基于指定特征的加权co-location 模式挖掘方法
2024-01-12赵秦怡黑邵敏
赵秦怡,黑邵敏
(大理大学数学与计算机学院,云南大理 671003)
空间co-location 模式挖掘是空间数据挖掘的研究分支,研究成果有广泛应用。co-location 模式(并置模式)是空间特征集的一个子集,其特征实例在地理空间中频繁出现互相近邻,在满足某种colocation 模式的空间中,模式的特征实例往往并置出现。例如,空间特征集{医院,药店,花店}是一个colocation 模式,则医院、药店和花店在地理空间中频繁出现互相近邻。
co-location 模式挖掘算法有大量的研究成果,基于全连接的挖掘算法〔1〕将两个低阶的模式表实例相连接,并查询不相同特征实例的近邻关系得到高阶模式表实例。基于部分连接的挖掘算法〔1〕把实例集中的实例分割为一些不相交的团,由团中实例间的互相近邻关系得到co-location 模式表实例,再通过扫描实例近邻关系集获取团之外的模式表实例。基于星型邻居模型的无连接挖掘算法〔2〕从星型邻居集中收集候选co-location 模式的星型表实例,再从星型表实例中去除非co-location 表实例。为解决挖掘过程中表实例生成时间复杂度高的问题,Wang 等〔3〕提出了基于前缀树的高效挖掘算法,挖掘过程中直接通过前缀树来快速生成所有模式的表实例集。在非经典数据挖掘研究方向,一些挖掘算法相继提出,如基于值不确定性及存在不确定性数据的co-location 模式挖掘、基于区间数据的colocation 模式挖掘、基于模糊数据的co-location 模式挖掘、带稀有特征的co-location 模式挖掘等方法〔4〕。而高效用co-location 模式挖掘〔5〕、主导特征colocation 模式挖掘〔6〕方法则提高了挖掘结果的指导性。
co-location 模式挖掘算法基于模式参与实例的数据度量模式的频繁度,挖掘特征集中所有的频繁模式,挖掘过程中不需要用户的涉入,未考虑数据特定的应用领域以及用户的偏好。显著特征的colocation 模式挖掘〔7〕、领域驱动的co-location 模式挖掘〔8〕、负co-location 模式挖掘〔9〕等方法对上述问题有很好的解决,减少了对挖掘结果的再处理。co-location 模式在特定领域如城市空间规划、植物栽培等有广泛的应用,例如基于公交站点的colocation 模式反映了学校、居民区、商场超市、医院、药店等空间对象基于公交站点存在的互相近邻关系,可用于指导在人群密集以及人员流动大的区域进行公交站点的选址。co-location 模式挖掘算法〔1〕采用特征最小参与率度量模式的频繁程度,存在如下情况:模式在基于指定特征的实例并置程度满足模式指导性要求,但由于部分特征的总实例数过多,使得这些特征在模式中的参与率小,模式具指导意义,但被界定为非频繁模式。基于此,研究了定义基于指定特征的加权参与率计算规则,提出一种基于指定特征的加权co-location 模式(weighted colocation patterns based on specified feature,WCPBSF)挖掘方法。WCPBSF 挖掘方法基于指定特征度量特征参与率及模式实例间的并置程度,可以有效挖掘WCPBSF,提高挖掘结果在指定领域的指导性,实验结果验证了该挖掘方法的有效性。
1 WCPBSF 挖掘方法
若c 为空间特征集的一个子集,c 的特征数为n,c 的模式频繁度用参与度度量,参与度指c 中所有特征参与率(participation ratio,PR) 的最小值(PR(c,fi)),记为PI(c)。特征参与率记为PR(c,fi),被定义为特征fi在模式c 的表实例(模式表实例中的实例之间均两两近邻)中不重复出现的实例个数与fi总实例个数的比率〔5,10〕,计算式表示为:
若c 的参与度大于给定的参与度阈值,则c 是一个co-location 模式〔4,9〕。在城市空间特征实例集中,若医院、药店、花店3 个特征的参与率均大于参与度阈值,则{医院,药店,花店}是一个频繁并置模式,称其为co-location 模式。
例1 设医院、药店、花店3 个特征的实例数分别为10、20、30,实例数分别为8、10、15,则它们的参与率分别为0.8、0.5、0.5,模式参与度为0.5,大于给定的参与度阈值0.4,该模式是co-location 模式,该模式是包含了医院特征的co-location 模式。
例1 中,若医院、药店、花店的表实例数分别为8、8、10,医院的参与率为0.8,大于给定的参与度阈值,药店参与率为0.4,花店参与率为0.33,参与度小于给定的参与度阈值,该模式不是co-location 模式。该模式所含知识解释为:80%的医院实例参与到{医院,药店,花店}的并置模式中,模式表实例中药店相对于医院的并置率为1,花店相对于医院的并置率为1.25,模式的表实例中,80%的医院意味着一个医院有一个药店和1.25 个花店和其互相近邻,由医院的参与率及其3 个特征实例之间的并置度可知该模式其实是一个具指导意义的模式。在该数据集中,由于药店和花店的总实例数较多,其中一部分实例参与到其他的模式中,致使花店和药店在模式{医院,药店,花店}中的参与率小,使得该模式不是频繁模式。而由模式所含知识可知,基于医院应用领域的该模式其实是具频繁性及指导性的,在本研究中将其称为基于医院特征的加权co-location模式,以下提出的WCPBSF 挖掘方法可以合理挖掘上述的WCPBSF。
指定特征集中特征M,模式c={f1,f2,…,fn}包含特征M,若模式c 基于M 的加权参与度大于给定阈值,则称c 为基于特征M 的加权co-location 模式。给定空间特征集c={f1,f2,…,fn},以及c 的特征实例集O={O1,O2,…,On},其中Oi为特征fi的实例集,对于空间特征集c 的一个特征fi,fi的实例数定义为fi在该空间中出现的总实例数,即fi的实例集Oi中的元素个数,记为Nfi(Nfi=|Oi|)。设空间实例集I={O1,O2,…,On},如果I 中实例互相之间都满足近邻关系,称I 是一个团实例〔11〕,如果I 包含了模式c中所有的特征,且I 中没有任何一个子集包含c 中所有特征,则称I 为模式c 的一个行实例〔11〕,将c所有行实例的集合称为c 的表实例〔11〕,记为:table_instance(c)={I1,I2,…,Im},其中m 为c 中的行实例总数。特征fi的表实例数定义为fi在模式c 的表实例中不重复出现的实例个数〔10〕。记为Bfi=|πfitable_instance(c)|。
定义1 特征的权。给定特征M,以及含M 的模式c,c 中特征fi的权定义如下:
定义2 特征的加权参与率。给定模式c,特征fi的加权参与率WPR(fi,c)定义为fi的权与fi的参与率的乘积,计算式表示为:
定义3 模式的加权参与度。模式c 的加权参与度定义为c 中所有特征加权参与率的最小值,计算式表示为:
定义4 WCPBSF。给定特征集中特征M,若模式c 基于特征M 的加权参与度大于阈值,则c 是一个基于指定特征M 的加权co-location 模式,简称WCPBSF 模式。
一个高阶co-location 模式的子模式均为colocation 模式〔4〕,本研究中一个高阶基于特征M 的WCPBSF 的低阶基于特征M 子模式均为基于M 的WCPBSF,即WCPBSF 的加权参与度满足随着模式阶数的增大而单调递减,证明如下:设cm为m 阶频繁模式,cm+1为cm的m+1 阶超模式,①若fi=M,W(fi,cm)=1,W(fi,cm+1)=1,有PR(fi,cm)≥PR(fi,cm+1),故WPR(cm)≥WPR(cm+1)成立;②若Bfi≥NM且fi!=M,有WPR(fi,cm)=1,当B(fi,cm+1)≥NM,WPR(fi,cm+1)=1,当B(fi,cm+1)<NM,则,故WPR(cm)≥WPR(cm+1)成立;③若Bfi<NM且fi!=M,,由于B(fi+1,cm+1)<NM,则WPR,故WPR(cm)≥WPR(cm+1)成立。
定义5 相对于M 的特征并置率。设M 为指定特征,特征fi相对于M 的特征并置率定义为fi的表实例数与M 的表实例数的比率。计算式表示为:
特征fi的并置率反映的是在一个指定特征M的实例周围,平均出现R(fi)个特征fi的实例与其相邻,特征M 的并置率为1。例1 模式c 中花店的并置率为1.5,说明在一个医院实例周围平均出现1.5个花店与其相邻。
定义6 模式并置值。c 为n 阶基于特征M 的加权co-location 模式,c 的并置值定义为M 的加权参与率与其所有特征并置率平均值的乘积,计算式表示为:
基于M 的加权co-location 模式并置值反映了地理空间中基于特征M 出现模式特征实例并置的可能性,模式并置值越大,在地理空间中出现该种模式实例并置的可能性越高,模式在特定领域的指导性越强。
例2 给定特征A、B、C 的实例数为5、10、10,查询所得模式{A,B}、{A,B,C}表实例见表1。

表1 co-location 模式表实例示例
模式{A,B}基于A 的并置值为0.6,该模式表实例中3 个特征A 实例邻接了3 个特征B 的实例。模式{A,B,C}基于A 的并置值为0.67,该模式表实例中3 个特征A 实例邻接了3 个特征B 实例,且邻接了4 个特征C 的实例,基于特征A 的模式{A,B,C}指导性高于基于A 的模式{A,B}。
2 WCPBSF 挖掘算法
WCPBSF 挖掘算法基于星型邻居模型,采用无连接的co-location 模式挖掘方法,用实例近邻关系查询方法代替实例连接操作。算法检测含指定特征的候选模式是否为WCPBSF,相对于特征集中所有频繁模式挖掘的算法,本算法仅检测模式中含指定特征的候选模式,提升了算法时间复杂度,且挖掘结果具领域驱动性,减少了在特定应用领域下对挖掘结果的再处理。在数据预处理阶段随机生成空间实例集,计算实例间距离,查询得实例集的星型邻居集。算法基于实例星型邻居集查询候选模式对应的星型表实例集,计算模式的星型参与度,进行第一次过滤。从模式的星型表实例集中去除候选模式中实例间不互相近邻的星型行实例,生成候选模式的表实例集,根据式(3)和式(4)计算候选模式基于指定特征的加权参与度,进行第二次过滤,挖掘得WCPBSF。根据式(6)计算WCPBSF 并置值,提供给用户用于评价模式的指导性。
算法描述如下:
输入:特征集F、特征数n、指定特征M、加权参与度阈值e、距离阈值w、实例集的星型邻居集N
输出:基于特征M 的WCPBSF、模式加权参与度、模式并置值算法步骤:
第1 步:产生一个含M 的特征子集→c。
第2 步:若c 是候选模式(新的子集),则转第3步,否则算法结束。
第3 步:查询c 的星型表实例集。
第4 步:计算c 的星型参与度,若大于等于e 则转第5 步,否则转第8 步。
第5 步:查询c 的表实例集。
第6 步:计算c 中每一特征的权以及特征的加权参与率,得c 的加权参与度。
第7 步:若c 的加权参与度超过阈值e,则c 是基于M 的WCPBSF,计算c 的模式并置值并输出。
第8 步:产生一个含M 的特征子集→c,转第2步。
设特征集中的特征数为n,其实例集中实例的星型邻居数最多为m,c 的星型表实例集行数最多为a,c 的表实例集行数最多为u,算法检测2n-1个候选模式,候选模式的表实例集查询复杂度为mn,模式表实例集查询时间复杂度为,加权参与率计算时间复杂度为u×n,不计特征加权参与率计算时间,则算法时间复杂度为O(2n-1mn)。
3 WCPBSF 挖掘算法与co-location 模式挖掘算法挖掘结果
例3 算法挖掘结果。给定特征集{A,B,C}、5个不同的特征实例集(不同的实例数及不同的实例近邻关系),给定co-location 挖掘算法参与度阈值0.4,WCPBSF 挖掘算法加权参与度阈值0.6,用colocation 模式挖掘算法挖掘co-location 模式{A,B,C},用WCPBSF 挖掘算法挖掘基于特征A 的WCPBSF 模式{A,B,C},挖掘结果见表2。
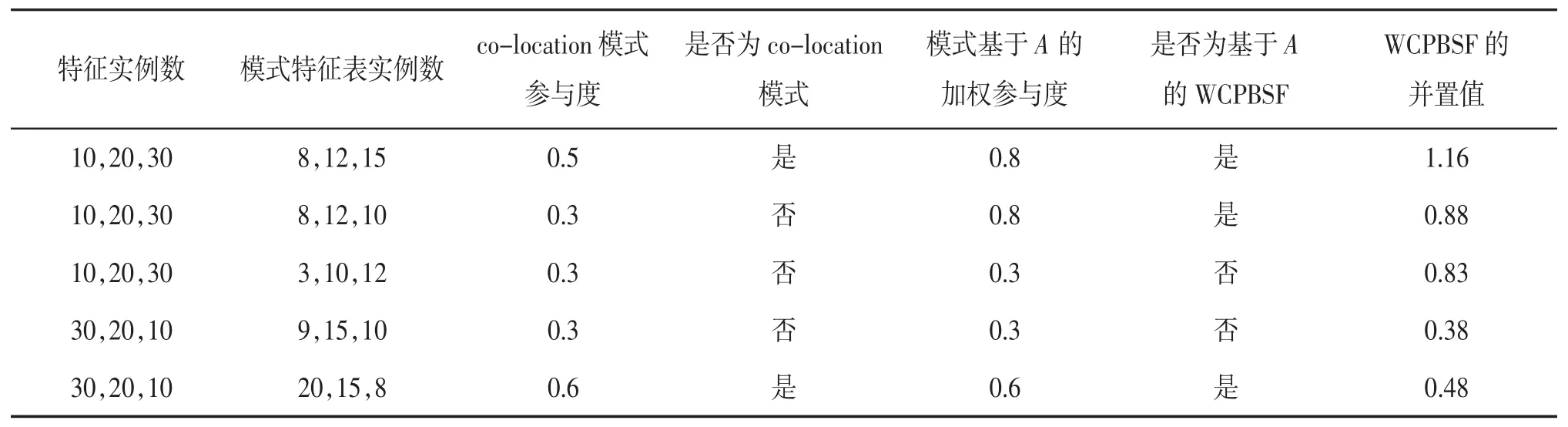
表2 co-location 模式挖掘算法与WCPBSF 挖掘算法挖掘结果
挖掘结果分析如下:
(1)实例集1 中模式{A,B,C}是co-location 模式,由于模式中含特征A,称其为包含特征A 的colocation 模式;由WCPBSF 挖掘算法也将该模式判定为基于特征A 的WCPBSF。实例集2 中的{A,B,C} 不是co-location 模式,但它是基于A 的WCPBSF。实例集4 中的{A,B,C}不是co-location模式,也不是基于特征A 的WCPBSF,但该模式其实是基于特征B 的WCPBSF,也是基于特征C 的WCPBSF。实例集5 中的模式{A,B,C}是co-location模式,也是基于特征A 的WCPBSF。
(2)上述3 个基于特征A 的WCPBSF 并置值则反映了模式的可指导性,基于特征A 的WCPBSF 模式1 的并置值最大,出现模式实例并置的概率最大。
(3)实例集3 中模式{A,B,C}不是co-location模式,虽然特征B 和特征C 基于特征A 的并置率较高,平均一个特征A 实例并置3 个特征B 实例、4 个特征C 实例,但由于指定特征A 的实例参与率太小,仅为0.3,模式不具备频繁性,故该模式不是基于特征A 的WCPBSF。
4 算法验证
算法验证数据集为随机生成的合成数据,实例位置在4 000×4 000 坐标之内随机生成,特征实例数在0 到之内随机生成。实验验证了3个算法:①co-location 模式挖掘算法(算法①)。算法挖掘特征实例集中所有的频繁模式。②含指定特征的co-location 模式挖掘算法(算法②)。给定特征集中某一特征,算法仅挖掘实例集中含该特征的频繁模式。③WCPBSF 挖掘算法(算法③)。给定特征集中某一特征,算法挖掘实例集中基于该特征的加权频繁模式。算法中模式表实例查询采用基于星型邻居模型的无连接方法。
(1)给定距离阈值100,参与度阈值0.2,加权参与度阈值0.6,特征数10,验证总实例数对算法效率的影响,实验结果见表3。

表3 总实例数对算法运行时间的影响
由于算法①挖掘特征集中的所有频繁模式,算法②和算法③仅在包含指定特征的特征子集中挖掘,算法②和算法③的时间复杂度低于算法①。实验结果表明,算法②和算法③的运行时间较算法①少,3 种算法在给定特征数不变的情况下,随着特征实例数递增,算法运行时间递增。但从应用驱动的角度看,算法②和算法③挖掘结果具应用驱动性。
(2)给定距离阈值100,参与度阈值0.2,加权参与度阈值0.6,实例总数10 000,验证特征总数对算法效率的影响,实验结果见表4。
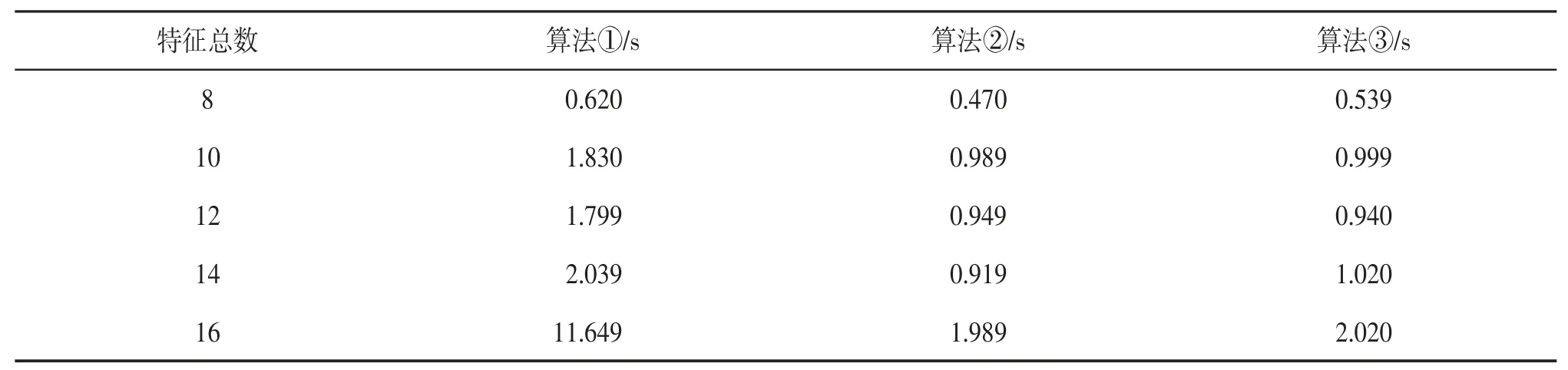
表4 特征总数对算法运行时间的影响
给定总实例数不变,随着特征总数增加,特征实例数递减,但3 种算法的运行时间总体呈递增趋势。在10 个特征与12 个特征之间,特征数增加,总实例数不变,特征实例数减少,算法运行时间有略微递减。
(3)给定距离阈值100,特征数10,总实例数10 000,验证参与度(加权参与度)阈值对挖掘结果的影响,实验结果见表5。

表5 参与度(加权参与度)阈值对算法挖掘所得频繁模式数量的影响
若给定距离阈值不变,随着参与度(加权参与度)阈值增大,挖掘所得频繁模式数量应该减少。实验结果表明,3 种算法挖掘所得频繁模式数量均随参与度(加权参与度)阈值的增大而相应递减。实验中随机生成的指定特征的实例数较少,挖掘到含该指定特征的co-location 模式数量较少,挖掘结果和算法①挖掘所得的模式中包含指定特征的模式结果一致。但算法③在不同的参与度阈值下均有效挖掘到基于该指定特征的加权频繁模式,算法③有效性明显。
(4)给定参与度阈值0.2,加权参与度阈值0.6,特征数10,总实例数10 000,验证距离阈值对挖掘结果的影响,实验结果见表6。

表6 距离阈值对算法挖掘所得频繁模式数量的影响
给定参与度(加权参与度)阈值不变,随着距离阈值增大,实例的星型邻居数量增加,挖掘到的频繁模式数量应该递增,实验结果表明,算法①和算法③随着距离阈值的增大,挖掘所得的频繁模式数量递增。由于本次实验中随机生成的指定特征的实例数较少,算法②未挖掘到含该指定特征的co-location模式,其挖掘结果和算法①挖掘结果是吻合的,而算法③有效挖掘到WCPBSF,算法③有效性明显。
(5)给定距离阈值100,加权参与度阈值0.4,特征总数10 ,总实例数10 000,指定特征1,验证基于指定特征1 的WCPBSF 参与度的反单调性及模式并置值,实验结果见表7。
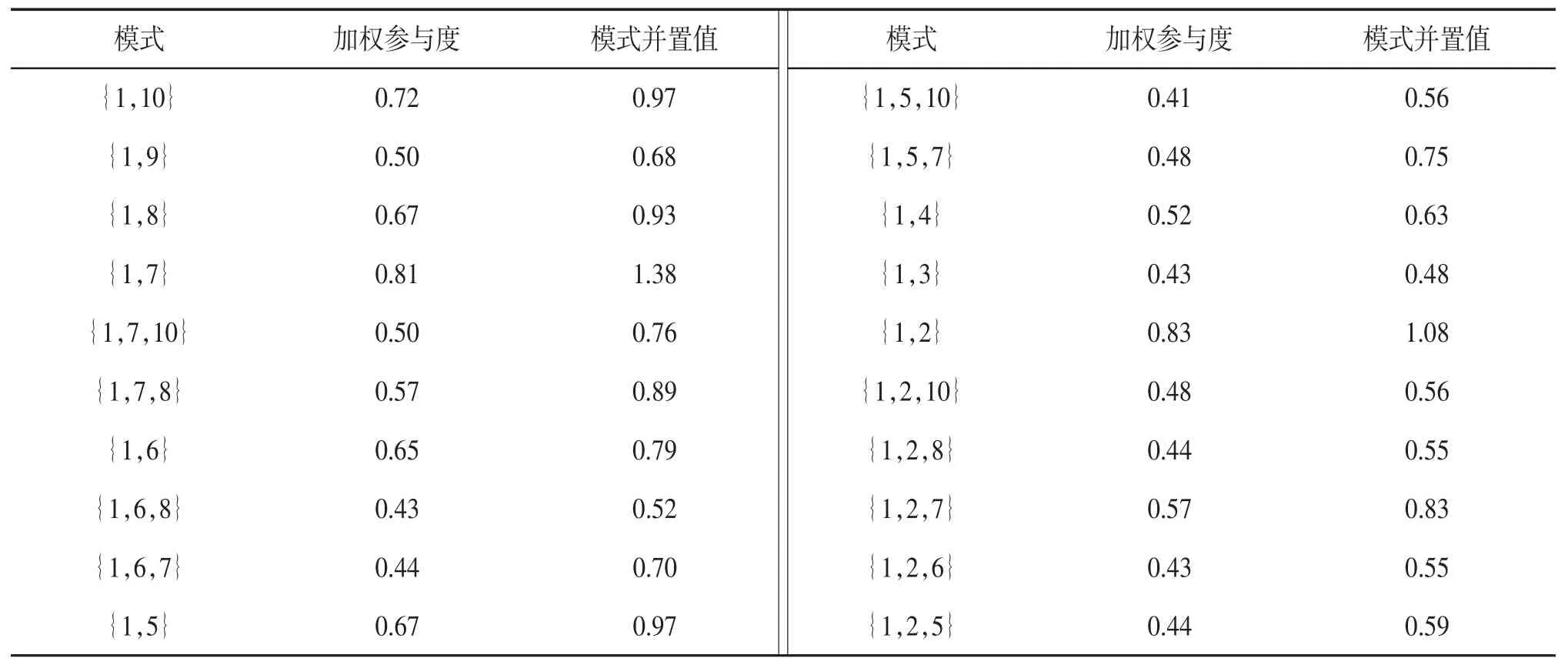
表7 WCPBSF 挖掘算法挖掘所得频繁模式的加权参与度及其模式并置值
算法③挖掘到20 条基于指定特征1 的WCPBSF,模式在基于特征1 的应用领域具指导性。挖掘所得频繁模式的加权参与度值随着模式阶数的增大而单调递减。模式{1,7}基于特征1 的并置值最大,指导性最强;模式{1,3}基于特征1 的并置值最小,指导性最弱。模式{1,5,7}及{1,2,10}的加权参与度均为0.48,模式并置值较大的{1,5,7}基于特征1 的指导性更强。
在挖掘co-location 模式时,若实例集中部分特征实例数量较多,在模式中的参与实例数量不够多而使得特征的参与率小,模式界定为非频繁模式,但模式基于指定特征具并置频繁性及指导性。本研究提出一种WCPBSF 挖掘方法,算法合理挖掘WCPBSF,挖掘所得模式适用于特定应用领域,模式并置值评估基于指定特征的模式实例出现并置的可能性,可用于评价模式的指导性。算法挖掘所得模式具应用驱动性,算法时间复杂度理想,实验结果验证了算法的时间效率及挖掘结果的有效性。
