基于Renyi熵的文本情感分析
2024-01-12张冠东姜荣
张冠东, 姜荣
(上海第二工业大学, 数理与统计学院, 上海 201209)
0 引言
在人工智能不断发展的今天,人们不仅可以通过各种社交媒体记录日常生活的感想,发表对时事新闻的观点,还能通过阅读别人发表的言论获取许多额外的信息。然而,发布的信息对整个社会的舆论导向有着重要的影响,有的信息会带来正能量,有的信息会有负面的煽动效应。因此,在海量文本数据下,为了有效地捕捉文本所包含的褒贬情感色彩,从而鼓励推广正能量信息的传播,同时也能提供有效的措施预防负面信息对社会带来的影响,学者们提出了许多研究方法。他们一般是利用关键词频率、预先设定的情感规则,或者利用已有的情感词典对文本进行分析,进而为文本贴上褒贬的标签[1],也有不少的方法采用机器学习、深度学习的理论构建分类器来分析文本的褒贬。但这些方式一般都以文本词性的单一性为基础,缺乏对文本词汇多样性的思考。
目前,在文本分类方面已经存在不少的研究并取得了一定的进展。在长文本研究领域:林呈宇等[2]对弱监督文本中的噪声进行了研究,通过增强标签语义提高了文本分类的精度;尹雪婷等[3]针对词频在文本分类中低准确率的问题,通过引入加权因子并结合上下文信息,提出了一种基于任务优化文本表示学习的文本分类算法,为文本分类提供了新的思路;李建平等[4]利用改进的长短时记忆网络更好地发现了特征词的前后关联关系,从而找到极其重要的潜在语义因素,提高了分类的准确率。在短文本研究领域:田小瑜等[5]利用标签到文本本身的映射过滤文本中的无效信息来生成文本信息标签,提出了一种深度模块化标签注意网络用于文本分类;李博涵等[6]重点研究了短文本的分类,将知识感知与双重注意力机制相结合,提出了一种新的文本分类机制,提高了模型对短文本中有效信息提取的效率。在情感分析领域:陈红阳等[7]将多因素融合在一起,构建了一种丰富语义与情感信息的文本特征向量进行文本分类;杨京虎等[8]对长文本的情感加以分析,其提出的模型可以通过滑动窗口抽取子事件的方法分析识别情感主体;赵宏等[9]将句法结构、上下文内容和语义特征等相融合,提出了一种特征融合的文本情感分析方法,提高了文本的分类精度。
以上研究的关注点在于文本文字方面的特征,且大部分研究内容更关注于文本的内容,缺少对词的多属性含义所含有的情感色彩研究。针对以上问题,本文主要针对英文文本中词汇的多属性特点进行褒贬倾向的分析,通过构建关键词句概括文本的内容,并给出褒贬评分来判断文本的情感色彩。
1 模型设计
1.1 理论分析
本文主要基于熵的理论基础。熵泛指度量某些系统或物质的一些状态,也可以理解为测量某些状态可能出现的程度。熵的理论已经被广泛地应用于热力学、物理学与信息论的研究。香农(Shannon)将熵引入了信息论,在目前的很多研究中,其可以描述为给定的概率分布(p1,p2,p3,…,pn},给出的公式为
(1)
Renyi熵[11]已经被应用于文本的关键词提取研究,且能揭示模型中混合随机变量的统计特性[10]。因此,在研究如何对文本的褒贬进行分类的问题中,本文也引入Renyi熵,其公式为
(2)

由于本文是基于文本语句的关键词进行褒贬分析的,且词汇并不是只有褒义或贬义的含义,因此提出一种新的改进型Renyi熵。由于贬义词包含的信息比褒义词多[12],因此将贬义词得分与褒义词得分的比值作为熵对数中的部分,设q=2,该改进型Renyi熵公式如下:
(3)
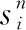
1.2 模型构建与实现
英文单词并不能简单地归结为褒义或贬义,在具体的语言环境中,不同的读者对词汇的理解可能会有不同的褒义或贬义的倾向。因此,在计算关键词句的褒义分值和贬义分值后,再对这些分值进行汇总得到语句的总的褒贬分。在提取关键词方面,由于BERT技术常用于关键词的提取[13-14],因此本文采用基于BERT的KeyBERT方法来提取关键词,该方法通过BERT嵌入,创建出与文本意思相似的关键词或短语。对关键词的多词性褒贬分值进行打分,采用SentiWordNet对单词的情感色彩进行打分,因为该英文电子词典能基于情感词进行极性标注并计算词极性的强度[15],从而对词的褒贬赋予有效的分值。本文方法的实现流程如图1所示。
图1 计算流程图
由于有的文本数据只包含符号或异常字符,这些文本语句将会被认定为异常文本而被过滤。对于正常文本,先对文本进行清洗,去除标点符号和异常字符,再将获得语句的关键词组成关键词句进行褒贬分值计算。
2 检验标准
对于文本的褒贬分类,通常采用准确率和精确率作为检验标准来判别模型的优劣。准确率(Accuracy)是指全部正确分类的对象数占总的研究对象数的比例,其计算方法为
(4)
其中,TP为正确的正例数,TN为正确的负例数,NAll为总的对象数。本文利用模型分类结果中正确的褒义分类数和正确的编译分类数之和与总的文本对象数的比值来计算准确率,因此TP可被认为是分类正确的褒义语句,TN可被认为是分类正确的贬义语句。精确率(Precision)是指模型各分类中所得的正确分类数占该类正确分类和错误分类之和的比例,其公式如下:
(5)
其中,Tc为正确的分类数,Fc为错误的分类数。本文对褒义和贬义分类均可计算精确度,公式为
(6)
(7)
其中,FP为错误的正例数,FN为错误的负例数。本文将FP认为是分类错误的褒义语句,FN认为是分类错误的贬义语句。
3 实例分析
对于英文的文本实例,所选用的数据集为被标签的IMDB和Yelp数据。将改进型Renyi熵、Renyi熵和香农熵分别应用于给定的公共数据集,得到的结果如表1、表2所示。
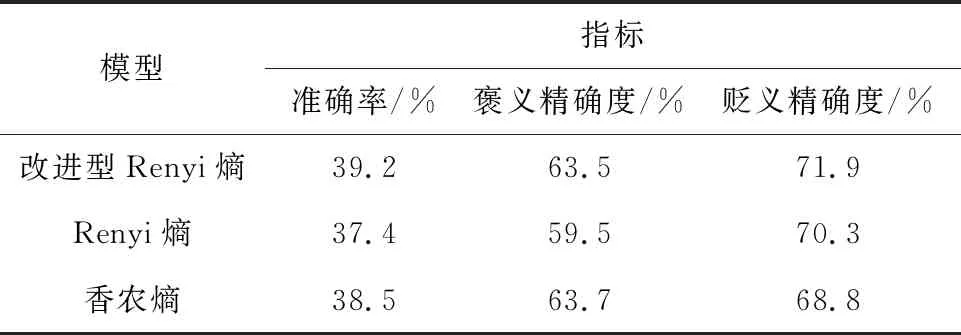
表1 IMDB数据集
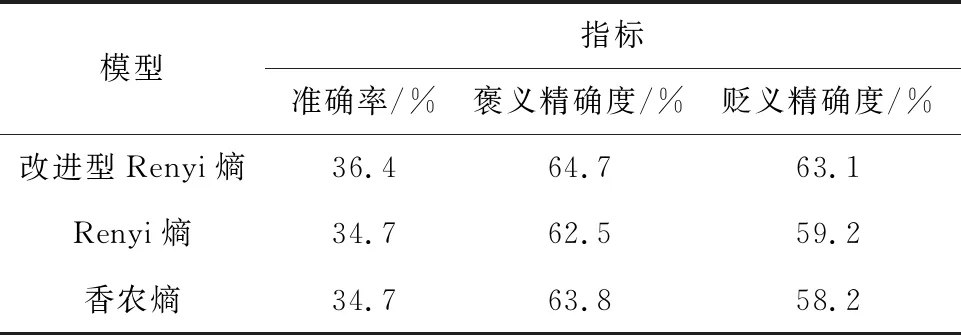
表2 Yelp数据集
由表1、表2可知,在准确率、褒义精确度和贬义精确度方面,绝大部分改进型Renyi熵的指标比Renyi熵和香农熵都有所提升。其中,精度比较结果如表3、表4所示。
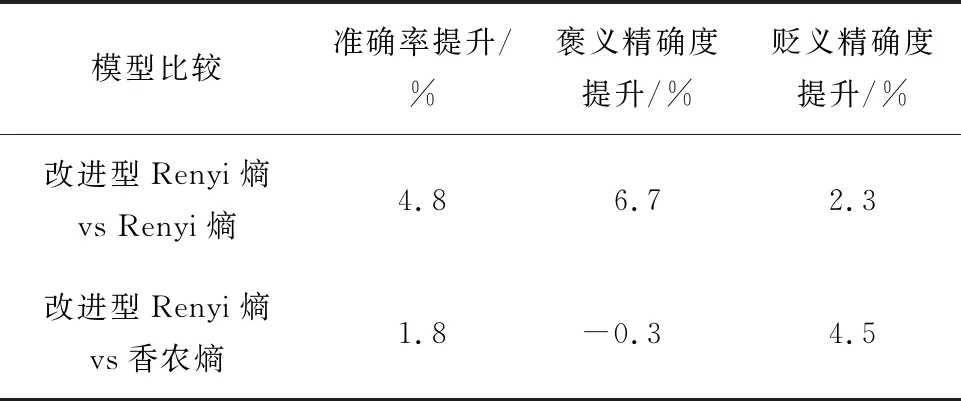
表3 IMDB数据集指标比较

表4 Yelp数据集指标比较
由表3、表4可知,在Yelp数据集中,改进型Renyi熵的褒贬分类性能均比Renyi熵和香农熵优越。在IMDB数据集中,虽然在褒义精确度方面,改进型Renyi熵比香农熵有所下降,但是其降幅仅为0.3%,其他的性能指标均显示出改进型Renyi熵比另2个模型优越。
4 总结
文本分析是人工智能时代重要研究内容之一,而文本褒贬分类则是文本分析领域的一个重要研究点。本文提出一种改进型Renyi熵模型对文本的褒贬进行分类,通过计算关键词多词性的情感倾向值分别得到词语的正面、负面情感倾向值,从而计算出该文本的褒贬倾向并加以分类。实验表明,该方法的分类性能较好,为文本分类提供了一种有效的思路。在未来的研究中,可以通过上下文的语境对关键词进行进一步的筛选,以提高文本分析的性能。
