基于模拟退火算法的稀疏表示图像去噪
2024-01-09李佳庆
李佳庆,雷 蕾
(1.山西经济管理干部学院,山西 太原 030024;2.山西城市职业技术学院,山西 太原 030027)
1 综述
X-CT 低剂量薄层扫描,即“薄扫”,能更精准地检出肺癌早期关键病灶。通过X 射线断层扫描和低剂量计算机断层扫描(Computed Tomography,CT)技术,对病灶进行筛查,发现病灶后再进行局部高分辨率扫描的检查。分析时,把电子探测器接收信号转化为数字信号输入计算机,再由计算机转化为图像。这种扫描已成为肺癌早期诊断最有效、最直接的影像学方式。
本文研究低辐射剂量、薄层扫描技术的CT 肺部序列结构影像,对连续高密扫描影像进行检测分析。由于成像设备和获取条件等因素的影响,需要对部分出现质量问题的序列图像进行快速去噪,利用图像去噪技术改善CT 图像的质量,在最大可能地保留和增强医学细微特征和信息的基础上,解决不完备投射带来的影像数据质量问题;去除低剂量方式带来的图像噪声,在去噪过程中避免将微小结节误清除。
由于医学图像去噪的特殊性,本文拟在研究图像去噪算法的基础上,研究保留医学细微特征信息,尽可能地去除掉图像的干扰成分,同时保证原始图像有用信息的完整度。本文研究算法实现快速有效的图像去噪处理方法来支持肺部病灶的检出,实现CT 薄层扫描下序列医学图像快速去噪。
目前,有许多学者在图像去噪方面做出了研究。MUKHOPADHYAY 等人[1]提出了一种利用遗传算法的随机化技术对阈值进行设定与优化的图像去噪方法,利用该方法将含噪声的图像分成固定大小的小块,通过小波变换对每个小块图像进行去噪。YANG H 等人[2]针对图像去噪时对边缘和纹理保护的问题,提出了一种基于双支持向量机的图像去噪方法,在对图像进行去噪的过程中充分利用Shearlet 变换的多分辨率分析和最优逼近的特点,对图像进行去噪的同时很好地保留了图像的边缘特征。PROTTER 等人[3]提出了一个通过稀疏和冗余表示对序列图像去噪的方法,比循环地处理单张图像有更好的峰值信噪比(Peak Signal to Noise Ratio,PSNR)。LI H 等人[4]根据小波变换、稀疏表示和冗余表示,提出了一个单尺度小波K-SVD 算法,对于强噪声图像处理有很好的峰值信噪比。
本文考虑薄层扫描切片及切片上肺结节的分析,在分析肺部CT 序列上下层切片相关性的基础上,结合专家提供的经验知识,设计非局部信息稀疏和冗余表示的图像去噪方法,将图像序列转化成一个既包含时间相关度又包含空间相关度的体素,从而将图像的去噪问题转换成一个基于冗余字典的最优稀疏表示的二次寻优问题。通过序列图像信息与稀疏表示方法对图像进行去噪,从而将图像的去噪问题转换成基于冗余字典的最优稀疏表示的寻优问题[5]。
2 相关工作
2.1 信号处理
时域和频域是信号的基本性质,为信号分析提供了不同的角度。对于需要处理的信号来说,在时域上本身就具有稀疏性的信号很少。为了寻找更好的稀疏,总能找到某种变换,使得在某种变换域中稀疏,即能够用较少的系数来表达。
常见的变换有正交变换、余弦基变换(Discrete Cosine Transformation,DCT)、小 波 变 换(Wavelet Transformation,WT)、多分辨率分析(小波变换)、多 尺 度 几 何 分 析[6](包 括Ridgelet、Curvelet、Bandelet、Contourlet 等一系列多尺度分析工具)。这些工具符合人类视觉皮层对图像有效表示的要求,通过变换的数学分析方法把图像分解在不同的尺度(不同的精细程度)上来处理。
2.2 稀疏表示去噪原理
含噪的图像是有一定的结构的,可以从信号中提取出能表达图像性质的原子,即将信号表示为字典和稀疏的乘积,将信号提取出来,即为去噪后的图像。而噪声是随机、不相关的,没有结构特性,因此提取不出来。通过这样的原理可以将图像提取出来,以达到图像去噪的目的。
2.3 稀疏表示
稀疏表示[7]是获得对信号的良好近似,优化模型是从信号重建的角度来设计的,将信号表示为字典的线性表示。即,y=Ax,其中y是待处理的信号,A是字典,x是稀疏系数。稀疏(性)是指x的大部分元素为0 或接近0,只有少部分元素不为0。其中,x满足稀疏性。稀疏表示的目的是选择最少的系数,从而重构信号y。已知量是输入信号y,未知量是字典A与稀疏系数x。对信号稀疏表示的目的是寻找一个字典使得信号在该字典下的系数(表达)最稀疏。
稀疏表示中稀疏的原因是:字典是在一个足够大的训练样本空间内,对于一个类别的物体,可以大致由训练样本中的样本子空间线性表示,因此当该物体有整个样本空间表示时,其表示的系数是稀疏的[8]。
稀疏表示的两个主要的问题是字典的生成和稀疏分解(编码)。
2.3.1 字典的生成
字典是一个矩阵,一个原子(基)是字典A矩阵中的一列。由这样一列一列的原子排列成的矩阵就是一个字典。字典表达信号的能力取决于信号的特征是否与字典中基的特征相吻合。字典是基的组合,有表达更多、更复杂的信号的能力。
字典有固定字典和自适应字典两种。常用的固定字典有超完备字典DCT、小波字典Contourlet 和曲波字典Wavelet 等。固定字典不能随着信号的变化做出相应的变化,一经选定,对所有的信号一视同仁,信号的表达形式单一;而学习字典是通过大量图像数据学习得到的,通过训练学习得到的字典可以根据输入信号的不同做出自适应的变化,能够更好地适应不同的图像数据。
2.3.2 稀疏分解(编码)
求信号在字典上的稀疏表示,即求出信号y在字典A上的稀疏表示x,常用的方法是正交匹配追踪 算 法(Orthogonal Matching Pursuit,OMP)。主要目标是找出x中最主要的k个分量和值。假设x=(x0,0,0,x1,x2,…)。为寻求与y最为接近的x,首先需计算信号与原子(字典中的每一列)之间的内积。内积可理解为计算矢量在某一指定方向上的投影长度。其次,确定最大值对应的原子,并利用最小二乘法来确立其稀疏系数。在接下来的步骤中,将余下的原子与字典中相应的列进行内积计算,以识别出与最大值匹配的字典列,不断迭代,直至达到算法的收敛状态。
稀疏分解算法的概念最早由MALLAT 提出,名为匹配追踪算法(Matching Pursuit,MP),以其简洁和易于实现的特性得到了广泛的应用[9]。此后,PATI 等学者在MP 算法的基础上提炼出OMP,其特点是具备更大的收敛速度。随后的研究进一步优化了OMP 算法,孕育出如压缩采样匹配追踪算法(Compressive Sampling Matching Pursuit,CoSaMP)、正则化正交匹配追踪算法(Regularized Orthogonal Matching Pursuit,ROMP)、分段式正交匹配追踪算法(Stagewise OMP,StOMP)以及子空间追踪算法(Subspace Pursuit,SP)等多种变种。
2.3.3 优化问题
2.3.3.1 凸优化问题
字典A是一个N×M的矩阵。由于M远小于N,用M个方程求解N个未知数,即用少的方程求解多的未知数,因此y=A*x是个欠定方程(有无穷多解),说明使用字典的线性组合表达信号将是不唯一的,所以求解此问题需要找到最优解。
解优化问题,如果加上适当的限定条件即有唯一解。那么需要解决的问题就是寻找是否存在一种最好的表达方式,使得在字典的表示下系数最稀疏。||x||0为x的稀疏度,表示x中非零系数的个数。要求解x尽可能地稀疏,即||x||0尽可能地小。0 范数的优化问题很难求解,而1 范数优化问题容易求解(存在且唯一)。在满足一定条件下将问题转换为1范数的优化问题(最小化问题),此时优化问题变成一个凸优化问题[10],应用已有的理论就可以解决。
2.3.3.2 最大期望算法
优化的模型是两个参数相乘,需要同时估计字典A和稀疏表示系数x,基本思想是:第一步,将字典A固定,求出x的值,即求信号y在A上稀疏表示;第二步,使用上一步得到的x来更新字典A,即字典更新,使得y和Ax最接近。如此反复迭代几次,即可得到优化的A和x。
在稀疏表示里,已知y和A求x的方法是OMP。已知y,求一个比较好的A的方法是Module(MOD)和K-SVD 等。字典的更新方法主要有最 大 似 然(Maximum Likelihood,ML)、最 大 后验 概 率(Maximum A posteriori Probability,MAP)、MOD、FOCUSS 字典学习算法、主成分分析(Principal Component Analysis,PCA)、K-SVD 以 及Online 等。本文以应用最广泛的K-SVD[11]算法为例做对比实验。
输入含噪序列图像后,K-SVD[12]训练字典用于图像去噪的算法步骤如下。
(1)选择字典作为过完备字典,训练字典;选取字典集,并更新字典。
(2)将含噪图像矩阵以m×m为一块,将一个大的矩阵划分为多个子矩阵。对于每个子矩阵,将元素按列连接为一个列向量,一个m×m的块转换为m2×1 的列向量,生成一个新的矩阵B。最后生成的矩阵B就是由A个块矩阵生成的A列矩阵。矩阵B就作为字典学习的输入。
(3)先取B中的M列,更新其中的每一个元素,B[i][j]B[i][j]-means{B[:,j]}B[i][j]=B[i][j]-means{B[:,j]},式中B[i][j]表示B[i][j]矩阵中第i行第j列元素,means{B[:,j]}表示元素(i,j)所在列(第j列)的平均值。
(4)固定字典,利用OMP 算法,求解该B在字典下面的稀疏系数cofes。
(5)更新B的每一列:B[:][j]=B[:][j]+means{B[:,j]},在此上下文中,B[:][j]第j列可被视为原子的代表。K-SVD 策略涉及逐一地更新原子(即字典的某一特定列)及其相应的稀疏系数。只有当所有的原子都经历了更新过程后,该算法才进入下一迭代。经过多次的精细迭代,最终能够获得经过优化的字典及其稀疏系数。
(6)取下一个M列,重复步骤(3)~(5),直到B矩阵的所有列都处理完成。
(7)将B的每一列(m2×1)转换为m×m的小块,逆运算得到去噪后的图像。
最终,输出去噪后的序列图像。
3 方法描述
本文采用模拟退火算法[13]得到最优值,算法是一种随机性组合优化方法,来源于对固体退火降温的过程。即将固体加温至充分高,再让其温度慢慢退却。固体加热时,固体内粒子随温度的升高而变为无序状,而冷却时,粒子逐渐趋于有序。这一过程中,每个温度下都达到平衡状态,不但能够解优化问题,而且能够优化字典中原子的组合,使字典具备更好的表达信息的能力,从而更好地去噪。
算法是从整体上考虑的,概率与系统能量E、温度T密切相关。在高温下,接受与当前状态能量差较大的新状态;在低温下,接受与当前状态能量差较小的新状态。这样避免陷入局部最优,有的放矢地高效找出最优解。所提方法描述如图1 所示。模拟退火算法[14]稀疏表示去噪算法具体步骤如下。

图1 方法描述
首先输入y=A*x中A与x的无穷多个解,限定条件||x||0和||x||1尽可能小(稀疏)。
(1)初始化状态信息,随机产生初始解x0(即在温度T条件下的解为x0)。
(2)设目标(能量)函数E=y-y*,其中y*=Ax,计算差值ΔE=Ej-Ei,i为当前状态,j为下一状态。若ΔE<0,则接受j为当前状态,即更接近最优解(内能变小更趋于有序状态),否则以一定的概率来接 受 状 态。min{1,exp(-ΔE/KT)}>random[0,1],K是Metropolis 接受准则,是以概率接受新状态。温度T为控制参数。对于exp(A)函数,当A<0,其值小于1;当A>0,其值大于1。ΔE<0,-ΔE>0,-Δf/TK>0,exp(Δf/TK)>1,min{1,exp(-Δf/TK)}取1,接受全部新值。当解为差解时ΔE>0,-ΔE<0,-ΔE/KT<0,exp(-ΔE/KT)<1,min{1,exp(-ΔE/KT)}中取exp(-ΔE/KT),最后通过概率p=exp(-ΔE/KT)>random[0,1]来接受新值,即概率p=exp[-(Ej-Ei)/KT]若大于[0,1]区间的随机数,接受状态j为当前状态;若不成立,则保留状态i为当前状态。
(3)不断产生新解,计算目标函数差,判断是否接受新解。经过大量的解变化后,可以求得给定控制参数的优化问题的相对最优解。
(4)设定阈值n是最优的n个解。保留这些解,寻找与图像最接近的若干解,并对这些解进行标记。利用模拟退火算法来优化自适应字典,以找到每个解的最佳自适应字典。最终,在所有解中选择最优解。
输出最优解,得到最优的字典A和稀疏系数x,逆运算Ax=y*得到去噪后的图像,从而完成图像去噪。
与广泛使用的K-SVD 算法相比,K-SVD 算法需要先更新每一个元素再更新每一列,更新速度慢,迭代次数多。而本文算法是从宏观的角度动态自适应地更新协调全部的值,更加整体和智能,在对比实验中得到的去噪效果较好。
4 实验结果
算法的实验环境是Matlab R2015b 软件,计算机处理器为Intel Core i7-3770,主频3.40 GHz,内存8 GB。用数学软件进行算法研究和数据分析,从评价图像质量的指标峰值信噪比PSNR 和算法性能的时间复杂度两方面进行实验。实验中,将提出的基于模拟退火算法的稀疏表示图像去噪算法与K-SVD 算法进行去噪效果对比。实验数据为采集的山西省人民医院患者数据,采集设备是医院现有X-Ray 薄扫设备。依次标记20 组序列图像,将每组序列图像数据集作为一组测试集。现列出一组序列图像的实验数据来说明算法[15]。
训练的字典如图2 所示。图2(a)是K-SVD算法的自适应字典,图2(b)是本文算法所得出的字典。

图2 训练字典
序列图像中其中一幅图像去噪后的实验结果对比如图3 所示。从图3 可以看出,本文算法的实验结果有较高的峰值信噪比,从直观感受方面看得到了很好的去噪效果。

图3 噪声图像与去噪后的图片对比
从整体看,一组序列图像的实验数据如图4、图5 所示。

图4 本文方法与K-SVD 方法的信噪比对比
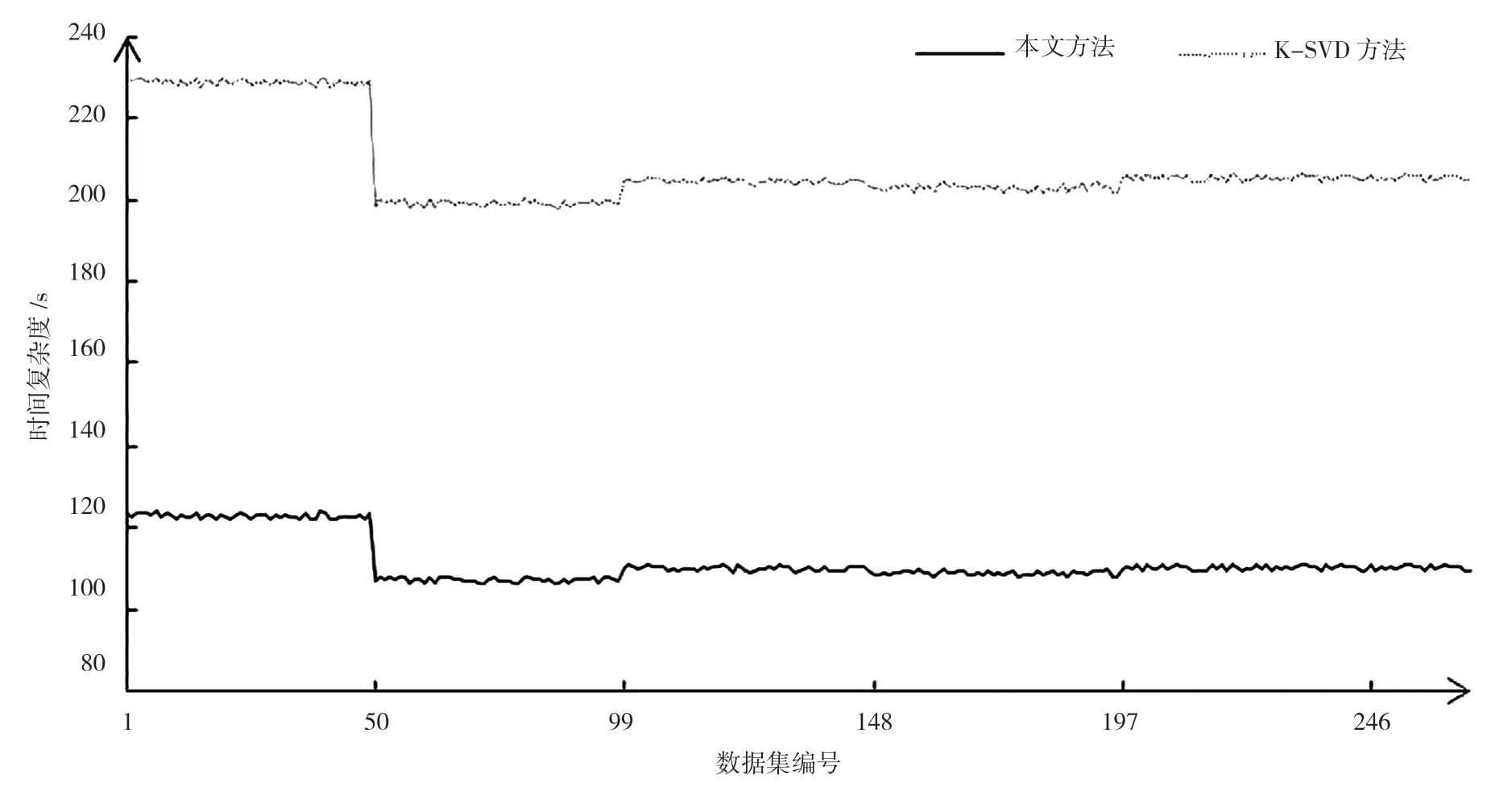
图5 本文方法和K-SVD 方法时间复杂度的对比
从实验数据可以看出,对于同一序列图像,传统的K-SVD 方法在序列图像的信噪比上有间歇性的不稳定,对于某些图像的去噪效果不好,但本文方法有很好的信噪比与稳定性。传统的K-SVD 方法时间复杂度较高,而本文方法在时间复杂度上有所降低[16]。
接下来,扩展至更多的数据集,使实验更具广泛性和稳定性[17-18]。以下是一组序列图像的实验结果,运行程序共运行了20 组实验数据,现列出5组数据平均值,以说明实验结果及去噪效果。将本文算法与现在广泛使用的K-SVD 的相关数据对比,结果如表1、表2 所示。表1 给出了其中5 组序列图像的去噪峰值信噪比平均值。可以看出,在对薄扫图像进行去噪时,本文提出的方法具有较高的信噪比。
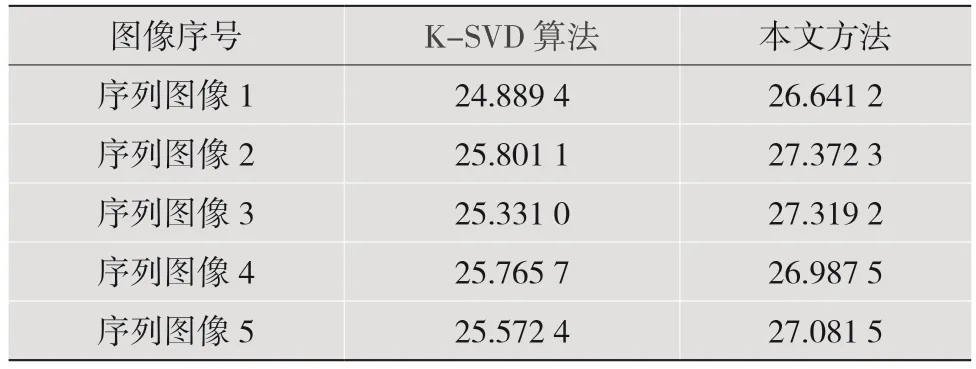
表1 峰值信噪比平均值对比 单位:dB
时间复杂度是评估算法性能的重要参数。实验中使用的算法对样本的时间复杂度如表2 所示。在实验比较的算法中,本文算法的速度比K-SVD 算法快。在测试阶段,本文算法识别一个手势图像序列消耗的平均时间为99.39 s。
在将快速去噪算法应用于整个肺部结节的检出实验中,根据先验知识与诊断结果,对是否检出病灶的实验数据进行比对,进而算出结节识别率进行对比,对于病灶不明显的图像具有一定的作用,实验数据存在偶然性,就目前所具有的数据,识别的结果有存在不一致的情况,这样降低漏诊率,在预处理方面对此课题有一定的辅助作用[19]。相对于传统的K-SVD 方法的性能优势的描述,包括信噪比的提高、稳定性的增强以及时间复杂度的降低。这些描述强调了本文方法在图像去噪任务中的优越性,并提供了实验数据支持,进一步强调了本文方法的创新性和实用性,使读者更容易理解本文方法是一个有价值的改进,为图像去噪带来了重要的进展。因此,本文提出的算法更适用于稀疏表示去噪,是一个行之有效的方法,在效果和性能方面都有一定的提高。
5 结语
将稀疏表示用于去噪,分为多尺度几何分析、稀疏表示和优化问题。其中,稀疏表示的两大任务是字典的生成和信号的稀疏分解。运用多尺度几何分析将图像转换到某个域中,使稀疏尽可能地稀疏,能够达到好的效果。本文运用优化方法进行解优化问题。在字典生成中,下一步的工作是用online 子空间聚类去批量去噪。对稀疏表示去噪还会继续进行研究,以为医学诊断做好坚实的前期工作。肺癌死亡率高的主要原因是其早期的细小病变特征很难被发现,临床漏诊率高。肺癌早期的检出对提高治愈率起着至关重要的作用,能够使达到医学图像诊断误差率尽可能小。
