基于数据挖掘的公选课资源共享个性化推荐模型研究
——以广东省民办院校为例
2024-01-10刘丽娜
刘丽娜
(广州工商学院工学院,广东 广州 510850)
0 引言
高校学生对公选课具有一定的自由选择权,包括选择课程、任课教师和上课时间。由于传统的选课制度不利于学生个性拓展、课程资源有限和选课引导不充分等方面因素,影响了学生的学习效果和学校的教学质量。
基于数据挖掘技术对广东省民办院校公选课资源共享个性化推荐模型进行研究,利用改进后的KIApriori 算法[1]从以往的选课数据中发现隐藏的、有用的数据规律来指导推荐公选课,从而改进和完善当前高校公选课的选课机制。
1 相关研究
目前,许多学者正在积极探索公选课选课机制的改革;研究较多也较为普遍的当属课程个性化推荐模型,此类模型有基于大数据或数据挖掘的个性化推荐[2-4],也有基于协同过滤的资源定制[5],以及基于图谱和图嵌入的学习资源推荐等等[6]。
本文利用数据挖掘算法构建推荐模型,以SPSS Modeler 为初步分析工具,以广州工商学院和广州科技职业技术大学两所民办院校应历届学生信息数据为研究对象,构建预测模型为在校学生推荐适合的公选课程,既能有效提高教学质量,又能实现跨校资源共享,提高资源利用率。
2 构建公选课资源共享个性化推荐模型
2.1 数据挖掘技术在预测推荐中的作用
数据挖掘技术是通过对历史数据进行分析,从而发现其中的规律,利用此规律来指导预测未来有可能产生的数据信息[7]。数据挖掘主要包括数据清洗、数据建模、模型数据分析、行为数据分析与结果反馈四个阶段。
(1)数据清洗
数据挖掘的前期工作是收集数据,在确定挖掘目标后基于该目标准备数据,并对收集到的结构化与非结构化数据进行整理清洗去除数据中噪声不一致的数据,以便于后续的分析处理。
(2)构建挖掘模型
数据建模阶段可以选择不同的数据挖掘技术针对数据进行分析建模,从而发现潜在的规律和结构。
(3)模型数据分析
模型数据分析可以将模型应用于实际问题中,构建推荐算法,并对模型效果进行验证,从而自动地为用户进行推荐。基于数据挖掘算法的推荐系统可以实现个性化、精准地推荐,同时也可以不断优化算法以提高推荐的效果。
(4)行为数据分析与结果反馈
行为数据分析是将得到的推荐结果结合实际行为进行分析,从而为系统提供反馈机制。通过对用户的反馈进行分析和挖掘,可以发现用户的意见和需求,从而进一步改进并优化推荐系统。
2.2 利用KIApriori 算法构建推荐模型
Apriori 算法通过分析历史数据发现其中隐藏的规律,利用规律分析现有数据并找出关联结果,从而达到推荐的目的[8]。而KIApriori 算法是对Apriori 算法处理多维复杂数据及执行效率的优化,KIApriori 构建推荐模型的过程包括利用改进的算法SK-Means 进行前期复杂数据的多维度分类、精简,然后利用改进的算法KIApriori 根据支持度和置信度识别强规则,然后使用强规则实现推荐项目,实现模型如图1 所示。
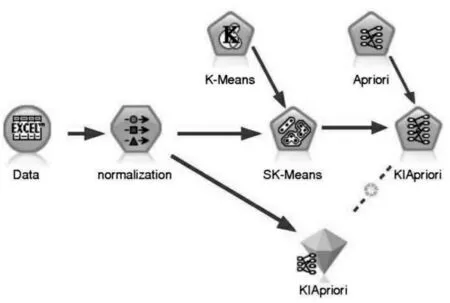
图1 KIApriori 算法推荐模型
首先是对收集到的数据Data 进行normalization清洗规范化,然后采用经过多维度改进K-Means 后的SK-Means 算法进行分类,最后再通过扫描数据库并使用KIApriori 识别频繁出现的项目来找出所有规则。该算法的工作原理是建立一组候选项集,然后根据最小支持度和置信度对该候选项集进行修剪。一旦确定了最频繁的项目集(即强规则),则可以利用规则向用户提出推荐建议。推荐过程识别出往届学生所选课程与其他数据的关联规律,再利用该规律为当前还未选课的学生推荐其感兴趣的课程。
因此,Apriori 关联规则可以识别最频繁的项目集,并使用它们向用户推荐项目,帮助构建推荐模型,从而提高推荐的准确性,更好地满足学生的学习需求,提高学生学习效果。
3 实施应用
本文以广东省两所民办院校近十年的学生数据为研究对象,采用线上公选课程为规则后项,具体实施分为六个阶段。
(1)数据清洗
确定广州工商学院和广州科技职业技术大学往届学生的特征数据,首先需要确定学生的行为习惯、学生专业与课程等多方面的特征数据,即通过采集学生的多层次的个人数据,在此基础上进行多维度衡量,然后对结构化和非结构化数据进行统一和去噪处理。例如,由于不同的专业所学习的专业课程不同,因此需将专业课进行聚类,根据成绩段进行归类,如分数在90 到100 之间的同学归为一类。同时,若同类属性当中有大量的不同值,如学生成绩,则应做概化处理。
概化:即将一些细节的数据抽象为上一层次的概念化的数据,如学生的“大学英语成绩”有0~100中的某一个数组成,不利于挖掘,在此可以将成绩根据[0,60)、[60,70)、[70,80)、[80,90)、[90,100]分为不及格、及格、中等、良好和优秀五个层次,那么“大学英语成绩”就可以概化为不及格、及格、中等、良好和优秀。
属性剔除:如果属性当中很多值都未概化处理,且与挖掘主题不相关,没有上层属性,则该类属性应剔除。如“姓名”或“教师编号”等属性。
(2)设计推荐算法
利用数据挖掘技术,根据学生的需求特征,建立合理的模型,利用关联分析等技术,确定个性化推荐算法,本文结合实际数据分析确定采用KIApriori 算法对第一阶段的数据进行挖掘。
(3)模型实施
在模型构建后,通过运用数据挖掘的技术对资源进行数据处理,本次挖掘设置最小支持度和置信度均为8%,然后根据生成的推荐结果选择合理规则前项并根据支持度与置信度设置推荐权重值为学生进行公选课程的推荐,部分挖掘结果如表1 所示。
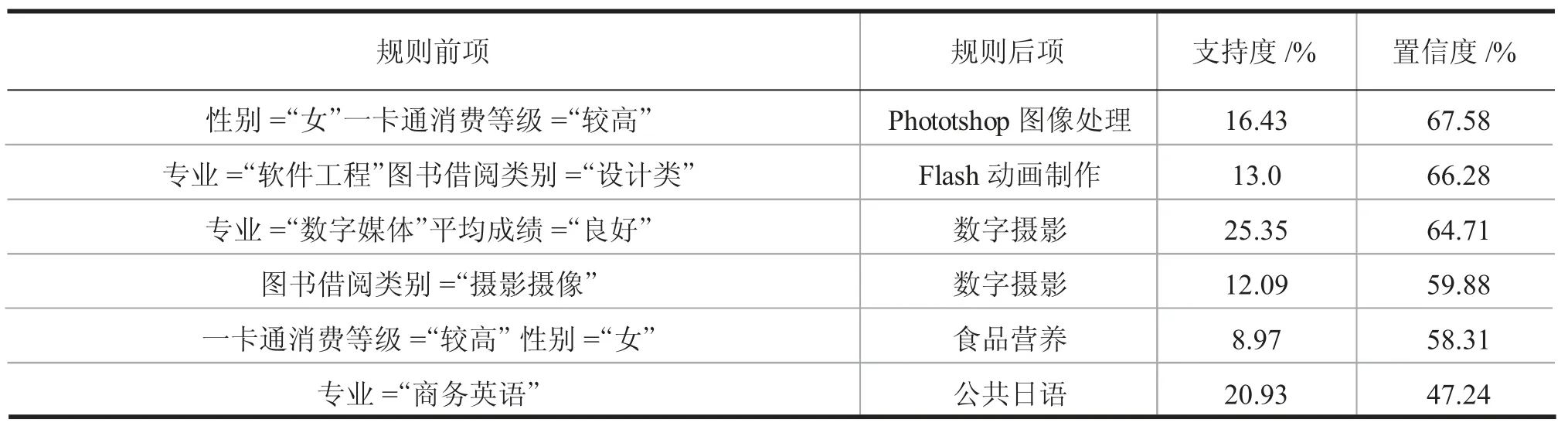
表1 部分挖掘结果
在表1 中,规则{专业=“数字媒体”、平均成绩=“良好”、选修=“数字摄影”}可以解释为大部分数字媒体专业专业课平均成绩良好的学生都会选修“数字摄影”课程。然后,推荐算法将向数媒专业平均成绩良好的学生推荐“数字摄影”课程,因为它是最频繁项目集中的一部分。
(4)模型测评
根据第三阶段的推荐结果,对规则的合理性进行分析,采集一定量的反馈数据,形成测试数据与目标数据可视化的对比结果,评估公选课资源共享个性化推荐模型的实施效果。
(5)确定稳定模型
根据模型衡量的反馈结果,不断迭代模型,并加以改进,以提高模型实施的准确性和稳定性。
(6)各层面实施应用
由学生、教师、试点学校和广东省民办院校合作四个层面构建公选课个性化推荐模型,如图2 所示。
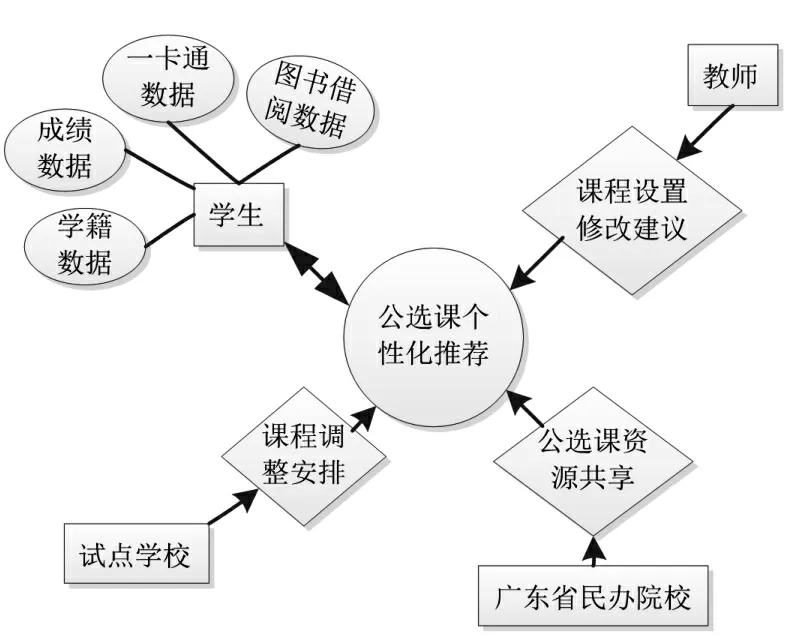
图2 公选课推荐模型
学生层面:分别根据学籍、成绩、一卡通和图书借阅等数据构建挖掘模型,为在校学生推荐适合的公共选修课程,为各种个性特征的学生提供充分的发展机会。
教师层面:通过数据挖掘分析,教师提出公共选修课科目的设置修改建议。
试点学校层面:协调课程、推荐选修,并根据推荐结果调整公选课程的安排,例如剔除选课人数较少的课程。
广东省民办院校层面:构建广东省民办院校跨校公选课资源共用共享及公选课学分互认机制,实现资源高效利用。
4 效果评估
本研究将确定的推荐模型应用于广州工商学院20 级网络工程专业2022-2023 学年第一学期的公选课推荐,以问卷的形式对此推荐的满意度、出勤率和适配度等进行调查,进一步分析模型的应用效果。
通过对广州工商学院20 级网络工程专业171名学生进行普查,发放问卷171 份,回收有效问卷167 份,问卷有效率为97.7%。问卷调查中出勤率为98.78%,而满意度、适配度调查结果如图3 所示。
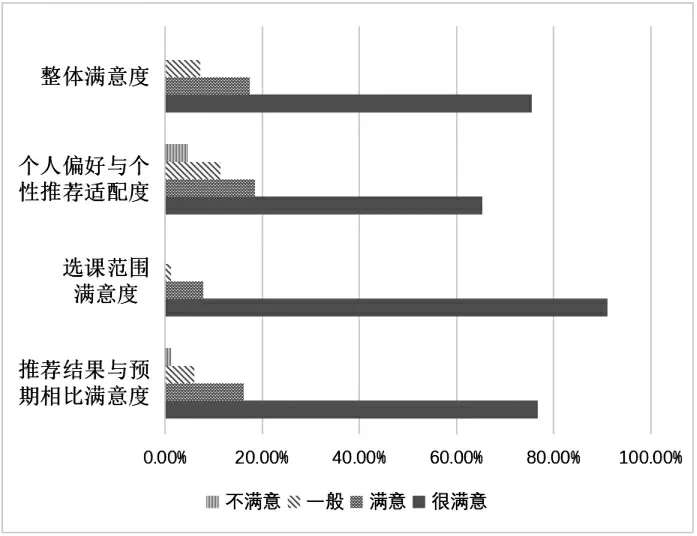
图3 公选课个性化推荐满意度调查
从图3 可以看出公选课的个性化推荐的选课范围较为满意,推荐结果与预期相比普遍达到满意或很满意;而由于个性化推荐与专业或成绩等其他因素相关,因此个人偏好与个性化推荐的适配度大部分亦达到满意或很满意,但相对于其他项目的满意度上稍微偏低。在公选课个性化推荐调查结果中可以看出超过80% 的学生对本次的推荐结果整体较为满意,且出勤率达到98.78%。由此可见,该推荐模型的实施应用,可以有效提升学生的参与度和学习效果,从而改善学校公选课的教学管理和学习质量。
5 结束语
本文以广东省两所民办院校近十年的学生数据为研究对象,构建公选课资源共享个性化推荐模型,在模型应用时实行资源共享学分互认。通过本次公选课推荐模型的实施可见,实行该模型有利于促进学生个性化学习,提升学习质量;有利于管理部门更合理地规划分配资源,完善选课机制;有利促进师资进修,强化师资队伍;有利于实现高校公选课资源共享,提高资源利用率。
虽然本次公选课模型的构建及实施取得了一定的成效,但由于数据量有限且公选课设置不一致等问题,对规则生成及支持度、置信度有一定的影响,若能获取更多的分析数据,且数据更加规范,则公选课资源的推荐及结果适配度将有更好的实施效果,规则的可靠性也将更高。
