模型建立后,进一步选择串联两个准确率都较高的相分类模型和硬度回归模型,对未知成分空间中的高熵合金进行相和硬度的高通量预测,从中选择目标相和硬度的成分,实现对含有特定相和硬度可控的高熵合金高效设计。
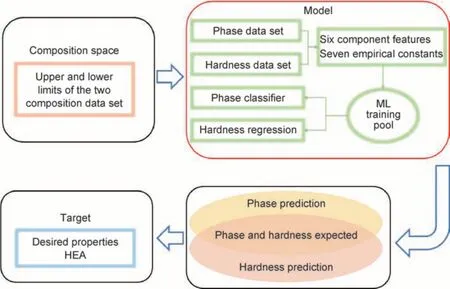
图1 机器学习指导高熵合金设计的路线图Fig.1 Flow chart of ML assisted HEA design
1.3 实验方法
本工作所用的Al,Co,Cr,Cu,Fe,Ni 单质金属原料都是直径1 mm、长度3 mm 左右的金属颗粒,纯度在99.5%以上。称重配料后使用电弧熔炼法制备铸态合金,炉内真空度7×10-3Pa,0.025 MPa 的氩气保护气氛,每个锭子反复熔炼5 次以上,保证合金中金属原料混合均匀。
使用CuKα 射线源对制备的合金进行X 射线衍射分析(XRD, RIGAKUD/MAX-C);硬度测试采用HMAS-C1000SZD 型号显微硬度计,测试力为10 N,保压时间10 s,每个合金测试3 次,取平均值。
2 结果与分析
2.1 AlCoCrCuFeNi 高熵合金的相结构预测模型
2.1.1 数据集分析
高熵合金中的固溶体(solid solutions, SS)相与金属间化合物(intermetallics, IM)相是最重要的两种相结构,它们分别代表着高熵合金中“熵”主导结构与“焓”主导结构。结合所得相结构数据集中的信息,本工作只研究固溶体相(包括FCC 结构和BCC结构)和IM 相(包括B2 相及其他IM 相)两种相结构。
数据集中含有不同相的合金样本数量存在较大差异,并且多数合金为多相结构,直接建立多分类模型需要考虑的类别较多。例如单相FCC、单相IM、FCC+BCC 相和FCC+IM 相等多种类别组合,使得每一类的数据量较少,难以达到较好的训练效果。因此,为了充分利用数据,将数据只分成两类,建立多个二分类模型,保证每一类别的数据量。
相结构数据集中的每个样本根据其组织中的相组成被赋予IM 类、FCC 类和BCC 类三种二分类标签:含有IM 相(1 类)和不含有IM 相(0 类)、含有BCC相(1 类)和不含有BCC 相(0 类)以及含有FCC 相(1类)和不含有FCC 相(0 类)。例如,其中的样本Al0.7Co0.3CrFeNi 合金,其组织为FCC+BCC+IM 混合相结构,因此在上述的IM 类、FCC 类和BCC 类的标签中都为1 类。通过上述三种二分类的数据来分别训练模型辨别合金中是否含有IM 相、FCC 相和BCC相的能力。
一般而言,相关性较大的特征不宜同时存在于数据集中。因此,在将数据用于模型训练之前,通常会计算特征之间的皮尔逊相关系数(Pearson correlation coefficient,PCC),来初步判断不同特征之间是否存在较大的线性相关性。一般认为|PCC|≥0.8 时,两个特征之间具有强相关性(线性相关);0.3<|PCC|<0.8时,两个特征之间具有弱相关性;|PCC|≤0.3 时,两个特征之间没有相关性。图2 为高熵合金相数据集中特征之间的PCC 热度图和相结构数据集中三种分类方式下的样本数据分布图。由图2(a)可知,相关性最大的两个特征为ΔHmix和δ,其PCC 值为-0.76。而据上述的评价标准,这两个特征仅是具有弱相关性。因此,通过PCC 值的初步评判,在相结构数据集中选用的13个特征两两之间不存在强相关性,该数据集是适合用于机器学习模型训练的。

图2 高熵合金相数据集中特征之间的PCC 热度图(a)和相结构数据集中三种分类方式下的样本数据分布图(b)Fig.2 PCC heat maps between features in HEA phase data set(a) and data distribution map under three types of classification in phase data set(b)
数据集的样本分布情况也是模型训练之前需要研究的重要部分。图2(b)给出了数据集在三种分类方式下的样本分布情况,图中斜线左边的数字表示该类样本的数量,右边的数据是该类样本所占的比例,例如样本集中IM 相的正样本有118 个,占所有样本的37%。由此可见,三种样本分布都不均匀,其中IM 类和FCC 类样本分布差异较大,说明数据集中含有IM相的样本数以及不含有FCC 相的样本数目较少,这类有偏数据集对模型的学习训练将带来一定的挑战,有可能使得模型的学习结果产生偏好性。
2.1.2 预测模型结果分析
采用SVM,RF 和ANN 算法分别构建基于IM 类、FCC 类和BCC 类三种分类方式的二分类模型,并使用5-CV 方法求取平均准确率,如表2 所示。
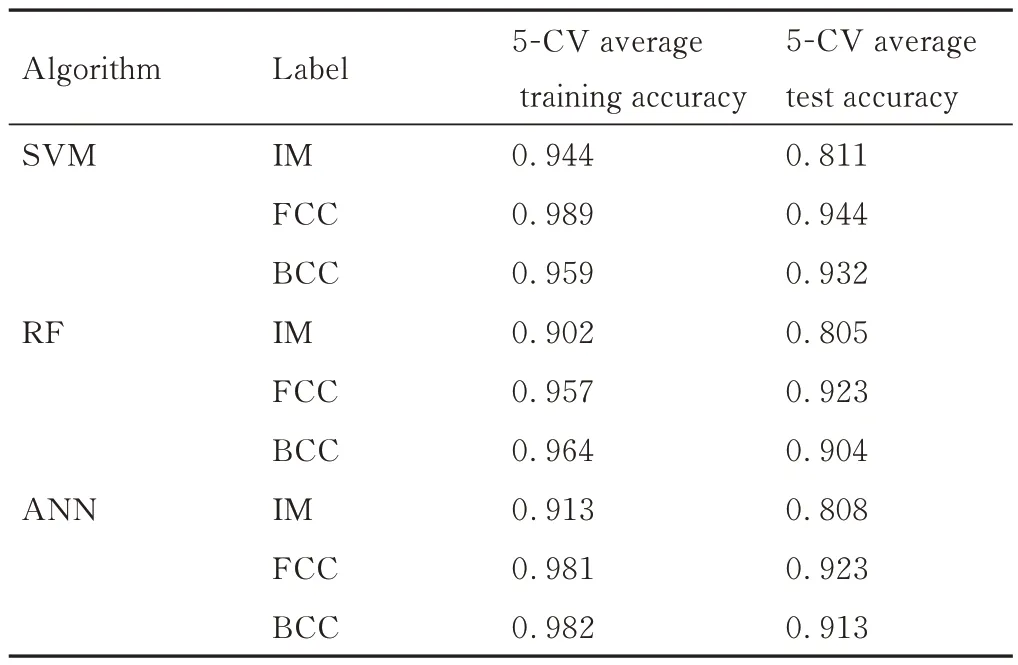
表2 三种算法在各个标签下的准确率Table 2 Accuracy of three algorithms under each tag
对比表2 中模型的训练效果,发现基于三种算法的模型对于相同标签的预测准确率较为相近,其中SVM 模型在三种标签的数据集中都有相对较高的分类准确率,说明SVM 算法在本工作所用的较小数据集中的二分类能力更有优势。反观RF 模型和ANN模型,其测试集准确率则是基本相当,但是通过对比两个模型的训练集和测试集准确率,可以发现,两个模型的训练集准确率显著高于测试集准确率;两个模型的测试集准确率基本相当,而ANN 模型的训练集准确率更高,说明两个模型都存在一定的过拟合,且ANN 模型的过拟合程度要更高一些。
此外,IM 类的分类准确率都较低,测试集准确率仅有约80%,而FCC 类和BCC 类的识别准确率都在90%以上,说明模型对IM 类的识别能力比较差。三个模型的训练结果都较差,因此问题可能出在数据集的质量上。前文提到有偏数据集会给模型的训练带来一些挑战,FCC 类数据是比IM 类更为偏的一组数据,然而FCC 类的预测准确率确很高。具体分析需要借助混淆矩阵(confusion matrix)的计算,混淆矩阵能够直观地观察到每一个类别的预测情况,帮助判断模型是否存在过拟合。
图3 为三个模型基于5 折交叉验证方法在各个标签类别下的混淆矩阵。图3(a-1),(a-2),(a-3)分别表示SVM 模型在IM 分类、FCC 分类和BCC 分类情况下计算得到的混淆矩阵。由于训练时使用了5 折交叉验证,而混淆矩阵只用测试集数据计算,因此这里将5次计算的混淆矩阵相加,最终得到全样本集预测结果的混淆矩阵。
以图3(a-1)为例,该图表示SVM 模型在IM 标签二分类下5 次交叉验证混淆矩阵的和,其中纵坐标为样本的实际标签,横坐标为模型预测标签。因此右下角0.73/86 表示实际为含有IM 类(1 类),并且SVM 模型的预测也为1 类的样本数为86,占IM 标签总数(118)的0.73,即正样本的召回率为73%。
有偏数据集的训练结果往往存在偏好性,模型往往倾向于把样本判断为类别比较多的那一方。若发生在图3(a-1)中所示的混淆矩阵中,则会导致把IM类认为是不含有IM 类,即左下角的样本数会比较多。这种偏好性往往是模型过拟合导致的,在样本较多的类别召回率接近模型训练集准确率的情况下,样本较少的类别召回率与训练集相差较大,而这种训练集准确率异常高于测试集准确率的情况称为过拟合。
图3 (a-1),(b-1),(c-1)中的结果表明,三个模型在IM 类别的预测上确实存在一定程度上的过拟合,其中RF 模型的过拟合程度最为严重,其测试集预测平均准确率为0.805,但是IM 类的召回率仅有61%。而ANN 模型拥有不逊于SVM 的测试集预测准确率的同时,其召回率达到了三个模型最高的0.75,与平均准确率0.808 较为相近。因此,在IM 相的预测模型中,尽管SVM 的测试集平均预测准确率最高,但由于存在一定程度的过拟合,凭借0 类样本更高的准确率提升了其平均准确率,不利于模型对未知合金的预测。综合上述考虑,ANN 模型在IM 类预测上的泛化能力更优。
与IM 类数据类似,FCC 相标签中两种类别的数据量比例失衡更为严重,因此也需要通过混淆矩阵辅助判断是否存在过拟合现象。图3(a-2),(b-2),(c-2)的结果表明,数据更少的不含FCC 相类别(0 类)并没有被模型更多地预测为含有FCC 相类(1 类),即左上角的数值较高表明较大的负样本召回率。通过比较三个模型的混淆矩阵,可以发现SVM 模型在FCC 类的预测上不仅有最高的召回率,平均预测准确率也是最高的,并且两个准确率相近,因此可以初步判定,本工作训练的SVM 相分类模型没有发生过拟合,为FCC 类预测的最佳模型。而RF 模型与ANN 模型虽然有相同且与SVM 模型相近的平均准确率,但RF 模型的召回率仅有0.82,远低于0.923 的平均准确率,ANN 模型的召回率同样较低,说明这两个模型存在较大的过拟合。
相比上述两类数据,BCC 相标签中的两类数据量则更为接近1∶1,不会造成模型有偏好地学习。图3(a-3),(b-3),(c-3)中的结果也证明了这一点。可以看出,正负样本的预测准确率比较相近,都在90%左右。其中又以SVM 模型的准确率最高,其两类样本的召回率都高于RF 模型和ANN 模型。
2.1.3 相形成影响因素分析
三个测试表现最佳的相分类模型分别是ANNIM,SVM-FCC 和SVM-BCC。然而机器学习模型不仅是一个高效的预测筛选器,研究者们往往更想知道模型为什么做出这样的预测,从而分析影响结果的因素,辅助理论解释的完善。图4 为基于ANN-IM 模型的特征重要性排序和SHAP(Shapley additive explanations)值分布图。图4(a)给出了基于ANN-IM 模型的特征重要性排序,图中纵坐标为特征名称,横坐标为该特征对模型输出值的平均影响占比。结果表明,Tm,ΔHmix,VEC 和Al 元素的含量是影响IM 相形成最重要的4 个特征。图4(b)给出了基于ANN-IM 模型的SHAP 值分布图,其中纵坐标同样为特征名称,并且是按照特征重要性排序,横坐标为特征中每个样本计算得到的SHAP 值,该值大于0 表示样本对模型的输出有正影响,即对IM 相(1 类)的形成有促进作用。右边的彩色柱代表特征数值的大小,具体表现在图中每一个点代表一个样本,在某一个样本中该特征的数值越大则该点越红,反之该特征的数值越小该点越蓝。以影响最大的Tm为例,Tm越高,合金越倾向于形成IM 相。
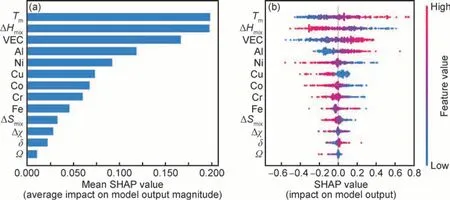
图4 基于ANN-IM 模型的特征重要性排序(a)和SHAP 值分布图(b)Fig.4 Feature importance ranking(a) and SHAP value distribution(b) based on ANN-IM model
图5 为基于SVM 的FCC 相预测模型和BCC 相预测模型的SHAP 值分布图。由图5(a)可知,Al 元素的含量、VEC 和Tm是影响高熵合金FCC 相形成的最重要的三个特征,并且Al 元素含量越低,VEC 越高或者Tm越低,合金越会倾向于形成FCC 相。由图5(b)可知,ΔSmix和Tm是影响高熵合金BCC 相形成的最重要两个特征,并且ΔSmix越大,Tm越低,越容易形成BCC 相。
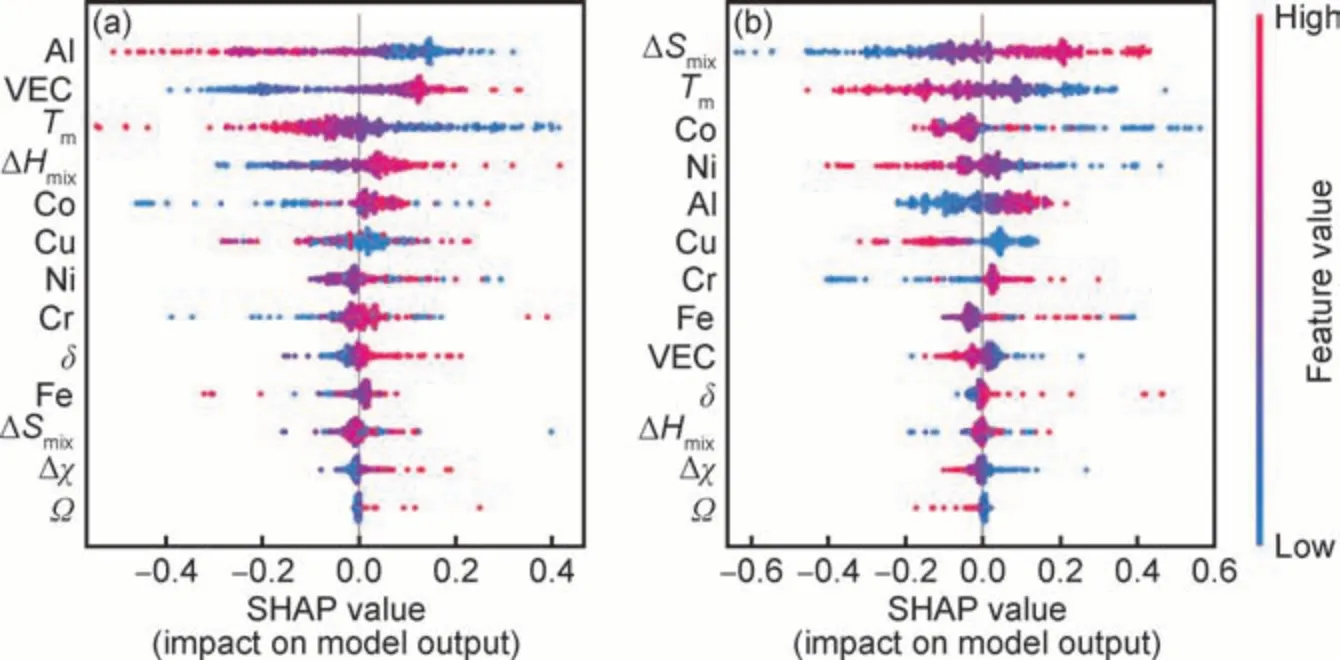
图5 基于SVM-FCC 模型(a)和SVM-BCC 模型(b)的SHAP 值分布图Fig.5 Distribution of SHAP values based on SVM-FCC model(a) and SVM-BCC model(b)
可知,ΔHmix越小,越容易形成IM 相。ΔHmix代表元素之间的亲和性以及形成化合物的倾向性,因此,ΔHmix很低时容易形成IM 相在材料学中是容易解释的。此外,从图4 和图5(a)中还能发现,VEC 和Al 元素含量都是影响IM 相和FCC 相形成的关键因素,其中VEC 越高,IM 相和FCC 相都越易形成。VEC 对于合金结构的影响主要取决于合金金属键的强弱。一般而言,较强的金属键往往具有较高浓度的价电子,金属键越强,意味着晶体结构的平衡原子间距更短、密堆程度更高。因此,价电子就像金属原子之间的黏结剂,VEC 越大,往往更倾向于形成致密程度较高的晶体结构。而IM 相和FCC 相一般都是密堆结构,与VEC 较大时这两相更易形成的结论吻合。Al元素含量则对两相起到相反的影响作用,Al 含量越多越容易形成IM相,且越难形成FCC 相,这可能与Al 原子的尺寸与其他3d 过渡族为主的金属原子相差较大且ΔHmix较负的因素有关。图5(b)的结果表明,影响BCC 形成的最重要因素是ΔSmix,且ΔSmix越大越容易形成BCC 相。ΔSmix越大越容易形成固溶体结构,再结合图4 的结果,在AlCoCrCuFeNi 体系中,ΔSmix大不仅仅容易形成固溶体结构,还易形成BCC 固溶体结构。
2.2 AlCoCrCuFeNi 高熵合金的硬度预测模型
2.2.1 数据集分析
构建机器学习硬度预测模型之前,同样需要对数据进行预分析。图6 为硬度数据集的PCC 热度图和硬度值分布图。由图6(a)的PCC 热度图可知,Tm,Δχ与Ω两两之间都存在强相关性,说明在硬度数据集中,这三个特征存在一定的信息重叠,理应删除其中两个特征。但是,一方面,PCC 只能说明两个特征之间的关系,在同时考虑多特征时可能出现不同的结果;另一方面,机器学习在处理高维度问题上拥有强大能力,能够同时纳入多特征进行多维度计算。因此,在硬度模型计算中仍保留这13 个特征。
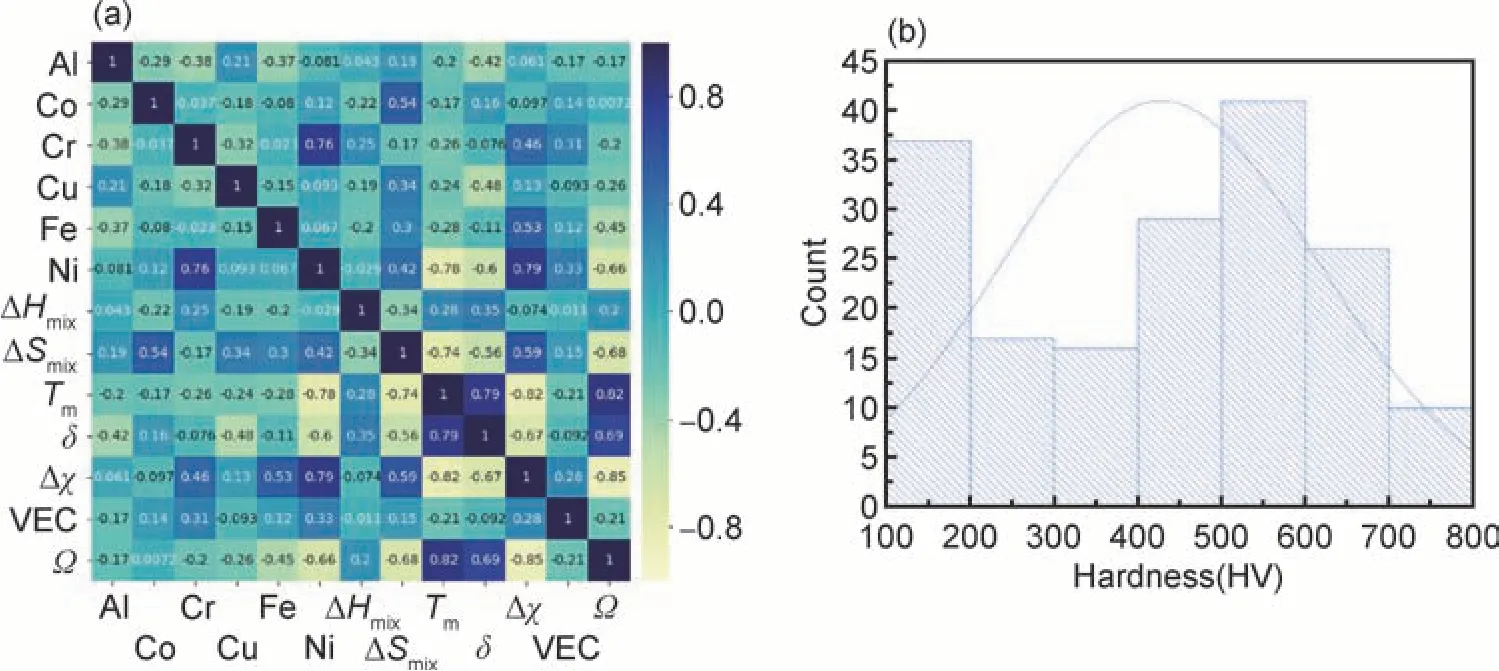
图6 硬度数据集中特征之间的PCC 热度图(a)和样本分布图(b)Fig.6 PCC heat maps(a) and data distribution maps(b) between features in hardness data set
图6 (b)给出的硬度值分布表明,数据集中除了100~200HV 低硬度的数据较多外,基本服从正态分布。但是对于机器学习来说,均匀分布的数据更适合其学习,正态分布的数据会使机器学习在两端的极值处获得较少信息。因此,以该数据集建立的机器学习模型对于数据分布较少的端部预测能力可能会较差,这将对高硬度合金预测与设计带来挑战。
2.2.2 预测模型结果分析
在硬度预测模型的训练中同样采用5 折交叉验证,并采用R2和RMSE 两个评价指标。图7 为基于SVM,RF 和ANN 三种算法的计算结果。可知,在5 折交叉验证方法下,RF 模型与ANN 模型的测试结果非常相近且较差,而SVM 模型拥有最高的R2值和最低的RMSE,表明SVM 回归在硬度数据的学习和预测上有着较大的优势。此外,模型带来的差异不可忽视,因此选择多种算法构建模型来对比结果是有必要的。
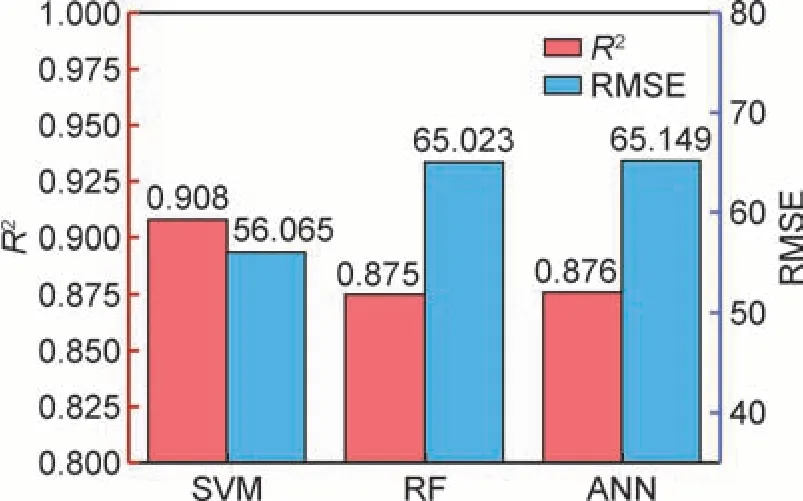
图7 硬度预测模型结果对比Fig.7 Comparison of results for hardness prediction models
2.2.3 硬度影响因素分析
图8 为基于SVM 模型计算得到的特征重要性柱状图和SHAP 值分布图。结果表明,Al 元素含量、δ、Ni 元素含量、VEC 和ΔHmix是影响较大的特征。
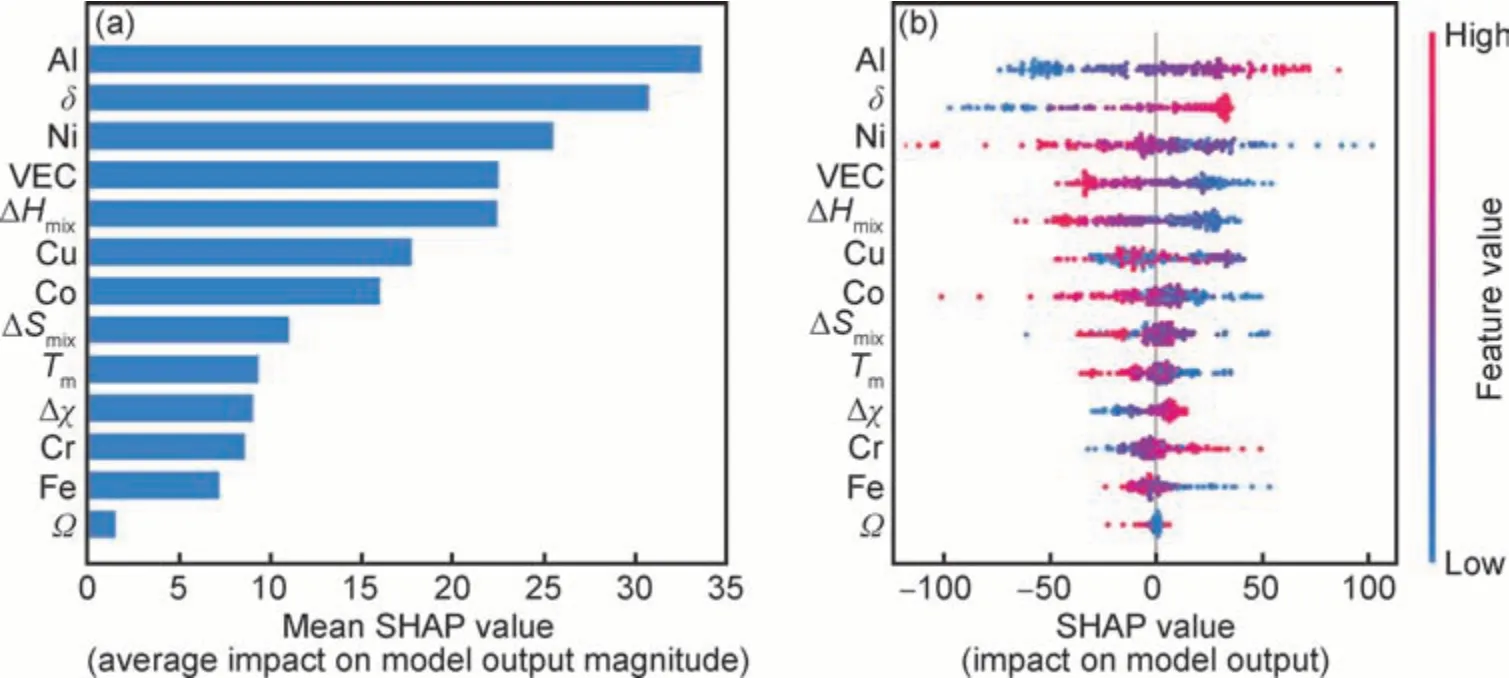
图8 基于SVM 硬度预测模型的特征重要性排序(a)和SHAP 值分布图(b)Fig.8 Feature importance ranking(a) and SHAP value distribution(b) based on SVM hardness prediction model
由图8(b)的结果可知,Al 元素含量与δ的值越大,对形成高硬度合金的影响越显著。事实上这两个特征存在一定的关系,相对于Co,Cr,Cu,Fe 和Ni 的原子半径(都约为12 nm),Al 原子的原子半径较大(约14 nm),当Al 原子与其他元素组成新合金后,δ会变得很大,导致晶格畸变较为严重,产生原子级别的固溶强化作用,从而提升合金的硬度。此外,Ni 元素含量、VEC 和ΔHmix的值越小,对形成高硬度合金的影响越显著 。实际上这几种特征之间是相互关联的,例如提高Al 元素含量并且降低Ni 元素含量,导致δ增大的同时,还会降低合金的VEC(Al 价电子数为3,Ni 价电子数为10)。此外,由于Al 元素和其他元素都有较低的ΔHmix,Al 元素含量较高同样也会降低合金ΔHmix,而ΔHmix较小时倾向于形成IM 相,IM 相往往具有比SS相更高的硬度,使得合金整体硬度提高。
2.3 基于串联模型的高熵合金成分高通量筛选与实验验证
2.3.1 机器学习模型指导AlCoCrCuFeNi 高熵合金设计方法
如图1 所示,进一步选择串联两个准确率都较高的相分类模型和硬度回归模型,对未知成分空间中的高熵合金进行相和硬度的高通量预测,从中选择目标相和硬度的成分,实现对含有特定相和硬度可控的高熵合金高效设计。具体步骤如下:首先根据两个数据集的成分范围构建AlCoCrCuFeNi 系合金的成分空间,数据集中各个元素成分上下限即为成分空间的上下限(5%≤Al≤47%,5%≤Co≤22%,6%≤Cr≤34%,5%≤Cu≤16%,5%≤Fe≤31%,5%≤Ni≤22%,原子分数),将成分变化步长设为1%,只保留四元、五元和六元合金,得到2730995 个成分。
进一步对成分空间进行相预测和硬度预测的双重约束预测。考虑到SVM-FCC 模型的分类结果较好,拥有超过90%的准确率,并且FCC 相在合金中常常起到增塑的作用,因此使用SVM-FCC 模型对合金是否含有FCC 相进行初步预测筛选,得到1408950 个含有FCC 相的成分点,再对这些数据(1408950 个成分点)进一步使用硬度回归模型预测其硬度,最后选出5种硬度较高的合金(Al28Co10Cr27Cu10Fe5Ni20,Al28Co10Cr25-Cu15Fe22,Al18Co21Cr34Cu10Fe12Ni5,Al18Co21Cr33Cu7Fe13Ni8及Al18Co22Cr6Cu12Fe30Ni12,以每个成分最后一个元素的含量代表该成分的合金,分别表示为Ni20,Fe22,Ni5,Ni8,Ni12)来验证模型的准确性。Ni20,Fe22,Ni5,Ni8,Ni12 的硬度预测值分别为623.68HV,618.90HV,651.13HV,668.16HV,503.29HV。
2.3.2 新型AlCoCrCuFeNi高熵合金制备与模型验证
图9 为5 种合金试样的XRD 谱图。可知,5 种合金中或多或少含有一些FCC 相,此与相预测模型相吻合,也证明本工作的机器学习相预测模型的准确率较高。
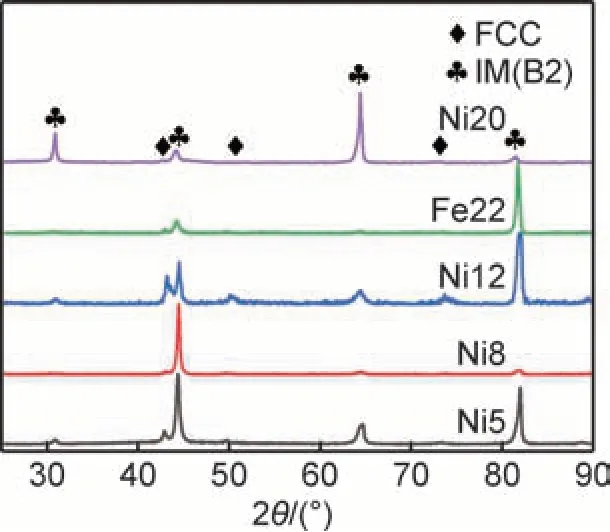
图9 所制备合金的XRD 谱图Fig.9 XRD patterns of prepared alloys
表3 为5 种合金的预测硬度和测试硬度值。为了更直观对比预测硬度和实际硬度,图10 给出5 种合金硬度的分布情况。可以看到,预测硬度和测试硬度较为接近,基本都在对角线附近,其R2达到0.944,并且RMSE 仅有12.58HV。
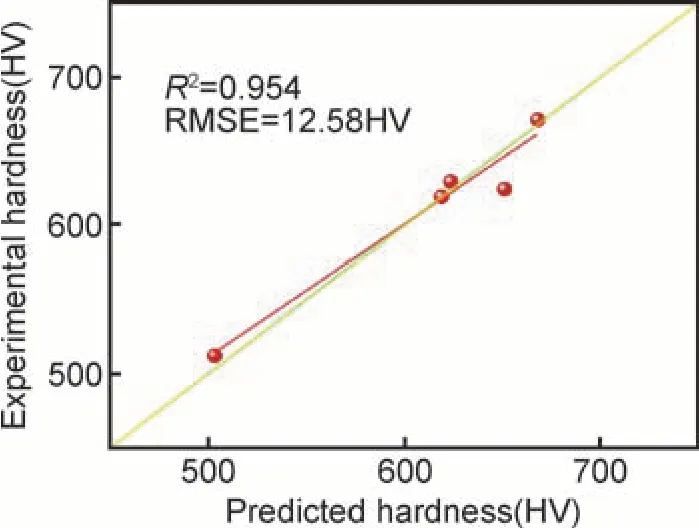
图10 合金的预测硬度与测试硬度对比Fig.10 Comparison of predicted hardness and experimental hardness of alloys
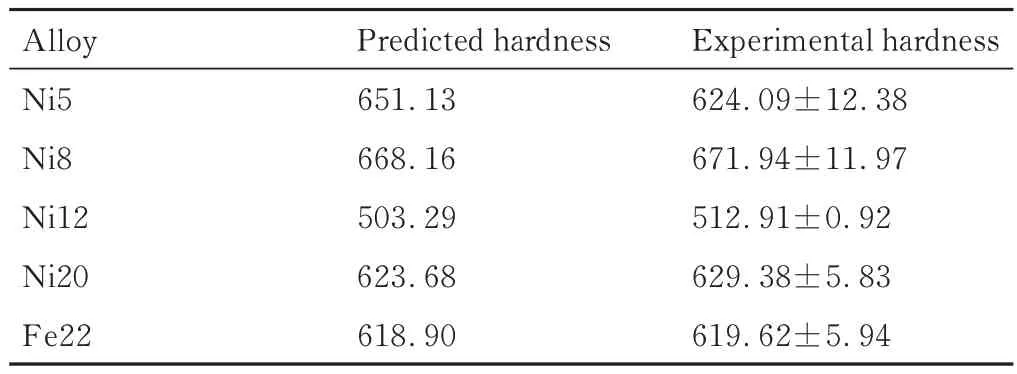
表3 所制备合金的测试硬度和预测硬度Table 3 Experimental hardness and predicted hardness of prepared alloys
在5 种合金中,Ni8 合金拥有最高的硬度。图9 中Ni8 合金的XRD 结果表明,B2 相和FCC 相的峰强相差较大,说明两相含量相差较大,更多的B2 相导致合金具有更高的硬度。通过合金显微组织分析,可以进一步揭示不同合金硬度差异的原因。图11 为5 种合金的BSE 图及点成分分析。可以观察到,每种合金都具有明显的两相组织,图中深色的相为基体相,少量的浅色相为第二相。以硬度较大的Ni5 和Ni8 合金为例,如图11(a),(b)所示,合金中存在白色条状或点状分布的FCC 相,并由成分分析可推测该相为FCC 结构富Cu 的固溶体析出相,基体相为硬度较大的B2 相,与XRD 谱图中含有少量FCC 相与大量B2 相的结果相吻合。此外,从图11(b)高倍数下照片能够观察到,基体相中存在纳米级别的白色细小第二相,其引入更多的相界面也能在一定程度上提升材料的硬度。再结合图11(c)~(e)中两相的比例,不难发现合金的硬度和白色的FCC 相的含量有关,与图9 的XRD 谱图中两相的峰强比结果也吻合。
为了进一步确认合金的相结构,选择5 种合金中硬度最高的Ni8 合金,对其进行TEM 观察,如图12 所示。图12(a)为Ni8 合金的TEM 图,能够明显观察到两种相的存在,分别是浅色的基体相与深色的析出相。图12(b),(c)分别为图12(a)中1,2 处所指两种相的选区电子衍射(SAED)图,根据图中所示的衍射斑点,确认基体相为B2 结构的硬质相,析出相为FCC 结构的相。因此,类比到其他4 种合金,结合图11 的BSE 图,可以确认FCC 相结构预测模型的结果与实际相吻合。
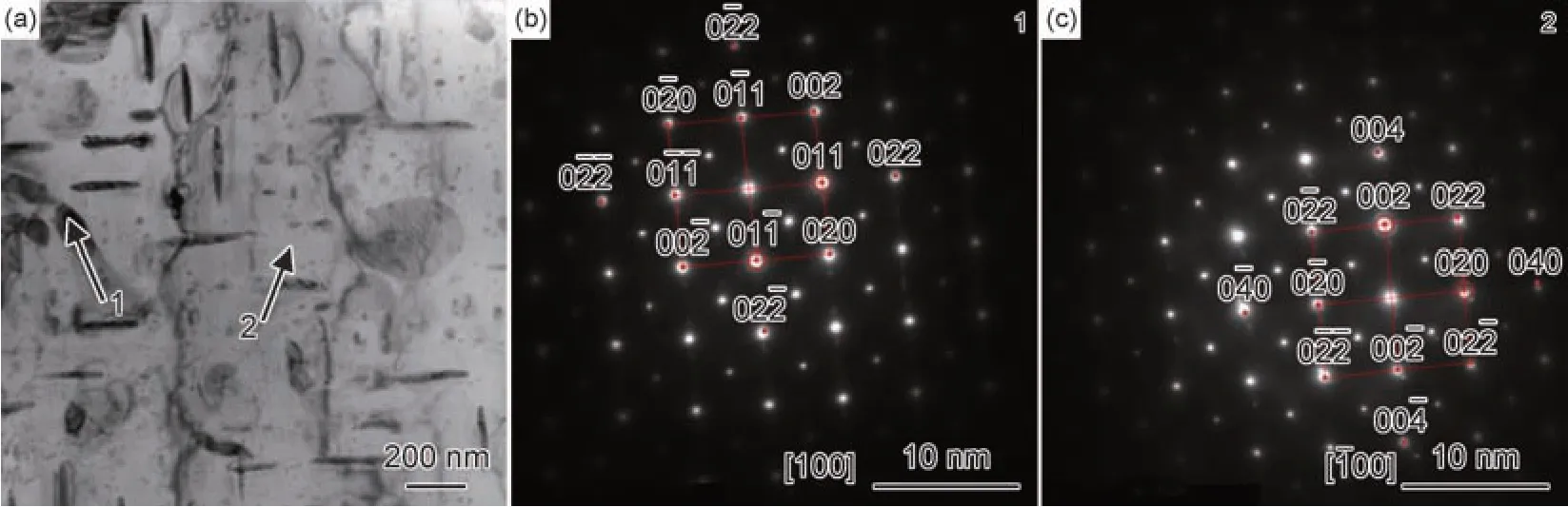
图12 Ni8 合金的TEM 图(a)及合金中基体相(b)和析出相(c)的SAED 图Fig.12 TEM image of Ni8 alloy(a),SAED images of matrix phase(b) and precipitated phase(c) in alloys
此外,对合金进行EDS 表征来观察合金的元素分布,如图13 所示。可以发现,基体相基本包含各种元素,而析出相是一种富Cu 相,且含有少量的Al,基本不含有其他元素,表明Cu 元素与基体相难以相容,凝固时容易析出。
3 结论
(1)在数据集较小的材料体系中,SVM 拥有比RF和ANN 更好的训练结果,其中SVM 模型在FCC 相的平均识别准确率高达0.944,SVM 硬度预测模型的RMSE 为56.065HV,达到一个较好的训练水平。
(2)VEC,Al 元素含量,ΔHmix是影响高熵合金形成FCC 相、BCC 相、IM 相最重要的因素。Al 元素的加入对合金的硬度影响最明显,且Al 含量越高,形成高硬度合金的可能性越大。
(3)通过两个训练好的模型,对高熵合金成分的巨大成分空间进行高通量相与硬度预测,筛选并制备了5 种新合金来验证模型。XRD,SEM 和TEM 等结果表明,5 种合金的相都是FCC+IM,与预测相吻合,且实验测试硬度与预测硬度的R2为0.944,RMSE 仅有12.58HV,模型预测结果良好。
