区域旱灾风险评估与诊断的动态差异度系数模糊数随机模拟方法*
2024-01-18赵齐雅金菊良张诗琪
赵齐雅,金菊良,2,崔 毅,2,汪 洁,张诗琪,周 乐
(1.合肥工业大学 土木与水利工程学院,安徽 合肥 230009;2.合肥工业大学 水资源与环境系统工程研究所,安徽 合肥 230009)
干旱灾害是一种频繁出现、遍布广泛、影响深远的重大自然灾害,它是干旱发展到一定程度后导致自然水源供水匮乏,并对作物和植被正常生长、人类正常生活和生产、生态环境正常功能造成不利影响、产生危害的事件,是多种自然因素与社会因素综合作用的结果[1]。在全球约有120个国家和地区遭遇过较严重的旱灾影响[2]。近年来,我国平均每隔2~3年会遇到一次较大干旱[3]。旱灾所导致的后果不仅影响农业、畜牧业等产业,严重的旱灾还可能危及人类生产、生活,造成无法估量的后果。可见,定量评价区域旱灾风险等级、定性定量诊断旱灾关键障碍因子的旱灾风险评估与诊断研究是一项非常重要的、关乎民生的重点工作,得到了较广泛关注和研究。例如,金菊良等[4]提出用半偏减法集势方法,动态评估了宿州市旱灾风险等级并诊断出脆弱性因子;周戎星等[5]提出把三元减法集对势视作一个服从正态分布的随机变量,随机模拟所得的评价结果用置信概率区间表示,增加了评价结果可靠性方面的信息;董涛等[6]提出风险矩阵与五元减法集对势耦合的链式传递模型,对济南市旱灾风险进行评估与诊断;李杨等[7]提出GIS方法与数理统计耦合模型,运用于洞庭湖流域旱灾风险综合评价中。为准确且合理地进行旱灾风险动态评估、定量识别关键障碍因子,本文应用三角模糊数随机模拟方法[8],构建差异度系数随评价指标样本值动态变化的三角模糊数与随机模拟耦合方法,其计算结果用95%置信概率下的实数区间表示,可反映旱灾风险评估系统的随机性和模糊性对评价结果的综合影响。将该方法运用于宿州市2007-2017年旱灾风险评估与诊断研究中,以验证耦合方法的旱灾风险评价结果的合理性,并用于诊断旱灾风险关键障碍因子。
1 动态差异度系数模糊数随机模拟方法的建立
建立该模拟方法包括如下8个步骤。

步骤2:联系数是刻画一个集对中两个集合确定性与不确定性关系及其相互作用的数学方法[11],常用的三元联系数u表达式为:
u=a+bI+cJ。
(1)
式中:a+b+c=1;I是差异度系数,取值为[-1,1];
J是对立度系数,取值-1。根据评价指标样本值与评价等级标准值两个集合接近程度这一可变模糊集[12-13],可以计算出区域旱灾风险评价指标样本值xij与评价等级标准值Sgj两个集合所构的“可变模糊集”的三元联系数的初始分量ugij为[9]:
(2)
(3)
(4)
式(2)~式(4)中,正向(反向)指标为评价指标样本值越大则等级越高(越低)的评价指标。旱灾风险等级随评价等级g=1,2,3的升高而升高,S0j、S1j、S2j、S3j分别为评价指标的等级阈值。分段函数ugij的取值原则为[9]:评价指标样本值xij若落在评价等级g的相同区间,则ugij取值1;若落在评价等级g的相邻区间,则ugij取[-1,1]内的值;若落在评价等级g的相隔区间,则ugij取值-1。
经式(2)~式(4)得出三元联系数初始分量ugij后,计算评价指标样本值xij与标准等级g两集合的相对隶属度[14-15]:
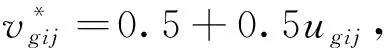
(5)
将式(5)归一化,得对应的指标值联系数各分量Vgij:
(6)
将式(2)~式(6)所得结果代入式(1),得到指标值联系数Uij:
Uij=V1ij+V2ijIij+V3ijJ。
(7)
式中:Iij为差异度系数,Vgij为联系数分量,J取值
-1。于是,可得评价样本值联系数Ui:
(8)
式中:Wj为评价指标权重,由AGA-FAHP[10]计算权重方法确定。
步骤3:构造动态差异度系数模糊数。将三元联系数中差异度系数I(I∈[-1,1])按照标准等级g三等分:若评价指标样本值处于1级值域内,则I1取值范围为[1/3,1];若评价指标样本值处于2级值域内,则I2取值范围为[-1/3,1/3];若评价指标样本值处于3级值域内,则I3取值范围为[-1,-1/3][9]。文献[9]把差异度系数与评价指标样本值的动态变化视为线性变化,而本文将I1、I2、I3分别取为I1=(1/3,2/3,1)、I2=(-1/3,0,1/3)、I3=(-1,-2/3,-1/3)三角模糊数形式。
步骤4:对差异度系数模糊数进行随机模拟[16]。若差异度系数模糊数为I=(a1,a2,a3),a1≤a2≤a3,使用式(9)随机模拟三角模糊数公式[17],随机模拟N次后,得到一组差异度系数的可能值I:
(9)
式中:u为[0,1]上的均匀分布随机数。
步骤5:截取显著性水平为α的置信概率区间[18]。由式(9)计算得评价样本的N个随机模拟变量I值,把对应的N个随机模拟变量I值代入式(8),得到N个样本联系数值后,再降序排列,根据随机变量的经验累积频率的数学期望公式(10)[18-19]和公式(11)计算出在显著性水平α下样本联系数的置信区间:
Pl=l/(N+1);
(10)
[uINT[(1-0.5α)(N+1)],uINT[0.5α(N+1)]]。
(11)
式中:Pl为N组联系数值降序排列、排序第l位的经验累积频率[19];uINT为取整某序号所对应的联系数值。
步骤6:为与本文旱灾风险评价等级结果进行比较,同时采用级别特征值法[20]计算评价等级:
(12)
步骤7:计算评价等级区间。以级别特征值法取值原则为依据,利用线性内插法把联系数值Ui转换为评价等级yi[21]:
(13)
式中:Ui为联系数值;yi为评价等级。当yi∈[1,1.5)时,旱灾风险处于“微险”;当yi∈[1.5,2.5]时,旱灾风险处于“轻险”;当yi∈(2.5,3]时,旱灾风险处于“重险”[5]。
步骤8:利用单指标联系数区间期望值u诊断区域旱灾风险关键障碍因子。将联系数u∈[-1,1]按照均分原则,把评价指标分为强阻碍型u∈[-1,-0.6]、中阻碍型u∈(-0.6,-0.2)、弱阻碍型u∈[-0.2,0.2]、弱提升型u∈(0.2,0.6]、强提升型u∈(0.6,1]这5个类型[9]。其中,强阻碍型和中阻碍型指标是严重影响区域旱灾风险等级的关键障碍因子,是区域旱灾风险诊断的重点研究对象。
2 实例分析
将本文模型应用于安徽省宿州市2007-2017年旱灾风险评估与诊断中,使用文献[4]中宿州市旱灾风险评价指标层、评价标准及权重等数据(表1)。

表1 宿州市旱灾风险评估指标体系及等级标准[4]
根据《安徽省统计年鉴》等资料查取宿州市 2007-2017 年各评价指标数据值,根据上文计算出显著性水平为α=0.05下的联系数区间、评价等级区间,将本文方法与动态差异度系数方法[9]、正态分布随机模拟方法[5]对比分析,其结果如表2所示。
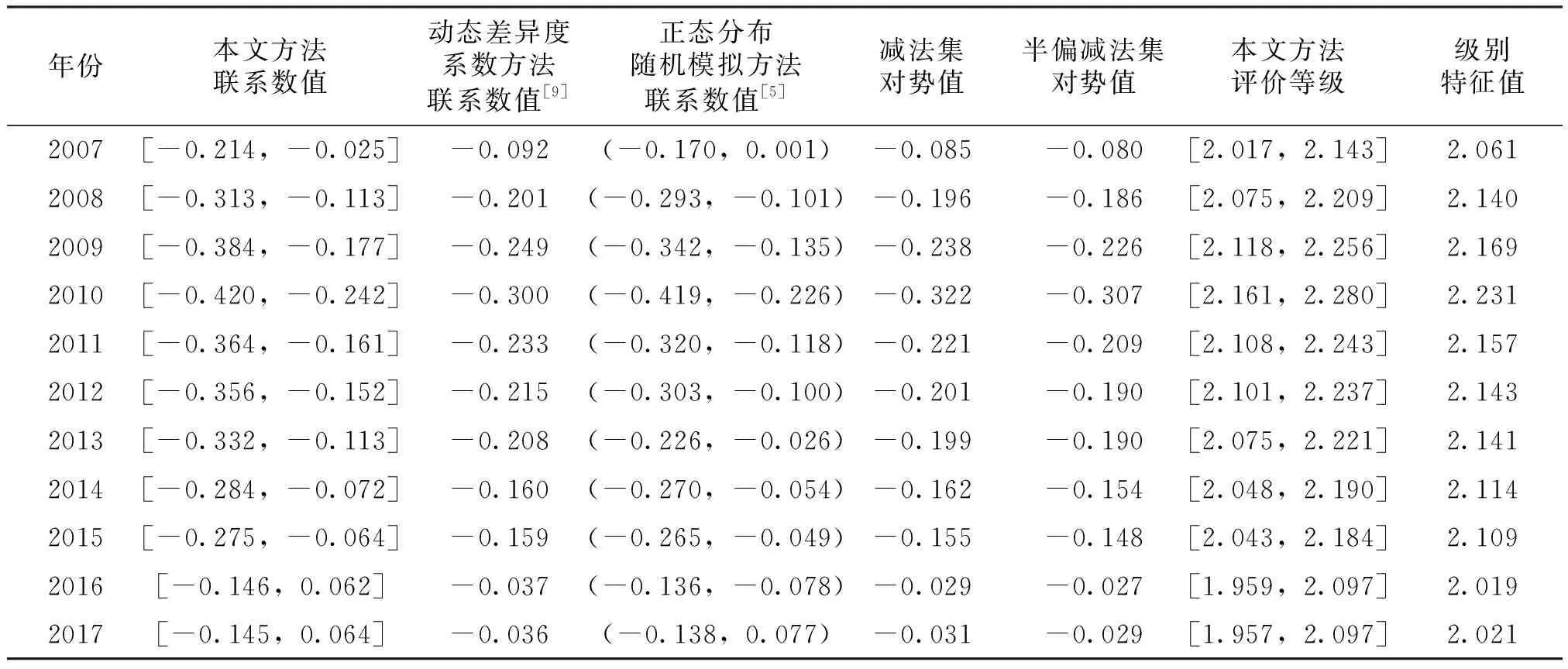
表2 宿州市 2007-2017 年旱灾风险评估样本联系数值、评价等级、减法集对势值[22]及半偏减法集对势值[23]
由表2得:①本文方法与正态分布随机模拟方法[5]所得的宿州市2007-2017年旱灾风险评估样本联系数都是以95%置信区间形式表示。本文方法的样本联系数区间范围在0.2左右,联系数区间期望值与减法集对势值的误差为0.025,样本联系数区间均包含减法集对势值、半偏减法集对势值,而正态分布随机模拟方法[5]样本联系数区间在2016年未包含减法集对势值、半偏减法集对势值。②对于相同研究区域,本文方法中95%置信区间均包含利用动态差异度系数方法[9]计算得的旱灾风险评价结果。
为更清晰地展示三种评价方法的优劣,进行结果讨论与分析。由图1得:①本文方法的置信区间的两条界线趋势平行,区间范围稳定在0.2左右,与减法集对势趋势变化一致。正态分布随机模拟方法[5]的置信区间的一条界线与减法集对势趋势变化相差较大,且评价结果范围波动较大、评价结果不够稳定。分析此现象的原因:差异度系数具有模糊不确定性,本文把差异度系数取为三角模糊数形式,将三角模糊数转化为一组随机数后进行随机模拟,计算得的样本联系数区间稳健、合理,与减法集对势趋势变化一致;正态分布随机模拟方法[5]假设减法集对势值满足中心极限定理的条件,将减法集对势值视为服从正态分布的随机变量进行随机模拟,但该假设不一定合理,评价结果可能与实际情况不一致。以上对比充分说明在同时满足α=0.05的情况下,本文方法的评价结果更具稳定性与精确性,其结果可更准确地表示旱灾风险所处的级别状态。②本文方法的置信区间均包含利用动态差异度系数方法[9]计算所得的联系数评价结果,两种方法的评价结果趋势变化一致。分析此现象的原因:两种方法的差异度系数均随评价指标样本值动态取值,动态差异度系数法[9]把差异度系数与评价指标样本值视为线性关系,将差异度系数在[-1,1]内按标准等级数目均分为3个区间。本文将差异度系数均分为3个区间,与文献[9]有所不同是本文将差异度系数作为三角模糊数处理,随机模拟后最终评价结果为95%置信区间,充分体现了联系数所蕴含的“不确定性”这一信息。由图2得:本文方法说明了宿州市旱灾风险等级有95%的可能性由2007年[2.017,2.143]持续增加至2010年[2.161,2.280],又减小至2017年的[1.957,2.097],整体上呈现“先增加,后减小,最后趋于稳定”的趋势,旱灾风险综合评价结果为“轻险”[5]。
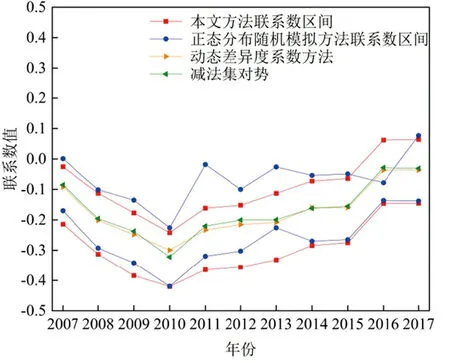
图1 联系数值对比图
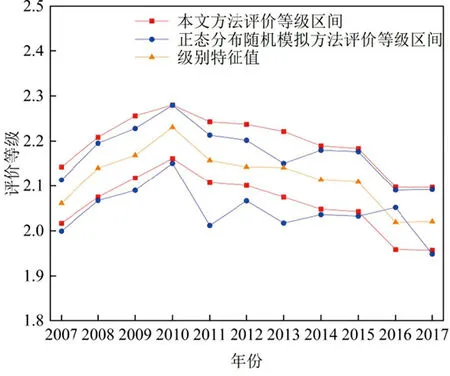
图2 评价等级对比
为更加深入判断旱灾风险系统综合评价结果与各子系统的关系,对各子系统评价结果进行分析说明。如图3所示,灾损敏感性子系统趋势基本保持稳定状态,说明灾损敏感性子系统不是影响宿州市旱灾风险综合评价结果趋势变化的主因,危险性、暴露性、抗旱能力三个子系统是影响宿州市综合评价结果趋势变化的主因,下面分别对这三个子系统作进一步分析。
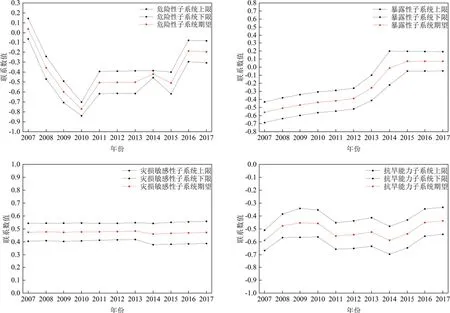
图3 各子系统联系数区间及期望
图4、图5、图6分别为危险性、暴露性、抗旱能力三个子系统中单指标评价结果,可以看出:x1,1、x1,2、x1,3、x1,4是影响危险性子系统评价结果趋势变化的关键指标;x2,3、x2,4是影响暴露性子系统评价结果趋势变化的关键指标;x4,4、x4,6、x4,7是影响抗旱能力子系统评价结果趋势变化的关键指标。根据模型步骤八中障碍性因子、提升性因子[9]区间,定量诊断宿州市旱灾风险的关键障碍因子:耕地率x2,2、水库调蓄率x4,2、农业人口比例x3,1三个评价指标为中阻碍型因子,水田面积比x3,2、万元GDP用水量x3,3为弱提升型因子,其余评价指标均为弱阻碍型因子(表3)。因此,耕地率x2,2、水库调蓄率x4,2、农业人口比例x3,1三个中阻碍型因子为宿州市旱灾风险关键障碍因子,需要研究区域重点调控。

图4 危险性子系统中各指标联系数区间及期望
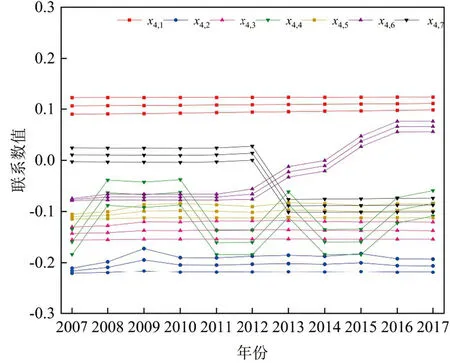
图5 暴露性子系统中各指标联系数区间及期望图
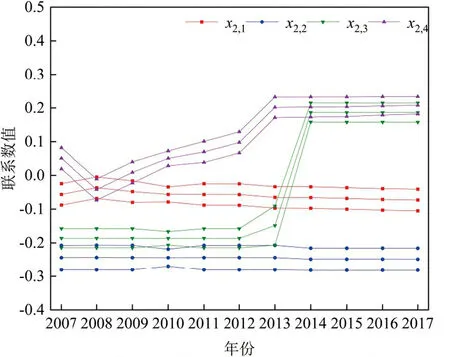
图6 抗旱能力子系统中各指标联系数区间及期望
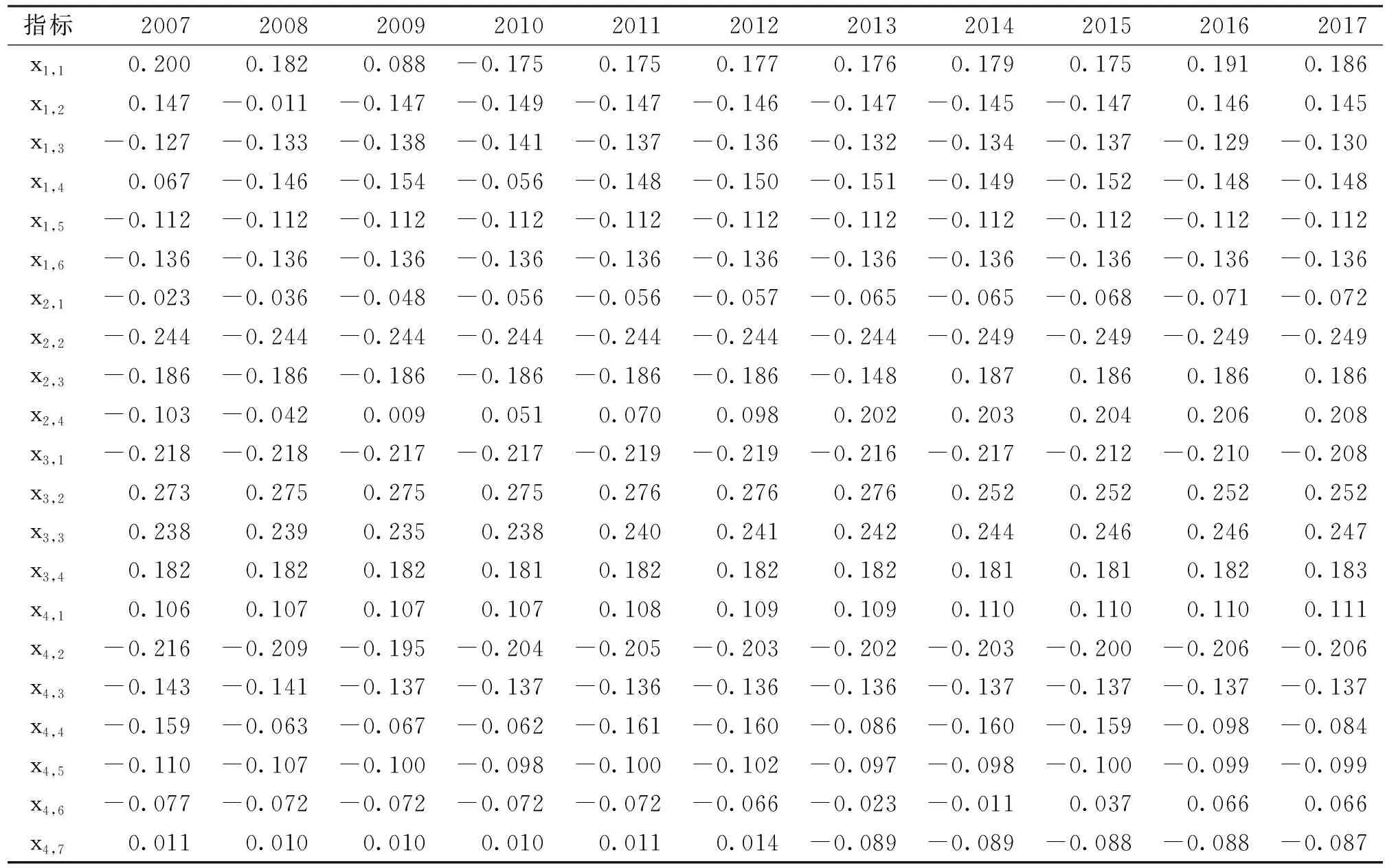
表3 宿州市2007-2017年旱灾风险单指标联系数区间期望值
3 结论
1)为准确且合理地评估旱灾风险状态、定量识别关键风险因子,应用三角模糊数随机模拟方法,构建了差异度系数随评价指标样本值动态变化的三角模糊数与随机模拟耦合方法,进行区域旱灾风险评估以及关键障碍因子定量识别,该方法计算得的置信区间能更好地反映评价问题的实际情况,评价结果更稳健、合理。
2)通过本文方法在宿州市2007-2017年旱灾风险评估与诊断中的应用,表明宿州市旱灾风险综合评价结果为“轻险”,整体上呈现“先增加,后减小,最后趋于稳定”的趋势;危险性、暴露性、抗旱能力三个子系统是影响研究区域旱灾风险综合评价结果趋势变化的主因;耕地率、水库调蓄率、农业人口比例三个评价指标是中阻碍型因子,是需要重点调控的对象,水田面积比、万元GDP 用水量是弱提升型因子,其余评价指标均为弱阻碍型因子。
3)结果表明,本文动态差异度系数模糊数随机模拟方法与正态分布随机模拟方法[5]、动态差异度系数方法[9]相比,本文方法在满足可靠性的同时也满足准确度,其结果可以更好地表示旱灾风险所处的级别状态,能为系统风险评估问题提供更多可靠性方面的信息。
