企业所得税税收风险识别中随机森林算法的应用研究
2024-01-17卞平原
卞平原
(池州职业技术学院 国际经济贸易系,安徽 池州 247000)
纳税人的数量与规模正随着经济的快速发展和经济主体的多元化而快速扩张,与此同时,也出现一些偷税漏税的行为。[1]我国一直致力于改革税收征管模式,其中的重点内容就是要防范税收流失并最大程度规避税收执法的相关风险。[2]风险管理是通过各种信息化和非信息化的手段对可能出现的各类风险进行识别、分析和解决,尽可能降低风险带来的不利影响和后果。[3-4]风险管理中的风险识别要求税务机关在税收征管工作中确定所有可能带来损失和不确定性的风险来源,及时评估其危害度和可能造成的不利后果,并提前做好应对准备工作。[5-6]企业所得税具有税务重、难以转嫁和计算复杂的特点,更容易出现纳税人出于主观意愿或无意识的偷税漏税现象。[7]研究基于大数据背景,对随机森林算法做出了相应的改进,并将其用于企业所得税的税收风险识别中,旨在为税务机关开展税收风险管理提供参考。
1 随机森林算法在税收风险识别中的应用研究
1.1 基于决策树约简的改进随机森林算法
随机森林(Random Forest,RF)算法是使用多个分类回归树(Classification And Regression Tree,CART)对数据样本进行训练和预测的一种分类器,但是RF算法较决策树分类器拥有更优秀的泛化能力和分类效果。[8-9]研究在RF算法的基础上,根据决策树的分类精度和树间相似性进行决策树数量约简,进一步提高RF算法的分类性能。改进后得到的基于决策树约简的随机森林算法(Random forest algorithm based on decision tree reduction,RFDTR)的流程图如图1所示。
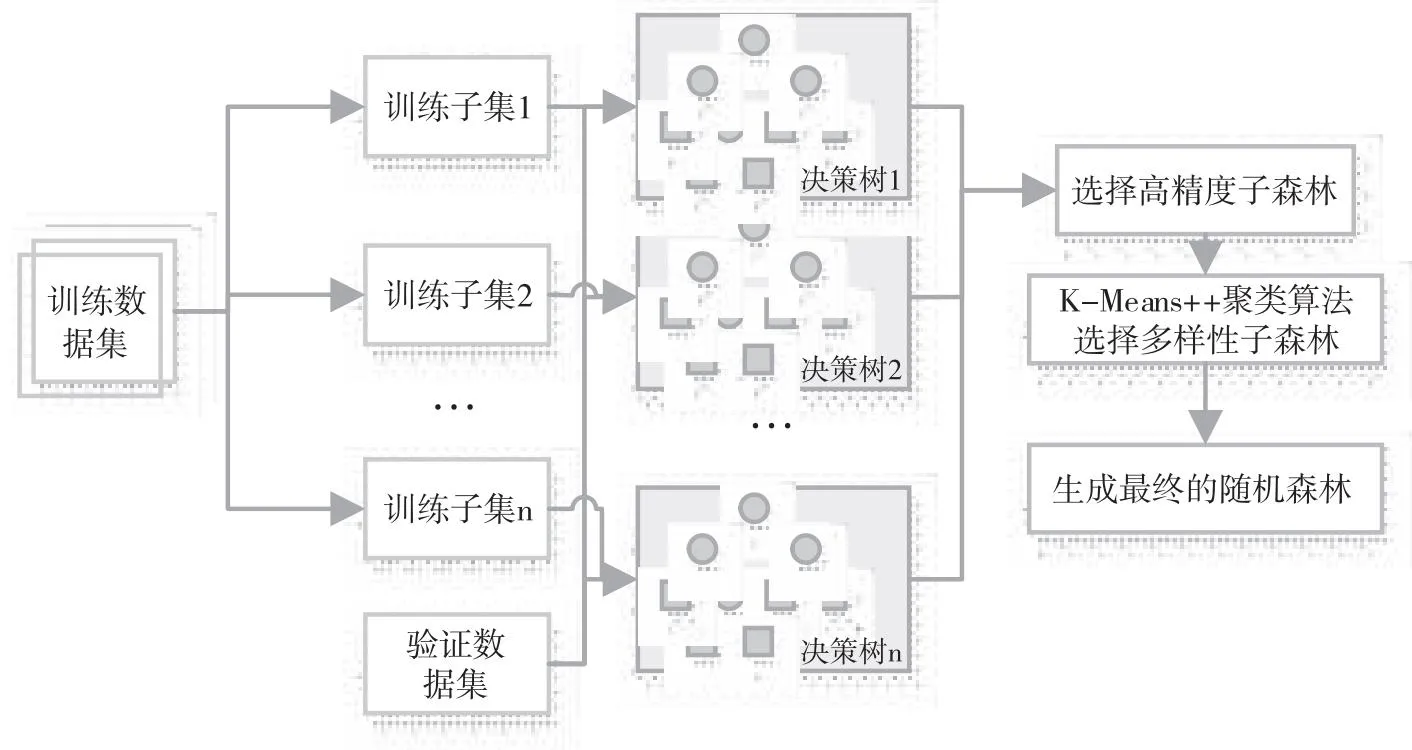
图1 RFDTR算法的流程图
由图1可知,RFDTR算法主要包括两个部分,一为传统的RF算法,二为约简决策树过程。通过约简的方式可去除不符合要求的决策树模型,将留下来的树组合为子森林,以此来减少模型存储和预测时间的成本。RF算法通过bootstrap抽样进行有放回地抽取原始样本后,采用CART构建基分类器模型。具体方式是通过基尼指数最小化准则或均方误差(Mean Average Error,MAE)最小化准则从分裂特征集中选择最优分裂特征和切分点用于分类或回归。如式(1)所示计算样本集合D的基尼指数G(D)。
(1)
式(1)中,Pk为第k类样本所占的比例,K为样本类别的数量。假设某一个特征H有n个取值,那么可以定义样本集合D在H已知的情况下的基尼指数G_index(D,H)如式(2)所示。
(2)
根据式(2)可得到基于基尼系数的最优划分特征标准。然后需要对决策树进行约简,约简操作分为选取高精度子森林和聚类选择多样性子森林两步。选取高精度子森林时利用验证集计算单棵决策树的AUC值,将AUC值作为决策树的分类精度。然后找到比原始森林F中的单棵决策树的分类精度平均值A_Auc更高的子森林SubF,如式(3)所示。
(3)
式(3)中,ti是第i棵决策树,Auci是其AUC值。该选取方式选择决策树的数目是不固定的,如果子森林SubF中的决策树数量超过了原始森林中决策树数量B的2/3,那么将SubF作为待聚类子森林,否则就降低选择标准继续选取高精度决策树。具体的策略是计算所有决策树AUC值的标准差σ,然后如式(4)所示继续选择决策树,直到组成待聚类子森林。
SubF={ti:Auci≥A_Auc-σ}
(4)
选取高精度子森林的操作在一定程度上导致了随机森林整体多样性下降,在进行分类时可能会出现分类结果集中、相似度高的情况。在这种情况下出现分类错误就会导致与之相似度高的其他决策树也出现分类错误。研究采用改进的K-Means++聚类算法对待聚类子森林SubF进行聚类,该算法的运行流程如图2所示。
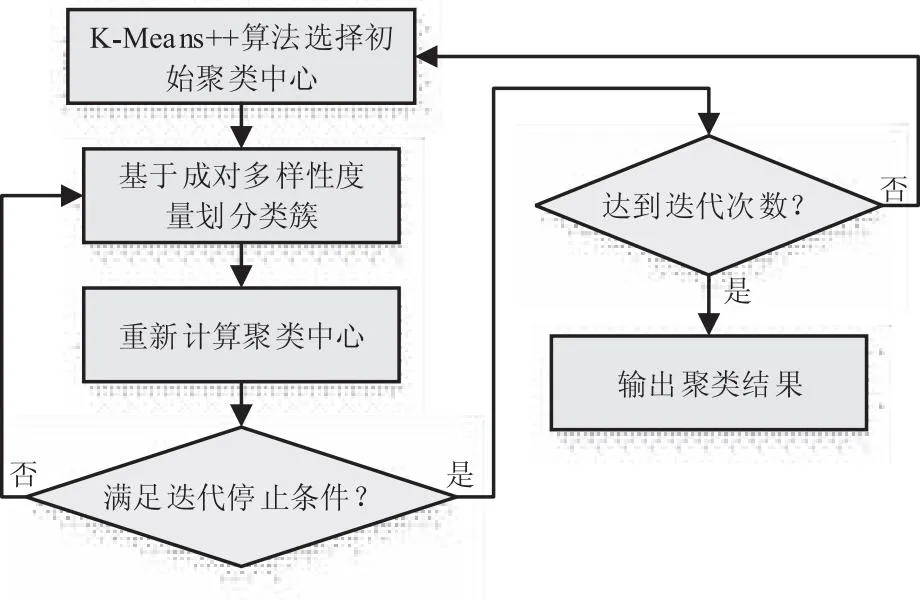
图2 K-Means++聚类算法的流程
如图2所示,算法首先从SubF对验证样本的分类结果数据X中选择M个数据作为初始聚类中心。具体步骤是随机选择一个样本作为初始聚类中心,然后遍历数据并将每个数据x与聚类中心成对多样性度量作为两者的最短距离Dist(x)。Dist(x)越大的点越有可能被选取为聚类中心,其被选取的概率Pc如式(5)所示。
(5)
然后使用轮盘法选择下一个聚类中心,直到选择出的M个聚类中心保持不变或得到最大迭代次数。该算法使用轮廓系数来衡量聚类效果并确定最佳K值。不同簇的轮廓系数如式(6)所示进行计算。
(6)
式(6)中,DAa和DAb分别表示样本点xi到该类簇和最近类簇中所有样本点的平均距离。整体的轮廓系数如式(7)所示。
(7)
式(7)中,N为数据集中的样本数量。通过聚类选择高精度低相似的决策树组成随机森林后,对分类结果进行统计得到最终的预测结果,再使用如式(8)所示的简单多数投票决策得到最优的分类结果。
(8)
式(8)中,T(α)为测试样本α的组合分类模型;A为测试样本集中样本的数量。Y为输出变量;I(·)为指示性函数。
1.2 基于随机森林算法的风险识别模型构建与评价方法
税收风险广义上是指相关企业在进行纳税申报、申请退税、代扣代缴、开具发票等一系列涉税活动时,由于主观故意或者客观过失而发生的,在一定程度上违反了税务机关某些规定的,会影响行为人利益带来的不确定性。[10-11]房地产行业由于兼具实体与金融行业,其财务处理具有一定的复杂性。而房地产行业税收风险识别需要兼顾及时性和有效性。这是因为房地产行业的财务资料在较长的开发周期中如果出现保管不当、财务人员工作更替或业务水平不足的情况,就很容易造成财务数据的不真实性,进而影响相关税务机关的检查工作。为满足税收风险识别的任务要求,首先需要对相关企业的数据进行抽样、清洗和转换等预处理操作。税务核心征收数据为通过相关的查询途径,根据时间维度获取到的2020年某市房地产行业数据,来源于企业的纳税申报和税务登记。出于数据安全的考虑,相关数据已进行了相应的加密处理,如企业名称采用数字编号代替。数据清洗又称数据过滤,是通过剔除样本数据中不符合判定规则的数据来提高分析结果的准确率,具体包括了数据初始化、注销和非正常企业的去除和残缺或明显有误数据的删除等操作。然后研究以税务核心征收数据为风险指标建立的支撑,以企业依法纳税产生的申报数据为风险指标的选择依据,从资产、成本、费用和收入等角度建立了税收风险指标。企业所得税税收风险指标如表1所示。

表1 企业所得税税收风险指标体系
不同风险指标对于风险识别的影响程度是不相同的,因此在确定模型使用的风险指标体系后,还需要根据随机森林的重要性度量确定对识别结果影响最大的指标。对随机森林中的任一棵决策树,首先使用OOB数据计算其数据误差erOOB1(xi),再对OOB数据中所有样本的特征xi加入噪声干扰并重新计算误差erOOB2(xi)。对N棵决策树进行重复操作,如式(9)所示计算特征xi的重要性。
(9)
式(9)中,IM(xi)代表了变量的重要性,其数值大小与特征的重要性成正比。IM(xi)<0说明该变量有明显噪声,会对模型产生负面影响。研究选择正确率、精确率、召回率和F1分数四个指标来评估基于随机森林算法的风险识别模型的分类性能。F-Measure是精确率和召回率加权调和平均,如式(10)所示。
(10)
式(10)中,β∈[0,∞),其取值代表了对精确率和召回率的不同侧重,β=1时的结果,即为F1分数。
2 企业所得税税收风险识别模型的运行效率与识别结果
成功构建基于随机森林的企业所得税税收风险识别模型后,研究进行了模型参数选择与模型性能检验实验和企业税收风险识别实验。实验使用的税务核心征收数据为通过相关的查询途径,根据时间维度获取到的2020年某市房地产行业数据,数据来源为企业的纳税申报和税务登记。实验数据集中包含了该市2035户行业门类为房地产业的企业,通过数据清洗剔除667户企业数据后得到的最终实验样本为1368户。随机森林算法中有两个参数对算法的运行效率和分类结果有重要影响:决策树个数和每次随机属性的个数,两者与OOB误差率的关系如图3所示。

图3 随机森林相关参数的选择
从图3(a)中可以看出,随机森林中的决策树为300时,误差率有剧烈波动,此后个数一直增加到400,中间仍有小幅度波动。当决策树个数等于400时误差线趋于平稳,因此模型中设置决策树为400棵。观察图3(b)可以发现误差率最低点对应的属性个数为6,因此随机森林算法中参数mtry设置为6。随机森林算法的评估分析实验结果如图4所示。

图4 不同算法的ROC曲线图
图4所示的ROC曲线可以反映分类识别模型的敏感度和模型自身的特异性连续变量的客观评价依据。但当分类模型准确率相差不大时无法凭借肉眼判断优劣,这时就需要使用ROC曲线组成的图像面积数值来标识分给模型的好坏。这个面积数值在评价中被称为AUC,如图4所示,随机森林分类识别模型的AUC为0.95,而决策树的AUC仅为0.87,实验结果表明,随机森林算法具有较好的分类性能。企业所得税风险识别模型的性能检验结果如图5所示。

图5 企业所得税税收风险识别模型的性能
如图5所示,随机森林算法和改进的随机森林算法在7种算法中均拥有较高的正确率和F1值。而基于改进随机森林算法的识别模型的准确率和F1分数最高,分别为90.20%和88.70%,较次优秀的随机森林算法分别提升了5.13%和4.60%。同时改进随机森林算法识别模型的运行时间也是7种算法中最低的,较原始的随机森林算法减少了33.33%,既验证了改进措施的有效性,又表明识别模型可以有效识别企业所得税的税收风险。某房地产企业所得税税收风险识别结果报告如表2所示。
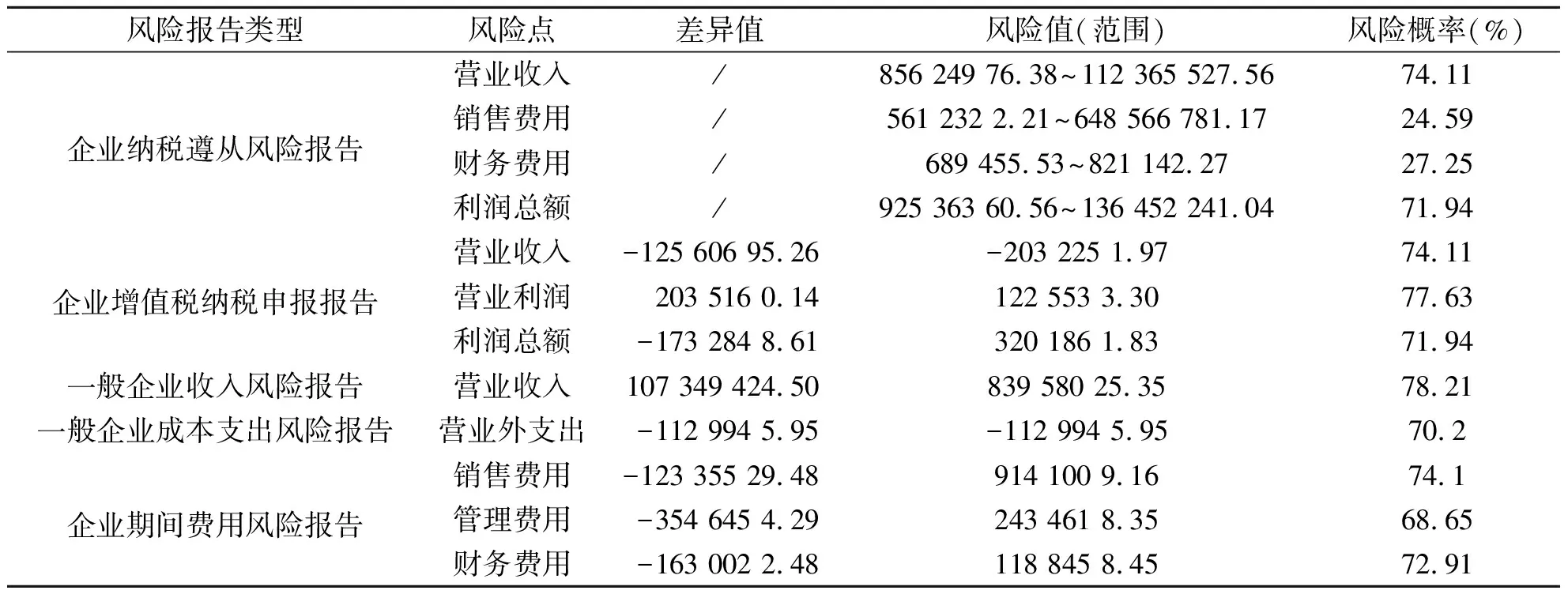
表2 某房地产企业所得税税收风险识别结果报告
由表2可知,该企业的申报值与模型判断值具有较大差异,其中风险点营业收入和利润总额的风险概率均在70%以上,证明该房地产企业明显有少缴纳企业所得税的问题,主要问题指向为少计营业收入和多计销售费用。在企业一般收入风险报告中,该企业的营业收入风险概率为78.21%,可能存在完工项目未及时结转收入、银行按揭带宽未及时确认收入、拆迁安置房收入未入账、租赁收入未申报等问题。一般企业成本支出显示营业外支出的风险概率为70.20%,存在较大差异,表明该企业可能存在的问题有:捐赠是否按税法政策合理扣除、是否存在自然灾害造成的非正常损失、资产盘点是否真实有效、是否按流程处置固定资产和无形资产等。具体的风险点需要通过核查企业账目信息才能确定。
3 结论
企业所得税是我国税务部门目前征收的18个税种中税源覆盖范围最广的,占税收收入总额的比重也在逐年上升。企业所得税对会计核算的要求很高,税收流失的风险也远高于其他税种。因此研究考虑到随机森林算法优秀的泛化性能和分类精度,通过约简决策树进一步提高RF算法的分类性能,在建立企业所得税税收风险指标体系的基础上构建了税收风险识别模型。在模型算法的性能评估实验中,RF算法获得了最高0.95的AUC,验证了随机森林算法用于风险识别模型的可行性。对不同算法构建的识别模型进行识别检测实验后发现,基于改进随机森林算法的识别模型准确率、F1分数和运行速度较原始的随机森林算法模型分别提升了5.13%、4.60%和33.33%,可以运用到企业所得税税收风险识别中。
