基于云计算技术的区域医疗档案信息数据安全共享方法
2024-01-04邱琳刘秉峰汤洁武金玉
邱琳,刘秉峰,汤洁,武金玉
(中国人民解放军陆军第八十集团军医院,山东 潍坊 261021)
0 引言
随着医疗行业的快速发展和信息化程度的不断提升,医疗档案信息数据的安全共享变得越来越关键。根据患者所在的区域建立区域性的医疗档案数据共享功能成为领域内所共同关注的问题。通过详细研究区域医疗档案,政府和医疗机构可以全面了解当地医疗资源的分配和使用状况,优化医疗资源的配置和规划,医疗服务的覆盖范围和效率也得到相应提升[1]。
区域医疗档案提供了丰富多样的病例和数据,为医学教育和研究提供了宝贵的资源库,推动了医学的持续发展。通过共享和互操作的区域医疗档案,患者可以在不同的医疗机构间无缝隙转诊,医生也可以更好地了解患者的健康状况,提供更连续且全面的医疗服务。
为解决如何确保数据的安全性、隐私性和共享性的问题,本文提出了一种区域医疗档案信息数据安全共享方法,为医疗档案信息数据的安全共享提供有效支持。基于此,本研究提出了一种区域医疗档案信息数据安全共享方法,并基于云计算技术对此进行实现。该方法利用云计算技术对于大数据量的负载均衡能力,对数据共享过程中数据量较大的问题进行优化,在很大程度上避免了数据共享前后的信息损失问题,进一步提高区域医疗档案信息数据的管理与应用水平。
1 区域医疗档案信息数据安全共享方法设计
1.1 异质分析区域医疗档案信息数据
基于区域医疗档案信息数据的分布和特征不同,对数据的异质性进行分析。这一过程主要针对特征空间异质性、标签分布异质性[2]两个方面进行分析。对区域医疗档案信息数据表现出的基本一致性进行表达,如公式(1)所示:
公式中,A表示信息数据的基本性质,i表示医疗档案信息数据,k表示该组数据所覆盖的区域,ri表示对应数据的标签,L表示数据梯度,wk表示对应区域的距离约束,Di表示该数据的差分隐私值。
根据两个共享节点之间的欧式距离对公式(1)的表达式进行梯度更新引导,如公式(2)所示:
公式中,Lr表示梯度更新引导值,N表示数据共享节点的数量,wi表示数据共享节点的距离约束。
将公式(2)的结果作为更新后的梯度代入到公式(1)中进行修正,得到对区域医疗档案信息数据异质性的分析结果。
1.2 基于云计算技术安全虚拟化数据
基于区域医疗档案信息数据共享量较大的问题,本研究引入云计算技术对信息数据进行虚拟化,对数据共享过程的数据访问步骤进行简化。
首先,根据分析所得的数据异质性,将数据写入文件,主要步骤为:
步骤1:调用FileSystem 创建数据写入文件请求[3]。
步骤2:接收到远程过程调用请求后创建元数据记录。
步骤3:文件分割成大小为128M 的数据块,并将这些数据块依次写入一个内部队列中。
步骤4:根据一定的策略找到合适的数据块副本存储节点,并通过管道流的方式将数据写入文件。
步骤5:应用master 向资源管理器申请并分配容器1给作业,并与容器1所在的节点管理器进行通信,开启作业的应用master进程。
在将数据写入文件后,对文件中的数据进行虚拟化处理。本研究采用Xen 作为云计算虚拟化的开源平台。将写入文件的档案信息数据载入到开源平台的硬件与云计算虚拟机之间,构成准虚拟化环境[4]。在准虚拟化环境中,设计云计算虚拟化指令,如图1所示。

图1 云计算虚拟化
图1中,虚拟化步骤中的含义如表1所示。
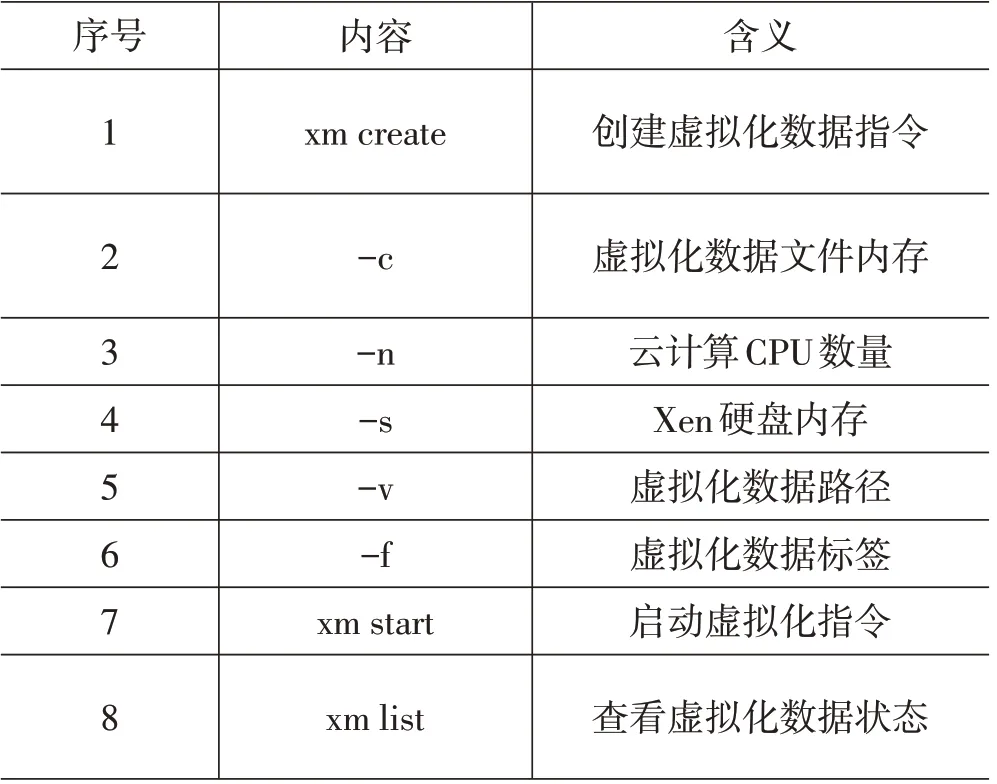
表1 云计算虚拟化含义表示
通过上述步骤,完成基于云计算技术的医疗档案信息数据的虚拟化过程。
1.3 构建认证框架实现安全共享
在数据共享端对通过云计算技术虚拟化后的区域医疗档案信息数据进行安全认证,实现数据安全共享。
本研究采用拜占庭容错共识算法建立区域医疗档案信息的认证框架。将虚拟化数据作为认证框架中的正常节点[5],则框架中的共享节点总数计算为公式(3):
公式中,| |
R表示,f表示虚拟化数据节点,m表示无效节点数。
当客户端发出医疗档案信息数据的共享请求后,认证框架的主节点进行数据哈希值检验,如公式(4)所示:
公式中,M表示哈希值检验通过的数据,Hi表示,数据i的哈希值,K表示数据共享请求来源区域,G表示数据认证遍历节点数。
当数据共享请求端通过认证后,将虚拟化数据传输至请求端,实现数据共享。
通过上述步骤,完成基于云计算技术的区域医疗档案信息数据安全共享方法的设计过程。
2 实验与结果分析
2.1 实验准备
设计对比实验对本研究所提出的基于云计算技术的区域医疗档案信息数据安全共享方法的实践应用有效性进行测试实验。
本次实验的数据采用某区县公共卫生平台所公开的健康档案数据作为初始样本,根据该样本进行区域医疗档案信息实验数据的模拟,每组实验数据的内容如表2所示。

表2 模拟实验数据内容
如表2所示的类别,在不同的数据仓库中模拟若干个医疗档案信息数据,模拟出区域性的信息数据,其信息格式如图2所示。

图2 医疗档案数据模拟格式
按照上述格式模拟生成本次实验的数据信息。完成上述准备后,于Python 3.9.2、PyTorch 1.13.0 的环境中开展本次实验。
2.2 实验结果及分析
为了更加有效地体现出本文所提方法的应用性,采用对比实验的方式进行本次实验。分别选用基于虚拟网络计算的档案信息数据共享方法以及基于特征提取与聚类的档案信息数据共享方法作为对照组,分别命名为方法1 和方法2,将本文所提方法命名为方法3。
分别为不同的共享方法导入不同数据量的实验数据,检验不同方法共享前后同一数据的一致性数量进行性能评价。
经过实验,得到不同共享方法的实验结果如图3所示。
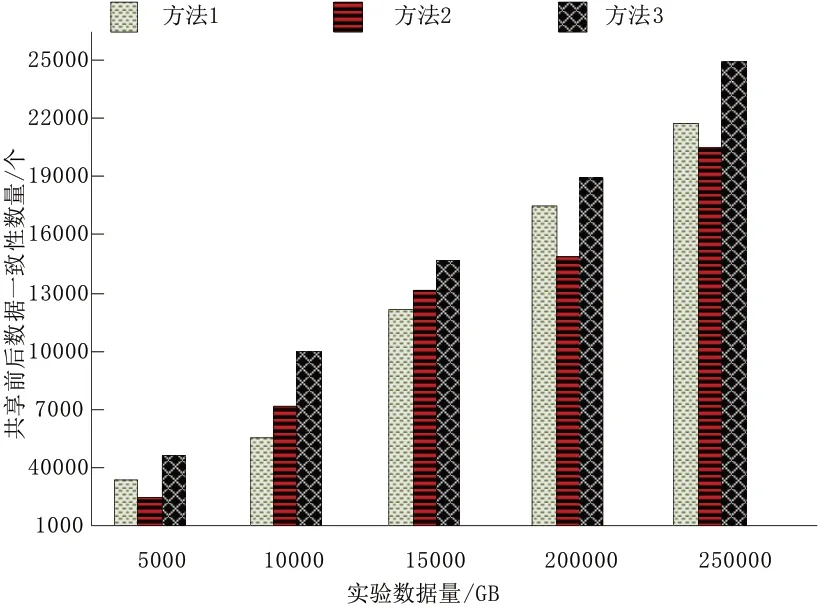
图3 不同方法实验结果
由图3可知,在本次实验中,在不同数据量下,本文所提出的数据安全共享方法对于区域医疗档案信息的共享结果,表现出的前后一致性均比较高,每轮实验均与实际导入数据量高度一致,而方法1和方法2 在不同数据量下,所表现出的一致数据量均较本文方法少。由此可见,本文所提方法对于区域医疗档案信息数据能够实现较高质量的安全共享,共享后的数据与原始数据基本一致,信息丢失情况较少,共享过程较为安全。
3 结束语
为了进一步提高医疗服务的整体质量,实现区域性的医疗档案信息数据共享十分重要,为医疗领域带来了更大的便捷性。对此,本研究提出了一种基于云计算技术的区域医疗档案信息数据安全共享方法。该方法有助于政府和医疗机构更好地了解本地医疗资源的分布和使用情况,优化医疗资源的配置和规划,提高医疗服务的覆盖面和效率。同时也为医学教育和研究提供了宝贵的数据资源库,推动医学科学的发展,成为未来医疗档案信息管理的重要趋势。
