基于回归算法修正的分布式光伏弃限电量统计方法
2024-01-10樊茂森胡文丽杨嘉良
樊茂森,高 龙,胡文丽,何 燕,杨嘉良
(国网河北省电力有限公司保定供电分公司,河北 保定 071051)
0 引言
近年来随着新能源电站装机容量的不断增加,我国能源结构发生重大改变,从曾经占重要地位的水电、火电模式逐渐向光伏、风力发电等新能源模式倾斜,截至2021年底,全国光伏发电装机容量为3.06亿k W,在可再生能源发电装机总容量中的占比为12.9%[1]。2021年,全国光伏新增装机容量为5 488万k W,在可再生能源新增装机容量中份额占比最大,达到31.1%,其中,光伏电站新增装机容量2 560万k W,分布式光伏新增装机容量2 928万k W。
分布式光伏相比于集中式光伏具有就近发电,就近并网、就近转换、就近使用的优势,不仅能够高效率地将光能转换为清洁电能,同时还能有效解决电力在升压及长途运输中的损耗问题。随着新能源占比的提高,电网调峰资源越来越紧张,有时仅仅靠集中式光伏电站与风电场不足以应对电网调峰需求。分布式光伏参与电网调峰逐渐成为一个不可绕开的课题。然而分布式光伏相比于集中式光伏分布范围更广,亟需一个科学的弃限电量统计方法来计算调峰后电网弃光电量与用户损失。
目前专业内多采用测光法和样板机法计算分布式光伏弃限电量[2]。测光法利用太阳辐射量、电池板总面积、光电转换效率、电池板衰减率等相乘得到光伏断网后的理论发电量,但受光伏面板清洁度、雾霾沙尘等天气因素影响较大,测算准确性过度依赖于气象条件。样板机法利用样板机折算总体分布式光伏理论发电量,这种方法受天气因素影响较小,但过度依赖样板机的选取,样板机选取的难度较大,选取时要尽量多而散,样板机平均发电效率要尽可能代表总体光伏的发电效率。
随着人工智能算法的发展,利用天气预报、地理位置、光伏发电特征等构建输入特征与电力输出关系来预测分布式光伏发电的方法越来越多。文献[3]提出了应用聚类算法对分布式光伏进行分析,在此基础上建立了基于BP-NN 的光伏电力预测模型。文献[4]介绍了基于Kriging空间差值法的光伏电力预测方法。文献[5]介绍了基于模糊神经网络的光伏发电量短期预测方法。上述方法主要应用在分布式光伏预测方面,而分布式光伏弃限电量统计存在数据量大、影响因素多、依赖近期历史数据等特征,可以借鉴人工智能算法的优势来提高估算精度。
1 分布式光伏弃限电量统计
分布式光伏电站通常是指利用分散式资源,装机规模较小、布置在用户附近的发电系统[6-8]。分布式光伏发电遵循因地制宜、清洁高效、分散布局、就近利用的原则,充分利用当地太阳能资源,替代和减少化石能源消费。GB 50797-2012《光伏发电站设计规范》中指出分布式光伏的上网发电量
式中:HA为太阳能年总辐照量;FZA为系统安装容量;K为综合效率系数。其中K受逆变器型号、光伏板使用年限、光伏板表面清洁程度等种因素影响。
分布式光伏弃限电量统计难度主要体现在两方面[9-12]。首先是每个光伏板的太阳能年总辐射量不同,分布式光伏一般多建在农村用户屋顶,存在分散面积广,每户光照量相差大的特点,而集中式光伏一般比较集中,不存在光照量差别大的情况。其次是综合系数差别大,分布式光伏由于逆变器型号、使用年限、清洁程度等因素的不同,发电效率差别较大,集中式光伏一般是集中采购,集中管理。分布式光伏很难像集中式光伏那样用统一的计算公式准确地估计弃限电量。
2 样板机估算法
集中式光伏电站采用以光伏样板机进行容量折算的方法[13-16]。参考集中式光伏电站弃限电量计算方法,可将分布式光伏分为不同区域,按区域(县)去选择样板机,限电后利用各个区域样板机估算总体限电量,再统计离网分布式光伏容量,折算得到弃限电量。这样就可以最小化太阳能辐射量不同带来的误差影响,计算方法如下
式中:P j,m为分布式光伏限电后区域j第m户估算发电功率;k为样板光伏户数;m为被控分光伏户数;N j,m为区域j第m户被控分的分布式光伏容量;M k为第k户样板分布式光伏容量;P j,k为j区域第k户样板光伏分布式光伏用户的实际功率;P j为分布式光伏区域j估算发电功率;P为整个地区分布式光伏限电后估算发电功率。
这种方法的优点是实用性高,计算简便,容易操作。但由于分布式光伏分布范围广,发电效率相差较大,公式存在一定量的误差。后续需要利用人工智能、机器学习方法,结合历史数据对实际功率与估算功率进行逼近。
3 考虑回归算法修正的弃限电量统计方法
样板机法主要用样本来估计总体发电量,然后用整体来估计分布式离网后的弃限电量[17 18]。这种方法的误差主要为样板机发电效率会随时间变化,综合系数K差别较大,样板难以精确地代表整体,可以考虑通过加入光伏总体发电效率的历史曲线,利用回归算法进行修正。以一个区域举例,先计算每个区域的弃限电量,最后再将所有区域相加。考虑回归算法修正的弃限电量统计方法的流程如图1所示。
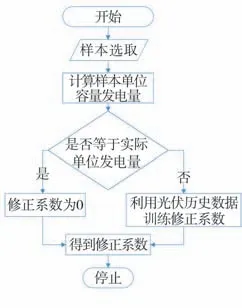
图1 考虑回归算法修正的弃限电量统计方法的流程
3.1 样本的选取
可以将分布式光伏进行区域划分,划分尽量多的区域来减少地理位置不同带来的光照差别影响,并在各个区域尽量选取多而散的样本来提高估算精准度。
分布式光伏用户数量较多,受安装角度、型号、地理位置等多种因素影响,可能会导致分布式光伏出力情况较为复杂,可以参考历史发电效率。例如选取过去30天内平均发电效率与该地区总体发电效率接近的光伏来当样板机,尽可能的提高样本估计精度。
3.2 计算样本单位容量发电量
根据选取的样板光伏折算单位容量发电量
3.3 样本单位容量发电量与实际单位发电量比较
分布式光伏发电功率为
式中:M为该地区分布式光伏总体装机容量;γ为该地区分布式光伏实际发电效率。
已知总体分布式光伏容量情况下,如果正确预估样本发电效率γ-就能正确估计出发电功率,进而积分得到弃限电量。实际发电效率与样本发电效率之间的关系为
式中:∂为修正系数。
发电效率会随着光伏板清洁程度和使用年限变化,∂也会随着时间变化。因此,采用过去一段时间光伏数据进行修正,引入机器学习的回归算法使公式逼近实际值。
3.4 回归算法修正
回归算法是一种监督算法,从机器学习的角度出发,构建一个算法模型(函数)做属性(X)与标签(Y)之间的映射关系[19-20]。在算法的学习过程中,训练公式中的参数寻找到一个函数使得参数之间的关系拟合性最好。回归算法中函数最终结果是一个连续的数据值,输入值是也一个数值向量。回归算法的标准公式为
式中:hθ为因变量;θi为修正系数;x i为自变量;n为样本个数;X为x i组成的矩阵。
利用人工智能的回归算法加入过去n天的历史数据,对公式模型进行训练得到Z的参数。
式中:K jn为j区域第n天的发电效率数据;Z n为需要训练的参数。Z为通过回归算法得出的修正系数,用来使计算值逼近实际值,减少误差,并没有实际物理意义。
损失函数为
J q为损失函数值,用来估量模型的预测值与真实值的不一致程度,数值越小,模型的鲁棒性就越好。利用梯度下降法使损失函数最小求解参数Z1到Z n,构建算法模型。
最后弃限电量模型为
4 仿真试验对比分析
例如数据集为区域A 过去30天分布式光伏曲线数据,共50 户分布式光伏用户,随机选取2个加入样板数据,选取过去5天数据进行回归算法训练,见图2。
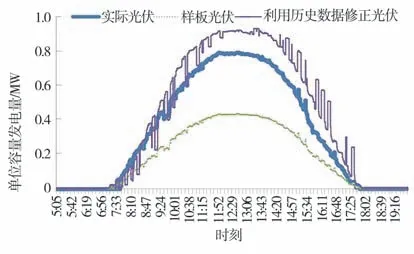
图2 回归算法修正的弃限电量统计方法效果
从仿真结果可以看出样板机法离实际曲线差别较大,样板光伏的准确性主要取决于样板光伏的选取,可以根据历史曲线选出更具有代表性的光伏样板进行估算来优化准确性。基于回归算法修正的分布式光伏弃限电量统计方法与实际曲线更为接近。在实际应用中,为了提升估算准确性,参考天数因素可以进一步优化。较短的参考天数可能会导致模型过于敏感,难以捕捉到季节性和周期性的变化,从而影响对未来光伏弃限电量的准确预测。相反,较长的参考天数可以提供更多的历史信息,有助于更好地理解光伏电量与气象因素之间的关系。
5 结束语
基于回归算法修正的分布式光伏弃限电量统计方法相比于样板机法可以充分利用历史数据对精准度进行修正,相比于样板机法能够更好的适应外部环境的变化,为分布式光伏的调峰管理提供数据支撑。为了提高精准程度,可以考虑对模型改进,考虑尝试更复杂的机器学习模型或者深度学习方法捕捉历史数据和气象因素之间的复杂关系,从而提高预测的精准度。
