中医古籍文献研究方法述要
2024-01-10赵辉张华敏张磊刘思鸿佟琳
赵辉 ,张华敏 ,张磊 ,刘思鸿 ,佟琳
1.中国中医科学院中医基础理论研究所,北京 100700;2.中国中医科学院中药研究所,北京 100700;3.中国中医科学院中医药信息研究所,北京 100700
中医古籍是指1911年以前(含1911年)书写或刻印于纸质载体上的中医学书籍[1]。它蕴藏着宝贵的中医理论知识和丰富的实践经验,是中医药知识宝库。对中医古籍文献的系统整理,有利于充分挖掘古籍中蕴含的中医药知识,促进中医药传承并加强文化遗产保护。而中医古籍版本众多,语义深奥,这给中医古籍文献的深入研究带来了困难,寻找恰当有效的中医古籍文献研究方法十分必要。本文对目前中医古籍文献研究方法进行简要梳理,以期为充分挖掘中医古籍价值提供参考。
1 中医古籍文献学研究方法
中医古籍成书久远,在传抄过程中,篡改脱衍,以讹传讹,加之文辞高古渊微,难以被阅读和挖掘利用。通过中医文献学的方法对古籍进行系统整理,去伪存真,让古籍资料更加清晰明了,尽可能地还原或接近古籍原貌。传统的中医文献学方法包括训诂、校勘、目录学、辨伪、辑佚等。
1.1 训诂
中医训诂学是利用形训、声训、义训对中医古籍内容进行训释,以解释深奥医理,所以中医训诂学是中医学与传统训诂学的结合,训诂体制和形式以正文训诂、随文释义、通释义词为主[2]。运用中医训诂学可对医籍词义、本草名物及腧穴名称进行释义。医籍词义训诂多引用《尔雅》《说文解字》等著作进行训释和通假字辨析,引用过程中运用“词义互释”法和“义界释词”法对文词进行同义词互训和字义、词义的界限[3-4]。本草名物词训诂主要是考证药物名称与具体药物之间的名实相符情况,并能研究药物命名的理据[5]。对腧穴名称训诂可帮助明确腧穴定位,揭示腧穴命名的内涵,从而更好地理解腧穴的临床作用原理,并能纠正错误命名[6]。
1.2 校勘
运用校勘学方法,发现并纠正流传中字、词、句、篇、章错误,使中医古籍尽可能地恢复原貌[7]。校勘的首要工作是确定校勘该书所依据的底本,底本的选择一般以初刻、精刻、早期刻本或有一定影响力的刻本,校勘时综合运用对校、本校、他校、理校对底本中出现的脱文、衍文、颠倒、疑似、异文、混乱作出校注[8]。使用他校时要确认引文出处,并需考察他校书的引文方式、引文采用的版本、引文的基本结构[9]。随着古籍数字化的发展,应用现代信息技术对古籍进行点校,节省点校的时间、资源,提高点校效率和质量,计算机可对一个或多个校本进行自动校勘,发现和标记不同版本间文字的差异,并显示需要校勘的信息[10]。
1.3 目录学
自西汉《别录》和《七略》起,中医古籍目录逐渐增多[11],借助目录可以从浩如烟海的中医古籍中顺利找到所需资料,系统了解所需文献。在古籍校勘工作中,可借助《中国中医古籍总目》获取图书信息和藏书地点,然后使用具有提要、评价的工具书,如《中国医籍提要》[12]。运用目录学方法研究中医文献有梳理稽考存佚、甄别伪赝、析别版本、部次类属、厘订卷次、辨章学术、考镜源流、补述史例、评骘得失9种方法[13]。而今借助网络信息,建立中医药信息资源目录学,将中医药文献资源目录数字化,并将数字目录应用到中医药资源管理系统,充分发挥目录学功用,促进中医药数字目录学发展[14]。
1.4 辨伪
伪书即古籍作者、内容、年代不真实,辨别伪书是古籍文献的研究基础,根据前人经验,辨别伪书主要可将查考历代书目、分析医书内容、研究语言特点、考辨应用文献及考订作者生平等方面综合应用[15]。该方法可以帮助找到书中的“伪迹”,有学者认为,辨伪工作不仅要找到“伪迹”,还要解释造成“伪迹”的原因,将古籍辨伪工作从传统考证作者、内容和年代真实性,扩大到古籍体裁、编撰方式及流传过程的考证[16]。中医古籍伪书存在一些共同特点,书托鬼神、古圣先贤、名家而成,或在校勘、编撰、传抄过程中在真书中掺杂伪文[17]。古籍辨伪是为恢复其本来的历史面貌,客观、真实地对伪书作出评价,以利于正确运用文献资料,而对于伪书的学术价值,可根据其内容作具体分析。
1.5 辑佚
一些重要的中医文献资料在流传过程中由于自然与人为的原因亡佚,在现存古籍文献中,搜集、考证、整理佚文,使佚书得以恢复或部分恢复原貌[18]。首先选择辑佚文最多、版本最好、编排合理的辑本作为主据本,其他辑本作为参考本;对主据本和参考本的佚文进行缀合与剔重,根据佚书篇名推测编排顺序;将剔重后的佚文与原始出处进行校对,补充佚文;最后将辑录完成的佚文进行标点和提供校语[19]。现代辑佚工作可借助网络资源,提高工作效率,在古籍数据库中嵌入模糊检索模块,将字段和句段的编辑实现智能化[20]。部分中医古籍文献学研究方法见表1。
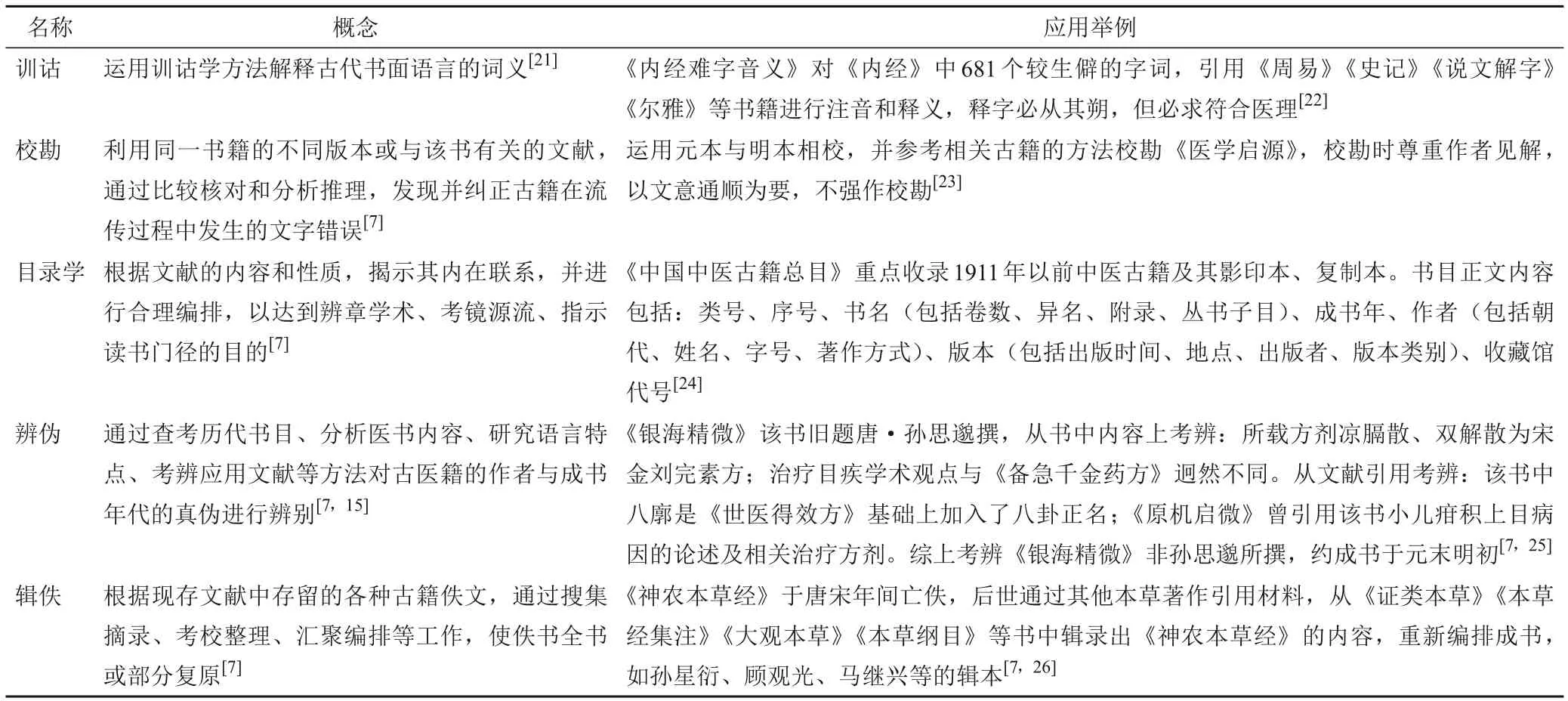
表1 中医古籍文献学研究方法举例
2 现代信息技术研究方法
随着科学技术的发展,运用现代技术对中医古籍进行数字化和网络化整理是中医药现代发展的趋势,同时也是中医古籍保护和利用的新手段,能更好地保护、利用和挖掘古籍知识。现代信息技术使传统古籍焕发新活力,推进中医药传承创新和中医药走向世界。
2.1 建立中医古籍数据库
目前,中医药大学基本都建立了古籍数据库,资源元数据来源于自身馆藏[27],数据库的建立使中医古籍实现了电子阅览,为其深入挖掘带来便利。关于数据库的建立方法,杨其霖等[28]认为,首先对元数据进行加工,运用《中国中医古籍总目录》对古籍进行分类。对古籍进行拍照时要求原书完整清晰,并对照片执行严格的录入规范。储存古籍图像时需与原书文本进行关联,建立索引关系。并从图像的名称、分类、主题、图中文字、释图文字等方面对图像进行数字化处理。此外,可以对古籍的内容进行专题数据库建立,如温病古籍知识库、中医古籍养生知识库等[29],这有利于建立更深层次的中医古籍知识数据库。目前已有学者提出基于本体、知识元、知识聚类和知识组织的中医古籍知识库建立方法[30-32]。
大数据、人工智能时代背景下,将积累的中医古籍数字资源构建多场景应用的大型特色专题知识库,辅助临床决策、药物研发与医家经验传承,应用新技术和新理念建立中医古籍知识库,实现古籍原创知识的提炼、展示与活化利用,让中医古籍在“增进人民健康福祉”中发挥更大作用。
2.2 数据挖掘
数据挖掘是从已建立数据库中提取、转换、分析有价值的知识信息[33],其在中医研究的应用包括证候研究、方剂配伍研究、古今医案研究、用药规律研究、针灸取穴规律研究、辨证规律分析等方面。
数据挖掘一般由5个步骤组成:数据集成、数据归约、挖掘、评价和表示[34]。数据集成也是数据的准备,研究者根据研究主题从各类数据库中提取统一的数据模型,建立一致的数据视图,是形成数据挖掘的基础。现在多使用已有的中医古籍电子档或古籍数据库摘录内容,如《中华医典》。数据集成后对数据做进一步加工,排除一些噪声与冗余数据,对有效数据做适当调整。这2个步骤是为数据挖掘做数据准备,保证挖掘有效性。数据准备完成后可以选用相应的方法、算法与相应的挖掘参数进行数据挖掘。对挖掘后的结果作出标准评价,选取符合要求的作为结果。最后将数据挖掘的结果通过文字、图片、表格等形式表示。由于中医古籍的特殊性,目前常用的中医古籍数据挖掘方法有频数分析、关联规则分析、聚类分析、因子分析、回归分析、神经网络、贝叶斯网络、粗糙集[35]。
中医古籍中知识通常为隐性知识,完成中医知识的收集、抽取、融合,将其文本化、数据化、知识化,对海量数据进行潜在价值挖掘。中医古籍数据挖掘常用方法见表2。

表2 中医古籍数据挖掘常用方法
2.3 知识图谱构建
知识图谱是一种概念网络,是具有属性的实体通过关系连接而成的网状知识库,节点代表实体(或概念),实体间的语义关系则构成网络中的边,最终以图形化的方式展示经过分类整理的结构化知识[55]。近年来以知识单元为前提,构建知识图谱,可以快速绘制、挖掘和分析相关知识之间的关系,从而对海量知识进行有效管理[56]。构建中医古籍知识图谱可将古籍中的病、症、治关系及医家学术思想用直观的形式进行表达,研究人员和临床医生可快速获得知识推荐,从而促进中医古籍的保护和利用。关于知识图谱的构建方法,首先从原始数据出发,步骤包括信息抽取、知识融合、知识加工[57]。卢克治[58]通过人工方式对中医古籍文献进行数据处理和标注,形成标准语料库,经过实体识别和实体关系抽取后,将抽取和标注数据进行医学术语规范,并将同义词不同表达的术语进行规范化表达,再将人工标注及智能抽取审核的关系数据存储到知识图谱平台中,采用 Neo4j 图形数据库构建知识图谱库,在此基础上对清肺排毒汤和宣肺败毒方中的经方进行搜索查询,得出经方对应的治法信息和药物使用情况。叶斌等[59]在研究胸痹病机的知识图谱时,先通过文献检索进行相关文献提取,并将文本分解为最小知识单元,形成知识元文本;将知识元分类,根据知识元部件内容编写DTD文档;通过SAS9.4软件进行编程,对部件文本进行语义提取和消除歧义;再对知识元文本进行频数分析和语义关联规则分析;最后通过SAS软件编写代码,对语义关系和语义分类关系进行图形化展示,形成胸痹辨证论治知识图谱,从而直观地理解胸痹证治的相关知识。
通过中医知识表示、本体构建与知识管理,基于概念类型、语义关系等对知识进行关联,可视化呈现“理、法、方、药”知识内容关联,提升中医隐性知识的发现效率,深入挖掘中医古籍的潜在价值。
2.4 人工智能
运用人工智能方法处理数字化的古籍,实现古籍的智能整理、挖掘,提高工作效率。运用该方法时,首先要解决的问题是机器对古籍文本的文字识别、自动断句与词法分析。由于古籍的排版不固定,不同作品字体存在差异,以及内容存在缺失等原因,传统的光学字符识别技术不能完全满足古籍文字识别,深度学习相对于传统方法能够更好地对古籍文字进行识别。构建对古籍字体数据进行特征学习的卷积神经网络可分为3个步骤:①构建训练集;②模型的构建与训练;③识别和结果分析。其本质是以深度学习方法构建汉字图片与字符的分类器,将概率最高的分类作为输出结果[60]。运用深度学习方法可以进一步提高古籍断句、标点、分词、词性标注和语义理解的效率[61]。程宁[62]通过构建Bert-BiLSTM-CRF模型,采用联合学习方法实现了古籍断句、分词和词性标注的一体化标注。洪涛等[63]用10亿字古籍语料对Transformer模型进行自动标点、断句训练,通过19本未训练语料的测试,发现该模型对古典文言文语料预测结果较好。同时利用机器学习,还可以对古籍进行深入挖掘。石清阳[64]以《伤寒论》作为训练数据,将训练好的RoBERTa-large模型对《伤寒论》中的经典条文进行证治规律分析,结果发现,该模型可以根据条文的不同含义进行分层分析,并展示条文主要症状的关联、症状与病证之间的关联等,从而对《伤寒论》进行深入剖析。
数据挖掘、人工智能等技术助推中医古籍数字化的深度与广度,既需要有高效管理大数据的能力,又需要有强大的知识推理能力,才能进一步提升中医古籍创造性转化利用的深度。
3 循证医学方法
循证医学强调在临床实践过程中,临床决策必须建立在最佳临床证据、临床专业技能和经验、患者价值观及情形相结合的基础上[65]。将循证医学方法运用到中医古籍研究中,具有一定优势,中医古籍中的有效处方,千百年来经过历代医家的反复临床实践验证,其证据级别可能高于部分专家的评定。然而循证医学方法在中医古籍研究中的应用还处于探索阶段,目前尚缺乏成熟、标准的研究方法。李焕芹等[66]认为,古籍循证选择的数据库应该是古籍数量充足和古籍版本是经权威认证的“善本”,以病证-证候类型检索,对检索结果进行去重、删除不符内容等,得出该疾病的证型分类目录,通过专家讨论得出疾病的临床常见代表证型,并对证型的方剂检索,根据每首方剂条文及其本身分级,综合得出每首方剂的证据评分。张磊等[67]认为,在制定中医古籍证据评价分级量表时,可以从诊断和防治两方面对证据进行区分,运用德尔菲法确定古籍证据评价条目,通过专家共识度对条目进行筛选并确定权重,对条目进行赋分,最后通过会议形成专家共识。刘迈兰等[68]认为循证方法研究中医古籍应服务于临床,以临床问题-治疗方法为模式进行挖掘整理,将临床疾病以病、证候、症状为纲目,建立具有中医特色的数据库,按照证据推荐级别排列治疗方案,通过古籍实践经验的引用率或专家共识对实践经验进行证据分级,最后将一致认可的证据制定成疾病治疗指南或编入教材。应用现代循证理念,注重中医知识评价和更新反馈,形成面向临床需求的中医典籍临床决策支持循证体系,提升中医古籍知识利用与转化效率,搭建中医典籍知识与当代重大疾病相关联的桥梁。
4 小结
中医古籍承载着中医药千百年来的经验总结,是中医学理论与实践的根源,也是中医药追求创新、启发研究的灵魂所在。从“青蒿一握,以水二升渍,绞取汁,尽服之”(《肘后备急方》)到青蒿素的诞生,无不显示着研究中医古籍的重要性。在研究方法上可以遵循传统的中医文献学研究方法,通过训诂、校勘、类编等方式对古籍整理研究,也可以运用现代信息技术对中医古籍进行深入挖掘;以及将中医古籍作为中医药临床指南制定的证据来源,建立适用于中医古籍内容的证据评价标准。以上研究方法是从不同角度对中医古籍内容进行研究,需要综合运用。应注重不同研究方法之间的有机契合,从多维度对中医古籍进行研究,从而不断扩大中医古籍的研究利用范围。
