基于新分区策略的ST-GCN人体动作识别
2024-01-13杨世强王金华李德信
杨世强,李 卓,王金华,贺 朵,李 琦,李德信
(西安理工大学 机械与精密仪器工程学院,陕西 西安 710048)
0 引言
视频序列动作识别是计算机视觉领域中一个重要研究内容,也是机器视觉、模式识别和人工智能等多个学科领域的交叉研究课题,在视频监控、人机交互、智能机器人、虚拟现实等领域中被广泛应用[1]。
基于视频流的人体行为识别包括基于图像序列[2]、基于深度图像序列[3]、基于双流融合(如RGB+光流)[4]和基于人体骨架序列[5]等多种方法。其中,人体骨架数据是人体关节和骨骼结构的一种拓扑表示方式,在面对复杂背景,以及人体尺度、视角和运动速度等变化时具有先天优势。相比其他数据模式具有更小的运算消耗,随着深度传感器和人体姿态估计技术的不断发展,可以获得准确的人体骨架结构数据。
传统的基于骨架结构方法通常利用手工特征从特定的骨架结构序列中提取运动模式,在一些特定的数据集上表现良好,但普适性较差[6-7]。近年来,随着深度学习方法在其他计算机视觉应用方面的的发展,使用骨架结构数据的卷积神经网络(Convolutional Neural Networks,CNN)[8]、循环神经网络(Recurrent Neural Networks,RNN)[9]和图卷积网络(Graph Convolutional Networks,GCN)[10]等模型开始涌现。
人体动作的骨架结构序列由关节点自然时间序列构成,而RNN比较适合处理时间序列数据。因此,基于RNN及其变种(如长短时记忆网络LSTM,门控循环单元GRU)的骨架结构行为识别方法比较多。当CNN处理骨架结构数据序列时,通常需要结合RNN模型,RNN的时序上下文信息和CNN丰富的空间信息相结合往往可以取得比单一结构模型更好的效果。最近两年,很多学者开始将GCN应用于骨架结构的行为识别。人体骨架结构序列本身就是一个自然的拓扑图结构,GCN网络模型更适合描述骨骼关键点之间空间和时序拓扑信息,比RNN更具优势。时空图卷积神经网络(Spatial Temporal Graph Convolutional Networks,ST-GCN)利用人体拓扑结构建立邻接矩阵,用以描述人体骨架结构的空间结构,文献[10]提出了一种基于距离采样的函数,将其作用于GCN的卷积层,使神经网络能更好地学习到人体骨骼结构数据之间在空间和时序的上下文信息,性能明显优于同时期的RNN算法。许多研究者在ST-GCN的基础上进行了改进,并提出了一系列基于人体骨架结构的行为识别算法[11-13]。
本文以ST-GCN为基础,针对ST-GCN网络模型中的分区策略只关注局部动作的问题,提出了一种新的分区策略。通过合理划分关联根节点与更远节点,加强了身体各部分信息的联系和局部运动之间的联系,提升了模型对整体动作的感知能力。
1 基于新分区策略的ST-GCN模型
ST-GCN模型使用图卷积隐式地学习骨骼结构序列信息特征,代替人工提取特征,模型简单,性能好。基于ST-GCN的人体动作识别流程如图1所示。人体动作识别以视频序列为基础,通过使用人体姿态估计模型,获得人体骨架结构变化序列,构造骨架结构变化时空图,随后输入ST-GCN网络模型,实现人体动作识别。本文在骨架数据集的基础上研究ST-GCN网络模型。

1.1 构造骨架时空图
ST-GCN网络模型需要依据输入骨架结构变化序列构造的骨架结构变化时空图,将离散骨骼点构造为类似于图片形式,即对于单帧人体骨骼点,通过连接相邻两个骨骼点形成空间骨架;对相邻两帧的人体骨骼点连接相同两个骨骼点形成时间骨架。Kinetics-skeleton数据集[14]中,骨骼结构点数N=18的各骨骼点如图2所示。在T帧的骨架结构序列上可构造一个如图3所示的骨架结构时空图G=(V,E),其中:V为骨骼点集合,E为骨架边集合。
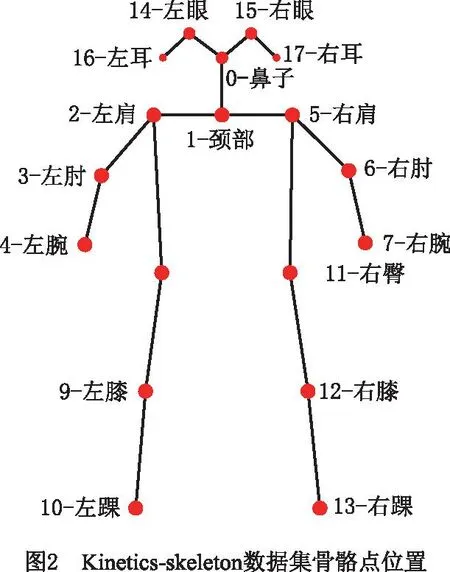
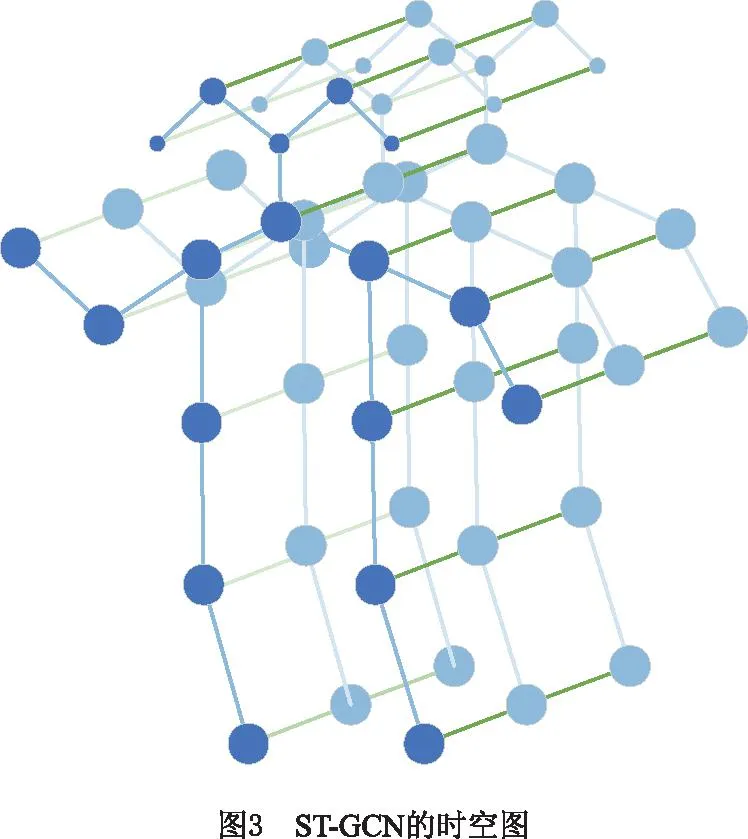
对于图3,骨骼点集合为:V={vti|t=1,…,T,i=1,…,N},由人体骨架结构变化序列中的全部骨骼点坐标组成;vti为第t帧上第i个骨骼点;E由骨架时空图中的骨架边构成,包括ES和EF,Es={vtivtj(i,j)∈H}为空间上相邻两个骨骼点形成的骨架边,vtj为第t帧上第j个骨骼点;EF={vtiv(t+1)i}为相邻两帧上相同骨骼点形成的骨架边,v(t+1)i为第t+1帧上第i个骨骼点。因此,构建的骨架结构变化时空图包含一个动作序列中的骨骼点变化信息,任意一个骨骼点i的变化曲线为EF中所有骨架边。
1.2 构造时空图卷积
ST-GCN模型使用图卷积处理空间中的离散特征点,在二维卷积的基础上进行构造。对于二维卷积,在一个通道数为c的输入特征矩阵fin上使用大小为K×K的滤波器,则特征矩阵上任意位置x的二维卷积公式为:
(1)
式中:p为采样函数矩阵;采样区域为x的邻域(h,ω),采样区域大小与滤波器大小相同;w为权重函数矩阵;fout(x)在c维空间中提供了一个权向量,用于计算与输入特征矩阵的内积(·为内积)。通过重新定义采样函数p和权重函数w,即可构造图卷积公式。
在骨架结构变化时空图上,以根节点vti为中心,其余骨骼点vtj到vti的最短距离为d(vtj,vti)(相邻两骨骼点间的距离为1),可以将所有骨骼点划分为2个集合,分别为:到根节点vti的最短距离小于等于采样距离阈值D的骨骼点集合和到根节点vti的最短距离大于采样距离阈值D的骨骼点集合。可以在到根节点vti的最短距离小于D的骨骼点vtj的集合B(vti)={vtj|d(vtj,vti)≤D}上定义采样函数。若采样函数P使用D=2的相邻区域B(vti),则采样函数p(vti,vtj)为:
p(vti,vtj)=vtj。
(2)
在骨架时空图上,通过对骨骼点vti的相邻区域进行映射操作lti:B(vti)→{0,…,K-1},对骨骼点vti的相邻区域赋予不同的权重参数,即可构造权重函数w。使用分区策略可以将骨骼点vti的相邻区域B(vti)分解为K个子区域{0,…,K-1},以此简化映射变化。权重函数w(vti,vtj)为:
w(vti,vtj)=w′(lti(vtj))。
(3)
通过使用式(2)和式(3)定义的采样函数和权重函数,可以重新构造式(1),得到空间上的图卷积公式:
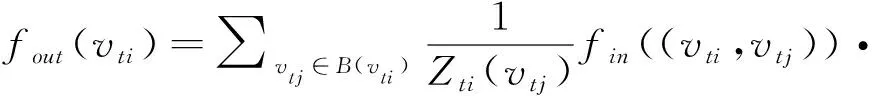
(4)
式中规范化项Zti(vtj)=|{vtk|lti(vtk)=lti(vtj)}|等于相应子区域的基数,该项可平衡不同子区域对输出的贡献。将式(2)和式(3)代入式(4)后得到图卷积公式如下:
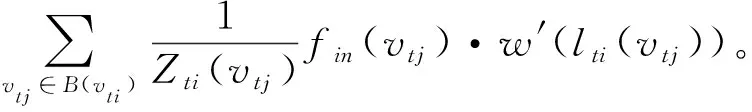
(5)
在构建骨架时空图时,通过连接相邻两帧中的两个相同骨骼点描述时间维度,选定一个时间范围为Γ的骨架帧序列。通过在这个序列范围内应用空间图卷积,可以将式(5)的空间图卷积公式推广到时间维度。时空图卷积公式为:
(6)
式中Γ为相邻图中的时间范围,即时间内核大小。
为实现骨架时空图上的便捷时空图卷积运算,在时间维度上,基于采样函数和权函数定义vti骨骼点相邻区域的映射结果lST为:
(7)
式中lti(vtj)为vti处骨骼点的映射结果。
以此,构造基于骨架时空图的时空图卷积。
1.3 构建新分区策略
在构造权重函数w时,使用分区策略可以将骨骼点vti的相邻区域B(vti)分解为K个子区域{0,…,K-1},通过对每一个子区域赋予不同的权重,简化权重函数的构建,从而提升建模能力和识别性能。
ST-GCN有3种分区策略,如图4所示。图4a中,红色虚线圈为任一骨骼点的采样区域,红色点表示采样区域的根节点vti,其余骨骼点用蓝点表示,采样函数P使用D=1的相邻区域B(vti)。无标签配置分区策略图4b中,根节点vti的相邻区域B(vti)没有划分,区域内的所有骨骼点赋予相同的权重(绿色)。距离配置分区策略图4c中,根节点vti的相邻区域B(vti)划分为根节点0(绿色)和其余骨骼点(蓝色)2个区域,每个区域赋予不同的权重。空间配置分区策略图4d中,以黑色十字表示的骨架重心为参考,将根节点vti的相邻区域B(vti)划分为根节点(绿色)、向心节点(蓝色)和离心节点(黄色)3个区域。向心节点到重心的距离小于根节点到重心的距离,离心节点到重心的距离大于根节点到重心的距离,每个区域赋予不同的权重。
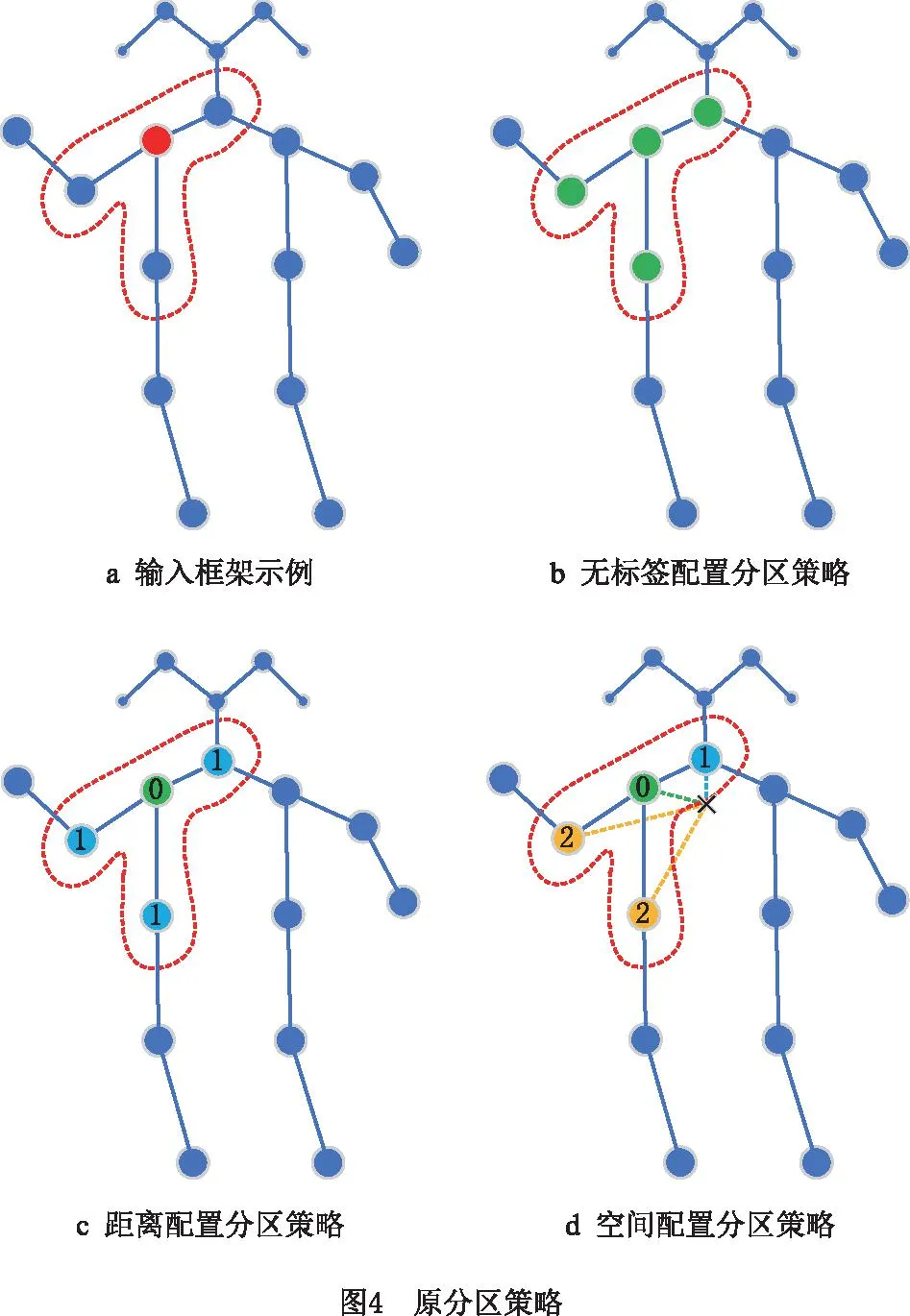
空间配置分区策略为根节点vti的相邻区域B(vti)赋予3种不同权重,效果最好。这种空间配置分区策略依据身体部位的运动可以大致分为同心运动和偏心运动。将邻域集分为3个子集:①根节点本身;②向心群:比根节点更接近骨架重心且与根节点相邻的骨骼点;③其余的部分为离心群。空间配置分区策略为:
(8)
式中:rj为骨骼点j到重心的距离,ri为重心到骨骼点i的平均距离。
本文采用了新的分区策略来构建ST-GCN模型。所设计的新分区策略为:设置采样函数P使用D=2的相邻区域B(vti),在原空间配置分区策略的基础上增加2个区域,将根节点的相邻区域分成5个子区域,如图5所示。其中:①根节点本身;②向心群:比根节点更接近骨架重心,且与根节点相邻的骨骼点;③远向心群:远离根节点且与向心群相邻的骨骼点;④离心群:比根节点更远离骨架重心,且与根节点相邻的骨骼点;⑤远离心群:远离根节点且与离心群相邻的骨骼点。

采样函数P使用D=2的相邻区域B(vti),图5中采样区域用红色虚线圈表示。根节点vti的相邻区域B(vti)分解为5个区域,根节点(绿色)、向心节点(蓝色)、远向心节点(橘色)、离心节点(黄色)和远离心节点(紫色),对每个区域的骨骼点赋予一种权重。每个区域的骨骼点权重为:
(9)
式中:rj为骨骼点j到重心的距离;ri为重心到骨骼点i的平均距离;rk,j为骨骼点k到骨骼点j的距离。
新的分区策略不仅考虑了身体局部的运动,还考虑了局部运动间的联系。通过关联根节点与更远节点,加强了身体各部分信息的联系和局部运动之间的联系,提升了模型对整体动作的感知能力,从而提升动作识别的精度。
1.4 基于新分区策略的ST-GCN网络模型
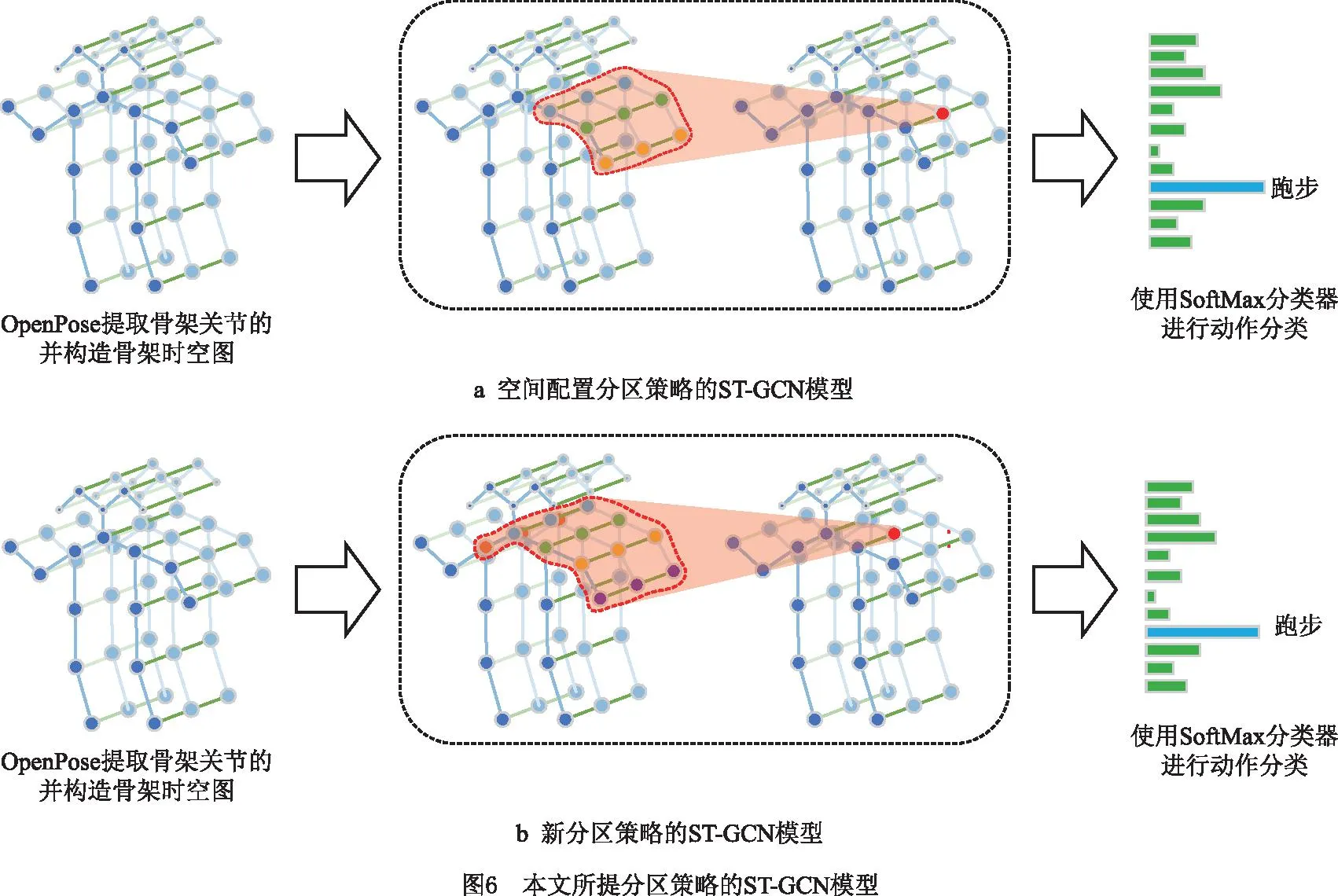
在骨架时空图上,使用时空图卷积和新的分区策略即可构建基于新分区策略的ST-GCN模型,如图6所示,图6a为空间配置分区策略的ST-GCN模型,图6b为新分区策略的ST-GCN模型。与空间配置分区策略的ST-GCN模型相比,本文的分区策略增大了采样区域,同时将采样区域划分为更多种权重参数。
新分区策略的ST-GCN网络结构如图7所示。其中包含9个ST-GCN(时空卷积)单元,时空卷积核大小为5×9。每个ST-GCN单元都使用了特征残差融合方式,可以实现特征的跨区域融合。在每个ST-GCN单元之后都采用0.5的dropout机制,这样可以降低模型过拟合的风险,同时在第4和第7个ST-GCN单元后使用步长为2的池化层操作,对特征进行下采样。ST-GCN模型的1~3单元包含64个输出维度,4~6单元包含128个输出维度,7~9单元包含256个输出维度。对最后的输出维度,通过使用SoftMax分类器即可对输入骨架序列进行动作分类。对得到的张量进行全局合并,得到每个序列的256维特征向量后,将其输入SoftMax分类器就可以得到相应的人体动作。

为实现基于ST-GCN骨架的动作识别,本文采用类似于图卷积的表达形式,单帧内骨骼点的自连接由单位矩阵I和表示体内连接的相邻矩阵A表示。在单帧情况下,新分区策略的ST-GCN使用以下公式实现:
(10)
其中邻接矩阵被拆分成几个矩阵Aj,
(11)
即
A0=I,
(12)
A1+A2+A3+A4=A。
(13)
在动作变化过程中骨骼点可能出现在空间中的任意位置,新分区策略的ST-GCN模型使用了和原模型相同的可学习掩码M。通过调整掩码权重参数,进一步提升新分区策略ST-GCN模型的性能。
2 实验及分析
为验证新分区策略ST-GCN模型的性能,本文在Kinetics-skeleton数据集[14]和NTU-RGB+D数据集[15]上进行模型训练和测试,随后在真实场景下采集动作序列进行测试。
2.1 Kinetics-skeleton数据集模型训练和测试
(1)Kinetics-skeleton数据集和评估指标
Kinetics-skeleton数据集是在大规模动作识别数据集Kinetics(Kinetics human action dataset)[16]上建立的。Kinetics是迄今为止最大的无约束动作识别数据集,包含从YouTube检索到的约30万个视频片段,视频涵盖多达400个人类动作,从日常活动和体育场景,到复杂的互动动作,视频中的每个剪辑持续大约10秒。YAN等[10]通过在Kinetics数据集上使用OpenPose[17]来获得每一帧上18个骨骼点的二维坐标(X,Y)和置信度得分C,且每一帧保留2个骨骼点平均置信度最高的人,对每一个动作选择300帧作为一个动作骨架序列来建立Kinetics-skeleton数据集。该数据集提供了24万个剪辑的训练集和2万个验证集。为便于比较,本文在训练集上训练模型,在验证集上验证模型的性能。
Kinetics-skeleton数据集上使用Top-1和Top-5的精确度指标验证新分区策略ST-GCN模型的识别性能。Top-1为预测的概率向量中排名第1的类别等于正确类别的概率,即分类的准确率;Top-5为预测的概率向量中排名前5的类别包含正确类别的概率。Top-1和Top-5的计算公式如下:
(14)
(15)
(2)模型训练和测试结果
本文在Kinetics-skeleton数据集上进行模型训练和测试,实验使用1块P106-100的显卡,显存为6 GB,CPU为Intel(R)Core(TM)i5-4460 CPU@3.20 GHz,软件环境为Pytorch1.0.0+Cuda9.0+cudnn7.0.0。模型训练使用SGD优化器,动量为0.9,权重衰减为0.0001。设置Batchsize大小为16,迭代次数设为50。初始学习率为0.1,当迭代次数分别到达20、30、40时,将学习率依次衰减0.1倍后继续迭代。
在Kinetics-skeleton数据集上不同分区策略ST-GCN模型的性能对比如表1所示。由表1中数据可以看出,本文提出的新分区策略模型与其他4种分区策略模型相比性能均有所提升,其中,Top-1的性能指标分别提升了11.8%、2%、1.1%和0.4%,Top-5的性能指标分别提升了16%、2.1%、0.9%和0.6%。
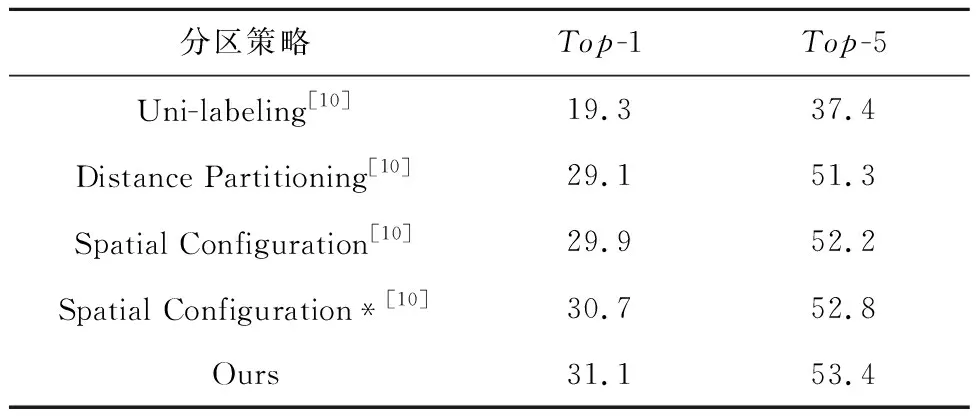
表1 不同分区策略的ST-GCN模型对比 %
Kinetics-skeleton数据集上新分区策略模型与其它模型的性能对比如表2所示。由表2中数据可以看出,本文模型与ST-GCN模型相比Top-1和Top-5分别提升了0.4%和0.6%,且准确率优于Temporal Conv方法。本文模型是对ST-GCN模型的改进,相比于其它优秀模型,如AS-GCN、2S-AGCN和GCN-NAS,本文的模型在准确率方面还有所差距。由于Kinetics-skeleton数据集视频采集环境比较严峻,基于骨骼点的动作识别模型在Kinetics-skeleton数据集上识别率不高。作为参考,表中列出了基于RGB帧方法和基于光流特征方法的性能。
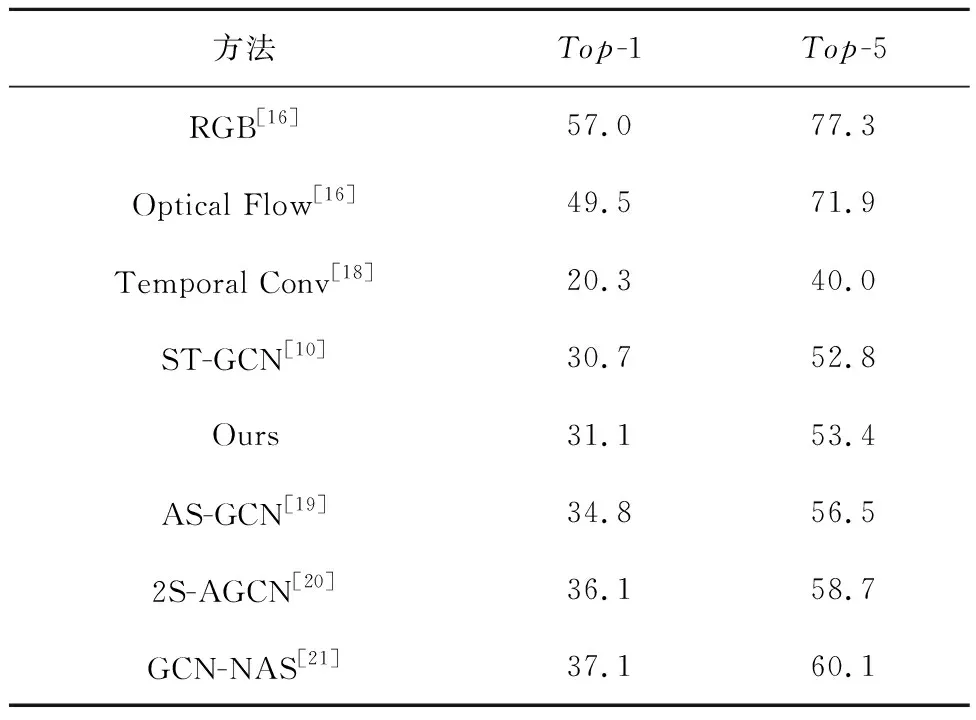
表2 新分区策略的ST-GCN模型与其他模型对比 %
2.2 NTU-RGB-D数据集模型训练和测试
(1)NTU-RGB+D数据集和评估指标
NTU-RGB+D是目前最大的用于人体动作识别任务的3D骨骼点数据集,包含60类动作,56 000个动作序列。所提供的标注信息是由Kinect深度传感器检测到的摄像机坐标系中的三维骨骼点位置(X、Y、Z),每个人提供25个骨骼点。该数据集提供了两个子数据集:
1)X-Sub子数据集:包括40 320和16 560个训练和评估剪辑,训练剪辑来自一个演员子集,模型根据其余演员的剪辑进行评估。
2)X-View子数据集:按摄影机来划分训练和评估剪辑,包括37 920和18 960个训练和评估剪辑,训练剪辑来自摄影机2和3,评估剪辑都来自摄影机1。
NTU-RGB+D数据集上使用Top-1性能指标如式(14)所示。
(2)模型训练和测试结果
本文在NTU-RGB-D的两个子数据集上进行模型训练和测试,模型训练使用SGD优化器,其动量为0.9,权重衰减为0.000 1;采用dropout机制,设置其阈值为0.5;设置batchsize大小为8,迭代次数设为80;初始学习率为0.1,当迭代次数到达10、50时将学习率依次衰减0.1倍。
NTU-RGB-D数据集上新分区策略下的ST-GCN模型与其它模型性能对比如表3所示。可以看出,在X-Sub和X-View两个子数据集上,本文模型性能优于Temporal Conv、GCA-LSTM和ST-GCN,相比于ST-GCN模型识别率提升了2.3%和3.3%;本文模型是对ST-GCN模型的改进,其中,Motif-STGCN方法同样基于ST-GCN进行改进,与Motif-STGCN方法相比,在X-Sub上本文模型准确率没有提升,在X-View上准确率提升了1.4%。相比于其它优秀模型,如AS-GCN、2S-AGCN和GCN-NAS,本文模型的识别准确率还有所差距。
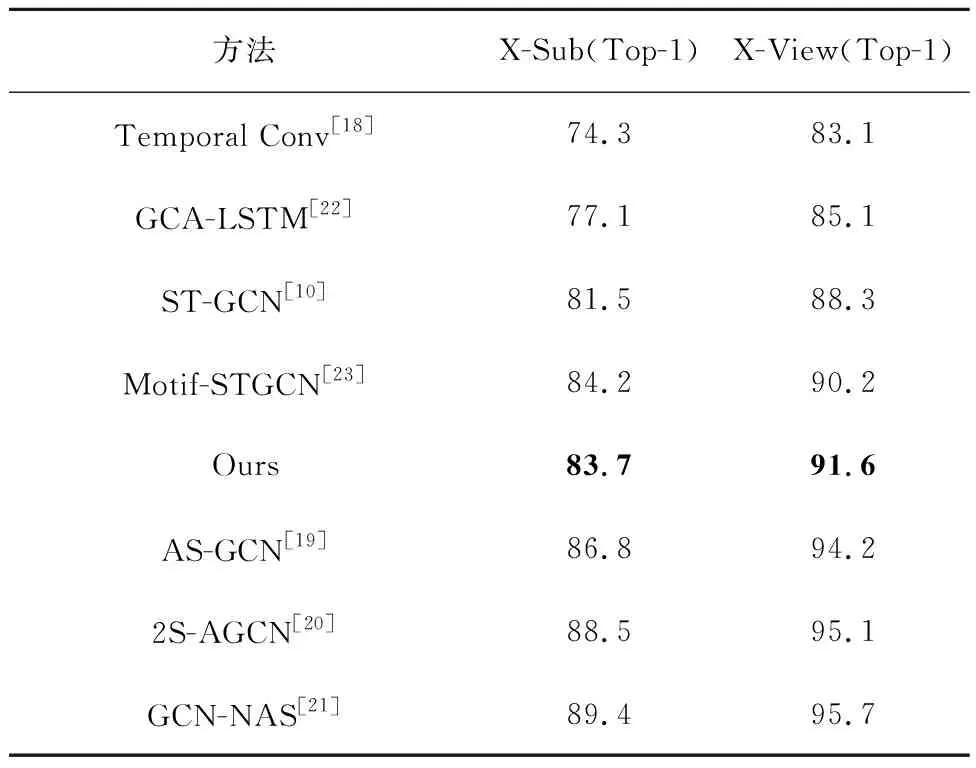
表3 新分区策略的ST-GCN模型与其它模型对比 %
2.3 真实场景下模型测试结果
对于基于二维骨骼点序列的动作识别,本文进行了真实场景下的动作识别,通过使用人体检测模型YOLO Nano和人体姿态估计模型HRNet-W32获得人体骨架序列,实现人体动作识别。识别流程如图8所示。

分别使用MV-EM130C相机和手机采集视频用于实验,MV-EM130C相机和手机的分辨率分别为1 280×960和1 280×720,由5人分别完成实验动作,视频采集设置如下:
(1)选择了6类动作,包括下蹲(squat)、慢跑(jogging)、鼓掌(clapping)、摇头(shaking head)、引体向上(pull up)和俯卧撑(push up)。
(2)使用MV-EM130C相机在室内场景采集了下蹲、慢跑、鼓掌和摇头4类动作,每类动作采集了10个10 s左右的动作序列,每个动作序列的帧数为300左右。
(3)使用手机在室外场景采集了引体向上和俯卧撑2类动作,每类动作采集了10个10 s左右的动作序列,每个动作序列的帧数为300左右。
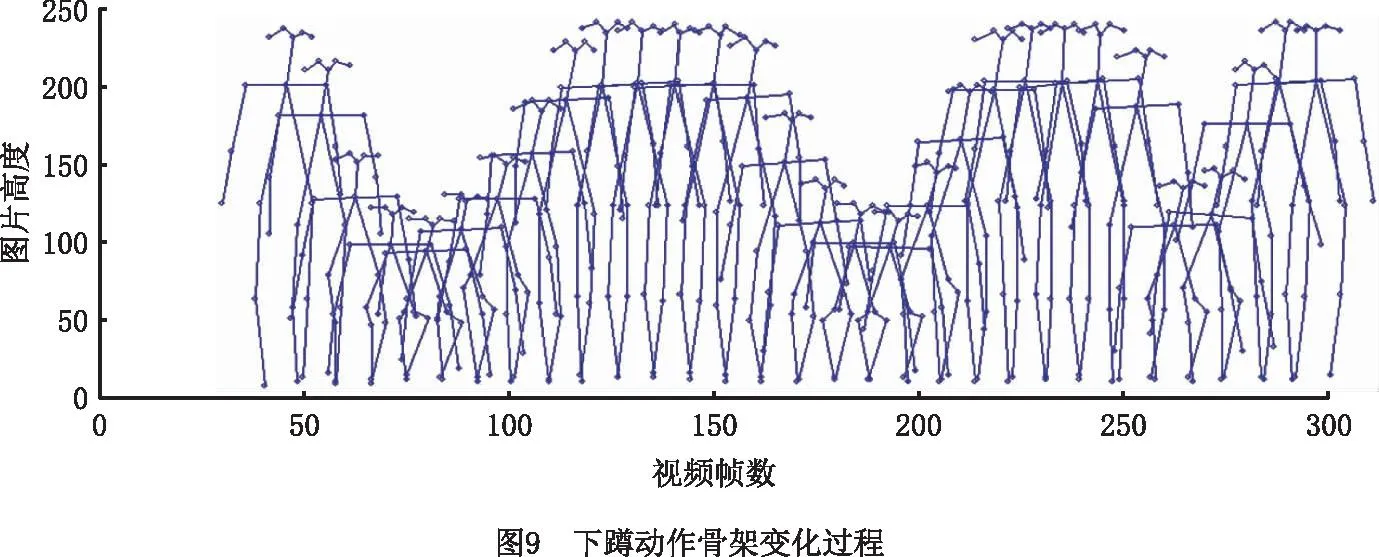
室内下蹲动作的骨架变化过程如图9所示,每隔10帧选取一帧,共30帧骨架序列。从图9中可以看出骨架的变化较为准确地表示了动作的变化。
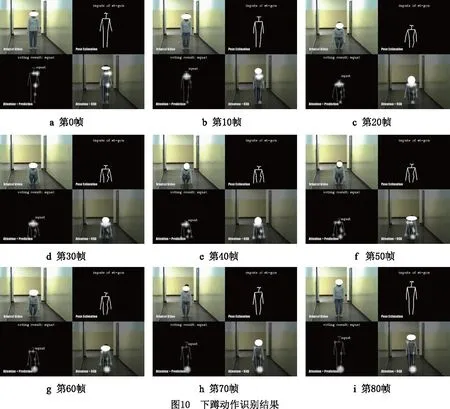
室内下蹲动作识别过程如图10所示,室外引体向上动作识别过程如图11所示。当前人体动作识别为对前n帧动作序列的识别结果,整个动作序列识别表达了最终的人体动作。如图10b中,第10帧的识别结果为人体动作识别模型对前10帧动作序列的识别结果,voting result为整个动作序列的识别结果。本文的人体动作模型可以聚焦运动过程中人体骨骼位置变化的信息,由图10可以看出,对于下蹲动作,其变化剧烈的骨骼点位置主要集中在上半身,从图11中可以看出对于引体向上动作,其变化剧烈的骨骼点位置为胳膊和肩膀。整体来看,模型对于关节点识别和动作的识别都较为准确地反映了人体动作的实际变化。

分别使用MV-EM130C相机和手机采集的室内和室外自然环境下6类动作,每类动作含10个动作序列,总体识别率统计如表4所示。可以看出,无论室内室外场景,本文模型对动作变化明显且区别大的动作如下蹲和慢跑动作,识别率高,分别为90%和100%;对局部运动和动作变化相近的动作如鼓掌和摇头动作,识别率偏低,分别为40%和60%;室内场景下的下蹲和慢跑动作的识别率分别为90%和100%,高于室外场景下的引体向上和俯卧撑动作的识别率,分别为80%和90%。
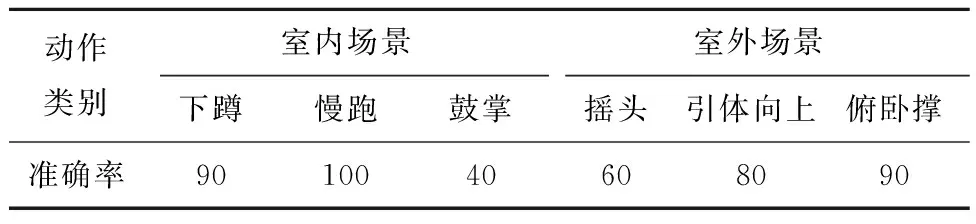
表4 动作识别准确率结果 %
2.4 讨论
在Kinetics-skeleton数据集和NTU-RGB-D数据集中,本文模型性能优于Temporal Conv、GCA-LSTM 和ST-GCN,但相较于AS-GCN、2S-AGCN和GCN-NAS等模型,准确率还有所差距。分析原因,主要影响因素有:①本文模型基于ST-GCN模型,不同方法有各自优缺点,与原ST-GCN相比较,本文模型取得了较好结果;②Kinetics-skeleton数据集视频采集环境复杂,动作的识别可结合人体任务、人交互环境和上下境信息,进一步提升识别率;③结合真实场景实验结果,模型对动作小微处的表达尚有进一步提升的空间。
真实场景中,采集视频识别结果来看,室内优于室外,大幅动作优于小微动作。分析其原因,主要影响因素有:①实验中采用传统二维相机,采用基于二维骨架的人体动作识别模型,二维骨架信息相较于三维骨架信息偏少;②室内实验采集数据采用工业相机,采集的视频质量较高,较稳定,室外实验采集的数据集使用手持手机拍摄,二维骨骼点位置随镜头变化而变化剧烈,引起关节点位置的变化,影响动作识别;③小微动作包含在大动作内,提取到的特征包含在大动作里,小微动作与大动作尺度变化较大,影响了模型的识别;④室外环境更为复杂,背景的复杂程度会影响人体动作识别模型的识别率。
3 结束语
本文设计了一种新的分区策略,将根节点的相邻区域划分为5个子区域,构建新分区策略的ST-GCN网络模型。新分区策略不但考虑了身体局部的运动变化,而且关联了根骨骼点与更远骨骼点,考虑了局部运动之间的联系,加强了身体各部分信息联系和局部运动之间的联系,从而提升模型对整体动作的感知能力。模型在大规模数据集Kinetics-skeleton上获得了31.1%的Top-1性能指标,相比原模型提升了0.4%。在NTU-RGB+D的两个子数据集上分别获得了83.7%和91.6%的Top-1性能指标,相比原模型提升了2.3%和3.3%。采集真实场景视频,实际场景中识别模型对于动作变化明显且区别大的动作,如俯卧撑和慢跑识别率高,分别为90%和100%,对于局部运动和动作变化相近的动作,如鼓掌和摇头,识别率偏低,分别为40%和60%,尚有进一步提高的空间。
