基于LDA的网络舆情分析智能平台的设计与实现
2024-01-18马燕妮卢铁领
马燕妮 卢铁领


收稿日期:2023-06-19
基金项目:2021年宁夏医科大学理学院科研项目(nylxy20210016);宁夏医科大学校级科研项目(XM2023226)
DOI:10.19850/j.cnki.2096-4706.2023.22.005
摘 要:严格把控舆情方向,监测网民动态和大众感情倾向是对舆情发展控制的有力手段,也是对大数据舆论信息检测的关键所在。文章针对微博热点搜索、搜狗网页提供的微信公众号热点和百度资讯的热点新闻爬取并预测舆论倾向,利用可视化界面展示分析后的结果。首先通过爬虫获取每日热点信息,文本预处理后存入数据库;然后利用LDA主题模型提取热点事件,使用卷积神经网络分析情感倾向(正面、中性和负面);最后采用Django框架展示页面,进行相关统计研究和数据的可视化展示,通过可视化界面展示分析后得到的热点事件和舆论倾向。
关键词:舆情分析;LDA主题模型;卷积神经网络;情感倾向性分析;网络爬虫
中图分类号:TP311 文献标识码:A 文章编号:2096-4706(2023)22-0020-06
Design and Implementation of an Intelligent Platform for Network Public Opinion Analysis Based on LDA
MA Yanni, LU Tieling
(Ningxia Medical University, Yinchuan 750004, China)
Abstract: Strictly controlling the direction of public opinion, monitoring the dynamics of Internet users and the emotional tendency of the public are powerful means to control the development of public opinion, and are also the key to the detection of big data public opinion information. This paper crawls and predicts the trend of public opinion for the hot search of Weibo, the hot news of WeChat public account provided by Sogou website and the hot news of Baidu News, and use the visual interface to display the analysis results. Firstly, the daily hot information is obtained by crawler, and the text is pre-processed and stored in the database. Then the LDA topic model is used to extract hot events, and the convolutional neural network is used to analyze the emotional tendency (positive, neutral and negative). Finally, the Django framework display page is used for relevant statistical research and visual display of data, and the hot events and public opinion trends obtained after analysis are displayed through the visual interface.
Keywords: public opinion analysis; LDA topic model; Convolutional Neural Networks; analysis of emotional tendency; Web crawler
0 引 言
網络文化、微博生态以及各类网络平台的发展已经成为大众发表言论,表达情绪和获取新消息的重要渠道,各类新消息在微博、微信公众号和百度资讯网页新闻等网络平台快速传播,网民在读取到消息的同时也会针对当次发生的事件发表自己的言论并转发在自己的社交平台,致使事件发酵并扩大,极有可能给社会造成不同程度的负面影响。准确把握社会舆论的发展倾向,营造一个和谐、文明、公正、法制、美丽、安全的网络世界对社会的发展至关重要。
本文旨在对微博、微信公众号及百度资讯网页的每日热点新闻进行爬取,对爬取到的数据进行文本预处理(去除广告、降噪和重复数据),使用卷积神经网络(CNN)对爬取到的舆论信息进行情感倾向性分析(分为正面、中性和负面三种),最后通过可视化界面将相关统计研究的每日热点事件和事件的舆论倾向进行展示。
1 舆情分析智能平台的构建
1.1 爬取数据
平台的微博数据来源于每日百度实时热点的获取(每天爬取前三条热点),将获取到热点事件的关键词作为当日的热点新闻存入MySQL数据库,根据日期将每天的热点新闻存储并分类(即使用日期作为主键进行数据的存储),依次拿到微博进行搜索,爬取搜索到的相关信息并记录,此时存储数据就使用URL作为网页的主键[1-3]。平台的微信公众号数据来源于搜狗网页下的微信公众号搜索;百度资讯网页的数据来源于百度资讯里的相关热点数据。
1.2 文本分类
数据预处理是文本分类必不可少的一部分。首先对文本进行分词、去停用词及降噪,其次进行文本特征的提取、特征的选择以及分类模型的选择,最后预测出文本所表达的情感。
微博短文本的特殊性决定了爬取到微博文本数据的预处理工作比微信公众号和百度资讯数据的预处理工作更加烦琐,微博文本数据中一些特殊的符号也需要进行特别的“关照”,常用符号有://、@、##、V。
1)符号//:是每位微博用户自己的评论,它可以有效地区分不同人之间的评论内容,可作为分隔符表示不同的内容。
2)符号@:是云传话的标志,俗称隔空喊话,@某某某就是提示这句话要传递给某某某这个人或者是这个组织(即提醒),@可以出现在文章开头、中间或者末尾。例如:有你真好[笔芯]@某某某。
3)符号##:两个#之间是话题,指后面的文本是针对这个话题产生的,点击也可进入到这个话题的界面。比如:#快乐大本营# 李维嘉吃桌子巧克力,这巧克力像到怀疑自己可能有对假眼睛!
4)符号V:是新浪微博对用户身份认证,俗称官方的。
中文分词借助jieba分词技术,分词后使用哈工大停用词表去除停用词,然后使用TF-IDF算法计算主题词的权重(即评估主题词的重要性),选取权重大的词作为特征词,最终进行特征的提取。分类模型使用卷积神经网络(CNN)最终输出情感分类的结果(正面、中性及负面)。
1.3 可视化展示
对文本情感倾向的预测和主题词的生成需要使用Django框架进行可视化的展示。Django使用ORM(Object Relational Mapping)模型,也称为对象关系映射,可用于实现不同类型系统数据之间的转换[4]。即ORM模型是个“翻译器”,能够使两种不同语言的人更好的交流。在本文中,ORM模型的使用让数据库里的数据转化成Django中的类对象,方便之后的测试与使用。针对“华为正式发布鸿蒙手机操作系统”热点,本舆情分析智能平台界面中爬取信息的信息汇总界面如图1所示。
1.4 数据库设计
本文提出的舆情分析智能平台中爬取到的数据使用MySQL数据库存储,建立了4个存储表:time表、opinion_data表、analysis_data表及word_cloud表。time表存储从百度时事热点里获取到的热点信息以及对应的时间;opinion_data表用于存储在微博、微信公众号以及百度资讯网页爬取的数据;analysis_data表存储经过分析后的数据舆情信息;word_cloud是存储词云相关信息的表,通过TF-IDF选取出10个频率最高的词作为词云展示。
2 网络舆情分析过程
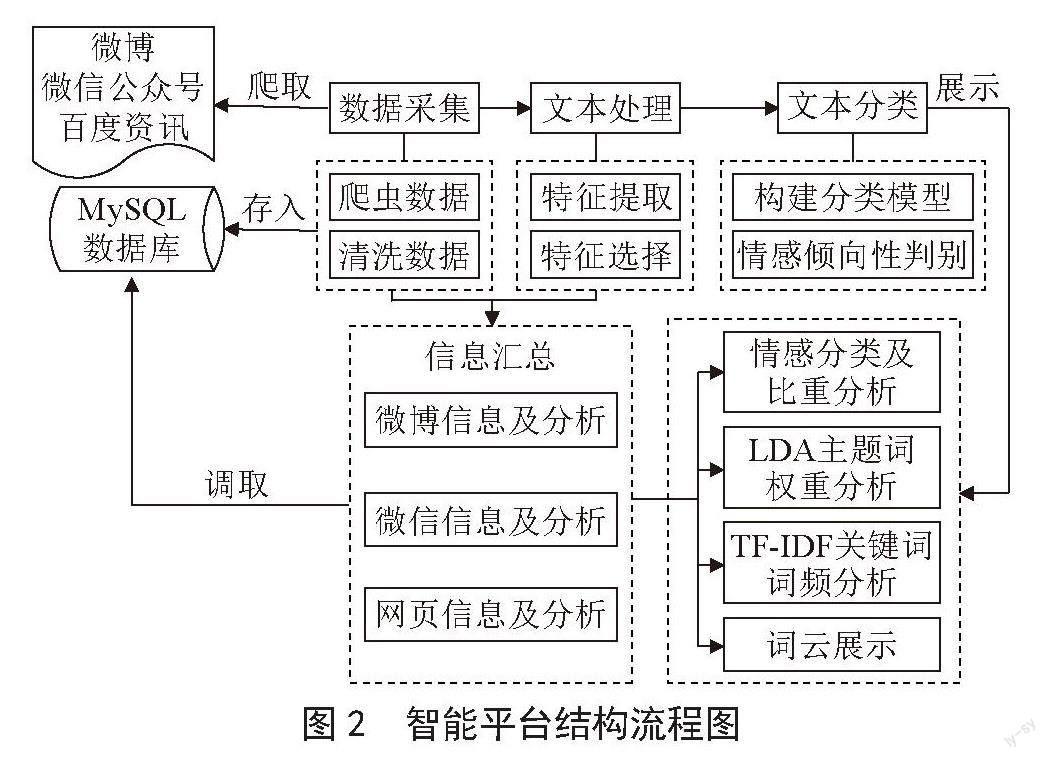
本文所述网络舆情分析的研究主要分为两步骤:一是在百度实时热点页面获取每天热点的前三条,以时间为主键,存入数据库,然后依次拿到微博进行搜索,爬取搜索到的数据再存入数据库,同时爬取搜狗界面提供的微信公众号的热点和百度资讯网页的每日热点新闻;二是通过对爬取到数据的处理,使用卷积神经网络(CNN)进行情感倾向性判断的实验,得出情感分类结果,利用LDA主题提取模型得到隐含主题,更加直观的显示出舆论信息。智能平台结构流程图如图2所示。
2.1 TF-IDF的词频分析
TF-IDF(術语频率-逆文档频率)的词频分析用来进行词云展示和词频度的统计[5]。它虽然不具有提取特征词的功能,但是它可以通过计算权重,测试单词在句子或文本中的重要程度,实现对特征词的评估,从而获得可以代表文本特征的词。同时,这种方法也可去除文本中经常出现的但又不重要的词,或是偶尔出现一次,但却与分类无益的单词。本文中,使用TF-IDF方法计算词的权重,按照降序方法提取特征词,最终实现词云展示和词频度的统计。
TF(Term Frequency)表示特征出现在单个文档中的频率。其中TFi, j是关键词i在文档j中出现的频率,Ni, j是指关键词i在文档j中出现的次数,K是文章中词的个数。式(1)是TF的计算公式:
(1)
IDF(即Inverse Document Frequency),表示逆文档频率。| D |是语料库中文档的总数,| dj ∈ D:ti ∈ dj |是出现词语i的文档的总数。例:语料库里有40篇文档,其中的20篇有同样的固定单词i,单词i的频率就是40/20,即1/2,逆文档频率就是1/2的倒数。式(2)是IDF的计算公式:
(2)
2.2 基于CNN的情感倾向性分析
将整理好的数据集读入txt(文本进入CNN的格式要求)文件中,使用CNN提取特征[6,7]。使用CNN进行文本情感倾向性分析的时候,文本必须是已经做好预处理工作。进入CNN后进行文本特征的提取,在提取的时候可以使用多个卷积层,一个卷积核只能提取一个特征,第一次卷积提一个低程度的特征,第二次就会加强,主次类推,但次数过多也会过犹不及,这个过程也叫特征降噪或特征浓缩,目的是得到一个可靠的特征进行文本情感分类的判别。CNN分类器如图3所示。
1)输入层:将已经做好预处理的数据训练成词向量依次排列成矩阵的形式输入到网络中。
2)卷积层:对已经输入到网络的数据进行特征提取,然后做情感倾向性判别。卷积之后通过激活函数进行特征的提取,激活后的值就可以作为卷积层的输出。
3)池化层:与卷积层类似,也叫下采样,也是对特征的压缩,即整体浓缩。池化层并非是CNN的必要网络层,在一些新设计的CNN中,很多并未使用。
4)全连接层:对提取到的特征进行分类得出最后结果并输出,在这里我们就能看到文本的情感倾向性判别的结果了。
2.3 基于LDA的主题提取
LDA(Latent Dirichlet Allocation)模型其实是一种生成概率的模型,通过文档和单词在句子中的离散程度来抽取文档中蕴含的主题模型,生成集各种意见与观点为一体的主题词,进而能挖掘出文本中隐藏的观点[8]。在LDA中,主题分布和词分布都是不确定的,它为主题分布和词分布分别加了两个Dirichlet先验,Dirichlet的概率密度函数为式(3)和式(4)所示。由此可得,Dirichlet分布是多项式分布的共轭分布[9,10]。
(3)
(4)
在使用LDA主题提取模型时,每篇文档中每个词的生成是需要使用两次Dirichlet分布:第一次是从doc-topic中得到所有词的topic;第二次是从topic-word中生成N个word。LDA主题提取生成模型的结构图如图4所示。
2.4 词云表示
使用TF-IDF算法计算主题词权重后生成一个单词表,把每条数据文本做成一个单词表,从这个单词表中选取10个词进行相关的词云表示,通过词云的方式展现出来。最后导入LDA包,获得到所爬取数据的隐含主题,选择生成主题的个数,进而挖掘出文本的隐含含义。
3 实验结果与分析
3.1 实验环境
本文提出的舆情分析智能平台搭建在Windows 10操作系统中,使用Python开发语言,在Fensorflow平台实现。
3.2 数据集的获取与介绍
本文实验数据来自自己爬取的微博情感数据,将此数据作为情感标注语料,由11名作者做情感交叉标注,对于有异议的数据再进行二次标注。本文手动收取原始数据10 000多条,经过去重、无情感的转发以及广告,可作为模型训练的数据由4 811条,其中积极情感1 348条,消极情感1 606条,中性情感1 855条。选取3 500条作为训练集,500条作为测试集,剩余的118条作为验证集。
3.3 TF-IDF词频度分析及词云展示
词频度的分析能够体现出一个热点的精华;词云的展示能够体现出每天热点呼声最高的词。通过词频度的分析和词云的展示能够快速正确的掌握舆情的倾向和大众的意向。
本文采用TF-IDF算法针对每条热点信息,分别从微博和微信公众号两个不同的来源选取出5个关键词进行词频度的分析,可以直观地了解到在微博和微信公众号两个信息不同来源的地方,针对同一条热点信息的敏感词和情感倾向,有利于做情感的进一步分析和捕捉工作。本网络舆情分析智能平台不仅能以柱状图进行展示,还可以以折线图和数据视图进行展示,当光标定位在某个词时,可以显示出这个词的具体词频。针对“华为正式发布鸿蒙手机操作系统”热点信息,微博、微信公众号、TF-IDF分析与网页TF-IDF分析折线图和数据视图如图5所示。
从TF-IDF词频度的分析可以看出,微博更注重于事件的本身,而微信公众号里则是添加了一些对事件的分析。
词云的展示,可以直观看到每日热点热议,即呼声最高的词。词云展示的词是通过TF-IDF算法从每日热点的文本集合中选取10个词进行展示。微博、微信公众号和网页分析的词云展示如图6所示。
3.4 基于CNN情感倾向性分析实验结果
将收集标注好的数据集经过处理后依次排列成文本矩阵的形式输入到CNN网络中,训练出情感分类模型。再训练模型时,将数据集划分为训练集、测试集和验证集,按照7:1.5:1.5的比例划分,随机打乱并保证训练集、测试集和验证集中包含每一类情感,保证数据的正常运行和模型的准确性。情感标注数据一共722条,其中积极情感197条,中性情感285条,消极情感240条。微博、微信公众号和网页情感倾向性分类的饼状图如图7所示。
3.5 基于LDA主题提取实验结果
LDA主题提取实验的训练过程:
1)按照先验概率p(di)选择一篇文档di。
2)重新扫描语料库,从Dirichlet分布α中取样生成文档di的主题分布θi,主题分布θi由超参数为α的Dirichlet分布生成。
3)从主题的多项分布θi中取样生成文档di第j个词的主题zi, j。
4)从Dirichlet分布β中取样生成主题zi, j对应的词语分布Φzi, j,词语分布Φzi, j由参数为β的Dirichlet分布生成。
5)从词语的多项式分布Φzi, j中采样最终生成词语wi, j。
微博、微信公众号和网页LDA权重比分析如图8所示。在LDA权重比分析中,也可以切换为折线图和数据视图的展示LDA权重比分析结果。
4 结 论
本实验通过爬取微博、微信公众号和网页信息,处理后进行情感倾向性分析与舆论倾向展示,清晰直观的体现舆情热点,为舆情监测提供有力手段。
参考文献:
[1] 潘晓英,陈柳,余慧敏,等.主题爬虫技术研究综述 [J].计算机应用研究,2020,37(4):961-965+972.
[2] 雍龙泉,贾伟,张建科.基于爬虫技术与智能算法的网络舆情监测 [J].智能计算机与应用,2021,11(4):35-38.
[3] 赵宸,刘建华.基于Django的分布式爬虫框架设计与实现 [J].计算机与数字工程,2020,48(10):2495-2498.
[4] AMIR J R,SEYED HASSAN M H. Lightweight formalization and validation of ORM models [J].Journal of Logical and Algebraic Methods in Programming,2015,84(4):534-549.
[5] 李昌兵,赵玲,李晓光,等.基于TF-IDF加权的卷积神经网络文本情感分类模型[J/OL].重庆理工大学学报:自然科学,2021:1-6[2023-04-19].http://kns.cnki.net/kcms/detail/50.1205.
T.20210425.1252.002.html.
[6] KIM Y. Convolutional Neural Networks for Sentence Classification [J/OL].[2023-04-18].https://arxiv.org/pdf/1408.5882.pdf.
[7] 徐凯旋,李宪,潘亚磊.基于双向编码转换器和文本卷积神经网络的微博评论情感分类 [J].复杂系统与复杂性科学,2021,18(2):89-94.
[8] 钱旦敏,郑建明.基于LDA主题模型的信息服务文献主题提取与演变研究 [J].数字图书馆论坛,2019(10):16-22.
[9] BLEI D M,NG A Y,JORDAN M I. Latent Dirichlet Allocation [J].Journal of Machine Learning Research,2003(3):993-1022.
[10] 王靜茹,陈震.基于隐含狄利克雷分布的文本主题提取对比研究 [J].情报科学,2018,36(1):102-107.
作者简介:马燕妮(1994.01—),女,回族,宁夏银
川人,助教,硕士研究生,主要研究方向:自然语言处理。
