基于XGBoost 和云模型的地质灾害易发性评价
2024-01-18胡舫瑞王咏林
张 威,胡舫瑞,綦 巍,彭 琳,王咏林,陈 枫
(辽宁省自然资源事务服务中心,辽宁 沈阳 110044)
0 引言
我国是世界上地质灾害最严重、受威胁人口最多的国家之一。以2021年为例[1],全国发生地质灾害4 772起,造成91 人死亡失踪,成功预报地质灾害905 起,涉及可能伤亡人员2.5 万余人。地质灾害多发频发,已严重威胁人民群众生命财产安全。因此,地质灾害易发性评价工作尤为重要。
地质灾害易发性评价是对地质灾害活动程度和危害能力的综合判别,受多种因素影响。地质灾害易发性因素可分为直接因素(如地貌因素、地质因素等)和间接因素(如气象因素、人类活动因素等)。间接因素促进了地质灾害的发生,而直接因素是区域是否具备地质灾害发生的基本条件。
国内外学者对地质灾害易发性进行了大量的研究。MOHAMMADY 等[2]基于信息量法采用坡度、坡向、高程等13 个因素对伊朗Golestan 地区地质灾害易发性进行评价。易靖松等[4]基于信息量法和层次分析法,采用地形地貌、工程地质岩组、结构类型等7 个因素分别对四川省阿坝县段的地质灾害易发性进行评价。黄艳婷等[5]基于层次分析法采用公路距离、流域距离、断层距离等11 个因素对藏东南地区泥石流地质灾害的易发性进行评价。许冲等[6]基于逻辑回归模型采用坡度、坡向、高程、与水系距离等8 个影响因子对汶川地震区地震滑坡易发性进行评价。陈水满等[7]基于人工神经网络采用坡度、坡高、岩性、岸坡结构类型等11 个影响因子构成基本评价体系对福建南平市滑坡易发性评价。HONG 等[8]基于随机森林模型采用高程、坡向、地形湿度指数等15 个因子对江西省广昌县滑坡易发性评价。
总体上看,基于信息量法和层次分析法[3-5]进行定量与定性分析评价地质灾害易发性的方法虽然操作简便易行,但是主观性较强,结果也比较抽象,难以反映各因子之间的权重关系。与传统的研究方法相比,基于机器学习的评价模型[6-8],能很好地解决传统模型中对非线性关系表达的问题,提高了地质灾害识别的精度,但是不能很好地反映各因子权重,可解释性不强。且地质灾害易发性判别有其自身的随机性和模糊性,以上单一评价模型无法获得很好的效果。针对这些问题,本文提出基于XGBoost 和云模型进行地质灾害易发性评价。
XGBoost 是一种新兴的基于决策树的改进集成算法,被地质、气象、能源和医学等领域广泛使用[9-14]。
该算法对数据质量要求不高,将多个学习器进行组合,通过优势互补达到强学习器的效果,可直观输出特征因子对结果的贡献值分数,具有准确率高、解释性强、不易过拟合等优势,能很好的反映各因子权重,避免人为干扰。云模型是李德毅等[15]首先提出的,可以将定性描述的随机性和模糊性问题转化为定量化的评价模型,用以解决因子分级中带来的随机性和模糊性问题[16-19]。本文根据辽宁朝阳市地质灾害资料,通过XGBoost 算法确定地灾因子权重,在此基础上利用云模型将因子分级的模糊性问题转化为定量问题,建立了朝阳市地质灾害易发性评价指标体系,进而评价地质灾害的易发性。
1 模型方法
1.1 XGBoost 模型
XGBoost 模型是CHEN 等[20]在集成算法的基础上提出,解决了集成算法中各个学习器之间只能串行,时间开销大的问题。
XGBoost 是一个寻找损失函数最小化的过程,集成了多棵分类决策树,对于一棵有t个分枝决策树,可表示为:
ft(xi)——决策树模型。
XGBoost 模型构建目标函数如下:
式中:i——数据集中样本号;
n——为所建导入第j颗树的数据总量;
t——建立全部树数量;
Ω(f)——正则惩罚项,其目的是防止模型过拟合。
Ω(f)可表示为:
式中:γ、λ——正则系数;
T——末端叶子节点的个数;
ω——末端叶子节点的权重。
损失函数L作二阶泰勒展开可得:
式中:gi、hi——损失函数L关于变量x的一阶与二阶导数。
通过迭代找到使目标函数ft取值最小,即完成模型的训练过程。
1.2 云模型
1.2.1 云模型及云发生器
云模型使用期望(Ex)、熵(En)和超熵(He)3 个数字特征来定量描述一个不确定性概念。云发生器是云的具体实现方法。其中由云的数字特征C(Ex,En,He)生成云滴算法称为正向发生器[21],用来实现定量数值和其定性语言值之间的不确定性转换。反之将一系列的精确数据有效转换为由数字特征表示的定性概念的算法称为逆向云发生器[22]。本文通过python 语言实现了正、逆向云发生器的编译。云模型(Ex=0,En=1,He=0.1)的示意图如图1 所示。

图1 云模型示意图Fig.1 Schematic diagram of cloud model
1.2.2 综合云模型
假设集合中有n朵云{C1(Ex1,En1,He1),C2(Ex2,En2,He2),···,Cn(Exn,Enn,Hen)},权重向量为ω={ω1,ω2,···,ωn}。若指标间相互独立,相关性较小,则运用虚拟云理论中综合云算法[23],综合云Cn(Exn,Enn,Hen)计算公式如下:
式中:ωi——指标i的权重;
Exi、Eni、Hei——相应指标云模型的数字特征参数。
1.2.3 云相似度
将评价对象云模型参数与评价指标云进行比较,分别定义云向量它们之间的余弦夹角称为相似度sim(i,j)[24],公式如下所示∶
利用式(8)来计算评价指标云与评价指标云的相似度,并依照最大相似度原则,相似度最高所对应的评价等级即为最终的评价等级。
1.3 易发性评价体系
基于XGBoost 和云模型,本文提出的地质灾害易发性评价体系的技术步骤如下:
(1)通过收集研究区的详细地质灾害调查资料,选取易发性影响因子;
(2)利用ArcGIS 平台提取各因子相关数据,分析各因子之间的相关性和分布规律,并对其进行归一化处理;
(3)使用网格搜索法,选定XGBoost 超参数取值,根据归一化后的数据进行模型训练,计算得到各因子的权重;
(4)根据规范、技术要求以及野外实践等分级标准构建评价指标体系,合理划分指标体系结构;
(5)利用编译好的正向云发生器程序绘制评价指标云图;
(6)针对研究对象生成各因子的单朵云模型并确定每个因子指标权重ωij,结合指标权重进行综合云计算,绘制评价对象综合云模型;
(7)通过评价对象综合云模型参数与评价指标云图的相似度,相似度最高所对应的评价等级即为最终的评价等级。
2 研究区概况及数据源
2.1 研究区概况
研究区朝阳市位于辽宁省西部。地处辽西山地丘陵地貌区,北接内蒙古黄土高原,东邻渤海沿岸和松辽平原。
地势由北西向南东呈阶梯状降低,属于塔里木—华北板块。南北横跨2 个二级构造单元,南部为华北陆块,北部为天山-赤峰造山系。区内NE 向分布大量中生代盆地群,断裂均为倾向盆内的正断层(图2)。其中侏罗纪盆地的盆缘断裂在盆地挤压褶皱时常反转为背向盆地的逆断层或逆冲断层。朝阳地区地层工程地质条件可以分为第四系松散土类、碳酸岩类、碎屑岩类、花岗岩类、片麻杂岩类、片岩、变粒岩、浅粒岩类等。

图2 朝阳市地质情况示意图Fig.2 Location map of the study area
2.2 数据来源
研究区是辽宁省地质灾害较严重区域,地质灾害类型以崩塌、滑坡为主。依据《辽宁省朝阳市地质灾害风险调查评价成果报告》中最新的地质灾害风险普查资料,研究区内共有地质灾害隐患点189 个。通过总结研究区地质灾害调查成果以及过往灾害发生历史情况,本文选取了12 个易发性影响因子,分别为高程、坡度、坡向、归一化植被指数、多年平均降水量、工程地质岩性、地质构造、人口密度、地下水涌水量、地质灾害点至公路、铁路和水系的距离。为便于统计与分析,根据研究区大小将整个研究区按照500 m×500 m 的格网单元进行划分,共划分为175 520 个栅格单元。各因子与研究区地质灾害点的空间位置如图3 所示。
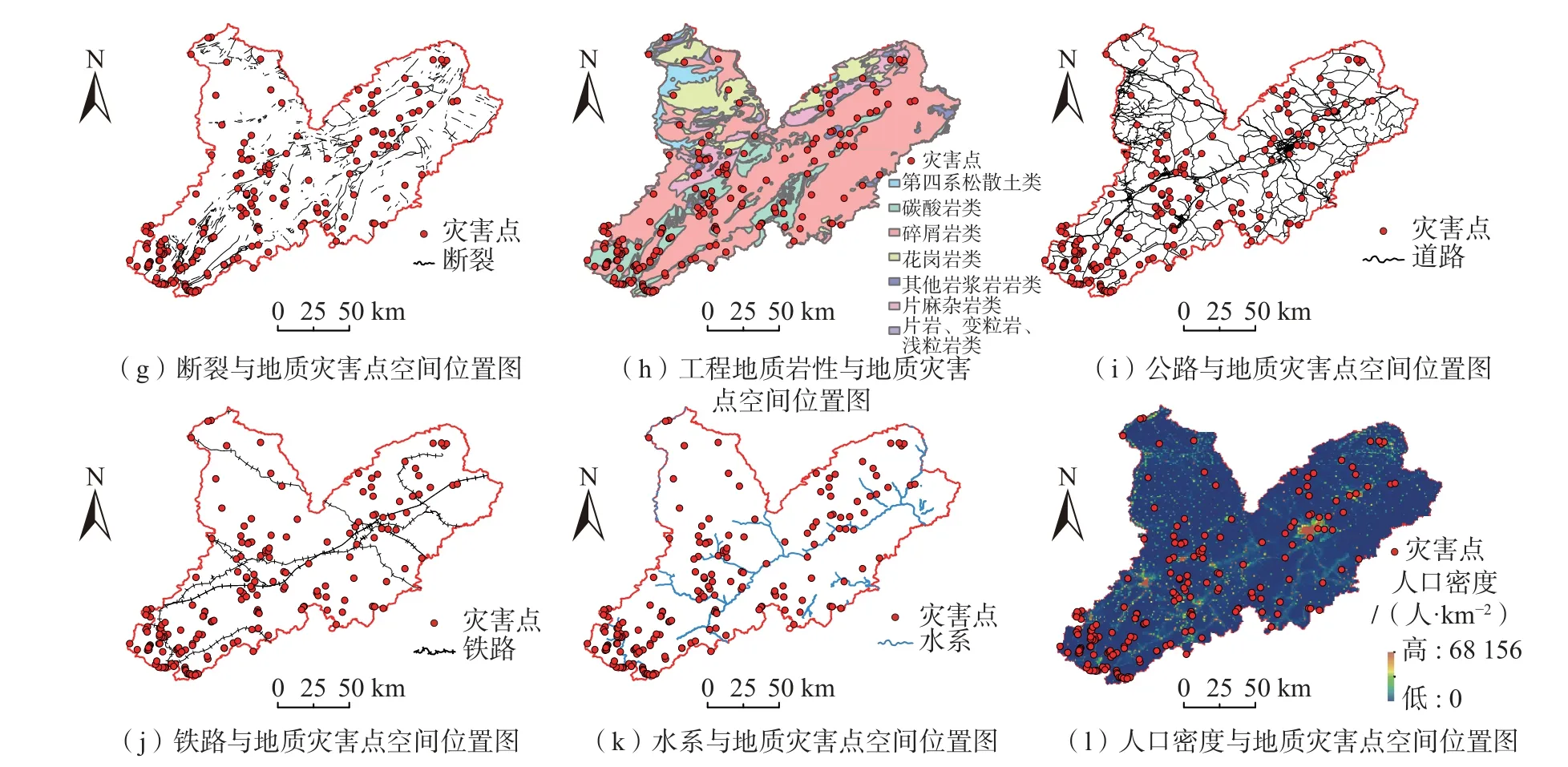
图3 地质灾害易发性因子与地质灾害点关系图Fig.3 The relationship between geological hazard susceptibility factors and disaster points
3 地质灾害易发性因子权重计算
3.1 易发性因子选取与空间分析
对选取的12 个因子进行相关性研究,结果如图4所示。12 个因子之间的相关性均小于0.5,即各因子之间相对独立,无强关联性,满足XGBoost 算法对因子独立性的要求。
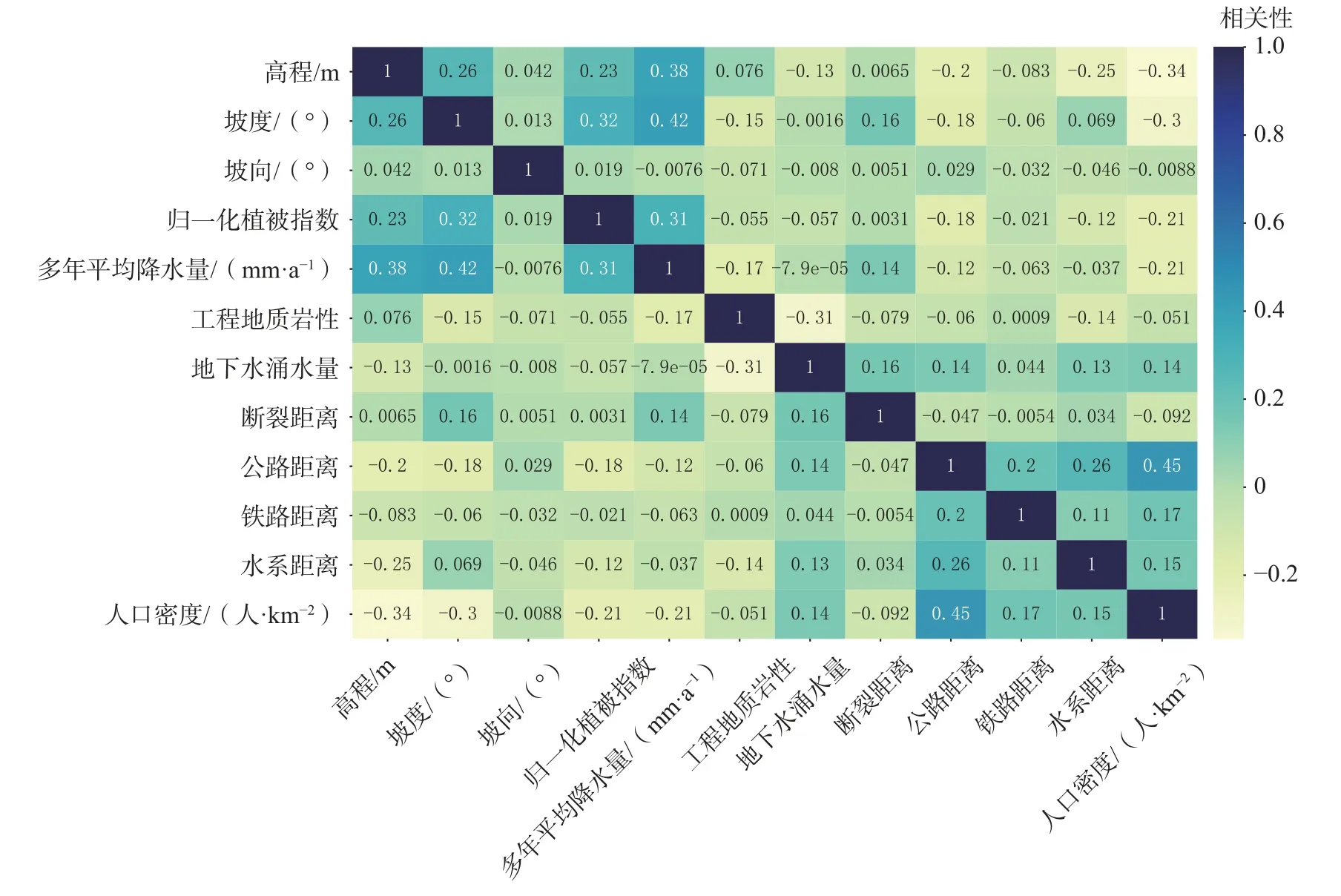
图4 易发性因子相关性图Fig.4 Correlation diagram of susceptibility factors
3.2 数据处理及建模
研究表明在进行易发性区划中,样本灾害点与总样本点的比例在1∶5~1∶10 时构建的模型效果最好[25]。本文经过多次实验,最终选取样本灾害点的比例为1∶5,即选取950 个非灾害点样本。对地质灾害点至地质构造、公路、铁路、水系等线性因子的距离依照<500 m,500~<1 000 m,1 000~<1 500 m,≥1 500 m 以上分为4 个等级,距线性因子500 m 内定义为第4 等级,以此类推。为了消除坡度和人口密度的数据倾斜问题,对上述2 个因子的数据进行了Log 化处理,12 个易发性因子的数据分布如图5 所示。

图5 易发性因子数据分布图Fig.5 Data distribution of susceptibility factors
采用网格搜索法对XGBoost 模型的超参数进行优化,并将数据按照80%和20%的比例将总样本划分为地质灾害训练集与测试集,并进行建模计算。样本与总体ROC 曲线及P-R曲线如图6 所示。结果表明得到的参数在地质灾害测试准确率AUC=82.7%,地质灾害总体预测准确率AUC为96.5%,取得了良好的学习效果。

图6 样本与总体ROC 曲线及P-R 曲线Fig.6 ROC curve and P-R curve for sample and overall population
整理得到的易发性因子权重分数如图7 所示。由图7 可知影响研究区内地质灾害发生的易发性影响因子重要程度依次为:坡度、多年平均降水量、归一化植被指数、高程、人口密度、坡向、地下水涌水量、公路距离、工程地质条件、断裂距离、水系距离、铁路距离。
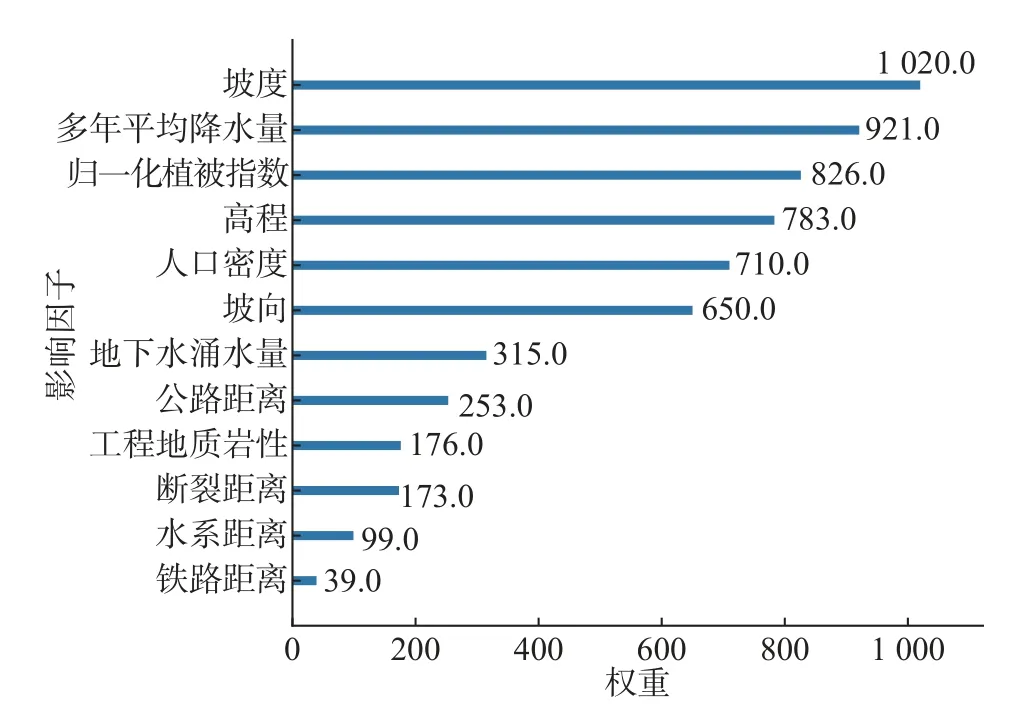
图7 易发性因子权重分数图Fig.7 Weighted scores of susceptibility factors
因子权重分数归一化之后可得其因子权重如表1所示。
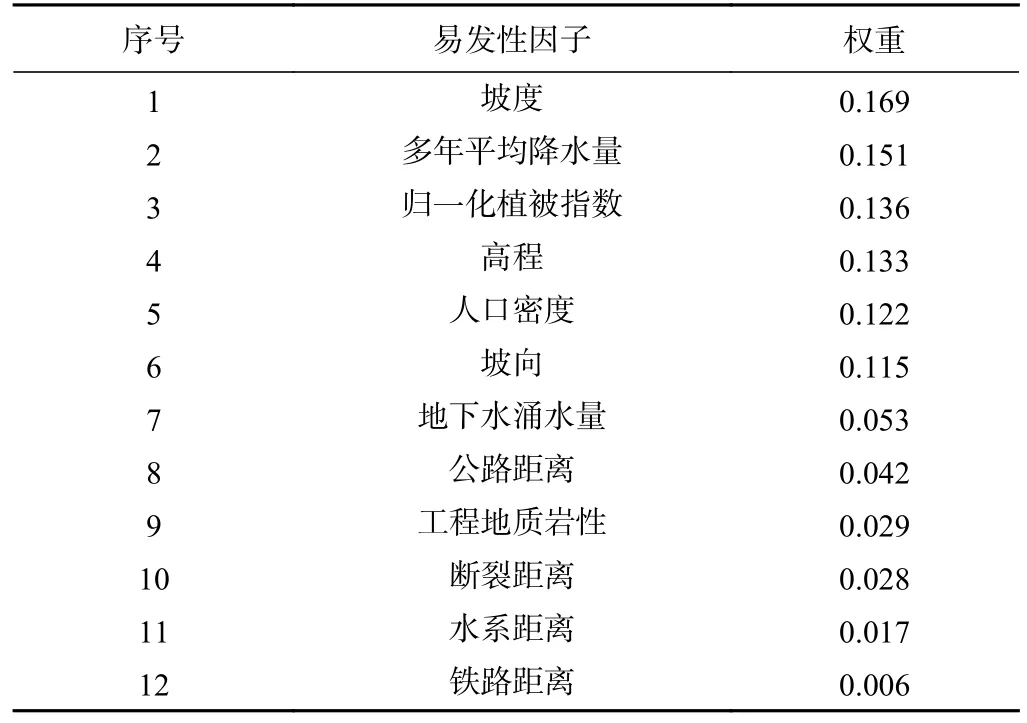
表1 影响因子权重表Table 1 Weight table of impact factors
4 构建评价指标体系
依照《滑坡崩塌泥石流灾害调查规范(1∶50 000)》(DZ/T 0261—2014)、《地质灾害风险调查评价技术要求(1∶50 000)》以及地质灾害野外调查实践确定指标分级,形成评价指标体系。将指标分级划分为4 级,如坡度分为平台、缓坡、陡坡、悬崖,多年平均降水量采取黄金分割法分为好、中等、较差、差。具体的因子分级见表2。

表2 影响因子分级表Table 2 Grading table of impact factors
对于“不易发”,“高易发”的判断较为精准,而对于“低易发”,“中易发”的概念认知较为模糊。将论域[0,10]划分为4 个评级区间,其中0 和10 分别为“不易发”与“高易发”的期望值。利用模糊逻辑概念结合黄金分割法[26],可以计算出“中易发”和“低易发”的期望值为6.91、3.09。本研究中取He=0.1,利用正态云的性质可以得到各评价等级的En值,其计算公式为:
综上所述可计算出的指标分级模型表示为:高易发(10,1.031,0.1),中易发(6.91,1.27,0.1),低易发(3.09,1.27,0.1),不易发(0,1.031,0.1)。各评价等级对应的评价云图见图8。
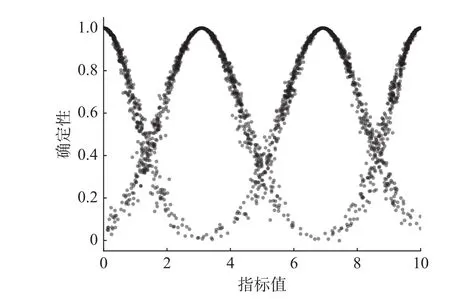
图8 评价指标云图Fig.8 Cloud map of evaluation indicators
在地质灾害实地调查的基础上,每个评价单元的易发性因子进行评价,得到每个评价单元的云评价指标。根据表1 中的易发性影响因子权重及式(7),计算出每个评价单元的综合云。在求得评价单元综合云的基础上,利用云相似度式(8)计算云模型隶属度关系,最终得到每个评价单元的易发性评价。
5 工程应用
评价单元大东山位于朝阳市龙城区边杖子乡林杖子村东山组的斜坡地带(图9),为龙城区西北城乡结合部。于2017年发生滑动,现场监测发现本点仍有变形发生,复滑可能性大。经过实地调查发现,滑坡南北长175 m,东西宽95 m。本点高程在331 m,属于高丘陵区。多年平均降雨量为549.3 mm,气象条件为较差。坡度为26°,属于陡坡。威胁人口20 人,滑坡主滑方向为242°。归一化植被指数为0.4,归一化植被指数差。地下水涌水量10 L/s,富水性好。距公路距离为1 000 m。工程岩性为泥质粉砂岩,灾害点距断裂较近,距水系、铁路距离较远。

图9 大东山滑坡正射影像Fig.9 Orthophoto image of Dadongshan landslide

图10 总体评估等级云相似度图Fig.10 Cloud similarity graph of overall evaluation grades
根据调查,本评价单元的云模型评价值如表3 所示。可通过式(7)计算得到本评价单元综合评价的云模型数字特征分别为(8.57,1.135,0.1)。利用Python 绘制综合评价云图,与评价指标云叠加,图 10 是将单元综合评价云与评价指标云叠加后所绘得,其中评价指标云图为红色,综合评价云图为黑色。

表3 大东山滑坡影响因子云模型评价值Table 3 Cloud model evaluation values of impact factors for Dadongshan landslide
利用式(8)可以计算本评价单元综合云与评价指标云夹角值,结果如表4 所示。

表4 总体评估等级云相似度表Table 4 Cloud similarity table of overall evaluation grades
表4 计算结果可以看出本评价单元易发性评价为高易发,与本灾害点的实际情况相符。
6 结论
(1)通过XGBoost 算法获得了朝阳地区地质灾害易发性因子权重系数。结果表明地质灾害测试预测成功率AUC为82.7%,总体地质灾害预测准确率AUC为96.5%。XGBoost 模型取得了良好效果,得到的地质灾害易发性因子权重系数较为合理,重要程度依次为:坡度、多年平均降水量、归一化植被指数、高程、人口密度、坡向、地下水涌水量、公路距离、工程地质岩性、断裂距离、水系距离、铁路距离。
(2)在获得地质灾害易发性因子权重系数的基础上,采用云模型创建了朝阳市地质灾害易发性评价指标体系。依据相关规范、调查技术要求以及野外调查实践将指标分级划分为4 级,利用Python 语言确定了评价指标云图,形成评价指标体系。
(3)选取朝阳市大东山滑坡作为评价单元对建立的朝阳市地质灾害易发性评价指标体系进行验证,发现该灾害评价单元的云模型数字特征为(8.57,1.135,0.1),与评价指标云图对比可判断该点的易发性为高易发,与实际情况吻合。验证结果表明本文提出评价指标体系可用于朝阳市的地灾易发性评价,该指标体系构建方法可对地质灾害易发性评价提供参考。
