基于预训练模型的注意力叠加方法及其在图像字幕生成中的应用
2024-01-09倪玉航张杰
倪玉航,张杰
(1.江苏理工学院机械工程学院,江苏常州 213001;2.江苏理工学院计算机工程学院,江苏常州 213001)
随着计算机视觉和自然语言处理领域的快速发展,图像字幕生成作为一项重要的任务,受到了越来越多的关注。图像字幕生成旨在让计算机自动地使用文本对给定的图像加以描述,其在图像检索、人机对话、盲人导航和自动安防等领域被广泛使用[1]。受神经机器翻译发展的启发,注意力机制已经广泛应用于当前的编码器-解码器图像字幕框架,并取得了令人瞩目的成果。目前的图像描述框架中,通常是先通过网络将图像编码为一组特征向量,然后通过基于RNN的网络解码为单词,其中,注意力机制通过在每个时间步上生成提取的特征向量的加权平均值来指导解码过程[2]。然而,这些方法存在一定的局限性,如提取的特征不够充分、注意力容易被误导等。为了克服这些问题,近年来,预训练模型和对注意力机制的改进被广泛应用于图像字幕生成领域。
本文将预训练模型与注意力叠加相结合,提出了一种基于预训练模型和注意力叠加(Attention on Attention)[3]的图像字幕生成框架,该框架结合了最新的技术和模型,用于提高字幕生成的质量和性能。具体而言,编码器部分采用了预训练的CLIP(Contrastive Language-Image Pre-Training)[4]模型及精炼模块,用于提取更好的图像特征。在解码器部分,采用了预训练的GPT-2[5]模型、LSTM[6]模型和注意力叠加模块,以更准确地生成字幕。首先,将原始图像输入CLIP模型中,获得图像的特征信息;然后,将原始图像特征输入精炼模块,以获取更好的经过改进的图像特征,将与图像配对的真实字幕文本输入GPT-2 中,获得文本输入特征;最后,将改进后的图像特征和文本特征输入LSTM 模型中,生成相应的图像描述。在公共图像数据集上的实验结果表明,基于预训练模型和注意力叠加的图像字幕生成框架相比传统方法具有更好的性能。
1 相关工作
1.1 图像字幕生成
图像字幕生成作为一项跨模态的任务,近年来吸引了大量研究者的关注。通常,图像字幕生成模型首先将输入图像编码为特征向量,然后使用这些向量生成最终的单词序列[7]。早期的图像描述方法采用基于模板或基于检索的方法。基于模板的方法是指在预设的模板字幕文本上采用填词的方法来生成字幕,这种方法通常通过检测图像中的对象、属性和动作来填充模板中的空白部分,从而生成语法正确的字幕文本。然而,这种方法只能在预定义的模板上操作,缺乏灵活性。基于检索的方法通过检索现有的字幕文本数据库来生成字幕文本,这种方法首先在文本数据库中查找公共特征子空间中距离较近的语句文本,然后将其作为候选字幕输出,这种方法不受预定义模板的限制,更加灵活。
近期主要采用基于深度神经网络的方法,具体来说,是利用受神经机器翻译发展启发的深度编码器-解码器框架。Vinyals等人[8]提出了一个端到端的框架,其中CNN 将图像编码为特征向量,LSTM 将其解码为描述语句。Xu 等人[9]将CNN 特征图上的空间注意力机制用于融合视觉上下文。Lu等人[10]提出了一种基于空间注意力和通道注意力的模型。Yao等人[11]在编码器-解码器框架中引入了自适应注意力机制,以决定何时激活视觉注意。随后,更复杂的信息,如对象、属性和关系,被整合到图像描述中,以生成更好的描述。
1.2 预训练模型
近年来,预训练模型的出现将计算机视觉(CV)和自然语言处理(NLP)等单模态领域带入了一个新时代。大量的工作表明,预训练模型有益于下游单模态任务,并避免了从头开始训练一个新模型。近来,研究人员发现预训练模型可以应用于跨模态任务,包括跨模态检索与跨模态生成。以跨模态检索[12-15]为例,预训练模型通过在大规模的多模态数据上进行预训练,学习到了丰富的跨模态表示[16]。这些表示不仅包含了图像、文本、音频等单模态特征,还能够捕捉到不同模态之间的语义关联和相似性。
CLIP 模型用于联合表示图像和文本描述。CLIP模型包括2个编码器,一个用于视觉,另一个用于文本。CLIP模型在无监督的对比损失引导下训练了超过4亿个图像-文本对,生成了丰富的语义潜空间,同时,适用于视觉和文本数据。许多工作已经成功地使用CLIP 模型进行需要理解某些辅助文本的计算机视觉任务,例如:基于自然语言条件生成或编辑图像。本文利用CLIP 模型的图像编码器进行输入图像的特征提取任务。
GPT-2模型是一种强大的自然语言处理预训练模型,其使用了改进的transformer 架构,并通过大规模的无监督语言模型预训练来建立语言的深层次理解。预训练过程中,GPT-2 模型在大量的文本数据上进行自我监督学习,以预测下一个词的概率分布。预训练完成后,GPT-2 模型可以用于各种下游NLP任务,例如文本生成、文本分类和命名实体识别等。为了对输入的真实字幕描述进行嵌入表示,本文使用GPT-2 模型进行文本特征提取任务。这一过程可以更好地帮助解码器理解输入字幕描述的语义信息,并为后续的文本生成任务提供更加准确和有用的文本特征。
2 方法
本节首先介绍了注意力叠加(Attention on Attention,简称AoA)模块,然后展示了如何将预训练模型和注意力叠加模块结合起来,应用在图像编码器和字幕解码器中,从而构建出基于预训练的注意力叠加方法的图像字幕生成模型。
2.1 注意力叠加
注意力机制[17]源于人类的直觉,已广泛应用于各种序列学习任务,并取得了重大的进展。在注意力机制中,首先,为每个候选向量计算重要性分数;然后,使用softmax 函数将分数归一化为权重;最后,将这些权重应用于候选向量以生成注意力结果,即加权平均向量。另外,还有许多已经被应用在图像字幕生成领域的其他注意力机制,例如:空间和通道注意力[18]、堆叠注意力[19]、多级注意力[20]、多头注意力和自注意力[21]。
如图1(a)所示,注意力模块fatt(Q,K,V)接收查询向量Q(queries)、键向量K(keys)和值向量V(values),并对它们进行操作以生成加权平均向量̂。首先,测量Q 和K 之间的相似性;然后,使用相似性得分计算V 上的加权平均向量。可以表示为:
式中:qi是Q 中第i 个查询,kj是K 中第j 个键;vj是V 中第j 个值;fsim是计算每个qi和kj相似性得分的函数;而̂ 是查询qi所关注的向量。
注意力模块对每个查询都会输出加权平均向量,不论查询和键值对之间是否存在关联。即使没有相关的向量存在,注意力模块仍然会生成加权平均向量V̂,这可能会产生不相关甚至误导性的信息。
因此,可以利用AoA 模块来衡量注意力结果与查询之间的关联,如图1(b)所示。AoA 模块通过2个单独的线性变换生成“信息向量”i 和“注意力门控”g,这两个变换都是在注意力结果和当前上下文(即查询)q 的条件下进行的,公式如下:
AoA 模块通过将注意力门控应用于信息向量,使用逐元素乘法添加了另一个注意力,得到所关注的信息̂:
其中,⊙表示逐元素乘法,整个AoA 的流程可以表示为:
2.2 基于预训练模型和注意力叠加的字幕生成模型
本文提出了一种基于预训练模型与注意力叠加的图像字幕生成模型,采用编码器-解码器的框架,其中编码器和解码器均嵌入了AoA 模块。编码器部分由预训练的CLIP 模型及带有AoA 的精炼模块构成,用于提取图像特征;解码器部分由预训练的GPT-2 模型、LSTM 模型及AoA 构成,用于生成图像字幕。整体框架图如图2 所示。

图2 基于预训练模型与注意力叠加的图像字幕生成模型框架
2.2.1 图像字幕编码器
本文对输入的一张图片I ,使用CLIP 模型提取一组图像特征向量A={a1,a2,a3,…,ak},其中,ai∈ℝD,k 是向量集合A 中向量的数量,D 是每个向量的维度。
为了提高编码器中特征的表示能力,在编码器部分引入精炼模块对编码器输出的特征进行进一步的处理。精炼模块中包含了一个AoA 模块,用于对原始图像特征进行精炼,如图3 所示。编码器中的AoA 模块采用了多头注意力机制,其中Q,K 和V 是特征向量A 的3 个独立线性投影。AoA 模块之后接残差连接和层归一化,具体如下:
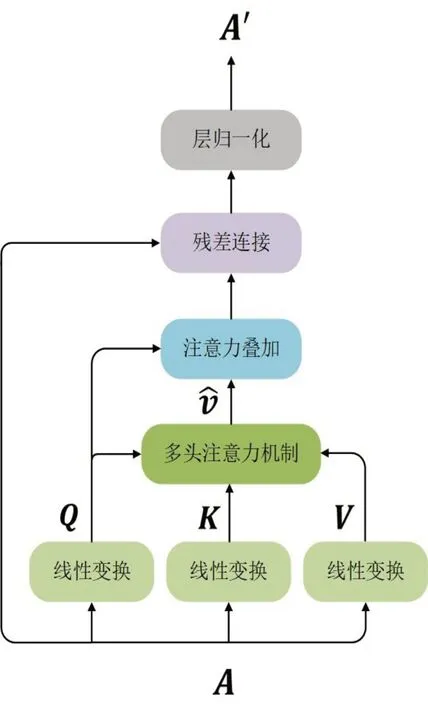
图3 图像字幕生成模型编码器的精炼模块
其中:WQe、WKe和WVe是3 个大小为D×D 的线性变换矩阵;fmh-att是多头注意力函数。将每个输入的Q、K 、V 沿通道维度分为h 份,本文中h=8,并对每个分片Qi、Ki、Vi应用缩放的点积注意力函数fdot-att,最后,将每个分片的结果连接起来,形成最终的注意力向量。具体如下:在这个精炼模块中,多头注意力模块旨在寻找图像中对象之间的交互关系,并应用AoA 来度量它们之间的相关性。在精炼后,更新图像特征向量A →A'。精炼模块不改变A 的维度,因此可以堆叠N 次(本文中N=6)。
2.2.2 图像字幕解码器
解码器利用精炼后的图像特征A 生成字幕序列y ,如图4 所示。为了计算词汇表上的条件概率,建立一个上下文向量ct:

图4 图像字幕生成模型解码器框架
其中: I是输入的图片;Wp是待学习的权重参数,Wp∈ℝD×|∑|;|∑|是词汇表的大小。
上下文向量ct包含了解码器当前的状态以及利用注意力模块得到的最新信息,注意力模块可以是单头或多头注意力,其关注特征向量并与LSTM的输出ht结合生成上下文向量ct。
解码器中的LSTM 模型用于实现字幕解码过程,LSTM的输入包括当前时间步的输入单词嵌入以及视觉向量(a+ct-1)。其中,输入单词嵌入由GPT-2模型的嵌入层输出,a 表示图像特征向量,ct-1表示上一时间步的上下文向量(在初始步骤时,ct-1初始化为全零向量)。解码过程可表示为:
其中:We是词嵌入矩阵,We∈ℝE×|∑|,|∑|表示词汇表的大小;∏t是时间步t 时输入单词wt的独热编码。
如图4所示,对于AoA解码器,ct是从被标记为AoAD的AoA模块中获取:
其中:WQd、WKd、WVd均为D×D 的线性变换矩阵;ht和mt为LSTM 的隐藏状态,且ht用作注意力查询。
2.3 训练过程
在自然语言处理领域中,交叉熵损失是一种常用的损失函数,用于衡量模型在分类任务中的预测结果与真实标签之间的差异。图像描述生成任务可以将其看作是一个序列到序列的问题,模型需要将图像编码用向量表示,然后使用该向量作为输入,生成对应的自然语言描述。为了训练一个良好的图像描述生成模型,通常需要最小化交叉熵损失函数,以使模型能够尽可能准确地预测每个词的概率分布,从而生成最佳的自然语言描述。
AdamW 算法是一种变种的Adam 优化算法,在标准Adam算法的基础上增加了权重衰减项,旨在缓解模型过拟合的问题。相比于其他优化算法,AdamW 算法在实验中表现出更快的收敛速度和更好的训练效果,使得模型能够更好地生成精准的字幕描述。与传统的随机梯度下降(SGD)法相比,AdamW 算法能够更好地处理训练数据中的噪声和稀疏性,并更快地达到收敛状态。在本文中,采用AdamW 算法来优化模型参数,以最小化交叉熵损失函数:
3 实验
3.1 数据集及参数设置
本实验在流行的MSCOCO 数据集和Flickr30k 数据集上评估了本文所提出的方法。MSCOCO 数据集和Flickr30k 数据集分别包含123 287 和31 014 张图像,每张图像都标有5 个字幕。实验使用离线的“Karpathy”数据拆分进行离线性能比较,并将所有句子转换为小写,删除出现次数少于5 次的单词。经过处理后的数据分布如表1 所示。本实验中设置模型的Epoch为20,batch size 为10,迭代次数为6 000。

表1 不同数据集参数对比
3.2 参数分析
学习率是深度学习模型中的重要超参数,控制着模型在每一轮迭代中参数的更新步长,模型在最佳参数下会收敛到最优。因此,本文针对模型的学习率进行了实验,使用了CIDEr-D 和METEOR 指标来评估模型性能。本文将学习率分别设置为1e-2、1e-3、1e-4 和1e-5,对不同学习率条件下的本文模型进行了对比,并将Epoch统一设置为20。图5展示了在不同学习率条件下模型性能的变化趋势,从实验结果中可以观察到,学习率的大小对模型的性能有着显著的影响。
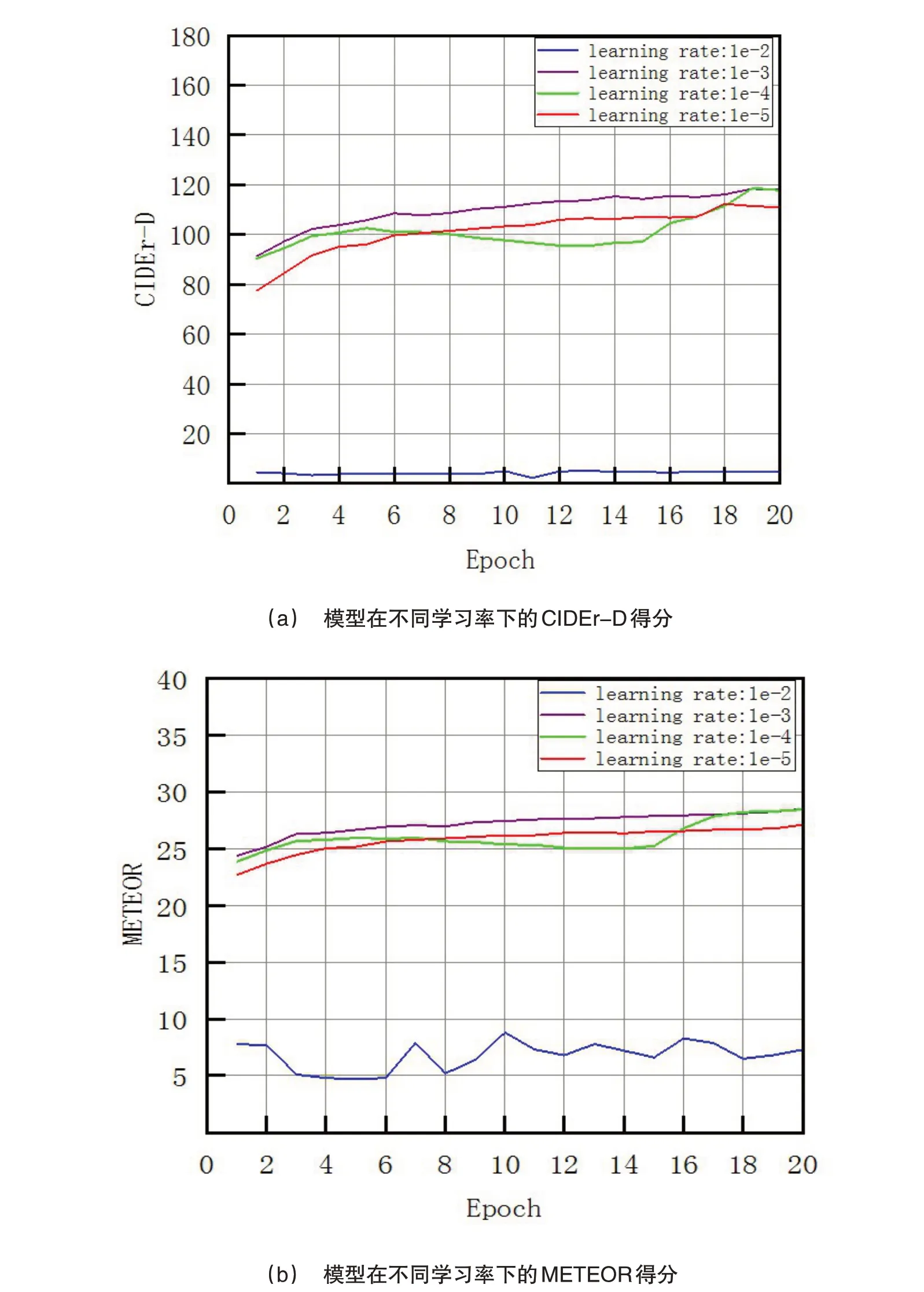
图5 学习率对CIDEr-D 和METEOR的影响
当学习率设置为1e-2 时,模型在初始迭代阶段的学习步长较大,可能导致模型在训练过程中发生震荡,难以稳定地收敛到最优解。因此,模型性能最差,CIDEr-D 和METEOR 指标得分最低。当学习率设置为1e-3时,模型的学习步长适中,能够较快地收敛到一定程度的最优解。实验结果显示,此时模型在测试数据上取得了较好的性能,CIDEr-D 和METEOR 指标得分较高。当学习率设置为1e-4时,模型的学习步长较小,可能导致模型收敛速度过慢,需要更多的迭代次数才能达到较好的性能。因此,相比于1e-3,模型在测试数据上的表现稍逊,CIDEr-D 和METEOR 指标得分有所下降。当学习率设置为1e-5 时,模型的学习步长非常小,导致模型在训练过程中很难更新参数,这将导致模型陷入局部最优或者无法收敛。因此,模型性能有所下降,CIDEr-D 和METEOR 指标得分较低。
综上所述,在本文的模型中,学习率的选择对于模型的性能至关重要。合理地选择学习率可以帮助模型更快地收敛到最优解并取得较好的性能。在本实验中,学习率设置为1e-3时表现最佳。
3.3 对比方法
本实验使用不同的评价指标,包括BLEU、METEOR、ROUGE-L、CIDEr-D 和SPICE 来评估所提出的方法,并与主流方法进行比较。这些方法包括:(1)NIC,该模型使用CNN 对图像进行编码,并使用LSTM进行解码;(2)SCST[22],该模型采用改进的视觉注意力并首次使用SCST 直接优化评估指标;(3)FCLN[23],该模型使用完全卷积的定位网络来同时检测和描述图像中的对象区域;(4)Clip-Prefix[24],该模型采用了全新的前缀结构,将图像特征表示嵌入文本空间中作为前缀;(5)Up-Down[25],该模型采用两层LSTM模型,并使用从FasterRCNN提取的自底向上特征;(6)AAT[26],该模型引入了自适应注意力时间,通过动态确定生成每个字幕单词所需的注意力步骤数量,实现了更灵活和准确的图像字幕生成。
3.4 定量结果分析
以下是本文模型(Pretrained-AoA)在公共离线测试集上的表现,以及与其他基准模型进行比较的结果,所有的值都是表示百分值(详见表2)。由于BLEU- n(其中n 代表n-gram,如BLEU-1、BLEU-2、BLEU-3、BLEU-4)的分数在一个特定的文本生成任务中的升降趋势是一致的,即随着n的增加,BLEU 分数会逐渐降低。BLEU-1 关注的是单个词语的匹配,而BLEU-4关注的是4个连续词语的匹配。因此,本实验选择了BLEU-1 和BLEU-4 作为评价指标。这样既考虑到了不同类型的匹配,以确保实验结果客观准确,又可以使表格结果更为简洁明了。
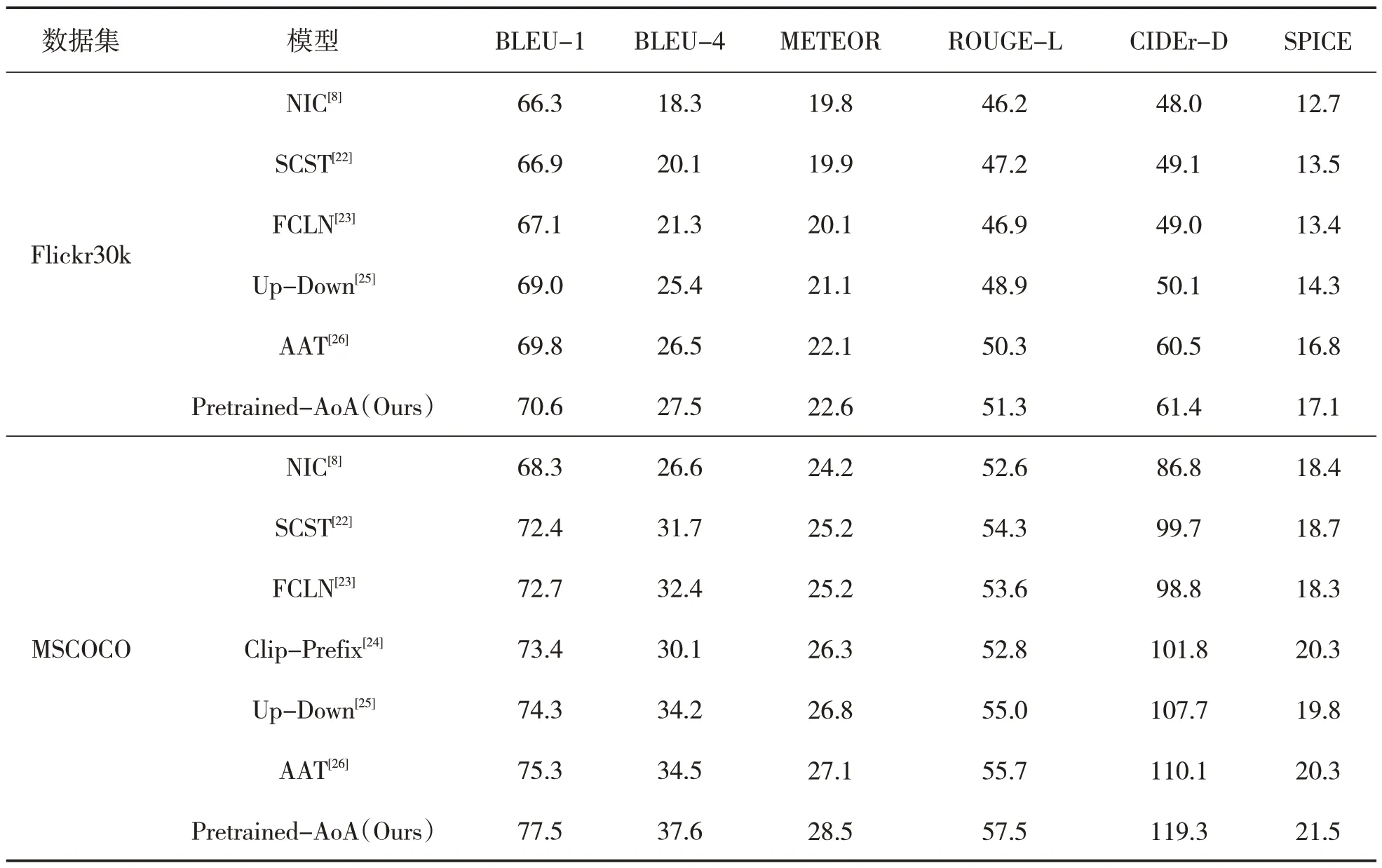
表2 模型在Flickr30k和MSCOCO测试集上的性能表现
为了对比实验的公平性,所有的模型都是在交叉熵(XE)损失下进行训练的。与其他基准模型相比,本文模型在多个评估标准中均取得了最优的性能。与Up-Down 模型相比,本文模型在MSCOCO 数据集和Flickr30k 数据集上的性能都有显著的提升。与Up-Down 模型相比,在MSCOCO 数据集上,本文模型在BLEU-1、METEOR 和CIDEr-D 指标上分别提高了3.2%、1.7%和11.6%。由于CIDEr-D 评价指标更加注重文本的连贯性和相关性,而且其处理重复词汇的方式与其他指标有所不同。本文模型在文本生成质量方面表现卓越,生成的文本更接近人工标注的真实字幕。此外,本文模型还有效地处理了文本中的重复词汇,这进一步提高了CIDEr-D 分数。因此,本文模型在CIDEr-D 指标上表现较为突出。在Flickr30k 数据集上,在相同的评估标准下,模型的性能分别提高了1.6%、1.5%、11.3%。相对主流方法中的基准模型,本文方法展现了更为优越的性能,这主要得益于引入了预训练模型和注意力叠加方法。预训练模型在编码器和解码器部分的应用使模型可以提取到更高层次的特征信息,并且注意力叠加模块的添加使模型得以专注于图像中的关键区域。因此,基于预训练模型的注意力叠加方法使得模型在生成字幕时能够更好地捕捉图像的语义信息,产生更具描述性和准确性的字幕。由表2 的结果可知,本文模型在Flickr30k 和MSCOCO 数据集上CIDEr-D 指标的值分别为61.4%和119.3%,比第二名的模型分别提高了0.9 个百分点和9.2 个百分点。此外,本文模型在其他4 种指标上的得分相较于第二名的模型都有了不同程度的提升。实验结果表明,本文模型在Flickr30k 和MSCOCO 数据集上的表现均优于其他所有对比方法。
3.5 定性分析
表3 展示了由本文提出的基于预训练模型的注意力叠加方法的图像字幕生成模型和一个基准模型生成的图像和字幕示例,以及人工标注的真实字幕。通过重新实现Up-Down 模型来得到基准模型,从这些示例中可以发现基准模型生成的字幕在语言逻辑上是符合的,但与图像内容不是特别符合,而本文的模型生成了高质量且准确的字幕。具体来说,在以下2 个方面优于基准模型:(1)对象描述更准确。在第1个例子中,本文提出的模型正确地描述了年轻男子在人行道上骑着滑板的情景,而基准模型仅仅将他们描述为站在滑板上。在第2个例子中,本文提出的模型准确地描述了一群人站在大象旁边,而基准模型只提到了一群大象站在一起。这表明本文提出的模型能够更准确地理解图像中的对象和它们的位置关系。(2)对象互动理解更好。在第3 个例子中,本文的模型准确地描述了浴室的组成部分,而基准模型则简单地提到了2 个洗手盆。在第4 个例子中,本文的模型准确地描述了一盏红色的交通灯邻近一座高楼,而基准模型只是简单地描述了一盏红色的交通灯在城市街道上。这表明本文提出的模型能够更好地理解图像中对象之间的互动和环境背景。

表3 本文提出的模型和基准模型生成的字幕示例,以及相应的真实字幕
总而言之,本文提出的模型在对象描述和对象互动理解上比基准模型更准确。通过使用预训练模型和注意力叠加的方法,该模型能够更好地理解图像内容并生成准确、细致的字幕描述。与基准模型相比,本文提出的模型通过使用多个预训练模型,如CLIP 和GPT-2,结合LSTM 经典模型,从输入图像中提取特征,并使用精炼模块进行特征优化,同时,注意力叠加机制使模型能够聚焦于图像中的重要区域,并生成更具描述性的字幕。
3.6 消融实验
为了验证本文模型的有效性和探究基于预训练模型的注意力叠加方法的作用,本文进行了一系列消融实验,结果如表4 所示。本文的模型由CLIP、GPT-2、LSTM 以及注意力叠加模块组成,实验以Up-Down模型为基准模型。本实验分别对基准模型进行了不同的设置,并在MSCOCO 数据集上进行了性能评估,分别验证CLIP、GPT-2和注意力叠加模块对整个模型的作用,所有变体模型的设置均在表4中展现。

表4 消融实验的设置和结果
本实验将模型主要分成以下几个部分:(1)基准+CLIP。为了验证CLIP 模型的作用,该模型将基准模型编码器中的ResNet 模型换成CLIP模型。(2)基准+GPT-2。该模型使用了GPT-2 进行文本特征提取,其余部分采用基准模型的设置。(3)基准+注意力叠加模块。为了验证注意力叠加方法的有效性,该模型在基准模型的基础上添加了注意力叠加模块。
从表4可以看出,基于预训练模型和注意力叠加方法的图像字幕生成模型在不同设置下性能都有所提升。其中,基准+CLIP 模型在BLEU-1、METEOR 和CIDEr-D 指标上分别提升了3.2%、6.0%和5.5%,证明了基于CLIP模型的编码器提取特征的有效性。基准+ GPT-2 模型在BLEU-1、METEOR 和CIDEr-D 指标上分别提升了2.8%、2.6%和4.3%,验证了GPT-2 模型对文本嵌入的有效性。基准+注意力叠加模块的模型在BLEU-1、METEOR 和CIDEr-D 指标上分别提升了3.1%、5.2%和8.5%,注意力叠加方法能够使模型聚焦于图像中的重要区域,消融实验证明了其有效性。完整的图像字幕生成模型在BLEU-1、METEOR和CIDEr-D 指标上分别提升了4.3%、6.3%以及10.8%。实验结果表明,采用预训练模型以及注意力叠加方法能够有效地提高模型的性能,使模型能够生成更加准确自然的图像描述。
4 结语
图像字幕生成是一项复杂的跨模态任务,其质量的提升需要依赖准确的模型设计和优化。本文致力于改进图像字幕生成任务,提出了一种基于预训练模型的注意力叠加方法的图像字幕生成框架。相较于传统的CNN 和RNN 组合,该框架充分利用了更多的数据和特征,从而提高了模型的性能和效果。通过在公共数据集上的对比实验,验证了基于预训练模型的注意力叠加方法的图像字幕生成模型框架具有更出色的性能。
