基于参考图像的超分辨率重建算法综述
2024-01-05张东晓
张东晓,唐 妮
(集美大学理学院,福建 厦门361021)
0 引言
图像超分辨率重建(super-resolution reconstruction,SR)是指从一张或多张低分辨率(low-resolution,LR)图像重建出高分辨率(high-resolution,HR)图像的过程[1],是一类典型的不适定性问题,也是计算机视觉和图像处理领域中重要的研究方向。图像SR在实际生活中有着丰富的应用,如智能安防[2]、医学影像[3]、无人机侦察[4]、大气遥感[5]等。
图像SR可分为多帧图像超分辨率重建(multiple image super-resolution reconstruction,MISR)和单帧图像超分辨率重建(single image super-resolution reconstruction,SISR)两大类。MISR[6-9]通常针对同一场景不同角度、不同方位的图像序列,利用这些序列之间存在的互补信息进行重建。但在某些场景中MISR并不适用,如在提升老旧照片分辨率时,对同一场景往往无法再次成像,所以无法获得存在互补信息的LR图像序列,此时MISR通常会失效。针对这种只有单张LR图像的情形,SISR通常通过学习的方法来重建出HR图像。本文主要关注SISR方面的进展。
在经典的SISR方法中,基于图像自相似的方法[10]和基于稀疏表示的方法[11]均取得过优异的重建效果。近年来,由于深度学习具有强大的特征表达能力,基于深度学习的图像SR胜过了经典SISR方法,成为了研究的热点。该方法通过神经网络直接学习LR图像到HR图像即端到端的映射,从而重建出HR图像。
自从Dong等[12]首次将卷积神经网络(convolutional neural networks,CNN)用于图像超分辨率重建以来,基于深度学习的图像SR得到快速发展,不断涌现出新的网络结构,重建效果也是逐步提升。如基于SRCNN(super-resolution CNN)[12]的改进算法[13-14]、基于残差网络的重建方法[15-17]、基于密集连接的重建方法[18-20]等。
近期,在SISR的研究中,一部分学者继续关注设计更好的网络结构、更优秀的损失函数;另一部分学者则开始关注SISR的新思路:将已有的HR图像作为参考,利用参考图中丰富的纹理来补偿LR图像缺失的细节信息,从而缓解图像SR的不适定性。这种基于参考图的超分辨率重建(reference-based super-resolution reconstruction,RefSR),其重建过程如图1所示。与普通的SISR不同,RefSR的输入除LR图像外,还需额外输入一张或多张与LR图像内容或纹理相似的HR参考图像。众多实验结果表明,在Ref图像的帮助下,RefSR能够重建出更多真实的细节和纹理信息,其结果优于SISR。

尽管RefSR的相关研究开展时间较短,但也涌现出了很多先进的重建思想和算法,因此急需对此做一个全面的梳理。在现有SISR的综述性论文中,鲜有专门介绍RefSR。如Wang等[21]从有监督、无监督和典型应用领域三个方面,全面阐述了基于深度学习的SISR技术;唐艳秋等[22]从模型类型、网络结构、信息传递方式等方面对SISR方法中各种算法进行了详细评述;曲延云等[23]将基于深度学习的SISR方法划分为有监督SISR方法和不成对SISR方法,并进行了深入分析等。这些关于超分辨率重建的综述性论文均未曾提及RefSR方法,更未对其进行详细阐述。因此,本文在分析和借鉴了若干图像RefSR研究成果的基础上,从基于图像对齐的方法和基于图像块匹配的方法入手,对近年来的RefSR方法进行综述性的介绍,以期抛砖引玉,为该领域的后续研究提供有益参考。
1 RefSR的主要方法
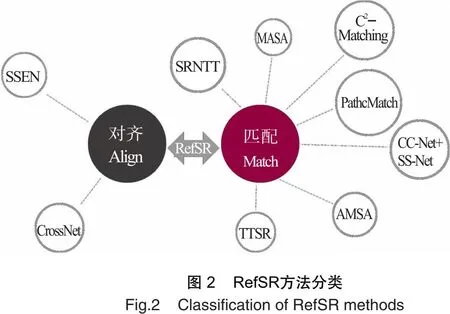
在RefSR算法设计过程中,需要考虑如何更好地使用Ref图像。通用的做法是在Ref图像中寻找LR图像对应的高频信息,尽可能利用Ref图像的纹理和细节信息来帮助LR图像重建。如图2所示,依据Ref图像与LR图像的对应方式,可以将RefSR分为两大类:基于图像对齐的方法和基于图像块匹配的方法。基于图像对齐的RefSR方法是利用光流、可变形卷积等模型将输入的LR图像与Ref图像进行全局配准,再将对齐后的Ref图像的纹理用于LR图像重建,其代表模型有SSEN、CrossNet。而基于图像块匹配的RefSR方法则是将输入图像分割为若干个块,对每个块进行相似度匹配,再利用匹配后的LR/Ref图像进行重建。该方法代表模型有SRNTT、TTSR、MASA等。
在Ref图像和LR图像是同一个场景的情况下,基于图像对齐的方法能够取得优异的重建效果,但是当它们的场景不相同时,基于图像对齐方法的重建效果则不理想。相较而言,基于图像块匹配的方法对参考图像要求不是很高,因此成为了目前该领域的研究热点。
1.1 基于图像对齐的RefSR方法
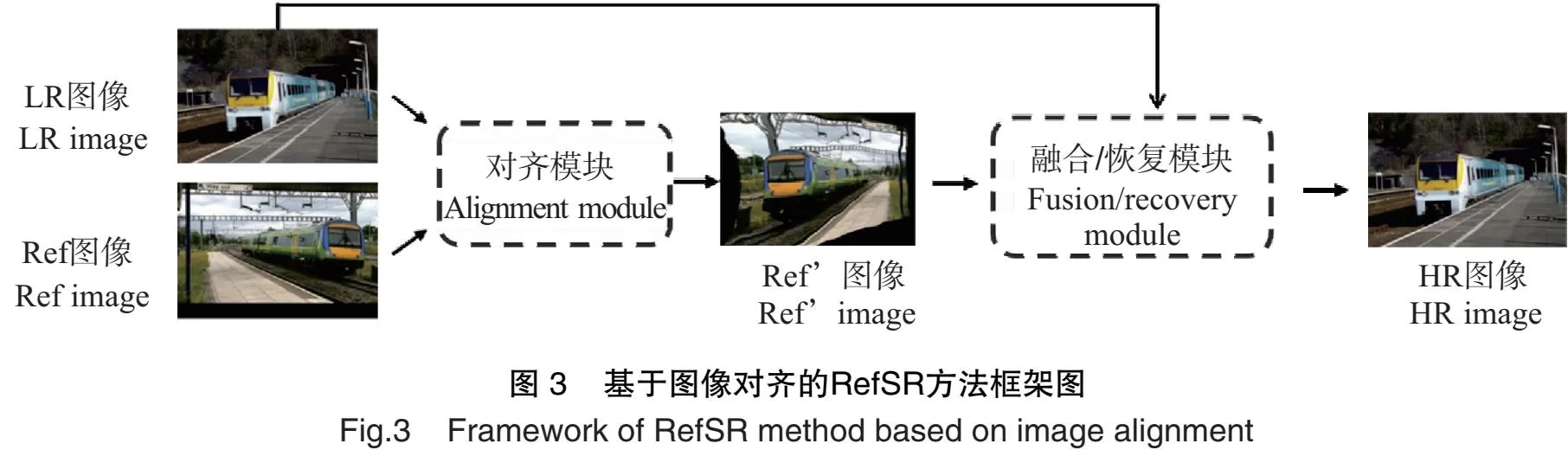
由于Ref图像与LR图像存在差异,若直接将Ref图像中的纹理信息融入到LR图像中,则重建出的HR图像的效果不佳,所以将两幅图像对齐显得尤为重要。这种基于图像对齐的RefSR方法的核心是图像对齐操作,其框架如图3所示。
1.1.1 CrossNet
基于图像对齐方法的代表是Zheng等[24]的研究,他们提出了一个跨尺度端到端的图像SR网络(CrossNet),其中图像对齐使用了光流法。该网络利用SISR方法对LR图像进行上采样,得到与Ref图像相同大小的上采样图,再分别提取出上采样图和Ref图像的多尺度特征;然后,利用改进的FlowNetS模型[25]学习不同尺度LR/Ref图像特征的光流信息来更新Ref图像,从而实现图像对齐操作;最后,通过融合操作重建出HR图像。该方法假设两幅图像具有较强的相似性,所以当LR/Ref图像相关性不强时,效果会有所下降。
1.1.2 SSEN
由于CrossNet中光流对齐的成本高,且使用其他预训练好的网络进行光流估计是不准确的,所以Shim等[26]提出了基于可变形卷积的网络结构SSEN(similarity search and extraction network,SSEN)。SSEN利用可变形卷积来寻找LR/Ref图像的对应关系,且用动态偏移估计器对可变形卷积的偏移量进行估计。同时,为了捕获特征内部和特征之间的全局相关性,Shim等[26]在动态偏移估计器中加入了非局部块。该方法能够处理非刚性变换的图像,计算量较小,但是无法解决长距离对应问题。
1.2 基于图像块匹配的RefSR方法
由于对图像进行全局配准要求图像具有较强的相似性,当Ref图像与LR图像只是纹理相似或者内容相似时,基于对齐的RefSR方法的效果将直线下降。针对以上问题,一些学者开始研究用图像块匹配的方式来寻找Ref图像与LR图像的对应关系。这种基于图像块匹配的RefSR方法的核心是图像块匹配模型的构建以及如何处理好匹配后的不对齐问题,其框架如图4所示,其中图4a为LR/Ref图像块匹配示意图,图4b为基于图像块匹配的RefSR方法的流程图。

1.2.1 图像块匹配
基于图像块匹配的方法可以追溯到Boominathan等[27]的研究。他们在提高光场(light field,LF)成像的分辨率和景深时,将单反数码相机捕获的HR图像作为Ref图像,指导LF图像的恢复。其算法核心是Ref图像的使用方式:Ref图像下采样后,计算其一阶、二阶梯度,利用欧式距离在梯度特征图中寻找与LR图像最相邻的9个块,然后加权平均得到融合结果。在后续研究中,该方法常被称作块匹配(patch match),它的匹配过程是在原始像素空间上进行的,操作简单,但匹配过程中没有充分利用高频信息,在融合阶段也只是简单地加权平均,导致高频信息没有得到很好地融合。
1.2.2 CC-Net+SS-Net
针对图像块匹配方法的问题,Zheng等[28]使用CC-Net(cross-scale correspondence network)模块,通过卷积神经网络提取LR/Ref图像特征,利用内积计算相似度,选择相似度最高的图像块作为匹配对,然后,将匹配好的图像块送入到SS-Net(super-resolution synthesis network)模块进行多尺度融合,最后得到SR图像。相对于图像块匹配方法中的梯度特征,该方法使用CNN提取的特征进行匹配,其准确度更高;但是在融合阶段是对每个图像块单独进行重建,所以该方法容易产生块状效应。
1.2.3 SRNTT
受图像风格迁移的启发,Zhang等[29]将RefSR作为纹理迁移问题,设计了一个端到端的SRNTT(super-resolution by neural texture transfer)模型:首先,对提取的图像特征进行密集块匹配,然后将匹配后的Ref图像进行纹理迁移,从而使得重建的SR图像拥有丰富的纹理信息。与图像块匹配方法不同,SRNTT方法是在特征空间进行匹配,虽然该方法促进了多尺度的纹理迁移,允许模型从语义相关的角度实现图像块匹配,但是其计算量大,不利于实际应用。
1.2.4 TTSR
Yang等[30]指出SRNTT忽略了全局信息,这使得现有方法对某类LR图像重建效果不佳。针对此问题,他们提出了一个包含注意力机制的SR网络架构TTSR(texture transformer network for image super-resolution)。该网络通过使用注意力机制挖掘深层次的特征对应关系,再将匹配好的特征送入跨尺度融合模块,最后得到SR图像。TTSR的特征匹配由4个模块组成,包括纹理特征提取模块、相关性嵌入模块、用于纹理迁移的硬注意力模块和用于纹理合成的软注意力模块。而在相关性嵌入模块,他们将LR图像中提取的特征作为转换器中的查询(query),将Ref图像中提取的特征作为转换器中的键(key),以获得硬注意力矩阵和软注意力矩阵。由于作为键的Ref图像是经过下采样后再上采样的图像,该操作无法避免信息丢失,从而导致匹配精确度下降,特别是在细节区域下降得较为明显。
1.2.5 MASA
目前,虽然密集图像块匹配方法的效果最好,但其计算量巨大且耗费存储空间;所以,Lu等[31]提出了一个粗-细对应匹配方案,称为MASA(matching acceleration and spatial adaptation for RefSR):首先对LR/Ref图像进行一个大尺度的图像块匹配,再利用图像的局部相似性,对大尺度图形块分块进行小尺度匹配。该方法可以大幅减少计算量。同时,虽然Ref图像与LR图像具有相似的内容或纹理,但其颜色和亮度可能不一样,若直接进行融合操作则效果不佳。所以他们在进行特征融合之前,加入了空间自适应模块,对得到的Ref特征图重新映射,使得模型对颜色和亮度更具有鲁棒性。
1.2.6 AMSA
虽然MASA方法的计算量有所下降,但是其计算复杂度仍是图像尺寸的平方级;所以,Xia等[32]对2009年Barnes等[33]提出的图像块匹配方法进行了改进,提出了CFE-PatchMatch(coarse-to-fine embedded patch match)快速匹配方法,并将其应用于RefSR中,使LR/Ref图像的匹配计算量从平方级降到了接近线性级。为了避免尺度不对齐问题,Xia等[32]提出了AMSA(accelerated multi-scale aggregation network)模型。其中,针对小规模的不对齐问题,提出了动态融合模块;针对大尺度不对齐问题,提出了多规模融合模块。这两个融合模块相互配合,产生了很好的融合效果。
1.2.7 C2-Matching
Jiang等[34]认为由于在输入LR图像与Ref图像之间存在两个差距——变换差距(如旋转、缩放等)和分辨率差距,使得执行局部迁移变得较为困难。针对这些问题,他们提出了C2-Matching(cross transformation and cross resolution matching)技术,用于跨变换和跨分辨率的关系匹配。对于变换差距,利用对比网络拉近匹配对之间的距离,疏远不匹配对之间的距离;对于分辨率差距,提出教师-学生关系蒸馏网络,与传统的知识蒸馏网络不同,此网络用HR-HR匹配来指导相对困难的LR-HR匹配。然后,通过设计的动态融合模块来解决潜在的错位问题。该技术在目前常用的数据集中,都显现出了极强的泛化能力,以及对大尺度和旋转变换的鲁棒性。
2 损失函数、数据集与评价标准
2.1 损失函数
损失函数在提升模型性能方面起着关键作用,常用于计算模型生成的HR图像与原始基准图像的差异,从而引导RefSR网络重建出更好的HR图像。损失函数的选择也尤为重要,一个好的损失函数能够帮助模型更优和更快地收敛,同时得到具有高精度,且与真实HR图像接近的HR图像。在RefSR方法中常用的损失函数主要有以下几种:
1)重建损失(reconstruction loss) 重建损失是图像SR中最常用的损失函数,一般可分为L1损失和L2损失,其表达式分别为:
其中:h,w和c分别表示图像的长、宽和通道数;ISR表示生成的HR图像;I表示真实图像。
2)感知损失(perceptual loss) 感知损失已被证明可用于提升视觉质量,并在图像SR中广泛应用。感知损失的核心思想是增强预测图像和目标图像在特征空间中的相似性,其公式为:
Lper=||φi(ISR)-φi(I)||2。
其中:φi表示某种特征提取网络的第i层。
3)对抗损失(adversarial loss) 在图像SR领域中,只需将SR模型作为一个生成器,再定义一个鉴别器来判断输入图像是否由生成器产生,就可以构造出一个对抗学习网络。而对抗损失能够有效地使模型产生更加真实的图像,其具体表达式为:
Lgan_ce_g=-lgD(ISR)
,
Lgan_ce_d=-lgD(I)-lg(1-D(ISR))。
其中:D(·)表示判别器;Lgan_ce_d是鉴别器的对抗损失;Lgan_ce_g是SR模型生成器的对抗损失。
4)纹理损失(texture loss) Zhang等[29]将纹理损失引入到RefSR方法中,来减少参考图像与生成图像的纹理差异,其表达式为:
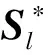
2.2 数据集
在RefSR研究中,最常用的数据集为CUFED5,该数据集是Zhang等[24]创建的,包含1个训练集(11 871个160 px×160 px的图像对)和1个测试集(126组图像)。在测试集中,每组图像包含1张HR图像和5个不同相似度的参考图像,如图5所示。

由于CUFED5数据集中占比最重的为室内、人、室外类型的图像,其他类型的图像较少,最近Jiang等[34]给出了一个新的数据集WR-SR,该数据集包含了80个图像对。相比于CUFED5数据集,WR-SR数据集还包含了动物、地标、建筑等图像类,其内容更加丰富,如图6所示。除此之外,常用的测试集还有Sun80[35](80张自然图像且有一些参考图像)、Urban100[36](100张建筑图像,无参考图像但图像有自相似性)、Manga109[37](109张漫画,无参考图像)。

2.3 评价标准
图像质量评价主要包括主观评价和客观评价两类。在RefSR研究中,常用的客观评价指标有峰值信噪比(peak signal to noise ratio,PSNR)和结构相似性(structural similarity index,SSIM)[38];主观评价一般采用主观质量评分法(mean opinion score,MOS)[39]。在图像SR中,使用对抗损失、感知损失等会获得更好的视觉效果,但是客观指标PSNR和SSIM会有所下降;所以,在使用PSNR/SSIM评价RefSR方法时,不仅要考虑基于所有损失(感知损失、对抗损失、重建损失等)的模型评价,还要单独评价只由重建损失训练的模型。
3 几种SR方法对比
自从卷积神经网络被引入图像SR以来,各种基于深度学习的图像SR方法不断涌现。近年来,RefSR方向吸引了大批学者,他们基于深度神经网络开展了很多卓有成效的研究。本文通过比较总结上述具有代表性的RefSR方法,概括了不同RefSR方法的网络特点及算法优点,详情如表1所示。

表1 RefSR方法对比

续表
如前所述,不管是基于图像对齐的RefSR方法,还是基于图像块匹配的方法,都关注着LR图像与Ref图像的对应问题;但是它们又各有侧重,如表1所示,这些方法各具特色,各有优点。具体归纳如下:
1)在方法的选择上,基于图像块匹配的方法是RefSR中的主流方法,其对图像的相关性要求没有基于图像对齐的方法高。此外,现有部分学者也开始研究多参考图的图像SR方法,如Yan等[40]提出的CIMR-SR模型等。
2)在参考图像的选择上,参考图像与LR图像内容越相似,RefSR方法重建出的HR图像效果越好。表2为不同方法在不同相似度的参考图像的帮助下,重建出的HR图像的PSNR和SSIM。其中:L1到L4表示输入相似度依次递减的参考图像,即L1是与LR图像相似度最高的HR图像,L4为相似度最低的HR图像;LR表示用LR图像作为输入的参考图像。由表2可以看到,算法的重建效果与参考图像的选择是有关系的,参考图像与LR图像相似度越高,重建效果越好。图7为图5展示的两幅CUFED5测试集图像基于不同相似度参考图像的细节重建结果,GT表示真实HR图像,可以看到,参考图像与LR图像相似度越高,重建出的HR图像的细节恢复得越好,这也证明了参考图像对RefSR重建的结果有一定的影响。

表2 不同相似度的参考图像对PSNR和SSIM的影响

3)从客观评价标准来看,RefSR方法的效果要优于现有的SISR方法。表3为不同的图像SR方法在CUFED5、Sun80、Urban100、Manga109测试集上的实验结果,实验结果均取自相关文献。这里除了比较RefSR不同算法的效果,也比较了主流的SISR算法。RefSR方法不仅比较了原始模型的PSNR和SSIM,还对比了只采用重建损失训练模型(用-rec表示)的PSNR和SSIM。由结果可见,与现有的SISR方法相比,RefSR方法的结果有大幅提升。
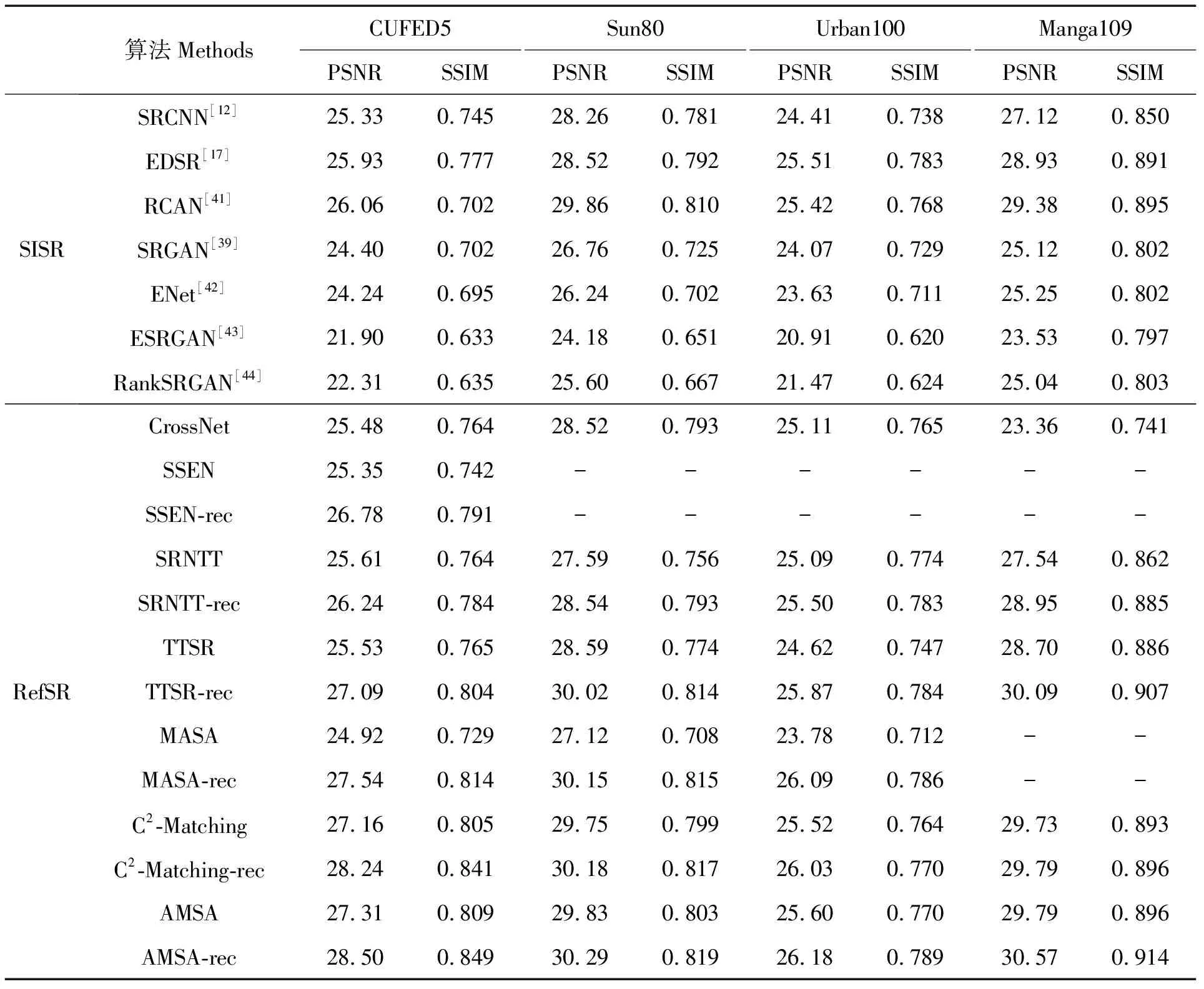
表3 不同SR方法的PSNR和SSIM
4)从视觉效果上看,在RefSR方法中,Ref图像为LR图像提供了更多的细节纹理信息。图8为目前效果最好的几种图像SR方法的效果(实验结果均取自相关文献),并展示了每张图像的低分辨率图及其参考图像,以及两种SISR方法(ESRGAN和BankSRGAN)和三种RefSR方法(MASA、C2-Matching、AMSA)对某个细节的重建效果。从图8可以看到,RefSR方法在人脸、字母等细节信息的恢复上效果更好,恢复出的细节信息更真实,其中AMSA模型效果是5种方法中最好的。
5)在RefSR方法中,模型中加入注意力机制、非局部块等,能大幅提升图像SR的效果。复杂的网络带来了好的重建效果,但也出现了计算量大、存储空间不足等问题。针对这些问题,研究者们对网络的设计不仅会考虑图像重建效果,还会考虑模型的计算量、参数量,使得模型更有利于实际应用。表4列出现有模型的参数量、计算量,可以看到AMSA模型的计算量是最小的,且其效果也是目前最好的。


表4 RefSR中各模型参数量和计算量
4 未来研究展望
图像SR作为计算机视觉领域底层视觉部分的经典问题,一直以来受到人们的广泛关注。目前,基于深度学习的RefSR方法取得了不错的效果。尽管如此,但仍存在一些问题有待解决:
1)现有的RefSR方法中,LR图像通常是由HR图像下采样得到的,以此模拟自然情况下图像退化过程,而在实际应用中图像的退化过程还包括噪声、模糊、压缩等。如何学习得到可以处理复杂退化图像的网络还有待探讨。
2)轻量化的RefSR方法。受算力的限制,现有RefSR方法无法在手机、平板等移动设备上直接使用,所以,如何将现有的RefSR方法轻量化,在保证效果的同时,降低参数量和模型复杂度是RefSR研究的热点。
3)在SISR方法中,现有的网络模块(如递归学习、密集连接等)和学习机制(如多路径学习、非局部相似性等)对SISR精度有很好的提升。在RefSR方法中,能否运用这些模块来进一步提升算法的性能,值得进一步去探讨。
