实景三维模型纹理的敏感目标自动识别与脱密方法
2024-01-15徐海燕郭为人李德民
徐海燕,郭为人,李德民,郝 君,徐 刚
(1. 浙江安防职业技术学院,浙江 温州 325016; 2. 温州市地理空间信息技术研究院,浙江 温州 325016; 3. 温州市自然资源和规划信息中心,浙江 温州 325000; 4.温州市天空地态势感知应用技术协同 创新中心,浙江 温州 325016; 5. 温州市自然灾害遥感监测预警重点实验室,浙江 温州 325016; 6. 温州市未来城市研究院,浙江 温州 325016)
实景三维模型是新型基础测绘的重要组成部分,作为构建“数字城市”“城市大脑”的基础空间信息数据,既能够表达城市的全要素信息,又具有测绘级的空间精度,逐步受到城市规划、建筑和管理部门的重视[1-2]。
随着网络的日益普及,三维模型数据访问、获取、使用、传播等更加便捷。然而大量已获取的实景三维数据正面临着保密与共享的难题,特别是实景三维模型中高分辨率的纹理信息能够暴露很多秘密机构、重要设施等敏感目标[3]。因此,需要对这些敏感目标进行脱密处理后才能保证数据的安全与共享应用,否则将对国家利益和安全构成威胁[4]。
三维模型的纹理脱密主要分为两个阶段,即敏感目标识别和脱密处理。传统的方法主要依赖于人工方法寻找纹理影像中的敏感目标,再使用图像编辑相关工具获取敏感目标周围的纹理并对其进行移除,以达到脱密的目的[5]。但该类方法在城市级的大场景下效率低,稳健性不足,无法满足高效脱密处理的要求。
随着深度学习方法的发展,文献[6]提出的YOLO网络模型在目标检测和识别领域取得了卓越的成就,在工业[7]、交通[8-9]、安防[10-11]等领域表现出巨大的应用前景。随后相继提出了YOLOv3[12]、YOLOv4[13]等版本。YOLOv5推出s、m、l和x这4个不同的网络模型,是在YOLOv4的基础上进行的参数优化调整,检测速度和精度有很大的提升,且更适合在生产环境中使用和部署。
在纹理修复方面,文献[14]提出了Patch match方法,具有较好的修复能力,其主要思想是在待修复纹理块区域边缘选取像素点,并以该点为中心划定一个大小合适的窗口,遍历整个图像,搜索与该纹理特征最为接近的图像块,利用纹理块的连续性找到最佳纹理块替代当前的纹理块。文献[15]以视频序列影像为数据,基于纹理块匹配建立全局的相关性函数以约束新的影像,使新影像的全局相关性达到最大。
本文方法主要分为两个阶段:一是基于YOLOv5s网络自动识别并有效提取敏感目标;二是基于多尺度纹理块匹配方法建立全局相关性函数进行纹理修复,达到脱密的目的。
1 技术路线
1.1 总体框架
本文的敏感目标自动识别和脱密模型总体框架如图1所示,主要由YOLOv5s模型、GrabCut模型[15]和多尺度纹理块匹配修复组成。其中,YOLOv5s模型用于敏感目标识别和定位;GrabCut模型利用定位的锚框准确提取敏感目标;多尺度纹理块匹配用于对敏感目标的自动脱密。
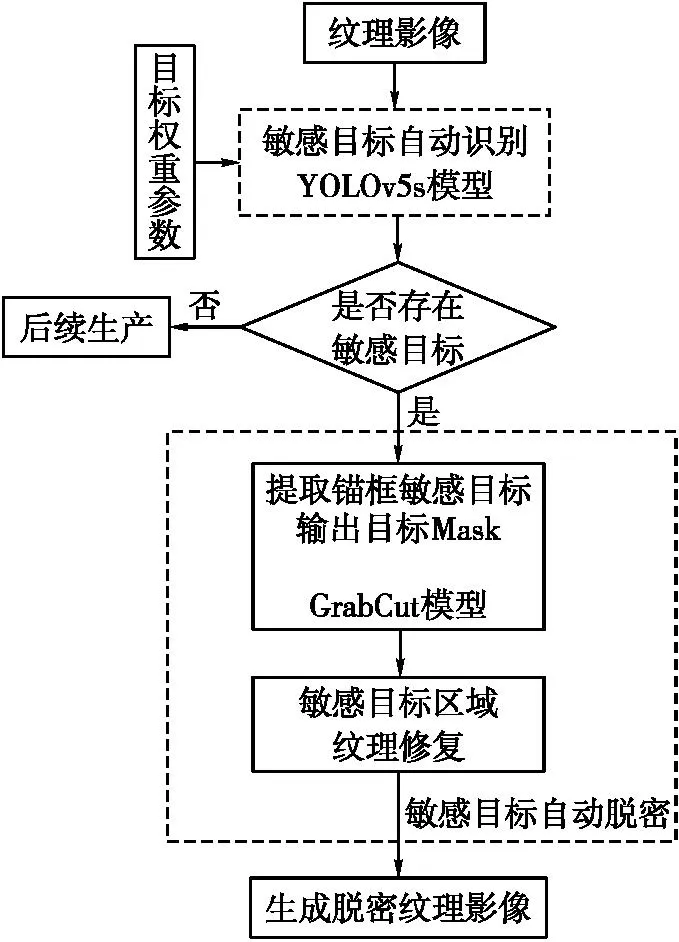
图1 总体框架
处理流程为:①预处理。根据秘密点POI获取三维模型及对应的纹理影像集,其中包含敏感目标的纹理影像。②输入纹理影像集和预先训练好的目标权重参数,使用YOLOv5s模型对纹理影像进行快速的检索、识别,判断是否存在敏感目标。③纹理影像中若不存在目标,则直接用于后续生成;若存在,则根据锚框坐标,利用GrabCut模型提取敏感目标,输出敏感目标对应的Mask。④使用多尺度的纹理块修复方法直接处理待修复区域,并最终生成脱密后的纹理影像,用于后续生产。
1.2 YOLOv5s模型
YOLOv5s网络是YOLOv5系列中的轻量化版本,其网络结构如图2所示。为满足敏感目标快速识别的要求,本文采用计算速度最快的YOLOv5s模型。

图2 YOLOv5s网络框架
YOLOv5s算法网络模型主要分为输入端、骨干端、颈部端、头部端4个模块[8]。输入端的主要功能是对输入图像进行预处理,包括 Mosaic 数据增强、自适应计算锚框、缩放图像等模块。骨干端是网络的主要部分,主要负责提取特征,由CBS、CSP1和SPPF组成。其中,CBS是由卷积、批量归一化和SiLU激活函数组成;CSP1为一种残差结构,可以减少计算计算过程中的参数,并通过残差模块控制模型的深度,也即由CSP1_X和CSP2_X的X所表示的残差模块使用的串联次数;SPPF是对特征图进行多次池化处理,对高层次特征进行提取并融合,具有更快的推理速度。颈部端使用路径聚合网络PANet进行特征融合,由CBS、上采样、CSP2组成。CSP2与CSP1相比,少了残差结构,因为特征融合不需要加深网络[9]。PANet在 FPN基础上添加了一个自底向上的信息流通途径,进一步提高了特征提取能力。检测头输出端采用GIOU函数作为边界框的损失函数,在目标识别后处理过程,使用非极大值抑制对多目标框进行筛选,提高多目标的检测能力。
1.3 Grabcut模型
GrabCut是基于图割的图像分割算法,如图3所示。该算法需要为图像设置矩形框,并以框内的像素作为分割对象,在矩形框外的像素将被自动分为背景,对于矩形框内的区域像素,将会利用背景中的像素信息区分前景和背景。基于高斯混合模型(GMM)对背景和前景建立模型,并将矩形框内的像素标记为可能为背景或前景,即待分类的像素。整个图像中的每个像素将被视为通过边与周围的像素相连接,而每条边都拥有一个属于背景或前景的概率,这是基于它与周边的像素颜色上的相似度。每个像素都会与一个前景节点s或背景节点t连接。在每个像素完成节点连接后,若相连接的两个像素不属于相同的前景或背景节点(即一个节点属于背景而另一个节点属于前景),则会切断两者之间的边,通过该方式将对象分割为前景和背景。

图3 GrabCut分割
自动识别模型会输出若干个锚框表示敏感目标的位置,但锚框不能准确提取目标。因此,本文将目标识别的锚框作为需要分割的对象自动输入至GrabCut模型,通过GrabCut模型可以将敏感目标作为前景从背景中提取出来,输出二值化Mask图像,用于脱密处理。
1.4 纹理脱密
在纹理修复中,图像需要保持最大的全局一致性才能达到良好的纹理脱密效果,全局一致性函数表示为
(1)
式中,SSIM为结构相似度函数;Wp为影像S需要填充的区域;Vq为影像D对应找到区域。
对于影像S和影像D,如果影像S中每个点都能在影像D中找到,则认为是全局一致性,即可以用影像D的窗口填充影像S的数据。从影像D中找到的patch块用V表示。H则是影像S中需要填充的空洞区域。如果可以用一些新的Wp填充丢失Vq,得到一个新的影像S*,与影像D一样具有最高的权交易全局一致性。虽然目前没有可行的方法能直接对该目标函数进行求解,但可知在最优解的位置,必然会满足以下两个条件:①包含P点的所有patch都来自影像D;②patch块在P点的投票值都是一样的。通过先在粗尺度上进行处理,在不断进行传播到细尺度上,可以提高纹理合成的效率。
由于是利用单幅纹理影像进行修复,因此影像S与影像D是一致的。在梯度设置方面,文献[15]使用了5种指标评估patch块之间的相似度,本文针对图像仅使用了RGB评价相似度。
2 试 验
2.1 构建数据集
以纹理影像中的敏感文字目标和标志目标为例,构建相应的数据集,以验证目标自动识别与脱密的性能。
2.1.1 试验数据
试验数据分为训练数据集和测试数据集。训练数据集将用于训练目标识别模型,测试数据集用于模型的识别应用。训练数据集由MSRA-TD500[16]和自采集纹理影像数据集两部分组成。MSRA-TD500是一个用于测试和评估多方向、多语言文字检测算法的自然图像数据集,分辨率较高。为了提高模型的稳健性,在自然图像数据集的基础上加入了自采集的纹理影像数据集,其中的纹理影像包含敏感目标。
2.1.2 数据预处理
由于倾斜影像以纹理映射方式贴到对应三维模型面上,立面纹理中的敏感文字和标志目标将以规整的排列方式呈现,如图4所示。因此,在训练数据集构建中对训练数据进行一定程度的透视变换,有针对性使其文字和标志排列方式保持水平或垂直,更有利于网络模型的训练。

图4 纹理映射中影像变换
使用Labelimg软件对训练数据集中的文字与标志目标等进行重新标注,构建纹理影像敏感目标识别数据集;按照8∶2的比例将数据集随机分为训练集和验证集。本文共标注了350张影像,其中训练集总数为280张,验证集为70张。测试数据集100张,用于评价,不参与模型训练。
2.2 参数设置
在识别模型网络参数设置中,学习率设置为0.01,批量大小设置为32,迭代次数300轮,使用SGD优化器。网络训练结束后得到目标权重参数文件,然后从测试数据集中抽取100张纹理影像,验证模型识别的性能。
GrabCut目标提取中,对于前景GMM模型和背景GMM模型中的类别数设置为5,迭代次数为3;在纹理修复中,尺度数scale设置为8,纹理块的大小设置为9。
3 结果与分析
3.1 评价指标
评价目标识别模型性能的指标主要为准确率、召回率、漏检率和F1值。准确率P表示识别模型正确的预测为正样本数量占所有预测为正样本数量的比例,计算公式为
(2)
式中,NTP表示预测正确的正样本数;NFP表示误预测为正样本数。
召回率R表示预测正确的正样本占所有正样本的比例,计算公式为
(3)
式中,N表示所有目标中为正样本的数量。
漏检率M用于评价模型对于目标的漏检程度,计算公式为
(4)
F1值是对准确率和召回率的综合衡量,以评价模型性能的优劣,计算公式为
(5)
评价纹理修复性能的评价指标主要为峰值信噪比(PNSR)和结构相似度(SSIM)。PNSR计算公式为
(6)
(7)
结构相似度S是通过构建亮度比较函数、对比度比较函数c、结构比较函数s,衡量两张图像之间的相似性,计算公式为
S(x,y)=(x,y)α·c(x,y)β·s(x,y)γ
(8)
当α、β、γ均为1时,S(x,y)可变形为
(9)
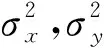
3.2 目标识别性能分析
在测试数据集中提取100张包含敏感目标的纹理影像进行测试,结果见表1。

表1 识别结果
通过目标识别后,锚框可以定位敏感目标的范围,如图5(b)所示。在测试数据集中实际目标359个,共检测出337个目标,其中正确数量321个。模型精度为95.3%,召回率为84.4%,F1值为92.2%,表明该模型对于敏感目标具有较好的识别和检测能力。图5(b)表示了敏感标志目标和敏感文字目标。

图5 目标识别与纹理脱密结果
3.3 纹理脱密性能分析
由于锚框内仍然包含大量背景信息即非敏感目标,会对后续的纹理脱密造成一定的干扰,因此利用GrabCut自动提取锚框内的敏感目标。为了保证提取敏感目标的完整性,对GrabCut得到的掩膜图像进行形态学膨胀处理,向外膨胀5个像素。图5(c)为掩膜处理后的纹理影像,其中白色部分表示敏感目标。将敏感目标掩膜图像和纹理影像作为输入,进行纹理脱密处理。图5(a)和图5(d)分别为脱密前和脱密后的纹理影像,可以看出,脱密后的纹理影像可以较好地隐藏立面上的敏感目标。
将脱密结果纹理映射至三维模型,图6为三维模型纹理脱密前后的对比效果。通过定性分析,脱密后的纹理在目视条件下保证了最大程度的真实性,同时移除了敏感文字和标志等,提高了共享的安全性,验证了本文方法的有效性。

图6 三维模型纹理脱密前后对比
从100张样本中随机抽取若干张纹理影像进行人工脱密处理,然后与本文方法的脱密结果进行PSNR和SSIM值计算,如图7所示。经统计,PSNR平均值为39.2,SSIM平均值为0.97,表明本文方法的脱密效果接近于人工脱密效果。

图7 PSNR平均值和SSIM平均值统计
使用本文方法的整个流程,处理100张分辨率大小不等的纹理影像共耗时约35 min;采用人工处理方法仅进行纹理脱密且不计敏感目标查找工作需要60 min以上。本文方法处理时间相较于人工处理缩短40%以上,有效提高了纹理脱密效率。
4 结 语
在本文方法中,三维模型纹理影像敏感目标自动识别的准确率、召回率等指标较高,纹理脱密效果合理自然,有效提高了纹理脱密的整体时间,表明结合深度学习的目标自动识别和脱密效果较好。后续将进一步研究实景三维数据脱密方法,为国家地理信息安全,以及维护国家安全和利益提供支撑。
