水利水电建筑工程造价指数预测模型研究
2024-01-24林世巍
林世巍
(营口市水利勘测建筑设计院,辽宁 营口 115000)
0 引 言
水利水电工程是国民经济发展中重要的基础设施,对水资源的综合利用起着关键作用。由于工程规模庞大、施工周期长、环境复杂等特点,水利水电工程建筑的造价估算与预测具有挑战性[1-2]。传统的预测方法主要依赖于经验判断和统计分析,缺乏准确性和可靠性。因此,研究人员开始应用数据挖掘和机器学习技术,以改善水利水电工程建筑工程造价的预测准确度和可靠性[3-4]。目前,神经网络可以从数据中学习到模式和规律,从而对所需的数据进行预测,但该网络对初始权重和学习率敏感度较高。而思维进化算法(Mind Envolutionary Algorithm,MEA)适用于多变量预测,可以对反向传播(Back Propagation ,BP)神经网络的最优权值和阈值进行计算。此外,GM(1,1)能够捕捉到时间序列数据,用于处理非线性、小样本或缺少历史数据的预测问题[5-7]。
鉴于此,本文提出MEA优化BP神经网络的初始权重,并结合GM(1,1)预测工料机单一造价指数的方法,为水利水电建筑工程的造价指数预测提供可行技术参考。研究创新点有两个:①将MEA模型、BP神经网络和GM(1,1)模型有机结合起来,提高造价指数模型预测的准确度和可靠性;②先对工料机单一造价指数进行预测,再利用单一造价指数和综合指数之间的关系进行预测。
1 水利水电工程造价指数预测模型探究
1.1 指数预测模型的构建及改进策略
在水利水电工程建设过程中,准确预测整个生命周期工程各阶段的造价指数,对于实现工程成本控制、资源优化分配和项目管理至关重要。MEA是一种模仿人类进化过程的机器学习方法,它具有强大的全局寻优能力,通过模拟进化过程中的选择、交叉和变异等操作,来搜索最优解。而BP神经网络是一种具有输入层、隐含层和输出层的前馈神经网络,通过信号正向传递和误差反向传递来进行学习和优化[8]。本研究将MEA和BP神经网络结合起来,设计一种MEA-BP模型,以充分利用两者的优势。该模型可以在预测水利水电工程建设过程中的造价指数时,同时考虑全局寻优和学习优化的能力,从而提高预测准确性和精度。其具体流程见图1。
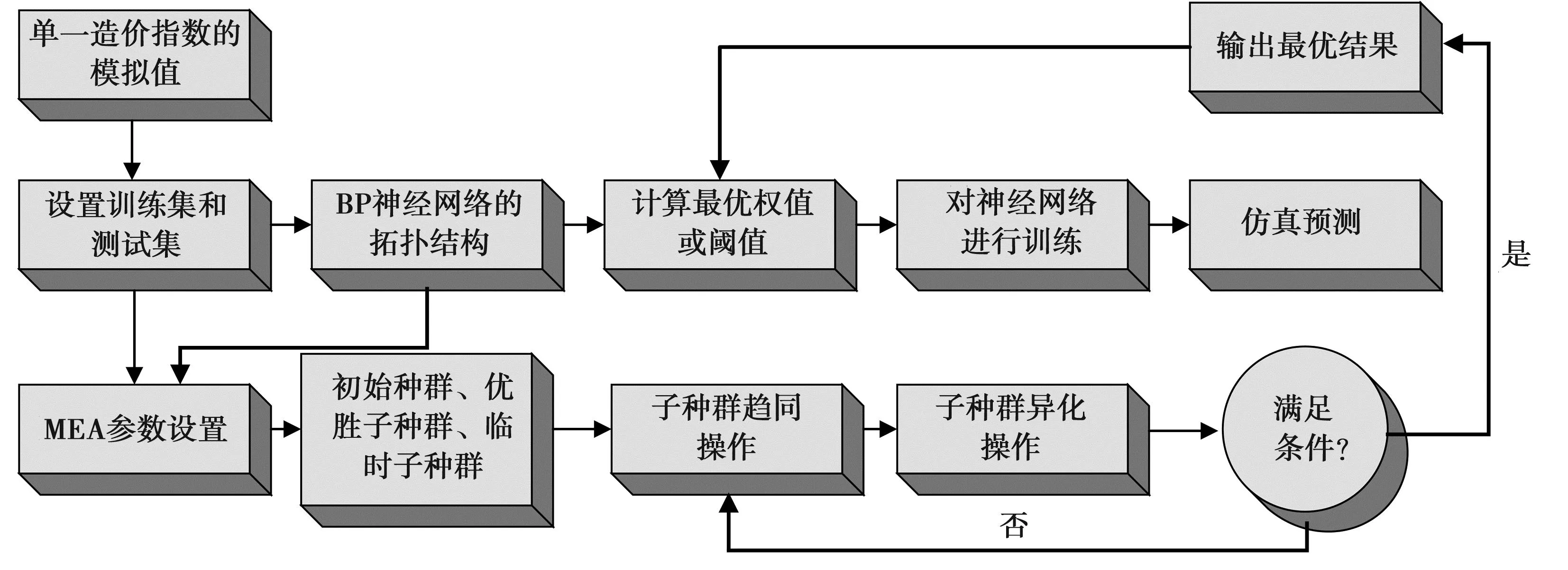
图1 MEA-BP模型运算流程图
本研究所设计的MEA-BP模型流程为:使用Octave编程语言软件,将处理过后的水利水电工程单一造价指数分为测试集和训练集;根据需要,设计相应的BP神经网络拓扑结构,便于生成MEA的参数;进行生成初始种群、生成子种群和优胜子种群、趋同操作、异化操作等步骤,得到MEA的最优输出结果;对最优输出结果进行解码计算,得出BP神经网络的初始权值和阈值;使用Octave编程语言软件,构建BP神经网络,并设定初始权值和阈值;对该神经网络进行训练。
MEA-BP模型利用MEA优化BP神经网络的初始权值和阈值,使其能更好地输出符合期望值的结果。经过MEA优化的BP神经网络,具有收敛速度更快、全局寻优能力更佳的特点。上述方法只是笼统地对整个水利水电建筑工程造价指数的预测,如果对各工料机的权重占比参数设置不当,则对整个预测模型的结果影响较大。
因此,研究提出采用改进的GA(1,1),先对各工料机的指数进行预测,以更加精细地了解每个指数的趋势和变化。研究改进的GM(1,1)模型,结合了灰色系统理论和最小二乘回归分析,可以有效处理工料机单一造价指数数据[9]。结合改进GM(1,1)的MEA-BP模型结构见图2。

图2 基于改进GM(1,1)的MEA-BP模型的框架结构
研究构建该模型的步骤为:收集2019年1月至2021年12月辽宁营口的工料机单一造价指数和水利水电综合造价指数并整理,确保数据的准确性和完整性;使用已知的工料机单一造价指数作为基础,利用改进的GM(1,1)模型进行预测,得到已知样本的模拟值和预测值;对已知样本数据和预测数据进行标准化处理,确保数据范围在合适的区间内,以提高神经网络训练的效果;确定MEA-BP模型的结构,包括输入层、隐藏层和输出层的节点数。标准化后的中心逼近式GM(1,1)模型的模拟值可以作为输入变量,而实际的水利水电工程综合造价指数可以作为输出变量;将已知样本数据分为训练集和验证集,用于模型的训练和评估;使用训练集,对MEA-BP模型进行训练。通过迭代训练过程中的正向传播和反向传播,调整神经网络的权重和偏置,以逼近样本数据的输出。通过上述步骤,就可得到所需时间段的水利水电综合造价指数的预测结果。
1.2 模型参数的选择和预处理
为了提高研究所构建的水利水电建筑工程造价指数预测模型的准确率,需对模型的相关参数和采集的数据进行优化和整理。研究所采用的BP神经网络的拓扑结构是传统的3层网络结构。其中,输入层为对水利水电建筑工程造价指数影响较大的11种工料机,包括人工、砖瓦、电、水泥、钢材、沙石、机械、炸药、燃油、钢筋、板枋材。因此设置研究模型的输入层为11个输入向量,用X(x1,x2,x3,...,x11)的集合表示[10]。隐含层采用单层结构,隐含层的节点计算公式如下:
(1)
式中:h为隐含层节点数;m为输入层节点数;n为输出层节点数;a为参数。
根据式(1),先设定隐含层神经元的个数为5,再逐渐增加神经元个数并训练神经网络,然后重新进行网络训练。在多次训练和比较模型过程中,确定具有最优性能的网络节点数为10。输出层仅包含单个神经元,用于表示水利水电建筑工程造价指数,因此将输出层设置为1,并用Y表示[11]。
构建的11-10-1的网络模型可以层与层之间相互联系,确定工料机单一造价因子和综合造价指数之间的关系。基于此,MEA-BP模型的参数类型选择及设计见表1。

表1 MEA-BP模型的参数类型选择及设计
水利水电建筑工程造价指数的预测,还需要定义预测指数的标准。现阶段,各指数的评判标准按照研究目的和方法分为许多种[12]。各种指数都有各自的含义,研究选取环比指数作为水利水电建筑工程工料机单一造价指数。选取环比指数作为工料机单一造价指数的优势有3点:通过与前一期或基准期进行比较,环比指数能够准确反映出短期内经济变化的趋势,帮助研究及时掌握市场的动态。其次,环比指数对于季节性波动和短期变动能够更为敏感地进行捕捉,从而更好地反映出市场的实际情况。此外,环比指数还可以用于预测和分析未来的趋势,通过对连续期间的环比指数进行比较,可以判断出经济的增长或下滑趋势,并对未来作出预测。
由于模型选择的单一造价指数种类,如果作为结果输出则略显繁琐。因此,研究选取综合造价指数作为输出结果。综合造价指数是基于多个工料机指标综合计算得出的一个相对数值,以衡量工程项目造价的整体水平和变化情况。本次研究使用BeautifulSoup网络爬虫软件,进入辽宁省工程造价通(https://ln.zjtcn.com/facx/c_t0119_d_p1_k_qa_qi.html),爬取辽宁省营口市2019年1月至2021年12月水利水电建筑工程的工料机单一造价指数和综合造价指数共36组数据,作为原始数据。首先,根据观察,人工剔除较为异常的两组数据。然后,利用剔除后的2019年1月至2021年6月的28组工料机单一造价指数作为基础,采用研究改进的GA(1,1)模型,预测2021年7月至2021年7月6组工料机单一造价指数。以2019年1月的数据为例,简单进行演示,2019年1月的各造价指数见表2。

表2 辽宁省营口市2019年1月工程造价指数
由表2可知,原始数据序列为X(t)=(115.2,100.7,111.2,116.3,144.3,102.3,110.2,100.6,114.3,120.3,111.8)。对原始数据进行累加,得到Y(t)序列:Y(t)=(115.2,215.9,327.1,443.4,587.7,690.0,800.2,900.8,1015.1,1135.4,1247.2);计算Y(t)序列相邻两项的均值,得到一个新的序列Z(t):Z(t)=(115.5,271.5,385.25,515.55,638.85,745.1,850.5,957.95,1075.25,1191.3)。构建微分方程,公式如下:
x(k+1)+ax(k)=b
(2)
使用最小二乘法,求解参数a约为0.1223,b约为238.8736。据此,可得工料机单一造价指数预测模型,公式如下:
(3)
根据建立的灰色模型和参数估计值,可以对工料机单一指数进行预测。
2 工程造价指数预测模型的性能分析和仿真应用
为了研究所构建预测模型性能的优越性和仿真预测的准确性,除了选取辽宁省营口市工程造价指数外,还以同样方式选取了位于西南的四川省成都市工程造价指数数据作为训练和测试集,以形成不同工程造价指数预测对照。同时,选取遗传算法(GA)、蚁群算法(ACO)与研究算法相同的试验环境中进行测试,形成模型之间的性能对照。
首先,对不同算法寻最优权值和阈值的误差进行测试,结果见图3。
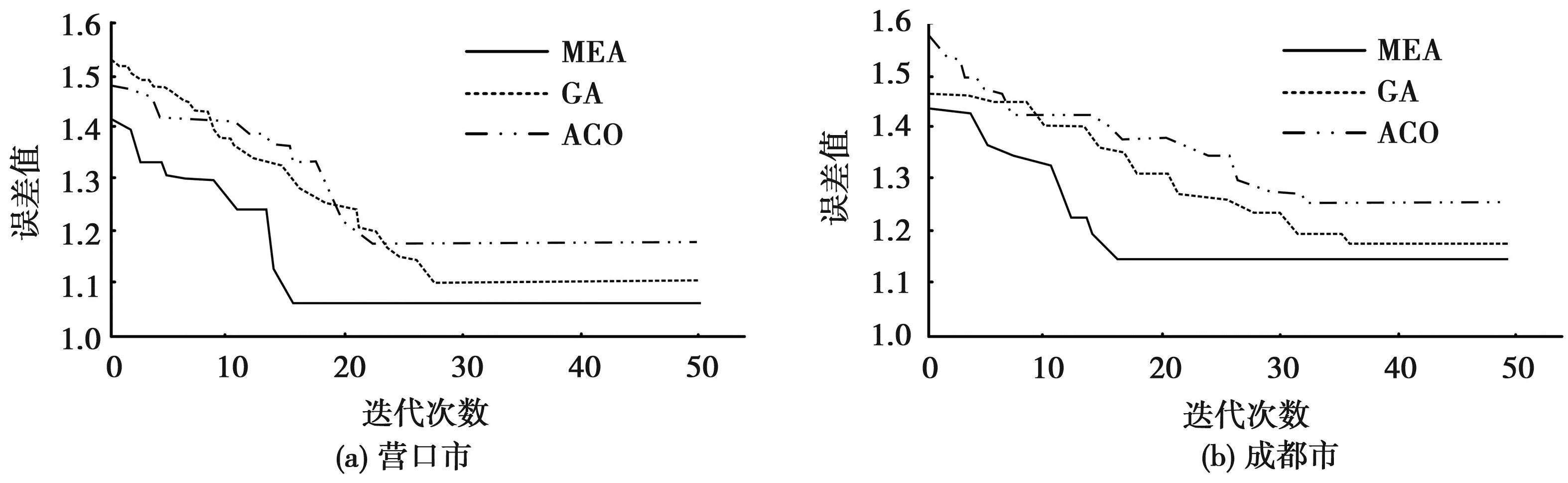
图3 最优权值和阈值的误差测试结果
图3(a)为利用营口市数据测试3种算法寻最优权值和阈值的误差结果。结果表明,3种算法的初始误差是GA>ACO>MEA;随着迭代次数的增加,3种算法的误差值均开始下降。GA和ACO分别迭代27次和23次趋于稳定,稳定后误差值分别约为1.10和1.18;而研究算法MEA仅迭代16次便趋于稳定,稳定后误差也是3种算法中最小的,约为1.06。
由图3(b)成都市的测试结果可知,由于地理位置不同,南北方工程造价环比指数预测存在一定差异,但差异并不大。MEA、GA、ACO三种算法分别迭代17、36、34次趋于稳定,稳定后误差值分别为1.14、1.17、1.26。表明MEA算法迭代次数较少,且能够达到更小的稳定误差,在寻找最优权值和阈值方面具有更高的效率和准确性。
然后,利用选取的3种算法对神经网络进行优化训练,具体结果见图4。
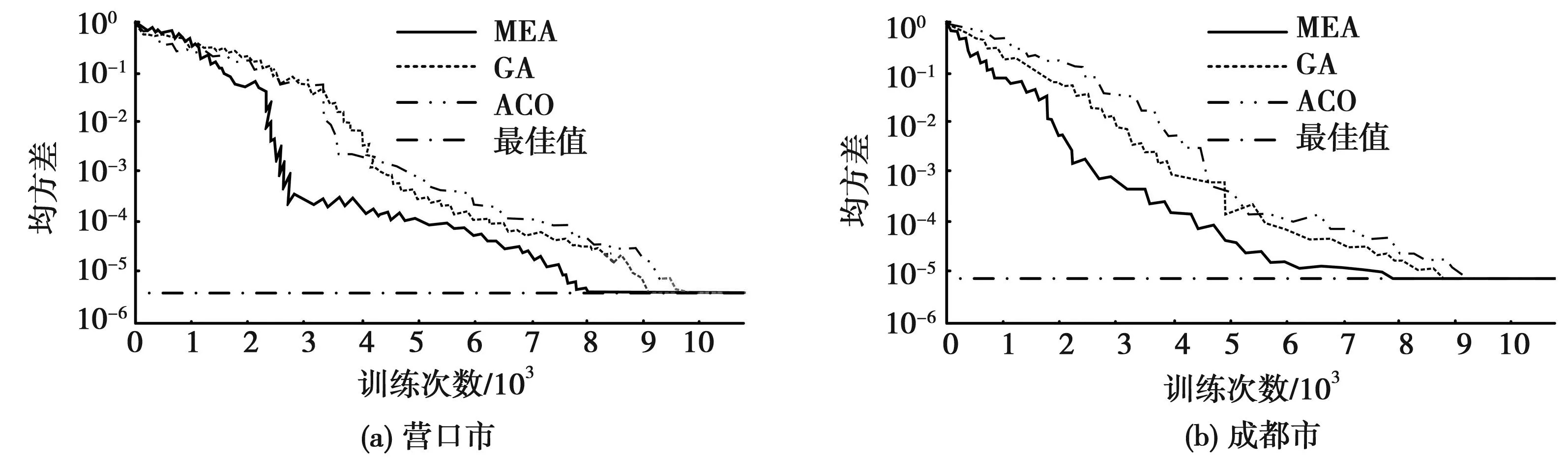
图4 神经网络训练结果
图4(a)为利用营口市数据测试3种算法对神经网络进行优化训练的结果。结果表明,随着训练的进行,各算法的均方差均开始减小。达到最佳训练状况时,MEA、GA、ACO分别训练了801、912、974次。由图4(b)可知,MEA、GA、ACO分别训练了791、883、924次达到最佳训练值。MEA算法在优化训练神经网络时,能够以较少的训练次数达到最佳训练状态,并减小均方差,表明MEA算法在训练效率和性能方面具有一定的优势。
然后,对整个预测模型(MEA-BP)的运算时间进行测试(定义1个预测数据量为一个月工程造价工料机单一指数和综合指数),具体结果见图5。

图5 模型响应时间测试结果
图5为3种算法在网络上爬取的100个数据集中运算时间对比结果。由图5可知,随着数据数量的增加,3种算法的运算时间均增加,但各算法增加幅度不同。约35个数据量之前,3种算法的运行时间几乎一致;随着数据量的增加,ACO和GA运算时间增长幅度越来越大。在100个数据量时,ACO运算时间约为8.8s;GA运算时间约为6.4s;MEA-GA运算时间幅度增长相对平和,预测100个数据量的运算时间约为2.4s。表明研究所建模型能够更高效地处理大规模数据,而这也是研究的目的。
最后,对两个市的2021年7月至2021年12月的综合造价指数进行仿真预测,结果见图6。
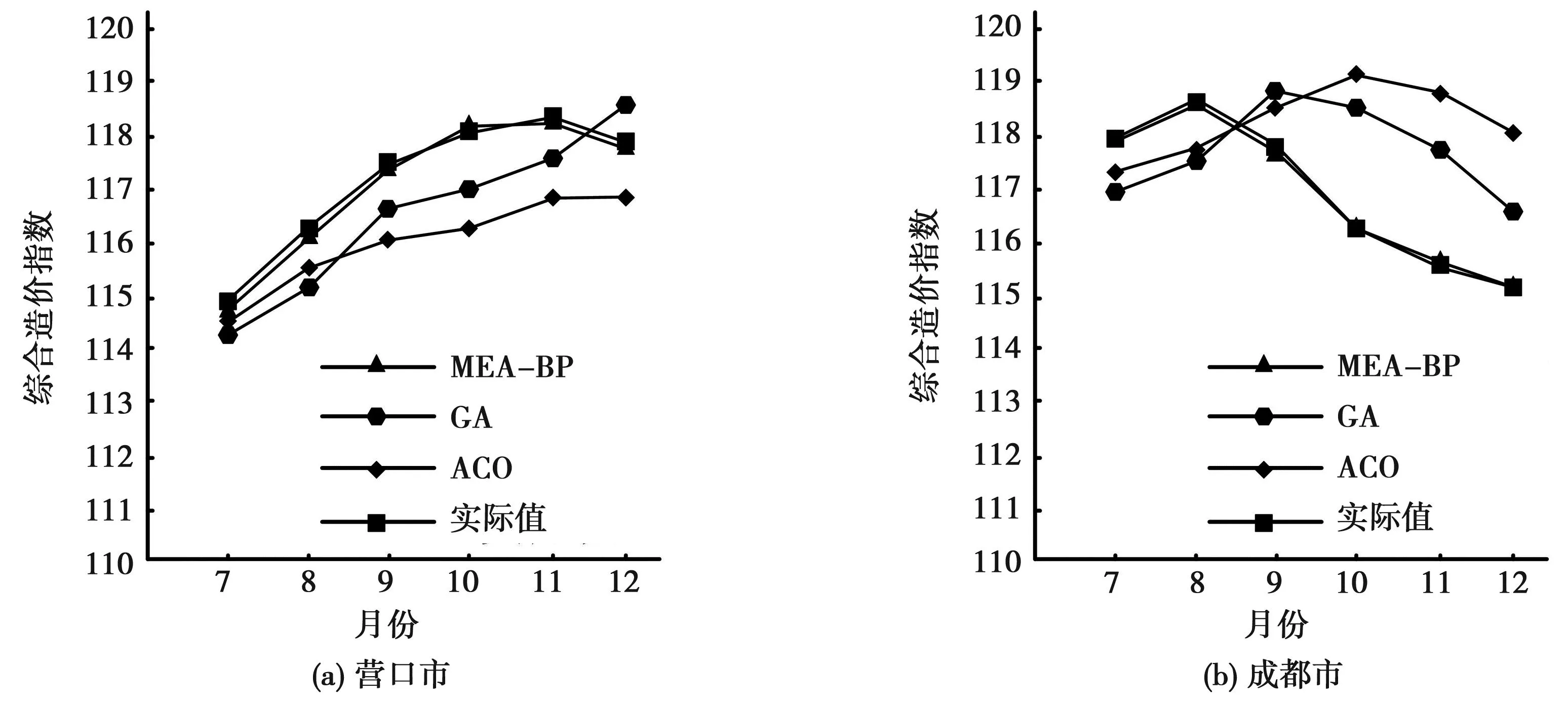
图6 综合造价指数预测结果
图6(a)为营口市2021年7月至2021年12月的综合造价指数对比结果。结果表明,该市实际的综合造价指数从7月份至11月份逐渐上涨,11月份至12月份略微下降。而研究模型的预测折线走势几乎与实际的综合造价指数一致,相对预测误差最大为8月份,约为0.25%。而GA和ACO模型的预测值,除了7月份误差(分别约为0.56%和0.82%)较小以外,其他月份与实际相比,误差均相对较大。并且这两种模型的预测折线走势是一直上升的,与实际不符。
由图6(b)可知,成都市的实际综合造价指数先升后降,8月份最高;研究模型的预测折线走势同样如此,且相对预测误差最大不超过0.16%。而GA和ACO模型的预测值与实际值相比,均相差很大,二者最小预测误差分别约为0.92%和1.07%。以上数据表明,研究模型在预测不同地区的工程综合造价指数表现较好,可以准确预测并反映实际走势。
3 结 论
准确预测工程造价指数,对工程的管理和决策有着重要意义。本文利用改进的GM(1,1),对工料机单一造价指数进行预测。在此基础上,结合MEA算法和BP神经网络的各自优点,构建了基于MEA-BP的工程造价指数预测模型。以营口市数据为例的测试结果显示,MEA迭代27次后,达到稳定误差值1.10,并且训练801次,达到最佳训练值,相对于其他两种算法,更快且更精准。研究预测模型运算100个数据量用时2.4s,并且最终的预测结果和实际值相比,相对误差不超过0.25%。以上数据表明,研究模型性能较优,预测结果精准,但研究所采用的方法与实际结果仍存在一定的偏差,有待进一步改进。
