“两微一端”视听节目监管系统探析
2024-01-23孟宪超
孟宪超
内蒙古自治区广播电视监测与发展中心 内蒙古 呼和浩特市 010050
引言
“两微一端”即微信公众号、微博和移动客户端,它们是新媒体领域的主要应用形式。随着“两微一端”在娱乐、新闻、资讯等领域的迅速发展和普及,对其进行更严格、更全面的监测监管迫在眉睫。因此,本文探讨一种基于虚拟化云计算技术的“两微一端”视听节目监管系统的设计与实现方法,以提高监测监管的效率和准确性。
1 系统软件架构
“两微一端”视听节目监管系统采用面向服务的架构,即SOA,以服务总线为基础,满足远程访问服务的相关要求,构建了可伸缩、有弹性的基础架构。此外,本系统所架构的技术模块与面向用户的门户一一对应,对公共服务、基础架构高度重视,缩短新业务开展时间,提高业务流程变更效率,为之后业务系统的不断扩展预留足够的空间。“两微一端”视听节目监管系统架构设计,如图1 所示。
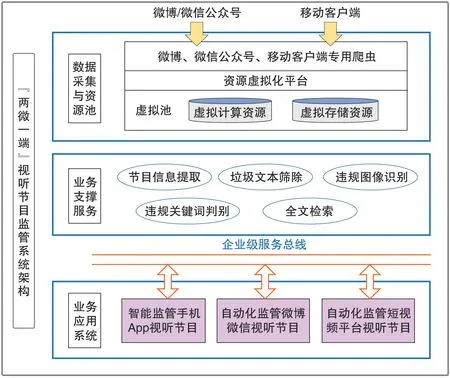
图1 “两微一端”视听节目监管系统架构
1.1 业务应用系统
本系统人机交互界面相对友好,用户通过该系统可以轻松地进行日常业务操作。系统在对App 视听节目进行监测监管的基础上,对微博、微信视听节目进行监测监管,满足用户在不同场景下的使用需求,有效提高工作效率和监管效果。
1.2 业务支撑服务
本系统采用模块化设计,性能稳定、功能强大,并通过企业级服务总线为上级业务系统提供多种服务,如平台、数据等,这些服务包含节目信息提取、违规关键词判别、违规图像识别、垃圾文本筛除以及全文检索等。
节目信息提取:对微博、微信以及客户端上的各种目标视听节目迅速准确地提取相关结构化信息,如目标视听节目的名字、来源、时间、基本内容等,并将这些信息进行整理,形成数据集,用于后续进行数据分析和决策。
违规关键词判别:对网络中整段的文本内容进行分词处理,并与已经收入数据库中的关键词进行比对,迅速检索分析敏感内容,及时发现违规视听节目并进行上报。
违规图像识别:系统自动对视听节目中的图像内容进行分析,发现涉黄涉暴或者其他违规图像及时识别并提取。这项功能主要用于及时发现并处理疑似含有违规内容的视听节目。
垃圾文本筛除:对垃圾文本进行过滤筛除。系统提前对网络中的广告、股票等没有实质意义的垃圾内容进行剔除。这是对文本内容进行分析处理的基础性措施,为了提高文本内容分析的准确率。
全文检索:利用本系统对视听节目进行全文检索。用户可以通过输入关键词或关键词组,对目标视听节目检索,迅速找到所需信息或者数据,提高信息提取效率。
1.3 数据采集与存储
在数据采集方面,系统主要提供手机App 以及微博、微信、专用爬虫模块,全面抓取和分析各类数据。
本系统是在虚拟化云计算平台的基础上进行构建的,将计算、存储、网络等物理硬件设备集中起来,通过虚拟化云计算平台形成一个虚拟资源池,通过这个虚拟资源池对这些资源进行搭建并实现动态调度,使这些资源与监测监管平台形成相对独立的耦合关系。由此,可以根据不同业务或者用户使用需求,利用虚拟资源池充分调用各种资源。此外,还可以利用虚拟资源池进行资源管理、数量统计和系统监控。本系统可以针对不同业务单位的不同需求,为其提供相应技术支撑平台和应用系统,用以调配资源、提供服务。
2 系统功能设计
2.1 智能监管手机App 视听节目
系统具备对辖区内手机App视听应用进行主动发现的功能,并能对用户设定的重点监测目标,即App 中传播的目标视听节目信息进行采集与分析。系统能主动发现违规或敏感的视听节目内容,经过人工审核确认后,帮助用户实现对手机App 视听节目的有效监管。
2.2 自动化监管微博微信视听节目
系统能主动识别用户设定的重点检测目标,如所关注的微博、微信,用户提前设置规则,系统根据规则提取并分析目标账号或者公众号上的视听节目信息,及时查找并处理违规视听节目内容,最终经过用户审核确认,以此对微博、微信平台上的视听节目进行有效监测监管。
2.3 自动化监管短视频平台视听节目
系统能够主动识别用户关注的目标短视频平台,根据用户提前设置的规则提取并分析相关短视频平台上传播的视听节目信息,及时查找并处理违规视听节目,以此对短视频平台上视听节目进行有效监测监管。
3 系统核心技术
3.1 爬虫需要规避“两微一端”防抓取策略
在实施爬虫时,必须考虑到可能会遭遇到防抓取策略的影响,可采用如下规避措施:
避免高频率请求:在抓取数据的过程中,爬虫可能会对目标网站发送大量的请求,导致目标网站的服务器拒绝或限制爬虫的访问。为避免这种情况的发生,可以采取主动规避的方式。例如,在抓取数据时,尽量避免处理同一来源的链接;遇到禁止访问的情况时,应采取学习的方式,适当增加延时参数,减少并发访问的数量。
反爬虫机制对策:目标网站可能部署了各种反爬虫机制,如验证码、用户登录、IP限制等,以防止爬虫的访问。对此,应采取使用代理IP、模拟浏览器或使用验证码等相应的技术手段来规避反爬虫机制。
数据准确性控制:在抓取数据的过程中,爬虫可能会出现数据不准确、不完整的情况。因此,需要对抓取的数据进行校验和处理,以确保数据的准确性和完整性。
提升爬虫性能:在抓取大量数据时,爬虫可能会出现性能下降、卡顿、崩溃等问题,可以通过优化爬虫代码和架构解决这些问题,如采用分布式、异步、缓存等技术手段,提高爬虫的性能和稳定性。
3.2 支持需要账户登录的数据采集
微博、微信公众号、手机客户端等平台往往需要用户先进行账号登录才能浏览或下载相关的数据内容。因此,系统应支持模拟用户登录状态下的数据采集。以下是关于支持账户登录状态下的数据采集的设计思路和技术实现:
模拟登录:爬虫系统可以使用自动化测试工具,模拟用户登录到目标网站,成功登录后,爬虫系统可以发送请求,获取需要采集的数据。这种方式能有效获取那些需要账户登录才能访问的数据,保证数据采集的完整性和准确性。
账号密码保存:为了方便后续的登录操作,爬虫系统可以将用户的账号密码保存在安全的地方,如放在加密数据库或本地文件中。在需要登录时,爬虫系统可以从这些地方获取账号密码,然后进行登录操作。
记录登录状态:为了提高用户体验,爬虫系统可以记录用户的登录状态,以便在下次访问时不需要再次输入账号密码,这可以通过在本地存储一些标识符或令牌来实现,减少用户操作。
登录失败处理:在实际操作中,可能会出现各种错误导致登录失败,如用户名或密码错误、验证码错误等。此时,爬虫系统需要通过重新登录、重新发送验证码等行为,保证数据采集的稳定性和连续性。
异常处理:在数据采集过程中,可能会出现各种异常情况,如网络中断、页面不存在等。爬虫系统需要通过重试请求、记录错误信息等方式来处理这些异常情况,以保证数据采集的可靠性。
3.3 敏感内容过滤筛选
当前网络监管系统在过滤敏感内容时,主要依赖文本内容的筛选,但这种方法存在一定的偏差。通过文本关键词来描述敏感内容并不精准,针对严格的定义可能会遗漏一些应该过滤的内容,而对宽泛的定义而言可能会导致虚警率过高,系统过滤的结果往往不是用户所期望的。同时,随着监管业务范围的扩大,人工工作强度也将增加。
为解决敏感内容过滤准确性的问题,本系统采用了综合的技术手段,包括对文本、图像内容进行智能分析的技术和多层级的自动过滤筛选技术。其中,涉黄涉暴图像检测智能分析技术可以有效识别敏感或违规内容,并通过多次筛选确定可信度最高的疑似违规内容,最终由用户进行审核确认。这种方法可以显著提高网络违规或敏感内容的鉴别准确率,降低人力成本。
3.4 知识库反衍学习
为了保证系统监管结果的准确性,系统的敏感内容知识库需要不断进行更新和完善,本系统采用了以下技术手段来实现这一目标:
敏感内容分析:对一段时间以来累积的经过人工审核确认的敏感内容进行分析,如热点词语、短句,从中提炼出有价值的信息,并主动推送给相关业务人员进行审核,审核确认后的信息将自动加入到系统敏感内容知识库,从而不断向用户汇总和推荐敏感线索资源。
机器学习算法:通过机器学习等技术,从大量的网络数据中自动提取和挖掘敏感信息,并将其加入到敏感内容知识库中。通过机器学习算法的不断训练和优化,系统的敏感内容知识库可以不断得到更新和扩展。
加强合作:与相关的监管机构进行合作,共同建立和维护敏感内容知识库,确保系统中的敏感内容知识库得到更全面和准确的覆盖,满足监管工作的需求,同时系统也可以得到更多的数据支持和专业技术支持。
结语
“两微一端”视听节目监管系统主要包含对视听节目数据的收集、分析、处理和存储等模块。数据收集模块通过互联网和移动客户端等多种渠道,实时采集视听节目的数据,并对其进行初步处理和筛选。数据分析模块利用虚拟化技术,对收集到的数据进行深入分析和挖掘,以实现对节目的精确监管。数据处理模块负责对节目的内容进行分类、审核和编辑等,以确保节目的质量和安全性。数据存储模块将处理后的数据存储在高性能的分布式存储系统中,以便后续的查询和分析。
整套系统的实现方法主要涉及云计算平台的建设和虚拟化技术的应用。首先,构建一个高效的云计算平台,该平台由多个计算节点组成,可实现抓取数据的分布式处理和存储。其次,利用虚拟化技术,将计算资源进行动态分配和管理,以提高系统的性能和效率。最后,采用容器化技术,使系统具有更好的可扩展性和可移植性。
未来,系统会得到进一步的完善和优化,以更好地适应复杂多变的监管需求。通过引入更先进的5G 技术和人工智能技术,使其性能更加卓越,进行更精准的节目监管、更高效的数据处理和更安全的数据存储,为广播电视行业发展带来积极影响。
