深度学习在多光谱行人检测中的研究现状与应用前景
2024-01-12秦君李晓敏夺实祥伟
秦君,李晓敏,夺实祥伟
(云南电网有限责任公司德宏供电局,云南 德宏 678400)
0 前言
行人检测是计算机视觉领域解决的任务之一,在安全监控、自动驾驶等领域发挥着重要作用。在夜间或恶劣天气等条件下,可见光图像获得的细节信息有限,行人检测性能明显下降。与可见光相机工作波长区间不同,热红外相机利用环境中散发的红外波段的信息进行成像,不需要外部光源,受恶劣天气条件的影响较小,但在光照良好条件下热红外图像获得的细节信息远小于可见光图像,可见光图像与热红外图像获取的信息具有互补性,因此将二者融合可以有效克服光照或天气变化的干扰,提高检测精度,实现全时段检测。另外,由于红外热成像仪成本的下降及其实用性的提高,热红外图像信息得以在多光谱行人检测的研究中广泛应用。
传统的多光谱行人检测主要基于人工设计的特征进行检测,包括Haar-like 特征[1]、方向梯度直方图特征(Histogram of Oriented Gradients,HOG)[2]、 局部二值模式特征(Local Binary Pattern,LBP)[3]、 积分通道特征(Integral Channel Features,ICF)[4]和聚合通道特征(Aggregate Channel Features,ACF)[5]等特征,这些特征一般结合支持向量机等浅层分类器完成检测。2015 年,韩国KAIST 大学Hwang 团队[6]制作的KAIST 数据集成为多光谱行人检测领域模型算法验证的标准数据集,该团队提出的ACF+T+THOG(Aggregate Channel Features+Thermal+Thermal Histogram of Oriented Gradients)行人检测器算法作为该数据集的基准方法。人工设计的特征算子是针对行人特定属性设计的,不具有通用性,在大规模行人检测数据集上性能表现不理想。
随着深度学习的兴起以及GPU 的使用,特征的抽取不再局限于人工设计的特征算子,而是通过学习的方式自动提取特征。研究发现基于深度学习抽取的高层次特征在行人检测上表现出的性能整体优于人工设计特征的行人检测,具有代表性的模型是R-CNN 系列的模型。然而,目前大多数深度学习模型是基于可见光图像进行建模的,多光谱检测通常需要比单模态方法更复杂的网络架构。设计有效的多光谱融合策略,充分利用两种光谱的信息,提高在夜间或恶劣天气等条件下的检测能力是目前该领域的一个重点和难点问题,需要进行更加深入和具体的研究。
1 深度学习应用于多光谱行人检测的原理
深度学习方法以原始数据作为输入,通过大量数据的学习,自动提取物体特征并分类。根据是否需要对候选区域分类,基于深度学习的多光谱行人检测可以分为两阶段行人检测和一阶段行人检测[7]。两阶段行人检测通过生成的候选区域进行分类判断,具有代表性的网络结构是Faster R-CNN。一阶段行人检测没有分类过程,而是直接预测行人的边界框和置信度,具有代表性的网络结构是SSD。
1.1 基于Faster R-CNN的多光谱行人检测网络
Faster R-CNN 网络由Fast R-CNN 网络和RPN 网络两部分构成。R-CNN 网络[8]首先使用选择性搜索(Selective Search,SS)算法对图像提取候选区域,随后使用CNN 进行特征提取,最后进行分类和回归。Fast R-CNN 网络是对R-CNN 网络的优化[9],在R-CNN 网络的最后一个卷积层后加入感兴趣区域池化层(Region of Interest Pooling Layer,ROI Pooling Layer),将边框回归放入卷积神经网络中一起训练,即将特征提取和边框回归统一到一个网络中。Faster R-CNN 网络是在Fast R-CNN 网络的基础上加入区域建议生成网络(Region Proposal Network,RPN), 用深度学习的方式生成行人建议,可以加快训练速度并实现端到端的训练。
Faster R-CNN 网络结构如图1 所示。特征提取网络由5 个卷积层组成,输入的图像经过多层卷积后输出特征图。特征图输入到RPN网络生成行人建议候选区域,RPN 网络利用SPPNet 网络的区域映射机制[10]在特征图上进行滑窗,滑动窗口即卷积核一般为3×3。在这个过程中,每个窗口的中心位置会生成9 个不同尺度和长宽比的锚点(Anchor)。通过RPN网络可以得到几千个候选区域,以正负样本比为1:2 的比例选取前300 个候选区域作为RPN网络产生的候选区域,将其输入到Fast R-CNN网络中进行分类和边框线性回归。
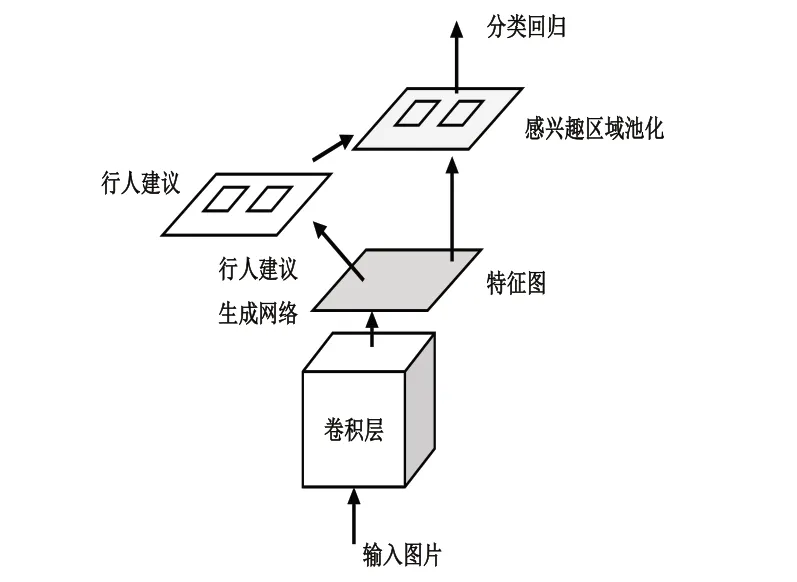
图1 Faster R-CNN简要结构
多光谱图像特征融合策略方式较多,以较为普遍的中间层特征堆叠融合策略[11]为例,介绍基于Faster R-CNN 的多光谱行人检测网络。如图2 所示,多光谱行人检测网络包含特征提取、融合特征生成、候选区域提取和分类回归四部分。特征提取模块由两路对称的深度卷积神经网络组成,与Faster R-CNN 特征提取网络相似,不同的是在多光谱行人检测网络中,可见光图像特征提取模块和热红外图像特征提取模块由Conv1-Conv4 共4 个卷积层构成。融合特征生成模块采用Fusion 层,首先将Conv4 层输出的多模态特征对级联,再经过融合层后获得融合特征。候选区域提取模块由卷积层Conv5 和RPN 组成,融合特征经过Conv5 层后获得特征图,特征图经过RPN 后获得行人建议,特征图和行人建议经过感兴趣区域池化层后送入全连接层进行分类回归,与Faster R-CNN 的分类回归部分相同。

图2 基于Faster R-CNN的多光谱行人检测网络
1.2 基于SSD的多光谱行人检测网络
SSD 网络是目前性能较好的目标检测框架之一,精度与Faster R-CNN 相当且速度更快,接近实时的效果。SSD 网络是一阶段目标检测方法之一,将候选区域提取、特征提取、分类回归步骤统一到一个网络中。SSD 网络对原始图像直接分类回归,采用了VGG16 的从卷积层Conv1-1 到卷积层Conv5-3 的13 个卷积层,将两个全连接层FC6 和FC7 转化为卷积层并额外增加了6 个卷积层,共21 个卷积层。它将6 个不同层次包括5 个卷积层和1 个池化层的特征图分别用卷积的操作预测目标位置偏移值和不同类别的得分,最后通过非极大抑制值得到最终的检测结果。但SSD 网络中没有全连接层,因此网络输出对目标周围信息更敏感。
一种基于多光谱信息融合的SSD 网络如图3 所示。网络的输入是成对的可见光和热红外图像,尺寸归一化为固定尺寸。SSD 网络由VGG16 网络的Conv1-Conv5 组成,将原始VGG16 网络的FC6 和FC7 用卷积层Conv6,Conv7 替代,并添加Conv8-Conv11 卷积块,最后选取Conv1-Conv5 中的Conv4-3、Conv7以及添加的Conv8-2、Conv9-2、Conv10-2、Conv11-2 共6 个不同尺寸,不同大小感受野的特征层去做行人目标检测。
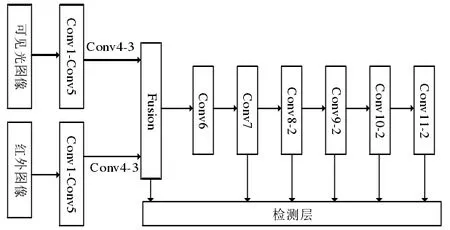
图3 基于SSD的多光谱行人检测网络
1.3 多光谱图像的融合方法
对于多光谱行人检测,数据融合是整个检测过程最重要的部分之一,不同形态、不同阶段的特征具有不同的表达能力。2016 年,Wagner等人[12]把多光谱行人检测方法分为像素级融合、特征级融合和决策级融合三类,并研究了两种基于深度学习方法的多光谱行人检测方法,分别是早期融合和晚期融合。2019 年,Li 等人[13]将融合方式分为输入融合、早期融合、中期融合、晚期融合和两种决策级的融合。
1.3.1 输入融合
在数据输入到模型之前,将可见光和热红外图像简单堆叠,形成4 通道RGBT 图像并输入到第一个卷积层,之后使用完整的网络进行检测,如图4(a) 所示。输入融合方法是从可见光图像行人检测到多光谱行人检测最直接简单的融合方法,因为对于不同的输入通道,只需要对网络的第一个卷积层进行修改。
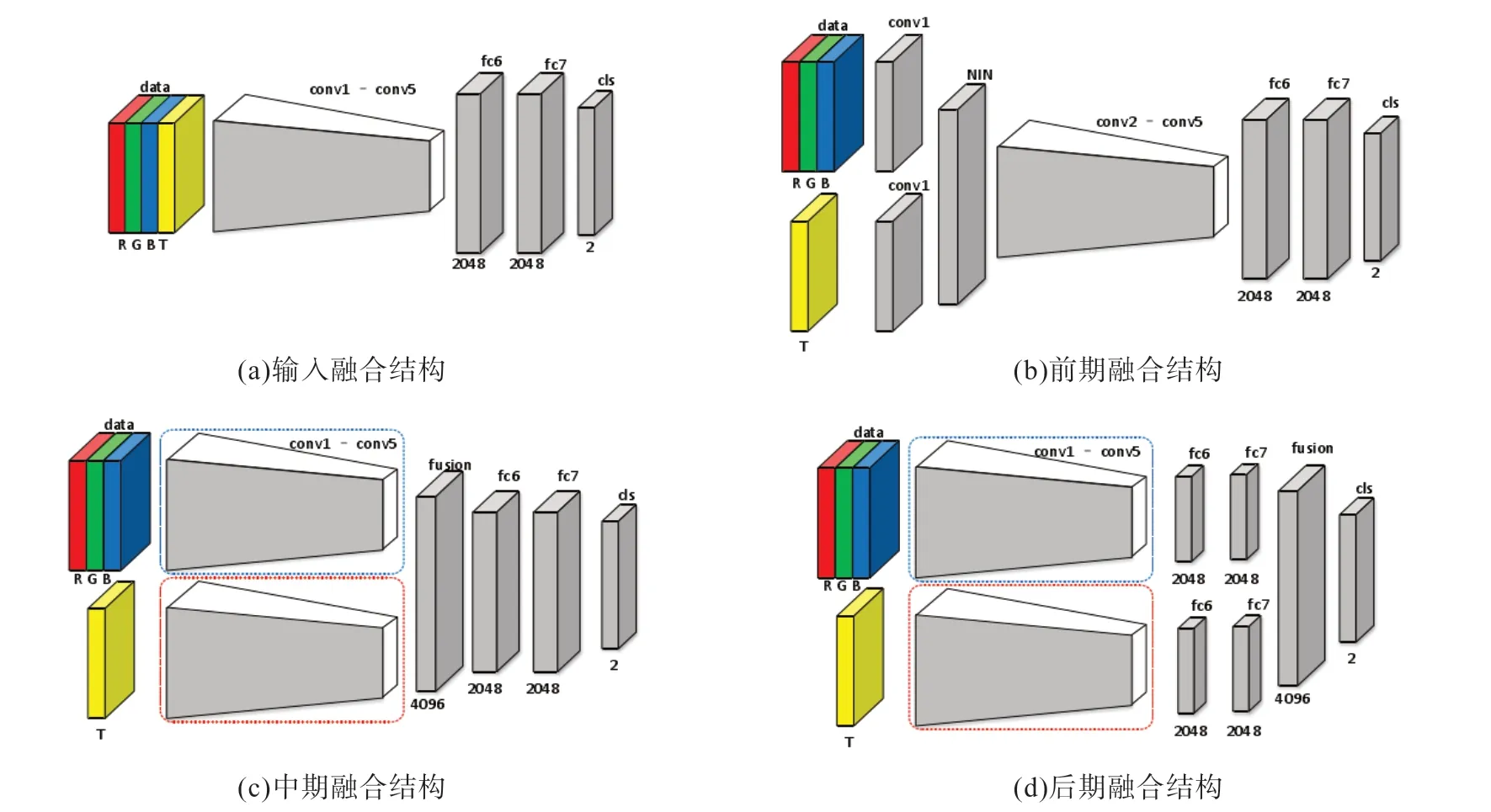
图4 常用的4种融合方式示例
1.3.2 早期融合
早期融合方法是在可见光图像和热红外图像分别在第一个卷积层进行特征提取之后,使用Network-in-Network(NIN)方式将特征连接起来并降维,之后通过共有的网络结构进行特征提取和分类回归,如图4(b)所示。早期融合方法在已有的目标检测网络基础上添加了NIN操作层。
1.3.3 中期融合
中期融合方法是在前期使用两个纯卷积网络分别对可见光图想和热红外图像进行特征提取,之后对提取的特征进行连接并使用NIN 方法降维,再使用全连接层进行分类回归,如图4(c)所示。
1.3.4 晚期融合
晚期融合方法是使用两个子网络分别处理输入的可见光图像和热红外图像,经过卷积层和全连接层之后再将输出进行连接,之后使用两个全连接层进行分类,如图4(d)所示。
1.3.5 决策级融合
决策级融合方法分为两种,级联融合方式和非级联融合方式。级联融合方式是通过两个单独的子网络检测,将检测结果输入到第三个子网络中,对置信度重新进行评分,最后对两阶段检测的置信度得分使用0.5 的权重进行合并,该方式可看作两个子网络的简单级联。非级联融合方式与晚期融合类似,通过两个子网络的特征生成最后的行人检测框,然后将两个子网络生成的检测边界框回归进行平均生成最后检测结果,该融合方式比级联融合方式效率更高。
2 深度学习在多光谱行人检测中的研究现状
随着硬件的升级以及深度学习的发展,基于可见光图像的行人检测技术有了巨大的发展,性能逐渐趋于完善。但是对于全时段检测,即包含夜间或恶劣天气条件下的检测,主要采用可见光和热红外图像融合的方式,利用多光谱信息的互补性可以提高行人检测的性能。多光谱行人检测的关键技术是热红外和可见光的融合技术,而使用深度学习进行多光谱行人检测的方法大多数基于特征级融合和基于决策级融合。
2.1 基于特征级的融合方法
特征级融合是指将不同的模态数据转化为高维特征表示后在模型的中间层融合,一般包括早期融合、中期融合和后期融合。
2016 年,Wagner 等人[12]首次使用深度模型融合可见光和热红外图像,并研究了前期融合和后期融合的CNN 架构对检测性能的影响。前期融合将可见光图像和热红外图像在像素级融合后输入模型中进行检测,而后期融合是使用单独子网络为可见光和热红外图像分别生成的特征表示级联后输入到后续全连接层中进行检测,结果表明后期融合检测器性能优于前期融合,且与ACF+T+THOG 行人检测器相比性能更好。Liu 等人[11]深入分析了两阶段的Faster R-CNN在多光谱行人检测任务中的应用,并对比研究了早期融合、中期融合、晚期融合和决策级融合在实验中的表现,结果表明中间层特征相较其它层,采用通道堆叠策略可以最大限度整合红外和可见光模态的信息,并能更好的保留低层的细节信息和高层的语义信息,结合中间层特征堆叠策略和Faster R-CNN 框架,在KAIST 多光谱行人检测数据集上获得了较高的准确率。
2017 年,Konig 等人[14]提出Faster R-CNN并不完全适用于行人检测任务的观点,并提出了Fusion-RPN 算法,使用Faster R-CNN 框架中的区域建议生成网络(RPN)和增强决策树分类算法(Boosted Decision Trees,BDT)协同完成多光谱行人检测。在特征融合部分使用Liu 等人提出的中间层特征堆叠策略。结果表明该算法在KAIST 多光谱行人检测数据集上获得了极优的性能,甚至远超后来的一些研究。但是BDT 算法计算量巨大、耗时大,导致整体算法训练复杂。
2018 年,Lee 等人[15]在特征融合过程中添加了特征关联层,用来增强红外与可见光两模态的特征信息,为融合红外和可见光做准备。该算法选用面向目标检测的一阶段去卷积检测器(Deconvolutional Single Shot Detector,DSSD),首先提取中间层特征Conv4 之后的一对特征,并对两流的特征采用特征相乘操作进行特征增强,再将两特征与相乘后的特征级联,并降维获得融合特征,用获得的融合特征完成后续检测任务。
2019 年,Cao 等人[16]提出了双流区域建议生成网络(Two-stream Region Proposal Network,TS-RPN), 在特征融合部分使用中间层特征堆叠策略,但是去除了网络中的最后三层全连接层,以减小模型尺寸,并获得了优于中间层特征堆叠策略的性能。同时,该算法还创新性引入无监督行人检测算法(Unsupervised-TS-RPN,U-TS-RPN), 通过可迭代的标注器自动生成标注,节省人工标注的成本和时间,但U-TS-RPN 的算法精度略低于TS-RPN。
2020 年,Zhang 等人[17]提出一种多层融合网络,并在网络中间分别加入空间注意力模块和通道注意力模块来处理模态关系,其中通道注意力模块用来融合红外和可见光特征,通过自监督的方式微调权重,而空间注意力模块是通过外部监督来训练。通过对比单独加入两种模块以及同时加入两种模块的算法性能,得出单独使用空间注意力模块的多层融合网络可以获得最优的检测性能。Pei 等人[18]首先针对深度卷积神经网络的三个卷积阶段设计了三种融合架构,然后在三种融合架构上比较三种融合策略(相加、取最大值、堆叠)的性能,得出在该网络上采用相加融合策略性能最优,最后将得出的最优融合策略与基于特征金字塔网络的目标检测器(Feature Pyramid Networks for Object Detection,FPN) 相结合, 利用FPN+SUM 算法完成多光谱行人检测。、
2022 年,Xiang J 等人[19]提出了单模态增强框架SMA-Net,通过增强单模态的特征提取能力来实现基于可见光- 热红外图像的行人检测。在该框架中引入了一种轻量级ROI 池化多尺度融合模块PMSF,通过自适应加权的方式对不同尺度的池化特征进行融合,可以获得更细粒度、更丰富的特征。实验结果表明,在KAIST 数据集上与目前最先进的方法相比,SMA-Net 在检测精度和计算效率方面具有更好的性能。
2.2 基于决策级的融合方法
决策级融合在通常使用在模型最终的预测阶段,好处是融合模型的错误来自不同的分类器,而来自不同分类器的错误往往互不相关和影响,不会造成错误的进一步累加。决策级融合方法通常利用光照信息学习融合权值来融合可见光和热红外图像的学习结果。
唐聪等人[20]利用预训练的单阶段目标检测器分别对红外与可见光图片获取检测框和分类分数,然后将所有检测框和分类分数收集到候选框组,删除具有高重叠率的检测框,并选择置信度最高的框。
Guan 等人[21]提出了一种基于光照感知多光谱行人检测和光照感知多光谱语义分割联合学习的新型多光谱行人检测器和昼夜照明子网络的光照感知加权机制。利用多光谱图像中编码的光照信息,通过设计的光照全连接神经网络IFCNN 准确计算出光照感知权值。结果表明,光照感知加权机制为改进多光谱行人检测器提供了一种有效的策略,该方法具有较高的检测精度且检测时间更短。
Li 等人[13]研究了基于Faster R-CNN 模型的六种网络结构并分析了它们的适用性,通过实验发现目标预测置信度会受光照影响,由此提出了IAF R-CNN 模型,通过对光照信息的自动感知辅助行人检测,该模型具有较高的检测准确度。
2.3 基于模态迁移的融合方法
Xu 等人[22]提出使用预训练的VGG16 搭建卷积网络来学习从可见光图像到红外图像的非线性映射关系,而无需人工监督。将学习到的特征表示迁移到第二个网络中,通过学习两者之间的关系对可见光图像进行操作并有效地对多模态信息进行建模,学习到的两者间的特征表示可以应用在其他许多常见的单模态行人数据集上。该方法在测试阶段仅使用可见光图像,检测性能上要差于同时使用多光谱数据的检测器。
Liu 等人[23]提出了一个教师- 学生网络来完成多光谱行人检测任务,教师网络是以红外和可见光为输入的双流网络,两流网络在中间层完成简单的融合,学生网络是只有可见光输入的单流网络。训练过程中以知识蒸馏的方式,用多模态网络指导单模态网络完成训练,其中学生网络可以很好的应用在只有可见光的行人数据集上。
综上所述,使用深度学习的多光谱行人检测方法多数采用特征级融合,基于决策级的融合主要在测试阶段对目标检测框进行处理,缺少网络训练过程中的交互,因此较少采用。模态迁移方法不同依赖数据,并且迁移方法对结果的影响较大,精度较低于其它融合方法。另外还有基于混合方法的融合,即同时采用特征融合和决策级融合的方法,此类方法大多会将研究的重点落在特征融合上,因此基于特征级融合的多光谱行人检测方法仍是目前最常用的研究方法。
3 深度学习在多光谱行人检测中的应用前景
3.1 全时段检测
可见光图像受到因白天和夜间光照变化的影响而导致不同的行人目标特征,从而使得可见光与热红外图像融合特征在不同光照环境下具有差异性。目前多光谱行人检测大多采用单一分类器进行特征分类,无法有效识别因光照环境变化而导致的不同行人特征,从而出现漏检的情况,增强多光谱行人检测在全时段检测的鲁棒性是未来的发展方向之一。
3.2 实时检测
使用深度学习方法的多光谱行人检测模型虽然检测精度高,但检测速度并不高,而对实时性要求高的场景如自动驾驶,对检测速度要求很高,现有方法并不能满足较高的实时性,因此有必要平衡检测精度和速度之间的矛盾,即在满足检测精度的条件下提高检测速度,是多光谱行人检测面向自动驾驶应用的关键技术之一。
