激发-发射矩阵荧光光谱用于鉴别百合掺假的研究
2024-01-08张思维张芷柔
唐 英 张思维 张芷柔 陈 瑶
湖南工业大学生命科学与化学学院 湖南 株洲 412007
1 研究背景
百合(药材)为百合科植物卷丹、百合或细叶百合的干燥肉质鳞叶[1],富含多糖类、生物碱类、甾体皂苷类、黄酮类以及酚类化合物等多种化学成分[2],具有止咳平喘、抗氧化、抗抑郁、抗肿瘤、抗真菌、降血糖、免疫调节等多种药理作用及养阴润肺、清心安神等保健功效[1,3],被广泛应用于临床中药配方和中成药。百合通常被加工成粉末状产品,从外观上难以辨别其品质优劣[4]。个别不良商家趁机往纯百合粉末中掺入一定量廉价淀粉(如土豆淀粉、红薯淀粉、小麦淀粉和玉米淀粉等)出售,更有甚者直接用淀粉类产品冒充纯百合粉出售,以此谋取暴利,从而导致市面上的百合粉质量良莠不齐。因此,探究快速有效鉴别百合粉中掺假掺伪问题的方法具有重要意义。
目前,近红外光谱[5-6]、薄层色谱[1,7]、气相色谱[8-9]、液相色谱[10-13]和质谱[14]等指纹图谱方法已被应用于中药掺假检测。然而,近红外光谱灵敏度和精度不够高,且易受环境因素影响。色谱和质谱的样品前处理通常比较复杂、耗时。与上述方法相比,荧光光谱具有分析速度快、样本制备简单、成本低、灵敏度高等优点。但传统的基于单一激发光谱或发射光谱的荧光光谱所具有的光谱信息量有限,有时不足以用于复杂样品的分析。激发-发射矩阵(excitationemission matrix,EEM)荧光光谱可以获取矩阵数据,比传统荧光光谱包含更多的信息。因此,激发-发射矩阵荧光光谱与先进的模式识别方法相结合,已被广泛用于诸多领域的分类和真伪鉴别。
本研究采用激发-发射矩阵荧光光谱构建百合的荧光指纹特征图谱,结合主成分分析-线性判别分析(principal component analysis-linear discriminant analysis,PCA-LDA)和偏最小二乘-判别分析(partial least squares-discriminant analysis,PLS-DA)两种化学模式识别方法,对百合中掺假粉末(精制淀粉、土豆淀粉、玉米淀粉和红薯淀粉)的种类进行快速检测和分类,用于快速鉴别掺假百合,为辨别市面上掺伪掺假的百合药材提供一种新方法。
2 实验部分
2.1 样品、试剂及仪器
2.1.1 样品准备
本研究收集了纯百合样品12 份,均来自湖南省湘西土家族苗族自治州龙山县的龙雨百合。精制淀粉、土豆淀粉、玉米淀粉和红薯淀粉4 种淀粉作为掺假物,各采购1 袋。现共有16 份样品。将所有样品放入烘干箱,在60 ℃下干燥6 h,烘干后用80 目筛进行筛分,把粉末分类装入塑封袋中并标记相应名称,常温储存在干燥箱中备用。
2.1.2 实验试剂及仪器
本研究所使用的试剂为无水乙醇(分析纯,国药集团化学试剂有限公司)、纯水;仪器为离心机(Super Mini Dancer,生工生物工程(上海)股份有限公司);F-7100 荧光分光光度计(日本日立集团),在个人计算机上搭配软件FL Solution 4.0 使用。
2.1.3 百合的预处理方法
准确称取25 mg 纯百合粉末于2 mL 离心管中,加1 mL 体积分数为60%的乙醇水溶液进行溶解。将溶液超声提取10 min,然后在4000 r/min 转速下离心5 min,即得到纯百合原液。取100 μL 原液上清液于另一2 mL 离心管中,加入乙醇水溶液稀释至1 mL,即稀释10 倍,得纯百合待测样。
2.2 单因素优化
2.2.1 测试参数
随机选取1 份纯百合样品,按上述预处理方法制备纯百合待测样后,放入荧光分光光度计中,在测试电压为600 V、扫描速度为30 000 nm/min、响应时间为自动调节、激发波长范围为200~700 nm、发射波长范围为200~750 nm、激发和发射步长均为10 nm、激发和发射狭缝宽度均为5 nm 的条件下进行全波长扫描,保存图谱和文本数据(TXT 格式)。且后续所有样品测试均按本节中已确定的参数设定值统一进行。
2.2.2 萃取剂浓度
现行药典中采用甲醇作为萃取剂。本研究考虑到实验安全性和绿色环保性,改用无水乙醇为萃取剂,并用纯水配制成体积分数分别为100%、90%、80%、70%、60%、50%、0%的乙醇水溶液。随机选取1 份纯百合样品,向7 个2 mL 离心管中放入准确称取的25 mg 粉末,分别加入1 mL 不同浓度的乙醇水溶液。超声10 min、离心5 min,得7 份纯百合原液。使用与原液样品所用浓度相同的乙醇水溶液于另外7个2 mL 离心管中稀释10 倍,共得7 份纯百合待测样。扫描测试无水乙醇空白样和7 份纯百合待测样,保存图谱和文本数据。
2.2.3 稀释倍数
稀释过程中,通过调整纯百合原液上清液与萃取剂的比例来达到稀释10 倍、50 倍和100 倍的效果。随机选取1 份纯百合样品,向3 个2 mL 离心管中放入准确称取的25 mg 粉末,各自加入1 mL 萃取剂(取上步优化最优结果)。超声10 min、离心5 min,得3 份纯百合原液。稀释过程:取100, 20, 10 μL 原液上清液,于另外3 个2 mL 离心管中,将其分别稀释至1 mL,得3 份不同稀释比例(10, 50, 100 倍)的纯百合待测样。扫描测试萃取剂空白样和3 份待测样,保存图谱和文本数据。
2.2.4 样品质量
随机选取1 份纯百合样品,在前述优化过程中所得的最优条件下进行预处理。向3 个2 mL 离心管中分别放入准确称取的20, 25, 30 mg 纯百合及1 mL 萃取剂;超声10 min 和离心5 min,得3 份纯百合原液,稀释得3 份不同浓度的纯百合待测样。扫描测试萃取剂空白样和3 份待测样,保存图谱和文本数据。
2.3 建立样本集
在上一步实验中,所有条件均已优化完毕,本步实验所使用纯百合样品及4 种淀粉掺假物样品均按优化后的最优条件进行预处理和扫描测试,确保荧光光谱图和文本数据的准确性和高精确度。
2.3.1 纯百合样品
现有12 份纯百合样品,对12 份样品进行标准预处理后,扫描测试萃取剂空白样和12 份纯百合样品,保存图谱和文本数据。
2.3.2 掺假的百合样品
现有精制淀粉、土豆淀粉、玉米淀粉、红薯淀粉4 种淀粉作为掺假物,均按标准百合预处理办法配制淀粉掺假物原液,然后使用同一种方法配制淀粉掺假物标准样。完成制备1 mL 纯百合原液和1 mL 淀粉掺假物原液后,取500 μL 纯百合原液上清液于10 mL 离心管中,再加入体积分数为60%的乙醇水溶液至5 mL,即稀释10 倍,得1 份纯百合标准样;同样,取600 μL 淀粉掺假物原液上清液于10 mL 离心管中,再加萃取剂稀释10 倍,得1 份淀粉掺假物标准样。取一定体积的纯百合标准样和淀粉掺假物标准样,按不同体积比进行梯度混合,得到掺假物体积分数为10%~100%,间隔为10%,具体如表1 所示。4 种淀粉掺假物的不同体积分数掺假样品均制备3 份,共可制得120 份掺假试样。扫描测试萃取剂空白样和120份百合掺假样品,保存图谱和文本数据。
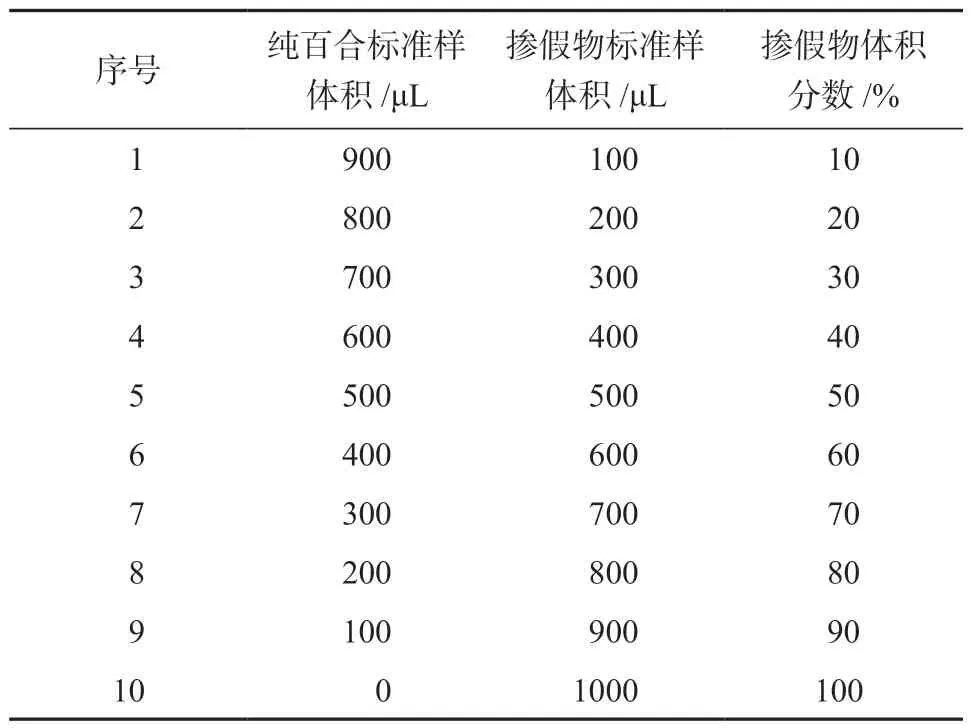
表1 纯百合样品与掺假物样品混合比例表Table 1 Mixing ratio table of pure lily samples and adulterate samples
2.3.3 新掺假百合样品
现用另一批次购买的玉米淀粉作为掺假物,均按标准百合预处理办法配制玉米淀粉原液,然后使用同一种方法配制玉米淀粉标准样。完成制备1 mL 纯百合原液和1 mL 玉米淀粉原液后,取500 μL 纯百合原液上清液于10 mL 离心管中,加入体积分数为60%乙醇水溶液稀释10 倍,得1 份纯百合标准样;再取600 μL 玉米淀粉原液上清液于10 mL 离心管中,加萃取剂稀释10 倍,得1 份淀粉掺假物标准样。取一定体积的纯百合标准样和玉米淀粉标准样,按掺假物体积分数分别为0%, 20%, 40%, 60%, 80%, 100%进行混合,共得6 份百合+新玉米淀粉掺假样。用该6份样品对模型进行外部验证。
2.4 化学计量学工具
化学模式识别方法是化学计量学的重要分支,按照是否已知样本的类别,可被分为有监督的模式识别(判别分析)和无监督的模式识别(聚类分析)两类。本研究所使用的方法中,PCA 属于无监督的模式识别一类,而LDA 和PLS-DA 则属于有监督的模式识别一类[15]。
2.4.1 主成分分析-线性判别分析
PCA 是一种常用的降维统计方法,借助构造适当的价值函数,对较高精度的多维变量系统进行降维处理,使之转换为一维系统,以提高计算效率和降低数据复杂度,更加简洁地展示主要变量之间的关系。PCA 不仅能降低所研究数据空间的维数、表示多维数据的图形,还能筛选回归变量、构造回归模型,用较少的计算量获得选择最佳变量子集合的效果。
LDA 是一种经典的线性学习方法。通过使用统计学、模式识别和机器学习等方法,寻求能够代表两类物体或事件特征的线性组合,用于区分它们或者将其特征化。该线性组合可以用作分类器,更普遍的是用于降维处理,使后续分类能够更加高效实现。
PCA-LDA 是将 PCA 和LDA 两者结合,通常用于提取有价值的信息并减少数据矩阵的维数[16],更有利于寻找到解释数据的最佳变量线性组合。
2.4.2 偏最小二乘-判别分析
PLS 是一种数学优化技术。当预测矩阵较观测矩阵包含更多变量或者X值中具有多重共线性时,PLS回归模型的适用性特别高。PLS 通过投影预测变量和观测变量到一个新空间来寻找线性回归模型。不仅如此,PLS 的优势还有区分系统信息与噪声的能力较强(有利于降低噪声的影响)、更易于说明每一个自变量的回归系数等。
DA 是一种统计判别和分类技术。它是在一定数量样本的一个分组变量和相应的其他多元变量的已知信息基础上,确定分组与其他多元变量信息所属的样本进行判别分组。
PLS 和DA 两者结合的优势在于其强大的解释能力:所需的样本数量较少;一定程度上降低变量间多重共线性所造成的影响等。
2.4.3 软件与参数
本研究所有数据处理均在MATLAB R2020b 环境中完成。PCA-LDA 与PLS-DA 算法则是通过classification-toolbox 5.1 工具箱来完成。
纯百合样品和百合掺假样品共有132 份,按照纯百合样品、精制淀粉掺假样品、红薯淀粉掺假样品、土豆淀粉掺假样品和玉米淀粉掺假样品5 类进行划分,建立5 个子样本集,每个子样本集中需要包含后续进行数据处理需要的所有样本数据信息。
样本集包括前述5 个子样本集,采用随机抽样的方法进行划分,随机选取97 份样品(包含所有类别)作为训练集,用于构建模型、选择最优参数并初步评估构建的分类模型性能;剩余35 份样品(包含所有类别)则作为验证集,进一步评估构建的分类模型性能,额外配制的6 个样本则作为预测集,对分类模型进行外部验证。
以计算所得的模型正确分类率(correct classification rate,CCR)作为分类模型的整体性能评估指标[17]。CCR 的计算方法为
式中:n为正确分类的样本数;m为样本总数。采用基于训练集的十折百叶窗交叉验证(cross verification,CV)得到的最佳CCR 确定模型的复杂度参数,如PCA-LDA 的主成分数(PCs)和PLSDA 的潜在变量数(LVs),在此基础上对PCA-LDA和PLS-DA 模型进行优化。
3 结果与讨论
3.1 单因素优化
3.1.1 测试参数
纯百合样品全波长扫描的荧光光谱图见图1。

图1 纯百合样品全波长扫描荧光光谱图Fig. 1 Full wavelength scanning fluorescence spectrogram of pure lily samples
由图1 可知,仪器扫描波长范围可精简至激发波长(EX)为200~460 nm、发射波长(EM)为260~570 nm。为提高结果的精确度,扫描速度降低至12 000 nm/min、激发和发射步长均减小至5 nm,测试电压、响应时间、激发和发射狭缝宽度维持原值不变。
3.1.2 萃取剂浓度
根据图1 谱图结果,7 份纯百合待测样的荧光强度最高值都在激发波长为270 nm、发射波长为350 nm(简述为EX/EM 270/350)和EX/EM 340/410 两点处附近波动,故选取7 份待测样在这两点处的荧光强度作图(见图2)。
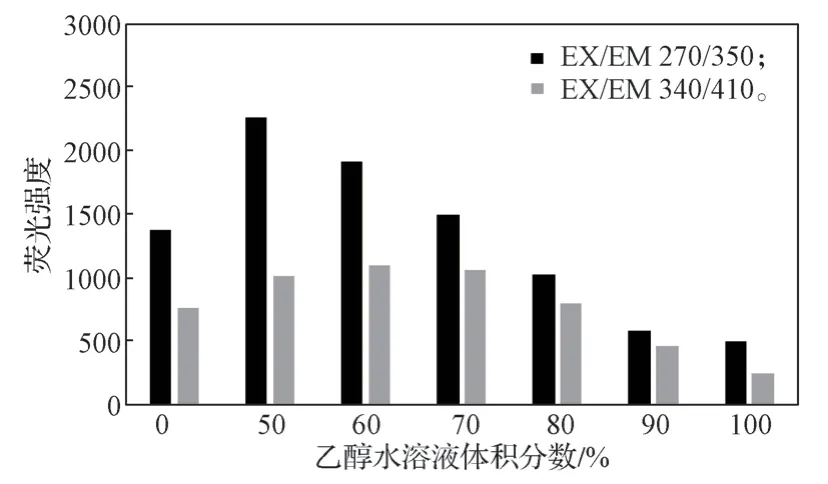
图2 纯百合样品萃取剂浓度-荧光强度关系图Fig. 2 Relationship between extractant concentration and fluorescence intensity in pure lily samples
由图2 可知,当EX/EM 340/410 时,荧光强度最高值对应的乙醇水溶液体积分数为60%;而当EX/EM 270/350 时,荧光强度最高值对应的乙醇水溶液体积分数为50%。
通过比较无水乙醇空白样及乙醇水溶液体积分数为50%待测样的原始谱图可知,在EX/EM 270/350 处有重叠峰出现,即此处的荧光信号强度推测是无水乙醇和百合的组合值(详细介绍见下文3.2.1节)。结合在EX/EM 340/410 处的荧光强度数据比较可知,荧光强度最高的乙醇水溶液体积分数应为60%,故选用60%乙醇水溶液作为标准萃取剂。
3.1.3 稀释倍数
根据图1 谱图结果,3 份纯百合待测样的荧光强度最高值都在EX/EM 275/350 和EX/EM 340/415 两点处附近波动,故选取3 份待测样在这两点处的荧光强度作图(见图3)。由图3 可以看出,当稀释倍数为10 倍时,在两点处荧光强度都最高,且远高于稀释倍数为50 倍和100 倍的荧光强度,故选用稀释10倍作为纯百合样品的标准稀释倍数。
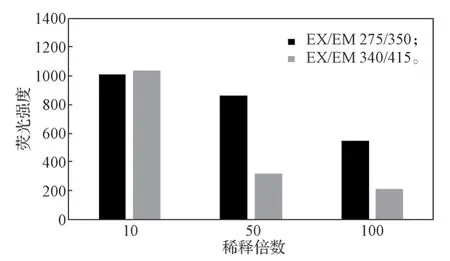
图3 纯百合样品稀释倍数-荧光强度关系图Fig. 3 Relationship between dilution ratio and fluorescence intensity in pure lily samples
3.1.4 样品质量
根据图1 谱图结果,3 份纯百合待测样的荧光强度最高值都在EX/EM 280/350 和EX/EM 385/420 两点处附近波动,故选取3 份待测样在这两点处的荧光强度作图(见图4)。由图4 可以看出,当样品质量为25 mg 时,在两点处荧光强度都最高,所以应该选定25 mg 作为标准样品质量。
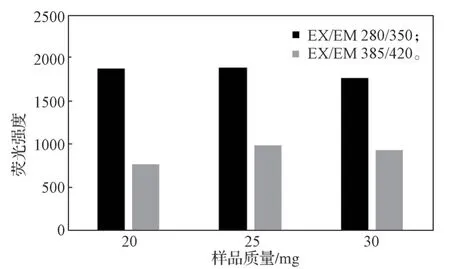
图4 纯百合样品质量-荧光强度关系图Fig. 4 Relationship between sample weight and fluorescence intensity in pure lily samples
3.2 样本数据分析
3.2.1 纯百合样品
图5 为纯百合样品及60%乙醇水溶液(萃取剂)的荧光光谱图。对比图5a 和图5b 可以看出,百合常在EX/EM 280/355 和EX/EM 340/425 两点处附近有极强的荧光信号。需要注意的是,百合在EX/EM280/355的荧光信号与60%乙醇水溶液的荧光信号有一定程度上的重叠,因此该点的荧光信号强度应该考虑为百合与萃取剂共同作用的结果,且不能认为是简单叠加。此外,该点处的荧光物质可能为生物碱、蛋白质和氨基酸等;EX/EM 340/425 处的荧光物质可能为皂苷类和多糖类化合物等。
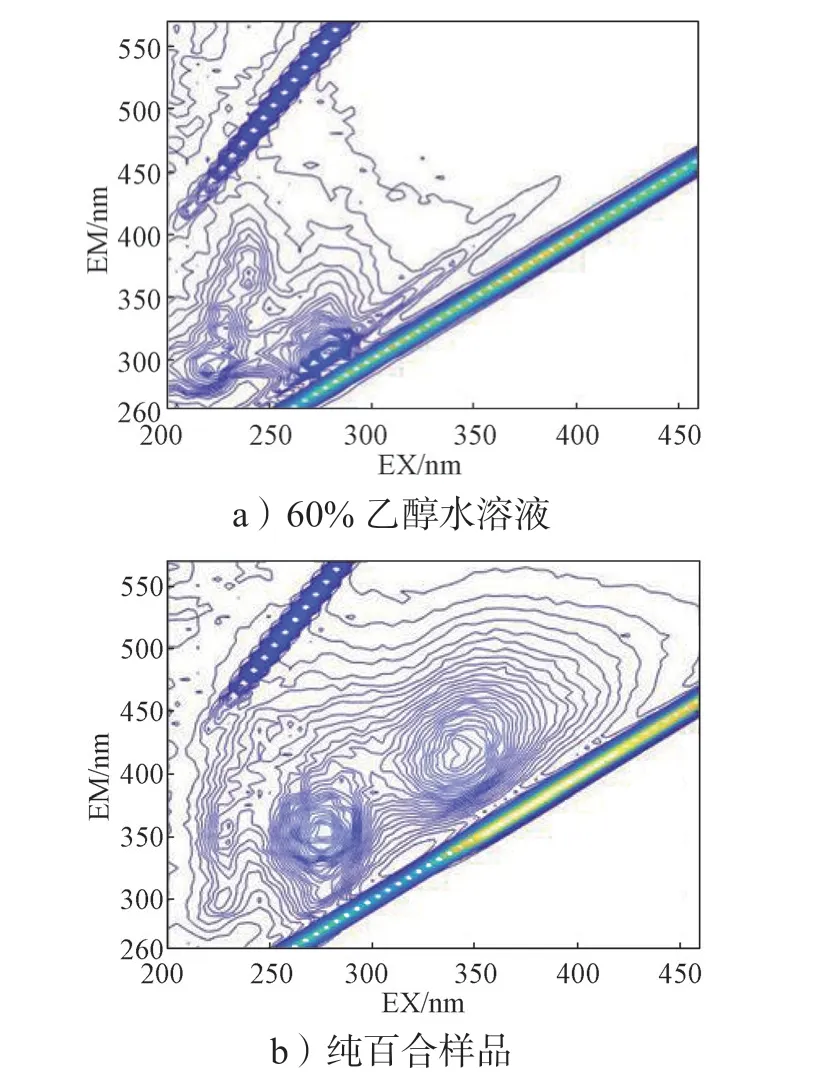
图5 萃取剂和纯百合样品的EEM 荧光等高线图Fig. 5 EEM fluorescence contour maps of extractant and pure lily samples
每个纯百合样品都是53×63(激发波长数×发射波长数)的矩阵数据。由荧光峰的位置可知,百合所含的内源荧光团的位置、强度、形状均大致相同,为接下来利用化学模式识别方法进行分类提供了重要依据。由此可建立百合的荧光指纹特征图谱。
3.2.2 淀粉掺假物样品
4 种掺假物(精制淀粉、红薯淀粉、土豆淀粉、玉米淀粉)的荧光光谱图如图6 所示。
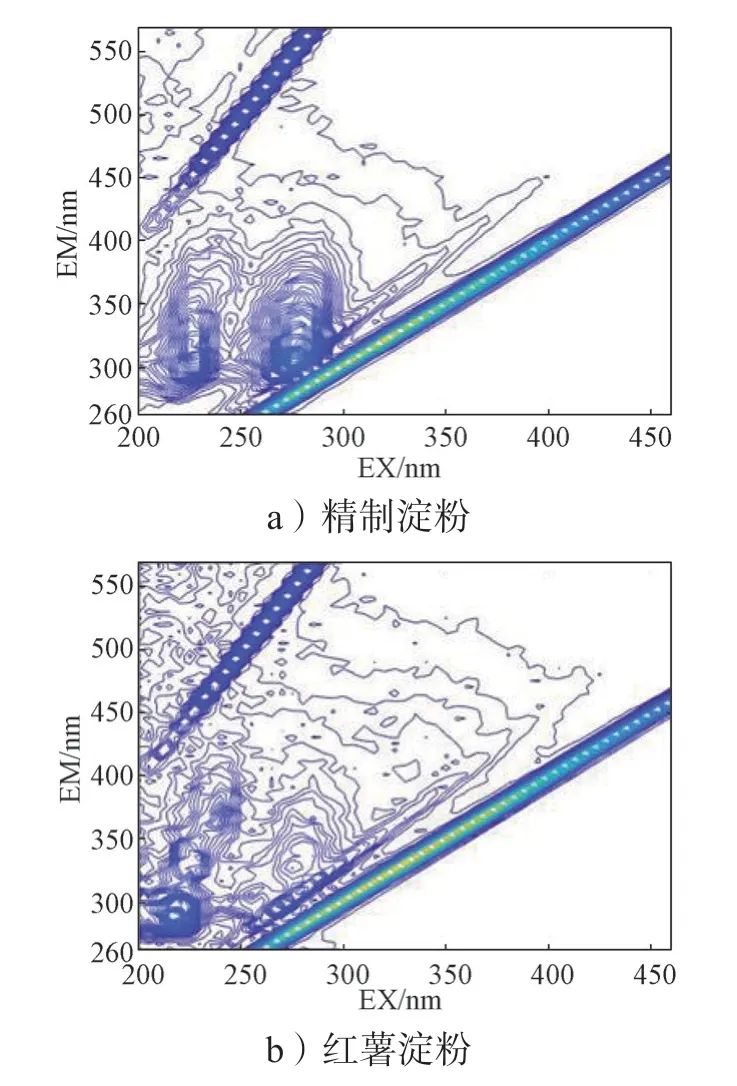

图6 淀粉掺假物EEM 荧光等高线图Fig. 6 EEM fluorescence contour maps of starch adulterants
对比图6 与图5b 可以明显看出,4 种淀粉掺假物在EX/EM 340/425 处附近均没有明显的、强烈的荧光信号;而在EX/EM 280/355 处的荧光信号都较为杂乱,荧光峰的个数也不尽相同,并不像图5b 中纯百合样品的图像,有一个排布规律且信号强烈的荧光峰团。因此,4 种淀粉掺假物与百合的荧光峰个数、位置、形状和强度等不同,为接下来的分类提供了极大的可能性。
3.2.3 掺假的百合样品
以玉米淀粉掺假纯百合样品为例,掺假体积分数0~100%、间隔10%,得到玉米淀粉掺假样品的荧光光谱图如图7 所示。由图可以看出,随着掺假物浓度的增大,百合含量不断降低,百合在EX/EM 280/355和EX/EM 340/425 两点处的荧光峰逐渐发生变化。EX/EM 280/355 处的荧光信号有一定程度的减弱,且荧光峰位置渐渐下移,不断靠近瑞利散射处,荧光团形状大面积缩小,信号强度也减弱较多。而EX/EM 340/425 处的荧光团变化过程更为明显,荧光团的形状不断缩减,且荧光强度随之减弱。由此推断,这两点处荧光峰的变化将成为百合掺假判别的重要依据。
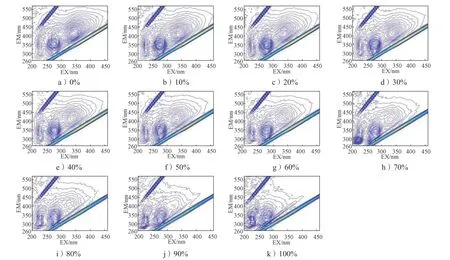
图7 不同含量玉米淀粉掺假样品EEM 荧光等高线图Fig. 7 EEM fluorescence contour line maps of corn starch adulterated samples with different content
图8~10 分别为精制淀粉、红薯淀粉和土豆淀粉掺假样品的EEM 荧光等高线图,均与上述玉米淀粉掺假样品变化情况大致相同。
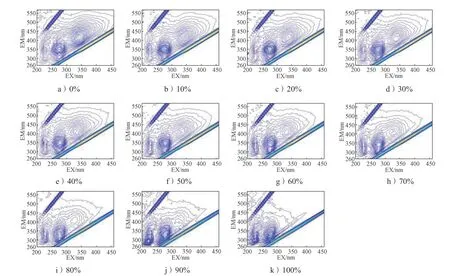
图8 不同含量精制淀粉掺假样品EEM 荧光等高线图Fig. 8 EEM fluorescence contour line maps of refined starch adulterated samples with different content
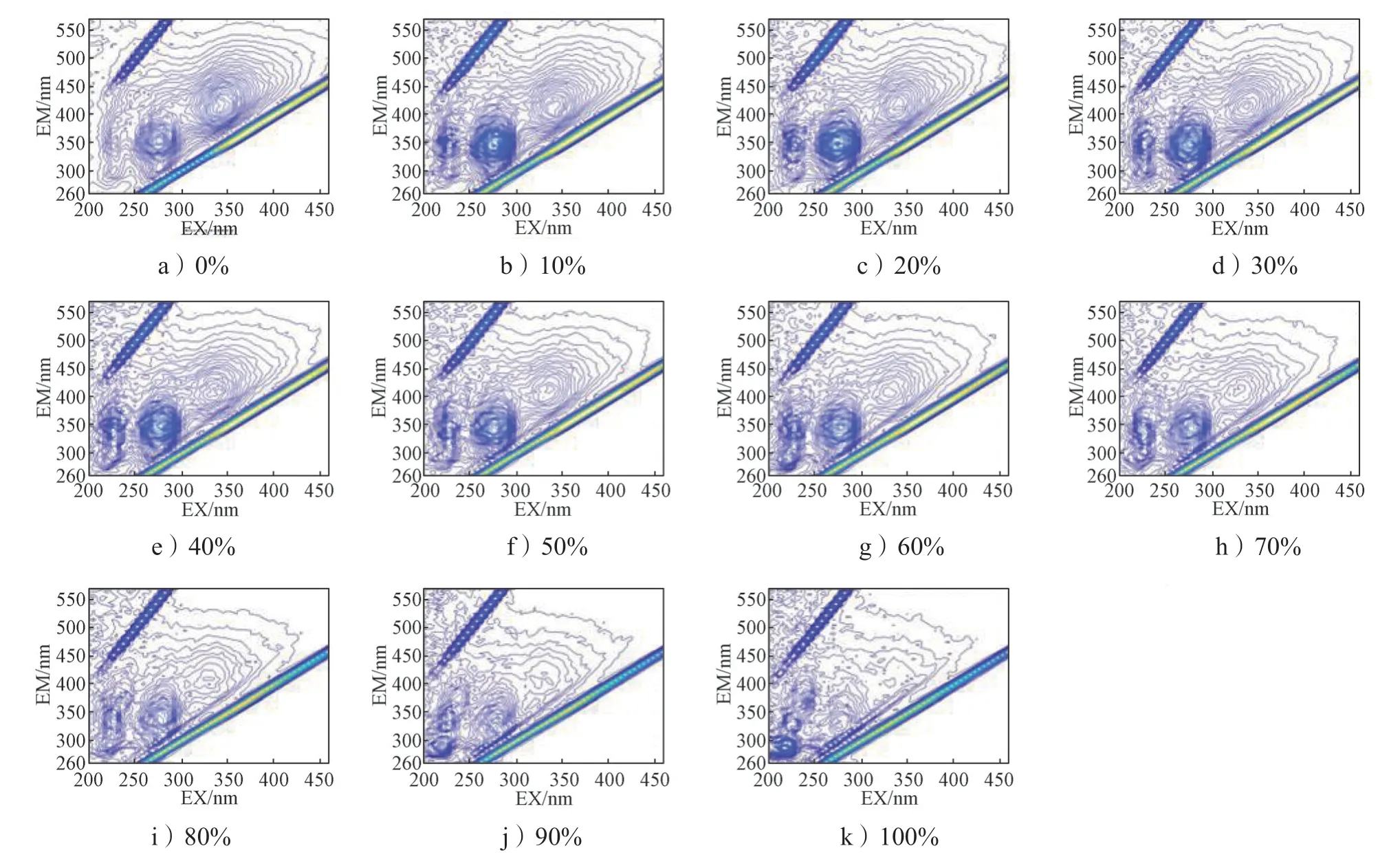
图9 不同含量红薯淀粉掺假样品EEM 荧光等高线图Fig. 9 EEM fluorescence contour line maps of sweet potato starch adulterated samples with different content
3.3 百合的掺假判别分析
3.3.1 分类模型的构建
百合的掺假分类样本共分为5 类:纯百合(A)、百合+精制淀粉(B)、百合+红薯淀粉(C)、百合+土豆淀粉(D)和百合+玉米淀粉(E)。采用PCA-LDA 和PLS-DA 两种化学模式识别方法,在前面建立的百合EEM 荧光指纹特征图谱基础上,对纯百合及4 种不同类型的掺假百合样品建立掺假判别模型。首先,基于CV 得到的CCR 来优化PCA-LDA模型的主成分数(PCs)和PLS-DA 模型的潜变量数(LVs)。当PCs为9 时,PCA-LDA 模型可以获得最佳结果,其交叉验证的CCR 为94.9%;当LVs为15 时,PLS-DA 模型可以获得最佳结果,其交叉验证的CCR 为95.9%。然后,这两个模型将用于验证训练集(train set)样本和测试集(test set)样本,结果如表2 所示。

表2 PCA-LDA 和PLS-DA 模型的最优参数及交叉验证、训练集和测试集的正确分类率Table 2 The optimal parameters of PCA-LDA and PLS-DA models and CCRs of CV, train and test sets
由表2 中测试集的CCR 可以看出,两个模型的分类效果都比较好,CCR 都高于97%,体现出这两个模型在辨别百合真伪上的优秀能力,尤其是PCALDA 模型的CCR 为100.0%,说明所有掺假样品全部判别成功。
另外,表3 为PCA-LDA 和PLS-DA 两种模型对训练集的混淆矩阵。
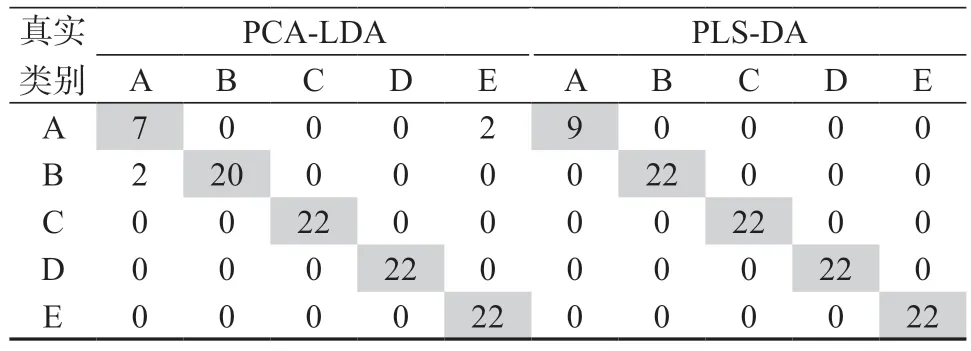
表3 PCA-LDA 和PLS-DA 模型获得的训练集混淆矩阵Table 3 Confusion matrix of train set obtained by PCA-LDA and PLS-DA models
由表3 可以看出,PLS-DA 模型的测试集分类效果较好,全部分类成功。PCA-LDA 模型的训练集虽略有错误,将2 个纯百合样品分类为玉米淀粉掺假样品、2 个精制淀粉掺假样品分类为纯百合样品,但误差仍在可接受范围内。且经对照样品编号发现,分类错误样品的淀粉掺假物体积分数均不超过20%。当淀粉掺假物浓度较低时,百合掺假样品与纯百合样品的荧光光谱较为相近,因此判别的过程中出现了失误。
图11 为基于PLS-DA 模型所有LVs的得分值使用t-SNE 降维处理的可视图。图中每一个点代表一个纯百合或掺假百合样品,同类型点聚集越密,不同类型点距离越远则分类效果越好。由此可以看出,纯百合样品和不同类型的掺假百合样品之间存在相对较高的分散度,表明PLS-DA 分类模型具有良好的分类性能。

图11 PLS-DA 模型中所有LVs 得分值的样本可视化结果图Fig. 11 The visualization results of lily adulterated samples based on all LVs of PLS-DA
3.3.2 分类模型的准确性验证
本研究使用额外制备的6 个新样本(百合+玉米淀粉掺假样)来检验分类模型的实际应用能力,结果如表4 所示,其中包含5 个掺入不同浓度玉米淀粉的百合样本(E)和1 个纯百合样本(A)。

表4 PCA-LDA 和PLS-DA 模型对新百合掺假样本的分类结果Table 4 Classification results of new lily adulterated samples by PCA-LDA and PLS-DA models
由表4 可知,在掺假体积分数不低于20%的情况下,PCA-LDA 和PLS-DA 模型均能获得100%的正确分类率。且在实际生活中,非法商贩为了获取较高利润,往往在百合中掺入大剂量的淀粉。由此可以看出,这两种分类模型都具有一定的实际应用能力,有望在百合甚至其它中药材、食品等领域的掺假辨别分析中得到广泛应用,从而保障消费者的合法权益,以及提高用药安全性。
4 结论
本研究采用EEM 荧光光谱法结合PCA-LDA、PLS-DA 两种化学模式识别方法的方式对百合掺假试样进行了研究。基于纯百合和4 种掺假百合(百合+精制淀粉、百合+红薯淀粉、百合+土豆淀粉、百合+玉米淀粉)的EEM 荧光指纹特征图谱建立的两个掺假判别分析模型都具有较高的正确分类率,PCA-LDA 模型训练集的CCR 为95.9%,PLS-DA 模型训练集的CCR 甚至高达100.0%,且两个模型还能对新掺假的6 个百合样本进行准确分类,CCR 均为100%。以上结果表明,两个模型皆可用于百合的快速检测及真伪鉴定,从而进一步完善百合质量评价体系。
