基于GEE的洱海流域土地利用/覆被分类算法对比研究
2024-01-20董亚坤何紫玲曾维军
董亚坤,王 钰,何紫玲,王 鹏,赵 昊,曾维军*
(1.云南农业大学 水利学院,云南 昆明 650201;2.云南农业大学 资源与环境学院,云南 昆明 650201;3.自然资源部 云南山间盆地土地利用野外科学观测研究站,云南 昆明 650201)
土地利用/覆被变化(LULC)反映区域的经济水平和城镇化的发展[1-3]。准确分类和评估土地利用变化对于保护土地和生态环境及制定可持续发展战略至关重要[4]。遥感影像具有观测面积广、周期短等优点,在监测大面积及长时序土地覆被变化方面具有优势,因此在LULC分类中被广泛使用[5]。从单一类型的LULC变化监测,如森林、水域等,到地表覆被的全部分类[6];从传统的人工目视解译,到如今的人工智能自动、批量化解译[7]。随着遥感技术及处理平台的发展,机器学习算法、人工智能解译在遥感影像分类中的应用,分类和回归树(classification and regression tree,CART)[5]、随机森林(random forest,RF)[8]、支持向量机(support vector machines,SVM)[9]等方法广泛应用于遥感图像分类中,GEE是一个采用JavaScript或Python语言调用、处理和分析数据的平台[6],其性能稳定,尤其适合大范围、长时间、多源遥感数据解译,一经推出便被众多科研人员使用,研究区涉及平原[10]、岛屿[11]、流域盆地[1]等地形地貌。
洱海流域内的大理市属于旅游胜地,频繁的人类活动造成地表变动剧烈[12]。目前,有关洱海流域土地覆被产品,如Globeland30、GLC_FCS30等是公认度较高的土地覆被产品,但总体精度不高,各有优缺点[5],在对分类精度要求更高的中小尺度内会存在区域适应性不强的问题[8]。如GLC_FCS30在云南山区会将湖泊、耕地错分成草地、林地或城镇用地;许晓聪等[13]指出Globeland30 分类结果细节表现不足且经过人工处理,而GLC_FCS30在中国南部的丘陵城市、印度中部的乡村、美国的东部平原,会出现部分地类错分或者分类结果不完整。陈逸聪等[14]指出,FROM_GLC、GLC_FCS30 和 GlobeLand30总体对占长三角地区面积越高的地类其分类精度越高。此外,谷晓天等[15]、戴琴等[16]对比4种分类算法,指出区域最优的分类算法并进行精度对比;贾玉洁等[17]将面向对象特征的决策树、 ISODATA法和最大似然法对Sentinel-2A影像进行分类对比,指出面向对象特征的决策树方法在大理市的适用性较好。众多分类方法多集中于单期的土地利用/覆被分类,缺少长时间序列下较大面积复杂高原山区的快速、准确提取。而高原山区受山脉阴影、地形复杂等因素影响,在遥感影像的长时间、高效分类上,难以满足研究需求。
因此,本研究利用GEE平台,利用CART、RF和SVM 3种常用的机器学习方法,进行洱海流域的长时间土地利用覆被变化分类,寻找最适合的分类方法,为洱海流域土地的合理开发利用及产业布局规划提供数据参考。
1 材料与方法
1.1 研究区概况
洱海流域位于中国云南省大理白族自治州境内,流域面积2 565.0 km2,属于川滇生态屏障区的重要组成部分[18]。流域气候湿润,是典型的亚热带高原季风气候,具有年温差小、日温差大、干湿季节分明的气候特点[19]。
1.2 数据来源和处理
1.2.1 数据来源 基于Google Earth Engine(GEE)平台数据集,选取数据见表1。

表1 数据来源
1.2.2 数据处理 首先,基于GEE平台加载研究区矢量边界和已有的土地利用/覆被数据(GLC_FCS30);选取研究区地表植被生长状况较好的时间段,同时为消除冬季高山积雪影响,设置各年份影像获取时间均为3-10月(此时间段虽横跨3个季节,但却为研究区种植水稻等粮食作物时节,也是植被生长旺盛时期,可利用季节性差异进行土地覆被分类),通过年份筛选含云量低于20%的遥感影像;其次,采用GEE中的算法对每期原始卫星影像数据进行裁剪等预处理,构建光谱指数;基于DEM数据提取高程、坡度等,构建地形特征,联合光谱指数构建多维分类特征集;然后,基于Google Earth Pro、遥感影像和GLC_FCS30产品数据选取样本点,进行洱海流域的LULC分类;之后进行八邻域空间滤波等分类后处理,平滑影像。研究技术路线见图 1。
1.3 研究方法
1.3.1 土地利用分类和样本点选择 结合研究区实际情况,将洱海流域的土地利用类型分为耕地、林地、草地、水域、建设用地和未利用地 6 类。样本点的选取采用“多源一致、时序稳定、均匀选取”的方法[5]。首先在GLC_FCS30等产品中遴选分类可信、稳定不变的区域选取样本点;其次利用实地调查数据、 Google Earth Pro历史影像、不同波段的影像组合选取样本点;在此基础上,再根据分类结果、评价精度,结合实地确认的地类,以目视方式,适当修正少量样本点,保证样本均匀分布的同时反复调整训练样本使不同方法分类效果达到较优状态[15]。经对不同地类、不同年份的样本点计算,样本点的重合率在80%以上,重合的区域为湖泊、永久基本农田、受人类活动影响较小的林地和草地以及建设用地(表2)。

图1 技术路线
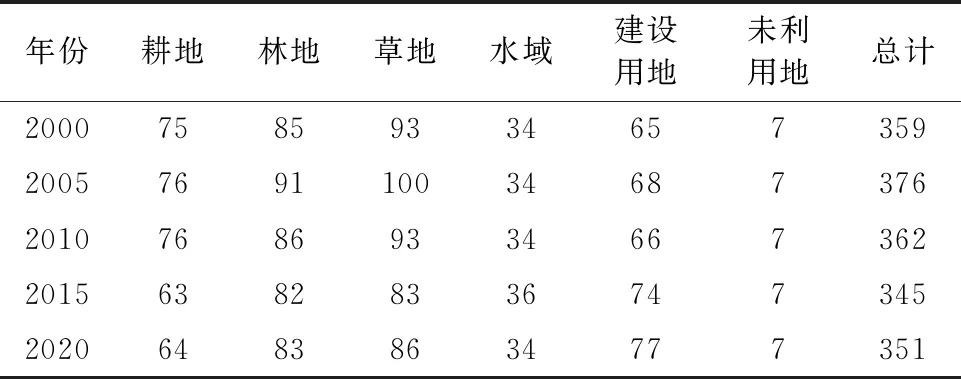
表2 训练样本点
1.3.2 分类特征 洱海流域地形、地貌多样,有高耸的苍山山脉,需要选择多种特征参数进行辅助分类,以提高分类精度。首先应用遥感影像丰富的光谱信息,因此光谱特征是最主要的特征参数。而山体阴影、坡度等会影响洱海流域土地利用/覆被分类,所以地形特征是分类过程中除光谱特征外最主要的特征参数[17]。在光谱特征中,植被在洱海流域中所占面积最大,NDVI和EVI是区分植被与非植被的重要参数;洱海流域存在大面积水域,城镇用地主要分布在洱海周围坝区与盆地坝区,MNDWI和NDBI对水域和城镇用地的提取具有重要作用。
1.3.3 土地利用分类算法 选取目前常用的3种机器分类方法——CART、RF和SVM分别进行土地利用分类,选取其中最适合研究区的分类算法。
CART方法是一种决策树学习分类器,其基本原理是从训练数据中构建预测模型,通过递归分割数据空间,拟合每个分区预测模型来预测连续的测试变量和目标变量,获得决策树模型[5]。
RF运用Bootstrap方法进行随机且有放回地从训练集中抽取训练样本[20]。RF需要设置决策树个数和结点特征数2个参数,决策树个数过多会影响模型效率,过少则影响模型精度,因此在兼顾效率和精度的同时,通过试验确定决策树个数为30[3]。
SVM是Vapnik根据统计学习理论提出的一种广义机器学习方法,通过计算出待分离样本之间的最佳分离超平面对样本进行归类[2]。
GEE中样本点的选择是随机的,分别选取60%、70%、80%、90%的样本点作为训练样本并进行分类对比,最终选取约70%的样本作为训练样本,约30%的样本作为验证样本。分类精度采用总体分类精度(OA)、消费者精度(UA)、生产者精度(PA)和Kappa系数进行评价[5]。
2 结果与分析
2.1 整体分类结果对比分析
在GEE中使用CART、RF和SVM对2000、2005、2010、2015年和2020年的洱海流域LULC进行分类,3 种分类算法的精度评价见表3。RF的总体精度和Kappa系数均在90%以上;CART的总体精度在90%,Kappa系数在87%;SVM的总体精度最高为91%,Kappa系数最高为88%。单从总体精度和Kappa系数来看,RF的总体精度和Kappa系数都最高,CART,SVM的总体精度和Kappa系数都最低。同时RF和CART的5期精度评价数值整体起伏变化基本一致,而SVM 5期精度评价数值结果波动较大,总体精度最大相差17%,Kappa系数最大相差22%。

表3 分类精度评价
以2020年为例,3 种分类算法的分类结果及各土地利用类型的评价精度见图2、表4。图2中,CART、RF和SVM均能够很好地对洱海流域的LULC进行分类。其中CART和RF的分类结果一致度更高,而SVM的分类结果和CART、RF有明显差别,尤其是在建设用地的分类中,如大理市区。
图2 2020年CART、RF和SVM土地利用分类结果

表4 2020年3种分类算法下的混淆矩阵
RF算法下的6种土地利用类型的PA和UA整体要好于CART和SVM算法。除了未利用地的PA较低之外,其余土地利用类型的PA和UA均在80%以上,达到良好的分类效果。而通过比较,3种分类方法下的PA和UA均水体最高,林地次之,未利用地的分类精度结果最低。RF算法比CART和SVM算法的结果更准确,更适合于洱海流域的地类划分。
2.2 局部分类结果对比分析
由图3可知,CART解译的结果细节较为突出,如道路能够准确提取。但图斑较破碎,实际准确度不够高,有错分区域,如草地错分成耕地,林地错分成水域;SVM图斑较为连贯、成片,但线状地物不够突出,实际分类结果也不够高,存在错分或少区域,如建设用地比实际缩小或错分成未利用地;相比之下,RF在线状地物提取的准确度不如CART,在图斑连续性不如SVM,但实际分类结果要高于二者,尽管也存在错分地类,如草地错分成耕地。在满足评价精度和实际准确度的基础上,RF在三者当中分类精度最高,同时也可以处理分类上的微小差异。因此,得到了基于RF算法的5期洱海流域LULC分类结果,称为Erhai_RF(图4)。

图4 Erhai_RF算法分类结果
由表5可见,协同使用光谱和地形特征获得了最高解译精度,单独使用地形特征解译精度最低。洱海流域2000、2005、 2010、2015年和2020年最高总体精度分别为93.10%、92.9%、95.0%、93.3%和93.3%,对应Kappa系数分别为91.2%、90.6%、93.4%、91.5%和91.3%,满足分析要求。与单独使用光谱特征和地形特征的分类相比,加入光谱和地形特征后,5期OA平均分别提高了2.7%和20.8%。可见,联合光谱和地形特征后,总体精度得到一定提高。
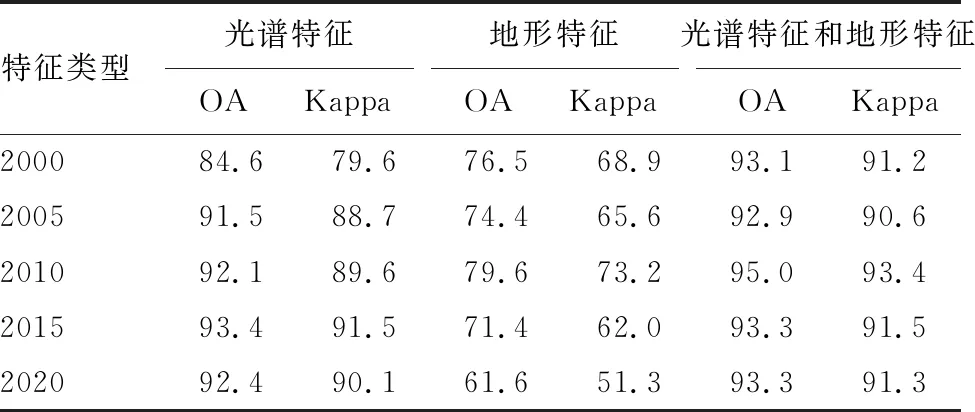
表5 RF不同特征组合的分类精度
2.3 Erhai_RF与Globeland、GLC_FCS对比分析
以2020年为例,选取了海西海水库北部(图5A)、山中道路(图5B)、大理机场(图5C)、典型草地(图5D)和洱海入水口(图5E)与出水口(图5F)共6个区域进行对比分析。图5A海西海水库北部的水体,图5B、5E、5F的道路、桥梁,Globeland和GLC_FCS 解译出部分或者未能完全解译出来,而Erhai_RF能够较完整地解译出水体、道路和桥梁;从图5C来看,Erhai_RF和Globeland均能够解译出机场跑道,但Erhai_RF却将机场附近的草地错分成耕地。GLC_FCS 未能将机场解译出;由图5B、5D看,Erhai_RF和GLC_FCS均能将林地和草地准确解译出,但Erhai_RF也出现将草地错分成耕地。Globeland也能够准确解译出林地但却将部分草地大面积错分成耕地。

A.海西海水库北部;B.山中道路;C.大理机场;D.典型草地;E.洱海入水口;F.洱海出水口
由表6分析可知,Erhai_RF2020的PA和UA几乎全部高于Globeland30和GLC_FCS30,最少也高出3.49%;同时OA和Kappa系数也至少高出Globeland30和GLC_FCS30 7.6%。其中Erhai_RF2020的草地的PA和UA较于Globeland30和GLC_FCS30相差最大,最大为74.04%;未利用地的PA和UA相较于二者相差最小,最小为4.34%。

表6 Erhai_RF2020与Globeland30、GLC_FCS30的精度比较
总之,局部区域解译对比显示,Erhai_RF与Globeland、GLC_FCS 均存在错分区域。但Erhai_RF与Globeland、GLC_FCS较少存在错分,同时在线状地物上如道路提取更加准确。
3 讨论
使用RF、CART和SVM 3种分类算法进行洱海流域的土地覆被解译,均取得良好的分类结果。RF分类算法总体精度最高,CART次之,SVM最差,与Kulithalai等[3]、戴声佩等[2]学者的研究结果一致。3种分类算法在不同地类之间的分类精度各有优缺点。CART在城镇用地细节上更加突出,SVM在草地分类上准确度更高,而RF更适合实际分类准确度和评价精度都较高的地类。主要原因在于3种分类算法的原理不同,其次地形地貌、样本点的质量和数量也是原因之一。在多次分类试验中,使用高分辨率的遥感影像、样本点选取进一步准确、遥感影像进行正射校正消除山体阴影等都会进一步提高解译的精度。经对比分析,3种分类算法当中,RF的实际分类结果、总体精度等都最适合洱海流域,说明RF算法适合高原、山区、平原等地形地貌。同时在大范围内也可使用RF算法[13],适用地形较多。
训练样本点的质量、数量和分布对于分类结果至关重要[13,20]。样本点的数量和研究区的面积、地形、地类复杂度具有相关性。研究区面积越大、地形越复杂、分类地物越多所需样本点数量越多[21]。样本点数量要根据研究区的实际情况确定,样本点过多会影响解译的速度和效率,过少会影响解译的精度[3]。尽管将Google Earth Pro、已有的GLC_FCS产品、各种波段组合的影像联合在一起来选取样本点,但地表“同物异谱”“异物同谱”现象普遍存在,如坡耕地和草地,裸岩石区域和建设用地,从而不可避免地造成遥感图像分类过程中的错分、漏分等现象[21]。
洱海流域属于高原山间盆地,流域面积2 000多km2,属于中小尺度流域,分类只按一级地类。因此对样本点的选取力求随机均匀地分布在整个研究区。经多次试验,样本点选取的数量也只有数百个,和Globeland、GLC_FCS等全球范围内的土地覆被产品选取数千甚至上万的样本点相比,相差巨大。但正是研究区域较小,所以RF分类方法在分类速度、分类精度上能够达到甚至超过Globeland、GLC_FCS,但在地类分类数量上不如二者。一方面是尺度不同,Globeland、GLC_FCS等是面向全球范围的LULC产品,另一方面是面向的使用者不同,需求不同。小范围的研究区更追求分类结果的准确性。结合洱海流域的地形地貌,相关学者[6]提出RF的分类方法精度更高,与本研究结果一致,但仍存在不足之处。遥感影像分辨率可进一步提高,如使用高分辨卫星影像、多源影像融合等方法以达到更好的结果。另外,本次引入的主要特征为光谱及地形特征,在提高分辨率后可加入纹理特征,并使用其他分类方法如面向对象的分类方法进一步提高解译精度。同时今后选取更加准确的训练样本也会提高解译精度。
4 结论
在RF 、CART和SVM分类算法中,RF对洱海流域分类精度最高,均超过90%,其次是CART,在90%左右,SVM最低,在85%左右;在使用相同数据源和训练样本的情况下,RF分类方法能够更准确识别各类地物信息,更适于洱海流域土地利用分类的研究。
洱海流域土地覆被分类与地形地貌、样本点等具有相关性。RF 、CART和SVM算法在洱海流域土地利用分类中均对水体的分类精度较高,对未利用地的分类精度较低。
Erhai_RF与Globeland、GLC_FCS虽在局部分类上存在一定差异,但是在空间布局上保持着较高的一致性,具有较高的分类精度,满足研究需求。
