基于图像分类网络的非侵入式负荷辨识算法的运算成本优化
2024-01-19杨舒惠黎静华韦善阳
杨舒惠,黎静华,韦善阳
(广西大学 广西电力系统最优化与节能技术重点实验室,广西 南宁 530004)
0 引言
近年来,数字电网技术在电网低碳转型中的作用日益显现,其中,传感量测是基础和重要的环节之一[1-2]。非侵入式负荷监测(non-intrusive load monitoring,NILM)是一种微型化的传感量测方法,从原理上概述,NILM 包括分解和辨识2 个步骤,分解是指从区域总电压、电流数据中分解得到设备的电压、电流数据;辨识是指通过对设备电压、电流数据的特征提取,辨识出设备的名称,这一过程也称非侵入式负荷辨识[3]。NILM 的结果可为用电行为分析、需求响应潜力评估等技术提供数据基础,也能为用电模式的优化提供参考[4]。
目前,基于图像分类网络的非侵入式负荷辨识算法可达到较高的准确率,是重要的研究方向之一,此类算法的框架可归纳为特征值的标准化处理、组合特征图的构造、基于图像分类网络的设备辨识模型建模3 大步骤。例如文献[5]和文献[6]都以设备样本的视在功率为基准,对该样本的有功或无功功率进行标准化;然后分别使用RGB 彩色编码算法和HSV 彩色编码算法构造组合特征图;最后基于AlexNet 图像分类网络实现设备辨识。但上述标准化处理方法改变了特征的种类,实质上,功率特征并未在设备辨识中发挥作用,影响辨识的准确性。为了改进这一不足,文献[7]以瞬时功率在全部设备样本上的最值为基准,对其进行标准化;然后使用RGB彩色编码算法构造组合特征,最后基于VGG-16 图像分类网络实现设备辨识。但这一特征标准化方法中基准参数的计算复杂,需考虑所有设备的所有运行状态,且要求计算结果必须精确,效率较低。
另外,以上文献所提方法都存在着参数冗余的问题:一是由于彩色编码算法的不足,设备组合特征存在参数冗余;二是由于图像分类网络的参数冗余,以上文献虽然都对原始的图像分类网络进行了优化,但仅限于网络的全连接层,且在优化方法上不具备理论支撑,参数冗余的改善效果不佳。算法的参数冗余将引发不必要的运算成本,不利于算法在工程上的规模化应用[8]。
本文针对基于图像分类网络的非侵入式负荷辨识,提出了一种运算成本优化算法。一方面,设计了一种新的非线性函数来实现特征的标准化,该方法中的基准参数可凭经验估计得到,效率更高、可操作性更强。另一方面,从设备特征和辨识模型2 个角度减少算法的参数冗余:①提出了一种基于灰色编码的特征组合方法,以减少特征的参数冗余;②基于图像分类网络ZFNet 构建设备辨识模型,并引入Inception 模块来减少模型卷积层输出的参数冗余,同时基于仿真实验结果调整模型全连接层的结构,以减少模型的参数冗余。最后,使用PLAID 数据集对本文所提算法的运算成本优化效果进行测试。
1 设备特征标准化方法
从数据的角度,设备特征可分为一维特征和二维特征,例如有功、无功功率等属于一维特征,而V-I轨迹属于二维特征,是一张图像。由于维度不同,一维特征和二维特征不能直接组合,一般通过将一维特征赋值给二维特征中某一位置的像素参数,实现特征的组合。当一维特征的取值范围与像素参数的取值范围相同时,可直接进行赋值操作;否则为了能够进行赋值操作,就需要对一维特征的值域进行调整,即特征标准化。
对取值范围有界的特征,标准化只需线性缩放即可;对取值范围无界的特征,本文设计了一种非线性函数来实现特征标准化。以本文中被组合的功率特征为例易知,虽然理论上功率的取值范围为无界区间,但实际中,考虑设备的经济性和安全性,存在一个涵盖绝大部分设备功率取值的有界子区间。对于该子区间内的特征,可进行线性映射,以保持特征的分布特性;对子区间以外的功率,可基于指数函数设计非线性映射,从而将无界的特征值域映射到像素参数的取值范围[0,1]中。
特征标准化函数的表达式如式(1)、(2)所示。
式中:P和Q分别为有功、无功功率的计算值;P′和Q′分别为有功、无功功率的标准化值;[0,p1]表示有功功率的有界子区间;[q1,q2]表示无功功率的有界子区间;[0,n]表示像素参数的取值范围,本文取为[0,1] ;α为[0,1] 范围内用于非线性映射的子区间长度。
本文中,α取为0.05,[0,p1]和[q1,q2]分别取为[0,2 000] W 和[-300,150] var,有功、无功功率的标准化函数分别如图1、2所示。
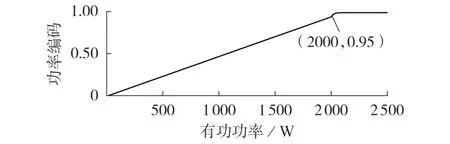
图1 有功功率的标准化函数Fig.1 Normalized function of active power
图1 和图2 中的参数取值为样本功率分布的统计分析结果,即将功率按大小顺序排列后,取距首、尾5 % 的数值,再就近取整所得。样本来自NILM 公开数据集PLAID,并排除了下文中的设备辨识模型测试样本,以保障测试结果的可靠性。
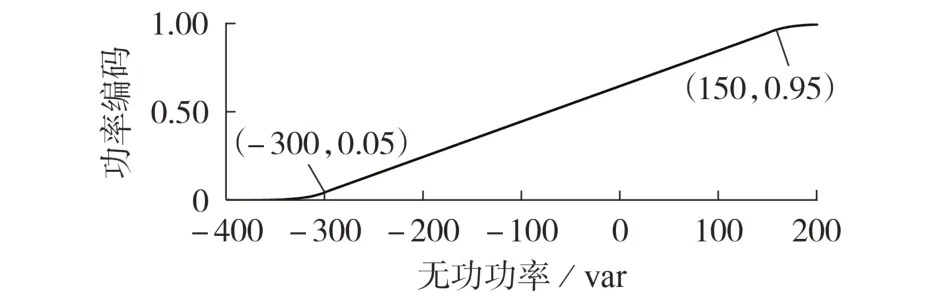
图2 无功功率的标准化函数Fig.2 Normalized function of reactive power
2 基于灰色编码的设备组合特征构造方法
2.1 基本原理
本文提出一种基于灰色编码的组合特征构造方法,对设备的暂态V-I轨迹、稳态V-I轨迹、稳态有功和无功功率进行组合。V-I轨迹是一种准确率较高的设备特征,但不能反映设备的功率,故使用V-I轨迹与功率的组合来构造组合特征[9]。特征组合方法的示意图如图3所示。图中:P′、Q′分别为有功、无功功率标准化值。
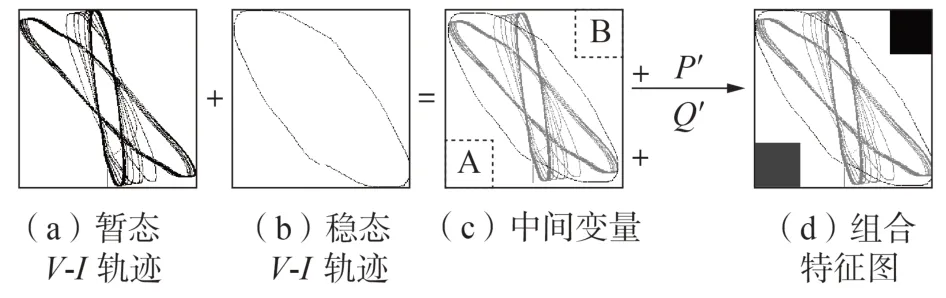
图3 基于灰色编码的特征组合方法Fig.3 Feature combination method based on gray coding
由图3 可见:图像数据本质上为矩阵,暂态V-I轨迹图(图3(a))和稳态V-I轨迹图(图3(b))可通过矩阵点乘合成为一张轨迹图(图3(c)),暂态和稳态V-I轨迹上像素点的参数值分别被赋值为0.5和0,以示区别。将有功、无功功率的标准化值分别赋给图3(c)中区域A、B的像素参数,即可得到组合特征图。
注意到图3(c)中轨迹的位置集中在主对角线附近,区域A、B中没有轨迹图像。对V-I轨迹图中轨迹位置的物理意义进行分析,如图4所示。
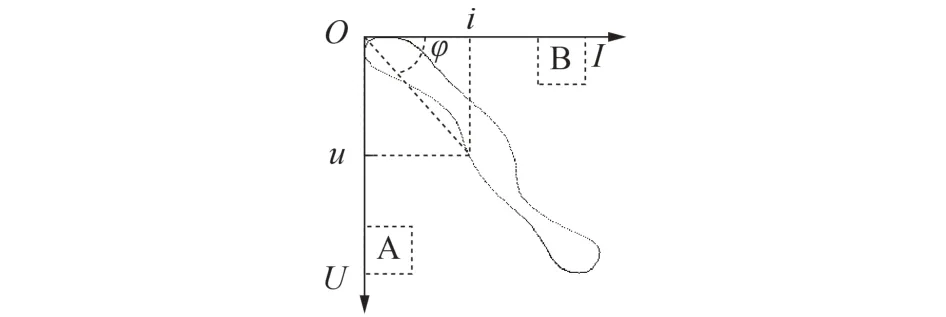
图4 V-I 轨迹分析结果Fig.4 Analytical results of V-I trajectory
由图4 可见,V-I轨迹是指以设备一定运行时段内的电流、电压值分别为横、纵坐标的点所组成的曲线,图4中的变量满足关系式(3)、(4)。
式中:u和i分别为电压、电流采样值;z和φ分别为设备阻抗和阻抗角。
易知,图4 中区域A、B 分别对应设备阻抗接近∞和接近0 的运行状态,实际中,设备处于此类运行状态的概率较小,即区域A、B中出现V-I轨迹曲线的概率较小。这些位置的像素点的参数值不包含V-I轨迹的特征信息,属于冗余参数。因此,使用有功、无功功率的标准化值对其进行赋值替换,以减少设备特征的参数冗余。
2.2 方法步骤
本文所提设备组合特征构造方法的步骤如下。
1)计算设备的有功功率和无功功率[10]。
2)按照第1章的方法,计算功率的标准化值;
3)构造设备的暂态、稳态V-I轨迹。由于V-I轨迹在构造过程中已进行了类似标准化的处理,本文不再对其进行标准化操作。V-I轨迹构造方法见文献[11],所需数据的采样时段分别为完整的暂态运行时段和一个周期的稳态运行时段。
4)按照2.1节方法,生成组合特征图。PLAID 数据集中设备特征图的示例如图5所示。
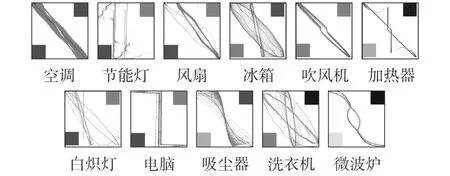
图5 设备组合特征图示例Fig.5 Examples of combination feature image of devices
本文中,特征图的分辨率为224×224,由于使用了轨迹图像更为复杂的暂态V-I轨迹作为特征之一,高分辨率的特征图虽然参数量更大,但可以反映更多的V-I轨迹的细节信息,特征的准确性更高,有利于设备的辨识。
3 基于ZFNet-Inception的设备辨识模型建模方法
3.1 模型结构和参数
设备特征的数据格式为图像,适合使用图像分类网络对设备特征进行分类,实现设备辨识。相比于图像分类网络最初始的应用对象,设备特征图的构成更简单,可以选择轻量级的图像分类网络,例如LeNet[12]、AlexNet[13]、ZFNet[14]等,以减少运算成本和模型训练的过拟合。其中:LeNet 的层数过少,其准确率较低;ZFNet相比AlexNet的网络性能更优。
综合考虑设备辨识模型的准确率和运算成本,本文基于ZFNet 构建设备辨识模型,模型结构和参数见附录A 图A1。模型主要包括卷积层和全连接层2 类结构,前者的作用是对输入图像进行特征提取;后者的作用是构造分界面,最终实现对特征的分辨。
相比于原始的ZFNet 模型,本文所提模型在结构和参数上的主要调整如下。
1)在卷积层中引入Inception 模块的1×1 卷积结构,Inception 模块的结构如图6 所示。图中:“1×1”“3×3”“5×5”表示卷积核的大小。
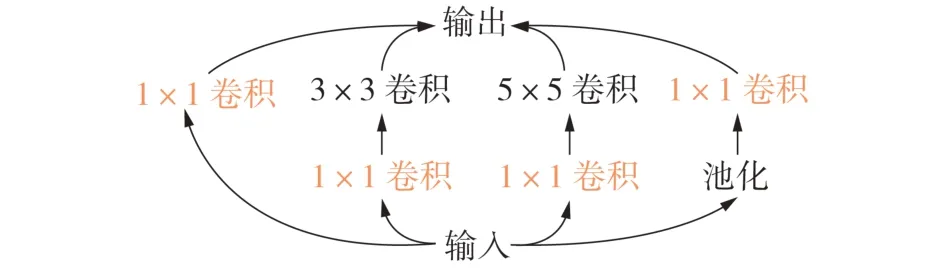
图6 Inception模块Fig.6 Inception module
本文将Inception 模块中的1×1 卷积结构引入设备辨识模型中。1×1 卷积的作用是对前一层的输出进行压缩。每层卷积在进行特征提取后,都会产生多个输出,但并不是每个输出都包含有效的信息,即卷积的输出具有稀疏性[15]。通过1×1卷积对其进行压缩,可以减少后层卷积在对前层输出进行运算时的运算量。
除此之外,Inception 模块中还包含由多个大小不同的卷积核组成的并联卷积结构。这一结构可使网络具备更强的分类能力,但其在简单图像的分类任务中的效果并不明显,反而会增加模型的运算成本和过拟合的概率,故在本文所提模型中并未使用。
2)对全连接层进行精简。
本节通过实验对ZFNet 全连接层的结构和参数进行优化。实验一共设置6组对比实验,第1组的模型为ZFNet,第2 — 6 组模型的卷积层与第1 组模型相同,而全连接层的参数量递减。使用各模型对设备组合特征图进行辨识,模型的参数量和辨识准确率如表1所示。
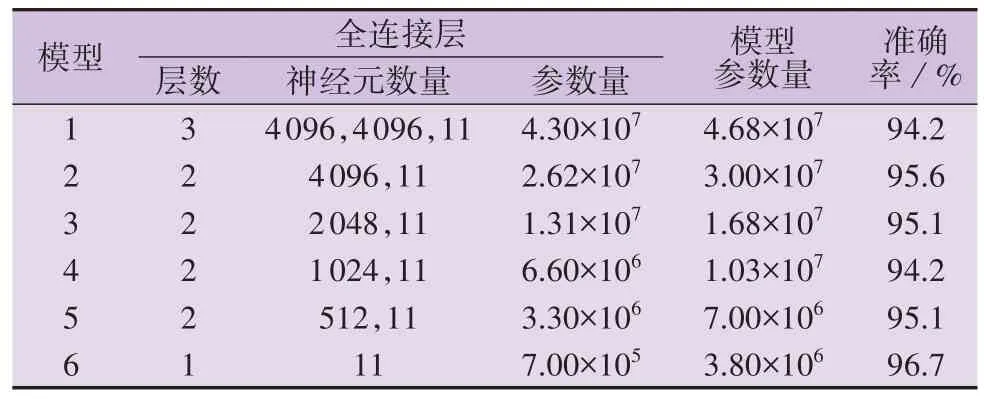
表1 ZFNet全连接层优化实验中各模型的参数和性能Table 1 Parameters and performance of each model in ZFNet fully connected layer optimization experiment
由表1可知:随着全连接层参数量的减少,1 — 5号设备辨识模型在辨识准确率上的波动小于1.4 %,6 号模型的准确率最高;1 — 5 号模型皆存在参数冗余,6号模型的全连接层结构和参数设计最优。
3)增加Dropout层和批归一化层。
Dropout 层和批归一化层的作用都是减少模型训练的过拟合,批归一化层还能加快网络的收敛速度[16]。
3.2 模型训练
本文中,设备辨识模型的训练使用交叉熵损失函数,模型参数优化算法为自适应随机梯度下降算法;初始学习率为0.01,每经过4 轮训练降低学习率为现有学习率的50 %,一共训练10轮。
4 算例分析
4.1 算法仿真流程与数据集划分
算法仿真分析使用的是NILM 领域公开数据集PLAID[17],其中包括空调、洗衣机等11 类常见家电的运行电压、电流数据共1 823组。在每类设备的样本集中随机抽取20 % 的数据构成模型测试集,剩余数据为模型训练集。算法仿真流程如图7所示。
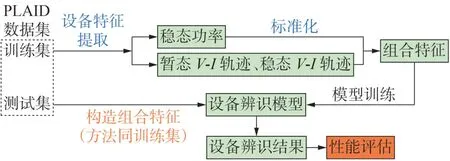
图7 算法仿真流程Fig.7 Flow of algorithm simulation
4.2 评价指标
1)设备辨识准确率。
设备辨识准确率指被正确辨识的样本数占总测试样本数的比例,计算公式如式(5)所示。
式中:mt为第t类设备的测试样本中被正确辨识的样本数;T为设备种类数;M为总测试样本数。
2)运算成本。
本文使用参数量和运算量来衡量算法的运算成本。其中:参数量分为设备特征的参数量和模型的参数量;运算量为数据从模型输入到输出的单次传递过程中乘法运算的总数。参数量与运算量具有一定的正相关关系,而运算量越大,显然算法的运算成本就越高。
4.3 仿真结果与对比分析
使用混淆矩阵对测试集样本的设备辨识结果进行整理,结果如图8 所示。图中:主对角线上的数值表示被正确辨识的样本数;其他位置的数值表示被错误辨识为相应设备的样本数,体现了辨识时2 类设备相互混淆的情况。根据混淆矩阵可以方便地计算出各类设备的辨识准确率,如表2所示。
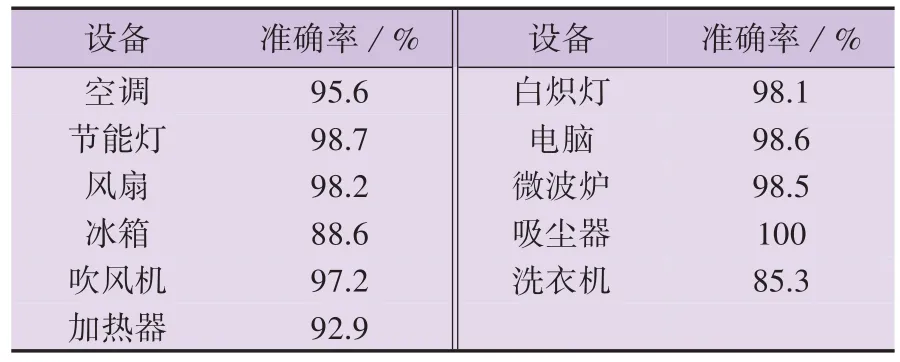
表2 本文所提算法的辨识准确率Table 2 Identification accuracy of proposed algorithm
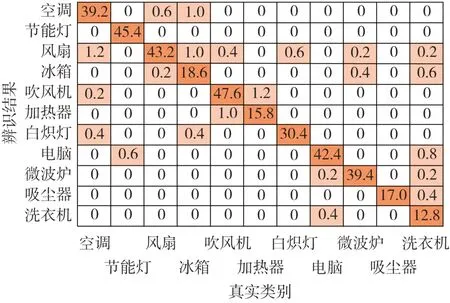
图8 设备辨识结果的混淆矩阵的平均值Fig.8 Mean value of confusion matrix of device identification results
综合图8和表2可知,本文所提算法对多数设备的辨识准确率可达95 %~100 %,在全体测试样本上的辨识准确率总体为96.7 %,仅冰箱和洗衣机的辨识准确率与平均水平相差较远,分别为88.6 % 和85.3 %。究其原因:一是PLAID 数据集中冰箱和洗衣机的样本数相对少,设备辨识模型未能充分学习到这2类设备的特征;二是这2类设备的运行状态更多变,设备特征更多样、复杂,辨识难度更高。
为了测试本文所提算法的性能,分别控制设备特征和辨识模型这2 项变量进行仿真对比实验,如表3 所示。保持测试数据抽取和模型训练方法相同,各实验组的准确率和运算量如表4 所示,详细数据见附录A表A1。
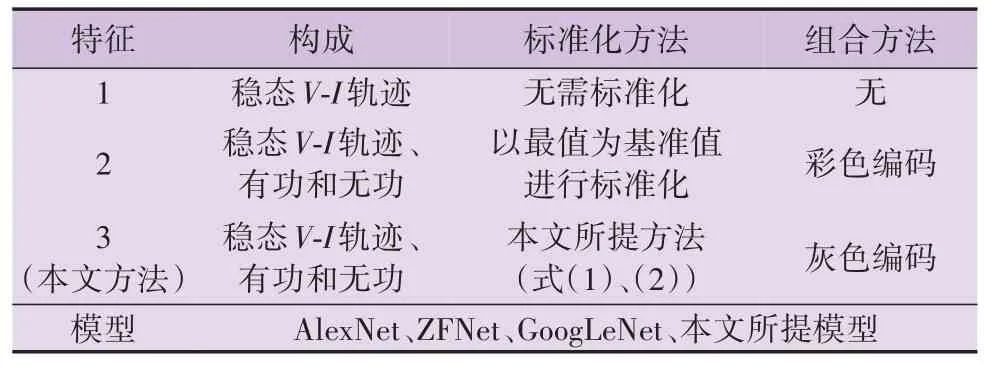
表3 对照实验的方案Table 3 Scheme of controlled experiment

表4 对照实验的结果Table 4 Results of controlled experiment
表4 中的数据兼具纵向对比和横向对比的功能。
1)纵向对比相同模型下不同特征的辨识效果,特征1 — 3 分别为稳态V-I轨迹、彩色编码和本文所提灰色编码特征。由表4 中数据可知,在AlexNet、ZFNet、GoogLeNet和本文所提模型上,灰色编码特征和彩色编码特征的辨识准确率的相差值皆小于1 %。理论上分析,设备辨识准确率主要取决于不同类设备之间特征的差异性(可区分性)和辨识模型的准确性,灰色编码和彩色编码所组合的特征是一致的,只是在组合方法上有所区别,且2 种组合方法都没有改变特征的差异性(可区分性),故两者对设备辨识准确率的贡献也应是相当的。在特征的参数量上,灰色编码相比彩色编码减少66.7 %;在模型的运算量上,灰色编码相比彩色编码减少了14.3 %~42.8 %。可知,灰色编码能有效减少特征占据的存储空间和设备辨识模型处理特征时的运算成本,且对辨识准确率的影响较小。
2)横向对比相同特征下不同模型的辨识效果,分别使用AlexNet、ZFNet、GoogLeNet 和本文所提模型对特征1 — 3 进行辨识。根据表4 中数据可知,本文模型的运算量相比AlexNet减少了18.7 %~42.8 %,相比ZFNet 减少了42.8 %~45.8% ,相比GoogLeNet 减少了15.8 %~18.7 %,可知本文所提模型的运算成本更低。
将本文所提算法与近年的同类非侵入式负荷辨识算法的准确率、参数量和运算量进行对比分析,如表5 所示,详细数据见附录A 表A2。表5 中数据为在同等的测试数据抽取和模型训练条件下,对各文献所提方法的原理进行复现仿真所得,可能与部分文献的实验条件不一致。
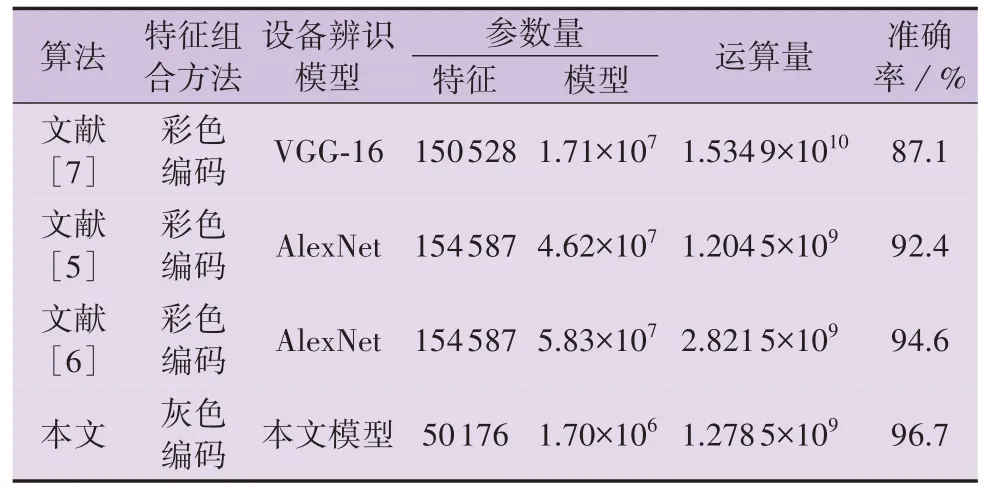
表5 同类算法的对比分析Table 5 Comparative analysis of similar algorithms
根据表5 中数据可知,相比于同类算法,本文所提算法在保持较高的设备辨识准确率的同时,在特征的参数量上减少了66.7 %~67.5 %,在模型的参数量上减少了90 %~97.1 %,在整体运算量上的变动为-91.7 %~6.1 %。由此可知,本文所提算法的参数冗余更少,运算成本更低。
5 结论
本文提出一种运算成本优化的非侵入式负荷辨识算法:在设备特征上,建立一种基于灰色编码的组合特征构造方法;在设备辨识模型上,基于图像分类网络ZFNet构建设备辨识模型,并通过引入1×1卷积结构和实验分析,对原ZFNet 模型的结构和参数进行了优化设计。经过算例分析可证实:所提方法在保障较高的设备辨识准确率的同时,可有效减少算法的参数冗余,降低算法的运算成本。
附录见本刊网络版(http://www.epae.cn)。
