机器学习在医疗与健康应用场景下的恶意流量检测
2024-01-24高健云刘颖颖戴依蓝李澍
高健云,刘颖颖,戴依蓝,李澍
1.中国食品药品检定研究院 医疗器械检定所,北京 102629;2.沈阳药科大学 医疗器械学院,辽宁 沈阳 117004;3.北京医药健康科技发展中心,北京 100035
引言
随着生活水平的提高,人们对于医疗的需求越来越高,同时网络技术的发展使多个医疗设备能够组合在一起并将医疗设备采集到的数据传输到服务器进行相关处理后应用到相应的场景中[1]。5G 技术的出现使数字化医疗更便捷[2]。为了增加人民健康幸福感,践行“健康中国”战略,医院对于5G、网络医疗健康场景需求愈发增加[3-4],尤其是院前急救中的及时诊断能够极大提高伤患存活率[5]。但近年来随着全球联网设备数量的快速增加,联网设备遭到各种恶意流量攻击的现象频发,对于存储医疗设备所采集数据的服务器以及连接到互联网中的医疗设备来说,网络安全至关重要,亟需检测各种可能出现的恶意流量并采取相应的安全措施。目前成熟的恶意流量检测系统如Maltrail,多使用决策树模型进行恶意流量判定[6-7],该类系统可能会产生过拟合现象,训练集中的异常值也会影响整个系统的准确率[8-9]。因此本文使用随机森林模型进行恶意流量监测以降低过拟合风险以及减少异常值所带来的影响。
当前恶意流量攻击发展迅速,手段比以往更加隐蔽与复杂,恶意流量攻击的关键特征往往隐藏在关键的数据流中,直观的攻击极少。同时每一流量中数据特征多、维度高,在采集样本时所采集到的流量样本往往由于不均衡导致训练模型实用性低,所以本文采用过采样技术解决样本不均衡问题[10],且本文提出的基于随机森林模型的恶意流量检测准确率较传统的决策树模型更高。
1 资料与方法
医疗与健康应用是将所采集的数据用于远程诊断或患者监控,因此医疗与健康应用场景必然要搭建在服务器上并连入到互联网中。由于连入互联网会使得医疗与健康应用场景更易受到他人攻击,因此为了更好地防范攻击,需要对连入互联网的医疗健康应用场景服务器可能遭到的恶意流量类型作出统计,以便恶意流量检测能够准确、无遗漏地检测到服务器可能遭到的恶意流量攻击。据统计,服务器主要容易遭到恶意流量攻击的类型有拒绝服务、端口扫描、跨站脚本攻击、SQL 注入、爆破攻击、渗透攻击。
入侵检测系统和入侵防御系统是抵御复杂且不断增长的网络攻击最重要的防御工具。由于缺乏可靠的测试和验证数据集,基于异常的入侵检测方法正面临着一致性较差和准确性较低的问题。CIC-IDS2017 数据集包含了正常流量和目前常见的绝大多数攻击流量,是在真实世界中基于超文本传输协议、超文本传输安全协议、文件传输协议、安全外壳协议和电子邮件协议所捕获的流量数据。该数据集使用基于时间戳、源以及目标IP、源以及目标端口、协议和攻击的标记流。
1.1 数据资料
本文以CIC-IDS2017 样本集作为模型的训练集与验证集,样本集中共包含目标端口、流量持续时间等76 个属性(表1)。该样本集包含了目前绝大多数攻击流量种类,因此在进行模型训练时可使用CIC-IDS2017 中的数据,其中所包含的恶意流量数目与种类如表2 所示。

表1 样本集样本属性
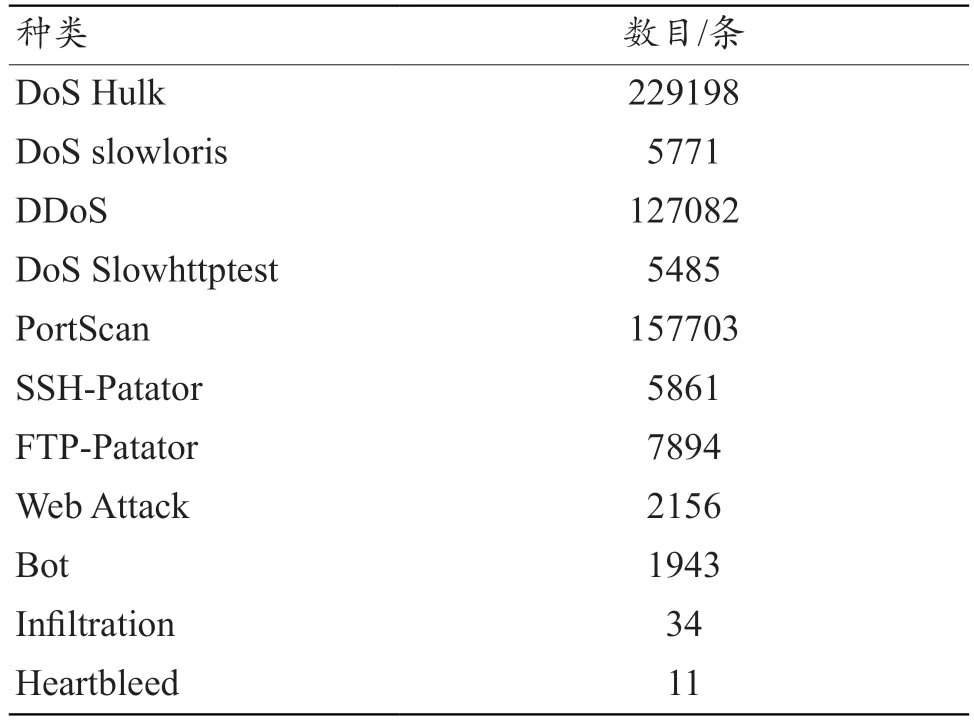
表2 样本集所包含恶意流量数目与种类
1.2 方法
1.2.1 样本数据预处理
由于CIC-IDS2017 所采集的样本并不均衡,导致机器学习模型无法学习到样本量较小的恶意流量类型的样本特征,从而使模型无法拟合现有数据,出现欠拟合的问题,影响模型预测的准确性。过采样技术可以解决样本不均的问题,提升模型泛化能力[10]。朴素随机过采样的核心是随机复制或重复少数类样本,使得所采集样本中少数类与多数类的个数达到较为均衡的状态。该技术简单,且所使用的训练集属性多、维度高,数据本身理解复杂。由于本文样本集部分恶意流量数目少、样本集数目不平衡且捕获新的数据代价高昂且复杂,所以更适合使用朴素随机过采样技术对其进行处理。同时,在对样本集进行过采样后需要将样本集中的脏数据进行剔除处理。
1.2.2 实验方法
样本集CIC-IDS2017 为5 d 内采集的数据,由于数据中各个种类的恶意流量数目差距过大,所以需先对样本集作样本预处理,再使用处理完毕的样本进行特定流量模型下的恶意检测。
在模型建立完毕后,将医疗设备所组建的场景与服务器、漏洞扫描设备连接到同一网络中搭建成所需要的实验环境。使用漏洞扫描设备向服务器发送恶意流量,同时将医疗设备所收集到的数据发送到服务器中,使用sniff捕获服务器所接收的前500 个流量。将捕获的流量数据进行数据预处理,再将其分别放到决策树模型和随机森林模型中进行模型预测。
1.2.3 机器学习方法
在医疗与健康应用场景下的恶意流量检测是对场景中所有产生的流量数据进行分类处理。在机器学习中,常用的算法有支持向量机、决策树、随机森林等。通过机器学习方法可以对样本集学习后场景中的恶意流量进行相应分类。
(1)支持向量机。支持向量机是一类按监督学习方式对数据进行二元分类的广义线性分类器,可以解决小样本、非线性和高维数据问题。支持向量机对新的、不可见的数据具有良好的泛化性能。
(2)决策树。决策树是一种树形结构,每个树上的非叶子节点表示针对数据的某个属性对其进行判断。每个分支代表一个判断结果的输出[11],每个叶节点代表具体的分类结果。决策树模型的生成算法有ID3、C4.5 和C5.0 等[12]。决策树算法具有计算复杂度不高、分类速度快、数据预处理简单、产生结果易理解且便于可视化等优点。但决策树算法容易出现过拟合现象,模型泛化能力低、稳定性较差,因此决策树算法是局部最优解而非全局最优解。
(3)随机森林。随机森林是由Breiman 和Culter提出的一种基于引导聚集算法(Bootstrap Aggregating,Bagging)和决策树算法的集成学习算法[13-14]。Bagging算法是并行式集成学习的代表,随机森林算法是Bagging 算法的一个扩展变体。随机森林在以决策树为基学习器构建Bagging 算法集成的基础上,进一步在决策树的训练中引入了随机属性选择,即利用Bootstrap技术从原始样本中抽取随机化的样本构建单棵决策树,再在决策树的每个节点通过随机特征子空间的方式选择分裂点进行分裂,最后把决策树组合在一起通过投票的方式得出最终的预测结果。
本文通过实现决策树与随机森林模型,将两个模型的性能进行对比,以此说明在随机森林模型建立所需时间与决策树模型建立所需时间相差微弱的情况下,随机森林模型的性能优于决策树模型,因此随机森林模型更适合医疗与健康应用场景下的恶意流量检测。
1.2.4 模型评估指标
捕获医疗设备所连接的服务器接收到漏洞扫描设备发送的恶意流量,将流量放到决策树模型与随机森林模型中进行预测,使用精准度、准确度、召回率、F1 得分作为模型性能评价指标[15]。其中,精准度体现了模型对负样本的区分能力;召回率体现了模型对正样本的识别能力;F1 得分越高,模型越稳健。精准度、准确度、召回率、F1 得分的计算方式分别如公式(1)~(4)所示。
式中,TP 为被正确预测的正例;FP 为被错误预测的正例;TN 为被正确预测的反例;FN 为被错误预测的反例。
2 模型建立
2.1 样本预处理
本文使用的CIC-IDS2017 样本集是真实世界中的网络数据,其中恶意流量的数目较正常流量少,且各类恶意流量的数目不均衡,直接使用CIC-IDS2017 样本集进行恶意流量检测模型训练很容易产生模型过拟合现象。为了避免该现象发生,本文利用朴素随机过采样方法对数目少的恶意流量进行数据扩充,避免模型产生过拟合现象。
失衡数据发生在分类应用场景中,类别之间的分布不均匀是失衡的根本。假设有一个二分类问题,目标(target)为y,取值范围为0 和1。当其中一方(如y=1)的占比远小于另一方(y=0)时,就会出现失衡样本。失衡分为3 种程度:轻度失衡:20%~40%;中度失衡1%~20%;极度失衡:<1%。本文的样本集中恶意流量总和为543135 条,在模型训练时随机抽取60%数据,将抽取后的数据中极少的恶意流量样本扩充到5000 条,以解决样本失衡问题。
本文使用的样本集数据没有整合,且存在如Nan 和Infiniti 类的脏数据,因此需要将数据集进行整合,并将数据集中的脏数据剔除。预处理的样本量为1708979 条。
2.2 模型实现
2.2.1 决策树模型构建
本文使用C4.5 决策树生成算法,该算法使用信息增益率来选择最优化分属性,增益率的计算方式如公式(5)所示,分裂信息度量的计算方式如公式(6)所示。信息增益的计算方式如公式(7)所示,信息熵的计算方式如公式(8)所示。
式中,GainRatio(S,A)为增益率;SplitInfor(S,A)为分裂信息度量;SplitInfor(S,A)为信息增益;H(S|A)为信息熵;S为所用数据集;A为某个特征;Sk为集合S中属于第k类样本的样本子集;Si为S中特征A取第i个值的样本子集。
为了避免决策树模型会根据样本固定顺序学习导致模型训练效果不佳,模型整体性能变差,同时为了增强决策树模型的鲁棒性,在进行模型训练时将输入样本进行随机输入。故随机抽取处理完毕的CIC-IDS2017 样本集中80%的数据(共1367183 条)进行决策树模型训练,样本集中剩余20%(共341795 条)的数据作为验证集。根据上述算法流程建立C4.5 决策树。为了获取最优决策树深度[14],对决策树深度进行逐次训练。模型精度随决策树深度的变化趋势如图1 所示。
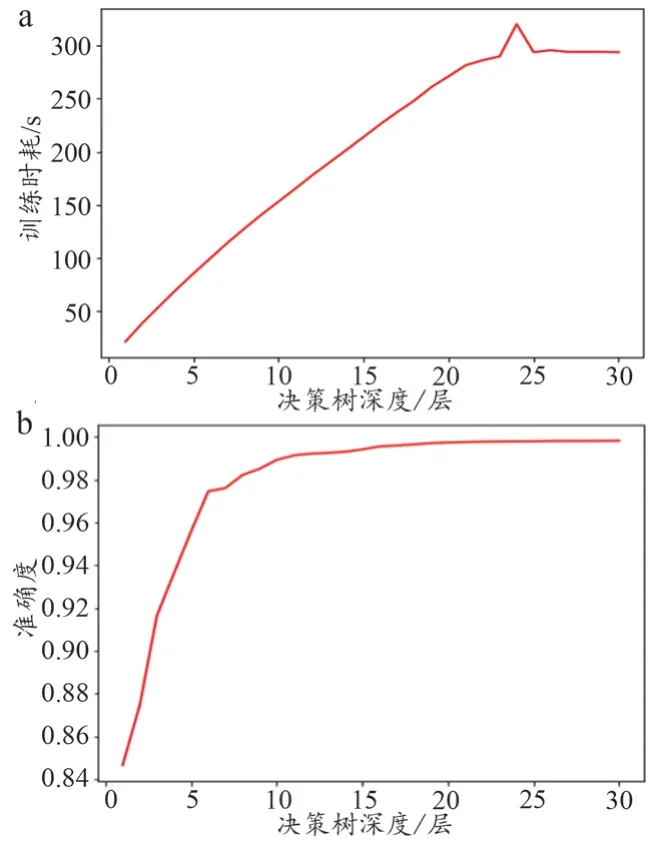
图1 决策树深度与模型训练时耗(a)和准确度(b)的关系图
模型精度随子树数目变化趋势随着决策树深度上升而上升,见图1。决策树深度为25 层时模型训练时耗的变化率最低[16],而决策树深度达到20 层后准确度变化率趋于0。在模型训练时耗与决策树深度变化关系中,出现了增长率突然变大的情况(图1a),推测与模型训练的硬件环境有密切关系。在决策树深度为23 层时,决策树模型准确度及模型训练时耗比相对较低(图1)。据此,进行决策树建立时,选取的决策树深度为23 层[17]。
2.2.2 随机森林模型构建
构建随机森林模型时,为增大样本的随机性,先从训练集中随机抽出样本进行训练,进而减少模型的相似性,提高整体模型的鲁棒性,增加模型的泛化能力。随机森林由多个弱分类器组成,本文选择CART 决策树作为随机森林的弱分类器。
为了保证模型准确率高且学习速率快,对模型参数(随机森林)构建树的数目对于模型准确率的影响进行训练。同建立决策树模型一样,在建立随机森林模型时,为了获取更好的训练效果,同时增强随机森林模型的鲁棒性,将处理完毕的CIC-IDS2017 样本集中80%的数据(共1367183 条)进行随机抽取,并进行决策树模型训练,样本集中剩余的20%的数据(共341795 条)作为验证集。模型子树数目与模型准确度、训练时耗的关系如图2 所示。
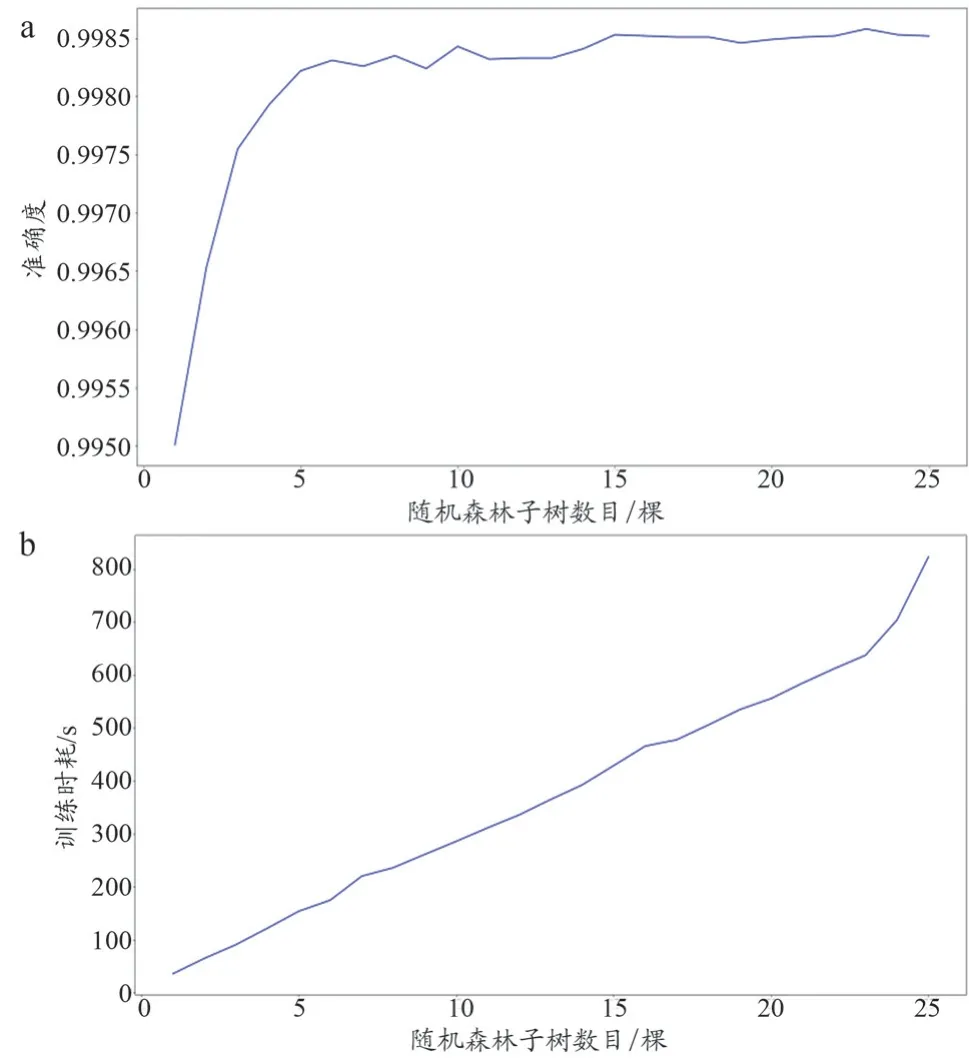
图2 随机森林子树数目与模型准确度(a)、训练时耗(b)的关系图
模型精度随着子树数目上升而上升,但当子树数目到达15 颗时,模型的准确度的上升速度逐渐平缓,增长率趋于0;模型训练时耗也随着子树数目的增加而增加,在区间15~23 颗内,时耗增长率较低[17]。根据图2 可以确定,随机森林的子树数目为23 颗时,模型准确度最高,且模型训练时耗适当,模型训练精度时耗比相对较低,故选择子树数目为23 进行随机森林模型建立[15]。
3 结果
以本文搭建的医疗与健康应用场景下捕获到的500 条网络流量作为测试集,将其分别放到决策树模型、随机森林模型中进行结果预测和分析,对两个模型进行评估对比。
3.1 决策树模型预测结果
在使用决策树模型对医疗与健康应用场景下捕获到的500 条网络流量进行结果预测完毕后,做出混淆矩阵图[18](图3)。由混淆矩阵可计算模型对应各个类别的准确度和召回率[19](表3)。由对决策树模型的评估结果可知,决策树模型对于慢速拒绝服务攻击以及跨站脚本攻击的预测准确度为95%。尤其是决策树模型对慢速拒绝服务攻击进行预测时,会将其与跨站脚本攻击混淆。
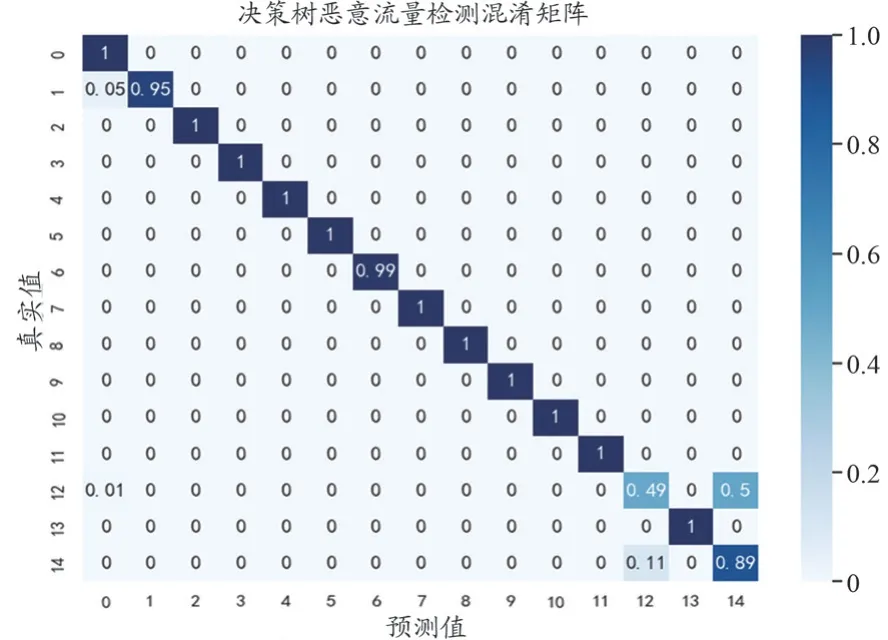
图3 决策树模型混淆矩阵

表3 决策树模型评估结果
3.2 随机森林模型预测结果
将随机森林模型的预测结果做成混淆矩阵图(图4)。随机森林模型对恶意流量的整体评估结果如表4 所示。随机森林模型对于慢速拒绝服务攻击预测准确度为99%,能够正确预测大多数慢速拒绝服务攻击。随机森林模型在医疗与健康应用场景下整体表现良好[20]。

图4 随机森林模型混淆矩阵
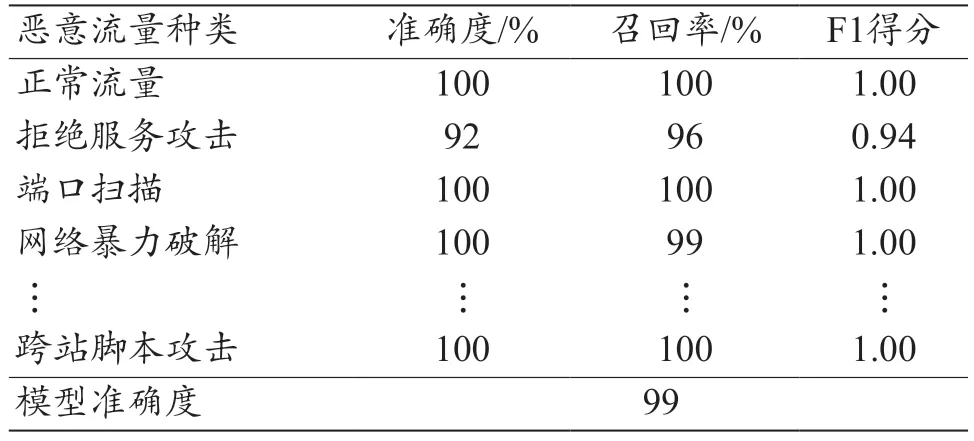
表4 随机森林模型评估结果
综上所述,决策树模型准确度为95%,而随机森林模型准确度为99%,同时随机森林模型在个别恶意流量预测方面(如慢速拒绝服务攻击、跨站脚本攻击随机森林模型等)的准确度都高于决策树模型,说明随机森林模型相较于决策树模型有更好的泛化能力。因此,随机森林模型在恶意流量检测方面的评估结果优于决策树模型,更适合医疗与健康应用场景下的恶意流量检测。
4 讨论
计算机网络技术的快速发展带动了医疗技术的发展,人们对于智慧医疗的需求也越来越高。智慧医疗健康场景需要安全的网络环境,因而对恶意流量检测的准确度要求变得严格。本文以采集的CIC-IDS2017 样本集作为模型的训练集与验证集,使用Python 与sklearn 对样本集数据进行预处理,并调整模型参数构建决策树和随机森林模型,用于医疗与健康应用场景下的恶意流量监测。将在医疗与健康应用场景下所捕获的500 条流量数据作为测试集,分别使用决策树模型与随机森林模型进行结果预测,并通过绘制混淆矩阵以及计算准确度、召回率、F1 得分对模型进行整体评估。2 个模型对恶意流量识别都有较好的预测结果,但对于慢速拒绝服务攻击,2 个模型预测结果准确度均不理想,但整体上,随机森林模型对恶意流量监测的准确度高于决策树模型。
本文将机器学习技术应用到医疗与健康应用场景下进行恶意流量监测,为医疗应用场景下的网络安全研究提供了一定参考。在今后的研究中,可将其他模型与随机森林模型结合形成新的模型进行研究,以进一步提高在医疗与健康应用场景下对特定恶意流量检测的准确度。
