基于IAO-PNN模型的天然气水合物生成条件预测研究
2024-01-07梁龙贵郭仕为景玉平李姜超
梁龙贵,张 龙,郭仕为,景玉平,梁 挺,李姜超
(1.中国石油塔里木油田公司 克拉采油气管理区 地面工艺部,新疆 库尔勒 841000;2.中国石油塔里木油田公司克拉采油气管理区 克深8采气作业区,新疆 库尔勒 841000;3.中国石油塔里木油田公司 克拉采油气管理区生产办,新疆 库尔勒 841000)
随着我国经济实力和科技水平的不断提高,越来越多的陆上及深海天然气资源被勘探和开发。在其开采、运输和处理的过程中,一旦满足高压、低温和饱和水的条件,天然气和水会形成冰晶状的笼形结构产物,即天然气水合物(简称“水合物”)[1]。形成的水合物可堵塞管道、井筒,增大管线起点压力,影响管输量,并造成设备腐蚀减薄,对正常生产造成较大的影响[2-3]。保障流动,解决水合物带来的问题,制定水合物防治措施,先决条件是研究水合物的生成相平衡条件。
近年来,国内外学者针对水合物生成条件进行了研究,形成了经验图解法、热力学模型法和关联公式法等主要方法。其中,经验图解法和关联公式法的计算过程相对简单,但预测效果和精度不尽如人意,常造成现场操作失误[4]。以van der-Waals-Platteeuw为代表的热力学模型,通过建立水合物相中水的化学位与富水相中水的化学位之间的关系,采用压力迭代法对水合物生成条件进行预测,并由此衍生出了Parrish-Prausnitz(P-P)、Ng-Robinson(N-R)、Holder-John(H-J)、Chen-Guo和Du-Guo等模型[5],预测精度得到进一步提高。但该热力学模型依然存在基础参数众多、计算复杂的问题,且在状态方程的适应性和选择性上有所不同。
随着计算机的高速发展,越来越多的非解释类数据挖掘算法被用于水合物生成条件的预测。马贵阳等[6]通过遗传算法(GA)和支持向量机(SVM)预测了水合物生成压力,平均相对误差为2.678%;卞小强等[7]量化了酸性气体对水合物的形成权重,通过SVM对酸性体系下的水合物生成条件进行预测,平均相对误差为5.7%;徐小虎等[8]对比了神经网络(BP)和最小二乘支持向量机(LSSVM)两种算法的预测效果,在抑制剂体系下,LSSVM 模型的预测效果更好,最大相对误差为4.47%;李恩等[9]采用正余弦算法(SCA)优化BP 模型中各层的权值和阈值,对于酸性体系和醇盐体系下水合物的生成温度进行了预测,模型最大相对误差为1.99%。以上研究中BP 模型和SVM 模型本质上是基于环境资源管理的传统统计方法,当输入参数样本不均衡时,仍有较大概率陷入局部最小值,且需要优化的模型参数较多,增大了算法随机性失误、泛化能力变弱的可能性。此外,上述研究的误差在低温低压条件下尚可接受,但在高压水合物的生成预测中明显偏大。
概率神经网络(PNN)可根据数据样本和预设期望值,自动获得各层单元之间的连接权值,在参数优化上只需设置一个平滑参数,具有收敛速度快、预测精度高和无需反复训练网络等特点[10]。基于此,本文在收集天然气水合物生成实验数据的基础上,将天然气组分、水相质量分数和压力作为输入变量,将水合物形成温度作为输出变量,构造PNN 模型;并采用改进的天鹰(ⅠAO)算法实时优化平滑参数,形成适合不同体系的水合物生成条件预测模型;通过与热力学方法和其他机器学习模型比较,验证算法的优越性。
1 模型基础
1.1 PNN模型
概率神经网络(PNN)模型是基于贝叶斯理论和Parzen窗的前馈型神经网络,由输入层、模式层、求和层和输出层组成[11]。其中,输入层只负责输入样本的预处理,将其转化为输入向量传入模式层;模式层负责计算输入向量与权值向量之间的相似程度,即计算各类别样本的出现概率;求和层负责对各类别的输出进行加权平均;输出层通过贝叶斯分类规则,将后验概率最大或响应度最大的值作为系统输出。模型公式见式(1):
式中,X为输入向量;Wi为两层之间的权值;δ为光滑因子。
1.2 AO算法
天鹰(Aquila optimizer,AO)算法是2021 年由ABUALⅠGAH等提出的仿生学算法,属于较新的种群优化算法,在调参和收敛未知域上具有优越性[12]。标准算法包括拓展搜索(X1)、缩小搜索范围(X2)、扩大范围(X3)和缩小开发范围(X4)等步骤,根据迭代次数和随机数大小,选择相应的捕捉策略,最终将猎物捕获。不同搜索策略下的位置信息算法公式分别见式(2)~式(5):
式中,Xi(t+1)为不同搜索策略下t+1次迭代的解;Xbest(t)为t次迭代的最优解,表示猎物的大致方位;XM(t)为当前解的位置均值;rand为[0,1]的随机数;T为最大迭代次数;Levy(D)为在D维空间中的莱维飞行函数;XR(t)为随机解;y和x分别为搜索范围,呈螺旋上升趋势;α和β为固定参数,取值为0.1;UB和LB分别为所求解函数的上限和下限;QF为用于平衡搜索策略的质量函数;G1、G2为天鹰跟踪猎物过程中的飞行斜率。
从算法实现过程看,位置更新中式(3)会收敛为常数,式(5)会收敛为0,且两种位置均采用了莱维飞行,保证种群分布的均匀性和搜索的随机性,因此只需对式(2)和式(4)进行改进。式(2)中的(1-t/T)作为Xbest(t)的系数,表示当前策略下最优解的生成权重。此时,采用线性减小的方式会明显降低局部搜索能力,故将指数函数引入其中,通过自适应权重确定目标猎物的范围,改进后的公式见式(6):
以T=100 为例,改进前后的数值大小见图1。前期的非线性变化速度较快,权重较大,有利于全局搜索;后期的非线性变化速度较慢,权重较小,有利于局部搜索。

图1 Xbest(t)数值的变化趋势Fig.1 Variation trend of Xbest(t) values
同理,式(4)中的α和β为固定值,也会降低种群的寻优趋向和收敛精度,在前期应保证α大于β,以便尽快确定最优解范围;在后期应保证α小于β,防止最优解突破问题边界,在此采用双曲正切函数进行改进。α、β修正后的公式分别见式(7)、式(8):
同样以T=100 为例,改进前后的数值大小见图2。改进后两个参数的变化策略与算法特点相匹配,寻优能力进一步增强。最终,对AO算法进行了改进,形成了ⅠAO(Ⅰmproved aquila optimizer)算法。

图2 α和β数值的变化趋势Fig.2 Variation trends of α and β values
2 基于ⅠAO-PNN 模型的天然气水合物生成条件预测模型
2.1 影响因素分析
在实际生产过程中,水合物的形成与多种因素相关,温度、压力是形成水合物的外因,气质组分、水相组分和抑制剂成分是形成水合物的内因[13-14]。当气体中乙烷和丙烷含量增加时,相平衡曲线向右侧偏移,说明这两种气体会促进水合物的生成,且水合物结构由Ⅰ型变为ⅠⅠ型;H2S和CO2等酸性气体的加入对水合物的生成起促进作用,且H2S 的促进作用更强;N2的加入可轻微抑制水合物的生成;甲醇、乙醇和乙二醇等热力学抑制剂对相平衡曲线的影响程度不一,随着抑制剂含量增大,甲醇的抑制效果不变,乙醇的抑制效果变小,乙二醇的抑制效果变大;不同盐类同样会破坏电离平衡,改变水合物的相平衡常数,对水合物起到抑制作用,主要以NaCl和MgCl2为代表性的地层孔隙水成分为主[15]。
2.2 预测模型建立
模型建立过程如下:(1)建立数据库,广泛选取文献中水合物的生成实验数据,选取原则为温度、压力应保持较大范围,且同一组分体系下的数据点足够多。考虑到现场工况均以甲烷为主体系的水合物,故删除乙烷、丙烷、丁烷和CO2含量(物质的量分数)超过80%的数据,最终提取了512个数据。数据结构见表1。第二列以CH4-H2O 的二元体系为主,第三列以CH4-C2H6-C3H8的多元体系为主,第四列以CO2-H2S 等酸性体系为主,第五列以NaCl、CH3OH等醇盐体系为主,且每种体系下的数据量基本一致,保证了后续数据回归的均衡性。除醇盐体系外,其余体系的最高压力较大,这对于我国四川盆地、塔里木盆地等高压气藏井下及井口节流后,水合物的预测起到重要作用。
(2)数据处理,为避免量纲差距过大对预测精度造成影响,将数据按照最大最小法进行归一化处理,统一至[0,1]区间。
(3)划分数据集,将数据集按照4:1,分为训练集和测试集,训练集用于训练模型参数和网络结构,以便得到最优PNN模型;测试集用于检验模型预测未知参数的泛化能力。鉴于现场对水合物形成温度的关注度较大,将天然气组分、水相质量分数和压力作为输入变量,水合物生成温度作为输出变量。
(4)模型优化,将训练集代入PNN模型,初始化ⅠAO 算法参数,按照式(2)~式(8)分策略计算适应度值,比较不同策略下适应度值的优劣,并根据最优解更新个体最优位置,当偏差达到预设值或不再变化时优化结束,得到最优光滑因子δ下的PNN 模型,形成训练好的ⅠAO-PNN 模型。适应度函数值Fitness公式见式(9):
式中:Z为数据个数;y为实验值;y’为预测值。
(5)模型预测,将测试集代入优化后的PNN 模型,将输出结果反归一化处理,通过均方根误差(RMSE)和决定系数(R2)两个统计学参数,评价模型的预测效果。
3 结果与讨论
3.1 不同算法适应度曲线分析
为验证AO 算法改进的有效性,将ⅠAO、AO、粒子群(PSO)和麻雀(SSA)算法进行比较,考察了其在训练集上的适应度曲线,如图3。
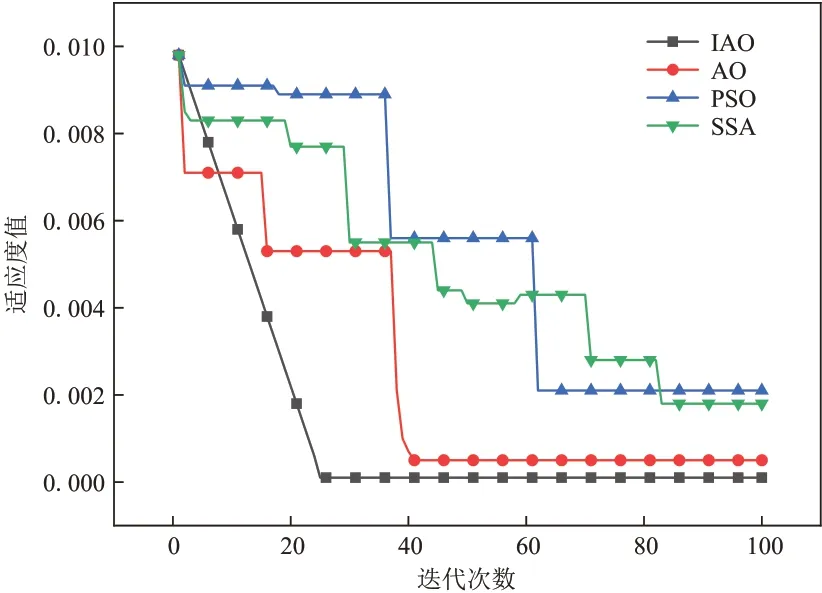
图3 不同算法的适应度曲线Fig.3 Fitness curves of different algorithms
PSO和SSA算法的原理和参数选取参照文献[29],PSO算法中加速因子均为1.5,惯性权重为2;SSA算法中安全值取0.8,警戒值为0.2;所有算法的种群大小均为50,维度取10。在迭代过程中,ⅠAO 的收敛速度、收敛精度和鲁棒性均优于其余算法,PSO 和SSA 算法经历了多次局部最优解,但始终无法跳出局值限值。
为进一步体现算法性能,采用Wilcoxon秩和检验进行非参数统计分析,验证算法之间是否存在显著差异,通过假设检验概率p值,衡量结果的显著性水平,当p<0.05时,表示该算法的显著性强于其余算法;当p>0.5 时,表示该算法的显著性弱于其余算法,如表2。其中,ⅠAO 和AO 算法的p值均小于0.05,且ⅠAO 算法的p值更小,PSO 和SSA 算法的p值大于0.05,说明ⅠAO 算法与其余算法存在明显差异。

表2 不同算法的Wilcoxon秩和检验结果Table 2 Wilcoxon rank sum test results of different algorithms
3.2 IAO-PNN模型训练
设置ⅠAO-PNN模型的网络结构为17-400-400-1,根据上述ⅠAO 算法的优化情况,最优光滑因子δ=0.35641,训练结果如图4。模型训练值均在回归线附近,RMSE为0.6176,R2为0.9994,只有高温高压情况下存在少许偏离回归线的点,这可能与实验室内高压危险性较大、数据较少有关,但总体来说训练效果较好。

图4 IAO-PNN模型的训练结果Fig.4 Training results of IAO-PNN model
3.3 IAO-PNN模型预测
3.3.1 与热力学模型对比
将训练好的ⅠAO-PNN 模型用于水合物生成温度的预测,同时与经典的热力学模型预测结果进行对比,如图5。

图5 不同体系下水合物生成温度预测结果Fig.5 Prediction results of hydrate formation temperature in different systems
P-P 模型简化了Langmuir 常数的计算方法,Chen-Guo 模型通过两步生成模型预测水合物形成过程[30],Du-Guo模型将抑制剂体系和酸性体系加入预测模型[31],这3 种模型在预测水合物生成条件下的代表性较强,故采用以上热力学模型进行对比实验。对于二元体系和多元体系,Chen-Guo 模型在低压时的预测精度均不足,与第一个实验点的差距较大;P-P 和Du-Guo 模型在低压时偏差较小,在高压时偏差较大,可能与传统模型未考虑水合物晶格体积变化,同时氢键作用增强,未考虑氢键间的缔合作用有关。对于酸性体系和醇盐体系,热力学模型中Chen-Guo的预测效果最好,但在高压下与实验值仍存在较大偏离,其余热力学模型未考虑水溶液中,气体溶解和离子反应对水合物诱导及生成的影响,在逸度计算上有所差异,故预测效果较差。ⅠAOPNN模型预测值与实验值的吻合度较高,预测曲线均穿过实验值,精度优于其他热力学模型,且在高压下依然保持较好的预测效果。此外,数据在测试集上的RMSE为0.7624,R2为0.9991,与训练集相比,误差和决定系数在同一数量级内,说明ⅠAO-PNN模型具有良好的泛化能力。
3.3.2 与BP、SVM模型对比
针对传统热力学模型在水合物生成条件预测上的局限性,将训练好ⅠAO-PNN模型用于水合物生成温度的预测,并与BP、LSSVM等机器学习模型进行对比,预测结果的绝对误差(预测值与实验值的差值)如图6。BP 和LSSVM 的网络结构参照相关文献设置[8-9],BP 模型的权值和阈值由ⅠAO 算法优化,SVM 模型的惩罚因子、核系数及不敏感参数统计也由ⅠAO 算法优化。ⅠAO-PNN 模型的预测精度明显优于其余两种模型,绝对误差在±0.2 K 的范围内;BP和LSSVM模型的绝对误差基本一致,但两者在高温高压区的预测精度有所下降,说明模型对于数据样本的要求较高,对于多子样、小样本的预测效果不好。BP和LSSVM模型在测试集上的RMSE分别为1.2468和1.1543,R2分别为0.9861和0.9905,与ⅠAO-PNN 模型(测试集上的RMSE为0.7624,R2为0.9991)相比精度明显降低。

图6 不同算法预测结果的绝对误差分布Fig.6 Absolute error distribution of prediction results by different algorithms
3.4 现场应用
以某气田2022年4月3日至8月10日的现场数据为例,其组分如表3。采用ⅠAO-PNN模型用于现场水合物相平衡的预测,对照管道维抢修记录,观察不同气井集输管道压力的波动情况。除气流脉动和传感器故障外,压力在一定时段内上升则认为管线中有水合物生成,如图7。测试的15口气井中有8口气井位于相平衡曲线右侧,压力未出现较大波动;7口气井位于相平衡曲线左侧,压力数次出现异常波动,此后均通过加大气嘴流量和末点降压的方式予以解堵。

表3 气田气组成Table 3 Gas composition in gas field
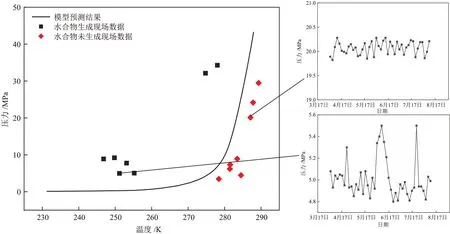
图7 水合物预测结果与现场数据对比Fig.7 Comparison of prediction results and field data of hydrate
4 结论
针对传统热力学模型和机器学习在水合物生成条件预测上的局限性,收集相关实验数据,建立了适合不同水合物体系的ⅠAO-PNN模型,并针对模型的泛化性和鲁棒性进行了评价,得到如下主要结论。
(1)通过自适应权重和双曲正切函数对AO 算法进行了改进,形成ⅠAO 算法,其寻优精度和收敛速度明显优于AO、PSO和SSA算法,可迅速跳出局部最优解的限制。
(2)与传统热力学模型和机器学习算法相比,ⅠAO-PNN模型与实验数据的吻合性最高,适合不同体系下的水合物预测,训练集上的RMSE为0.6176、R2为0.9994,测试集上的RMSE为0.7624、R2为0.9991,两者的差距较小,说明本文模型未出现过拟合或欠拟合的现象。
(3)通过现场验证,水合物预测结果与现场工况保持一致,证明了模型的可靠性,该模型可为现场解堵措施的制定,以及抑制剂加量的优化调整提供参考。
