基于计算机体系结构的大模型加速研究进展
2024-01-18武琼
武琼
北京冉腾语云科技有限公司 北京 100000
引言
大模型时代已然到来,我们要拥抱未来,改变世界。但大模型在网络受限、计算资源不足的场景下,不能有效使用,算力低,无法满足端侧训练及本地化部署的问题亟待解决。大模型加速、轻量化,是大模型能在消费级配置中运用的必然之路。
大模型的出现,改变了冯诺依曼的传统计算机体系结构。处理器结构、计算速度、计算精度等,对处理器及内存提出了分布式存储计算的要求,对体系架构下各设备之间的输入输出提出了更高的要求。
大模型出现之前,算法与硬件是可以解耦的,但大模型的出现,需要算法强依赖硬件资源,只有合理使用硬件,对硬件做到足够优化的基础上,才能更好地支撑算法的训练和应用。
目前在大模型轻量化的研究主要集中在模型量化,剪枝,蒸馏等算法层面,并未从硬件到软件,从计算机体系角度全面贯通的大模型轻量化方法。
本文从计算机体系架构角度,分析大模型对计算机各组成部分的优化技术和调整方案,以满足将大模型在消费级移动设备和小型设备上进行训练和部署的目标。
本文主要从计算机体系架构的7个方面分析大模型轻量化研究进展:①基于大模型的计算机体系架构的变化;②处理器计算加速;③显存加速;④输入输出通信传输加速;⑤操作系统加速;⑥编译加速;⑦算法加速。
1 大模型下计算机新体系架构
大模型技术的出现,在计算机系统架构中,最大变化是处理器,由单CPU模式变革到CPU与GPU联合处理模式,这也是大模型得以实现的关键所在。处理器变化如下图。
1.1 新计算机体系架构框架
整体架构如图1所示。
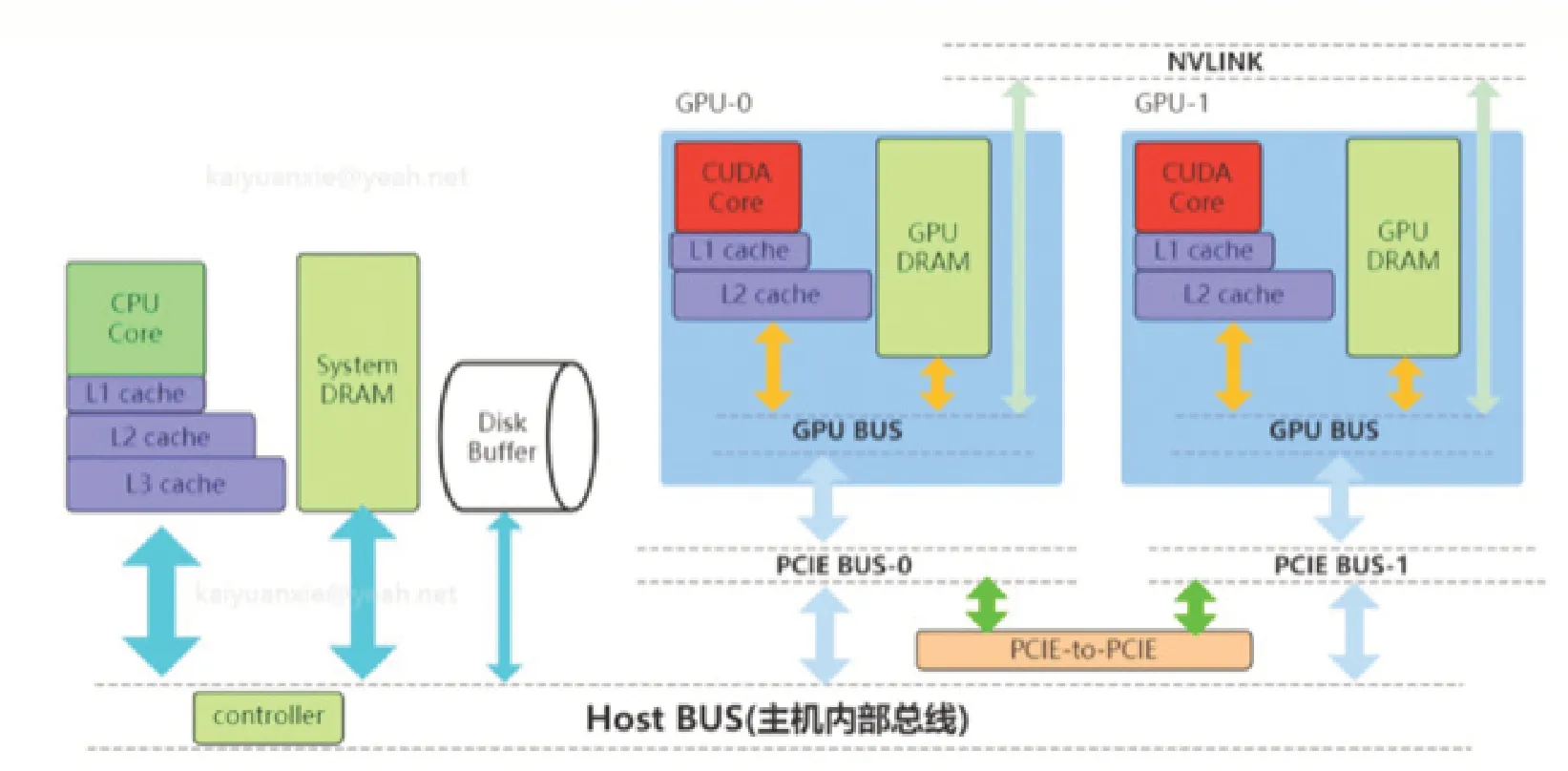
图1 新计算机体系架构
1.1.1 系统存储。
(1)L/L2L3:多级缓存,其位置一般在CPU芯片内部。
(2)System DRAM:片外内存,内存条。
(3)Disk/Buffer:外部存储,如磁盘或者固态磁盘。
1.1.2 GPU设备存储。
(1)/L2 cache:多级缓存,位置在GPU芯片内部。
(2)GPUDRAM:通常所指显存。
(3)GPU设备存储包含许多存储单元。
1.1.3 传输通道。
(1)PCIEBUS:PCIE标准的数据通道,数据是通过该通道从显卡到达主机。
(2)BUS:总线。计算机内各个存储之间交互数据通道。
(3)PCIE-to-PCIE:显卡之间通过PCIE直接传输数据。
(4)NVLINK:显卡之间的一种专用的数据传输通道。
1.2 新旧体系架构的变化
所有对大模型的优化、加速、轻量化,都是对于体系架构中更好利用CPU、多级内存、GPU并行计算速度,GPU显存更好利用,提升速度等方面的优化。
①为了适应大模型千亿数据的并行计算,处理器由CPU单一架构,增加了GPU集群;②为了存储更多的参数,内存由过去的CPU缓存,增加了多级缓存,最革新的变化为增加了大量的GPU显存;③处理器内部,增加了内存到显存、显存到显存的通信传输通道。
2 处理器计算加速
处理器加速的最大变革是增加了GPU。为了更好地优化算法,最大程度节省硬件资源,需要对算法进行算力评估。
2.1 算力计算
2.1.1 训练算力。
训练算力 = 训练步数×每步计算量×并行度
(1)训练步数:模型训练的迭代次数,确保模型能够收敛到最优解。
(2)每步计算量:每个训练步骤需要的计算量,取决于模型的复杂度和训练数据的大小。
(3)并行度:计算设备的并行计算能力,计算设备的并行度越高,计算速度就越快。
2.1.2 参数计算。
其中:
C是训练transformer模型所需的计算量,单位为总浮点运算数(FLOP);
C=C前向+C后向;
C前向≈ 2PD;
C后向≈ 4PD。
τ是训练集群的实际总吞吐量:
τ=GPU数×每GPU的实际每秒浮点运算数(实际FLOPs),单位为FLOPs;
T是训练模型所花费的时间,以秒为单位;
P是transformer模型的参数量;
D是数据集大小,表示为数据集的总词元数。
2.1.3 精度计算。
精度计算如图2所示。
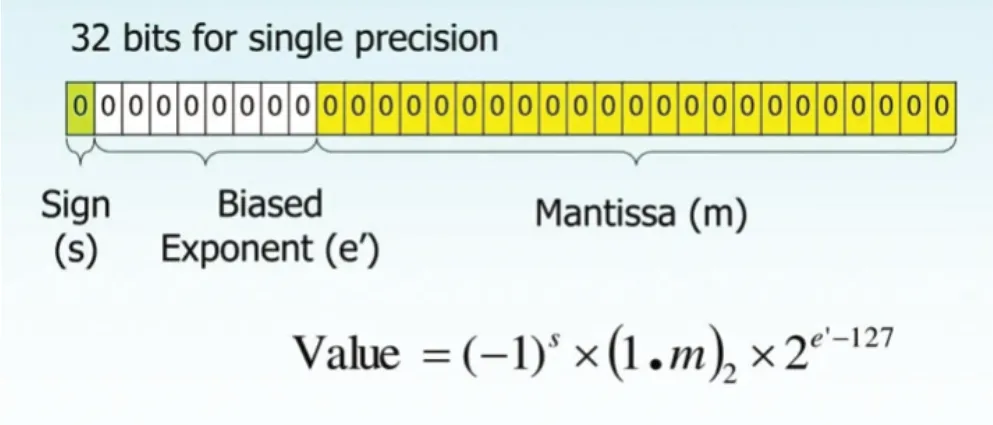
图2 精度计算结构
2.2 构建GPU集群
GPU集群能够支持万级卡的高速互联,支持各种异构计算,包括CPU、GPU等算力的高速互联。
GPU集群支持模型并行、数据并行、流水线并行、张量并行,大大提高计算速度。
3 存储加速
大模型环境下,存储加速考虑最多的是GPU显存加速。
3.1 消耗显存的来源
GPU的高性能已成为业界共识,但单个GPU的显存大小却增长缓慢,显存能力成为大模型训练的主要瓶颈,大模型的加速目标主要集中在对显存的优化与加速。首先要明确消耗显存的来源。
①数据显存:输入数据和神经网络每层输出的激活值大小受batchsize及上下文长度影响;②模型显存:权重参数、梯度参数、优化器状态等都直接影响显存的性能;③临时显存:GPUkernel计算时用到的临时内存和其他缓存等。④精度计算。
3.2 显存优化的方法
①Batch size:减少每次传入模型的样本数量。较小的batchsize可以减少显存的使用,但也会降低模型的训练效果,batchsize选择要权衡显存的限制和模型的性能要求;②减少模型的参数量:也就是减少模型的复杂度,减少模型的隐藏层、每层神经元数量,但会导致模型的表示能力下降,影响模型性能,要选择适当的参数量,达到两者平衡后的最佳效果。③梯度累积技术:将梯度计算结果存储在显存中,以便在计算下一批样本时重复使用;④压缩模型参数:利用GPU集群,使用分布式存储计算推理技术,将模型的计算分布到多个设备上,以减少单个设备的显存需求;⑤模型并行:将模型的参数、梯度、优化器状态以模型并行的方式切分到所有的GPU,利用ZeRO-Cache框架把内存作为二级存储offload卸载参数、梯度、优化器状态到CPU内存;⑥数据并行:在各个GPU上都拷贝一份完整模型,各自有一份数据,算一份梯度,最后对梯度进行累加来更新整体模型;⑦流水线并行:当模型太大,一块GPU放不下时,流水线并行将模型的不同层放到不同的GPU上,通过切分mini-batch实现对训练数据的流水线处理,提示GPU计算通信比,通过re-materialization机制降低显存消耗;⑧内存架构优化:可以采用参数服务器集中式和去中心化两种方式。
4 输入输出传输通信加速
大模型的基础设施需要高性能智能计算,在万卡规模的网络架构中,要保证网络的扩展性,没有拥塞,是非常困难的。大模型体系架构的通信特点是,有很多集合的通信操作,集合通信可以分解为同号卡之间的集合通信,在同号卡之间构建高速的通信通道,提升整个网络的吞吐量。
大模型架构体系的输入输出通信模式,也对大模型性能有很大的影响,大模型通信优化方向:①改善网络硬件资源,从物理上直接提升带宽,降低延迟,但成本高,需要新设备及使用维护开销;②采用AllReduce集合通信,减少带宽聚合,但不利于集中管理;③增加并行度,通过重叠计算与通信减少通信独立时间,但实现设计深度学习框架,修改困难;④改善同步通信算法,通过选取更合适的算法来减少通信时间,但不同环境下算法选择不固定;⑤使用张量融合技术,减少小通信包的通信时间占比,有额外的计算开销,会造成异步;⑥使用异步通信算法,减小由于计算时间差导致的节点等待,但只支持PS结构,另外会造成浑浊梯度影响训练精度;⑦量化压缩及稀疏化压缩,大幅度降低通信量,造成数量信息丢失,影响训练精度;⑧与拓扑相关的网络优化,充分利用拓扑带宽,限定应用范围,系统,算法实现难;⑨专用系统设计,减少带宽聚合,减少节点计算量,但硬件成本高;⑩减少通信占比,调整神经网络来降低同步参数量,但在多数环境下性能因素并非调整神经网络的主导因素。
5 操作系统加速
大模型在内存的分布式存储与并行计算,对计算机系统管理提出了更高的要求,越来越多的操作系统管理工作放在GPU中,以及与GPU相关的CUDE中,未来大模型会是操作系统中的一部分。
大模型需要在更多不同操作系统的端侧设备,如手机、汽车、智能家电等点在设备、VR可穿戴设备等终端设备运行,需要有更高效的操作系统在硬件与软件之间找到平衡。
6 算法加速
6.1 算法架构优化
①减少卷积核大小,将大卷积分解成一系列小的卷积核的操作组合,将少attention点积操作;②减少通道数;③加强神经网络架构搜索:更少的乘法操作,更快的速度;④损失函数优化。
6.2 矩阵优化计算
对矩阵计算进行优化,提高计算效率和节省存储空间。
6.2.1 分块矩阵乘法:将矩阵划分成小矩阵的块,通过重新组合计算顺序来减少计算量。可以利用矩阵的局部性,将少内存访问次数,提高计算效率。
6.2.2 并行计算的矩阵乘法优化:将大矩阵分解成多个子矩阵,分配给不同的处理器进行并行计算,加快计算速度。
6.2.3 矩阵转置优化:交换矩阵的行和列,需要使用额外的存储空间,时间复杂度高。
6.2.4 矩阵分解优化:将一个矩阵分解成多个子矩阵,常用的矩阵分解方法LU分解、QR分解、奇异值分解。
6.3 模型剪枝[1]
大模型网络结构中,有大量的冗余参数,在推理过程中,仅有少部分的权值与有效计算,并对推理结果产生主要影响。剪枝方法通过把网络结构中冗余的权值、节点或层去掉,减少网络的规模,降低复杂度。
6.3.1 剪枝原理:训练一个性能较好的原始模型,参数巨大,推理速度慢。判断原模型中参数的重要程度,去除重要程度较低的参数,在训练集上微调,尽量避免由于网络结构变化而出现的性能下降,判断模型大小、推理速度、效果等是否满足要求,不满足继续剪枝。
6.3.2 非结构化剪枝:权重剪枝,神经元剪枝。
6.3.3 结构化剪枝:卷积剪枝,跨多层剪枝。
6.3.4 Channel-wise: 通道剪枝[2]。
6.3.5 Stripe-wise pruning:[3]。
6.4 模型量化
大模型中计算量非常大,需要GPU等专用的计算pintail才能实现实时运算,这对于端上产品是不可接受的,模型量化就是减少计算量的方法。量化,对模型网络的权值,激活值等从高精度转化成低精度的操作过程,模型量化优势如下。
6.4.1 量化方法。①聚类量化[4];②对数量化;③二值量化;④对称量化;⑤非对称量化;⑥训练后量化和训练感知量化。
6.4.2 量化步骤。①选择合适的量化方法,确定选用的对称量化或非对称量化;②统计输输入数据的数值区间;③根据量化方法,输入区间,计算量化参数,零点值,缩放系数;④根据转换公式,对输入的float32精度的数据转换为int8精度数据;⑤验证量化后的模型效果。
6.5 知识蒸馏[5-6]
大模型结构复杂,但有良好的性能和泛化能力,小模型网络规模小,表达能力有限,利用大模型学习到的知识去指导小模型训练,使得小模型具有与大模型相当的性能,使参数量大福降低,可实现大模型轻量化。
6.5.1 知识蒸馏一般流程。
知识蒸馏如图3所示。
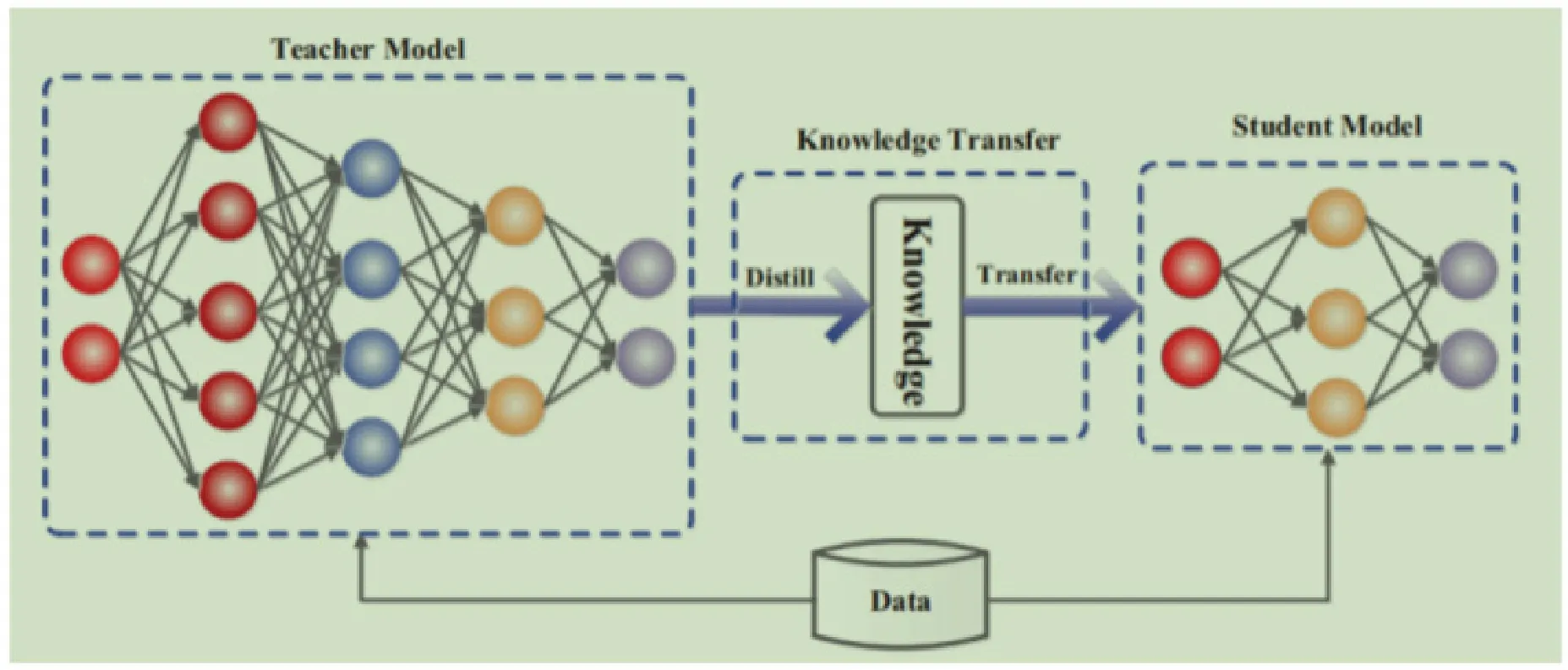
图3 知识蒸馏一般流程
6.5.2 知识蒸馏方法。①利用蒸馏损失函数刻画的教师神经网络中的知识在蒸馏过程中的丢失程度;②多教师知识蒸馏;③融合图神经网络的知识蒸馏;④结合多模态的知识蒸馏。
7 编译加速
编译器是连接算法和体系结构的部分,是解决训练环境与部署环境不一致的直接方法。一般通过大模型特有的深度学习训练框架,作为训练环境和部署环境的中间层,在中间层表示做系列标准的流图优化操作(loop调度,算子融合等),最后在按需求生成各自目标平台的机器码。常用的大模型编译器:①TVM:实现算子代码的自动生成;②TensorflowXLA:是一种优化TensorFlow计算的编译器,可以提高服务器的移动平台的速度,改进内存使用、提升便携性和可移植性;③PytorchGlow:Glow是一个机器学习编译器和执行引擎,可以面向多种硬件;④DeepSpeed:微软开源的一个LLM模型训练推理加速工具,并在此编译框架下复现了instructGPT论文工作,可以将速度提升15倍以上。DeepSpeed提供了GPU加速、模型压缩、ZeRO优化、自动混合精度、算力预测等功能,支持多种编程语言和编译框架,如Python、PyTorch、TensorFlow、JAX等编译器。
8 结束语
全文从计算机体系架构角度,从底层硬件到上层软件,对目前存在的LLM大模型加速方进行总结分析,建立了一种全视角LLM大模型加速的思路,有利于下一步通过计算机体系架构整体研究LLM大模型加速。
