基于双边实时语义分割的金属缺陷检测
2024-01-05张伟娜李卫东李晓娟赵子琪
张伟娜,李卫东,李晓娟,赵子琪
(河北经贸大学信息技术学院,河北 石家庄 050061)
0 引言
带钢作为钢铁类主要产品之一,是现代化工业生产中不可或缺的原材料。然而,带钢表面的油污、划痕、氧化皮等缺陷会严重影响产品的抗腐蚀能力、耐磨性以及疲劳强度。因此,设计一种轻量化语义分割网络实时检测带钢表面质量对制造行业具有重要意义。
由于带钢表面缺陷类内差异明显、类间相似性较高。传统的缺陷检测方法如频闪法[1]、无损检测[2,3]以及基于图像处理的方法[4]等效率低下、主观性强、泛化性差且无法满足实时性要求。基于深度学习的方法都是通过扩大感受野实现对物体变化的感知,如Chen等人[5]研究了在Deeplabv2中引入空洞卷积增强模型对特征变化的感知,但过多使用空洞卷积会导致网络伪影;Yang等人[6]提出DenseASPP空间金字塔池化对骨干网不同尺度下提取的特征进行融合,但池化会造成信息的丢失。对于类间相似性问题,模型需要实现对图中不同类别对象的整体感知,细化边缘特征。Segnet[7]、UNet[8]将高维抽象特征上采样与低层边缘特征进行融合,聚合空间信息,但是在实时场景下,轻量化网络会剪裁模型,导致网络中Decoder不能通过浅层网络恢复空间信息。对于实时任务,一些轻量化分割网络如ENet[9]、ICNet[10]通过压缩图像和模型来降低计算量,但会大大降低精度。
针对以上问题,本文采用较为新颖的双边实时分割网络模型Bisenetv2[11]进行缺陷的分割,该模型将空间信息和语义信息单独进行处理,然后进行特征融合,做到在检测缺陷方面速度和精度的相对平衡。针对检测情况对原模型进行部分改进,在避免网络伪影和信息丢失的情况下充分提取上下文信息增强模型对物体的整体感知。利用本文模型在NEU数据集[12]上进行测试,相较于原始Bisenetv2网络,本文模型能更好地区分类内差异信息和类间相似特征,并且在参数量减少4%的情况下,MIoU值提升了11.1%,既保证了推理速度又提升了分割精度。
1 网络原理与结构
1.1 Bisenetv2算法原理
语义分割既需要丰富的空间信息,又需要相当大的感受野。Bisenetv2是一种双路分割网络[11],其结构如图1所示,模型主要由三部分组成,双路主干、聚合层和助推部分。双路主干的空间分支使用宽通道小步幅的卷积操作来提取图像浅层次的空间细节,该分支特征表征了物体的边缘细节。双路主干的语义分支通道容量较低使得该分支轻量化,网络层数较深旨在捕获高级语义,在语义分支的最后一层接一个全局平均池化来嵌入全局上下文响应。因为两路分支提取的特征是独立的,需要设计聚合层来融合空间分支和语义分支两个层次的特征表示。在助推部分,设计由3×3卷积和1×1卷积组成的辅助分割头来增强训练阶段的特征提取,可以将分割头插入不同位置进行在线增强策略。测试阶段可以舍弃,因此并不占用计算资源。Bisenetv2网络的双路分割策略实现了分割精度和推理速度的良好平衡。

图1 Bisenetv2结构图
1.2 本文模型的网络总体架构
随着卷积层的不断堆叠,缺陷图像的细节信息会逐步消失,网络在实际运用中难以区分特征差异较大的同类缺陷并将其归为背景造成边缘过分分割和内部欠分割现象。针对上述问题,本文提出的双边实时语义分割网络充分考虑上下文信息来扩大感受野,其网络总体结构如图2所示。

图2 本文模型网络总体架构
改进了语义分支的上下文嵌入块以感知不同缺陷对象的区别和联系。聚合层将具有全局上下文信息的高级特征经过两倍上采样和四倍上采样通过门控机制与低层特征进行融合,更好地过滤噪声,弥补缺陷图像在不断下采样过程中丢失的细节信息。在模型的预测阶段引入两个连续的交叉注意网络(criss-cross attention,CC)[13],每个像素最终可以从所有像素捕获长期依赖关系,以较低的内存和计算成本获得密集上下文信息。主干部分采用了Faster Bisenet[14]的思想,使用1×1卷积整合了一个共享的浅层网络对细节特征进行编码。语义信息仍然可以通过图2中的语义分支卷积块对低分辨率特征进行有效学习。在图2的各阶段加入分割头,同时引入深度监督指导训练过程,通过控制图中α1、α2、α3和α来控制各阶段损失函数所占比重,经过实验验证将α1、α2、α3设为0.1,α设为0.7作为最终损失函数组成。图2中卷积块上边的数字代表卷积核通道大小,下边的分数代表特征图分辨率与原图的比值。
1.3 双路分支
空间分支的实例化包含三个阶段,即将原图下采样到1/8大小,每一层都是卷积层,然后是批处理归一化(BN)和激活函数(Relu)。语义分支的前三层特征共享空间分支的前三层,如图2中主干部分所示,由1×1卷积连接,第四层和第五层由聚合扩展层(gather-and-expansion layer,GE层)提取特征,其内部结构如图3所示。
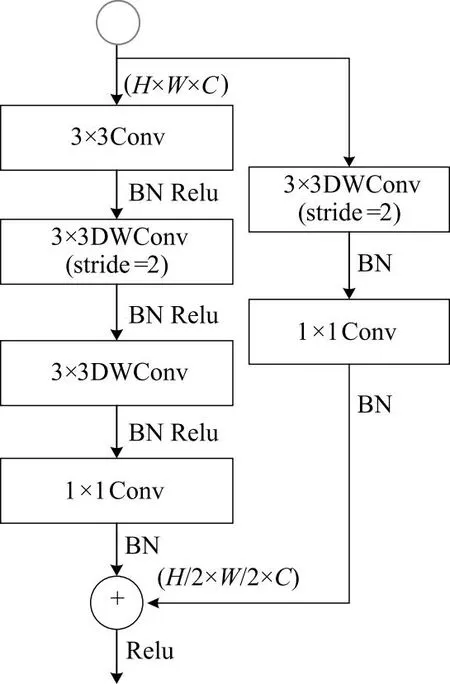
图3 聚合扩展层
聚合扩展层包括:①用卷积核大小为3的普通卷积聚合特征响应并将其扩展到更高维空间;②在聚合扩展层的每个输出分支上独立执行3×3深度卷积;③最后使用1×1卷积进行通道整合,将深度卷积的输出投影到一个低通道容量空间。当stride=2时,采用两个3×3深度卷积,进一步扩大了感受野,一个3×3深度可分卷积作为残差连接进一步加强特征。主干部分双路分支的实例化见表1,其中opr为操作,k为卷积核大小,c为通道数,s为步幅大小,r为重复次数。
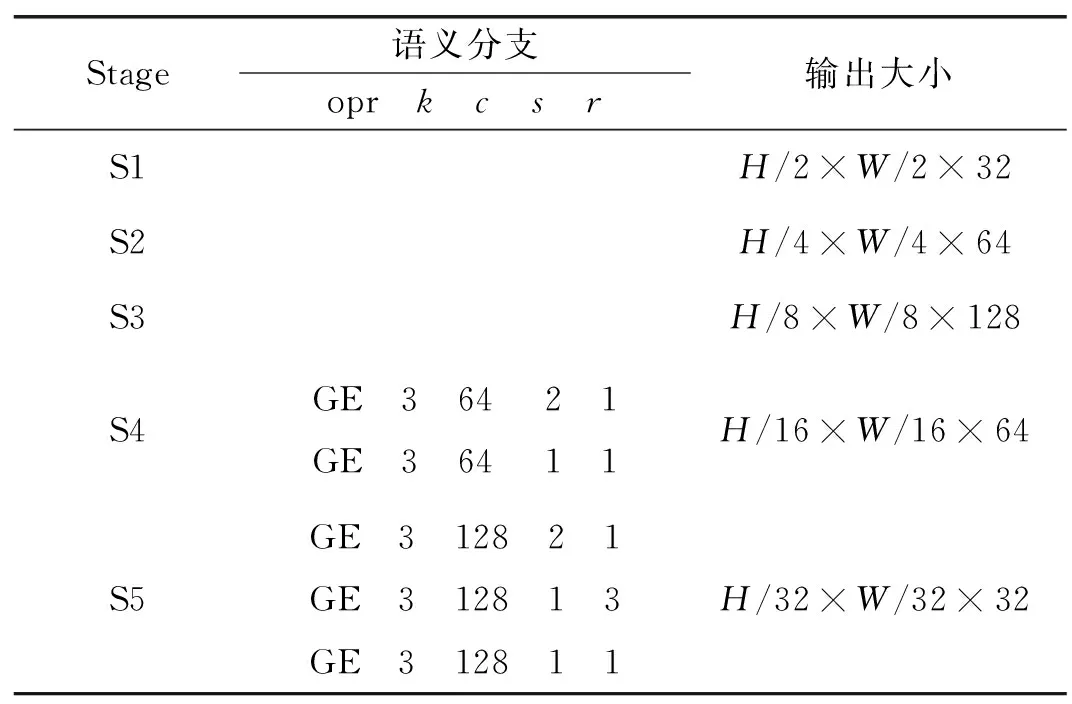
表1 双路分支实例化
1.4 上下文引导块
语义分支需要大的接受域捕获高级语义,但是Bisenetv2的上下文嵌入(context embedding)块仅使用全局平均池化来获取全局信息,提取到的信息不够丰富。因此在语义分支之后设计一个上下文引导(context guided,CG)块是很有必要的,本文借鉴于CGNet[15],将原文中CG块的全局平均池化之后的全连接层改为1×1卷积,可以减少参数量并且不破坏图片空间结构,具体如图4所示。
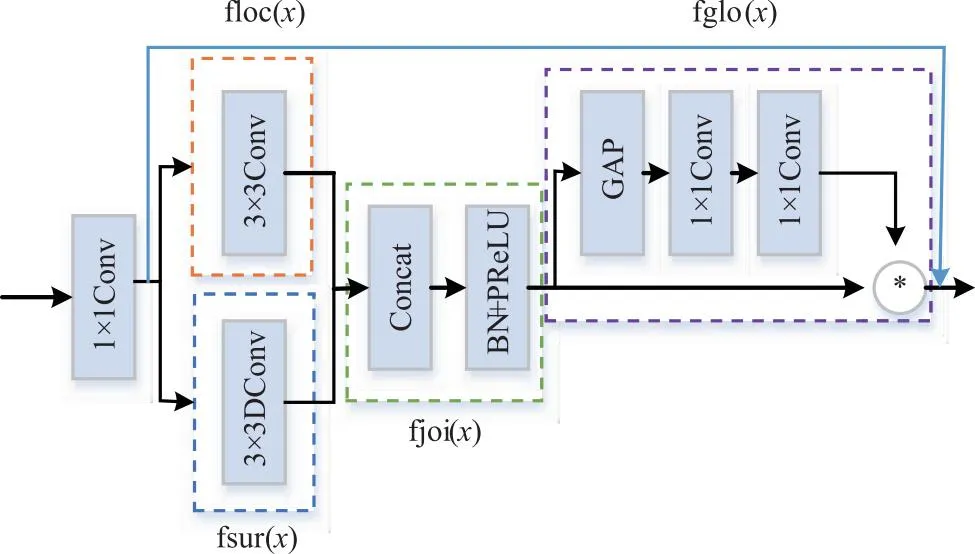
图4 上下文引导块
图4中左上方虚线框内为局部特征提取器floc(x),x代表此部分输入特征,使用3×3卷积获取局部特征。左下方框内为周围上下文提取器fsur(x),使用3×3空洞卷积获取周围特征,通过控制空洞系数可以调节周围视野大小,空洞系数设置为3。之后为联合特征提取器fjoi(x),从floc(x)和fsur(x)中获取关键特征,fjoi(x)被设计为通道连接操作,批处理归一化加一个激活函数PReLU。最后虚线框内fglo(x)提取全局信息以改进联合特征,fglo(x)使用一个全局平均池化,聚合对应的全局上下文,然后使用1×1卷积进行扩通道的特征整合,所提取的信息被视作一个加权向量应用于通道细化联合特征。fglo(x)的细化操作对于输入图像是自适应的,因为提取的全局上下文是从输入图像生成的。此外,CG块使用由图中箭头所示的残差连接。这有助于学习高度复杂的特征,并在训练过程中改善梯度反向传播。
1.5 双门控引导聚合层
由于细节分支和语义分支所提取的特征是不同层次的,两个分支的相关信息较少,简单的信息融合会导致聚合结果的性能下降。受门控完全融合GGF模块[16]的启发,设计了双门控引导聚合层(dual gated guided aggregation layer,DGA层),DGA在H/16×W/16和H/8×W/8两个层次对空间分支和语义分支的特征进行选择性融合,H和W代表原图的高和宽大小。门控是一种成熟的机制,使用Sigmoid操作衡量特征图中每个特征向量的有用性,以有效增强有用信息和抑制无用信息。然后利用空间分支中有价值的空间特征来弥补语义分支中缺失的细节。其结构设计如图5所示,公式定义如下:
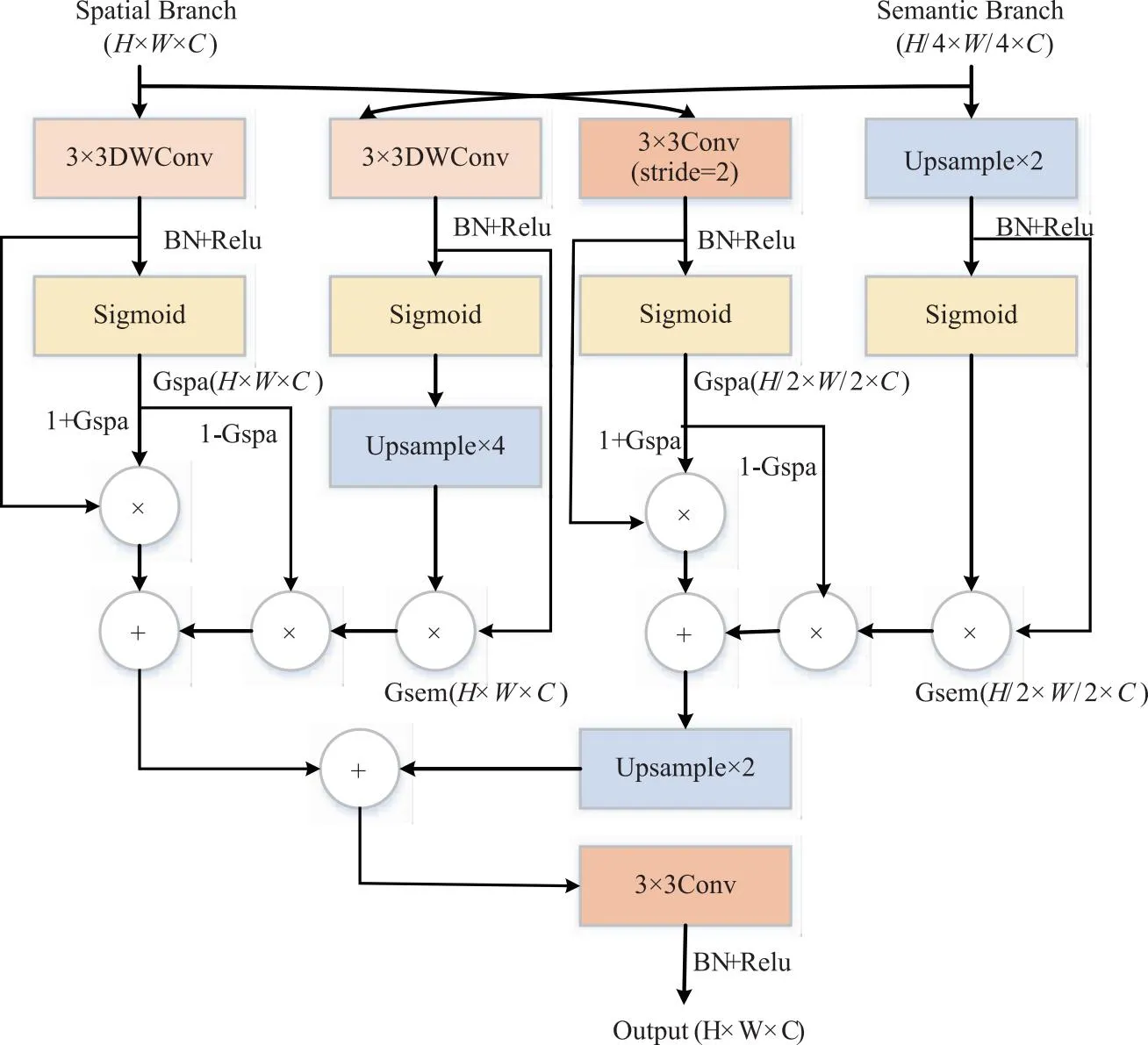
图5 双门控引导聚合层
Out=[(1+Gspa)·Xspa+(1-Gspa)·Gsem·Xsem]+
[(1+Gspa2)·Xspa2+(1-Gspa2)·Gsem2·Xsem2]
(1)
其中,·为通道维度上逐元素相乘,+为通道维度上逐元素相加,X为两个分支的输出特征图,Xspa2,Xsem2,Gspa2,Gsem2为H/16×W/16层次的信息,每个门值G为对应特征的Sigmoid输出。由公式(1)可知,只有当Gsem值较大而Gspa值较小时空间分支的特征向量可以融合来自语义分支的特征向量,即当语义分支拥有空间分支所缺少的有用信息时才会发送信息。门控机制可以通过门将有用的信息调节到正确的位置,从而避免信息冗余。与Bisenetv2中的简单卷积聚合相比,DGA能逐像素衡量每个特征向量的有用性,避免了冗余操作,有效聚合特征。
1.6 交叉注意模块
长期依赖关系可以捕获有用的上下文信息,从而有利于语义理解,本文在特征融合之后模型预测之前利用循环交叉注意(recurrent criss-cross attention,RCCA)模块[13]在基于细分的基准上实现优越的性能。纵横交错的注意模块在水平和垂直方向上收集上下文信息,以增强像素的代表能力,获得聚合远程上下文的新特征图。由于基于自注意力的方法需要生成巨大的注意映射来度量每个像素对之间的关系,其计算复杂度较高,因此将交叉注意模块加在分辨率较小的特征融合之后,可以减少大量参数同时在预测之前增强特征,其结构设计如图6所示。

图6 交叉注意模块
给定局部特征X∈RC×H×W,对局部特征分别进行三个1×1卷积操作生成三个特征映射Q,K,V,其中{Q,K}∈RC′×W×H,V∈RC×W×H,由于降维Q,K特征的通道数小于输入通道数,然后对获得的映射Q,K进行Affinity运算和Softmax获得注意映射A∈R(H+W-1)×W×H。特征图Q在空间维度的每一个位置u处,可以得到一个向量Qu∈Rc′,对于Q中每一个位置u,从K中与u在同一行同一列的向量提取特征,可以得到一个集合,Ωi,u∈Rc′,Ω∈Rc′代表特征图Ω中位置i,u处的特征向量。对Q中的每个位置u都与K中对应的Ωi,u进行向量相乘即Affinity操作,即可以获得一个新的特征图D,Affinity操作如公式(2)所示:
(2)
di,u∈D为特征Qu与Ωi,u的关联度,i=[1,...,(H+W-1)],D∈R(H+W-1)×W×C。然后,沿着通道维度在D上应用一个softmax层,得到注意映射A代表Q与K的关联度。同理,特征图V在空间维度的每一个位置u处,可以得到向量Vu∈RC和集合Φu∈R(H+W-1)×W×C。集合Φu为V中与位置u同行或同列的特征向量集合,通过Aggregation运算收集远程上下文信息,运算如公式(3):
(3)
其中,Xu′为输出特征映射X′∈RC×W×H中对应每一个位置u处的特征向量。Ai,u为A在通道i处位置u处的标量值。将蕴含的远程上下文信息以权值的方式添加到局部特征X中,增强局部特征的像素表示。由于聚合了局部特征水平和垂直方向的周围信息它具有广阔的语义视野,并根据空间维度的注意映射有选择地聚合语义,这种特征表示实现了计算速度与捕获长期依赖的双赢,对分割任务具有更强的鲁棒性。
尽管纵横交错的注意模块可以在水平和垂直方向上捕获长距离的上下文信息,但像素与周围像素之间的连接仍然稀疏。获取密集的上下文信息有助于语义分割。本文在上述交叉注意模块的基础上引入了循环交叉注意模块,可以通过控制循环次数决定获取周围信息的感受野大小,本文使用两次循环,在第一个循环中,交叉注意模块以局部特征映射X作为输入,输出特征映射X′,其中X与X′形状大小相同。在第二个循环中,交叉注意模块以X′为输入特征映射,X″为输出特征映射。
如图2中循环交叉注意部分所示,本文使用两个连续的交叉注意模块,足以从所有像素中获取远程依赖关系,生成新的特征图,具有密集丰富的上下文信息。
2 实验
2.1 数据集
本文实验所用图像数据来自东北大学的NEU缺陷数据集,选取夹杂物(Inclusion)、斑块(Patches)、划痕(Scraches)三类图像样本进行语义级别标注,并对其进行拼接、翻转等操作扩充数据,最后包括训练集图片4 632张,测试集图片840张。实验将图片分辨率大小调整为480×480,为了标准化数据对输入的图像及其对应的掩膜进行归一化处理。
2.2 实验设置
实验所用操作系统为Windows10, 显卡配置为NVIDIA GeForce MX250,编程语言采用Python3.6集成工具OpenCV、Pandas等扩展库和PyTorch深度学习框架。
由于网络模型较小,本文采用从头训练的方式,设置训练迭代次数200次,采用SGD优化器进行迭代优化,初始学习率设置为1e-3,动量设置为0.9,衰减率设置为5e-4,使用动态学习率衰减策略,Batchsize设为8。
2.3 评价指标
本实验使用平均交并比(MIoU)和平均F1分数(MF)来评价模型的性能,评价指标基于混淆矩阵,其中包含真阳性(TP)、假阳性(FP)、真阴性(TN)和假阴性(FN)四项。对于每个类别,F1分数和IoU计算公式如下:
(4)
(5)
其中Ppre=TTP/(TTP+EFP),Rrec=TTP/(TTP+FFN),此外,MIoU为所有类别IIoU的平均值,MF为所有类别F1的平均值。
2.4 消融实验
为了验证本文模型对于带钢表面实时缺陷检测的有效性,分别利用Bisenetv2,Bisenetv2+RCCA,Bisenetv2(特征共享)+RCCA+CG,Bisenetv2(特征共享)+RCCA+CG+DGA(本文模型)进行消融实验,结果见表2。
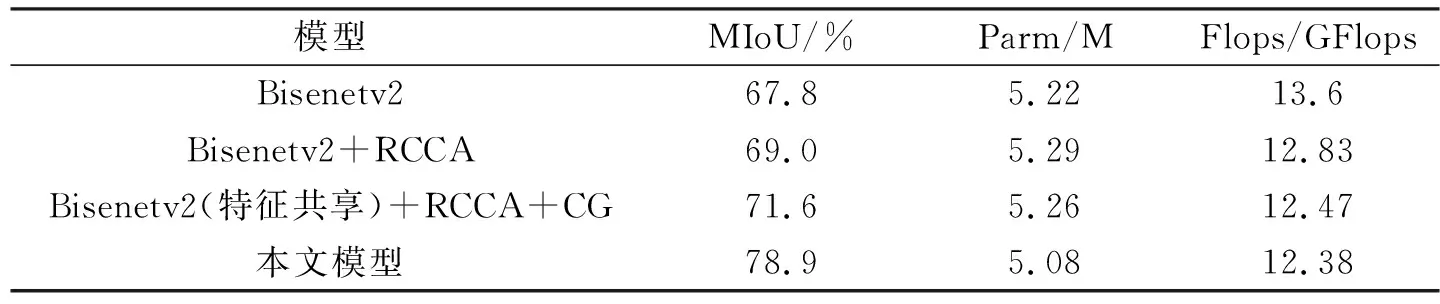
表2 消融实验对比
从表2可以看出,本文模型改进非常有效,原模型加上循环交叉注意网络、上下文引导块等获取全局信息之后,MIoU提高了3.8%,在此基础上加入本文设计的双门控引导聚合层之后,MIoU提升了7.3%。总体来说本文模型在减少0.14 M参数量和计算量的情况下MIoU提升了11.1%。对比改进前后模型的MIoU值可以看出本文模型具有更好的像素表达能力。
在NEU缺陷数据集中选取840张数据进行测试,部分检测结果如图7所示。图7中每一行代表不同的测试图片。从第一行可以看出,对于简单背景、缺陷类别数较少的情况,两者都能达到不错的检测效果。从下边几行可以看出在复杂背景下,Bisenetv2漏检、多检、错检的情况,而本文模型可以检测出第二行和第四行中对比度较弱的内含物如图7中框内所示,而原模型会漏检。对于第三行和第五行中框内原模型多检的情况,本文模型可以更好地对比类间信息,防止边缘误差。

图7 检测结果对比图
2.5 对比实验
为了进一步验证模型有效性,将本文模型与当前主流语义分割模型进行对比,包括通用语义分割模型Segnet[7]、DenseASPP[6]、实时语义分割模型Enet[9]、CGNet[15]、Bisenetv1_Res18[17]、Bisenetv2等模型进行对比,结果见表3。从表3中可以看出本文模型精确度高于其他模型,参数量除了比ENet、CGNet略高之外远远小于其他模型,进一步验证了本文模型的有效性。
3 结束语
针对缺陷检测中存在的类内差异性和类间相似性,以及实时语义分割网络精确度不高的问题,本文提出一种改进的Bisenetv2模型,通过引入全局信息以较低的计算成本和内存成本捕获了密集上下文信息,提高了精确度。设计双门控融合机制学习多层次特征图,更好地弥补了空间分支和语义分支之间的差距,使细节特征可以融合到各级别特征中,提高了聚合效果。经实验验证,本文模型能以较快检测速度和较高检测精度完成带钢表面缺陷的分割任务,可大大减少高强度人工作业,对带钢质量的定期巡检有一定参考价值。
由于带钢表面缺陷类型复杂多样,数据采集标注任务有一定难度,本文仅对内含物、斑块、划痕三类容易标注缺陷类型进行了训练,开裂、氧化皮、轧制鳞片等其他缺陷类型暂未进行实验。为进一步提升方法的实用性和鲁棒性,未来的研究将会拓宽途径收集标注更多的数据样本或者通过半监督学习降低对大量数据样本的依赖,使技术可以应用到更复杂多变的场景中。
