基于Fuzzy-BLS 的银川市大气污染物浓度预测研究
2024-01-17李付兰
李付兰
(宁夏环境科学研究院(有限责任公司)宁夏银川 750011)
近年来,银川市大气污染呈现复合型污染特征,颗粒物(PM10)、臭氧(O3)污染问题凸显,增加了空气污染防治的难度。银川市于2017 年建立了空气质量多模式预报系统,包括1 个统计模式和4 个数值模式,数值模式系统包括CMAQ、NAQPMS、WRF-Chem 和CAMx 模式[1]。由于WRF 模拟的气象场具有不确定性,排放清单的分配也无法达到非常精细且与实际排放情况完全相符,数值模式系统对一些具有复杂化学反应机制的污染物生成机理不太清晰,导致预报结果准确性不够,尤其是对O3浓度的预报数值偏差更大。目前,常用的大气污染物预测方法主要包括灰色GM(1,1)预测、多元回归预测、支持向量机SVM、长短期记忆网络(LongShort-TermMemory,LSTM)预测、RNN 预测等模型[2],对其优缺点进行分析,如表1 所示。

表1 不同大气污染物预测方法的比较
针对上述问题,本文基于气象台空气质量预报数据及实测数据,采用Takagi-Sugeno 模糊模型为支撑,构建基于Fuzzy-BLS 的大气污染物浓度预测模型,对《环境空气质量标准》(GB 3095—2012)明确的6 种常规大气污染物日平均浓度进行预测,并对预测精度进行评估。
1 基于Fuzzy-BLS 的大气污染物浓度预测模型
引入模糊推理系统,通过If-Then 规则对气象数据和污染物数据中所蕴含的专家经验进行提取、表述,以达到更好的预测效果。这里针对缺少物理信息模型的情况,采用自适应神经模糊推理系统(ANFIS),但该模型在特征维数以及输出结果等方面存在一定的局限性,为了保留模糊推理系统的优势,又使得模型便于本题目求解,引入基于宽度学习的Takagi-Sugeno模糊模型,称为Fuzzy-BLS[3]。Fuzzy-BLS 模型原理如图1 所示。
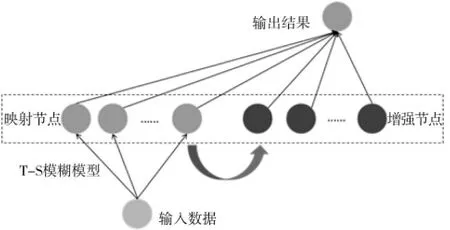
图1 Fuzzy-BLS 模型原理图
模型主要包含数据输入层,映射节点、增强节点层,输出结果层3 层。数据输入后,通过Takagi-Sugeno 模糊子系统进行初步计算,得到映射节点,同时将模糊子系统结果输入到增强层中,构建增强节点,将映射节点和增强节点通过岭回归求解伪逆的方式确定每个节点的权重,最终输出结果。具体流程如下。
在Takagi-Sugeno 模糊模型中,通常使用If-Then 规则,即式(1)。
用数学公式表示为式(2)。
其中参数可见式(5)~(7)。
得到增强节点输出,同时将Zi再进行处理,得到映射节点输出,即式(10)。
通过岭回归算法求解伪逆得到W,见式(14)和式(15)。
通过求解上述模型,即可得到大气污染物SO2、NO2、PM10、PM2.5、CO 的单日浓度值和O3的最大8 h 滑动平均浓度。
1.1 基于Fuzzy-BLS 的一次污染物浓度的预测模型
对PM2.5、NO2、SO2、CO、PM10一次污染物进行预测,输入数据主要是各污染物的预报浓度和实测浓度,经过模型训练与迭代,获得优化后的一次污染物浓度预测值。模型结构如图2所示。
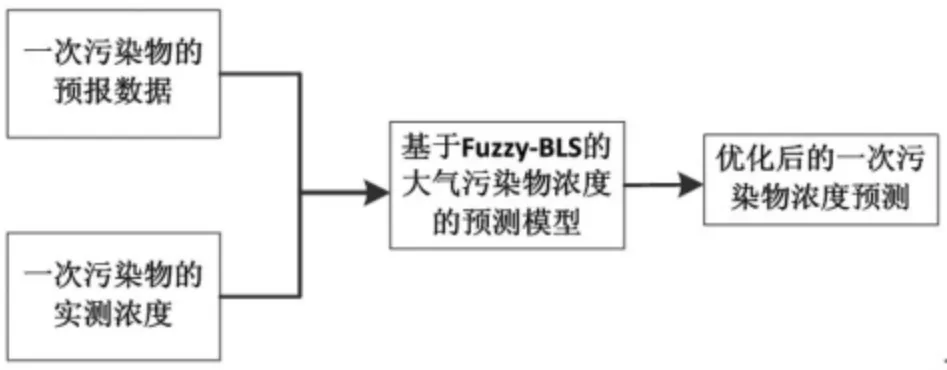
图2 基于Fuzzy-BLS 的一次污染物浓度预测模型
1.2 基于Fuzzy-BLS 的二次污染物浓度的预测模型
由于O3属于二次污染物,要考虑各种气象条件以及NOx的影响,故输入数据主要是O3的预报浓度、气象因子、NO2的预报数据。以实测的O3浓度,经过模型训练与迭代,获得优化后的O3浓度预测值。对于气象因子选择,本文通过PCA 降维法和相关性分析法进行气象因子的筛选,最终筛选出温度、湿度、风速、太阳辐射及雨量等因子。模型结构如图3 所示。
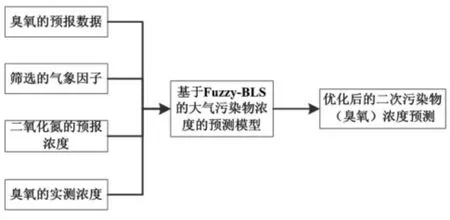
图3 基于Fuzzy-BLS 的二次污染物浓度预测模型
2 实例验证
2.1 模型评价指标
为了有效评价模型的性能,本文使用2 种模型评价方法,分别是MSE 和R2。MSE 可以估计训练出的预测值与实际的浓度值之差的平方的期望值,MSE 的值越小,说明污染物浓度预测的精确度越高。R2是指回归平方和与总离差平方和的一个比值,体现的是总离差平方和中能够由回归平方和来解释的比例,数值越大,模型就越准确,回归成效就越明显[4]。其计算如式(16)和式(17)。
2.2 模型验证
选取银川市2020 年1 月1 日—12 月31 日空气质量预报数据和实测数据,利用建立的Fuzzy-BLS 模型,预测6 种大气污染物的日平均浓度。同时将每种污染物的气象台预报浓度和模型预测浓度与实测浓度分别相减,计算二者的绝对误差[5-6],如图4 所示。

图4 6 种大气污染物预测浓度绝对误差图
利用6 种大气污染物的气象台预报浓度和Fuzzy-BLS 模型预测浓度,计算2 种预测方法的精度,计算结果如表2 所示。
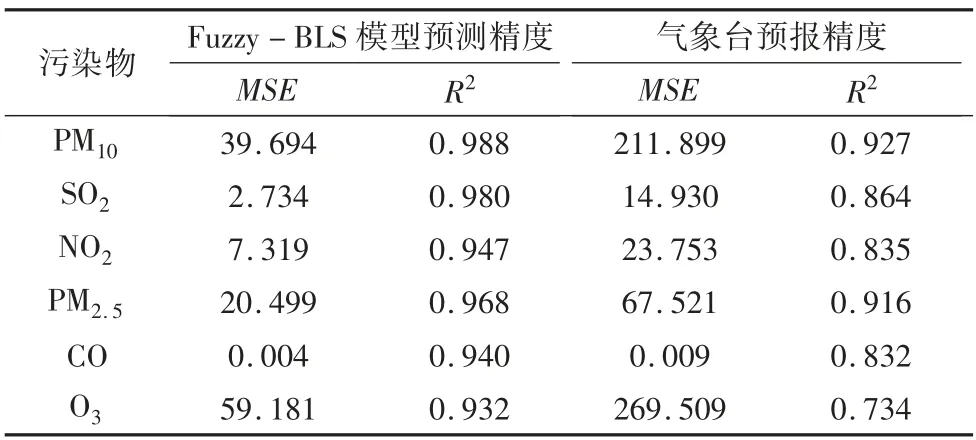
表2 2 种预测模型的精度对比表
由图4、表2 分析可知:①本文建立的基于Fuzzy-BLS 的大气污染物浓度预测模型预测效果较好,精度最高的是PM10和SO2,分别为0.988 和0.980,最低的是O3,预测精度是0.932,达到了较高精度;②PM10和O3的MSE 数值较大,是因为这2 种污染物的原始数值比较大,但精度数值都在可接受的范围内;③对比气象台预报模型与本模型的预测浓度绝对误差曲线,能够显著看出本模型预测精度更好,预测误差更小。经计算,对于一次污染物(PM10、SO2、NO2、PM2.5、CO),MSE指标平均下降了71.7%,R2指标提高了10.4%;对于二次污染物臭氧,MSE 指标下降了78.0%,R2指标提高了26.9%。
3 结语
本文建立的基于Fuzzy-BLS 的大气污染物浓度预测模型擅长处理具有时序性和非线性的数据,对气象及污染物数据具有较强的适用性,对多种污染物浓度预测精度较高,是一种可行的预测手段,在解决实际环境问题的过程中能够辅助决策。同时,在建立模型过程中,考虑到了多种气象因素对大气污染物浓度的影响,使建立的污染物浓度预测模型很大程度上能反应实际的大气情况,对于环境空气质量监测及环境保护具有较大的参考价值,实用性和可推广性较强。
