局部判别损失无监督域适应方法*
2024-01-24王姗姗汪梦竹骆志刚
王姗姗,汪梦竹,骆志刚
(1.安徽大学计算智能与信号处理教育部重点实验室,安徽 合肥 230039; 2.国防科技大学计算机学院并行与分布计算重点实验室,湖南 长沙 410073)
1 引言
在计算机视觉领域,模型的成功依赖于是否有足够多的标签数据进行训练。然而,收集数据往往需要耗费巨大的精力和时间,在现实场景中并不具有可实现性。无监督域适应[1-5]是针对该特定问题提出的一种解决方案,旨在利用来自不同领域但有相关性的源域知识辅助学习目标领域的信息,从而提升分类的精度。然而,领域之间的差异仍然是制约无监督域适应方法得以大规模应用的瓶颈,目前的域适应方法主要用于减小领域之间的分布差异。
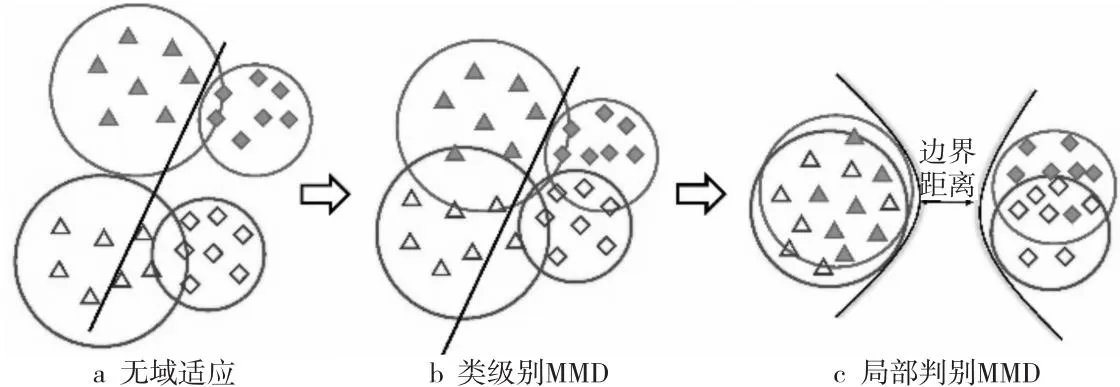
Figure 1 Motivation of the proposed method图1 本文方法动机
为了降低域间分布差异带来的负面影响,一系列方法[6-8]应运而生,其中大部分方法通过对齐域间分布来学习领域不变特征或分类器,如最大平均差异MMD(Maximum Mean Discrepancy)[9]和对抗学习[10,11]。但是,由于分布对齐是全局结构的边缘对齐,模型易忽略细粒度的类级别条件分布信息,无法保证学习到的特征或分类器在目标领域内具有理想的判别能力。
因此,一个代表性的MMD变种——类级别MMD[12]被提出且广泛用于量化领域间的条件分布差异,通过同时匹配全局结构的域级别信息和局部结构的类级别信息,从而实现边缘分布和条件分布的联合分布对齐。另外,文献[13]从理论层面上重新审视了类级别的MMD方法,揭示实现最小化类级别的MMD等同于最大化源域和目标域的类内紧凑性,但如图1所示(图中无填充形状表示源域,有填充形状表示目标域),其忽略了特征的类间判别性,因此类级别的MMD方法可能会导致不同类别间的重叠。
受文献[12,13]工作的启发,本文拟从2个方面改进MMD的可判别性。一方面,为解决类别间的不平衡性问题,在对齐边缘分布的基础上,考虑对条件分布进行对齐。由于条件分布对齐需要利用标签信息,而域适应中的目标域样本不含标签,因此首先需要为目标域样本分配伪标签。然后基于伪标签,计算2个域中类级别MMD的权重,从而使难分类的类别与易分类的类别在域间分布中保持一致。另一方面,如图1所示,尽管加权的类级别MMD方法考虑到每个类别的细粒度信息,但其忽略了类间的可判别性,容易导致类间样本的不可分离性。因此,考虑到加权类级别MMD方法的缺陷,如图1c所示,本文提出利用样本特征建立一个富含更多信息的结构,用来学习具有判别性的特征。
在锚点样本的升序列表中,将所有正样本排列在负样本之前,对样本对进行局部对比损失的排序优化,并在不同类别的样本之间设置一个强制边界。尽可能为每一个样本学习一个超球面,使正样本对之间的距离小于阈值,从而既保持样本之间的相似结构,又能实现类内紧致性和类间可分离性。
同时,为了捕获长期依赖的精确位置信息,本文采用一种新的轻量级注意力机制,称为协调注意力机制,协调注意力机制继承了通道注意力机制的优点,可以模拟通道间的关系,有效提升模型的泛化性能。在5个数据集上进行实验,本文的方法展现出了良好的效果。
本文工作是文献[14]会议论文的扩展版本。与会议论文相比,本文进行了以下改进:将本文所提的方法扩展至注意力网络结构中,具备了即插即用的效果;此外,在更多的数据集上验证了本文方法的有效性。
本文主要工作总结如下:
(1)考虑了加权的类级别 MMD 方法和局部对比损失,提出了一种改进最大平均差异的无监督域自适应方法——局部判别损失域适应。
(2)从理论上分析加权的类级别 MMD 方法存在的问题,并阐述特征判别能力下降的原因。
(3)提出一种简单有效、即插即用的域适应方法,提高了特征的可判别性,并将该方法扩展至注意力机制的网络中,证明了其即插即用的泛化能力。
2 相关工作
针对无监督域适应问题,学术界曾提出了一系列缩小域间分布差异的方法。最大平均差异MMD[9]是其中的一种主流方法,通常用来对齐2个域之间的高维特征。条件 MMD方法[12]度量源域和目标域中经验条件的希尔伯特-施密特核范数均值嵌入,最小化域间的均值差异,缩小域间分布差异。加权最大均值差异WMMD (Weighted Mean Maximum Discrepancy)[15]在原始的 MMD 方法的基础上,利用源域和目标域的类别先验概率,引入特定类级别的辅助权重。Long等人[12]提出的联合分布适应JDA (Joint Distribution Adaptation)方法联合了边缘分布和条件分布,但该方法忽略了类别不平衡问题中类别权重的重要性。
另一类主流方法是借助对抗学习的思想缩小无监督域适应的域间分布差异。Wang等人[16]提出利用对抗学习的优化方法对齐特征,准确地迁移特征从而使域差异最小化。Wang等人[17]提出了一种自适应重加权的对抗域适应方法,但考虑的是迁移过程中样本重要性的不同。Long 等人[18]提出了一种条件对抗方法,利用基于分类器预测获得的判别信息构造对抗适应模型。 Li 等人[19]提出了一种距离损失,并将其应用至对抗域适应中,以应对平衡问题的挑战。
与以上方法不同,本文方法旨在显式地减少类级别的错误匹配,从而学习到具有判别性的领域不变特征。之前也有一些方法[20,21]从提高判别力的角度出发构造模型。Li等人[21]提出了领域不变表示和类判别表示DICD (Domain Invariant and Class Discriminative representations)方法,试图同时最大化类间离散,最小化类内分散,改善类别的判别性特征。Satio等人[20]提出最大化分类差异MCD (Maximum Classifier Discrepancy)的方法,通过利用特定任务的决策边界来调整源域和目标域的分布。
3 基于局部判别损失域适应
3.1 问题的定义

虽然使用 MMD 策略可以缩小2个域之间的分布差异,但仅用它还远远不够,该策略依然受到2个方面的影响。一方面 MMD 方法未考虑类别间的不平衡性问题,易导致对齐过程中出现类间差异。另一方面,从文献[13]中可知,最小化 MMD 方法等同于最大化源域和目标域之间的类内距离,由于类内距离和类间距离之间的关系互斥,类间距离无法得到约束,容易造成类间的重叠。为了解决这一问题,本文提出了一种判别策略来抑制 MMD 方法的不利影响,如图2所示,其损失函数包括源域分类损失、局部对比损失和加权类级别MMD损失。

Figure 2 Unsupervised domain adaptation method图2 无监督域适应方法
为解决类别间的不平衡性问题,本文首先提出采用加权类级别 MMD 的方法,但是基于权重分类的 MMD 方法忽略了特征的类间可分辨性,容易降低域的自适应性能。为提升判别性,在加权类级别MMD 的基础上,本文拟为每一个类别设置一个保证边界的策略,如图 1c所示。同时,强行拉近正样本对的距离,使其小于某个阈值。本文采用使每个样本的超球面直径小于某个阈值的方式代替简单的拉近同类样本的约束。在这2方面的作用下,本文能够保持每个类别内样本之间的相似性结构,并通过改进权重分类的 MMD 方法使其具有判别性。
3.2 加权类级别MMD方法
为了度量2个域之间的距离,本文采用域适应中常用的非参数度量方法:最大平均差异MMD方法[12]。它可以计算k维嵌入的源域特征均值与目标域特征均值之间的距离,计算公式如式(1)所示:
tr(ATSbA)=tr(ATSvA)-tr(ATSwA)
(1)
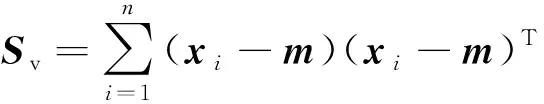
根据式(1),将加权的类级别MMD方法改写如式(2)所示:
(2)
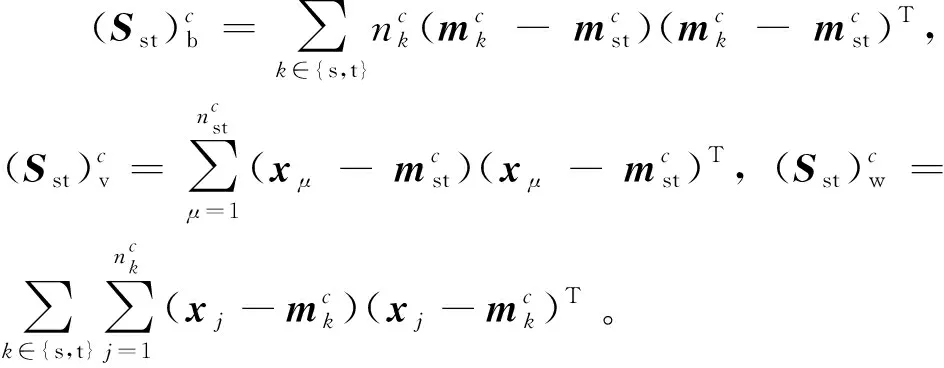

经过化简之后,再次改写式(2)可得式(3):
(3)
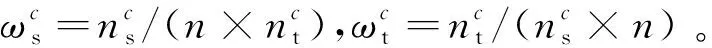
将式(3)代入式(2)后,可得式(4):
(4)
根据式(4)可以得出,加权类级别MMD方法的目标是最大化源域和目标域的类间距离,最小化源域和目标域的类内距离。但是,由于整个数据的方差为一个固定值,使用MMD使类内距离扩大时[13],类间的距离会越来越小。这样不同的类别之间就会出现不同程度的混沌重叠,特征的可判别性就会大大降低。为了解决可判别性问题,本文设计了一个判别性策略,以提高类别的可判别特性。
3.3 判别性策略
与调和平均线性判别分析不同[22],本文的判别性策略为:给定一个选定的图像样本xi,尽可能将不同类别的样本推至距离边界β更远的位置,将与其相同类别的样本拉近至比边界β-g更靠近的位置,因此2个边界之间的边界距离为g,如图3所示。判别性策略的使用可以使任意的类别之间都具有一定的保证边界。样本对的损失函数的数学表达式如式(5)所示:
Ls(xi,xj,f(·))=(1-yij)·max(0,β-dij)+
yij·max(0,dij-(β-g))
(5)
其中,当yi=yj,即样本标签一致时,yij=1,表示样本对为正样本对;当yi≠yj时,yij=0,表示样本对为负样本对;dij=|f(xi)-f(xj)|2表示样本对特征间的欧氏距离;xi和xj表示样本;Ls表示样本对的损失函数;f(xi)和f(xj)表示样本特征。

Figure 3 Discriminative strategy图3 判别性策略
对于所选样本xi来说,由于不同的样本到所选样本的距离不同,为了充分平衡这层关系,本文根据它们与所选样本的对应距离对样本进行加权。在设计判别性策略的时候,本文考虑到每个样本的可迁移性不同,从而给予每个样本对不同的权重。为防止使用了加权的类级别MMD方法之后的模型过拟合,需减小易迁移样本的权重,加大难迁移样本的权重,所以权重策略表示如式(6)所示:
(6)
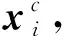
为了拉近所有正样本的距离,并设置一个边距来学习类别的超球面,本文将正样本对的损失LP最小化为式(7):
(7)
其中f()表示训练提取样本特征的函数。
同样地,为了使负样本集Nc,i远离边界β之外,本文将负样本损失LN最小化为式(8):
(8)
综上,判别策略损失可以表示为式(9):
(9)

3.4 注意力机制
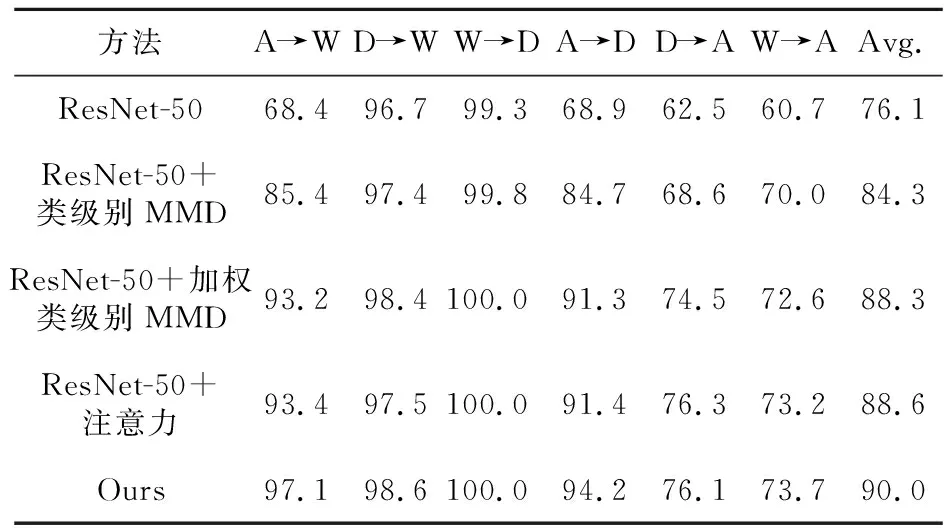
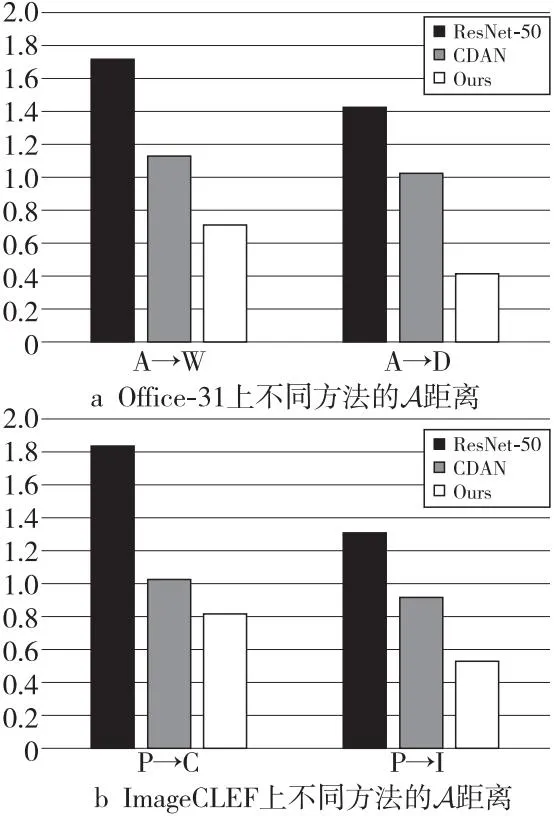
在通道注意力中,研究人员通常使用ResNet[23]网络中的全局池化对空间信息进行全局编码,但它将全局空间信息压缩到通道描述符中,因此很难保留位置信息,而位置信息对于在视觉任务中捕获空间结构至关重要。为了鼓励注意模块通过精确的位置信息在空间上捕捉远程交互,本文将全局池化转换为一对一维特征编码操作。具体来说,给定输入X,使用2个空间范围的池核(H;1)或(1;W)分别沿水平方向坐标和垂直方向坐标对每个通道进行编码。因此,第c个通道在高度h(0≤h (10) 类似地,第c个通道在宽度为w处的输出表示为式(11): (11) 以上2种变换沿着2个空间方向进行特征聚合,返回一对方向感知注意力图。这和挤压激发SE模块产生一个特征向量的方法截然不同,这2种变换允许注意力模块捕捉到沿着一个空间方向的长程依赖,并保存沿着另一个空间方向的精确位置信息,这有助于网络更准确地定位感兴趣的目标。 具体来说,首先将式(10)和式(11)生成的聚合特征连接起来,接着将其输入共享的1×1卷积变换函数F1(·),得到式(12): f=δ(F1([zh,zw])) (12) 其中,[·,·]表示沿空间维度的串联操作,δ(·)是非线性激活函数,f∈RC/r×(H+W)是在水平方向和垂直方向上编码空间信息的中间特征,zh表示经过编码后的水平方向输出特征,zw表示经过编码后的垂直方向输出特征。r用于控制卷积块大小的缩小比。然后将f沿空间维度拆分为2个独立的张量fh∈RC/r×H和fw∈RC/r×W,利用另外2个卷积变换Fh(·)和Fw(·),将fh和fw分别变换成具有相同通道数的张量,如式(13)所示: gh=σ(Fh(fh)), gw=σ(Fw(fw)) (13) 最后将输出的gh和gw分别展开并用作注意力权重。协调注意模块Y的输出如式(14)所示: (14) 本文方法的目标是缩小域间差异,提高加权类级别MMD的可判别性。所以,本文所提模型通过注意力机制提取特征,在基本损失的基础之上,加入了加权类级别MMD损失和判别性损失。总的损失函数Ltotal如式(15)所示: (15) 其中,Lc表示在源域样本上的标准分类损失,p和q表示不同类别的样本。 初始网络模型采用在ImageNet2012数据集上预训练得到的CNN模型,并对其进行微调。模型的训练方式主要遵循标准的小批量随机梯度下降算法。 本文在5个常用基准数据集上进行实验,并将本文方法与域适应中的其他先进方法进行对比,从而验证本文方法的有效性(方法的代码已在https://github.com/dreamkily/A3N开源)。为了验证本文方法的泛化性,数据集不仅包括 Office-31[24]、ImageCLEF-DA等小规模数据集,还包括 Office-Home[25]、VisDA-2017[26]和 DomainNet[27]大规模数据集。 (1)Office-31。Office-31是域适配领域的一个基准数据集。Office-31包含来自Amazon(A)、Webcam(W)和Dslr(D)3个领域的一共31种类别样本,共4 652 幅图像,可组成6项域适应任务,分别是A→W,W→A,W→D,D→W,A→D 和 D→A。 (2)ImageCLEF-DA。ImageCLEF-DA是域适应挑战赛中的基准测试数据集。它包含3个域:Caltech-256(C)、ImageNet ILSVRC 2012(I)和Pascal VOC 2012(P)。每个域由12个类别组成,每个类别有50幅图像样本,共600幅图像样本。本文在所有6项挑战性任务上进行方法评估,分别是 C→I,C→P,I→P,I→C,P→C,P→I。 (3)Office-Home。Office-Home是一个具有挑战性的大规模数据集,包含65个类别共15 500幅图像。它具有4个显著不同的领域:Artistic (Ar),Clipart (Cl),Product (Pr)和Real-World (Rw)。本文在所有的12项挑战性任务中进行方法评估。 (4)VisDA-2017。VisDA是一个非常大且具有挑战性的域适应数据集,包含来自3个不同领域的12个类别,一共有超过280 000幅图像。3个领域分别是训练领域(Synthetic)、验证领域(Real)和测试领域。 (5)DomainNet。DomainNet是迄今为止最大且最具挑战性的域适应数据集。它包含来自6个不同领域的345个类别的图像,共计约60万幅。6个领域分别是Clipart(clp),Infograph(inf),Painting(pnt),Quickdraw(qdr),Real(rel)和Sketch(skt)。每个领域分别作为源域和目标域,共可以构建出30项域适应任务:clp→inf,…,skt→rel。 采用PyTorch平台实现本文提出的方法,通过加权衰减为5×10-4、动量为0.9的小批量随机梯度下降优化模型。使用以下方式调整,其中θ在训练过程中从0到1线性变化,参数ηθ=η0/(1+αθ)β,参数α=10,β=0.75,用参数θ改变λ1,设λ1=2e-10θ-1,λ2=0.01,设置批数为32。 为了与其他域自适应方法进行比较,本文选择了一些经典的和最新的高性能深度学习方法,包括迁移成分分析TCA (Transfer Component Analysis)[29]、测地线流核GFK (Geodesic Flow Kernel)[30]、深度域混淆DDC (Deep Domain Confusion)[31]、深度适应网络DAN (Deep Adaptation Network),[32]、 域对抗神经网络DANN (Domain Adversarial Neural Network)[10]、联合对抗网络JAN (Joint Adversarial Network)[12]、残差迁移网络RTN (Residual Transfer Network)[33]、条件领域对抗适应网络CDAN (Conditional Domain Adversarial Network)[18]、对称网络SymNet (Symmetric Network)[34]、对抗性判别领域适应ADDA (Adversarial Discriminative Domain Adaptation)[28]、增强版协作对抗网络iCAN (incremental Collaborative and Adversarial Network)[35]、域适应的可迁移注意力TADA (Transferable Attention for Domain Adaptation)[16]、多对抗领域适应MADA (Multi-Adversarial Domain Adaptation)[36]、深度子域自适应网络DSAN (Deep Subdomain Adaptation Network)[37]、批量核范数最大化BNM (Batch Nuclear-norm Maximization)[38]、逐步自适应特征范数SAFN (Stepwise Adaptive Feature Norm)[39]、切片沃瑟斯坦差异SWD (Sliced Wasserstein Discrepancy)[40]和跨域梯度差异最小化CGDM (Cross-domain Gradient Discrepancy Minimization)[41]。 (1)Office-31上的实验结果。Office-31是领域自适应研究方法中应用最广泛的数据集之一,各方法在该数据集上的实验结果如表1所示,其中,*代表无注意力机制,结果出自会议论文。 可以看出,本文提出的方法在现有的迁移学习任务中优于大多数对比方法。值得注意的是,本文通过加大难迁移样本权重,降低容易迁移样本权重的方法,大大提高了难迁移任务的分类精度,如D→A 任务中源域和目标域的分布差异显著不同,而 W→A任务中源域数据集的规模比目标域规模小,但在这2个迁移任务中,本文方法表现出了相当高的性能。从表1可以看出,本文方法非常接近全监督设置结果的上界。 Table 1 Recognition accuracies on Office-31 dataset表1 Office-31数据集上的识别精度 % (2)ImageCLEF-DA上的实验结果。Office-31数据集中的对象都来自办公场景,与之不同,ImageCLEF-DA数据集中的对象资源更加多样化。在ImageCLEF-DA数据集上对本文提出的方法进行了评估,以验证其在不同场景下的有效性。在ImageCLEF-DA上使用ResNet-50作为本文方法的骨干网络。从表2可以看到,本文方法优于对比方法,尽管任务变得更具有挑战性,但该方法的识别精度基本都有提高。除Pascal数据集外,在其他数据集上的评估中,本文方法的识别精度均在90%以上。这表明,本文所提方法不仅适用于广泛应用于办公场景,而且还适用于更加多样化的场景。 (3)Office-Home上的实验结果。本文在Office-Home数据集上验证本文方法在大规模数据场景下的泛化性。实验依然采用ResNet-50作为本文方法的骨干网络,结果如表3所示。从表3中可以看出,与最近报道的几个著名的深度域自适应方法相比,本文方法的平均分类精度最优。 Table 2 Recognition accuracies on ImageCLEF-DA dataset表2 ImageCLEF-DA数据集上的识别精度 % (4)VisDA-2017和DomainNet上的实验结果。本文遵循与CDAN[18]相同的实验协议,并与最近在VisDA-2017和DomainNet数据集上报道的几种深度方法的结果进行了比较,结果如表4和表5所示。从2个表可以看出,本文方法在平均分类精度方面取得了有竞争力的结果。 4.2.1 消融实验 为了验证本文方法各个部分所起的作用,本节在Office-31数据集上对不同策略下本文方法的不同变种进行消融实验,结果如表6所示。ResNet-50的基线结果表示只使用源域分类器,且没有MMD策略参与。ResNet+类级别MMD表示考虑类级别 MMD,识别性能从76.1%提高到了84.3%。ResNet-50+加权类级别MMD代表本文方法,即加权的类级别对齐方法,识别性能提高到了88.3%,加上注意力机制后,识别性能达到了88.6%。 Table 3 Recognition accuracies on Office-Home dataset 表3 Office-Home数据集上的识别精度 % Table 4 Recognition accuracies on VisDA-2017 dataset 表4 VisDA-2017数据集上的识别精度 % Table 5 Recognition accuracies on DomainNet dataset表5 DomainNet数据集上的识别精度 % Table 6 Ablation experiments on Office-31 dataset表6 Office-31数据集上的消融实验 % 从表6可以看出,本文方法既得益于加权类级别的权重MMD,也受益于判别策略,注意力机制也对其性能的提升起到了作用。 4.2.2 特征可视化 本文在图4a和图4b中展示了任务A→W的可视化结果。特征分别由ResNet-50和本文方法进行提取,然后使用t-随机邻近嵌入t-SNE (t- distributed Stochastic Neighbor Embedding)嵌入特征[42]并进行特征可视化。图4a容易造成一些难对齐样本点分类错误。与之相比,图4b显示相同的类别非常接近,具有良好的对齐特性,这验证了本文方法的有效性。结果表明,该方法学习到的特征在2个域之间可以很好地对齐,且保留了更多的类间判别性。 Figure 4 t-SNE figure图4 t-SNE图 4.2.3 域适应分布差异的量化 图5给出了ResNet-50、CDAN和本文方法的A距离。A距离被广泛用来度量分布散度,而且距离越小代表分布对齐越好。从图5可以看出,本文方法能够实现比CDAN更小的A距离,这意味着本文方法能够更好地对齐2个域。 Figure 5 A-distance to quantitative distribution discrepancy图5 A-distance量化域间分布差异 本文提出了一种新的无监督域适应方法,采用改进的加权 MMD 方法提升本文方法的判别性。具体地说,该方法包括3个主要部分:样本判别构造模块、加权的类级别MMD模块和伪标签分配模块。其中,样本判别构造模块用于构造一个类间判别性损失,以衡量不同类别之间的差异;加权的类级别MMD模块用于对齐不同域之间的特征分布;伪标签分配模块用于为每个样本分配一个伪标签,以帮助更好地学习。与以往的度量学习[43]、解耦表示学习[44]和对抗域适应方法训练困难、收敛缓慢相比,本文方法实现简单、收敛速度快且即插即用,在域适应数据集上的综合实验验证了该方法的有效性。在未来的工作中,计划基于此方法构建更有效的具有判别性的加权类级别 MMD,并将本文方法扩展到其他深度无监督域适应研究上,如跨域行人重识别,单目标、多目标跟踪和视频时刻检索场景。3.5 本文模型网络结构
4 实验与结果分析
4.1 数据集与实验设置
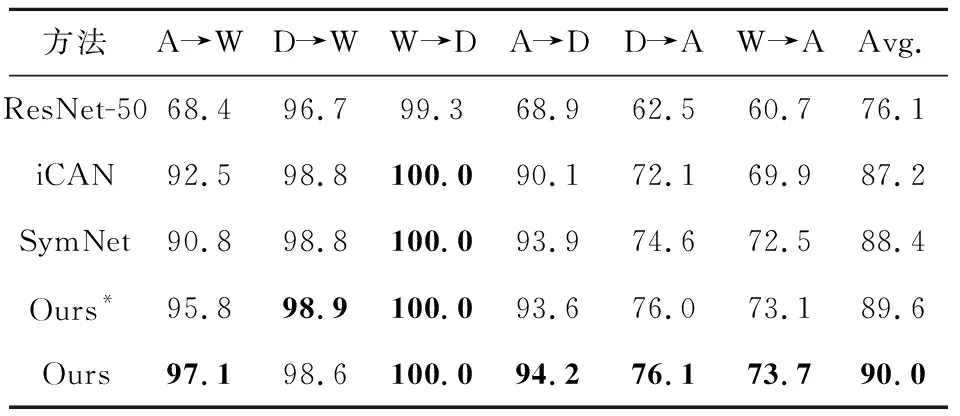
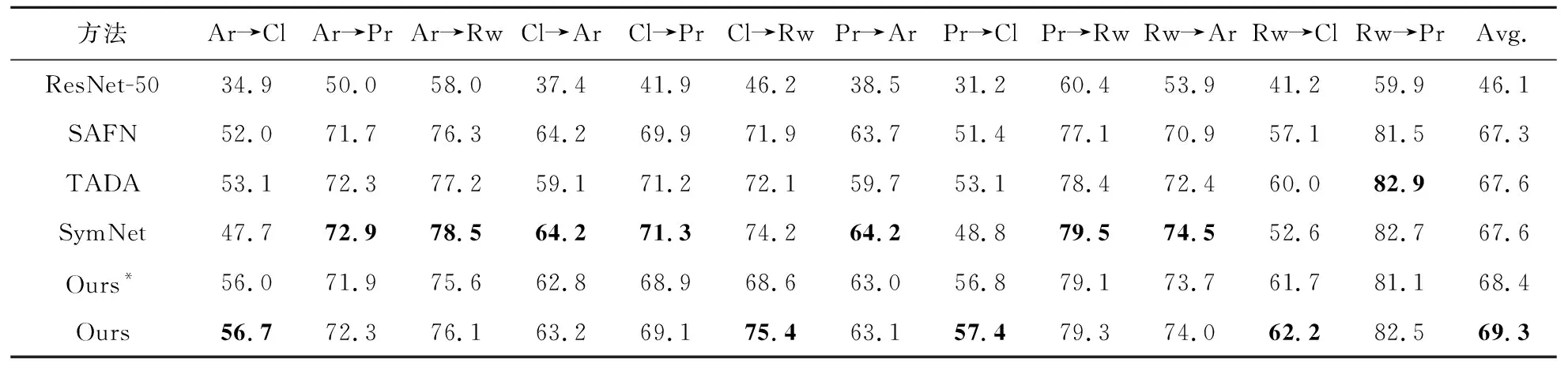
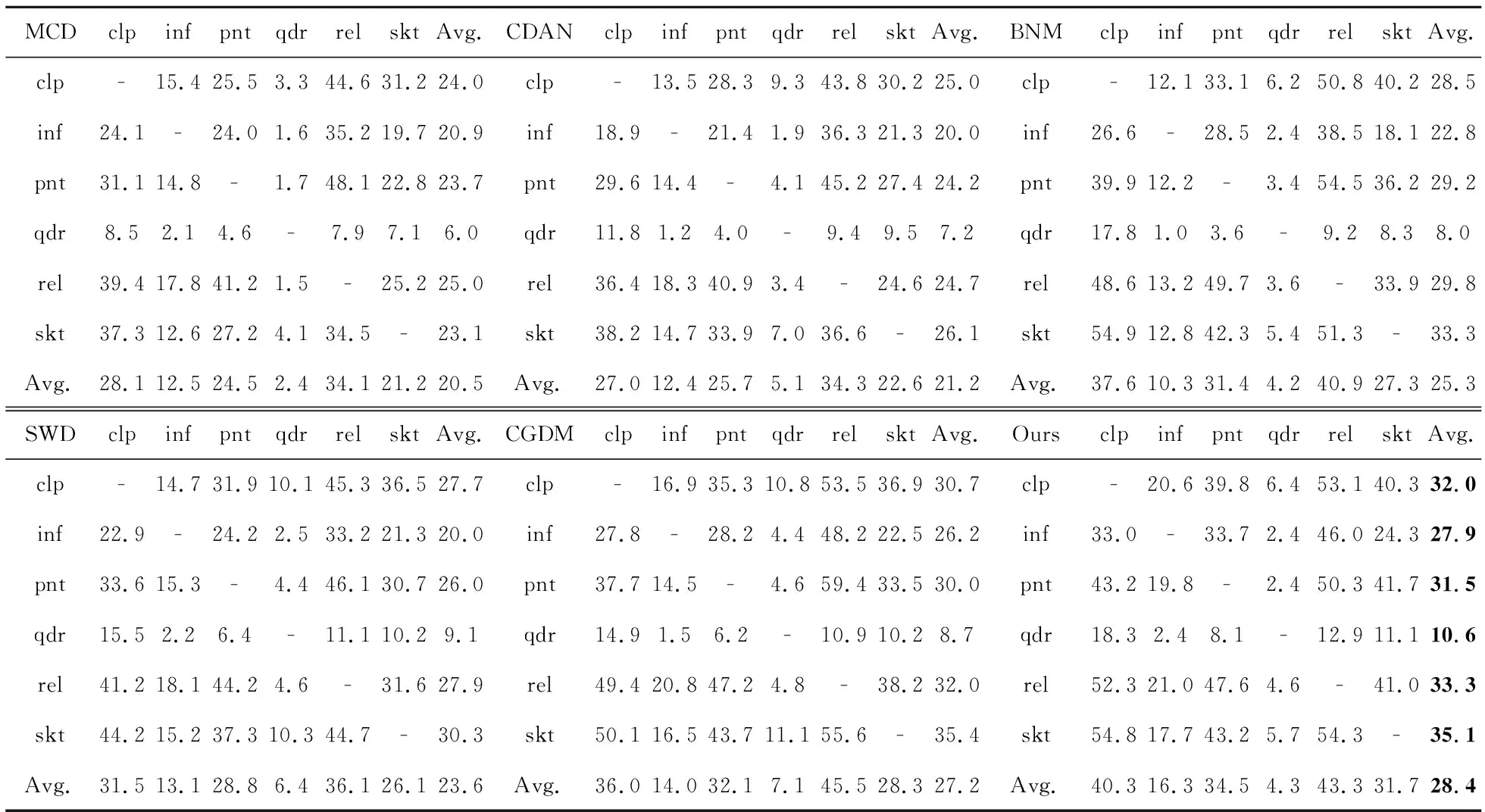
4.2 与当前先进方法的对比分析



5 结束语
