侵权诉讼背景下标准必要专利价值分类识别体系构建
2024-01-20彭启宁








柳炳祥 付振康 贝汶瑜
摘要:[目的/意义]基于机器学习算法,对行业标准专利构建多模态特征融合的自动分类筛选模型,探究侵权诉讼背景下标准必要专利价值分类指标体系。[方法/过程]首先利用美国专利商标局的发生侵权诉讼后的标准必要专利作为标记数据,将文本数据和指标数据进行降维融合后,建立基于机器学习中监督学习和半监督学习模型专利分类筛选模型,最后对数字创意產业的标准专利进行分类筛选。[结果/结论]基于机器学习中监督学习和半监督学习模型算法构建一套较为完整的多特征融合专利价值自动分类筛选模型。构建的4种模型在测试集上的平均F1值均在0.8以上,其中伪标签随机森林模型表现最优,平均F1值达到0.871 06。
关键词:侵权诉讼;标准专利;机器学习;自然语言处理;分类筛选
分类号:G306
引用格式:彭启宁, 柳炳祥, 付振康, 等. 侵权诉讼背景下标准必要专利价值分类识别体系构建[J/OL]. 知识管理论坛, 2023, 8(6): 461-475[引用日期]. http://www.kmf.ac.cn/p/364/.
专利是反映科技创新成果的主要客体,是知识产权的重要部分之一。近几年,随着经济全球化的不断深入,各国针对行业的标准必要专利研究也在不断加强,拥有行业标准必要专利,意味着能在相关技术领域中占领重要地位。标准必要专利(standard essential patent, SEPs)是指包含在国际标准、国家标准和行业标准中,且在实施标准时必须使用的专利,国内学者马丽婧等[1]指出,利用标准必要专利能够快速掌握行业的技术标准、企业战略和市场竞争等信息。2010年版《国家标准涉及专利的规定》[2]中指出,允许标准中有条件地含有专利。与此同时,随着标准必要专利申请数量的不断增加,专利侵权和专利无效宣告案件发生的数量在不断增长,涉及国际的专利侵权纠纷也在不断增加,《知识产权强国建设纲要(2021-2035年)》[3]提出要深度参与全球知识产权治理,积极参与知识产权全球治理体系改革和建设,要建设知识产权涉外风险防控体系。因此,构建一套完整标准必要专利分类识别体系,识别行业内标准必要重点专利以及易发生侵权诉讼的风险专利,对于提高我国相关创新主体的创新能力以及研判产业发展方向具有重要意义。
笔者以侵权无效宣告专利为切入点,通过整理已经发生侵权专利技术特征,利用数据挖掘模型进行侵权专利识别分类训练,获取最优参数模型,构建标准必要专利侵权识别分类识别体系。笔者在综合分析侵权专利无效宣告的诉讼风险特征影响因素的前提下,结合标准必要专利的特点,选取新兴产业中数字创意产业在新一代信息技术产业中的应用作为研究主题,从专利计量指标和文本特征两个方面建立较为精准的标准必要专利识别分类体系,构建多特征融合的标准必要专利分类识别模型。
1 相关研究综述
1.1 侵权无效宣告相关研究
经阅读文献可以发现,目前国内对侵权专利无效宣告的研究主要集中在以下几个方面:①在专利法视域下,主要针对专利无效宣告制度的特点进行一系列讨论。李晓鸣[4]认为,相关法律法规对专利无效宣告各类程序的期限规定不完善并提出一系列完善建议;王瑞龙[5]指出了侵权诉讼中专利权无效抗辩制度弊端,认为专利无效抗辩制度导致专利侵权诉讼周期长并提出了解决方式。然而,上述文献主要涉及无效宣告判别的各类程序,未涉及导致无效宣告发生的指标研究。②在创新经济学视野下,主要针对专利无效宣告对市场份额影响进行一系列研究。S. Alessandro[6]认为,专利无效宣告倾向与专利市场份额增长率呈正相关,专利的市场份额越高,专利发生无效宣告的可能性越大;但上述文献主要探讨了专利无效宣告与市场价值的关系,未涉及各类指标对无效宣告结果的影响。③在情报学视野下,在竞争情报学中将申请宣告竞争对手的专利无效视作是一种重要的专利战略手段。李睿等[7]指出,在技术市场权益的争夺中,优质专利通常是竞争对手申请无效宣告的主要目标;周克放[8]指出专利异议通常由竞争对手提出,能够成功抵御异议的专利往往可以被定义为该领域价值相对较高的专利。此外,专利无效宣告倾向在不同技术领域所表现的程度不尽相同,J. R. Allison等[9]指出专利无效宣告行为的经济属性暗示了其为市场价值的低质量专利。与此同时,P. A. Patel等[10]发现专利异议率在不同的领域所占比例不同,其中在电气工程领域的异议率在5.3%至9.7%左右;但上述文献并未涉及从侵权专利无效宣告的角度对专利的价值进行分类预测。
通过以上文献可以看出,学术界对于侵权专利无效宣告识别分类可以得出以下结论:在侵权案件发生后,依旧被判定为“有效”的专利可视为该行业的重点且质量较高专利,与之相反,被判定为“无效”的专利可视为该行业市场中存在较大竞争争议的专利。因此,笔者主要从侵权专利无效宣告出发,提出对此两种类型的专利进行分类模型的构建,进而实现对两种类型专利的自动分类筛选。
1.2 标准必要专利相关研究
经阅读文献可以发现,国内外对于标准必要专利的定义主要涉及两个方面:①标准必要专利涉及的技术市场垄断研究。王晓晔[11]探讨了标准必要专利涉及的反垄断诉讼问题,认为FRAND(Fair, Reasonable and Non-Discriminatory)许可条件没有可操作性,以至于越来越多的涉及标准必要专利的案件进入了反垄断执法机构和法院;R. Bekkers等[12]认为标准必要专利所披露的信息存在大量的信息不对称;李宗辉[13]指出标准必要专利在通信技术领域较为集中,相关的国际平行诉讼体现在各国技术、产业和市场竞争的司法层面,以及J. L. Contrera[14]也同样指出标准必要专利涉及的技术垄断在5G无线通信标准的背景下尤为突出。此外,在标准必要专利的市场价值研究上,叶若思等[15]认为一个必要标准专利具有唯一性和不可替代性,标准必要专利权人在必要专利许可市场均拥有完全的份额,具有阻碍或影响其他经营者进入相关市场的能力;M. V. Laer等[16]指出标准必要专利在国内保持了较高的增值份额,加入全球价值链需要吸收能力,但中国进入SEPs市场较晚,SEPs对中国的贸易效应不同于对成熟经济体的贸易效应,其SEPs的初始值较低。②标准必要专利的特征识别研究。马丽婧等[1]指出潜在标准必要专利在引用次数、被引用次数、权利要求数量、审查时长、同族成员个数等计量指标上显著高于普通专利;李婳婧等[17]基于TF-DIF方法进行权重计算,优化标准关键词并建立检索式,建立隐含在标准里面的潜在标准必要专利信息识别路径。
通过以上文献可以看出,学术界对于标准必要专利的研究主要集中在标准必要专利的市场价值或是其特征研究上,鲜有文献通过专利侵权的角度对标准必要专利中的价值较高专利、易发生侵权诉讼专利两者相结合同时进行分类筛选的研究。
1.3 专利识别模型相关研究
随着学科融合的进一步发展,现今针对专利的各种特征的识别模型各不相同。对于专利识别的研究主要集中在两个角度,具体如下:
一是利用傳统的数学统计分析方法进行研究。孙玉艳等[18]利用市场法、成本法、收益法和修正收益法对专利价值进行线性组合和非线性组合预测,得到加权算数平均值组合预测和加权调和平均组合预测两种评估模型;徐晨倩等[19]采用量化研究与案例研究相结合的方法,构建了诉讼专利特征与337调查的回归模型,并将模型运用至其他专利侵权诉讼案件中,从而达到专利情报预警的目的;王子焉等[20]利用文献计量、社会网络分析方法从专利价值的内涵、评估指标体系、评估方法3个方面对专利价值进行评估。
二是利用数据挖掘方法(如深度学习、机器学习等)对专利各类特征进行识别。张杰等[21]采用AdaBoost算法对诉讼专利的专利质量进行评价;李静等[22]采用深度学习算法模型对新兴主题进行分析,从而了解新兴主题发展趋势;翟东升等[23]利用SAO结构对专利语义特征进行抽取,并将其表示为图的形式,再将图转换为邻接矩阵,通过计算邻接矩阵的相似性进而达到判定专利侵权的目的;国外学者J. Jee 等[24]利用人工神经网络方法对制药技术领域专利进行分类,达到识别高质量专利的目的;I. S. Kang等[15]提出建立聚类模型来对侵权专利进行检索,从而建立侵权专利的特征模型,但上述研究均未涉及利用专利特征指标构建风险识别体系。K.V. Indukuri等[25]利用自然语言处理技术通过句法和语义匹配计算不同专利权利要求项之间的相似性,得出专利之间的相似性。
通过总结上述文献的研究方法可以看出,学术界目前的研究主要利用统计学模型,将单个或多个模型结合进行单一类型数据的分类或预测,但对于专利质量与专利风险结合分析研究较为欠缺。因此,笔者在基于传统侵权专利的分析研究下,从侵权专利无效宣告的特征角度出发,结合美国专利商标局(United States Patent and Trademark Office, USPTO)中必要标准专利的特征,采用多特征融合的方法,对文旅行业的必要标准专利进行分类识别,以筛选出文旅行业内高质量专利以及易发生侵权诉讼风险专利。
2 特征选取与研究设计
2.1 研究思路
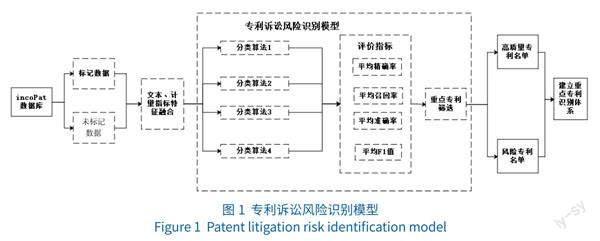
图 1为专利风险识别模型。首先,通过阅读国内外的大量研究文献,对标准专利的概念进行界定,结合指标的可获取性、科学性等因素,选取标准专利的文本内容和数据指标;通过文献检索的方法,获取美国专利商标局(USPTO)[26]标准专利中发生侵权诉讼后被判定为“有效”或“无效”的标准专利作为标记数据和选定待预测的未标记数据集。其次,对文本数据和指标数据进行降维数据融合,形成新指标特征。最后,选取机器学习的监督学习中K近邻、朴素贝叶斯模型和半监督学习算法中半监督向量机、伪标签随机森林等模型,对未标记数据进行专利的分类预测筛选,其中被判定为“有效”的专利即为行业标准专利内的重点具有核心价值的专利,被判定为“无效”的专利即为行业标准内极易发生侵权诉讼的专利。最终,通过从专利侵权无效宣告的角度出发,达到对不同领域标准必要专利中的潜在重点专利识别的最优选算法指标选取目的,进而建立较为精准的潜在重点专利自动筛选体系。
2.2 指标选取
2.2.1 语义特征提取
学术界对于专利文本的选取各不相同,但主要包含专利摘要、专利权利要求书和专利说明书。笔者选取专利摘要进行语义特征提取,专利摘要是对专利说明书内容的概述,主要包括发明或实用新型专利的名称、专利所属的技术领域和需要解决的技术问题、发明或实用新型涉及的主要技术特征和用途。在专利摘要研究方面,缪建明等[27]在专利摘要的基础上,采用类中心向量分类算法对专利进行快速自动分类;吴洁等[28]利用专利摘要生成专利的核心词汇网络,搭建基于图卷积网络的高质量专利自动识别模型;周群芳等[29]利用摘要对中文专利的新技术术语进行识别。
因此,在语义识别方面,笔者利用自然语言识别中Word2vec模型对文本内容进行词语向量化处理,主要涉及两种模型:CBOW模型和Skip-gram模型(见图2)。笔者主要采用CBOW模型,具体训练方法为:输入层由one-hot编码的输入文本组成,隐藏层是n维的向量,最后输出层是由one-hot编码的输出文本向量。
2.2.2 计量指标选取
学术界对于专利的各类特性的评估指标选取方式也各不相同,冯君[30]从专利技术质量、专利权保护质量、产业高度和社会经济效益4个方面对单件专利质量进行评价;刘亚杰等[31]从法律风险、技术风险、组织管理风险、合作因素风险、环境因素风险5个方面构建高校专利运营风险评估指标体系。因此,笔者结合国内对专利质量评价和专利风险评估两方面的研究选取重点专利筛选指标,主要从技术层面、法律层面和市场层面3个维度选取构建专利筛选模型指标。
在技术层面,笔者主要选取8个计量指标,首先是专利技术方面,涉及单件利的“技术先进性”“技术稳定性”和“IPC个数”,此类指标主要体现了专利的技术覆盖范围,J. Lerner 等[32]提出用专利文件中的IPC(国际专利分类号)小类的数量来衡量专利覆盖的技术范围;其次是专利引证方面,主要涉及单件专利的“引证次数”“家族引证次数”,张娴等[33]指出根据专利的引证关系可以看出专利之间的累积与继承关系;最后是专利的被引证方面,主要涉及单件专利的“被引证次数”和“家族被引证次数”,李春燕等[34]指出如果专利的被引用次数越多,则该专利越能代表该领域的基础技术,可以反映出该专利的技术先进性。在法律层面,笔者主要选取“权利要求数量”“保护范围”“转让次数”和“首权字数”,主要涉及专利权法律效力所涉及的发明创造的范围,郭青等[35]认为权利要求数量越多,专利的保护范围越广;“保护范围”主要涉及专利权法律效力所涉及的发明创造的范围,“转让次数”反映专利的交易次数,刘强[36]认为重大技术的专利转让会给企业带来大额的经济效益,极易发生转让合同生效与解除、合同权利与义务等法律问题;“首权字数”反映专利保护的技术特征数量。在市场层面,笔者主要选取“简单同族个数”“扩展同族个数”和“DocDB同族个数”,杨秀财[37]认为同族专利数量可以反映专利家族学术影响力。重点专利筛选指标如表1所示:
2.3 研究方法
2.3.1 模型选取
(1)模型降维融合。在模型文本特征和计量指标数据降维融合方面,笔者选取目前较为常用的降维方法——PCA主成分分析法(principal component analysis),它是一种非监督的机器学习算法。一般使用方差(variance)来定义样本之间的间距,公式如下:
(2)训练模型选取。在数据模型建立方面,笔者选取机器学习中分类模型,主要涉及监督和半监督学习中以下几种模型:一方面是半监督学习中半监督向量机(transductive support vector machine, TSVM),TSVM是支持向量机在半监督学习上的推广,穿过数据低密度区域的划分超平面将两类有标记样本分开;其次是利用伪标签(pseudo-labelling)算法和集成学习中随机森林(random forest)算法结合,利用随机森林训练标记数据建立模型,再利用该模型为未标记数据集生成伪标签,将原始标签和伪标签的数据集组合在一起进行最终分类模型训练。另一方面是监督学习K近邻(K-Nearest Neighbor,KNN),KNN是将已知类别的样本作为参照,计算未标记数据集与标记数据集的距离,将未标记数据与K个最邻近标记数据集中所属类别占比较多的归为一类;朴素贝叶斯算法(Naïve Bayesian)根据贝叶斯公式来对未标记进行分类,把未标记数据判别为概率最大的一类。
2.3.2 模型评估
笔者采用多模态模型最终完成的任务是专利无效宣告的二分类问题,故采用准确率(accuracy)、平均精确率(precision)、平均召回率(recall)、平均F1值(F1)以及ROC曲线下方的面积(area under ROC the curve)5个指标对模型的性能进行评价。对于二分类问题,将样例数据根据机器学习的预测类别与实际类别相结合分为真正例(true positive)、假正例(false positive)、真反例(true negative)、假反例(false negative)4种情况。
准确率是指模型分类正确的专利样本数量与所有的专利样本数量的比值,其计算公式如下:
精确率是指检测出某类特征的数量与检测出的所有特征数量之间的比率,衡量的是模型的查准率,其计算公式下:
平均召回率是指检测出的某类特征的数量和数据集中所有的该类特征数量的比率,衡量的是检索系统的查全率,其计算公式如下:
F1是基于查準率与查全率的调和平均(harmonic mean)定义的,一般情况下,当F1较高时则说明试验方法比较有效,其计算公式如下:
AUC(Area Under Curve)可通过ROC曲线下各部分的面积求和而得,假定ROC曲线(receiver operating characteristic)是由坐标为{(x1, y1), (x2, y2)……(xm, ym)}特征值组成,ROC曲线的y代表“真正准确率”(true positive rate),x代表“假正例率”(false positive rate),其计算公式如下:
3 实证分析
3.1 数据来源与数据处理
《“十四五”文化和旅游科技创新规划》[38]中指出开展信息技术在文化和旅游领域应用示范,推动行业开发信息技术应用新场景。因此,笔者选取新兴产业中数字创意产业在新一代信息技术产业中的应用作为研究主题,利用机器学习中分类模型,对该主题必要标准专利中的潜在高质量专利和易发生侵权诉讼的专利进行分类识别。模型主要涉及以下两个方面:首先是标记数据库,笔者选用美国专利商标局(USPTO)[27]标准专利中侵权专利数据库作为标记数据,该数据为USPTO官方网站公布的1963—2016年在美国联邦地区法院提起的专利诉讼数据集,王春博等[39]认为通过分析美国专利诉讼的发生原因,能为中国企业提前降低专利诉讼风险提供一定的参考;其次是未标记数据,笔者选取欧洲电信标准化协会(European Telecommunications Standards Institute)和国际电信联盟(International Telecommunication Union)标准专利数据库中该主题的国内标准必要专利,构建检索式为:INDUSTRY1=(8 AND 1) AND STD-TYPE=(ETSI OR ITU),其中,INDUSTRY为战略性新兴产业类型(1:新一代信息技术;8:数字创意产业),STD-TYPE为标准必要专利类型。综上所述,标记数据为422件,未标记数据1 972件专利。
3.2 分类模型构建
3.2.1 特征转化融合
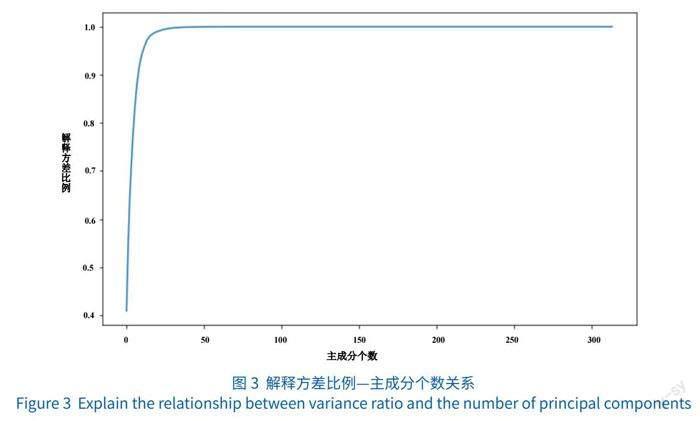
首先,利用2.2.1节所述的文本向量模型对专利摘要进行词向量处理,将专利摘要转化为一个300维的特征向量用以表征专利文本特征;其次,再将文本向量和数据指标横向拼接后得到特征矩阵,再利用PCA成分分析法对特征向量矩阵进行降维处理,利用PCA算法对所构建的特征矩阵进行融合重组,得出解释方差比例和主成分个数之间的关系。如图3所示,当主成分个数在50左右时,解释方差的比例开始趋近于稳定。因此,在模型构建时,将主成分个数设定为50进行特征合并。
3.2.2 分类模型
首先,使用Word2vec对专利摘要进行文本词向量化转换,再利用PCA主成分分析法对数据进行数据融合,将融合后的数据分别建立半监督向量机、K近邻、朴素贝叶斯算法、伪标签随机森林4种机器学习模型,利用“留出法”(hold out)按照8:2的比例,将数据划分为训练集和测试集。在训练集上进行单独训练,其中KNN模型利用交叉验证绘制错误率走势图,如图4所示,当neighbors为8左右时,整体模型错误率最低,仅为0.17左右。
其余模型均采用交叉验证结合网格搜索以及学习曲线的方式寻找最优超参数组合,各个分类器的参数组合见表2。由表2可以看出,集成学习的模型参数划分相比较于单个学习模型划分要更加细致,这主要是由于集成模型会对原始数据进行有放回的随机采样,所以在模型的参数划分上更加细致。
3.3.1 特征重要程度评估
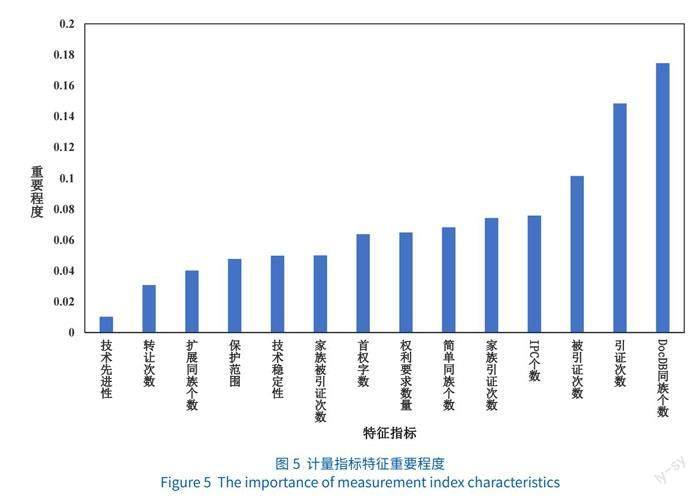
图5为训练集模型指标的特征重要程度。在训练模型构建完成后,由于不同特征对于模型的影响程度不同,为了防止个别指标重要性较高,影响模型其他指标效果,则需要对所选取特征的信息熵进行分别计算,选取最优指标。笔者将训练集数据进行特征重要程度可视化,由图5可以看出,首先是特征重要程度排名前三的指标,排在第一位的是“11DocDB同族个数”,对于模型分类结果的重要程度最高,重要程度为0.16左右;排在第二位的是“3引证次数”,重要程度为0.15左右;排在第三位的是“4被引证次数”,重要程度为0.10左右。其次,“6技术先进性”重要程度在14项指标中排名最低,仅为0.02左右。最后,其余指标的重要程度均在0.05左右。
根据特征的重要程度可以看出,所选取的14项指标的特征重要程度分布相对较为均衡,不存在个别指标主导整体模型情况。因此,所构建模型选取的14项指标均可放入多特征融合的必要标准专利分类当中。
3.3.2 参数评估
为了评估笔者构建的机器学习模型的性能,采用2.2.3节所述的评估指标,对半监督向量机、K近邻、朴素贝叶斯算法、伪标签随机森林4个模型在测试集上的Accuracy(准确率)、Precision(精准率)、Recall(召回率)、F1-score(F1分数)以及AUC(可分离测度)在测试集上的表现进行评分对比。如表3所示,从表中可以看出,在测试集中,Random Forest的Accuracy、Precision、Recall、F1以及AUC的评分是所有模型当中最高的,其评分均在0.85以上。由此可见,笔者构建的数据在伪标签随机森林集成模型上的表现相较于其他单个模型表现较优,将计量指标和文本特征进行融合后,对标准专利识别分类模型所涉及的内容更加全面,对于专利的分类识别也就更加准确。另外,本文数据主要来源于美国USPTO中标准专利侵权案件,根据上述5种模型的运行和评估情况,均可以将模型运用在不同领域的专利不同类别的识别。
3.4 专利分类筛选
模型构建完成后,再将“未标记”数据集放入模型进行无效宣告预测,结果为341件专利被预测为“有效”,即为行业内重点必要标准专利;1 631件专利被预测为“无效”专利,即为行业内极易发生侵权诉讼专利。表4为未标记数据特征平均值,表5为模型预测结果为“有效”的专利清单,表6为模型预测结果为“无效”的专利清单(仅展示部分数据)。
根据表4可以看出,其中被预测为“有效”的高质量专利的主要计量指标特征的取值分别为:平均被引证次数为0.243左右、平均首权字数为258、平均技术先进性为9.65、平均技术稳定性为8.95、平均同族个数为17.77、权利要求数量为24.29;而被预测为“无效”的极易发生侵权诉讼的主要计量指标特征的取值分别为:平均被引证次数0.91、平均首权字数为288、平均技术先进性为9.21、平均技术稳定性为8.76、平均同族个数为19.21、权利要求数量为19.42。由此可以看出,两者的相差主要集中在被引次数、首权字数和权利要求数量,其余指标的相差较小。因此,企业应多注重自身被引次数较高、首权字数较多的专利,该类专利易发生侵权诉讼风险。
根据表5所预测结果为“有效”的专利主题可以看出,近5年,在文化和旅游科技创新领域的高质量重点标准专利主要集中在涉及网络安全监视、网络密钥、信息处理等技术主题中。同时,根据表6所预测结果为“无效”的专利主题可以看出,近5年,在文化和旅游科技创新领域的标准专利在移动通信系统、信息终端接入、移动数据处理等技术主题中极易存在诉讼竞争的风险。结合崔维军[40]所指出的5G标准必要专利分布特征主要集中在内部固定网络、LTE和无线电技术等领域。因此,行业内企业在后续专利研发、布局中可以参考标准必要重点专利清单,同时根据诉讼风险清单尽可能规避该类技术主题存在的诉讼风险。
4 研究发现与结果讨论
4.1 研究发现
笔者首先根据前人对于专利无效宣告和必要标准专利的相关研究,提出了从专利侵权无效宣告视角出发,基于多模态融合的专利分类方法;其次,利用Word2vec对文本进行数据转换,再采用集成学习模型和机器学习中二分类模型,对专利无效宣告倾向进行分类,进行模型对比验证;最后,在数据库的选取上,将美国标准专利数据库和国内新兴产业标准专利相结合,对模型进行实验分析,验证笔者构建的专利分类模型的有效性及准确性。通过实证分析得出如下結论:
(1)模型构建方面。在对文本和数据的处理上,由于数据向量形成较多,则需要对融合向量进行数据合并和数据降维处理,可选用主成分分析法对向量进行降维。与此同时,在模型分化时,为了防止模型的过拟合,含有过多的不必要信息,需要计算模型的最佳节点和最
佳分化方法,可利用交叉验证方法绘制错误率、网格搜索法以及绘制学习曲线的方式来获取所选取模型的各类最优参数。另外,根据模型的评估结果可以看出,伪标签和随机森林相结合模型效果较好,准确率为0.86左右,F1为0.85左右。在模型构建后,为了防止个别指标出现主导整体预测结果的现象出现,需要对所选取的特征指标进行特征重要程度的分析。根据特征重要程度排序可以看出,集成学习模型的整体表现要优于单个模型的训练。
(2)识别结论。通过构建模型识别可以看出,文化和旅游科技创新领域的高质量重点标准专利主要集中在涉及网络安全监视、网络密钥、信息处理等技术主题,在移动通信系统、信息终端接入、移动数据处理等技术主题中极易存在诉讼竞争的风险,为后续国内文旅企业专利布局提供一定的参考。并且根据模型的整体呈现效果,建立一套较为完整的专利分类筛选体系,可以应用于多个领域,快速定位行业内的重点专利的同时,达到很好的专利预警效果。
4.2 结果讨论
笔者主要以美国专利商标局(USPTO)披露的各行业必要标准专利为参考标准,选取当中发生的侵权专利,对国内新兴产业行业内专利进行重点专利和易发生诉讼专利进行分类筛选,同时实现两种不同类型专利的分类筛选。综上所述,笔者构建的必要标准专利预测模型以及专利无效宣告的预警体系对我国专利的研究具有一定的参考性以及现实意义,可以为企业以及其他创新主体对于自身专利的情况提供一定的判断依据,为保护自身专利的稳定性提供相应的数据支持。
但是,笔者构建的预测模型和预警体系也存在一定的局限性:①在数据识别指标的选取上,主要选取部分定量指标进行模型构建,并未充分考虑其他外部因素指标对于侵权无效宣告预测的影响,识别预测指标体系也需进一步完善。并且选取数据二分类较为均衡,且本文数据模型是对已经涉及侵权案例中最终有效或无效进行判定,并未充分考虑是否侵权判定。②在文本类别的识别上,笔者主要选取摘要作为本文数据,并未涉及专利的说明书和权利要求书,对于专利文本的提取不够全面。③在模型的选取上,笔者仅采用机器学习中伪标签、支持向量机、K近邻、朴素贝叶斯以及集成学习中随机森林对专利进行分类筛选的构建,模型选择较为单一,并未尝试利用数据挖掘中其他模型对专利进行分类预测的构建。因此,在后续的研究过程中,笔者将根据以上三点进行更加深入的研究,不断完善专利预警预测模型,进而构建更加精准的专利无效宣告的预警体系,进一步改进模型,使分析结果更为准确。
参考文献:
[1] 马丽婧, 刘婷, 赵亚娟, 等. 潜在标准必要专利特征研究[J]. 中国发明与专利, 2021, 18(7): 3-12. (MA L J, LIU T, ZHAO Y J, et al. Research on the characteristics of potential standard essential patents[J]. CHINA invention & patent, 2021, 18(7): 3-12.)
[2] 孙茂宇, 苏志国, 毛琎. 标准涉及专利问题研究[C]//专利法研究(2013). 北京: 知识产权出版社, 2015: 263-273. (SUN M Y, SU Z G, MAO J. Standards research on patent issues [C]//Patent Law Research (2013). Beijing: Intellectual Property Publishing House, 2015: 263-273.)
[3] 知识产权强国建设纲要(2021—2035年)[J]. 知识产权, 2021(10): 3-9. (Outline for building a strong intellectual property country (2021—2035)[J]. Intellectual property, 2021(10): 3-9.)
[4] 李晓鸣. 我国专利无效宣告制度的不足及其完善[J]. 法律科学(西北政法大学学报), 2021, 39(1): 149-159. (LI X M. The deficiency and perfection of patent invalidation system in China [J]. Science of law (Journal of Northwest University of Political Science and Law), 2021, 39(1): 149-159.)
[5] 王瑞龙. 侵权诉讼中专利权无效抗辩制度弊端及解决路径[J]. 中南民族大学学报(人文社会科学版), 2018, 38(2): 126-131. (WANG R L. The drawbacks and solutions of the patent invalidation defense system in infringement litigation [J]. Journal of South-Central Minzu University (humanities and social sciences edition), 2018, 38 (2): 126-131.)
[6] STERLACCHINI A. Trends and determinants of energy innovations: patents, environmental policies and oil prices[J]. Journal of economic policy reform, 2020, 23(1): 49-66.
[7] 李睿, 徐璇. 宣告無效专利的引文特征及其情报学意义[J]. 情报理论与实践, 2019, 42(2): 25-30. (LI R, XU X. Citation characteristics and information science significance of invalid patents [J]. I Information studies: theory & application, 2019, 42(2): 25-30.)
[8] 周克放, 乔永忠. 基于无效程序的ICT领域专利质量影响因素研究[J]. 科研管理, 2021, 42(10): 148-155. (ZHOU K F, QIAO Y Z. Research on the influencing factors of patent quality in ICT field based on invalid procedures [J]. Scientific research management, 2021, 42(10): 148-155.)
[9] RAI A K, ALLISON J R, SAMPAT B N. University software ownership and litigation: a first examination[J]. North Carolina law review, 2009, 87(5): 1519.
[10] PATEL P A, HALL A, AUGOUSTIDES J G T, et al. Dynamic shunting across a patent foramen ovale in adult cardiac surgery—perioperative challenges and management[J]. Journal of cardiothoracic and vascular anesthesia, 2018, 32(1): 542-549.
[11] 王晓晔. 标准必要专利反垄断诉讼问题研究[J]. 中国法学, 2015(6): 217-238. (WANG X Y. Research on antitrust litigation of standard essential patents [J]. China legal science, 2015(6): 217-238.)
[12] BEKKERS R, MARTINELLI A, TAMAGNI F. The impact of including standards-related documentation in patent prior art: Evidence from an EPO policy change[J]. Research policy, 2020, 49(7): 104007.
[13] 李宗辉. 标准必要专利跨国诉讼中禁诉令的适用标准研究[J]. 法商研究, 2022, 39(4): 187-200. (LI ZH. Research on the applicable standards of injunction in transnational litigation of standard essential patents[J]. Legal quotient research, 2022, 39(4): 187-200.)
[14] CONTRERAS J L. Patents on 5G standards are not matters of national security[J]. IIC-International review of intellectual property and competition law, 2022, 53(6): 849-852.
[15] KANG I S, NA S H, KIM J, et al. Cluster-based patent retrieval[J]. Information processing & management, 2007, 43(5): 1173-1182.
[16] LAER M V, BLIND K, RAMEL F. Standard essential patents and global ICT value chains with a focus on the catching-up of China[J]. Telecommunications policy, 2022, 46(2): 102110.
[17] 李婳婧, 谢秋琪, 李闻宇. 潜在标准必要专利信息识别路径研究——以5G标准为例[J]. 中国标准化, 2022(15): 81-87. (LI H J, XIE Q Q, LI W Y. Research on the identification path of potential standard essential patent information-taking 5G standard as an example[J]. China standardization, 2022(15): 81-87.)
[18] 孫玉艳, 张文德. 基于组合预测模型的专利价值评估研究[J]. 情报探索, 2010(6): 73-76. (SUN Y Y, ZHANG W D. Research on patent value evaluation based on combined forecasting model[J]. Information research, 2010(6): 73-76.)
[19] 徐晨倩, 朱雪忠. 基于诉讼专利情报的美国337调查风险预警研究[J]. 情报杂志, 2021, 40(9): 37-44. (XU CQ, ZHU XZ. Research on risk early warning of US 337 investigation based on litigation patent information[J]. Journal of intelligence, 2021, 40(9): 37-44.)
[20] 王子焉, 刘文涛, 倪渊, 等. 专利价值评估研究综述[J]. 科技管理研究, 2019, 39(16): 181-190. (WANG Z Y, LIU W T, NI Y, et al. Review of patent value evaluation research[J]. Science and technology management research, 2019, 39(16): 181-190.)
[21] 张杰, 孙超, 翟东升, 等. 基于诉讼专利的专利质量评价方法研究[J]. 科研管理, 2018, 39(5): 138-146. (ZHANG J, SUN C, ZHAI D S, et al. Research on patent quality evaluation method based on litigation patents[J]. Scientific research management, 2018, 39(5): 138-146.)
[22] 李靜, 徐路路. 基于机器学习算法的研究热点趋势预测模型对比与分析——BP神经网络、支持向量机与LSTM模型[J]. 现代情报, 2019, 39(4): 23-33. (LI J, XU LR. Comparison and analysis of research hotspot trend prediction models based on machine learning algorithms-BP neural network, support vector machine and LSTM model [J]. Journal of modern information, 2019, 39(4): 23-33.)
[23] 张杰, 孙超, 翟东升, 等. 基于诉讼专利的专利质量评价方法研究[J]. 科研管理, 2018, 39(5): 138-146. (ZHANG J, SUN C, ZHAI D S, et al. Research on patent quality evaluation method based on litigation patents[J]. Scientific research management, 2018, 39(5): 138-146.)
[24] JEE J, SHIN H, KIM C, et al. Six different approaches to defining and identifying promising technology through patent analysis[J]. Technology analysis & strategic management, 2022, 34(8): 961-973.
[25] INDUKURI K V, AMBEKAR A A, SUREKA A. Similarity analysis of patent claims using natural language processing techniques[C]//International conference on computational intelligence and multimedia applications (ICCIMA 2007). Piscataway: IEEE, 2007: 169-175.
[26] Patent litigation data from US district court electronic records (1963-2015)[EB/OL]. [2023-09-20]. https://www. uspto.gov/.
[27] 缪建明, 贾广威, 张运良. 基于摘要文本的专利快速自动分类方法[J]. 情报理论与实践, 2016, 39(8): 103-105, 91. (MIAO J M, JIA G W, ZHANG Y L. Rapid automatic classification of patents based on abstract text[J]. Information studies: theory & application, 2016, 39(8): 103-105, 91.)
[28] 吴洁, 桂亮, 刘鹏, 等. 多维特征视角下基于图卷积网络的专利技术领域自动识别研究[J]. 中国管理科学, 2023, 30(12): 185-197. (WU J, GUI L, LIU P, et al. Research on automatic identification of patent technology field based on graph convolutional network from the perspective of multi-dimensional features[J]. Chinese journal of management science, 2023, 30(12): 185-197.)
[29] 周群芳, 吴婕, 谷俊. 基于本体的专利语义检索研究[J]. 情报探索, 2013(9): 71-74. (ZHOU Q F, WU J, GU J. Research on ontology-based patent semantic retrieval[J]. Information research, 2013(9): 71-74.)
[30] 冯君. 基于专利信息分析的高校科技创新能力评价指标体系初探[J]. 科技情报开发与经济, 2010, 20(10): 193-194, 204. (FENG J. Evaluation index system of university science and technology innovation ability based on patent information analysis[J]. Sci-tech information development & economy 2010, 20(10): 193-194, 204.)
[31] 刘亚杰, 陈朝晖, 谢薇. 高校专利运营风险指标体系构建研究[J]. 中国发明与专利, 2018, 15(1): 20-24. (LIU Y J, CHEN Z H, XIE W. Research on the construction of patent operation risk index system in universities [J]. China invention and patent, 2018, 15(1): 20-24.)
[32] LERNER J, SERU A. The use and misuse of patent data: Issues for finance and beyond[J]. The review of financial studies, 2022, 35(6): 2667-2704.
[33] 張娴, 田鹏伟, 茹丽洁, 等. 专利前向引用遵循Logistic扩散模型再验证[J]. 知识管理论坛, 2017, 2(2): 110-119. (ZHANG X, TIAN P W, RU L J, et al. Patent forward citations follow the Logistic diffusion model for re-verification [J]. Knowledge management forum, 2017, 2(2): 110-119.)
[34] 李春燕, 石荣. 专利质量指标评价探索[J]. 现代情报, 2008(2): 146-149. (LI C Y, SHI R. Evaluation of patent quality indicators [J]. Modern intelligence, 2008(2): 146-149.)
[35] 郭青, 戚湧, 高盼军. 基于技术、法律和经济三位一体的专利质量评价及应用研究[J]. 中国发明与专利, 2021, 18(1): 21-29. (GUO Q, QI Y, GAO P J. Research on patent quality evaluation and application based on the trinity of technology, law and economy[J]. China invention & patent, 2021, 18(1): 21-29.)
[36] 刘强. 专利开放许可费认定问题研究[J]. 知识产权, 2021(7): 3-23. (LIU Q. Research on the determination of patent open license fee [J]. Intellectual property, 2021(7): 3-23.)
[37] 杨秀财, 林波, 王园. 专利家族学术影响力的影响因素研究[J]. 科技与经济, 2020, 33(3): 46-50. (YANG X C, LIN B, WANG Y. Research on the influencing factors of the academic influence of patent family [J]. Science & technology and economy, 2020, 33(3): 46-50.)
[38] 文化和旅游部发布《“十四五”文化和旅游发展规划》[J]. 中国会展(中国会议), 2021(12): 26-29. (The Ministry of Culture and Tourism issued the “14th Five-Year Plan for Cultural and Tourism Development” [J]. China convention and exhibition (China conference), 2021(12): 26-29.)
[39] 王春博, 王宇开, 杜伟, 等. 基于美国专利数据的涉诉专利申请特征研究[J]. 情报杂志, 2022, 41(12): 64-70, 15. (WANG C B, WANG Y K, DU W, et al. Research on the characteristics of patent applications involving litigation based on US patent data [J]. Intelligence journal, 2022, 41(12): 64-70, 15.)
[40] 崔维军, 李璐, 韩硕, 等. 5G标准必要专利分布特征: 国际比较研究[J]. 科技管理研究, 2022, 42(5): 162-169. (CUI W J, LI L, HAN S, et al. Distribution characteristics of 5G standard essential patents: international comparative study [J]. Science and technology management research, 2022, 42(5): 162-169.)
作者贡献说明:
彭启宁:数据分析与论文撰写;
柳炳祥:数据分析与论文指导;
付振康:数据收集与整理;
贝汶瑜:数据收集与整理。
Construction of Standard Essential Patent Value Classification Recognition System Under the Background of Infringement Litigation
Peng Qining1 Liu Bingxiang1,2 Fu Zhenkang3 Bei Wenyu1
1Intellectual Property Information Service Center, Jingdezhen Ceramic University, Jingdezhen 333001
2School of Information Engineering, Jingdezhen Ceramic University, Jingdezhen 333403
3School of Information Management, Nanjing University, Nanjing 210008
Abstract: [Purpose/Significance] Based on machine learning algorithm, an automatic classification and screening model based on multi-modal feature fusion is constructed for industry standard patents. The research also explores a classification indicator system for the value of standard-essential patents in the context of infringement litigation. [Method/Process] First, standard necessary patents after infringement litigation in USPTO are used as marker data. Then, the text data and indicator data are integrated with dimensionality reduction, and the patent classification and screening model based on supervised and semi-supervised learning machine model is established. Finally, the standard patents of digital creative industry are classified and screened. [Result/Conclusion] The average F1 value of the four models constructed in this paper is above 0.8 on the test set, among which the pseudo-labeled random forest model has the best performance and the average F1 value reaches 0.871 06.
Keywords: patent infringement litigation standard patent machine learning natural language processing classification screening
基金項目:本文系2022年度文化和旅游部提质培优计划专业研究生重点扶持项目(MLIS类)“中小型文化创意企业知识产权创造能力影响因素研究——以景德镇陶瓷文创企业为例”(项目编号:Mlis-003)和江西省研究生创新基金项目“江西省新材料产业核心专利识别研究”(项目编号:JYC202207)研究成果之一。
作者简介:彭启宁,硕士研究生;柳炳祥,教授,博士,通信作者,E-mail: 1093624070@qq.com;付振康,博士研究生;贝汶瑜,硕士研究生。
收稿日期:2023-05-08 发表日期:2023-11-20 本文责任编辑:刘远颖
