基于信息量、信息量-逻辑回归模型综合法的地质灾害易发性研究❶
——以诸暨市马剑镇为例
2024-01-12王美华
王美华
中化地质矿山总局浙江地质勘查院,浙江 杭州 310002
地质灾害易发性评价是一种预测地质灾害发生概率的方法,通过综合分析地质环境条件、灾害孕育因素以及诱发因素等多方面因素来进行评估[1-2]。常用的评价方法包括统计学方法,如逻辑回归法和多元线性回归法[3-6];概率学方法,如信息量法[7-8]、熵指数法[9]和确定性系数法[10-11];数据挖掘方法,如人工神经网络法、支持向量机法和随机森林法等[12-18]。
以往的地质灾害易发性评价方法通常采用单一模型,如信息量模型、专家评分法、层次分析法、综合指数法、神经网络法以及逻辑回归模型等[19-21]。然而,每种模型都存在局限性和不足之处,综合运用多种模型可以相互弥补优势,进而提升评价结果的准确性。近年来,随着3S 技术的快速发展,区域地质灾害评价精度得到有效提升,尤其是信息量法、确定性系数法和逻辑回归法等定量评价方法的组合使用在地质灾害易发性评价中得到了广泛运用,并取得了较好的效果。如杜谦[22]等采用二元逻辑回归和信息量模型相结合的方法对任河小流域进行地质灾害易发性分区研究,结果显示采用二元Logistic 回归模型模拟具有较高的准确性;张晓东[23]等采用信息量法、确定性系数法与逻辑回归法组合对宁夏盐池县进行地质灾害敏感性的对比研究,结果表明采用信息量模型+逻辑回归模型和确定性系数模型+逻辑回归模型2 种组合模型都能有效客观评价该区地灾敏感性;栗泽桐等[24]以青海沙塘川流域为例,开展了信息量、逻辑回归及其耦合模型的滑坡易发性评估研究,使用逻辑回归模型和信息量模型进行滑坡易发性评估效果较理想,因而应用较普遍。但以往在区域定量化评价研究过程之中,存在将所有灾种简单以同一种模型方法进行评价,未将区别于其他灾种的沟谷泥石流进行单独评价。为了进一步探索更为理想的定量估算模型,本次以浙江省目前已开展的1∶2000 地质灾害乡镇风险调查评价的诸暨市马剑镇为例,基于地理信息系统和地面调查,以斜坡为评价单元,并选取了坡度、坡向、高差、坡型、覆盖层厚度、岩性与岩土结构、斜坡结构、与构造间距离以及切坡高度等9 个因子作为评价指标因子,使用信息量模型综合法和信息量-逻辑回归模型综合法这两种方法进行易发性综合评价。与以往研究相比,本研究方法考虑了沟谷泥石流形成机制和相关影响因素与崩塌、滑坡及坡面泥石流的差异性。评价地质灾害时,先评价除沟谷泥石流之外的其他地质灾害,然后结合沟谷泥石流易发性评价结果进行综合评价[25],以得出更直观和合理的评价结果。该研究旨在为浙江省和类似地质环境中的地质灾害风险评价、地质灾害风险防控和监测预警提供科学依据。
1 研究区概况
研究区位于浙江省诸暨市马剑镇,现辖14个行政村,总面积114.28km2。该区地处浙北丘陵山区,属于龙门山的余脉,地势北高南低,四周环绕着群山,中间是一条狭长的冲洪积山间谷地,海拔+102m~+1015.2m。山体自然地形的坡度多在15°~45°,主要地貌类型包括构造侵蚀剥蚀低山、侵蚀剥蚀丘陵和山间谷地。该地区属于亚热带季风气候,多年平均降水量为1663.7mm,日最大降水量为195.7mm。地层主要以白垩系黄尖组(K1h)流纹质晶屑玻屑熔结凝灰岩和寿昌组(K1s)流纹质晶屑玻屑凝灰岩为主,东部地区主要分布下白垩统花岗斑岩(γπ)和流纹斑岩(λπ)等潜火山岩。该地区的断裂构造发育,主要构造方向为北东向,其次为北西向(图1)。根据岩土体的形成条件、岩性组合特征及岩土的工程地质性质,该区的岩土体可划分为4 类,包括酸性岩岩组、坚硬块状熔结凝灰岩岩组、坚硬-较坚硬块状凝灰质碎屑岩岩组和砂类土岩组。该区存在频繁的人类工程活动,主要包括农村山区居民建房、城镇建设、道路交通以及山塘水库和低丘缓坡开发等。
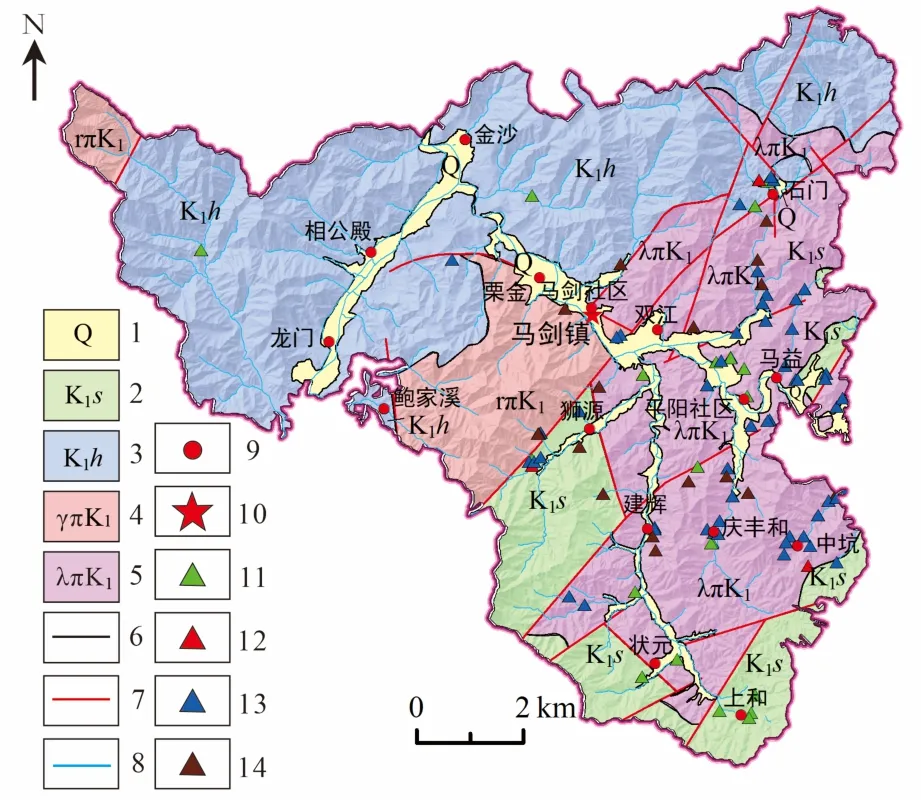
图1 研究区地质背景暨地质灾害点分布Fig.1 Geological background and disaster spot distribution map of the study area
该区已发生的崩塌、滑坡和泥石流(坡面泥石流和沟谷泥石流)等地质灾害共计93 处,其中滑坡3 处、崩塌23 处、泥石流67 处,主要以坡面泥石流为主,共计47 处,占比50.54%。这些灾害多发生在梅汛期和台汛期,前者持续时间较长,后者降雨短时强度大,两者合计约占全年降水量的2/3。暴雨和持续性强降雨是灾害主要诱发原因,特别是2021 年6 月10 日的降雨,雨量站数据显示,在泥石流爆发前的1h、3h 和6h 内,降水量分别达到81.1mm、167.1mm和175.2mm[26],而在爆发前15min 内,高强度持续降雨引发了大规模泥石流。
2 研究方法
2.1 信息量模型
信息量模型是一种统计分析和预测方法,通过地质灾害发生时的熵值个数来反映地质灾害的易发性。通过对每个评价因子进行分类,利用地质灾害发生频率或密度反映出各评价因子下二级分类致灾效应的大小,将地质灾害评价因子的实际数据值转化成表示地质灾害易发性大小的信息量。通过在ArcGIS 平台上叠加各因子信息量,计算出总信息量大小,总信息量值越大,地质灾害易发性越高[22]。
式中:I(Ai-j)-第i个评价因子第j个二级分类的信息量;P(Ai-j)-第i个评价因子第j个二级分类地质灾害发生的概率;P(B)-研究区地质灾害发生的概率。
在实际计算中,由于研究区地灾点规模除1个是中型为外,其余都为小型,因此本次单一因素计算时采取样本频率代替总体概率方式来处理,公式(1)转换为:
式中:Ni-j-第i 个评价因子第j个二级分类发生地质灾害个数;Si-j-第i 个评价因子第j 个二级分类斜坡单元面积,km2;N-研究区地质灾害总数;S-研究区总面积,km2。
对单因子信息量进行叠加计算,得出多因子综合信息量评价结果:
式中:I(Ai)-第i个评价因子单因子信息量;I-多因子综合信息量;n-评价因子总数;频率比。该模型将总信息量I作为评判斜坡单元内地质灾害易发性大小的指标,其值越大表明该斜坡单元地质灾害易发程度越高。
2.2 信息量-逻辑回归模型
逻辑回归属于二项分类回归分析模型,适用于定性变量的不确定性和复杂性进行预测。在地质灾害评价中,此模型以地质灾害发生情况作为因变量(Y),致灾因素信息量值为自变量(xn),进行二元逻辑回归来确定地质灾害发生的概率(P)[27]。该模型可以使用连续或离散自变量,不需要满足正态分布,其公式如下:
式中:P-地质灾害发生概率,取值范围为[0,1];Z-地质灾害发生的目标函数;bn-逻辑回归系数;b0-逻辑回归常数项;xn-地质灾害因子的信息值;n-因子数;Y-因变量,表示地灾发生或不发生。
在实际操作中利用SPSS 软件先对9 项因子进行独立性检验和共线性诊断,而后通过二元逻辑回归,得出Z值,通过公式(4)计算出P值。P值越接近1 表示事件发生的确定性越大,地灾越容易发生;越接近于0 表示事件发生的确定性越小,地灾发生的可能性低;0.5 表示条件概率与先验概率相等,无法确定事件是否发生,即地灾发生的概率为50%。根据不同P值进行地质灾害易发性评价,并利用ROC 曲线对评价模型敏感度进行预测。最后,利用稳定性较差或差斜坡作为检验样本进行结果验证[28]。
3 易发性评价因子选择与分析
3.1 评价指标因子选取
结合研究区的地质背景、地质灾害形成条件及发育特征,选取了坡度、坡向、高差、坡型、覆盖层厚度、岩性与岩土结构、斜坡结构、与构造间距离和切坡高度9 个因素作为评价指标。基础资料包括浙江省测绘科学技术研究院获取的最新马剑镇的1∶10000 数字地形图、1∶2000数字地形图、2m 间距DEM 数据、0.2m 分辨率航空分幅正测航片和1∶50000 的地质图,通过ArcGIS 高程数字模型(DEM)数据提取分析得到研究区每个斜坡单元坡度、坡向、坡型、高差。基于1∶50000 区域地质图(或工程岩组分布图)资料,结合孕灾地质条件野外调查,获取每个斜坡单元的岩性与岩土结构、斜坡结构、覆盖层厚度、切坡高度等相关数据。对于距断层距离这个影响因子则结合收集的1∶5 万区域地质资料、遥感解译和野外断裂调查,利用ArcGIS 平台近邻分析方法确定每个斜坡单元距断裂构造最小距离。
3.2 评价指标因子分析
3.2.1 坡度
坡度对地质灾害,尤其是崩塌有着重要的影响。根据统计分析,本研究区的坡度分级为0°~15°、15°~25°、25°~35°、35°~45°、>45°计5 级(图2a),发生地质灾害的坡度主要集中在25°~45°。在35°范围内,地质灾害百分比大于分级面积百分比,即频率比>1;在超过35°的情况下,地质灾害百分比低于分级面积百分比,表明随坡度增加,地质灾害密度总体先上升而后逐渐递减。

图2 研究区地质灾害易发性九项影响因子分级Fig.2 Nine grading maps of influencing factors of susceptibility to geological disasters in the study area
3.2.2 坡向
坡向影响斜坡的稳定性,一般阳坡易发生地质灾害。研究区坡向按45°间隔分为北(337.5°~22.5°)、北东(22.5°~67.5°)、东(67.5°~112.5°)、南东(112.5°~157.5°)、南(157.5°~202.5°)、南西(202.5°~247.5°)、西(247.5°~292.5°)和北西(292.5°~337.5°)8 个分类(图2b)。地质灾害发生的位置主要集中在区内的南东坡和南坡。在坡向由北往北西顺时针方向分级过程中,除了东、南东和南3 个坡向地质灾害百分比高于分级面积比例之外,其他坡向地质灾害百分比都低于分级面积百分比,这说明东、南东和南3 个坡向对地质灾害影响较为显著。
3.2.3 高差
研究区高差分为0~20m、20~50m、50~100m、100~300m、>300m 计5 级(图2c)。地质灾害主要集中在50~300m 范围内。频率比呈现中间高、两头低情况,表明高差在50~300m 范围内地质灾害影响较为显著,且在50~100m 高差范围对地质灾害影响达到最大。
3.2.4 坡型
坡型是斜坡形状和特征反映,亦是影响斜坡稳定性和发生地灾的重要因素之一,其值为正时表明边坡是凸面坡,为0 时表明为直坡、折形坡,为负时表明边坡为凹面坡[22]。本次将坡型划分为凸形坡、凹形坡、直坡、折形坡3 种(图2d)。据统计,凸形坡是地质灾害点的主要集中地,表明凸形坡对地质灾害具有较大的影响。
3.2.5 覆盖层厚度
本次研究将覆盖层厚度此连续性变量划分为0~1m、1~3m 和>3m 这3 个级别(图2e)。根据统计分析,研究区地质灾害点数量同覆盖层厚度存在明显正相关关系,其覆盖层厚度1~3m和>3m对比,其频率比由4.15 迅速增加到34.8,这表明随覆盖层厚度增加,地灾点密度亦增加,当覆盖层厚度超过3m 时,地质灾害发生概率剧增。
3.2.6 岩性与岩土结构
根据资料收集与野外地质调查结果,将区内岩性与岩土结构分为“岩石坚硬、结构完整”、“岩石较坚硬、结构较完整”、“岩石较破碎、镶嵌结构”、“岩石破碎、有不连续软弱结构面”和“岩石特别破碎、有连续软弱结构面”5 个级别(图2f)。据相关数据统计,“岩石特别破碎、有连续软弱结构面”的地质灾害百分比最高,频率比最大,主要原因在于随着岩石破碎程度的增加,表层全强风化层在强降雨作用下,吸水容重大幅度增加、抗剪能力降低,进而引发相应的地质灾害。
3.2.7 斜坡结构
根据实地调查所得的具体情况,将斜坡结构分为顺向坡、斜向坡、横向坡、逆斜坡和块状结构斜坡这5 种(图2g)。据相关统计数据显示,其频率比顺向坡最大,达6.71,块状结构斜坡最小为0.57,表明顺向坡对地质灾害影响最大,而块状结构斜坡对地质灾害的影响最小。
3.2.8 与构造间距离
在研究区,东部是北东和北西两组断裂带的主要发育区,本次将此因子分为0~50m、50~100m、100~300m、300~500m 和>500m 这5 级(图2h)。据统计,以往灾害点主要分布在断裂带上或距离断裂带两侧不超过500m 范围内,该地区地灾受构造影响相对较小。
3.2.9 切坡高度
本次调查将切坡高度作为影响因子,分为0~3m、3~6m、6~12m 和>12m 这4 个级别(图2i)。根据调查结果显示,增加切坡高度与地质灾害的发生呈正相关关系。具体的统计数据表明,当切坡高度达到或超过3m 时,地质灾害的比例超过了分级面积百分比,这表明切坡高度超过3m 时,地质灾害的发生程度受切坡高度的影响较为显著。
4 地质灾害易发性评价
4.1 评价单元的选择
本次野外调查和评价以斜坡单元作为基本单元,划分时遵循技术要求,以上方和两侧的分水岭以及沟谷为界限,下方包括可能影响的居民区、道路或河流等外侧为界,同时还注重微地貌特征和单元之间的衔接,每个斜坡单元具有相似的地质环境条件、成灾机制和致灾模式等相关要素[29]。遵循上述原则,共划分了1497 个斜坡单元,且这些单元的面积大小总体均匀分布。故本文选择斜坡单元作为本次研究的评价单元。
4.2 信息量模型
4.2.1 相关性分析
为确保评价结果精度,本研究选取的各评价因子可能存在相关性,如果不进行筛选,会使它们对地质灾害的影响互相叠加,从而降低评价结果的精度。为了确保各评价因子之间相互独立,本研究使用SPSS 软件对研究区所有评价指标的信息量值进行了相关性分析,并列出了各指标之间的相关性系数(表1)。由表可知,本文选取的9 个评价指标之间相关性较弱,可以将他们纳入研究区评价模型[30]。
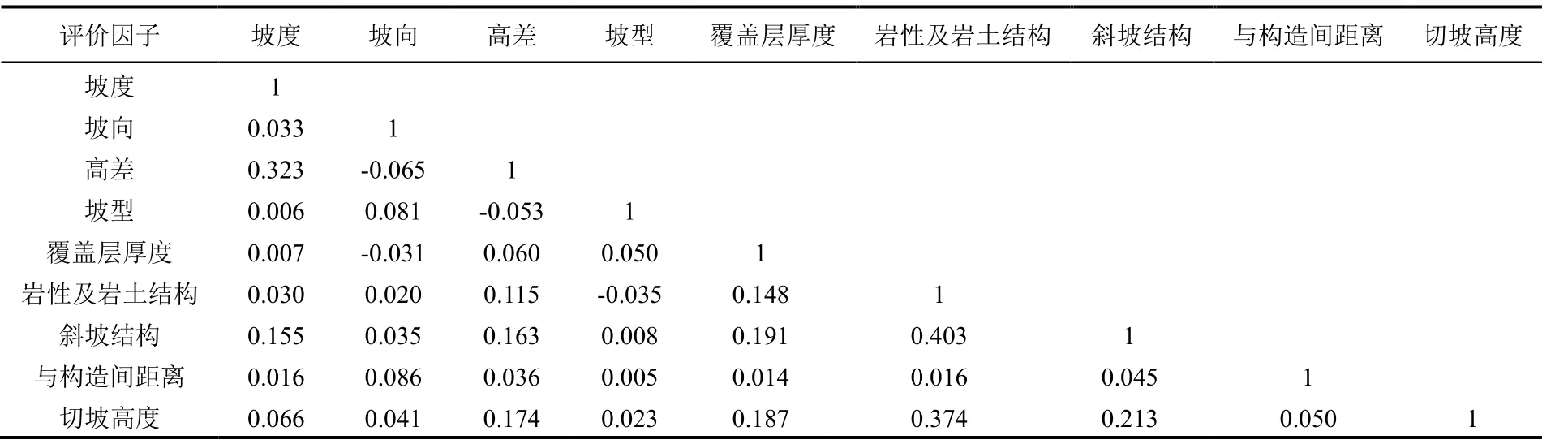
表1 评价指标因子相关系数Table 1 Correlation coefficient of the assessment indexes
4.2.2 评价因子信息量计算
本次选取的研究区总面积为114.28km2,记录了包括崩塌、滑坡和泥石流共计93 个地质灾害点。由于沟谷泥石流大多涉及多个斜坡,其形成机制和相关影响因素与崩塌和滑坡明显不同,因此采用泥石流沟易发程度数量化评分标准进行评价[25]。而对于坡面泥石流,由于缺乏相应的评价标准,并且本地区的坡面泥石流都涉及单一斜坡,其影响因素与滑坡相似。在采用信息量模型计算时,首先排除了研究区内的20 个沟谷泥石流灾害点,剩下73 个地灾点包括崩塌、滑坡和坡面泥石流灾种参与计算。
为了建立地质灾害易发性评价指标体系,选择9 个评价因子,这些因子包括坡度、坡向、高差、以及斜坡的坡型、覆盖层厚度、岩性与岩土结构、斜坡结构、与构造间距离、以及切坡高度。根据公式(2),使用ArcGIS 软件中的斜坡单元计算器功能,可以得到各评价因子二级分类的信息量值(表2)。

表2 全部影响因子分类及信息量值Table 2 All influence factor classifications and information values
4.3 信息量-逻辑回归模型
为建立信息量-逻辑回归模型,选取包括崩塌、滑坡和坡面泥石流在内的73 个地质灾害点作为样本,并在ArcGIS 平台上随机选择相同数量的非灾害斜坡点,共计146 个点,来构造训练集。从训练集样本中获得了9 个评价指标的属性信息,并将灾害点和非灾害点分别标记为二分量值1 和0,作为模型的因变量。为了排除评价变量之间存在共线性的可能性,通过使用SPSS 软件进行共线性检验,结果显示,各评价因子的容忍度均大于0.1,方差均小于10,不存在共线性。随后,将已准备好的73 个地质灾害样本点和73 个非地质灾害样本点斜坡的评价因子信息量值导入SPSS软件中。以各评价因子分类级别的信息量值作为自变量,以是否发生灾害作为因变量(0 表示未发生地质灾害,1 表示已发生地质灾害),进行二元逻辑回归计算。在逻辑回归计算中,显著性Sig≤0.05 表示回归系数有效,评价指标因子具有统计意义[31]。经过逻辑回归计算,除坡度、与构造间距离和斜坡结构这3 个因子逻辑回归系数显著性Sig值大于0.05 外,其他6 个因子的Sig值均小于0.05,表明这6 个评价因子之间存在显著性差异。经过霍斯默(Hosmer)和Lemeshow 检验,结果显示Sig值为0.273>0.05,表明这种逻辑回归模型有效。根据逻辑回归结果(表3),6 个评价因子逻辑回归系数都是正数,表明这些评价指标因子对模型都起正向作用,其中坡向和覆盖层厚度因子系数值都大于1,在6 个因子权重占比分别为26.45%和24.68%,说明这2 个因子对地灾发生的影响作用相对较大。

表3 各评价因子逻辑回归系数和显著性Table 3 Logical regression coefficient and significance of each assessment factor
将表3 各评价因子的逻辑回归系数带入公式(5),并同公式(4)一起构建基于信息量-逻辑回归模型的地质灾害易发性评价体系。在ArcGIS 平台上使用斜坡单元计算功能,将各评价因子图层进行叠加,得到研究区地质灾害易发性评价指数图。使用ArcGIS 自然断点功能将该指数图划分为高易发区、中等易发区、较低易发区和极低易发区。
4.4 综合评价结果
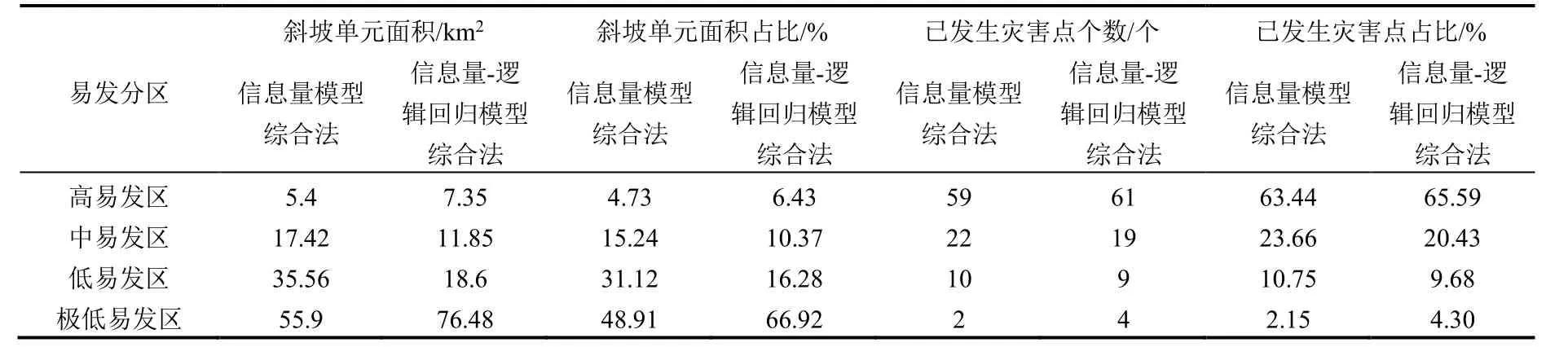
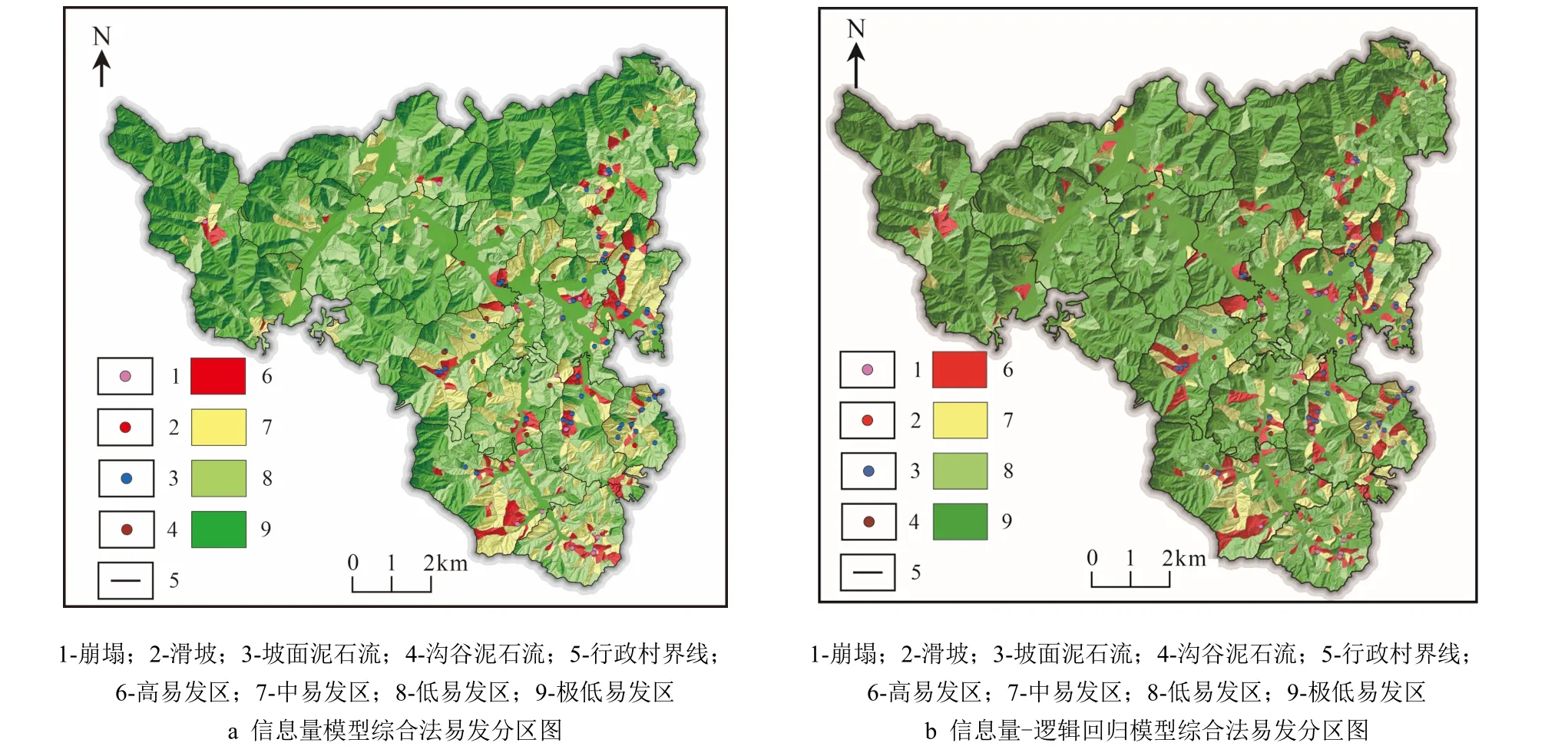
信息量模型综合法和信息量-逻辑回归模型综合法均采用自然断点法对地质灾害易发性进行级别划分,并将结果与沟谷泥石流易发性评价结果进行比较,得出了综合性的评价结果。
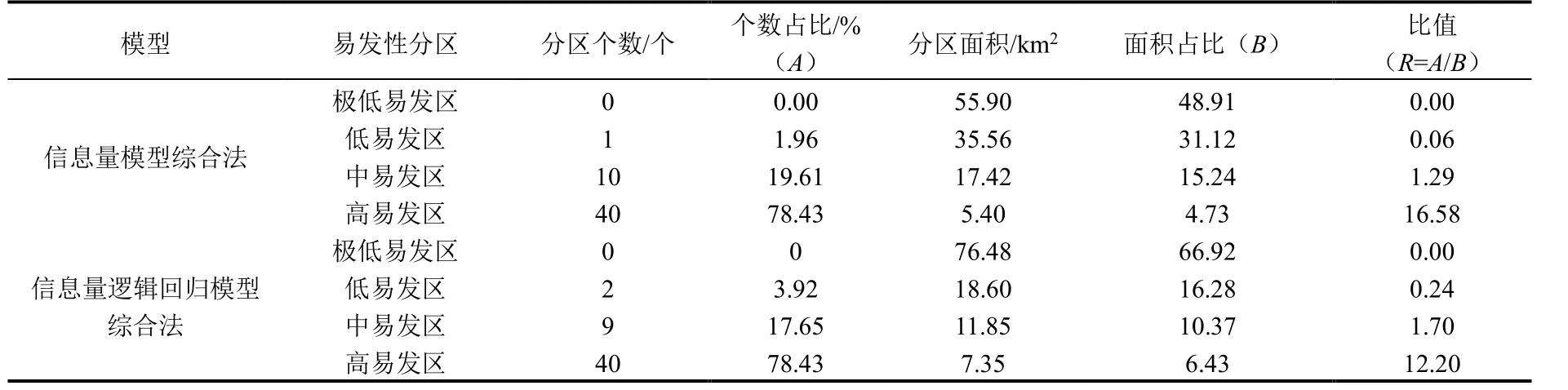
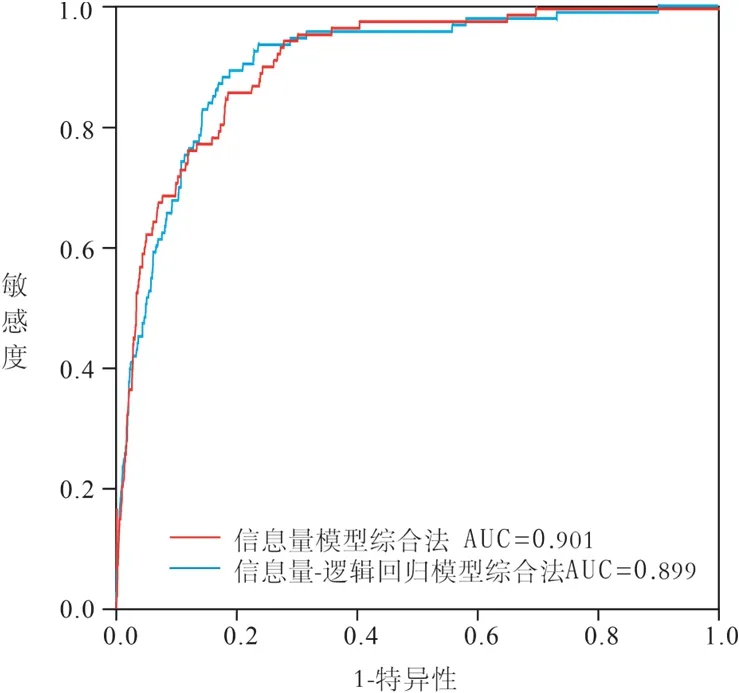
信息量模型综合法首先利用ArcGIS 平台计算每个斜坡的9 个因子的信息量值,并将其累加得到斜坡的综合信息量值。而后采用自然断点法对研究区的斜坡进行易发性级别划分,将其分为极低易发区(-9 表4 沟谷泥石流易发性评价结果Table 4 Assessment results of the susceptibility of valley debris flow 根据信息量模型综合法和信息量-逻辑回归模型综合法的综合易发性评价结果,研究区被划分为极低易发区、低易发区、中易发区、高易发区,其面积分别为:信息量模型综合法评价结果为55.90km2、35.56km2、17.42km2、5.40km2(图3a);信息量-逻辑回归模型综合法评价结果为76.48km2、18.60km2、11.85km2、7.35km2(图3b)。根据易发性评价结果,统计了2 种方法各易发性等级斜坡面积、面积占比、已发生灾害点个数和地灾点个数占比(表5)。 表5 各易发性分区占比统计Table 5 Statistics on the proportion of each susceptible zone 图3 研究区地质灾害易发性分区Fig.3 Division map of geological hazard susceptibility in the study area 由表5 可知:信息量模型综合法和信息量-逻辑回归模型综合法发生在中、高易发区以上地灾点占比分别达87.10%和95.02%,且都以高易发区地灾点占比最大,随着地质灾害易发性由高到低,相对应的地质灾害点占比也越来越小,在理论上符合等级划分的原则。 信息量模型综合法和信息量-逻辑回归模型综合法地质灾害易发性等级的频率比值均从极低易发区到高易发区明显增大,表明均能有效评价研究区地质灾害易发性。信息量模型综合法和信息量-逻辑回归模型综合法计算的高易发区频率比值分别占总频率比值百分比为 87.37%和79.50%。 研究结果显示,易发区域主要分布在东部,包括石门村、马益村、庆丰和村以及中坑村,这些地区的易发性受到多个因素的综合影响。断裂构造和密集节理的存在导致岩体破碎,从而增加地质灾害的风险性;东部地区的岩石容易受到风化和破碎影响,从而导致该区产生相对较厚的全、强风化层,进一步加剧了地质灾害的易发性;该地区存在较厚的覆盖层,增加了地质灾害的发生概率;人类工程活动加剧该区地质灾害的发生,特别房前屋后切坡高度较大且没有有效支撑措施时,其影响将进一步扩大。 相比之下,研究区的西部地区易发性较低。这主要归因于岩性坚硬、结构完整且第四系厚度相对较薄,减少了地质灾害的发生概率。综合来看,研究区易发区域的分布格局是由地质条件和人类干预的综合影响所决定的。 本次将野外调查的未进入模型的51 个稳定性较差或差的斜坡进行模型效果检验,以验证模型是否满足稳定性较差或差检验点斜坡落在高易发区内占比最大、极低易发区所占面积占比最大、检验样本各分区个数占比和模型各分区的面积占比的比值由极低易发区向高易发区逐渐增大。 如表6 如示,两种方法都符合要求,但信息量模型综合法R值区分度稍高于信息量-逻辑回归模型,但差别不大;这2 种方法的高易发面积占比分别为4.73%和6.43%,稳定性较差或差斜坡各分区个数占比两者都为78.43%。此外,信息量模型综合法在高易发区比值R为16.58,略高于信息量-逻辑回归模型综合法的比值12.20,表明在相同高易发面积条件下,信息量模型综合法灾害命中概率要略高于信息量-逻辑回归模型综合法;信息量模型综合法的极低、低易发区比值分别为0.00、0.06,略低于信息量-逻辑回归模型综合法的0.00、0.24,说明在低易发区域,使用信息量-逻辑回归模型综合法预测灾害发生概率要略高于信息量模型综合法。由此可见,信息量模型综合法与信息量-逻辑回归模型综合法的分区结果相比较,其准确性和合理性略高。 表6 研究区地质灾害评价效果检验Table 6 Test of the assessment effect of geological hazard in the study area 本文使用ROC 曲线来评价拟合数据和实测数据之间的关系,以AUC 值表示成功率或有效性(图4)。曲线中纵轴为敏感度,横轴为特异性,ROC 曲线下的面积是AUC 值,AUC 值越大表示模型的评价效果越好[24]。在精度验证过程中,对于采用沟谷泥石流评价结果的斜坡,其信息量I值和信息量-逻辑回归法p值按沟谷泥石流评价方法得出易发性得分以内插法换算相应I 值和p值数据与原模型计算数据进行就高原则对比确定(表4)。经验证,信息量模型综合法和信息量-逻辑回归模型综合法AUC 值分别为0.901 和0.899,表明这2 种方法均能相对准确地评价研究区地质灾害的易发性,信息量模型综合法比信息量-逻辑回归模型综合法评价精度略高,但两者相差不大。这结论与前人李信等[30]和田钦等[32]研究结果信息量-逻辑回归模型ROC 检验精度高于信息量模型有所不同,可能原因是该地区存在大量坡面泥石流,导致了数据集的特殊性。坡面泥石流可能具有明显的地质、地形、水文等特征,这些特征可能在信息量法中起到重要作用,从而导致信息量法的评价精度表现更优。 图4 ROC 曲线Fig.4 ROC curve plot 分别采用信息量模型综合法和信息量-逻辑回归模型综合法对诸暨马剑镇开展地质灾害易发性评价研究,并利用ROC 曲线对评价精度进行检验,实地调查得到的稳定性较差或差斜坡进行结果验证,得出如下结论: (1)信息量模型综合法和信息量-逻辑回归模型综合法对评估结果都具有较好的合理性和准确度,在精度预测方面,信息量模型综合法略微优于信息量-逻辑回归模型综合法,但差距并不显著。 (2)地质灾害易发性评价结果表明高易发区主要集中于研究区东部,该区域受到频繁的人类工程活动影响,岩体整体比较破碎且覆盖层厚度较大,坡向、覆盖层厚度岩性、坡型和与岩土结构等因素对地质灾害的控制起着关键作用。 (3)研究区的主要地质灾害为由“6.10”降雨事件引发的坡面泥石流,鉴于所提取数据源的特殊性,采用信息量-逻辑回归模型综合法中的线性回归来描述评估因子之间的复杂非线性关系仍然面临挑战。因此,在研究该区域地质灾害易发性评价时,仍需要进一步加强对该区致灾因子的复杂性分析。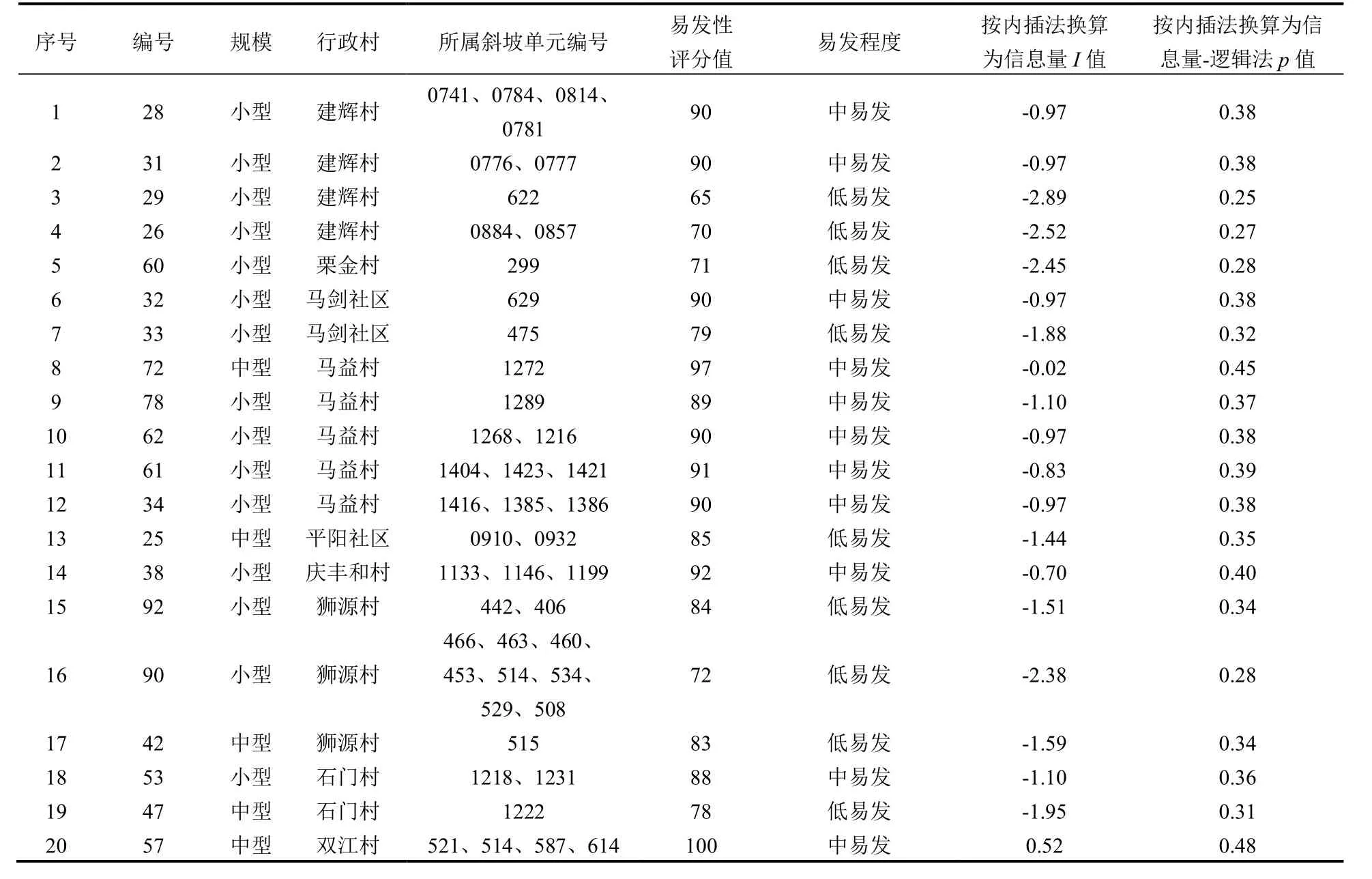
4.5 地灾规律初步认识
5 评价效果检验
5.1 评价结果检验
5.2 精度验证
6 结论
